В этой главе мы рассмотрим несколько примеров анализа данных с помощью системы STATISTICA. Первый пример относится к области маркетинга (мы показываем возможности модуля Множественная регрессия), три следующие примера к промышленным приложениям (мы показываем возможности модулей Планирование эксперимента и Карты контроля качества), пятый пример иллюстрирует возможности STATISTICA по наложению результатов анализа на географические карты.
Еще раз отметим, что современная STATISTICA — это средство разработки приложений в конкретных областях (бизнесе, медицине, промышленности и др.). Библиотека STATISTICA содержит более 10 000 тщательно отлаженных и проверенных на практике процедур анализа данных. Развитие системы естественно приводит к созданию средств разработки собственного интерфейса и использования библиотеки STATISTICA для создания оригинальных модулей, включающих, наряду с процедурами STATISTICA, алгоритмы разработчика. Все эти процедуры объединяются общим интерфейсом, средствами управления данными и графикой STATISTICA.
Именно в создании средств для разработки приложений мы видим будущее систем анализа данных.
Пример 1
Пример основан на реальных данных, описывающих рынок пива в Греции (см. статью Kioulofas К. Е. «An Application of Multiple Regression Analysis to the Greek Beer Market» в журнале «Journal of Operational Research Society», Vol. 36, № 8, p. 689-696,1985).
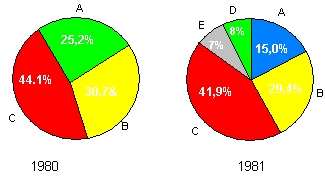
Известно, что этот рынок поделен между 5 фирмами, обозначенными далее А, В, С, D и Е. До 1981 года на рынке присутствовали фирмы А, В и С, в 1981 году на рынок пришли фирмы D и Е. Но уже в' 1983 году фирма D не выдержала конкуренции, а у фирмы А возникли финансовые проблемы.
|
Фирма/год |
1980 |
1981 |
1982 |
|
А |
27,6 |
21,3 |
21,3 |
|
В |
28,6 |
22,0 |
22,0 |
|
С |
43,8 |
33,8 |
33,8 |
|
D |
- |
14,7 |
14,7 |
|
Е |
- |
8,2 |
8,2 |
В следующей таблице представлены объемы продаж в отрасли и доля каждой фирмы.
|
Фирма/ Год |
1980 Знач. % |
1981 Знач. % |
1982 Знач. % |
|
В целом |
7646,287 100,0 |
10458,140 100,0 |
13 475,974 100,0 |
|
А |
1 926,300 25,2 |
1 571,417 15,0 |
1 595,742 11,8 |
|
В |
2 347,987 30,7 |
3 073,511 29,4 |
3 660,954 27,3 |
|
С |
3 372,000 44,1 |
4 381,000 41,9 |
5 677,000 42,1 |
|
D |
- |
596,755 5,7 |
1 042,278 7,7 |
|
Е |
- |
835,457 8,0 |
1 500,000 11,1 |
Можно заметить, что после появления фирм D и Е произошло резкое снижение доли фирмы А. Две новые фирмы D и Е по-разному освоили рынок. Фирма D имела большие производительные способности, чем фирма Е, но заметно отстала по объемам продаж. Этот пример интересен тем, что показывает соотношение затрат на рекламу и производство.
Будем считать, что основным показателем эффективности рекламы является объем продаж фирмы. В этой таблице представлены расходы на рекламу каждой фирмы и ее доля в рекламе.
|
Фирма/ Год |
1980 Знач. % |
1981 Знач. % |
1982 Знач. % |
|
В целом |
44,596 100,0 |
136,273 100,0 |
187,997 100,0 |
|
А |
12,667 28,4 |
6,747 5,0 |
22,298 11,9 |
|
В |
13,897 31,2 |
38,174 28,0 |
43,079 22,9 |
|
С |
18,050 40,4 |
39,581 29,0 |
65,114 34,6 |
|
D |
- |
21,340 15,7 |
20,687 11,0 |
|
Е |
- |
30,421 22,3 |
36,519 19,6 |
Понятно, что вхождение в отрасль фирм D и Е потребовало больше расходов на рекламу (в процентном отношении к объему продаж). Это отчетливо видно из следующей таблицы:
|
Фирма/год |
1980 |
1981 |
1982 |
|
А |
0,7 |
0,4 |
1,4 |
|
В |
0,6 |
1,2 |
1,2 |
|
С |
б |
0,9 |
1,1 |
|
D |
- |
3,6 |
2,0 |
|
Е |
- |
3,6 |
2,5 |
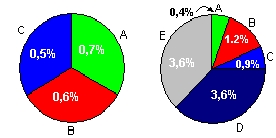
Заметим, фирма D в 1982 году резко снизила расходы на рекламу, что, возможно, стало причиной потери рынка.
Предполагается, что для рекламы используются следующие средства массовой информации: телевидение, газеты, журналы и радио.
Эффективность рекламы в каждом случае различна, и возникает вопрос о количественных зависимостях между объемом продаж и расходами на рекламу в каждом из средств массовой информации. Обычно доля телевидения составляет 70-90%, и поэтому в таблице, представляющей распределение расходов на рекламу между средствами массовой информации, все СМИ, кроме телевидения, объединены в одну группу «другие».
На реальный объем продаж пива влияют также такие факторы, как температура воздуха, число туристов и индекс потребительских цен (инфляция).
В предлагаемой модели теоретическая зависимость основывается на предположении, что объем продаж за период t (далее это месяцы) является функцией объема продаж за прошлый период расходов на рекламу в периоды t и t-1, количества туристов, значений температуры и индекса розничных цен.
s1 = b0 + b1St-1 + b2 Аt + bАt-1 + b4Tt + b5Wt + b6Pt
где
St — объем продаж (в драхмах);
At — ассигнования на рекламу;
Tt — число туристов в месяц t;
Wt — средняя температура воздуха;
Pt — индекс розничных цен.
Итак, мы построили модель зависимости, но коэффициенты этой модели неизвестны. Эти коэффициенты оцениваются из исходных данных в модуле Множественная регрессия.
Оценка коэффициентов по методу наименьших квадратов выявила статистическую незначимость переменных Wt и Pt, и они были исключены из дальнейшего анализа.
В результате получилось уравнение, содержащее меньшее число переменных:
St=b0+b1St-1+b2At+bAt-1+b4Tt(*)
Оценим коэффициенты этого уравнения, используя реальные данные. Для анализа использовались данные о месячных продажах за 2 года. Число наблюдений равнялось 24. Результаты регрессии приведены в таблице:
|
Фирмы |
St-1 |
Аt |
Аt-1 |
Tt |
R2 |
Н |
С. о. Р. |
|
Отрасль |
0,56 |
11,81 |
0,52 |
0,801 |
1,56 |
132,11 |
|
|
А |
0,29 |
7,93 |
0,22 |
0,881 |
1,95 |
35,82 |
|
|
В |
0,49 |
3,85 |
11,75 |
0,25 |
0,893 |
1,14 |
43,28 |
|
С |
0,45 |
12,41 |
0,19 |
0,703 |
-0,21 |
55,09 |
|
|
D |
0,59 |
0,1 |
0,73 |
0,317 |
0,21 |
37,75 |
|
|
E |
0,60 |
2,6 |
13,9 |
0,600 |
-0,68 |
41,76 |
Значения коэффициента детерминации R2, близкие к единице, говорят о хорошем приближении линии регрессии к наблюдаемым данным и о возможности построения качественного прогноза.
Низкое значение коэффициента детерминации R2 для фирмы D объясняется низкой эффективностью рекламной кампании и трудностями на административном уровне. Можно сделать вывод, что модель плохо применима к фирме D.
Статистики Дарбина—Уотсона свидетельствуют об отсутствии автокорреляции остатков при 5%-м уровне значимости, т. к. все ее значения по модулю меньше 1,96.
Все значения регрессионных коэффициентов значимы при уровне значимости 0,5, за исключением коэффициентов при At для фирм В, D и Е.
Одним из возможных объяснений этого факта является то, что показатели этих фирм зависят от рекламной деятельности за прошлый период времени, то есть от Аt-1
Это подтверждается тем, что для этих фирм коэффициенты при At-1 значимы на уровне 95%. Более того, можно заметить, что показатели всех фирм, кроме фирмы Е, имеют положительную корреляцию с числом туристов. Незначительную корреляцию между туризмом и объемами продаж фирмы Е можно объяснить недавним появлением этой фирмы. Объемы продаж всех фирм также находятся под влиянием объемов продаж в прошлом периоде, St-1 возможно, благодаря эффекту «привычки» потребителей к торговым маркам. Значимость этого параметра с распределенным лагом также наводит на мысль о некоторых обучающих эффектах.
Продажи фирмы А имеют значительную положительную корреляцию с ее расходами на рекламу за период t, что отличает ее от других фирм. Окончательно взаимосвязь между рыночными продажами и совокупными расходами на рекламу положительна и значима при уровне 5%.
Представленные выше результаты регрессии образуют основу оценки эффективности совокупных расходов на рекламу.
Покажем, как строятся такие модели в системе STATISTICA. Для этих целей обычно используется модуль Множественная регрессия.
В этом модуле собраны методы, позволяющие оценить зависимость одной переменной от нескольких других переменных.
Переменная, для которой строится зависимость, называется зависимой (по-английски dependent variable). Эта переменная входит в левую часть уравнения, описывающего зависимость (см. уравнение (*)). Переменные, от которых мы хотим построить зависимость, называются независимыми переменными (по-английски independent variables) или предикторами (от английского predict — предсказывать). Эта переменная входит в правую часть уравнения, описывающего зависимость. Сам термин множественная регрессия (по-английски multiple regression) означает, что модель может содержать несколько предикторов, позволяющих предсказывать зависимую переменную.
Итак, общая идея состоит в том, чтобы по значениям предикторов предсказывать значения зависимой переменной, например, по значениям продаж и расходам на рекламу в текущем и предыдущем месяце предсказывать продажи в следующем месяце.
Конечно, количество предикторов можно увеличить, например, ввести объем продаж у конкурентов или какие-то другие, имеющие смысл и доступные наблюдению переменные. Однако здесь имеется тонкость, предикторы могут оказаться зависимыми между собой.
Переменные, которые следует включить в модель, определяет специалист в предметной области. Затем нужно выполнить следующие действия.
Шаг 1. Запустите модуль Множественная регрессия.
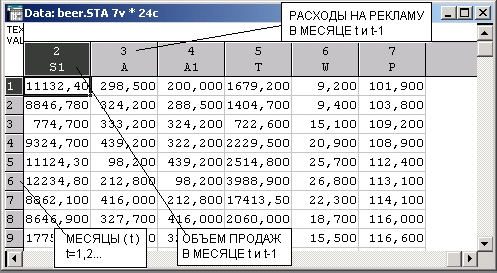
Шаг 2. Введите исходные данные в файл системы STATISTICA. Назовите его, например, Beer.sta.
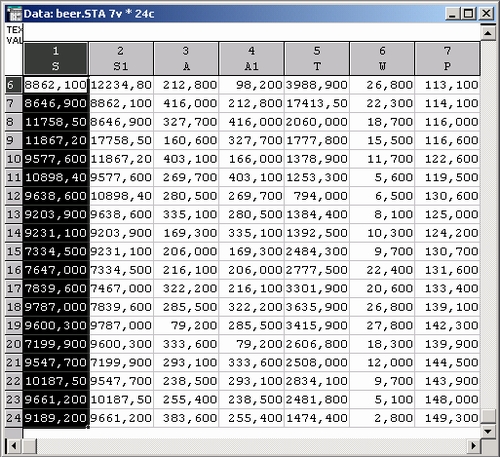
Шаг 3. Определите переменные в модели. Задайте S в качестве зависимой переменной и S1...P — в качестве независимых переменных, или предикторов. После этого стартовая панель модуля будет выглядеть так:
Шаг 4. Нажмите кнопку ОК. Появится диалоговое окно результатов, в котором отображаются итоги стандартной процедуры.
Измените процедуру на Пошаговую с включением. Для этого нажмите на кнопку Отмена и в появившемся диалоговом окне Определение модели выберите в поле Процедура опцию Пошаговая с включением. В этой процедуре система начинает построение модели с одного предиктора, затем, используя F-критерий, в модель включается еще один предиктор и т. д. На каждом шаге вычисляется коэффициент множественной корреляции. Квадрат коэффициента множественной корреляции, коэффициент детерминации, свидетельствует о качестве построенной модели. Нажмите кнопку ОК.
В появившемся окне Пошаговая множественная регрессия снова нажмите ОК.
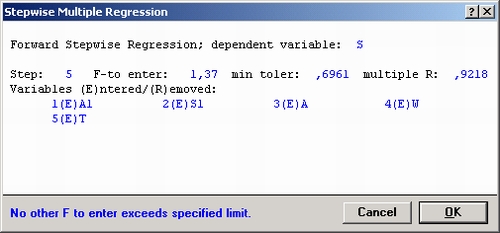
Теперь перед вами диалоговое окно результатов, полученных с помощью пошаговой процедуры с включением. Следует отметить, что в нем указаны стандартизованные коэффициенты регрессии.
Заметим, если вы предполагаете, что в модели должно присутствовать небольшое число предикторов, то естественно использовать пошаговый метод с включением предикторов. Если вы предполагаете, что в модели должно присутствовать большое число предикторов, то естественно использовать метод с исключением.

Шаг 5. Нажмите кнопку Итоговая таблица регрессии. Появится таблица результатов с подробными статистиками.
В столбце БЕТА показаны стандартизованные коэффициенты регрессии, а в столбце В — нестандартизованные коэффициенты. Все коэффициенты в таблице значимы, так как р-значения для каждого из них меньше заданной величины 0»05.
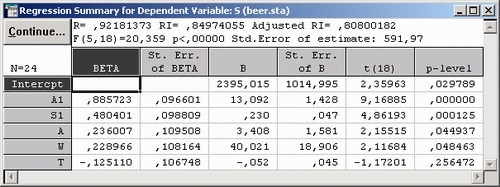
Шаг 6. В окне результатов нажмите кнопку Анализ остатков.
Шаг 7. В диалоговом окне Анализ остатков нажмите кнопку Статистика Дарбина—Уотсона. Эта статистика позволяет исследовать зависимость между остатками. Формально остатки представляют собой разность: наблюдаемые значения зависимой переменной минус оцененные с помощью модели значения зависимой переменной.
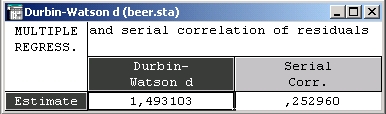
Зачем проверять зависимость остатков? Идея проста: если остатки существенно коррелированны (зависимы), то модель неадекватна (нарушено важное предположение о независимости ошибок в регрессионной модели).
Рассмотрим более подробно статистику Дарбина—Уотсона. Мы уделяем этой статистике так много внимания, потому что статистика Дарбина—Уотсона является стандартом для проверки некоторых видов зависимости остатков и с ней нужно научиться работать.
Статистика Дарбина—Уотсона используется для проверки гипотезы о том, что остатки построенной регрессионной модели некоррелированы (корреляции равны нулю), против альтернативы: остатки связаны авторегрессионной зависимостью вида:
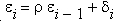
где di независимые случайные величины, имеющие нормальное распределение с параметрами (0, s), i = 1 ... n».
Формально статистика Дарбина—Уотсона вычисляется следующим образом:
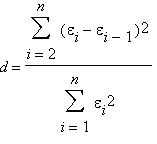
Иными словами, сумма квадратов первых разностей остатков нормируется суммой квадратов остатков. Проведя вычисления, вы легко выразите статистику Дарбина—Уотсона через коэффициент корреляции: d = 2(1 — р).
Критические точки статистики Дарбина—Уотсона табулированы (см. например, Драйпер Н., Смит Г. Прикладной регрессионный анализ. М.: Финансы и статистика, т. 1. с. 211, см. также таблицу, показанную ниже).
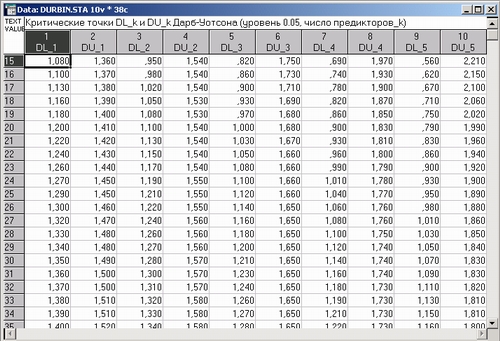
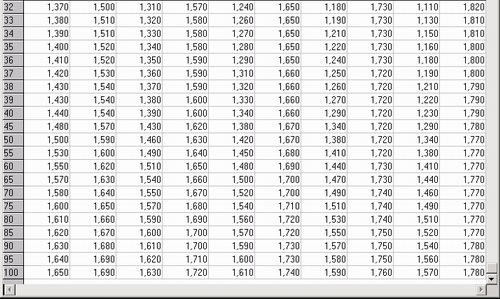

В таблице приведены два критических значения статистики Дарбина—Уотсо-на: DL_k и DU_k — нижнее и верхнее, зависящие как от числа наблюдений, по которым оцениваются параметры, так и от числа предикторов k, которые включены в модель.
На графике видно, как меняются значения DL_k и DU_k в зависимости от числа наблюдений (k = 1, 2, 3, 4, 5).
Число наблюдений, для которого рассчитаны критические значения, указано в заголовках строк приведенной таблицы.
Итак, вы находите строку с нужным числом наблюдений и два смежных столбца с нужным числом предикторов. На пересечении строки и столбцов располагаются нижние и верхние критические точки статистики Дарбина—Уотсона.
Если нужно проверить гипотезу: «остатки независимы, то есть р =0», против общей альтернативы р не равно 0, поступают следующим образом. Вычисляют значение статистики Дарбина—Уотсона d. Для данного числа наблюдений и числа предикторов находят критические точки DL_k и DU_k в таблице, составленной для определенного уровня а. В приведенной таблице уровень a=0,05
Если d < DL_k или 4 — d < DL_k, то гипотеза о независимости остатков отвергается на уровне 2ос. Если d > DU_k и 4 — d > DU_k, то гипотеза о независимости остатков не отвергается на уровне 2a.
Если нужно проверить гипотезу: «остатки независимы р = 0», против альтернативы р > 0, то есть остатки положительно автокоррелированы, поступают следующим образом. Вычисляют значение статистики Дарбина—Уотсона d. Находят по таблице критические точки DL_k и DU_k, вычисленные для определенного уровня a. Заметьте, в приведенной таблице a=0,05.
Если d < DL_k то гипотеза о независимости остатков отвергается на уровне а в пользу альтернативы.
Если d > DU_k, то гипотеза о независимости не отвергается на уровне a.
Случай DL_k < d < DU_k является сомнительным.
Если нужно проверить гипотезу: «остатки независимы р = 0», против альтернативы: р < 0, то есть остатки отрицательно автокоррелированы, то вместо d следует рассмотреть значение 4 — d и повторить рассуждения предыдущего абзаца, которые использовались для проверки гипотезы «остатки независимы р = 0», против альтернативы р > 0.
После того как мы познакомились со статистикой Дарбина—Уотсона, продолжим работу в модуле Множественная регрессия.
Шаг 8. Нажмите кнопку Предсказанные и наблюдаемые.
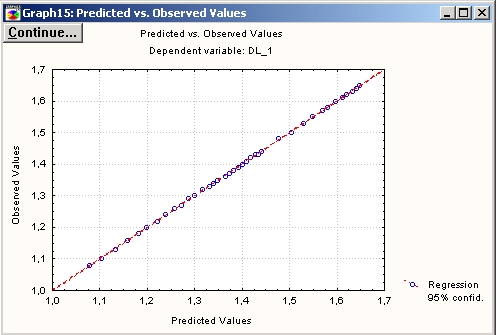
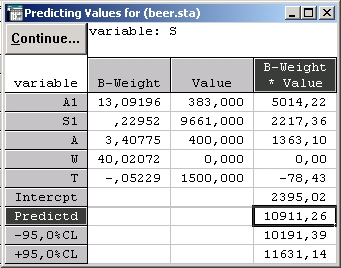
Шаг 9. Вернитесь в окно Результаты множественной регрессии и нажмите кнопку Предсказать зависимую переменную. Далее в полях А1 и S1 укажите значения текущего месяца, а в полях Т и А — значения на следующий месяц.
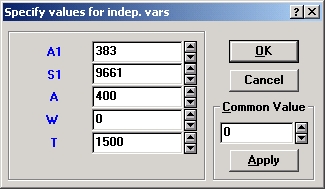
Нажмите кнопку ОК. Появится таблица результатов предсказания. На рисунке выделена ячейка, содержащая прогнозируемый объем продаж на следующий месяц.
Пример 2
Этот пример относится к промышленной статистике (см. Cornell J. А. (1990). How to Apply Response Surface Methodology, vol. 8 in Basic References in Quality Control: Statistical Techniques, edited by S. S. Shapiro and E. Mykytka. Milwaukee: American Society for Quality Control).
Любая машина или станок, используемые на производстве, позволяют операторам производить настройки, чтобы воздействовать на качество производимого продукта. Изменяя настройки, инженер стремится добиться максимального эффекта, а также выяснить, какие факторы играют наиболее важную роль в улучшении качества продукции.
В системе STATISTICA имеется мощный модуль планирования экспериментов, позволяющий эффективно планировать и анализировать эксперименты.
Задача состояла в том, чтобы исследовать факторы, влияющие на качество производимых пластиковых дисков.
Известно, что наибольшее влияние на качество оказывают следующие два фактора:
1) материал, характеризующийся отношением наполнителя к эпоксидной резине,
2) расположение диска в форме.
В качестве зависимой переменной рассматривалась плотность полученного диска.
Сначала использовался дробный факторный план 22 для того, чтобы определить адекватность модели первого порядка. В этой модели оба фактора комбинировались друг с другом на верхних и нижних значениях (всего имеется 4 комбинации). Но оказалось, что модель оказалась адекватной лишь для некоторой области значений факторов и неадекватной для всей значений факторов. На самом деле зависимость между факторами и откликом была нелинейной. Поэтому было решено использовать центральный композиционный план и применить модель второго порядка.
Центральный композиционный план может состоять из куба и звезды. Куб соответствует полному факторному плану — точки эксперимента располагаются в вершинах куба (фактически это факторный план 22).
Звезда содержит дополнительное множество точек, расположенных на одинаковых расстояниях от центра куба на отрезках, исходящих из центра и проходящих через каждую сторону куба.
В данном исследовании применялся ротатабельный план, в котором дисперсия отклика является постоянной во всех точках, одинаково удаленных от центра плана.
Пусть фактор А — это характеристика материала, из которого изготовлен диск, более точно, так называемое композиционное отношение (disk composition ratio), фактор В — положение диска в форме (position of disk in mold). Зависимая переменная, или отклик эксперимента, — плотность диска (Thickness).
Запустите модуль Планирование эксперимента.
На стартовой панели выберите Центральные композиционные планы, поверхности отклика и нажмите кнопку ОК.
В появившемся диалоговом окне выберите опцию Построение плана, а в поле Факторы/блоки/опыты — строку 2/1/10. Нажмите кнопку ОК.
Появится диалоговое окно План эксперимента для поверхности отклика. Нажмите на кнопку Имена факторов, значения и заполните таблицу в диалоговом окне Итоги для переменных .
Нажмите кнопку Далее и выберите опции для настройки .отображения плана так, как показано на следующем рисунке. Сделайте точно все показанные настройки, чтобы получить нужный результат!
Просмотрите план. Для этого нажмите Просмотр/Правка/Сохранение.
Задание имени и сохранение экспериментального плана
Выберите Сохранить как файл данных...; появится соответствующее диалоговое окно. Задайте имя плана disk.sta и нажмите кнопку ОК.
Вернитесь в диалоговое окно План эксперимента для поверхности отклика.
Нажмите кнопку Печать итогов. В зависимости от настроек вывода в диалоговом окне Параметры страницы/вывода результаты плана будут распечатаны на принтере или выведены в отчет.
В построенной таблице показан порядок сбора экспериментальных данных.
Данные, полученные в результате эксперимента, занесены в таблицу.
|
Номер |
Block |
Ratio |
Mold |
Thickness |
|
1 |
1 |
0,75 |
0,5 |
7,3 |
|
2 |
1 |
0,9 |
0,5 |
7 |
|
3 |
1 |
0,75 |
1 |
7,1 |
|
4 |
1 |
0,9 |
1 |
8 |
|
5 |
1 |
0,718934 |
0,75 |
7,6 |
|
6 |
1 |
0,931066 |
0,75 |
7,4 |
|
7 |
1 |
0,825 |
0,396447 |
7,4 |
|
8 |
1 |
0,825 |
1,103553 |
7,9 |
|
9 |
1 |
0,825 |
0,75 |
8,2 |
|
10 |
1 |
0,825 |
0,75 |
8,3 |
Анализ экспериментальных данных
Проведем анализ полученных данных.
В диалоговом окне План эксперимента для поверхности отклика нажмите кнопку Отмена. Вы возвратитесь к диалогу Центральные композиционные планы.
Выберите опцию Анализ результатов. Нажмите кнопку Переменные. Задайте thick в качестве зависимой переменной, ratio и mold в качестве независимых переменных и block в качестве блоковой переменной.
В поле Для перекодирования использовать оставьте принятое по умолчанию положение уровни факторов из файла данных. Теперь нажмите ОК.
На экране появится следующее окно системы STATISTICA:
Прежде всего оцените адекватность модели второго порядка.
Для оценки адекватности воспользуйтесь таблицей дисперсионного анализа и графиками. На панели Включить в модель выберите опцию гл. лин./кв. эфф. и 2-взаимодействия, а на панели Член ошибки ДА — Остаточная сумма квадратов. Нажмите на кнопку Дисперсионный анализ.
Из этой таблицы следует, что статистически значимые эффекты (уровень р<0,05) имеют два квадратичных члена ratio (Q) и mold (Q).
Для того чтобы определить, насколько модель хорошо описывает экспериментальные данные, будем использовать тест lack-of-fit (потери согласия).
Вернитесь к диалоговому окну результатов анализа, выберите Чистую ошибку для Члена ошибки ДА и снова нажмите кнопку Дисперсионный анализ. Система добавит в таблицу значения потери согласия и чистой ошибки.
Вследствие того, что р-значение использованного дополнительного теста больше 0,05, модель второго порядка представляется адекватной для описания отклика.
Установите снова Член ошибки ДА в положение Остаточная сумма квадратов.
Теперь рассмотрим вероятностный график.
Для этого нажмите на кнопку
Видно, что квадратичные члены с меткой Q находятся в стороне от линии нормального распределения, что указывает на статистическую значимость их влияния на отклик.
Рассмотрим также карту Парето. Нажмите на кнопку Парето эффектов.
Итак, квадратичные члены модели дают значимые эффекты. Соответствующие им колонки пересекают вертикальную линию, которая представляет 95%-ю доверительную вероятность.
Определим теперь область значений факторов, в которой плотность пластиковых дисков является максимальной. Для этого лучше всего использовать график поверхности отклика. Нажмите на кнопку Поверхность.
Эта поверхность имеет экстремум, равный примерно 0,9. Для более детального рассмотрения области максимума целесообразно рассмотреть контурный график (цветная квадратная кнопка рядом с кнопкой Поверхность). На графике показаны линии уровня поверхности. Это весьма удобно для исследования поверхности.
Посмотрите на цветовые метки, расположенные слева от графика. Эти метки, показывающие интенсивность цветов, позволят легко сориентироваться и понять, что максимальная плотность достигается при изменении параметров в центральном эллипсе, положение главных осей которого легко оценить графически.
Например, максимально прочные диски будут получены при значениях композиционного соотношения, изменяющихся от 0,78 до 0,86, и значениях mold, изменяющихся от 0,6 до 0,9. Более строго — все значения независимых переменных, попадающие в центральный эллипс, приводят к наивысшему качеству пластиковых дисков.
Пример 3
В этом эксперименте изучается ракетное топливо, которое представляет собой комбинацию окислителя, горючего и связывающего вещества. Интересующим нас свойством топлива является его эластичность. Цель состоит в том, чтобы найти пропорции, для которых эластичность достигает величины 3 000. Задача такова — по результатам эксперимента найти математическую формулу, позволяющую связать эластичность с компонентами топлива.
Пример основан на данных, описанных в кн.: Kurotori I. S. (1966). Experiments with Mixtures of Components Having Lower Bounds, Industrial Quality Control, 22, p. 592-596.
Начнем с построения плана эксперимента.
Запустите модуль Планирование эксперимента.
В данном случае выберите Планы для смесей, потому что компоненты, выраженные в долях, в сумме должны равняться 1. Нажмите кнопку ОК.
В появившемся диалоговом окне выберите опцию Построение плана, далее укажите Симплекс-центроидный план, введите 3 в поле Число факторов и выделите опцию Дополнить внутренними точками.
Нажмите кнопку ОК. Появится диалоговое окно План эксперимента для смеси.
Нажмите на кнопку Имена факторов, значения и заполните появившуюся таблицу .
Нажмите кнопку Далее. Полученный план можно просмотреть, нажав на кнопку Просмотр/Правка/Сохранение, предварительно определив опции.
Сохраните план. Для этого выберите из меню Файл — Сохранить как файл данных, появится соответствующее диалоговое окно. Задайте имя плана rocket.sta и нажмите кнопку ОК.
План построен. Это позволяет организовать сбор данных.
Предположим, что вы организовали эксперимент согласно построенному плану и для разных значений компонент измерили эластичность ракетного топлива.
После того как данные собраны, задача состоит в том, чтобы провести анализ и найти зависимость между эластичностью и компонентами ракетного топлива.
Откройте файл данных rocket.sta и добавьте переменную elastic, содержащую данные для 10 откликов, полученных экспериментальным путем.
Введите данные. В диалоговом окне Планирование экспериментов для смесей выберите Анализ результатов.
Нажмите кнопку Переменные. Задайте elastic в качестве зависимой переменной, binder, oxidizer и fuel — в качестве независимых переменных.
В поле Перекодировать факторы оставьте принятое по умолчанию положение Автоматически определяемые мин./макс. значения. Теперь нажмите ОК. Появится диалоговое окно Анализ эксперимента для смеси.
На панели Модель выберите Специальная кубическая.
Нажмите на кнопку Дисперсионный анализ. Появятся две таблицы, В одной из. них приведена сводка проведенного анализа, а в другой — результаты дисперсионного анализа для специальной кубической модели.
Значимые модели выделены красным цветом.
Из таблицы видно, что статистически значимые эффекты наблюдаются в квадратической и специальной кубической моделей (р-значения меньше 0,05).
Качество регрессионной модели оценивается с помощью коэффициента детерминации R-квадрат.
Так как у специальной кубической модели среднеквадратичная ошибка меньше, а значения коэффициента детерминации R-квадратов больше, чем у квадратической модели, мы будем использовать специальную кубическую модель.
Нажмите кнопку Оценки псевдокомпонент. Программа отобразит статистики, рассчитанные для специальной кубической модели.
Как следует из полученных результатов, все члены специальной кубической модели имеют значимые эффекты (р < 0,05), кроме одного члена АВ.
Таблица дисперсионного анализа показывает весьма неплохие результаты для подобранной специальной кубической модели (р-значение гораздо меньше 0,05).
Чтобы проиллюстрировать данные результаты, рассмотрим графики. Нажмите на кнопку Поверхность.
На графике поверхности отклика хорошо виден максимум эластичности топлива. Заметьте, что зависимость эластичности от компонент смеси носит нелинейный характер.
Для точного определения оптимальных долей рассмотрим контурный график. Он вызывается кнопкой Контур.
На графике визуально легко определить, при каких значениях FUEL, BINDER, OXIDIZER достигается нужная эластичность.
Эластичность 3 000 лежит вблизи доли связующего вещества 0,25, доли окислителя 0,45 и доли горючего 0,25. Более точные значения пропорций компонентов следующие: связывающее вещество — 0,26667; окислитель — 0,46667 и горючее — 0,26667.
Можно выбрать некоторые пропорции компонентов, которые дают значения эластичности, близкие к 3 000. Например, набор компонент (0,25; 0,5; 0,25) дает эластичность 2 927,7, набор (0,25; 0,45; 0,3) — эластичность 3 042,9.
На значения компонент могут быть наложены дополнительные ограничения, например, можно максимизировать эластичность для значений окислителя или связывающего вещества, лежащих в определенных пределах.
Для нахождения таких решений опции STATISTICA оказываются незаменимыми.
Чтобы оценить эластичность по любому набору компонент, воспользуйтесь кнопкой Предсказать зависимую переменную. Задайте значения факторов.
Нажмите кнопку ОК.
На экране появится таблица прогнозируемых значений эластичности. В нижней части таблицы показывается значение Предсказ. - 2 396,872 предсказанной эластичности для исходных компонент. Также приводятся верхние и нижние границы 95%-го доверительного интервала и границы для прогноза. Измените значения компонент топлива, например, BINDER ~ 0,27, OXIDIZER - 0,43, FUEL - 0,3.
Для этих компонент будут получены значения эластичности.
Пример 4
Этот пример иллюстрирует возможности системы STATISTICA для промышленных приложений, связанных с контролем качества. Мы рассматриваем химическое производство, но вы легко можете представить и другую область применения, например, пищевую промышленность или металлургическую промышленность.
Пример основан на данных, взятых из книги Montgomery D. С., Hunger G. С. (1994). Applied Statistics and Probability for Engineers (N. Y.: Wiley & Sons).
Предположим, необходимо контролировать концентрацию некоторого вещества на выходе химического процесса. Вы наблюдаете процесс в реальном времени в течение 20 часов и снимаете с датчиков нужную характеристику каждый час. Считается, что процесс выходит из-под контроля, если концентрация превысит допустимый уровень и выходит за верхнюю контрольную границу.
Рассмотрим данные, представленные в таблице.
|
1 |
7 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
102 |
95 |
98 |
98 |
102 |
99 |
99 |
98 |
100 |
98 |
|
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
|
101 |
99 |
101 |
98 |
97 |
97 |
100 |
101 |
97 |
101 |
Особенностью процессов, протекающих в реальном времени, является то, что в них не является естественным группировать измерения, так как производя группировку вы с запаздыванием реагируете на ухудшение качества. Группируя данные, вы добиваетесь более точных оценок параметров процесса, однако плата за точность — запаздывание в управлении. Поэтому воспользуемся контрольными картами для индивидуальных наблюдений. Назовем контролируемый параметр concent.
Шаг 1. Введите исходные данные в файл системы STATISTICA, например, с именем Chemipro.
Шаг 2. Запустите модуль Интерактивный контроль качества.
Шаг 3. На стартовой панели выберите Отдельные наблюдения и скользящий размах и нажмите кнопку OK. В появившемся диалоговом окне выбирите concent в качестве переменной с измерениями.
Шаг 4. Постройте контрольную карту скользящих размахов для последовательности наблюдений.
Шаг 5. Известно, что для всех производственных процессов возникает необходимость установить пределы характеристик изделия, в рамках которых произведенная продукция удовлетворяет своему предназначению.
Вообще говоря, существует два «врага» качества продукции:
1) отклонения от значений плановых спецификаций изделия и
2) слишком высокая изменчивость реальных характеристик изделий относительно значений плановых спецификаций, что говорит о несбалансированности процесса.
Вы видите, что на Х-карте скользящих средних все точки попадают внутрь контрольных границ.
На контрольной карте скользящих размахов (MR-карте) все точки также находятся внутри контрольных границ. Размахи служат оценкой изменчивости характеристик, поэтому можно сказать, что концентрация вещества подчиняется требованиям статистического контроля по уровню средних и изменчивости.
Продолжение анализа. Следует иметь в виду, что карты для индивидуальных или отдельных наблюдений не способны отражать малые изменения среднего уровня концентрации, которые, однако, могут играть существенную роль в реальном производственном процессе.
Поэтому для анализа данных воспользуемся также контрольными картами накопленных сумм.
Шаг 6. Выявление малых изменений средних значений.
Запустите модуль Карты контроля качества.
Шаг 7. На стартовой панели выберите CUSUM карта для непрерывных переменных и нажмите кнопку ОК.
Заметьте, термин CUSUM происходит от сокращения кумулятивные, или накопленные, суммы.
Шаг 8. В появившемся диалоговом окне выберите concent в качестве переменной с измерениями.
Тип анализируемых данных: исходные данные.
Нажмите кнопку ОК. На экране появится CUSUM-карта.
На карте изображена также так называемая V-маска, имеющая следующий смысл.
Запомните: если в наблюдаемом процессе имеется значимое смещение среднего значения, то точки выходят за пределы V-маски.
В системе STATISTICA V-маска строится автоматически, и вам не нужно думать о ее определении. В нашем случае точки не выходят за пределы маски, поэтому можно сделать заключение о том, что исследованный химический процесс удовлетворяет требованиям контроля качества.
Из приведенного графика следует, что все точки данных попадают внутрь контрольного интервала.
Шаг 9. Опции STATISTICA позволяют всесторонне исследовать результаты и управлять процессом, находя незначительные сдвиги в значениях (см. опцию Обнаружить сдвиг больше чем...).
Например, нажмите на кнопку Описательные статистики на панели. Вы увидите таблицу с результатами.
Шаг 10. Можно продолжить анализ, например, просмотреть Гистограммы средних. Для этого нажмите кнопку Гистограммы средних. Далее задайте желаемые значения контрольных пределов и числа категорий и нажмите кнопку ОК.
Пример 5
На этом примере мы покажем, как наложить результаты анализа на географическую карту. Мы намеренно берем грубую реализацию карты и очень простые данные, чтобы показать принципиальную возможность метода.
Представьте, что имеется файл данных о заболеваниях определенного вида и травматизме для каждого региона России (данные носят чисто модельный характер, не отражают реальной ситуации и необходимы лишь для иллюстрации возможностей).
Координаты границ регионов задаются в отдельном файле данных. STATISTICA отображает карту России
Конечно, эту карту можно улучшать, делать более точными границы регионов, увеличивать и т. д. Мы намеренно берем самую грубую реализацию.
На карте цвета задаются случайным образом.
Наложим данные о заболеваемости на эту карту. Выберем опцию Шкалирование карты в диалоговом окне выбора слайда. Показанные далее диалоговые окна не являются частью какого-либо модуля STATISTICA, они легко создаются с помощью языка STATISTICA BASIC.
Далее выберем переменную, с помощью значений которой мы хотим провести раскраску карты, выберем, например, Заболевание. Идея проста: мы хотим добиться того, чтобы регионы с большей интенсивностью заболевания были окрашены более интенсивным цветом.
Следующее меню предлагает выбрать способ отображения карты. Линейное разбиение позволяет задать число интервалов или категорий (цветов), на которые будут разбиты все регионы.
Зададим, например, число интервалов, равное 4.
Последний шаг — выбор общего цвета (раскраска карты производится путем тональной градации выбранного цвета в зависимости от уровня заболевания):
В результате мы получили карту, раскрашенную в 4 цвета. Все регионы разбиты на группы по значению показателя Заболевание. Самый темный цвет соответствует группе (региону), в котором наблюдаются самые большие значения показателя Заболевание.
Изменим число градаций цвета, возьмем 10 и наложим на карту графики STATISTICA, тогда можно получить, например, следующую карту.
Теперь регионы разбиты на 10 групп по степени заболеваемости.
Конечно, такой анализ может быть гораздо изощреннее: на карте можно отобразить корреляции, зависимости между различными параметрами, например, между использованием мобильной связи и Интернета в различных регионах, можно рассмотреть карту отдельного региона и т. д.
|
|
