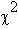 2/193 - 16,442.
2/193 - 16,442.
Данная глава продолжает тему главы Построение и анализ таблиц. Мы рекомендуем просмотреть ее, а затем приступить к чтению данного текста и упражнениям на STATISTICA.
Анализ соответствий (по-английски coirespondence analysis) — это разведочный метод анализа, позволяющий визуально и численно исследовать структуру таблиц сопряженности большой размерности.
В настоящее время анализ соответствий интенсивно применяется в разнообразных областях, в частности, в социологии, экономике, маркетинге, медицине, управлении городами (см. например, Thomas Werani, Correspondence Analysis as a Means for Developing City Marketing Strategies, 3rd International Conference on Recent Advances in Retailing and Services Science, p. 22-25, Juni 1996, Telfs-Buchen (Osterreich) Werani, Thomas).
Известны применения метода в археологии, анализе текстов, где важно исследовать структуры данных (см. Greenacre, M. J., 1993, Correspondence Analysis in Practice, London: Academic Press).
В качестве дополнительных примеров приведем:
Применение анализа соответствий в медицине связано с исследованием структуры сложных таблиц, содержащих индикаторные переменные, показывающие наличие или отсутствие у пациента данного симптома. Подобного рода таблицы имеют большую размерность, и исследование их структуры представляет нетривиальную задачу.
Задачи визуализации сложных объектов могут быть также исследованы, по крайней мере, к ним можно найти подход, с помощью анализа соответствий. Изображение — это многомерная таблица, и задача состоит в том, чтобы найти плоскость, позволяющую максимально точно воспроизвести исходное изображение.
Математическое основание метода. Анализ соответствия опирается на статистику хи-квадрат. Можно сказать, что это новая интерпретация статистики хи-квадрат Пирсона.
Метод во многом похож на факторный анализ, однако, в отличие от него, здесь исследуются таблицы сопряженности, а критерием качества воспроизведения многомерной таблицы в пространстве меньшей размерности является значение статистики хи-квадрат. Неформально можно говорить об анализе соответствий как о факторном анализе категориальных данных и рассматривать его также как метод сокращения размерности.
Итак, строки или столбцы исходной таблицы представляются точками пространства, между которыми вычисляется расстояние хи-квадрат (аналогично тому, как вычисляется статистика хи-квадрат для сравнения наблюдаемых и ожидаемых частот).
Далее требуется найти пространство небольшой размерности, как правило, двухмерное, в котором вычисленные расстояния минимально искажаются, и в этом смысле максимально точно воспроизвести структуру исходной таблицы с сохранением связей между признаками (если вы имеете представление о методах многомерного шкалирования, то почувствуете знакомую мелодию).
Итак, мы исходим из обычной таблицы сопряженности, то есть таблицы, в которой сопряжены несколько признаков (подробнее о таблицах сопряженности см. главу Построение и анализ таблиц).
Допустим, что имеются данные о пристрастии к курению сотрудников некоторой компании. Подобные данные имеются в файле Smoking.sta, входящем в стандартный комплект примеров системы STATISTICA.
В этой таблице признак курение сопряжен с признаком должность:
|
Группа сотрудников |
(1) Некурящие |
(2) Слабо курящие |
(3) Средне курящие |
(4) Сильно курящие |
Всего по строке |
|
(1) Старшие менеджеры |
4 |
2 |
3 |
2 |
11 |
|
(2) Младшие менеджеры |
4 |
3 |
7 |
4 |
18 |
|
(3) Старшие сотрудники |
25 |
10 |
12 |
4 |
51 |
|
(4) Младшие сотрудники |
18 |
24 |
33 |
13 |
88 |
|
(5) Секретари |
10 |
6 |
7 |
2 |
25 |
|
Всего по столбцу |
61 |
45 |
62 |
25 |
193 |
Это простая двухвходовая таблица сопряженности. Вначале рассмотрим строки.
Можно считать, что 4 первых числа каждой строки таблицы (маргинальные частоты, то есть последний столбец не учитывается) являются координатами строки в 4-мерном пространстве, а значит, формально можно вычислить расстояния хи-квадрат между этими точками (строками таблицы).
При данных маргинальных частотах можно отобразить эти точки в пространстве размерности 3 (число степеней свободы равно 3).
Очевидно, что чем меньше расстояние, тем больше сходство между группами, и наоборот — чем больше расстояния, тем больше различие.
Теперь предположим, что можно найти пространство меньшей размерности, например, размерности 2, для представления точек-строк, которое сохраняет всю или, точнее, почти всю информацию о различиях между строками.
Возможно, такой подход неэффективен для таблиц небольшой размерности, как приведенная выше, однако полезен для больших таблиц, возникающих, например, в маркетинговых исследованиях.
Например, если записаны предпочтения 100 респондентов при выборе 15 сортов пива, то в результате применения анализа соответствий можно представить 15 сортов (точек) на плоскости (см. далее анализ продаж). Анализируя расположение точек, вы увидите закономерности при выборе пива, которые будут полезны при проведении маркетинговой кампании.
В анализе соответствий используется определенный сленг.
Масса. Наблюдения в таблице нормируются: вычисляются относительные частоты для таблицы, сумма всех элементов таблицы становится равной 1 (каждый элемент делится на общее число наблюдений, в данном примере на 193). Создается аналог двухмерной плотности распределения. Полученная стандартизованная таблица показывает, как распределена масса по ячейкам таблицы или по точкам пространства. На сленге анализа соответствий суммы по строкам и столбцам в матрице относительных частот называются массой строки и столбца соответственно.
Инерция. Инерция определяется как значение хи-квадрат Пирсона для двух-входовой таблицы, деленный на общее количество
наблюдений. В данном примере: общая инерция
= 2/193 - 16,442.
Инерция и профили строк и столбцов. Если строки и столбцы таблицы полностью независимы (между ними нет связи — например, курение не зависит от должности), то элементы таблицы могут быть воспроизведены при помощи сумм по строкам и столбцам или, в терминологии анализа соответствий, при помощи профилей строк и столбцов (с использованием маргинальных частот; см. главу Построение и анализ таблиц с описанием критерия хи-квадрат Пирсона и точный критерий Фишера).
В соответствии с известной формулой вычисления хи-квадрат для двухвходовых таблиц ожидаемые частоты таблицы, в которой столбцы и строки независимы, вычисляются перемножением соответствующих профилей столбцов и строк с делением полученного результата на общую сумму.
Любое отклонение от ожидаемых величин (при гипотезе о полной независимости переменных по строкам и столбцам) будет давать вклад в статистику хи-квадрат.
Анализ соответствий можно рассматривать как разложение статистики хи-квадрат на компоненты с целью определения пространства наименьшей размерности, позволяющего представить отклонения от ожидаемых величин (см. таблицу ниже).
Здесь показаны таблицы с ожидаемыми частотами, рассчитанными при гипотезе независимости признаков, и наблюдаемыми частотами, а также таблица вкладов ячеек в хи-квадрат:
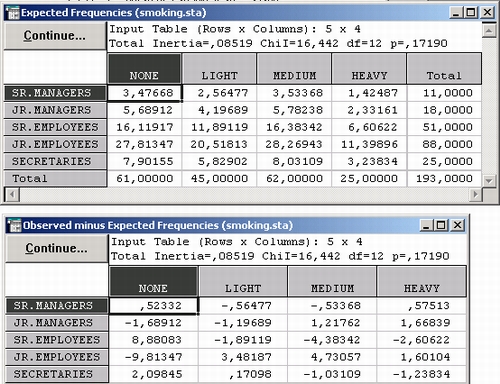
Например, из таблицы видно, что число некурящих младших сотрудников примерно на 10 меньше, чем можно было бы ожидать при гипотезе независимости. Число некурящих старших сотрудников, наоборот, на 9 больше, чем молено было бы ожидать при гипотезе независимости, и т. д. Однако хотелось бы иметь общую картину.
Цель анализа соответствий состоит в том, чтобы суммировать эти отклонения от ожидаемых частот не в абсолютных, а в относительных единицах.

Анализ строк и столбцов. Вместо строк таблицы можно рассматривать также столбцы и представить их точками в пространстве меньшей размерности, которое максимально точно воспроизводит сходство (и расстояния) между относительными частотами для столбцов таблицы. Можно одновременно отобразить на одном графике столбцы и строки, представляющие всю информацию, содержащуюся в двухвходовой таблице. И этот вариант — самый интересный, так как позволяет провести содержательный анализ результатов.
Результаты. Результаты анализа соответствий обычно представляются в виде графиков, как было показано выше, а также в виде таблиц типа:
|
Число измерений |
Процент инерции |
Кумулятивный процент |
Хи-квадрат |
|
1 |
87,75587 |
87,7559 |
14,42851 |
|
2 |
11,75865 |
99,5145 |
1,93332 |
|
3 |
0,48547 |
100,0000 |
0,07982 |
Посмотрите на эту таблицу. Как вы помните, цель анализа — найти пространство меньшей размерности, восстанавливающее таблицу, при этом критерием качества является нормированный хи-квадрат, или инерция. Можно заметить, что если в рассматриваемом примере использовать одномерное пространство, то есть одну ось, можно объяснить 87,76% инерции таблицы.

Две размерности позволяют объяснить 99,51% инерции.
Координаты строк и столбцов. Рассмотрим получившиеся координаты в двухмерном пространстве.
|
Имя строки |
Изменение 1 |
Изменение 2 |
|
Старшие менеджеры |
-0,065768 |
0,193737 |
|
Младшие менеджеры |
0,258958 |
0,243305 |
|
Старшие сотрудники |
-0,380595 |
0,010660 |
|
Младшие сотрудники |
0,232952 |
-0,057744 |
|
Секретари |
-0,201089 |
-0,078911 |
Можно изобразить это на двухмерной диаграмме.
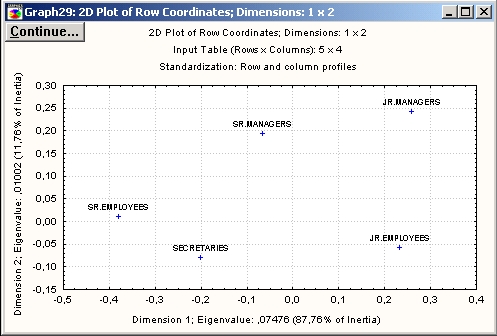
Очевидным преимуществом двухмерного пространства является то, что строки, отображаемые в виде близких точек, близки друг к другу и по относительным частотам.
Рассматривая положение точек по первой оси, можно заметить, что Ст. сотрудники и Секретари относительно близки по координатам. Если же обратить внимание на строки таблицы относительных частот (частоты стандартизованы так, что их сумма по каждой строке равна 100%), то сходство данных двух групп по категориям интенсивности курения становится очевидным.
Проценты по строке:
| Категории курящих | |||||
|
Группа сотрудников |
(1) Некурящие |
(2) Слабо курящие |
(3) Средне курящие |
(4) Сильно курящие |
Всего по строке |
|
(1) Старшие менеджеры |
36,36 |
18,18 |
27,27 |
18,18 |
100,00 |
|
(2) Младшие менеджеры |
22,22 |
16,67 |
38,89 |
22,22 |
100,00 |
|
(3) Старшие сотрудники |
49,02 |
19,61 |
23,53 |
7,84 |
100,00 |
|
(4) Младшие сотрудники |
20,45 |
27,27 |
37,50 |
14,77 |
100,00 |
|
(5} Секретари |
40,00 |
24,00 |
28,00 |
8,00 |
100,00 |
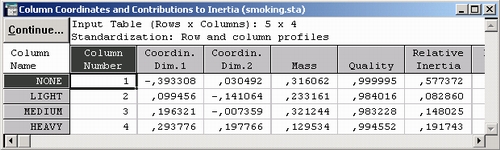
Окончательной целью анализа соответствий является интерпретация векторов в полученном пространстве более низкой размерности. Одним из способов, который может помочь в интерпретации полученных результатов, является представление на диаграмме столбцов. В следующей таблице показаны координаты столбцов:
|
Категории курящих |
Измерение 1 |
Измерение 2 |
|
Некурящие |
-0,393308 |
0,030492 |
|
Слабо курящие |
0,099456 |
-0,141064 |
|
Средне курящие |
0,196321 |
-0,007359 |
|
Сильно курящие |
0,293776 |
0,197766 |
Можно сказать, что первая ось дает градацию интенсивности курения. Следовательно, большую степень сходства между Старшими менеджерами и Секретарями можно объяснить наличием в данных группах большого количества Некурящих.
Метрика координатной системы. В ряде случаев термин расстояние использовался для обозначения различий между строками и столбцами матрицы относительных частот, которые, в свою очередь, представлялись в пространстве меньшей размерности в результате использования методов анализа соответствий.
В действительности расстояния, представленные в виде координат в пространстве соответствующей размерности, — это не просто евклидовы расстояния, вычисленные по относительным частотам столбцов и строк, а некоторые взвешенные расстояния.
Процедура подбора весов устроена таким образом, чтобы в пространстве более низкой размерности метрикой являлась метрика хи-квадрат, учитывая, что сравниваются точки-строки и выбирается стандартизация профилей строк или стандартизация профилей строк и столбцов или же сравниваются точки-столбцы и выбирается стандартизация профилей столбцов или стандартизация профилей строк и столбцов.
Оценка качества решения. Имеются специальные статистики, помогающие оценить качество полученного решения. Все или большинство точек должны быть правильно представлены, то есть расстояния между ними в результате применения процедуры анализа соответствий не должны искажаться. В следующей таблице показаны результаты вычисления статистик по имеющимся координатам строк, основанные только на одномерном решении в предыдущем примере (то есть только одно измерение использовалось для восстановления профилей строк матрицы относительных частот).
Координаты и вклад в инерцию строки:
|
Коор-ты |
Масса |
Кач-тво |
Относит инерция. |
Инерция измер.1 |
Косинус**2 измер.1 |
|
|
Старшие менеджеры |
-0,065768 |
0,056995 |
0,092232 |
0,031376 |
0,003298 |
0,092232 |
|
Младшие менеджеры |
0,258958 |
0,093264 |
0,526400 |
0,139467 |
0,083659 |
0,526400 |
|
Старшие сотрудники |
-0,380595 |
0,264249 |
0,999033 |
0,449750 |
0,512006 |
0,999033 |
|
Младшие сотрудники |
0,232952 |
0,455959 |
0,941934 |
0,308354 |
0,330974 |
0,941934 |
|
Секретари |
-0,201089 |
0,129534 |
0,865346 |
0,071053 |
0,070064 |
0,865346 |
Координаты. Первый столбец таблицы результатов содержит координаты, интерпретация которых, как уже отмечалось, зависит от стандартизации. Размерность выбирается пользователем (в данном примере мы выбрали одномерное пространство), и координаты отображаются для каждого измерения (то есть отображается по одному столбцу координат на каждую ось).
Масса. Масса содержит суммы всех элементов для каждой строки матрицы относительных частот (то есть для матрицы, где каждый элемент содержит соответствующую массу, как уже упоминалось выше).
Если в качестве метода стандартизации выбрана опция Профили строк или опция Профили строк и столбцов, которая установлена по умолчанию, то координаты строк вычисляются по матрице профилей строк. Другими словами, координаты вычисляются на основе матрицы условных вероятностей, представленной в столбце Масса.
Качество. Столбец Качество содержит информацию о качестве представления соответствующей точки-строки в координатной системе, определяемой выбранной размерностью. В рассматриваемой таблице было выбрано только одно измерение, поэтому числа в столбце Качество являются качеством представления результатов в одномерном пространстве. Видно, что качество для старших менеджеров очень низкое, но высокое для старших и младших сотрудников и секретарей.
Отметим еще раз, что в вычислительном плане целью анализа соответствий является представление расстояний между точками в пространстве более низкой размерности.
Если используется максимальная размерность (равная минимуму числа строк и столбцов минус один), можно воспроизвести все расстояния в точности.
Качество точки определяется как отношение квадрата расстояния от данной точки до начала координат, в пространстве выбранной размерности, к квадрату расстояния до начала координат, определенному в пространстве максимальной размерности (в качестве метрики в этом случае выбрана метрика хи-квадрат, как уже упоминалось ранее). В факторном анализе имеется аналогичное понятие общность.
Качество, вычисляемое системой STATISTICA, не зависит от выбранного метода стандартизации и всегда использует стандартизацию, установленную по умолчанию (то есть метрикой расстояния является хи-квадрат, и мера качества может интерпретироваться как доля хи-квадрат, определяемая соответствующей строкой в пространстве соответствующей размерности).
Низкое качество означает, что имеющееся число измерений недостаточно хорошо представляет соответствующую строку (столбец).
Относительная инерция. Качество точки (смотри выше) представляет отношение вклада данной точки в общую инерцию (Хи-квадрат), что может объяснять выбранную размерность.
Качество не отвечает на вопрос, насколько в действительности и в каких размерах соответствующая точка вносит вклад в инерцию (величину хи-квадрат).
Относительная инерция представляет долю общей инерции, принадлежащую данной точке, и не зависит от выбранной пользователем размерности. Отметим, что какое-либо частное решение может достаточно хорошо представлять точку (высокое качество), но та же точка может вносить очень малый вклад в общую инерцию (то есть точка-строка, элементами которой являются относительные частоты, имеет сходство с некоторой строкой, элементы которой представляют собой среднее по всем строкам).
Относительная инерция для каждой размерности. Данный столбец содержит относительный вклад соответствующей точки-строки в величину инерции, обусловленный соответствующей размерностью. В отчете данная величина приводится для каждой точки (строки или столбца) и для каждого измерения.
Косинус**2 (качество, или квадратичные корреляции с каждой размерностью). Данный столбец содержит качество для каждой точки, обусловленное соответствующей размерностью. Если просуммировать построчно элементы столбцов косинус**2 для каждой размерности, то в результате получим столбец величин Качество, о которых уже упоминалось выше (так как в рассматриваемом примере была выбрана размерность 1, то столбец Косинус 2 совпадает со столбцом Качество). Эта величина может интерпретироваться как «корреляция» между соответствующей точкой и соответствующей размерностью. Термин Косинус**2 возник по причине того, что данная величина является квадратом косинуса угла, образованного данной точкой и соответствующей осью.
Дополнительные точки. Помощь в интерпретации результатов может оказать включение дополнительных точек-строк или столбцов, которые на первоначальном этапе не участвовали в анализе. Имеется возможность для включения как дополнительных точек-строк, так и дополнительных точек-столбцов. Можно также отображать дополнительные точки вместе с исходными на одной диаграмме. Например, рассмотрим следующие результаты:
|
Группа сотрудников |
Измерение 1 |
Измерение 2 |
|
Старшие менеджеры |
-0,065768 |
0,193737 |
|
Младшие менеджеры |
0,258958 |
0,243305 |
|
Старшие сотрудники |
-0,380595 |
0,010660 |
|
Младшие сотрудники |
0,232952 |
-0,057744 |
|
Секретари |
-0,201089 |
-0,078911 |
|
Национальное среднее |
-0,258368 |
-0,117648 |
Данная таблица отображает координаты (для двух размерностей), вычисленные для частотной таблицы, состоящей из классификации степени пристрастия к курению среди сотрудников различных должностей.
Строка Национальное среднее содержит координаты дополнительной точки, которая является средним уровнем (в процентах), подсчитанным по различным национальностям курящих. В данном примере это чисто модельные данные.
Если вы построите двухмерную диаграмму групп сотрудников и Национального среднего, то сразу убедитесь в том, что данная дополнительная точка и группа Секретари очень близки друг к другу и расположены по одну сторону горизонтальной оси координат с категорией Некурящие (точкой-столбцом). Другими словами, выборка, представленная в исходной частотной таблице, содержит больше курящих, чем Национальное среднее.
Хотя такое же заключение можно сделать, взглянув на исходную таблицу сопряженности, в таблицах больших размеров подобные выводы, конечно, не столь очевидны.
Качество представления дополнительных точек. Еще одним интересным результатом, касающимся дополнительных точек, является интерпретация качества, представления при заданной размерности.
Еще раз отметим, что целью анализа соответствий является представление расстояний между координатами строк или столбцов в пространстве более низкой размерности. Зная, как решается данная задача, необходимо ответить на вопрос, является ли адекватным (в смысле расстояний до точек в исходном пространстве) представление дополнительной точки в пространстве выбранной размерности. Ниже представлены статистики для исходных точек и для дополнительной точки Национальное среднее применительно к задаче в двухмерном пространстве.
|
Косинус**2 Группа сотрудников |
Качество |
Измерение 1 |
Измерение 2 |
|
Старшие менеджеры |
0,892568 |
0,092232 |
0,800336 |
|
Младшие менеджеры |
0,991082 |
0,526400 |
0,464682 |
|
Старшие сотрудники |
0,999817 |
0,999033 |
0,000784 |
|
Младшие сотрудники |
0,999810 |
0,941934 |
0,057876 |
|
Секретари |
0,998603 |
0,865346 |
0,133257 |
|
Национальное среднее |
0,761324 |
0,630578 |
0,130746 |
Напомним, что качество точек-строк или столбцов определено как отношение квадрата расстояния от точки до начала координат в пространстве сниженной размерности к квадрату расстояния от точки до начала координат в исходном пространстве (в качестве метрики, как уже отмечалось, выбирается расстояние хи-квадрат).
В определенном смысле качество является величиной, объясняющей долю квадрата расстояния до центра тяжести исходного облака точек.
Дополнительная точка-строка Национальное среднее имеет качество, равное 0,76. Это означает, что данная точка достаточно хорошо представлена в двухмерном пространстве. Статистика Косинус**2 — это качество представления соответствующей точки-строки, обусловленное выбором пространства заданной размерности (если просуммировать построчно элементы столбцов Косинус 2 для каждого измерения, то в результате мы придем к величине Качество, полученной ранее).
Графический анализ результатов. Это самая важная часть анализа. По существу вы можете забыть о формальных критериях качества, однако руководствоваться некоторыми простыми правилами, позволяющими понимать графики.
Итак, на графике представляются точки-строки и точки, столбцы. Хорошим тоном является представление и тех и других точек (мы ведь анализируем связи строк и столбцов таблицы!).
Обычно горизонтальная ось соответствует максимальной инерции. Около стрелки показан процент общей инерции, объясняемый данным собственным значением. Часто указывают также соответствующие собственные значения, взятые из таблицы результатов. Пересечение двух осей — это центр тяжести наблюдаемых точек, соответствующий средним профилям. Если точки принадлежат одному и тому же типу, то есть являются либо строками, либо столбцами, то чем меньше расстояние между ними, тем теснее связь. Для того чтобы установить связь между точками разного типа (между строками и столбцами), следует рассмотреть углы между ними с вершиной в центре тяжести.
Общее правило визуальной оценки степени зависимости заключается в следующем.
Рассмотрим анализ конкретных данных в системе STATISTICA.
Шаг 1. Запустите модуль Анализ соответствий.
В стартовой панели модуля имеются 2 вида анализа: анализ соответствий и многомерный анализ соответствий.
Выберите Анализ соответствий. Многомерный анализ соответствий будет рассмотрен в следующем примере.
Шаг 2. Откройте файл данных smoking.sta папки Examples.
В файле содержатся данные о распространении курения среди сотрудников фирмы.
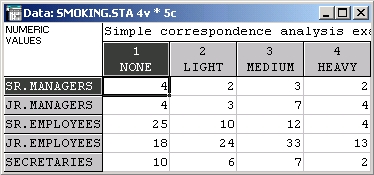
Файл уже представляет собой таблицу сопряженности, поэтому табуляция не требуется. Выберите вид анализа — Частоты без группирующей переменной.
Шаг 3. Нажмите кнопку Переменные с частотами и выберите переменные для анализа.
В данном примере выберите все переменные.
Шаг 4. Нажмите OK и запустите вычислительную процедуру. На экране появится окно с результатами.
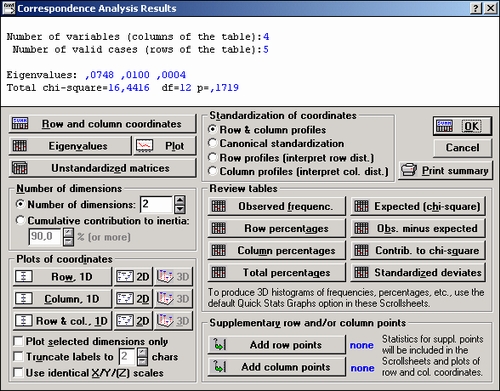
Шаг 5. Рассмотрим результаты с помощью опций данного окна.
Обычно сначала рассматриваются графики, для чего имеется группа кнопок График координат.
Графики доступны для строк и столбцов, а также для строк и столбцов одновременно.
Размерность максимального простарнства задается в опции Размерность.
Наиболее интересна размерность 2. Заметьте, что на графике, особенно если имеется множество данных, метки могут накладываться друг на друга, поэтому может быть полезной опция Сократить метки.
Нажмите третью кнопку 2М в диалоговом окне. На экране появится график:
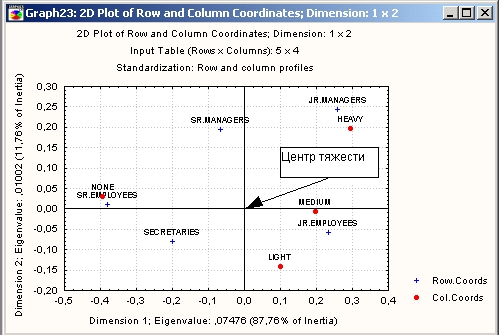
Заметьте, что на графике представлены оба фактора: группа сотрудников — строки и интенсивность курения — столбцы.
Соедините отрезком прямой категорию СТАРШИЕ СОТРУДНИКИ, а также категорию НЕТ с центром тяжести.
Образовавшийся угол будет острым, что на языке анализа соответствий говорят о наличии положительной корреляции между этими признаками (просмотрите исходную таблицу, чтобы убедиться в этом).
Координаты строк и столбцов можно посмотреть и в численном виде с помощью кнопки Координаты строк и столбцов.
Используя кнопку Собственные значения, можно увидеть разложение статистики хи-квадрат по собственным значениям.
Опция График только выбранных измерений позволяет просмотреть координаты точек по выбранным осям.
Группа опций Просмотр таблиц в правой части окна позволяет просмотреть исходную и ожидаемую таблицу сопряженности, разности между частотами и другие параметры, вычисленные при гипотезе независимости табулированных признаков (см главу Построение и анализ таблиц, критерий хи-квадрат).
Таблицы большой размерности лучше всего исследовать постепенно, вводя по мере надобности дополнительные переменные. Для этого предусмотрены опции: Добавить точки-строки, Добавить точки-столбцы.
В главе Анализ и построение таблиц был рассмотрен пример, связанный с анализом продаж. Применим к данным анализ соответствий.
Ранее отмечалось, что вопрос, какие именно покупки произвел покупатель при условии, что куплено 3 товара, является сложным.
Действительно, всего мы имеем 21 продукт. Чтобы просмотреть все таблицы сопряженности, требуется выполнить 21×20×19 = 7980 действий. Число действий катастрофически возрастает при увеличении товаров и количества признаков. Применим анализ соответствий. Откроем файл данных с индикаторными переменными, отмечающими купленный продукт.
В стартовой панели модуля выберем Многомерный анализ соответствий.

Зададим условие выбора наблюдений.
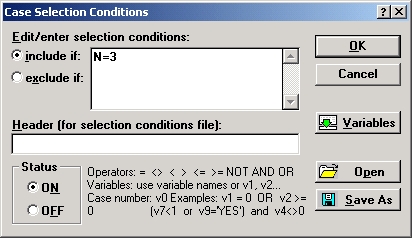
Это условие позволяет выбрать покупателей, сделавших ровно 3 покупки.
Поскольку мы имеем дело с нетабулированными данными, выберем вид анализа Исходные данные (требуется табуляция).
Для удобства дальнейшего графического представления выберем небольшое количество переменных. Выберем также дополнительные переменные (см; окно ниже).
Запустим вычислительную процедуру.
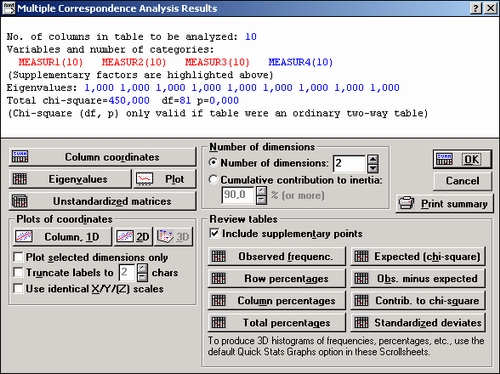
В появившемся окне Результаты многомерного анализа соответствий просмотрим результаты.
С помощью кнопки 2М выводится двухмерный график переменных.
На этом графике дополнительные переменные отмечены красными точками, что удобно для визуального анализа.
Заметьте, что каждая переменная имеет признак 1, если товар куплен, и признак 0, если товар не куплен.
Рассмотрим график. Выберем, например, близкие пары признаков.
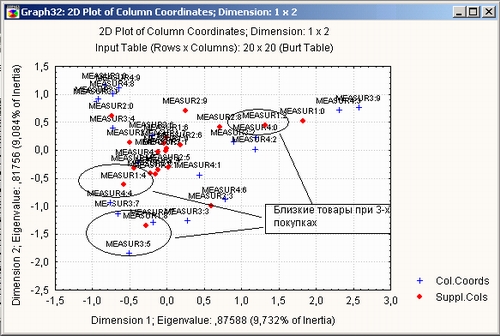
В итоге получим следующее:
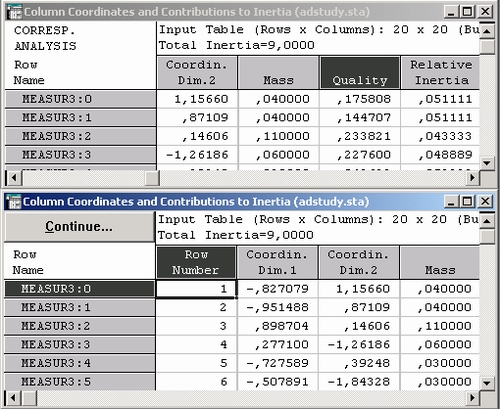
Аналогичные исследования можно провести и для других данных, когда отсутствуют какие-либо априорные гипотезы о зависимостях в данных.
|
|
