Анализ данных начинается с группировки и вычисления описательных статистик в группах, например, вычисления средних и стандартных отклонений.
Если у вас имеется две группы данных, то естественно сравнить средние в этих группах. Такого рода задачи во множестве возникают на практике, например, вы можете захотеть сравнить средний доход двух групп людей: имеющих высшее образование и не имеющих высшего образования.
В данной главе мы будем иметь дело с переменными, измеренными в непрерывной шкале, такими переменными являются, например, доход или артериальное давление. Переменные, измеренные в бедных шкалах, исследуются с помощью специальных методов. В частности, категориальные переменные исследуются с помощью таблиц сопряженности (см. главу Анализ и построение таблиц). Переменные, измеренные в порядковых шкалах, исследуются методами непараметрической статистики (см. главу Непараметрическая статистика).
Рассмотрим типичную задачу. Предположим, при производстве бетона вы придумали добавлять в него некоторую новую компоненту и полагаете, что она увеличит прочность бетона. Чтобы проверить свои предположения и доказать их потребителю, вы взяли несколько образцов бетона с добавкой и несколько образцов без добавки и измерили прочность каждого образца.
Таким образом, получили два столбца (две группы) цифр: прочность образцов с добавкой и прочность образцов без добавки. Как разумно сравнить эти группы?
Очевидный подход состоит в том, чтобы сравнить описательные статистики, например, средние двух групп. Конечно, можно было бы сравнивать медианы или другие описательные статистики, но естественно начать со сравнения средних значений. Итак, вы имеете два средних: среднее для первой группы и среднее для второй группы.
Можно формально вычесть одно среднее из другого и по величине разности сделать вывод о наличии эффекта. Однако целесообразно принять во внимание разброс данных относительно средних, то есть вариацию (см. главу Элементарные понятия). Очевидно, разумная процедура должна принимать во внимание вариацию. Первое, что приходит в голову, — подходящим образом нормировать разность средних двух выборок (групп данных), поделив ее, например, на стандартное отклонение (корень квадратный из вариации).
Именно так и рассуждал В. Госсет — английский статистик, известный под псевдонимом Стьюдент, придумавший t-критерий для сравнения средних двух выборок.
Допустим, мы проверяем гипотезу о том, что добавка неэффективна (или как говорят на сленге анализа данных: нет эффекта обработки), иными словами, средние в двух группах равны. Этому положению соответствует альтернатива, согласно которой имеется эффект — прочность бетона увеличивается при добавлении в него новой компоненты.
Обратим внимание, альтернатива может быть выражена и по-другому, например, средние не равны или средняя прочность образцов увеличилось (добавка привела к увеличению прочности бетона).
Заметим далее, что возможны два варианта организации данных: вы можете иметь дело с независимыми группами наблюдений или с зависимыми группами наблюдений.
Если вы случайным образом разбили выборку на две части и сравниваете показатели в первой и второй группе, то, скорее всего, вы имеете дело с независимыми группами.
В STATISTICA t-критерий доступен в обоих вариантах организации данных.
Естественным развитием сюжета сравнения средних является обобщение t-критерия на три и более групп данных, что приводит к дисперсионному анализу (в английской терминологии ANOVA — сокращение от Analysis of Variation — Дисперсионный анализ), а также на многомерный отклик. Если мы имеем дело с многомерным откликом, то используем методы MANOVA. Итак, методы дисперсионного анализа позволяют разумным образом сравнить групповые средние, если количество групп больше двух. Например, если вы хотите сравнить доход жителей нескольких регионов, то можно использовать дисперсионный анализ. Если вы исследуете два региона, то применяйте t-критерий.
Опишем один случай, не укладывающийся в общую схему. Представьте, вы изучаете категориальную переменную, принимающую два значения 0 и 1, и хотите сравнить различие частот появления единиц в двух группах. Например, вы желаете сравнить относительное число голосов, поданных за кандидата в двух избирательных округах. Термин относительное число означает число голосов, поданных за кандидата, деленное на общее число голосовавших. Статистический критерий для сравнения частот (долей, пропорций...) реализован в модуле Основные статистики и таблицы в диалоге Другие критерии значимости.
Т-критерий для независимых выборок
t-критерий является наиболее часто используемым методом, позволяющим выявить различие между средними двух выборок. Еще раз напомним, переменные должны быть измерены в достаточно богатой шкале, например, количественной.
Конечно, применение t-критерия имеет некоторые ограничения, впрочем, очень слабые.
Теоретически t-критерий может применяться, даже если размер выборки очень небольшой (например, 10; некоторые исследователи утверждают, что можно исследовать и меньшие выборки) и если переменные нормально распределены (внутри групп), а дисперсии наблюдений в группах не слишком различны. Известно, что t-критерий устойчив к отклонениям от нормальности.
Предположение о нормальности можно проверить, исследуя распределение (например, визуально с помощью гистограмм) или применяя критерий нормальности. Следует заметить, что эффективно проверить гипотезу о нормальности можно для достаточно большого объема данных (см. замечание Фишера о проверке нормальности, цитированное нами в главе Элементарные понятия анализа данных).
Более осторожно нужно подходить к различию дисперсий сравниваемых групп. Равенство дисперсий в двух группах, а это одно из предположений F-критерия, можно проверить с помощью F-критерия (который включен в таблицу вывода t-критерия в STATISTICA). Также можно воспользоваться более устойчивым критерием Левена.
При сравнении средних, как и всегда в анализе данных, чрезвычайно полезны визуальные методы. Например, на приведенной ниже категоризованной диаграмме размаха видно существенное различие средних значений для мужчин и женщин. На диаграмме точками показаны средние значения, а также стандартные отклонения (прямоугольники) и стандартные ошибки (отрезки прямых линий), вычисленные отдельно для мужчин и женщин.
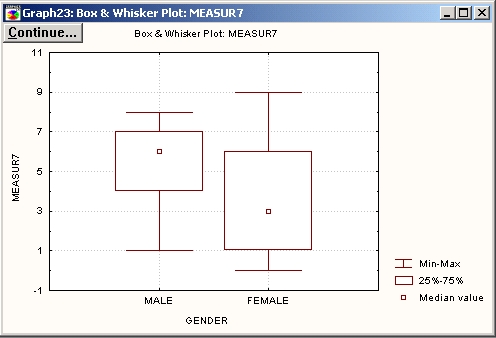
На графике заметно различие дисперсий в группах — высота прямоугольника FEMALE больше высоты прямоугольника MALE.
Если условия применимости t-критерия не выполнены, то можно оценить различие между двумя группами данных, с помощью подходящей непараметрической альтернативы ^-критерию (см. главу Непараметрическая статистика, где обсуждается вопрос применения альтернативных процедур,).
Р-уровень значимости f-критерия равен вероятности ошибочно отвергнуть гипотезу об отсутствии различия между средними выборок, когда она верна (то есть когда средние в действительности равны).
Некоторые исследователи предлагают в случае, когда рассматриваются отличия только в одном направлении (например, переменная X больше (меньше) в первой группе, чем во второй), рассматривать одностороннее t-распределение и делить полученный для двухстороннего t-критерия р-уровень пополам. Другие предлагают всегда работать со стандартным двухсторонним t-критерием.
Чтобы применить t-критерий для независимых выборок, требуется, по крайней мере, одна независимая (группирующая) переменная и одна зависимая переменная (например, тестовое значение некоторого показателя, которое сравнивается в двух группах).
Вначале с помощью значений группирующей переменной, например, мужчина и женщина, если группирующей переменной является Пол, или Имеет высшее образование и Не имеет высшего образования, если группирующей переменной является Образование, данные разбиваются на две группы. Далее в каждой группе вычисляется среднее значение зависимой переменной, например, артериальное давление или доход. Эти выборочные средние сравниваются между собой.
Конечно, при применении t-критерия, как и при применении любого другого критерия в анализе данных, нужно сохранять здравый смысл. Применение t-критерия мало оправданно, если значения двух переменных несопоставимы. Например, если вы сравниваете среднее значение некоторого показателя в выборке пациентов до и после лечения, но используете различные методы вычисления
количественного показателя или другие единицы во втором измерении, то высокозначимые значения t-критерия могут быть получены искусственно, за счет изменения единиц измерения. Аналогично, не имеет смысла сравнивать доходы, выраженные в рублях, при многократной девальвации или высокой инфляции.
В следующем разделе даются формулы вычисления статистики критерия Стьюдента для проверки равенства средних двух выборок. Если вас интересует только практическое применение, вы можете пропустить этот раздел.
Формальное определение t-критерия
Формально в случае двух групп (k = 2) статистика t-критерия имеет вид:
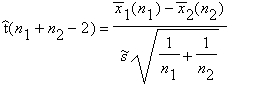
где х¯1(n1)м x¯2(n2) — выборочные средние первой и второй выборки, s~2—оценка дисперсии, составленная из оценок дисперсий для каждой группы данных:

Если гипотеза: «средние в двух группах равны» — верна, то статистика t^(n1 +n2 -2) имеет распределение Стьюдента с (n1 +n2 -2) степенями свободы (см. например, справочное издание Айвазян С. А., Енюков И. С., Мешалкин Л. Д., Прикладная статистика., М.: Финансы и статистика, 1983. С. 395—397).
Большие по абсолютной величине значения статистики t^(n1 + n2 - 2) свидетельствуют против гипотезы о равенстве средних значений.
С помощью вероятностного калькулятора STATISTICA найдем 100a/2%-ю точку распределения Стьюдента с (n1 + n2 - 2) степенями свободы.
Обозначим найденную точку через ×
Если | t^(n1 +n2 -2)| > t(a /2), то гипотеза отвергается.
Заметим, что большие абсолютные значения статистики Стьюдента t^(n1 +n2 -2)могут возникнуть как из-за значимого различия средних, так и из-за значимого различия дисперсий сравниваемых групп.
Статистический критерий равенства или однородности дисперсии двух нормальных выборок основан на статистике:
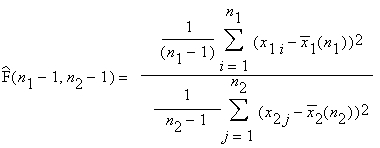
которая при гипотезе: «дисперсии в двух группах равны» имеет распределение F(n1-1,n2-1).
Зададимся уровнем значимости a.
С помощью вероятностного калькулятора вычислим 100(1 — a/2)% и 100(a/2)% точки распределения F(n1 -1, n2 -1).
Если F1-a/2 (n1 -1, n2 -1) < F(n1 -1, n2 -1) < Fa/2 (n1 -1, n2 -1), то гипотеза об однородности дисперсии не отвергается.
Т-критерий для зависимых выборок
Степень различия между средними в двух группах зависит от внутригрупповой вариации (дисперсии) переменных.
В зависимости от того, насколько различны эти значения для каждой группы, «грубая разность» между групповыми средними показывает более сильную или более слабую степень зависимости между независимой (группирующей) и зависимой переменными.
Например, если при исследовании среднее значение WCC (число лейкоцитов) равнялось 102 для мужчин и 104 для женщин, то разность только на величину 2 между внутригрупповыми средними будет чрезвычайно важной в том случае, если все значения WCC мужчин лежат в интервале от 101 до 103, а все значения WCC женщин — в интервале 103-105. Тогда можно довольно хорошо предсказать WCC (значение зависимой переменной) исходя из пола субъекта (независимой переменной). Однако если та же разность 2 получена из сильно разбросанных данных (например, изменяющихся в пределах от 0 до 200), то разностью вполне можно пренебречь.
Таким образом, понятно, что уменьшение внутригрупповой вариации увеличивает чувствительность критерия.
Т-критерий для зависимых выборок дает преимущество в том случае, когда важный источник внутригрупповой вариации (или ошибки) может быть легко определен и исключен из анализа. В частности, это относится к экспериментам, в которых две сравниваемые группы наблюдений основываются на одной и той же выборке наблюдений (субъектов), которые тестировались дважды (например, пациенты до и после лечения).
В таких экспериментах значительная часть внутригрупповой изменчивости (вариации) в обеих группах может быть объяснена индивидуальными различиями субъектов. Заметим, что на самом деле такая ситуация не слишком отличается от той, когда сравниваемые группы совершенно независимы (см. t-критерий для независимых выборок), где индивидуальные отличия также вносят вклад в дисперсию ошибки. Однако в случае независимых выборок вы ничего не сможете поделать с этим, т. к. не сможете определить (или «удалить») часть вариации, связанную с индивидуальными различиями субъектов. Если та же самая выборка тестируется дважды, то можно легко исключить эту часть вариации.
Вместо исследования каждой группы отдельно и анализа исходных значений можно рассматривать просто разности между двумя измерениями (например, «до теста» и «после теста») для каждого субъекта. Вычитая первые значения из вторых (для каждого субъекта) и анализируя затем только эти «чистые (парные) разности», вы исключите ту часть вариации, которая является результатом различия в исходных уровнях индивидуумов.
В сравнении с t-критерием для независимых выборок, такой подход дает всегда «лучший» результат, так как критерий становится более чувствительным.
Теоретические предположения ^-критерия для независимых выборок также применимы к критерию зависимых выборок. Это означает, что парные разности должны быть нормально распределены. Если это не выполняется, то можно воспользоваться одним из альтернативных непараметрических критериев (см. главу Непараметрическая статистика).
В системе STATISTICA ^-критерий для зависимых выборок может быть вычислен для списков переменных и просмотрен далее как матрица. Пропущенные данные при этом обрабатываются либо попарным, либо построчным способом.
При этом возможно возникновение «чисто случайно» значимых результатов. Если вы имеете много независимых экспериментов, то «чисто случайно» можете найти один или несколько экспериментов, результаты которых значимы.
Как уже говорилось, сравнение средних в более чем двух группах проводится с помощью дисперсионного анализа (английское сокращение — ANOVA).
Если имеется более двух «зависимых выборок» (например, до лечения, после лечения-1 и послелечения-2), то можно использовать дисперсионный анализ с повторными измерениями. Повторные измерения в дисперсионном анализе можно рассматривать как обобщение f-критерия для зависимых выборок, позволяющее увеличить чувствительность анализа.
Например, дисперсионный анализ позволяет одновременно контролировать не только базовый уровень зависимой переменной, но и другие факторы и включать в план эксперимента более одной зависимой переменной.
Интересен следующий прием объединения результатов нескольких t-критери-ев. Этот прием можно использовать также для объединения результатов других критериев (см.: Справочник по прикладной статистике/Под редакцией Э. Ллойда и У. Ледермана, т. 1. М.: Финансы и статистика, 1989. С. 274). Для нас этот пример также интересен тем, что мы можем продемонстрировать новые возможности STATISTICA.
Предположим, используя независимые эксперименты, вы получили уровни значимости а(1), а(2) ... а(m). Предположим, эти уровни недостаточно убедительны. Если уровни значимости неубедительны, то, возможно, имеет смысл объединить данные и рассмотреть их как результат одного целого эксперимента.
При нулевой гипотезе уровни значимости, рассматриваемые как случайные величины, имеют равномерное распределение. Следовательно, величина
L = -2× (Ln(a(l)) + Ln(a(2)) + ... + Ln(a(m))
имеет хи-квадрат распределение с числом степеней свободы 2m.
Например, если в испытаниях на прочность бетона были получены недостаточно убедительные уровни 0,047, 0,054, 0,042, то уровень значимости объединенного эксперимента равен 0,005547 и гипотеза о неэффективности добавки явно отвергается.
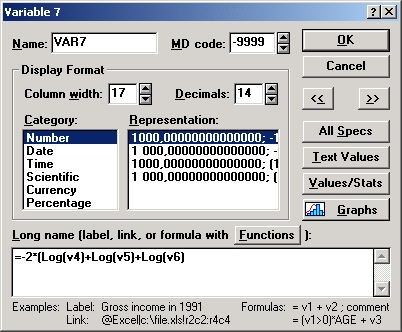
Для того чтобы понять это, воспользуемся средствами системы STATISTICA. Сначала вычислим величину L, например, задав формулу в электронной таблице.
Создайте файл и в первой строке введите запись:

Переменная var7 содержит значение L, вычисленное по формуле.
Затем откройте вероятностный калькулятор системы STATISTICA, выберите в нем распределение хи-квадрат, введите число степеней свободы б, а в поле хи-квадрат введите величину 18,29.
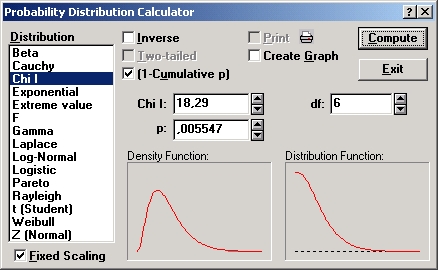
В результате в поле р мы получили 0,005547.
Таким образом, получен объединенный уровень значимости трех t-критериев (сравните с результатами, приведенными в Справочнике по прикладной статистике, под редакцией Э. Ллойда и У. Ледермана, т. 1. М.: Финансы и статистика, 1989. С. 275). Это явно высокий уровень значимости, поэтому нулевая гипотеза отвергается.
Здесь мы будем работать с файлом intemet2000.sta. Можно также использовать файл ad.study.sta из папки Examples.
В файле intemet2000.sta собраны результаты опроса нескольких пользователей относительно их восприятия сайтов ENNUI и POURRITURE.
Такого рода данные несложно получить с помощью Интернет. Вы можете, например, вывесить на сайт анкету, которая будет заполняться посетителями.
В этом модельном примере пользователи оценивали сайты в разных шкалах (полнота, технологичность решения, информативность, дизайн и др.) В каждой из шкал респонденты давали оценку сайту по десятибалльной шкале, от 0 до 9 баллов.
Интересен вопрос: различается восприятие сайтов мужчинами и женщинами?
Мужчины могут в некоторых шкалах давать более высокие или низкие оценки по сравнению с женщинами.
Для решения этой задачи можно использовать t-критерий для независимых выборок. Группирующая переменная пол разбивает данные на две группы. Выборки мужчин и женщин будут сравнены относительно среднего их оценок по каждой шкале. Вернитесь к стартовой панели Основные статистики и таблицы и щелкните на процедуре t-критерий для независимых выборок, чтобы открыть диалоговое окно Т-критерий для независимых выборок (групп).
Щелкните по кнопке Переменные, чтобы открыть стандартное диалоговое окно для выбора переменных. Здесь вы можете выбрать и независимые (группирующие), и зависимые переменные.
Для нашего примера выберите переменную GENDER как независимую переменную и переменные от 3 до 25 (содержащие ответы) в качестве зависимых переменных.
Щелкните ОК в этом диалоговом окне, чтобы вернуться в диалоговое окно Т-критерий для независимых выборок (групп), где отобразится ваш выбор.
Из диалогового окна Т-критерий для независимых выборок (групп) доступно также много других процедур.
Щелкните ОК для вывода таблицы результатов.
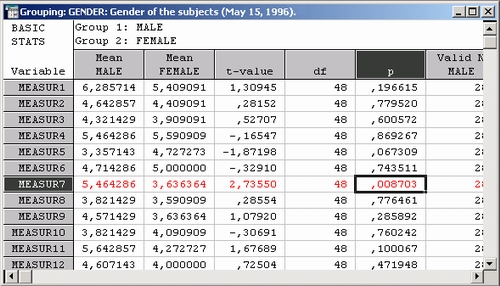
Самым быстрым способом изучения таблицы является просмотр пятого столбца (со держащего р-уровни) и определение того, какие из р-значений меньше установленного уровня значимости 0,05.
Для большинства зависимых переменных средние по двум группам (МУЖЧИНЫ - MALES и ЖЕНЩИНЫ - FEMALES) очень близки.
Единственная переменная, для которой f-критерий соответствует установленному уровню значимости 0,05, — это Measur 7, для нее р-уровенъ равен 0,0087. Как показывают столбцы, содержащие средние значения (см. две первые колонки), для мужчин эта переменная принимает в среднем существенно большие значения — в выбранной шкале измерений для мужчин она равна 5,46, а для женщин — 3,63. При этом нельзя исключить вероятность того, что пол ученная разница на самом деле отсутствует и получилась лишь в результате случайного совпадения (см. ниже), хотя это выглядит маловероятным.
Графиком по умолчанию для этих таблиц результатов является диаграмма размаха. Для построения этой диаграммы щелкните правой кнопкой мыши в любом месте строки, соответствующей зависимой переменной (например, на среднем для Measur 7).
В открывшемся контекстном меню выберите построение графика Диаграмма размаха из подменю Быстрые статистические графики. Далее выберите опцию Среднее/ст.ош./ст.откл. окна. Диаграмма размаха и нажмите OK для построения графика.
Разность средних на графике выглядит более значительной и не может быть объяснена только на основании изменчивости исходных данных.
Однако на графике заметно еще одно неожиданное отличие. Дисперсия для группы женщин намного больше дисперсии для группы мужчин (посмотрите на прямоугольники, которые изображают стандартные отклонения, равные корню квадратному из вариации).
Если дисперсии в двух группах существенно отличаются, то нарушается одно из требований для использования г-критерия, и разность средних должна рассматриваться особенно внимательно.
Кроме того, дисперсия обычно коррелирована со средним значением, то есть чем больше среднее, тем больше дисперсия.
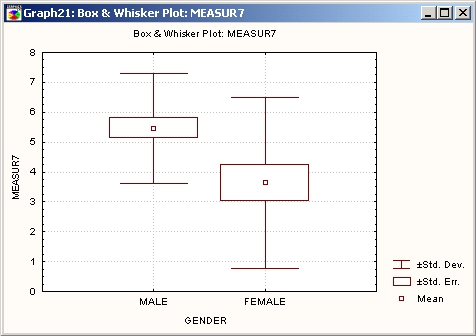
Однако в данном случае наблюдается нечто противоположное. В такой ситуации опытный исследователь предположил бы, что распределение переменной Measur 7, возможно, не является нормальным (для мужчин, женщин или для тех и других).
Поэтому рассмотрим критерий разности дисперсий для того, чтобы проверить, является ли наблюдаемое на графике отличие действительно заслуживающим внимания.
Вернемся к таблице результатов и прокрутим ее вправо, увидим результаты F-критерия. Значение F-критерия действительно соответствует указанному уровню значимости 0,05, что означает существенную разность дисперсий переменной Measur 7 в группах МУЖЧИНЫ - MALES и ЖЕНЩИНЫ - FEMALES.
Однако значимость наблюдаемой разности дисперсий близка к граничному уровню значимости (ее р-уровенъ равен 0,029).
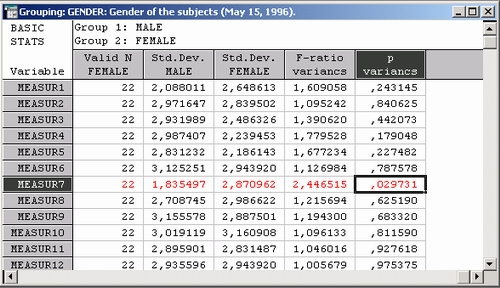
Большинство исследователей посчитало бы один этот факт недостаточным для признания недействительным t-критерия разности средних, дающего высокий уровень значимости для этой разности (р - 0,0087).
При проведении сравнений средних в трех и более группах можно использовать процедуры множественных сравнений. Сам термин множественные сравнения означает просто многократные сравнения.
Проблема состоит в следующем: мы имеем n > 2 независимых групп данных и хотим разумным образом сравнить их средние. Предположим, мы применили F-критерий и отклонили гипотезу: «средние всех групп равны». Наше естественное желание — найти однородные группы, средние которых равны между собой.
Конечно, мы можем сравнить группы с помощью t-критерия и найти путем многократных сравнений однородные группы. Но, оказывается, трудно вычислить ошибку выполненной процедуры или, как говорят, составного критерия, отправляясь от заданного уровня значимости каждого t-критерия.
Тонкость состоит в том, что сравнивая с помощью t-критерия много групп, вы чисто случайно можете обнаружить эффект. Представьте, что в 1000 клиник вы провели испытание нового лекарства, сравнивая в каждой клинике группу больных, принимающих препарат, с группой больных, принимающих плацебо. Конечно, чисто случайно может найтись клиника, где вы найдете эффект. Однако с высокой степенью вероятности, это может быть арт-эффект.
Чтобы обезопасить себя от подобного рода случайностей, используются специальные критерии для множественных или многократных сравнений.
В системе STATISTICA процедуры множественного сравнения реализованы в модуле Основные статистики и таблицы в диалоге Апостериорные сравнения средних.

Описание процедур множественного сравнения можно найти, например, в книге: Кендаял М. Дж. и Стьюарт А. Статистические выводы и связи. М.: Наука, 1973. С. 71—79.
Заметим, что самые общие методы сравнения нескольких групп реализованы в модуле Общий дисперсионный анализ.
Однофакторный дисперсионный анализ можно провести в модуле Основные статистики и таблицы.
Однофакторный дисперсионный анализ и апостериорные сравнения средних
Итак, если вы хотите продвинуться в исследовании различий нескольких групп, то дальнейший анализ следует вести в диалоге группировка и однофакторный дисперсионный анализ (ANOVA). Мы работаем с данными, которые находятся в файле adstudy.sta (папка Examples).
Сделайте вслед за нами следующие установки.
Вначале стандартным образом выберите группирующие и зависимые переменные в файле данных.
Затем выберите коды для группирующих переменных. С помощью этих кодов наблюдения в файле разбиваются на несколько групп, сравнение которых мы будем проводить.
После того как выбраны переменные для анализа и определены коды группирующих переменных, нажмите кнопку ОК и запустите вычислительную процедуру.
В появившемся окне вы можете всесторонне просмотреть результаты анализа.
Посмотрите внимательно на диалоговое окно. Результаты можно отобразить в виде таблиц и графиков. Например, можно проверить значимость различий в средних с помощью процедуры Дисперсионный анализ.
Щелкните на кнопке Дисперсионный анализ, и вы увидите результаты однофакторного дисперсионного анализа для каждой зависимой переменной.
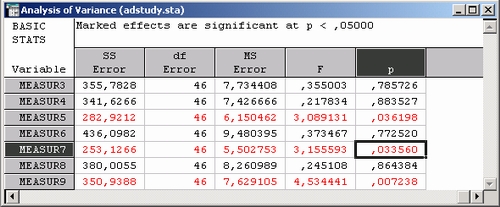
Заметьте, что в таблице дисперсионного анализа мы имеем уже дело с F-критперием.
Как следует из результатов, для переменных Measur 5, Measur 7 и Measur 9 процедура однофакторного Дисперсионного анализа дала статистически значимые результаты на уровне р<0,05.
Эти результаты показывают, что различие средних значимо. Итак, с помощью F-критерия (этот критерий обобщает t-критерий на число групп больше двух) мы отвергаем гипотезу об однородности сравниваемых групп.
Возвратитесь в диалоговое окно результатов и нажмите кнопку Апостериорные сравнения средних для того, чтобы оценить значимость различий между средними конкретных групп. Прежде всего нужно выбрать зависимую переменную. В данном примере выберем переменную Measur 7.
После того как вы нажмете ОК в окне выбора переменной, на экране появится диалоговое окно Апостериорные сравнения средних.

В этом окне можно выбрать несколько апостериорных критериев.
Выберем, например, Критерий наименьшей значимой разности (НЗР).
Критерий НЗР эквивалентен t-критерию для независимых выборок, основанному на N сравниваемых группах.
t-критерий для независимых выборок показывает (проверьте на STATISTIC А!), что имеется значимое различие между ответами МУЖЧИН — MALES и ответами ЖЕНЩИН — FEMALES для переменной Measur 7.
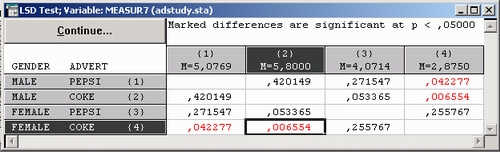
Используя процедуру Группировка и однофакторная ANOVA, мы видим (см. таблицу результатов), что значимое различие средних имеется только для лиц, выбравших СОКЕ.
Графическое представление результатов. Различия средних можно увидеть на графиках, доступных в диалоговом окне Внутригрупповые описательные статистики и корреляции — Результаты.
Например, для того чтобы сравнить распределения выбранных переменных внутри групп, щелкните по кнопке Категоризованные диаграммы размаха и выберите опцию Медиана/кварт./размах из диалогового окна Диаграмма размаха.
После того как вы нажмете OK, STATISTICA построит каскад диаграмм размаха.
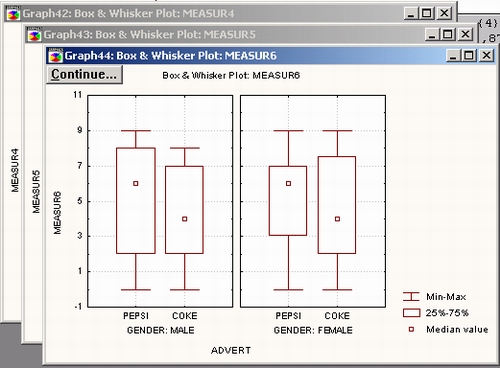
Из графика видно, -что между группой FEMALE — СОКЕ и группой MALE — СОКЕ имеется явное различие.
Такого рода анализ с последовательно усложняющейся группировкой и сравнением средних в получающихся группах, особенно часто применяемый в массовых обследованиях, может быть с успехом выполнен в STATISTICA.
|
|
