Предположим, имеется таблица следующего вида:
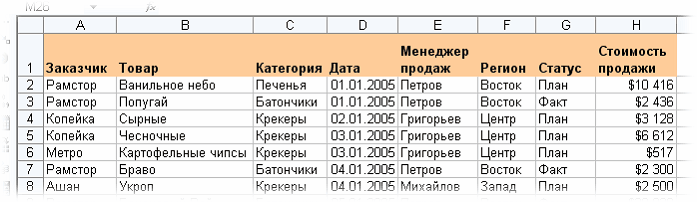
В ней необходимо найти повторяющиеся строки, причем при поиске дубликатов учитывать только столбцы Заказчик, Товар, Менеджер продаж и Статус. Способ с применением Расширенного фильтра, описанный здесь, в данном случае не подходит, поскольку работает только для поиска совпадений в одном столбце, а у нас их здесь четыре.
Пойдем не небольшую хитрость. Создадим дополнительный столбец, куда перенесем и соединим значения из четырех требуемых столбцов, чтобы получить своего рода уникальный идентификатор каждой строки. Сделать это можно при помощи оператора склейки (&) вот так:

Получившийся столбец жутковато выглядит, но нам он нужен не для красоты (впоследствии его можно скрыть). Теперь наша задача сводится к поиску дубликатов в этом столбце. Сделать это можно несколькими способами. Самый простой - использовать функцию СЧЁТЕСЛИ (COUNTIF) для подсчета того, сколько раз текущее значение идентификатора встречалось в столбце I:

Теперь нужные строки можно отобрать Автофильтром по столбцу J или подсветить условным форматированием. Например так:

Знаете ли Вы, как разрешается парадокс Ольберса?
(Фотометрический парадокс, парадокс Ольберса - это один из парадоксов космологии, заключающийся в том, что во Вселенной, равномерно заполненной звёздами, яркость неба (в том числе ночного) должна быть примерно равна яркости солнечного диска. Это должно иметь место потому, что по любому направлению неба луч зрения рано или поздно упрется в поверхность звезды.
Иными словами парадос Ольберса заключается в том, что если Вселенная бесконечна, то черного неба мы не увидим, так как излучение дальних звезд будет суммироваться с излучением ближних, и небо должно иметь среднюю температуру фотосфер звезд. При поглощении света межзвездным веществом, оно будет разогреваться до температуры звездных фотосфер и излучать также ярко, как звезды. Однако в дело вступает явление "усталости света", открытое Эдвином Хабблом, который показал, что чем дальше от нас расположена галактика, тем больше становится красным свет ее излучения, то есть фотоны как бы "устают", отдают свою энергию межзвездной среде. На очень больших расстояниях галактики видны только в радиодиапазоне, так как их свет вовсе потерял энергию идя через бескрайние просторы Вселенной. Подробнее читайте в
FAQ по эфирной физике.
НОВОСТИ ФОРУМА

Рыцари теории эфира | | 10.11.2021 - 12:37: ПЕРСОНАЛИИ - Personalias -> WHO IS WHO - КТО ЕСТЬ КТО - Карим_Хайдаров.
10.11.2021 - 12:36: СОВЕСТЬ - Conscience -> РАСЧЕЛОВЕЧИВАНИЕ ЧЕЛОВЕКА. КОМУ ЭТО НАДО? - Карим_Хайдаров.
10.11.2021 - 12:36: ВОСПИТАНИЕ, ПРОСВЕЩЕНИЕ, ОБРАЗОВАНИЕ - Upbringing, Inlightening, Education -> Просвещение от д.м.н. Александра Алексеевича Редько - Карим_Хайдаров.
10.11.2021 - 12:35: ЭКОЛОГИЯ - Ecology -> Биологическая безопасность населения - Карим_Хайдаров.
10.11.2021 - 12:34: ВОЙНА, ПОЛИТИКА И НАУКА - War, Politics and Science -> Проблема государственного терроризма - Карим_Хайдаров.
10.11.2021 - 12:34: ВОЙНА, ПОЛИТИКА И НАУКА - War, Politics and Science -> ПРАВОСУДИЯ.НЕТ - Карим_Хайдаров.
10.11.2021 - 12:34: ВОСПИТАНИЕ, ПРОСВЕЩЕНИЕ, ОБРАЗОВАНИЕ - Upbringing, Inlightening, Education -> Просвещение от Вадима Глогера, США - Карим_Хайдаров.
10.11.2021 - 09:18: НОВЫЕ ТЕХНОЛОГИИ - New Technologies -> Волновая генетика Петра Гаряева, 5G-контроль и управление - Карим_Хайдаров.
10.11.2021 - 09:18: ЭКОЛОГИЯ - Ecology -> ЭКОЛОГИЯ ДЛЯ ВСЕХ - Карим_Хайдаров.
10.11.2021 - 09:16: ЭКОЛОГИЯ - Ecology -> ПРОБЛЕМЫ МЕДИЦИНЫ - Карим_Хайдаров.
10.11.2021 - 09:15: ВОСПИТАНИЕ, ПРОСВЕЩЕНИЕ, ОБРАЗОВАНИЕ - Upbringing, Inlightening, Education -> Просвещение от Екатерины Коваленко - Карим_Хайдаров.
10.11.2021 - 09:13: ВОСПИТАНИЕ, ПРОСВЕЩЕНИЕ, ОБРАЗОВАНИЕ - Upbringing, Inlightening, Education -> Просвещение от Вильгельма Варкентина - Карим_Хайдаров.
|



