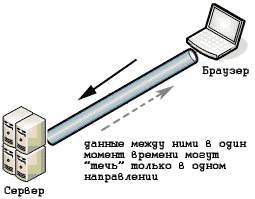
Перед тем как пользователь увидит содержимое сайта у себя на экране, браузер делает запрос на сервер чтобы получить это самое содержимое. Вопрос получения данных интересен тем, что этот этап уж очень сильно влияет на скорость отображения веб страниц. И чтобы уметь разгонять свои сайты нужно как минимум представлять как эти данные получает браузер.
Первое что нужно запомнить — браузер запрашивает и получает данные посредством HTTP протокола, поэтому его (браузер) еще называют HTTP клиентом.
Протокол передачи Гипертекста (HTTP — англ. HyperText Transfer Protocol) — специально разработанный протокол как основа World Wide Web и используется для передачи всех необходимых данных: HTML кода, изображений, CSS файлов, javascript и т.д. Остановимся только на моментах интересных фронт разработчику (с тонкостями HTTP все желающие могут познакомится в спецификации).
Основой HTTP является технология «клиент-сервер»: клиент — это тот кто запрашивает данные, сервер — кто обрабатывает и отдает. Связь между ними осуществляется посредством череды перемежающихся HTTP-запросов и HTTP-ответов.
HTTP является синхронным протоколом. Это значит, что клиент послал запрос серверу и пока ждет от него ответ, следующие запросы послать не может. Это как лифт, который уехал. И чтобы им воспользоваться, нужно подождать пока он вернется.
Запрос происходит в несколько этапов:
Это легко проследить если воспользоваться например, плагином для Firefox — Firebug или встроенными средствами для разработчика в Chrome.

Первый этап (DNS-запрос и установка соединения) отнимает довольно много времени. В протоколах HTTP ранних версий, после того, как получен ответ на запрос, соединение разрывалось. И чтобы послать новый запрос, нужно снова тратить время на DNS-запрос и установку соединения. Это было большим ступором, который устранили в спецификации HTTP 1.1 — появился режим постоянного соединения (keep-alive): при первом запросе происходит соединение, которое не разрывается. Это был прорыв, который ощутимо разогнал Веб.
Соединение не разрывается, если все запросы направлены на один хост. Если какой-то элемент веб страницы размещен на другом хосте, для запроса этого элемента устанавливается новое соединение, начиная с DNS-запроса.
Но смотрим на диаграмму HTTP запроса дальше: видим, что время соединения ощутимо меньше, чем время ожидания ответа. И тут уже HTTP 1.1 не спасает. Поэтому не важно, что у тебя четыре процессора, 5 Гб оперативки и навороченная видеокарта. От этого веб страницы быстрей открываться не станут, ведь большую часть времени вся эта «мощь» простаивает в ожидании пока пакеты данных пройдут туда-сюда.
Этот медленный механизм обмена данными, делает сайты неконкурентноспособными по отношению к десктопным приложениям в вопросах скорости реакции на действия пользователя. Поэтому одним из основных способов разогнать сайт — это свести к минимум число отдельных обращений к серверу.
В реальности схема связи с сервером несколько сложней и это выходит за рамки данной статьи.
Чтобы хоть немного ускорить работу HTTP, был разработан механизм параллельных соединений, которые устанавливает браузер для одновременной доставки нескольких объектов веб страницы. Спецификация HTTP 1.1 рекомендует не использовать одновременно не более двух соединений к одному хосту. Связано с тем, что разрабатывалась спецификация давно, тогда не было таких широкополосных каналов и мощных серверов. Современные браузеры таких соединений устанавливают минимум 4 и это число можно увеличить до 8 ручными настройками.
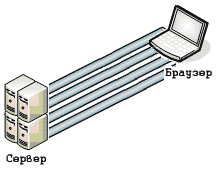
Каждое из этих соединений естественно тратит время на DNS-запросы и установку соединения, но в целом параллельные соединения дали ощутимый прирост скорости.
Изначально, HTTP устанавливал соединение, отправлял один запрос и ждал на него ответ. После расширения каналов связи, стало ясно, что такой подход ведет к существенным временным задержкам. Чтобы это устранить, была разработана технология HTTP конвейера (HTTP pipelining) — когда браузер может послать несколько GET-запросов в одном соединении, не дожидаясь ответа от сервера. Сервер в таком случае должен ответить на все запросы последовательно.
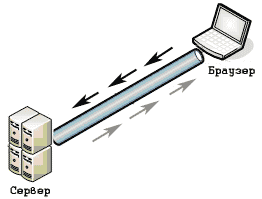
Технология конвейера показала существенный прирост скорости загрузки веб страниц, особенно это актуально для широких каналов.
Конвейерная обработка может также резко сократить количество TCP/IP-пакетов. С типичным MSS (максимальный размер сегмента) в диапазоне от 536 до 1460 байт, можно упаковать несколько HTTP-запросов в один TCP/IP-пакет. Сокращение числа пакетов, необходимых для загрузки страницы — это преимущество интернета в целом, так как снижается нагрузка на маршрутизаторы и каналы.
|
|
