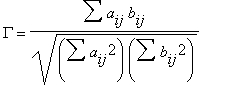
Одним из факторов, ограничивающих применения критериев, основанных на предположении нормальности, является объем выборки. До тех пор пока выборка достаточно большая (например, 100 или больше наблюдений), можно считать, что выборочное распределение нормально, даже если вы не уверены, что распределение переменной в популяции является нормальным. Тем не менее, если выборка мала, эти критерии следует использовать только при наличии уверенности, что переменная действительно имеет нормальное распределение. Однако нет способа проверить это предположение на малой выборке.
Использование критериев, основанных на предположении нормальности, кроме того, ограничено шкалой измерений (см. главу Элементарные понятия анализа данных). Такие статистические методы, как t-критерий, регрессия и т. д. предполагают, что исходные данные непрерывны. Однако имеются ситуации, когда данные, скорее, просто ранжированы (измерены в порядковой шкале), чем измерены точно.
Типичный пример дают рейтинги сайтов в Интернет: первую позицию занимает сайт с максимальным числом посетителей, вторую позицию занимает сайт с максимальным числом посетителей среди оставшихся сайтов (среди сайтов, из которых удален первый сайт) и т. д. Зная рейтинги, мы можем сказать, что число посетителей одного сайта больше числа посетителей другого, но насколько больше, сказать уже нельзя. Представьте, вы имеете 5 сайтов: А, В, С, D, Е, которые располагаются на 5 первых мест. Пусть в текущем месяце мы имели следующую расстановку: А, В, С, D, E, а в предыдущем месяце: D, E, А, В, С. Спрашивается, произошли существенные изменения в рейтингах сайтов или нет? В данной ситуации, очевидно, мы не можем использовать t-критерий, чтобы сравнить эти две группы данных, и переходим в область специфических вероятностных вычислений (а любой статистический критерий содержит в себе вероятностную калькуляцию!). Мы рассуждаем примерно следующим образом: насколько велика вероятность того, что отличие в двух расстановках сайтов вызвано чисто случайными причинами или это отличие слишком велико и не может быть объяснено за счет чистой случайности. В этих рассуждениях мы используем лишь ранги или перестановки сайтов и никак не используем конкретный вид распределения числа посетителей на них.
Для анализа малых выборок и для данных, измеренных в бедных шкалах, применяют непараметрические методы.
Краткий обзор непараметрических процедур
По существу, для каждого параметрического критерия имеется, по крайней мере, одна непараметрическая альтернатива.
В общем, эти процедуры попадают в одну из следующих категорий:
Вообще, подход к статистическим критериям в анализе данных должен быть прагматическим и не отягощен лишними теоретическими рассуждениями. Имея в своем распоряжении компьютер с системой STATISTICA, вы легко примените к своим данным несколько критериев. Зная о некоторых подводных камнях методов, вы путем экспериментирования выберете верное решение. Развитие сюжета довольно естественно: если нужно сравнить значения двух переменных, то вы используете t-критерий. Однако следует помнить, что он основан на предположении нормальности и равенстве дисперсий в каждой группе. Освобождение от этих предположений приводит к непараметрическим тестам, которые особенно полезны для малых выборок.
Далее имеются две ситуации, связанные с исходными данными: зависимые и независимые выборки, в которых применяется t-критерий для зависимых и независимых выборок соответственно.
Развитие t-критерия приводит к дисперсионному анализу, который используется, когда число сравниваемых групп больше двух. Соответствующее развитие непараметрических процедур приводит к непараметрическому дисперсионному анализу, правда, существенно более бедному, чем классический дисперсионный анализ.
Для оценки зависимости, или, выражаясь несколько высокопарно, степени тесноты связи, вычисляют коэффициент корреляции Пирсона. Строго говоря, его применение имеет ограничения, связанные, например, с типом шкалы, в которой измерены данные, и нелинейностью зависимости, поэтому в качестве альтернативы используются также непараметрические, или так называемые ранговые, коэффициенты корреляции, применяемые, например, для ранжированных данных. Если данные измерены в номинальной шкале, то их естественно представлять в таблицах сопряженности, в которых используется критерий хи-квадрат Пирсона с различными вариациями и поправками на точность.
Итак, по существу имеется всего несколько типов критериев и процедур, которые нужно знать и уметь использовать в зависимости от специфики данных. Вам нужно определить, какой критерий следует применять в конкретной ситуации.
Непараметрические методы наиболее приемлемы, когда объем выборок мал. Если данных много (например, n >100), часто не имеет смысла использовать непараметрическую статистику.
Если размер выборки очень мал (например, n = 10 или меньше), то уровни значимости для тех непараметрических критериев, которые используют нормальное приближение, можно рассматривать только как грубые оценки.
Различия между независимыми группами. Если имеются две выборки (например, мужчины и женщины), которые нужно сравнить относительно некоторого среднего значения, например, среднего давления или количества лейкоцитов в крови, то можно использовать t-тест для независимых выборок.
Непараметрическими альтернативами этому тесту являются критерий серий Валъда—Волъфовица, Манна—Уитни [7-тест и двухвыборочный критерий Колмогорова— Смирнова.
Различия между зависимыми группами. Если вы хотите сравнить две переменные, относящиеся к одной и той же выборке, например, медицинские показатели одних и тех же пациентов до и после приема лекарства, то обычно используется t-критерий для зависимых выборок.
Альтернативными непараметрическими тестами являются критерий знаков и критерий Вилкоксона.
Если рассматриваемые переменные категориальны, то подходящим является хи-тадрат Макнемара.
Если рассматривается более двух переменных, относящихся к одной и той же выборке, то обычно используется дисперсионный анализ (ANOVA) с повторными измерениями.
Альтернативным непараметрическим методом является Ранговый дисперсионный анализ Фридмана и Q-критерий Кохрена.
Исследование зависимости между порядковыми переменными
Для того чтобы оценить зависимость между двумя переменными, обычно вычисляют коэффициент корреляции Пирсона. Непараметрическими аналогами коэффициента корреляции Пирсона являются коэффициенты ранговой корреляции Спирмена R, статистика Кендалла и коэффициент Гамма (более подробно см. например, книгу Кендалл М. Дж., Ранговые корреляции 1975, ).
Коэффициент ранговой корреляции (rank correlation coefficients') оценивает величину зависимости между переменными, измеренными в порядковых шкалах, т. е. между порядковыми переменными.
Прозрачный способ построения парных коэффициентов корреляции из обобщенного коэффициента корреляции предложил Daniels (Daniels Н. Е., 1948, Biometrika, v. 35, p. 416-417), см. также заметку Е. В. Кулинской в Энциклопедии: «Вероятность и математическая статистика», 1999. С. 537-538. Обобщенный коэффициент корреляции определяется формулой:
где аij = a(Xi Xj), bij = b(Yi, Yj) — некоторые функции пар наблюдений X и Y соответственно, суммирование ведется по всем парам i, j.
Заметим, что при аij =Xj - Хi, bij= Yj- Yi. получаем обычный коэффициент корреляции Пирсона. Если переменные ранжированы, то мы работаем с рангами. Упорядочим значения Xi по возрастанию, то есть построим вариационный ряд этих величин. Номер величины Хi в этом ряде называется ее рангом и обозначается Ri
Затем упорядочим значения Yi в порядке возрастания. Номер величины Yii в этом ряде называется ее рангом и обозначается Si
Коэффициент ранговой корреляции Спирмена вычисляется как обобщенный коэффициент парной корреляции с заменой наблюдений их рангами. Формально для обобщенного коэффициента корреляции нужно положить aij = Rj — Ri,bij = Sj - Si
Коэффициент Кендалла вычисляется, если в формуле для обобщенного коэффициента положить аij = 1 при Ri< Rj и аij = -1 при Ri > Rj Величины bij задаются аналогичными соотношениями с заменой рангов Rij ранги Si наблюдений Y. Итак, мы ясно видим, что идея всех корреляций возникает из одного и того же источника.
Если имеется более двух переменных, то используют коэффициент конкорда-ции Кендалла. Например, он применяется для оценки согласованности мнений независимых экспертов (судей), например, баллов, выставленных одному и тому же участнику конкурса.
Если имеются две категориальные переменные, то для оценки степени зависимости используют стандартные статистики и соответствующие критерии для таблиц сопряженности: хи-квадрат, фи-коэффициент, точный критерий Фишера.
Нелегко дать простой и однозначный совет, касающийся использования этих процедур. Каждая имеет свои достоинства и свои недостатки.
Например, двухвыборочный критерий Колмогорова—Смирнова чувствителен не только к различию в положении двух распределений, но также и к форме распределения. Фактически он чувствителен к любому отклонению от гипотезы однородности, но не указывает, с каким именно отклонением мы имеем дело.
Критерий Вилкоксона предполагает, что можно ранжировать различия между сравниваемыми наблюдениями. Если этого сделать нельзя, то используют критерий знаков, который учитывает лишь знаки разностей сравниваемых величин.
В общем, если результат исследования является важным и наблюдений немного (например, отвечает на вопрос — оказывает ли людям помощь определенная очень дорогая и болезненная лекарственная терапия?), то всегда целесообразно испытать непараметрические тесты. Возможно, результаты тестирования (разными тестами) будут различны. В таком случае следует попытаться понять, почему разные тесты дали разные результаты.
С другой стороны, непараметрические тесты имеют меньшую мощность, чем их параметрические конкуренты, и если важно обнаружить даже слабые эффекты (например, при выяснении, является ли данная пищевая добавка опасной для здоровья), следует провести многократные испытания и особенно внимательно выбирать статистику критерия.
Описание непараметрических процедур на примерах
Стартовая панель модуля Непараметрические статистики
Стартовая панель модуля имеет вид:
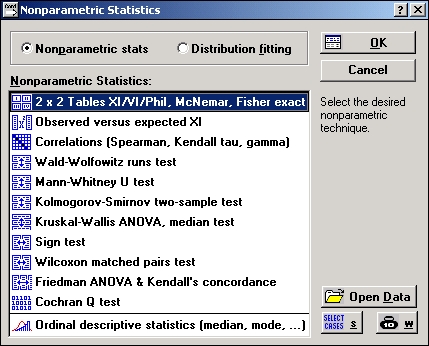
Таблицы частот 2× 2: статистики Хи/V/Фи-квадрат, Макнемара, точный критерий Фишера
Опция открывает диалоговое окно, в котором можно ввести частоты в таблицу 2×2 (состоящую из двух строк и двух столбцов) и вычислить различные статистики, позволяющие оценить зависимость между двумя переменными, принимающими только два значения.

Типичный пример таких таблиц — определение, например, числа мужчин и женщин, предпочитающих рекламу ПЕПСИ или КОКИ, или числа заболевших и не заболевших людей из числа сделавших и не сделавших прививки, и т. д.
Итак, одна переменная — ПОЛ, другая переменная — НАПИТОК. Первая переменная имеет 2 уровня (принимает 2 значения) — мужчина, женщина. Вторая переменная, НАПИТОК, также имеет 2 уровня, например, ПЕПСИ или КОКА.
Задача состоит в том, чтобы оценить зависимость между двумя табулированными переменными.
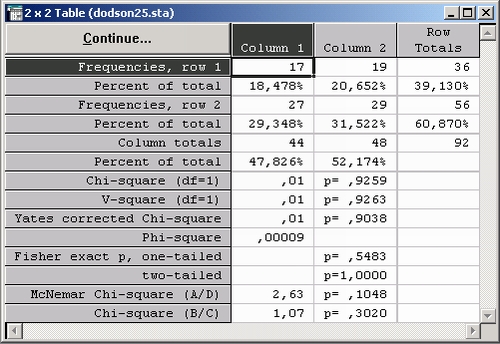
Укажем на важное методологическое отличие использования слова связь (зависимость) в повседневной жизни и в анализе данных (см. главу 33 фундаментального текста Кендалла и Стьюарта Статистические выводы и связи). Обычно мы говорим, что два признака А и В связаны между собой, если они часто встречаются вместе. В анализе данных дается строгое определение: если А встречается относительно чаще с В, чем с не-В, то А и В связаны. Или переходя на язык теории вероятностей, Р( АХВ) должна быть больше Р(АХ не-В). Оценкой вероятности является частота.
В приведенной выше таблице пусть признак А — пол, признак В — напиток, принимающий, например, два значения: пепси — не-пепси. Пусть a, b — частоты в первой строке, с, d — частот во второй строке. Если а/(а+с) = b/(b+d) то признаки независимы. Формально имеем: 17/(17+27) = 0,39, 19/(19+29) - 0,396. Теперь нам нужно понять, существенно или нет различие в частотах. Статистические критерии, реализованные в этом диалоге, как раз и позволяют это сделать. В данном случае различие, конечно, несущественно (или, как говорят в анализе данных, незначимо). Следовательно, признаки независимы, — пол не связан с выбором напитка.
Опция 2x2 может быть использована как альтернатива корреляциям, если обе рассматриваемые переменные являются категориальными.
Дополнительно к стандартному критерию хи-квадрат Пирсона и скорректированному хи-квадрат (V-квадрат) вычисляются следующие статистики:
Классическая статистика хи-квадрат Пирсона замечательна тем, что ее распределение приближается распределением хи-квадрат, для которого имеются подробные таблицы. Процентные точки распределения хи-квадрат могут быть также эффективно вычислены в системе STATISTICA с помощью вероятностного калькулятора.
Свойство критерия хи-квадрат (точность аппроксимации распределения статистики распределением хи-квадрат) для таблиц 2× 2 с малыми ожидаемыми частотами может быть улучшено за счет уменьшения абсолютного значения разностей между ожидаемыми и наблюдаемыми частотами на величину 0,5 перед возведением в квадрат.
Это так называемая поправка Йетса на непрерывность для таблиц частот 2×2, которая обычно применяется, когда ячейки содержат только малые частоты и некоторые ожидаемые частоты становятся меньше 5 (или даже меньше 10).
Фи-коэффициент. Статистика фи-квадрат представляет собой меру связи между номинальными или категориальными переменными, значения которых нельзя упорядочить.
Пусть даны маргинальные или суммарные частоты в таблице 2×2. Предположим, что оба фактора в таблице независимы. Зададимся вопросом: какова вероятность получить наблюдаемые частоты, исходя из маргинальных? Замечательно, что эта вероятность вычисляется точно, подсчетом всех возможных таблиц, которые можно построить, основываясь на данных маргинальных частотах. Это и делается в критерии Фишера. STATISTICA вычисляет р-уровни одностороннего и двустороннего критерия Фишера.
Если сумма частот небольшая, то лучше использовать точный критерий Фишера вместо критерия хи-квадрат.
Известны рекомендации Кокрена для таблиц 2×2: если сумма всех частот в таблице меньше 20, то следует использовать точный критерий Фишера.
Если сумма частот больше 40, то можно применять критерий хи-квадрат с поправкой на непрерывность.
Однако эти рекомендации не универсальны (см. например, Справочник по прикладной статистике п/р Э. Ллойда и У. Ледермана, с. 375-376).
Рассмотрим следующий пример.
Пример. Исследуются 30 человек, совершивших преступления. У каждого из преступников есть брат-близнец. Спрашивается, имеется ли связь между род ственными отношениями и преступлением (см. Справочник по прикладной статистике п/р Э. Ллойда и У. Ледермана, с. 376). Данные приведены в таблице:
|
Оба брата преступники |
Только один брат преступник |
Сумма |
|
|
Однояйцевые близнецы |
10 |
3 |
13 |
|
Разнояйцовые близнецы |
2 |
15 |
17 |
|
Сумма |
12 |
18 |
18 |
Проверяемая гипотеза состоит в том, что зависимости между родством и преступностью нет. Альтернативная гипотеза заключается в следующем: чем теснее родственные связи, тем более вероятно совместное участие в преступлении (то есть между признаками имеется положительная связь). Заметьте — это односторонняя альтернатива, т. к. нас интересует отклонение от гипотезы лишь в одну сторону (вольно выражаясь, с сохранением знака больше).
Введем данные в систему STATISTICА.

После нажатия на кнопку ОК получим следующую электронную таблицу с результатами:
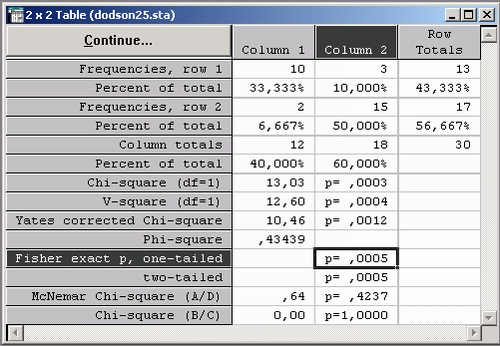
Значение статистики хи-квадрат равно 13,03.
Так как в данных имеются ячейки с малыми частотами (2 и 3), то для улучшения точности критерия хи-квадрат используем поправку Йетса. Поскольку нас интересует односторонняя альтернатива, мы делим уровень р = 0,0012 пополам и получаем 0,0006.
Точное значение одностороннего критерия Фишера равно 0,0005 (см. таблицу). Оба эти результата высокозначимы, следовательно, мы отвергаем исходную гипотезу об отсутствии зависимости между родством и преступлением в пользу альтернативы: «между признаками имеется тесная положительная связь».
Заметьте, что сумма всех частот в таблице меньше 40, но оба критерия, точный Фишера и хи-квадрат Йетса, дают почти одинаковые результаты.
Критерий хи-квадрат Макнемара. Этот критерий применяется, когда частоты в таблице 2x2 получены по зависимым выборкам. Например, когда наблюдения фиксируются до и после воздействия на одном и том же экспериментальном материале.
STATISTICА включает также модуль Логлинейный анализ, позволяющий выполнить полный логлинейный анализ многовходовых таблиц сопряженности. STATISTICA содержит программу на STATISTICA BASIC для вычисления критерия Ментела—Хенцела (файл Ma.nthaen.stb в каталоге STBASIC), позволяющего сравнить две группы данных. Обратитесь к комментариям в программе Manthaen.stb за дополнительной информацией.
Наблюдаемые частоты в сравнении с ожидаемыми
Опция позволяет оценить согласие наблюдаемых частот с произвольным набором ожидаемых частот.
Процедура предлагает пользователю ввести две переменные: одна содержит ожидаемые, другая — наблюдаемые частоты. Для проверки согласия наблюдаемых и ожидаемых частот вычисляется критерий хи-квадрат.
Следующий пример основан на данных (искусственных) об авариях на шоссе (данные содержатся в файле Accident.sta). Данные записывались с интервалом, равным месяцу, в 1983 и 1985 годах.
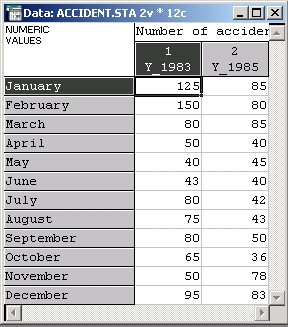
Допустим, что в 1984 году были потрачены значительные средства с тем, чтобы улучшить безопасность движения на этом шоссе. Если затраченные средства ни к чему не привели (нулевая гипотеза), то число несчастных случаев в 1985 году могло бы прогнозироваться на том же уровне, что и в 1983-м (при условии, что общее число машин на трассе и интенсивность движения не менялись). Таким образом, данные за 1985 год рассматриваются здесь как ожидаемые значения, данные за 1983 год — как наблюдаемые.
Задание анализа. После запуска модуля Непараметрические статистики и распределения откройте файл Accident.sta и выберите в стартовой панели опцию Наблюдаемые в сравнении ожидаемыми. В появившемся диалоговом окне Наблюдаемые и ожидаемые частоты нажмите кнопку Переменные и выберите Y_1983 — переменную с наблюдаемыми частотами и Y_1985 — переменную с ожидаемыми частотами.
После нажатия ОК таблица с результатами появится на экране.
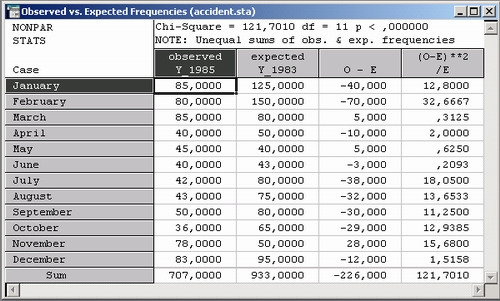
Из таблицы ясно видно, что снижение числа аварий в 1985 году по сравнению с 1983 годом высокозначимо.
Заметим, что в нижней части таблицы результатов показано общее число аварий за каждый год (Сумма); разности между наблюдаемыми и ожидаемыми значениями даны в третьем столбце, квадраты разностей, деленные на ожидаемые значения (слагаемые хи-квадрат), — в четвертом столбце.
Обратите внимание на число степеней свободы (ее) распределения хи-квадрат, в этом примере оно равно 11.
Корреляции (Спирмена R, тау Кендалла, Гамма)
Опция позволяет вычислить три различные альтернативы коэффициенту корреляции Пирсона: корреляцию Спирмена R, статистику тay Кендалла и статистику Гамма. После выбора опции на экране появится диалоговое окно, в котором можно выбрать переменные и определенный тип корреляции для вычисления. Можно вычислить одну непараметрическую корреляцию или матрицу непараметрических корреляций.
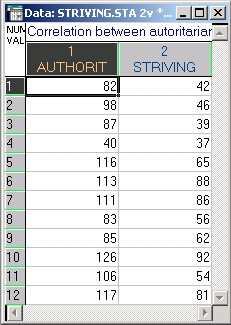
Следующий пример основывается на данных (файл Striving.sta), представленных Siegel and Castellan (1988) Nonparametric statistics for the behavioral sciences (2nded.) New York: McGraw-Hill.
Двенадцать студентов ответили на вопрос анкеты, чтобы оценить связь между двумя переменными: авторитарностью и борьбой за социальное положение. Авторитарность (Adorno и др., 1950) — психологическая концепция, состоящая, грубо говоря, в том, что властные люди имеют тенденцию считать, что власть должна быть жесткой и ей следует подчиняться (иными словами, придерживаются принципа: «закон и порядок»).
Данные показаны ниже.
Цель исследования состояла в том, чтобы выяснить, зависимы, в действительности, эти две переменные или нет.
Задание анализа. После запуска модуля Непараметрические статистики и распределения откройте файл Accident.sta и выберите в стартовой панели опцию Корреляции (Спирмена, may Кендалла, гамма). В появившемся диалоговом окне нажмите кнопку переменные и выберите Authorit как первую переменную, Striving — как вторую переменную.
Модуль Непараметрические статистики и распределения вычисляет также корреляционные матрицы. В этом примере выберите просто Спирмена R и Подробный отчет.
После нажатия OK таблица с результатами появится на экране.
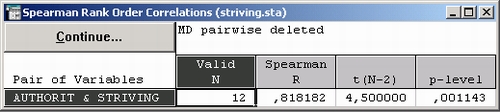
Вы видите, что корреляция между двумя шкалами высокозначима, и можно сделать вывод, что индивидуумы, имеющие внутреннюю установку на авторитарность, в свою очередь, стремятся к борьбе за свое положение в обществе (при условии, что анкета адекватна данному исследованию), тем самым подтверждается концепция Адорно.
Авторитаризм — внутренняя установка (ее трудно непосредственно измерить). В отличие от этого борьба за положение в обществе и продвижение по иерархической лестнице наблюдается отчетливо. Итак, между властностью и карьеризмом имеется отчетливая зависимость.
Вы можете визуализировать найденную зависимость двумя способами. Либо нажав кнопку Матричная диаграмма в диалоговом окне Непараметрические корреляции (после того как выбрали переменные), либо щелкнув правой кнопкой мыши на таблице результатов и выбрав опцию Диаграмма рассеяния/довер из меню Быстрые статистические графики.
Параметрическая корреляция (r Пирсона) между шкалами (r = 0,77) показана в заголовке графика (см. ниже). Интересно, что эта корреляция меньше ранговой корреляций Спирмена (Спирмена R равно 0,82).
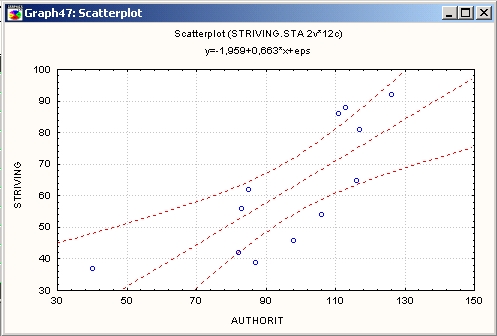
Если бы в этом примере мы располагали большим объемом данных, то могли бы сделать вывод, что рассмотрение рангов (а не самих наблюдений) в действительности улучшает оценку зависимости между переменными, так как «подавляет» случайную изменчивость и уменьшает воздействия выбросов.
Статистики Кендалла тay и Гамма. Для сравнения вернитесь в окно Непарамет рические корреляции и выберите опцию Статистика тay Кендалла а также опцию Гамма. Обе статистики Кендалла тay и Гамма будут вычислены и окажутся равными 0,67.
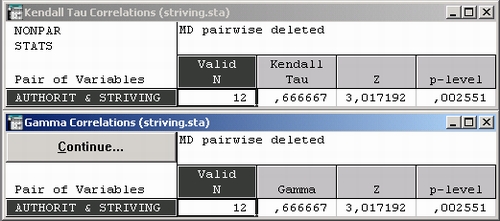
Как было сказано ранее, эти статистики тесно связаны между собой, но отличаются от статистики Спирмена. Статистику Спирмена R можно представить себе как вычисленную по рангам корреляцию Пирсона, т. е. в терминах доли изменения одной величины, связанной с изменением другой. Статистики Кендалла тay и Гамма скорее оценивают вероятности, точнее, разность между вероятностью того, что наблюдаемые значения переменных имеют один и тот же порядок, и вероятностью того, что порядок различный.
Матрицы двух списков. Опция вычисляет только корреляции между переменными, заданными в первом списке, с переменными, заданными во втором списке.
Квадратная матрица. Опция вычисляет корреляции для одного списка переменных (квадратная матрица). Заметим, если выбраны два списка переменных, а затем выбрана эта опция, то списки будут «объединены» в один.
Нажмите кнопку, чтобы построить матричную диаграмму рассеяния для выбранных переменных.
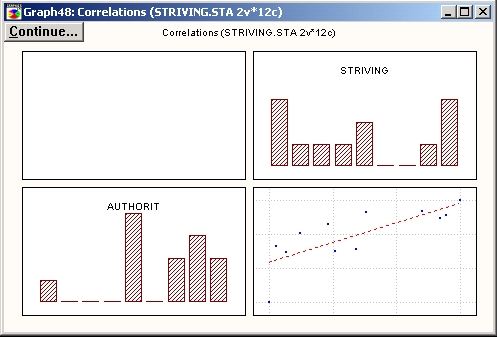
Этот график полезен тем, что он позволяет быстро оценить и сравнить распределения выбранных переменных и форму зависимости между ними (например, коэффициент ранговой корреляции R Спирмена может измерять нелинейную монотонную зависимость между переменными).
Критерий серий Вальда—Вольфовица
Критерий серий Вальда—Вольфовица представляет собой непараметрическую альтернативу ^-критерию для независимых выборок. Данные имеют тот же вид, что и в t-критерии для независимых выборок. Файл должен содержать группирующую (независимую) переменную, принимающую, по крайней мере, два различных значения (кода), чтобы однозначно определить, к какой группе относится каждое наблюдение в файле данных.
Программа открывает диалоговое окно выбора группирующей переменной и списка зависимых переменных (переменных, по которым две группы сравниваются между собой), а также кодов для группирующей переменной (опция Коды).
Критерий серий Вальда—Вольфовица устроен следующим образом. Представьте, что вы хотите сравнить мужчин и женщин по некоторому признаку. Вы можете упорядочить данные, например, по возрастанию, и найти те случаи, когда субъекты одного и того же пола примыкают друг к другу в построенном вариационном ряде (иными словами, образуют серию).
Если нет различия между мужчинами и женщинами, то число и длина «серий», относящиеся к одному и тому же полу, будут более или менее случайными. В противном случае две группы (мужчины и женщины) отличаются друг от друга, то есть не являются однородными.
Критерий предполагает, что рассматриваемые переменные являются непрерывными и измерены, по крайней мере, в порядковой шкале.
Критерий серий Вальда—Вольфовица проверяет гипотезу о том, что две независимые выборки извлечены из двух популяций, которые в чем-то существенно различаются между собой, иными словами, различаются не только средними, но также формой распределения. Нулевая гипотеза состоит в том, что обе выборки извлечены из одной и той же популяции, то есть данные однородны.
Критерий Манна—Уитни представляет непараметрическую альтернативу t-критерию для независимых выборок. Опция предполагает, что данные расположены таким же образом, что в и t-критерии для независимых выборок. В частности, файл должен содержать группирующую переменную, имеющую, по крайней мере, два разных кода для однозначной идентификации принадлежности каждого наблюдения к определенной группе.
Критерий U Манна—Уитни предполагает, что рассматриваемые переменные измерены, по крайней мере, в порядковой шкале (ранжированы). Заметим, что во всех ранговых методах делаются поправки на совпадающие ранги.
Интерпретация теста, по существу, похожа на интерпретацию результатов t-критерия для независимых выборок за исключением того, что U-критерий вычисляется как сумма индикаторов парного сравнения элементов первой выборки с элементами второй выборки.
U-критерий — наиболее мощная (чувствительная) непараметрическая альтернатива t-критерию для независимых выборок; фактически, в некоторых случаях он имеет даже большую мощность, чем t-критерий (см. например, Холлендер М., Вульф Д. А. (1983), Непараметрические методы статистики, а также заметку М. С. Никулина в Энциклопедии: «Вероятность и математическая статистика». С. 299). Формально статистика Манна—Уитни вычисляется как:
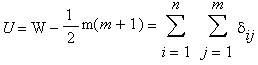
где W — так называемая статистика Вилкоксона,
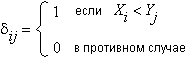
Таким образом, статистика U считает общее число тех случаев, в которых элементы второй группы, например, мужчины, превосходят элементы первой группы, например, женщин.
Двухвыборочный критерий Колмогорова—Смирнова
Критерий Колмогорова—Смирнова — это непараметрическая альтернатива t-кри-терию для независимых выборок. Формально он основан на сравнении эмпирических функций распределения двух выборок. Данные имеют такую же организацию, как в t-критерии для независимых выборок. Файл должен содержать кодовую (независимую) переменную, имеющую, по крайней мере, два различных кода для однозначного определения, к какой группе принадлежит каждое наблюдение.
Опция открывает диалоговое окно выбора кодовой переменной и списка зависимых переменных (переменных, по которым две группы сравниваются между собой), а также кодов, используемых в кодовой переменной для идентификации двух групп (опция Коды).
Критерий Колмогорова—Смирнова проверяет гипотезу о том, что выборки извлечены из одной и той же популяции, против альтернативной гипотезы, когда выборки извлечены из разных популяций. Иными словами, проверяется гипотеза однородности двух выборок.
Однако в отличие от параметрического i-критерия для независимых выборок и от U-критерия Манна—Уитни (см. выше), который проверяет различие в положении двух выборок, критерий Колмогорова—Смирнова также чувствителен к различию общих форм распределений двух выборок (в частности, различия в рассеянии, асимметрии и т. д.).
Пример. Критерий серий Вальда—Вольфовица, Манна—Уитни U-критерий, двухвыборочный критерий Колмогорова—Смирнова
Все эти критерии представляют собой альтернативы t-критерию для независимых выборок. Пример основан на исследовании агрессивности четырехлетних мальчиков и девочек (Siegel, S. (1956) Nonparametric statistics for the behavioral sciences (2nded.) New York: McGraw-Hill). Данные содержатся в файле Aggressn.sta.
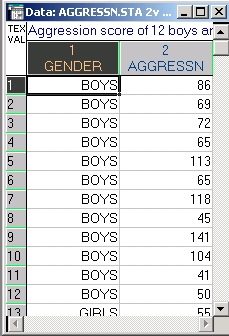
Двенадцать мальчиков и двенадцать девочек наблюдались в течение 15-минутной игры; агрессивность каждого ребенка оценивалась в баллах (в терминах частоты и степени проявления агрессивности) и суммировалась в один индекс агрессивности, который вычислялся для каждого ребенка.
Задание анализа. После запуска модуля Непараметрические статистики откройте электронную таблицу с данными (файл Aggressn.sta), выберите опцию Критерий серий Вальда—Волъфовица.
Далее нажмите ОК.
Нажмите кнопку Переменные и выберите переменную Пол — Gender как группирующую и переменную Aggressn как зависимую.

Коды для однозначного отнесения каждого наблюдения к определенному полу будут автоматически выбраны программой.
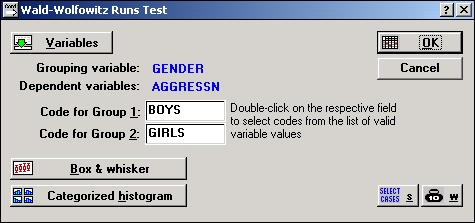
Далее нажмите OK, чтобы выполнить анализ.

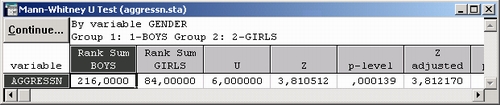
Как видно из таблицы результатов, различие между агрессивностью мальчиков и девочек в этом исследовании высокозначимо.
Выполните то же самое исследование с помощью критерия Манна—Уитни.
Нажмите кнопку Переменные и выберите переменную Пол — Gender как группирующую и переменную Aggressn — как зависимую.

Коды для однозначного отнесения каждого наблюдения к определенному полу будут автоматически выбраны программой.
Выберите опцию Двухвыборочный критерий Колмогорова—Смирнова.
Нажмите кнопку Переменные и выберите переменную Пол — Gender как группирующую и переменную Aggressn — как зависимую.

Коды для однозначного отнесения каждого наблюдения к определенному полу будут автоматически выбраны программой.
Электронная мультимедийная таблица с результатами имеет вид:
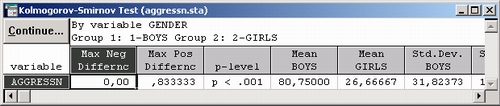
Заметьте, что стандартные отклонения в обеих группах не равны (см. шестой и седьмой столбец в таблице результатов) и мы не можем непосредственно применить t-критерий.
График по умолчанию для этих тестов — диаграмма размаха. Вы можете построить его двумя способами: нажав кнопку Диаграмма размаха в окне Критерий знаков или щелкнув на таблице результатов правой кнопкой мыши и выбрав затем опцию Диаграмма размаха в меню Быстрые статистические графики. Далее программа попросит выбрать переменные. В этом примере выберите обе переменные. Затем выберите тип графика в окне Диаграмма размаха: (см. ниже). Выберите Медиана/кварт./размах и нажмите ОК.
На диаграмме размаха для каждой переменной показаны: медиана, квартальный размах (25%, 75% процентили), размах (минимум, максимум).
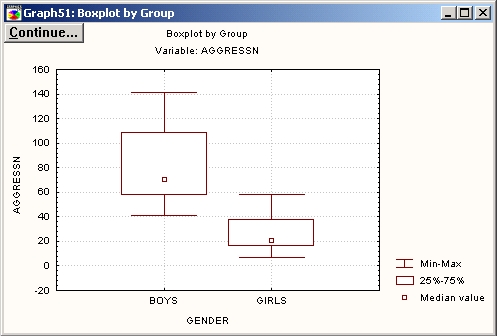
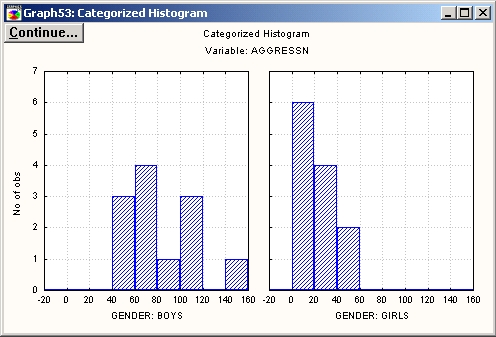
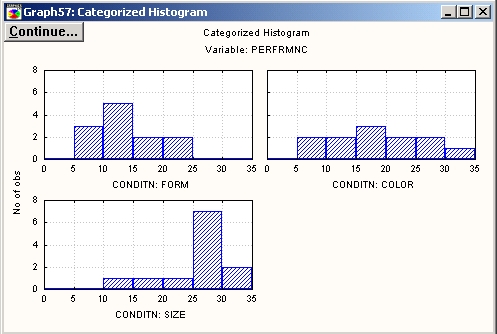
Из графика видно, что мальчики более агрессивны, чем девочки. Для того чтобы увидеть распределение зависимой переменной, разбитой на группы, нажмите кнопку Категоризованная гистограмма.
ANOVA Краскела—Уоллиса и медианный тест
Эти два теста являются непараметрическими альтернативами однофакторного дисперсионного анализа. Мы применяем t-критерий, чтобы сравнить средние значения двух переменных. Если переменных больше двух, то применяется дисперсионный анализ. Английское сокращение дисперсионного анализа — ANOVA (analysis of variation).
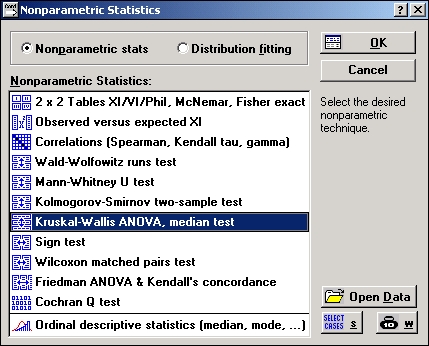
Критерий Краскела—Уоллиса основан на рангах (а не на исходных наблюдениях) и предполагает, что рассматриваемая переменная непрерывна и измерена как минимум в порядковой шкале. Критерий проверяет гипотезу: имеют ли сравниваемые выборки одно и то же распределение или же распределения с одной и той же медианой. Таким образом, интерпретация критерия схожа с интерпретацией параметрической однофакторной ANOVA за исключением того, что этот критерий основан на рангах, а не на средних значениях.
Медианный тест — это «грубая» версия критерия Краскела—Уоллиса. STATISTIC A просто подсчитывает число наблюдений каждой выборки, которые попадают выше или ниже общей медианы выборок, и вычисляет затем значение хи-квадрат для таблицы сопряженности 2× k.
При нулевой гипотезе (все выборки извлечены из популяций с равными медианами) ожидается, что примерно 50% всех наблюдений в каждой выборке попадают выше (или ниже) общей медианы. Медианный тест особенно полезен, когда шкала содержит искусственные границы, и многие наблюдения попадают в ту или иную крайнюю точку (оказываются «вне шкалы»).
Пример основан на данных, представленных в книге Hays (1981) Statistics (3rd ed.) New York: CBS College Publishing, которые содержатся в файле Kruskaista. Откройте файл данных.
Файл содержит результаты исследования маленьких детей, которые случайным образом приписывались к одной из трех экспериментальных групп. Каждому ребенку предлагалась серия парных тестов, например, давались два мяча: красный и зеленый. Далее ребенка просили выбрать зеленый мяч, если он делал правильный выбор, то получал вознаграждение.
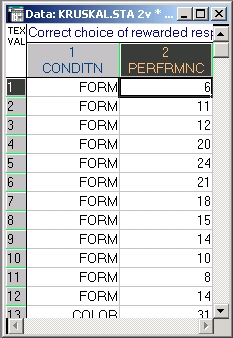
В первой группе тестом была форма (группа 1-Форма — 1-Fonri), во второй — цвет (группа2-Цвет — 2-Соlor), в третьей — размер (3-Размер — 3-Size) предмета.
Зависимая переменная, показанная во втором столбце, — это число испытаний, которые потребовались каждому ребенку, чтобы получить вознаграждение.
Задание анализа. После запуска модуля Непараметрические статистики и распределения и выбора файла KruskaLsta выберите опцию ANOVA Краскела—Уолли-са и медианный тест, чтобы открыть диалоговое окно Дисперсионный анализ Крас-кела—Уоллиса и медианный тест.
Далее нажмите кнопку Переменные и выберите переменную Conditn как независимую и переменную Perfrmnc — как зависимую.
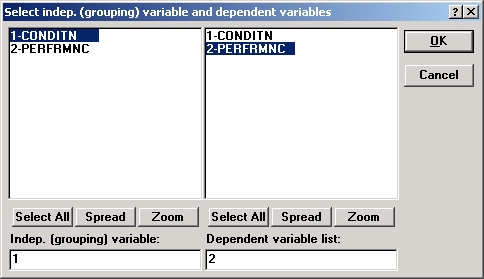
Нажмите кнопку Коды и выберите все коды для независимой переменной (нажмите кнопку Все).
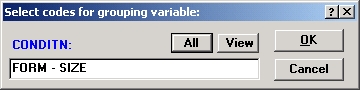
Диалоговое окно Дисперсионный анализ Краскела-Уоллиса и медианный тест появится на экране:
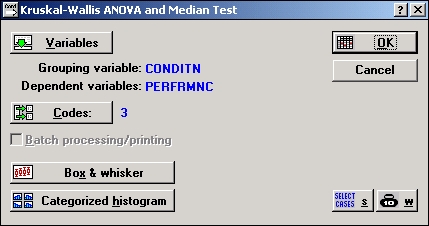
Результаты. В диалоговом окне нажмите ОК для начала анализа. Результаты ранговой ANOVA Краскела—Уоллиса будут показаны в первой таблице результатов, результаты медианного теста — во второй.
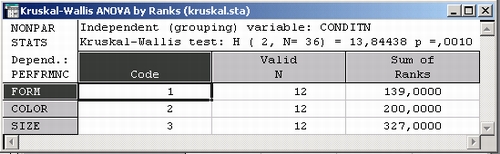
Вы видите, что критерий Краскела—Уоллиса высокозначим (р= 0,001). Таким образом, характеристики различных экспериментальных групп значимо отличаются друг от друга. Напомним, что процедура Краскела—Уоллиса, по существу, является дисперсионным анализом, основанным на рангах. Суммы рангов (для каждой группы) показаны в правом столбце таблицы результатов. Наибольшая ранговая сумма (самое худшее выполнение теста) относится к Размеру — Size (это тот параметр, который надо различить, чтобы получить вознаграждение). Наименьшая ранговая сумма (лучшее выполнение) относится к Форме — Form.
Медианный критерий также значим, однако в меньшей степени (р - 0,0131).
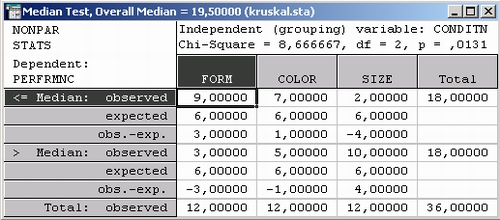
В таблице результатов показано число детей в каждой группе, число попыток которых меньше (или равно) общей медианы, и число наблюдений, лежащих выше общей медианы.
И вновь оказывается, что наибольшее число испытуемых с числом попыток (до получения вознаграждения) выше общей медианы относятся к группе Размер — Size.
Больше всего испытуемых с числом попыток ниже медианы относятся к группе Форма — Form.
Таким образом, медианный тест также подтверждает гипотезу, согласно которой форма предмета наиболее легко различается детьми, тогда как размер различается хуже всего.
Графическое представление результатов. График по умолчанию для этих тестов — диаграмма размаха. Его можно построить двумя способами: нажав кнопку Диаграмма размаха в окне Дисперсионный анализ Краснела—Уоллиса и медианный тест или щелкнув на таблице результатов правой кнопкой мыши и выбрав опцию Диаграмма размаха в меню Быстрые статистические графики. Далее программа попросит выбрать переменные для графика. В этом примере выберите обе переменные. Затем выберите тип статистики для графика в окне Диаграмма размаха: (см. ниже). Выберите опцию Медиана/кварт./размах и нажмите ОК.
На диаграмме размаха для каждой переменной показаны: медиана, квартальный размах (25%, 75% процентили), размах (минимум, максимум).
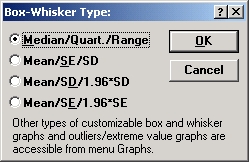
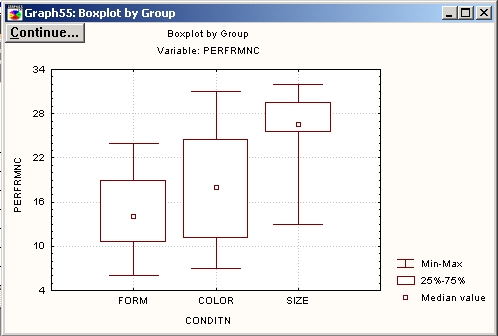
Отчетливо видно, что выполнение теста в группе Форма — Form было лучше любого другого; медиана числа испытаний при этом условии ниже, чем при любом другом.
Для того чтобы увидеть распределение зависимой переменной, разбитой на группы, нажмите кнопку Категоризованная гистограмма. Этот график снова подтверждает, что в группе Форма — Form выполнение «лучше» (распределение слегка скошено влево), чем при других условиях. Самое худшее выполнение, как отчетливо видно из графиков, относится к группе Размер — Size.
Отсюда также можно заключить, что наиболее легко дети различают Форму — Form.
Это непараметрическая альтернатива t-критерию для зависимых выборок.
Критерий применяется в ситуациях, когда исследователь проводит два измерения (например, при разных условиях) одних и тех же субъектов и желает установить наличие или отсутствие различия результатов.
Для применения этого критерия требуются очень слабые предположения (например, однозначная определенность медианы для разности значений). Не нужно никаких предположений о природе или форме распределения.
Критерий основан на интуитивно ясных соображениях. Подсчитаем количество положительных разностей между значениями переменной (А) и значениями переменной (В).
При нулевой гипотезе (отсутствие эффекта обработки) число положительных разностей имеет биномиальное распределение со средним, равным половине объема выборки (положительных разностей будет примерно столько же, сколько отрицательных). Основываясь на биномиальном распределении, можно вычислить критические значения. Для малых объемов выборки n (меньше 20) предпочтительнее использовать значения, табулированные Siegel and Castellan (1988) Nonparametric statistics for the behavioral sciences (2nded.) New York: McGraw-НШ, чтобы оценить статистическую значимость результатов.
Критерий Вилкоксона парных сравнений является непараметрической альтернативой t-критерию для зависимых выборок.
После выбора опции на экране появится диалоговое окно, в котором можно выбрать переменные из двух списков. Каждая переменная первого списка сравнивается с каждой переменной второго списка. Это то же самое расположение данных, что и в f-критерии (зависимые выборки) в модуле Основные статистики и таблицы.
Предполагается, что рассматриваемые переменные ранжированы. W — статистика Вилкоксона равна сумме рангов элементов второй выборки в общем вариационном ряду двух выборок. Итак, наблюдения двух групп объединяются, строится общий вариационный ряд и вычисляется сумма рангов второй группы в построенном ряде.
Требования к критерию Вилкоксона более строгие, чем к критерию знаков. Однако если они удовлетворены, то критерий Вилкоксона имеет большую мощность, чем критерий знаков.
ANOVA Фридмана и коэффициент конкордации, или согласия, Кендалла
ANOVA Фридмана — это непараметрическая альтернатива однофакторному дисперсионному анализу с повторными измерениями. Коэффициент конкордации (согласия) Кендалла — аналог R Спирмена (непараметрический коэффициент корреляции между двумя переменными), когда число переменных больше двух.
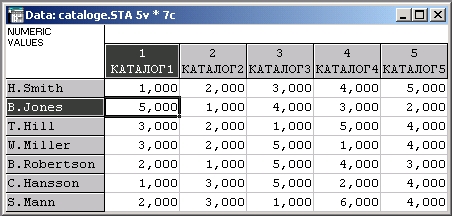
В следующем файле приведены рейтинги, выставленные пятью каталогам программ независимыми экспертами. Экспертов просили учесть: информативность издания, привлекательность, качество рекламы.
Анализ преследовал следующие цели:
1. Определить, можно ли на основании оценок экспертов сделать вывод о значимых различиях между каталогами. Это? вопрос может быть решен с помощью рангового дисперсионного анализа" (ANOVA) Фридмана.
2. Можно ли доверять экспертам? Иными словами, согласованы их оценки или нет (зависимы или нет эксперты)? Если нет, то вы, очевидно, не можете доверять их оценкам. Гипотезу о том, что эксперты согласованы в большей степени, чем можно было бы ожидать из-за чисто случайных совпадений их мнений, можно проверить с помощью коэффициента конкордации Кендалла.
Задание анализа. После запуска модуля Непараметрические статистики и распределения и выбора файла cataloge.sta выберите опцию ANOVA Фридмана и кон-кордация Кендалла.
Теперь нажмите OK, таблица с результатами появится на экране. Можно отметить, что между каталогами имеются высокозначимые различия. Дополнительно также видно, что эксперты, выставившие оценки, согласованы друг с другом — конкордация Кендалла равна 0,57 (среднее ранговых корреляций равно 0,53).
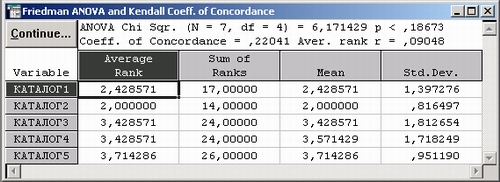
График по умолчанию для этих таблиц результатов — диаграмма размаха. Его можно построить двумя способами: нажав кнопку Диаграмма размаха в окне Ранговый дисперсионный анализ Фридмана или щелкнув на таблице результатов правой кнопкой мыши и выбрав опцию Диаграмма размаха в меню Быстрые статистические графики. Далее программа попросит выбрать переменные для графика. В этом примере выберите все 20 переменных. Затем выберите тип статистики для графика в окне Диаграмма размаха: (см. ниже). Выберите опцию Медиана/кварт./размах и нажмите ОК.
Q-критерий Кохрена — это развитие критерия хи-квадрата Макнемара. Критерий проверяет, значимо или нет различаются между собой несколько сравниваемых переменных, принимающих значения 0-1. После выбора опции Q-критерий Кохрена в стартовой панели программа предложит определить список переменных и коды, идентифицирующие две категории или два уровня факторов.
Реализация критерия в системе STATISTICA предполагает, что переменные закодированы как единицы и нули, и коды, определенные пользователем, соответственно преобразуются в эти значения (только для данного анализа, сам по себе файл не будет изменен).
Выбор этой опции позволяет вычислить разнообразные описательные статистики: медиана, процентили, квартили, размах, квартальный размах, а также среднее, гармоническое среднее, геометрическое среднее, стандартное отклонение, асимметрия, эксцесс, дисперсия, гармоническое среднее, сумма.
Пользователь может также вычислить заданные процентили. Эти опции дополняют опции основных статистик.
Дополнительно стандартные описательные статистики (минимум, Максимум, среднее, число наблюдений), а также описанные ниже статистики вычисляются для каждой переменной.
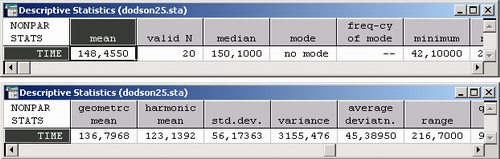
Медиана разбивает выборку на две равные части. Пятьдесят процентов наблюдений лежит ниже медианы, пятьдесят процентов — выше медианы. Если значение медианы существенно отличается от среднего, то распределение скошено (более подробно см. главу Элементарные понятия).
Мода — это максимально часто встречающееся значение в выборке. Частота встречаемости также отображается. Если имеется несколько значений с максимальной частотой, то распределение мулътимодалъно. Если каждое значение встречается лишь одни раз, программа делает запись: моды нет (см. электронную таблицу с результатами).
Геометрическое среднее — это произведение всех значений переменной, возведенное в степень 1/n (единица, деленная на число наблюдений). Геометрическое среднее полезно, например, если шкала измерений нелинейная.
STATISTICA вычисляет геометрическое среднее с помощью логарифмического преобразования: log(геометрическое среднее) = {a[log(xi)]}/n, где xi— i-е значение, n — число наблюдений. Если переменная содержит отрицательные значения или нуль (0), геометрическое среднее вычислить нельзя.
Гармоническое среднее иногда используют для усреднения частот. Гармоническое среднее вычисляется по формуле: ГС = n/S( 1/хi) где ГС — гармоническое среднее, n — число наблюдений, хi — значение наблюдения с номером i. Если переменная содержит нуль (0), гармоническое среднее вычислить нельзя.
Дисперсия и стандартное отклонение
Выборочная дисперсия и стандартное отклонение — наиболее часто используемые меры изменчивости (вариации) данных. Дисперсия вычисляется как сумма квадратов отклонений значений переменной от выборочного среднего, деленная на п-1 (но не на п). Стандартное отклонение вычисляется как корень квадратный из оценки дисперсии.
Размах переменной является показателем изменчивости, вычисляется как максимум минус минимум.
Квартальный размах, по определению, равен: верхняя квартиль минус нижняя квартиль (75% процентиль минус 25% процентиль). Так как 75% процентиль (верхняя квартиль) — это значение, слева от которого находятся 75% наблюдений, а 25% процентиль (нижняя квартиль) — это значение, слева от которого находится 25% наблюдении, то квартильный размах представляет собой интервал вокруг медианы, который содержит 50% наблюдений (значений переменной).
Асимметрия — это характеристика формы распределения. Распределение скошено влево, если значение асимметрии отрицательно. Распределение скошено вправо, если асимметрия положительна. Асимметрия стандартного нормального распределения равна 0. Асимметрия связана с третьим моментом и определяется как: асимметрия
= n × М3/[(n-1) × (n-2) × s3], где М3
равно: 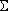 (хi-xсреднееx)3,
s3— стандартное отклонение, возведенное в третью степень,
n — число наблюдений.
(хi-xсреднееx)3,
s3— стандартное отклонение, возведенное в третью степень,
n — число наблюдений.
Эксцесс — это характеристика формы распределения, а именно мера остроты его пика (относительно нормального распределения, эксцесс которого равен 0). Как правило, распределения с более острым пиком, чем у нормального, имеют положительный эксцесс; распределения, пик которых менее острый, чем пик нормального распределения, имеют отрицательный эксцесс. Эксцесс связан с четвертым моментом и определяется формулой:
эксцесс = [n × (n+1) × М4- 3 × М2× М2× (n-1)]/[(n-1)
× (n-2) × (n-3) × s4], где Mj равно:
(х-хсреднееx, s4— стандартное отклонение в четвертой степени,
n — число наблюдений.
|
|
