ПВМ (параллельная виртуальная машина) - это побочный продукт продвижения гетерогенных сетевых исследовательских проектов, распространяемый авторами и институтами, в которых они работают. Общими целями этого проекта являются исследование проблематики и разработка решений в области гетерогенных параллельных вычислений. ПВМ представляет собой набор программных средств и библиотек, которые эмулируют общецелевые, гибкие, гетерогенные вычислительные структуры для параллелизма во взаимосвязанных компьютерах с различными архитектурами. Главной же целью системы ПВМ является обеспечение возможности использования группы компьютеров совместно для взаимосвязанных или параллельных вычислений. Детальное описание и обсуждение концепции, логики, методологии, связанные с этим базирующимся на использовании сетей вычислительным процессом описаны в соответствующих разделах лекции. Вкратце, постулаты, взятые за основу для ПВМ, следующие:
Система ПВМ состоит из двух частей.
Первая часть - это демон под названием pvmd3 - часто сокращается как pvmd, который помещается на все компьютеры, создающие виртуальную машину. (Примером программы-демона может быть почтовая программа, которая выполняется в фоновом режиме и обрабатывает всю входящую и исходящую электронную почту компьютера.) pvmd3 разработан таким образом, чтобы любой пользователь с достоверным логином мог инсталлировать этот демон на машину. Когда пользователь желает запустить приложение ПВМ, он прежде всего создает виртуальную машину, запуская ПВМ. После этого приложение ПВМ может быть запущено с любого UNIX-терминала на любом из хостов. Несколько пользователей могут конфигурировать перекрывающиеся виртуальные машины, каждый пользователь может последовательно запустить несколько приложений ПВМ.
Вторая часть системы - это библиотека подпрограмм интерфейса ПВМ. Она содержит функционально полный набор примитивов, которые необходимы для взаимодействия между задачами приложения. Эта библиотека содержит вызываемые пользователем подпрограммы для обмена сообщениями, порождения процессов, координирования задач и модификации виртуальной машины.
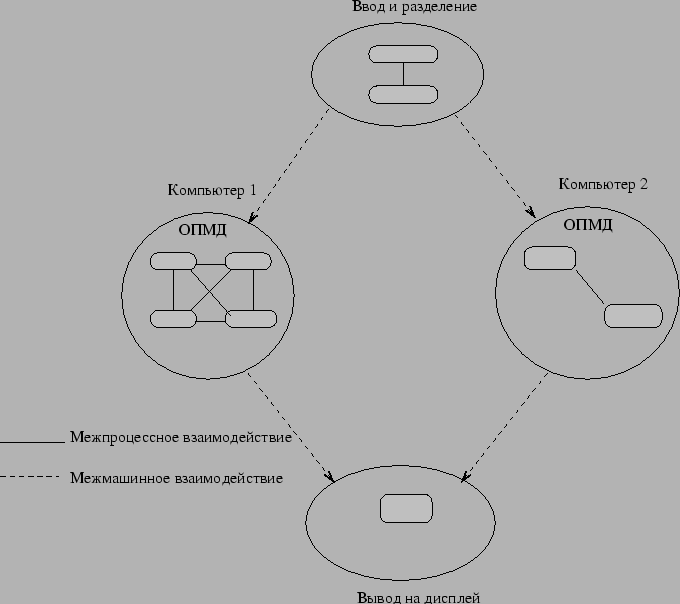
Вычислительная модель ПВМ базируется на предположении о том, что приложение состоит из нескольких задач. Каждая задача ответственна за часть вычислительной нагрузки приложения. Иногда приложение распараллеливается по функциональному принципу, то есть каждая задача выполняет свою функцию, например: ввод, порождение, счет, вывод, отображение. Такой процесс часто определяют как функциональный параллелизм. Более часто встречается метод параллелизма приложений, называемый параллелизмом обработки данных. В этом случае все задачи одинаковы, но каждая из них имеет доступ и оперирует только над небольшой частью общих данных. Схожая ситуация в вычислительной модели ОКМД (одна команда, множество данных). ПВМ поддерживает любой из перечисленных методов отдельно или в комплексе. В зависимости от своих функций задачи могут выполняться параллельно и нуждаться в синхронизации или обмене данными, хотя это происходит не во всех случаях. Диаграмма вычислительной модели ПВМ показана на рис. 81, а архитектурный вид системы ПВМ, с выделением гетерогенности вычислительных платформ, поддерживаемых ПВМ, показан на рис. 82.
В текущий момент времени ПВМ поддерживает языки программирования C, C++ и Fortran. Этот набор языковых интерфейсов взят за основу в связи с наблюдением о том, что преобладающее большинство целевых приложений написаны на C и Fortran, но наблюдается тенденция экспериментирования с объектно-ориентированными языками и методологиями.
Привязка языков C и C++ к пользовательскому интерфейсу ПВМ реализована в виде функций, следующих общепринятым подходам, используемым большинством C-систем, включая UNIX-образные операционные системы. Уточним, что аргументы функции - это, как обычно, комбинация числовых параметров и указателей , а выходные значения отражают отражают результат работы вызова. В дополнение к этому, используются макроопределения для системных констант и глобальные переменные, такие как errno и pvm_errno - служат для точного определения результата в числе возможных. Прикладные программы, написанные на C и C++, получают доступ к функциям библиотеки ПВМ путем прилинковки к ним архивной библиотеки (libpvm3.a) - это часть стандартного дистрибутива.
Привязка к языку Fortran реализована скорее в виде подпрограмм, чем в виде функций. Такой подход применен по той причине, что некоторые компиляторы для поддерживаемых архитектур не смогли бы достоверно реализовать интерфейс между C- и Fortran-функциями. Непосредственным следствием из этого является то, что для каждого вызова библиотеки ПВМ вводится дополнительный аргумент - для возвращения результирующего статуса в вызвавшую его программу. Также унифицированы библиотечные подпрограммы для размещения введенных данных в буферы сообщения и их восстановления, они имеют дополнительный параметр для отображения типа данных. Кроме этих различий (и разницы в стандартных префиксах при именовании: pvm_ - для C и pvmf_ - для FOTRAN), возможно взаимодействие "друг с другом" между двумя языковыми привязками. Интерфейсы ПВМ на Fortran реализованы в виде библиотечных надстроек, которые в свою очередь, после разбора и/или определения состава аргументов вызывают нужные C-подпрограммы. Так, Fortran-приложения требуют прилинковки библиотеки-надстройки (libfpvm3.a) в дополнение к C-библиотеке.
Рис. 81. Вычислительная модель ПВМ
Все задачи ПВМ идентифицируются посредством целочисленного "идентификатора задачи" (task identifier - TID). Сообщения передаются и принимаются с помощью идентификаторов задач. Поэтому эти идентификаторы должны быть уникальными в пределах внутренней виртуальной машины - что поддерживается локальным pvmd и прозрачно для пользователя. Хотя ПВМ кодирует информацию в каждом TID, пользователь склонен трактовать идентификаторы задач как скрытые целочисленные идентификаторы. ПВМ содержит несколько подпрограмм, которые возвращают значения в TID, тем самым, давая возможность пользовательскому приложению идентифицировать другие задачи в системе.
Существуют приложения, при рассмотрении которых естественно подумать о "группе задач". А также случаи, когда пользователю было бы удобно определять свои задачи по номерам: 0 - (p-1), где p - количество задач. ПВМ поддерживает концепцию именуемых пользователем групп. При этом задача состоит в группе и ей поставлен в соответствие "случайный" номер в этой группе. Случайные номера стартуют с 0 и возрастают. В соответствие философии ПВМ, групповые функции разрабатываются таким образом, чтобы они были очень обобщенными и понятными для пользователя. Например, любая задача ПВМ может войти в состав любой группы или покинуть ее в произвольный момент времени без необходимости информировать об этом каждую задачу в данной группе. Кроме того, группы могут перекрываться, а задачи могут рассылать широковещательные сообщения, адресованные тем группам, в которых они не состоят. Для использования любой из групповых функций к программе должна быть прилинкована libgpvm3.a.
Общая парадигма для программирования приложений с помощью ПВМ описана ниже. Пользователь пишет одну либо более последовательных программ на C, C++ или Fortran 77, в которые встроены вызовы библиотеки ПВМ. Каждая программа порождает задачу, и реализующую приложение. Эти программы компилируются по правилам каждой архитектуры в пуле хостов, и в результате получаются объектные файлы, помещаемые по местам, доступным на машинах в пуле хостов. Для выполнения приложения пользователь обычно запускает одну копию задачи (обычно это "ведущая" или "инициирующая" задача) вручную на машине из пула хостов. Этот процесс последовательно порождает другие задачи ПВМ; в конечном счете получается группа активных задач, оперирующих локально и обменивающихся сообщениями друг с другом для решения проблемы. Обратите внимание на то, что выше приведен типичный сценарий, но вручную можно запускать столько задач, сколько нужно. Как уже упоминалось выше, задачи взаимодействуют путем прямого обмена сообщениями с идентификацией определенными системой, скрытыми TID.
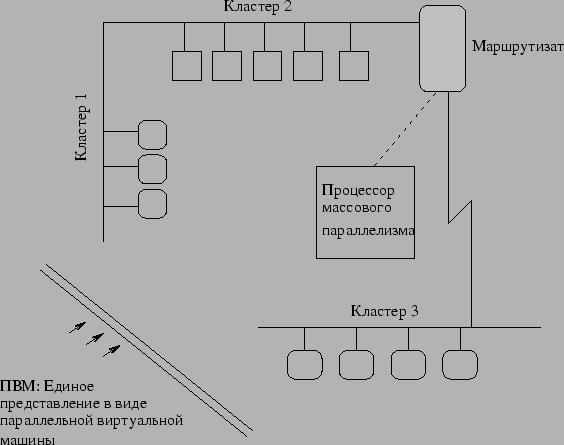
Рис. 82. Обзор архитектуры ПВМ
Ниже приведена программа ПВМ hello - простой пример, который иллюстрирует базовую концепцию программирования ПВМ. Эта программа рассматривается как запускаемая вручную; после вывода на экран своего идентификатора задачи (полученного с помощью pvm_mytid()) она порождает копию другой программы под названием hello_other, используя функцию pvm_spawn(). Успешное порождение заставляет программу выполнить блокирующий прием с помощью pvm_recv(). После приема сообщения программа выводит на экран сообщение, посланное ей ее абонентом - также как и свой идентификатор задачи; содержимое буфера извлекается из сообщения применением pvm_upsksrt(). Заключительный вызов pvm_exit "выводит" программу из системы ПВМ.
main()
{
int cc, tid, msgtag;
char buf[100];
printf("Это программа t%x\n", pvm_mytid());
cc = pvm_spawn("hello_other", (char**)0, 0, "", 1,&tid);
if (cc == 1) {
msgtag = 1;
pvm_recv(tid, msgtag);
pvm_upkstr(buf);
printf("Вывод из t%x: %s\n", tid, buf);
} else
printf("Невозможно запустить hello_other\n");
pvm_exit();
}
main()
{
int ptid, msgtag;
char buf[100];
ptid = pvm_parent();
strcopy(buf, "hello, world from");
msgtag = 1;
gethostname(buf + strlen(buf), 64);
msgtag = 1;
pvm_initsend(PvmDataDefault);
pvm_pkstr(buf);
pvm_send(ptid, msgtag);
pvm_exit();
}
|
|
