Дескриптивные, или описательные, статистики рассматривались в главе Элементарные понятия анализа данных. Здесь мы покажем, как вычисляются дескриптивные статистики, и уделим особое внимание описательным статистикам для группированных данных.
Дескриптивные статистики очень важны. Представьте, вы издаете журнал и вам нужно описать читательскую аудиторию. Вы проводите анкетирование читателей и просите их указать: пол, возраст, уровень образования, доход и другие параметры. Затем вы вычисляете описательные статистки и находите, что основную аудиторию составляют мужчины в возрасте от 32 до 47 лет, имеющие доход свыше а долларов, образование высшее, женщины от 27 до 35 лет, имеющие доход свыше b долларов, образование среднее и т. д. Разнообразные графики помогают вам визуально представить результаты, которые являются основой для проведения издательской политики.
Заметим, что различные способы построения таблиц, описанные в главе 11, также чрезвычайно полезны для анализа подобных данных.
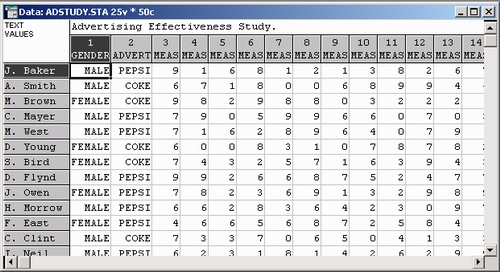
Мы будем работать с файлом Adstudy.sta, который находится в папке Examples и поставляется вместе с системой STATISTIC А. Этот файл выбран специально для того, чтобы вы могли повторить наши действия и далее самостоятельно проводили описательный анализ собственных данных.
Файл Adstudysta содержит 25 переменных и 50 наблюдений. Эти данные были собраны путем социологического опроса в одном рекламном исследовании, где мужчины и женщины оценивали качество двух рекламных роликов.
Каждому респонденту случайным образом предлагался на просмотр один из двух рекламных роликов (ADVERT: 1 = CokeВ,2 = PepsiВ). Затем респонденты оценивали привлекательность рекламы по 23 различным шкалам (с Меры 1 — Measur 1 до Меры 23 — Measur 23).
В каждой из шкал респонденты могли дать ответы по десятибалльной шкале, то есть выставить от 0 до 9 баллов. Пол респондента кодировался: 1 — МУЖЧИНА, 2 - ЖЕНЩИНА.
Нажмите кнопку Описательные статистики. Далее нажмите кнопку Переменные и выберите переменные для анализа.
В данном случае выберите все переменные. После нажатия ОК в окне выбора переменных диалоговое окно Описательные статистики будет выглядеть следующим образом:
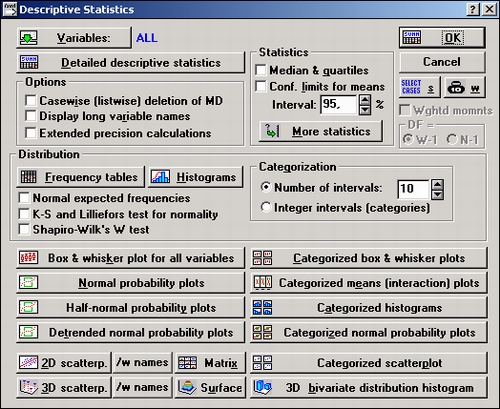
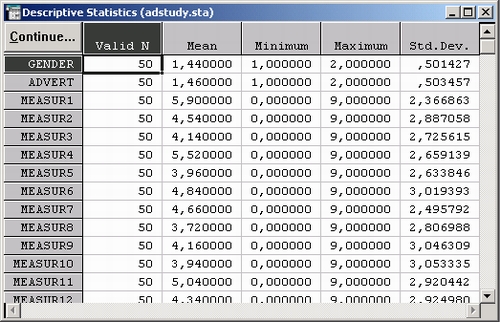
По умолчанию таблицы результатов окна Описательные статистики содержат средние значения, число наблюдений без пропусков N, стандартные отклонения, а также минимальные и максимальные значения для выбранных переменных.
С помощью кнопки У задаются условия выбора наблюдений.
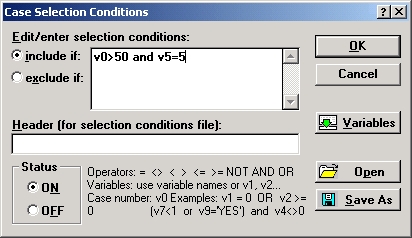
В окне условия выбора наблюдений можно задать правила выбора наблюдений из файла данных. Таким образом, будут анализироваться не все наблюдения, а только те, которые удовлетворяют заданным условиям.
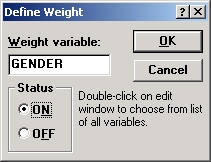
Кнопка В позволяет ввести веса, таким образом могут быть введены, например, группированные данные (см. пункт Как проверить нормальность наблюдаемых величин в главе Элементарные понятия анализа).
Нажмите кнопку Другие статистики, чтобы открыть окно Статистики, в котором можно выбрать различные описательные статистики.
Вы можете выбрать любой набор статистик из предложенного списка. В нашем примере оставьте выбор статистик, сделанный по умолчанию, и нажмите кнопку Подробные описательные статистики для построения таблицы результатов.
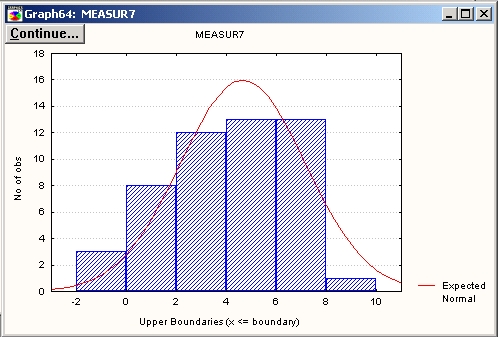
Графиком по умолчанию для этой таблицы результатов является гистограмма с наложенной на нее нормальной кривой.
Этот график обычно используется для того, чтобы представить, как распределены значения переменной, а также для визуальной проверки нормальности исходных данных (подробно гистограммы описаны в разделах книги по визуальные методам анализа данных).
Для построения графика щелкните правой кнопкой мыши в любом месте таблицы результатов (например, на среднем значении переменной Measur 7) и в появившемся контекстном меню выберите построение графика Гистограмма/нормалън из меню Быстрые статистические графики.
Такая же гистограмма может быть построена после нажатия кнопки Гистограммы в разделе Распределение окна Описательные статистики. Этот раздел также позволяет анализировать распределение частот для каждой выбранной переменной (при этом происходит построение по одной таблице результатов или гистограмме на каждую переменную). В этом окне возможно также вычисление некоторых специальных критериев нормальности и использование настроек категоризации изучаемых данных.
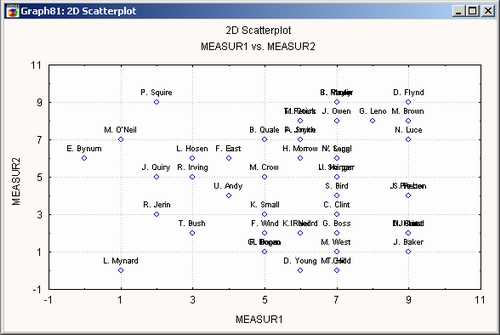
Окно Описательные статистики предлагает большое количество графических процедур для проведения визуального анализа распределений переменных и корреляций между ними. Например, нажмите кнопку 2М рассеяния (с именами), чтобы получить наглядное представление о характере зависимости между двумя переменными.
При использовании опции с именами программа располагает на диаграмме имена наблюдений рядом с соответствующими им точками. Вы можете построить матрицу диаграмм рассеяния, нажав кнопку Матричный.
Кнопка Поверхность предназначена для построения поверхности в пространстве (по умолчанию второго порядка), приближающей значения выбранных переменных.
Также возможно построение категоризованных диаграмм размаха, гистограмм, диаграмм рассеяния и вероятностных графиков.
Наконец, есть возможность построить ЗМ гистограммы двух переменных для изучения двухмерного распределения выбранных переменных.
Этот график обычно используется для описательных целей, а также при проведении разведочного анализа данных; однако иногда он может быть полезен при проверке нормальности двухмерного распределения.
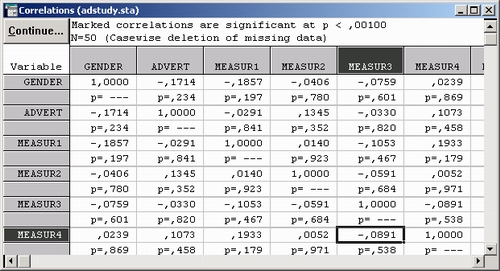
Корреляции измеряют степень зависимости между переменными. В файле данных имеем несколько шкал (переменные Measur 1 — Measur23).
Вначале проверим, не коррелируют ли между собой оценки в различных шкалах, другими словами, не измеряют ли некоторые шкалы, по сути, одни и те же свойства объекта. Если окажется, что некоторые шкалы зависимы, мы просто сократим анкету, выбросив из нее лишние пункты.
Вначале вычислим корреляции по всем наблюдениям, далее рассмотрим внутригрупповые корреляции, то есть корреляции внутри групп. Вообще, вычисление корреляций наряду с группировкой и построением таблиц — стандартный первый шаг всякого исследования, связанного с анализом данных.
В стартовой панели Основные статистики и таблицы выберите процедуру Корреляционные матрицы и щелкните ОК (или можете просто дважды щелкнуть на процедуре Корреляционные матрицы).
После выбора этой процедуры откроется диалоговое окно Корреляции Пирсона.
Вы можете выбрать переменные как из одного списка (то есть матрица будет квадратной), так и из двух списков (прямоугольная матрица).
В данном примере для простоты выберем все переменные для анализа. Однако следует помнить, что корреляции Пирсона больше подходят для переменных, измеренных в количественных шкалах.
Для номинальных переменных, таких как GENDER, ADVERT, применяются другие методы исследования зависимости (см. главу Построение и анализ таблиц).
Итак, хотя формально корреляции вычисляются для всех переменных, мы сосредоточим свое внимание на корреляциях между Measur 1 — Measur 23.
Нажмите ОК, чтобы вернуться в диалоговое окно Корреляции Пирсона.
Вы можете указать уровень значимости (альфа ~ 0,05 по умолчанию) для выделения значимых коэффициентов корреляции в таблице результатов .
Чтобы изменить уровень альфа, щелкиите по кнопке Параметры на панели инструментов таблицы результатов и откройте диалоговое окно Уровень значимости. Введите в это окно уровень значимости 0,001 и щелкните OK.

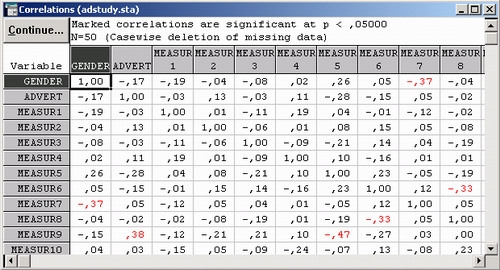
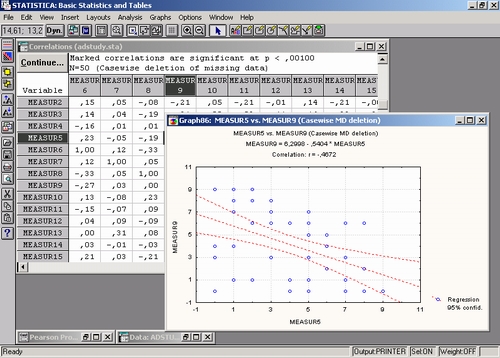
Легко обнаружить высокие корреляции (например, корреляция между Мерой 5 — Measur 5 и Мерой 9 — Measur 9 равна — 0,47).
Такая высокая отрицательная корреляция показывает, что две шкалы оценок могут измерять одну и ту же характеристику зрительного восприятия рекламы (хотя одна мера этой характеристики возрастающая, а другая — убывающая).
Две опции из диалогового окна Корреляции Пирсона позволяют получить таблицу данных с коэффициентами корреляции, а также более подробными статистиками (например, р-значение, число пар N, r2-коэффициент детерминации, t-зна-чения и т. д.).
Когда вы выберете установку Корр. матрицу (отображать р и N), вместе с коэффициентами корреляции будут также выведены р-значения и число пар N наблюдений, по которым они вычислены. Данная опция полезна, если в данных есть пропуски и нужно точно знать объем выборки.
Выбор опции
Подробную таблицу результатов в диалоговом окне Корреляции Пирсона возможен только при выборе 20 или меньше переменных для анализа, так как для каждой корреляции автоматически будет выводиться большое количество информации. После выбора этой опции будет построена таблица результатов, содержащая соответствующие описательные статистики, коэффициенты корреляции, р-значения и число пар N, а также наклон и отрезок регрессии для каждой переменной.
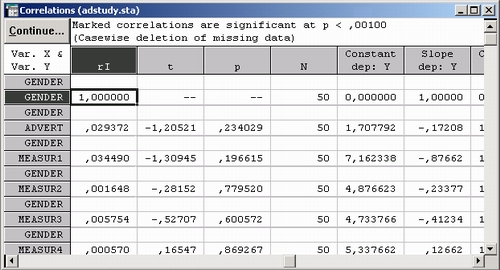
Эту опцию следует использовать только для отдельных корреляций (но не для подробного анализа), потому что в этом формате для каждого коэффициента корреляции будут заняты 22 ячейки таблицы результатов; таким образом, для матрицы корреляций 20x20 получится таблица результатов с 8 800 ячейками.
Вы видите, что корреляция между Measur 5 и Measur 9 действительно значима (р=.0006). Это говорит о том, что ошибка, связанная с принятием гипотезы о независимости, составляет б из 10,000.
После того как получена оценка корреляций, посмотрим зависимости на графиках.
Чтобы визуализировать значения корреляций между переменными, можно построить график корреляций. Если щелкнуть по соответствующему коэффициенту корреляции (-0,47) правой кнопкой мыши, то появится меню:
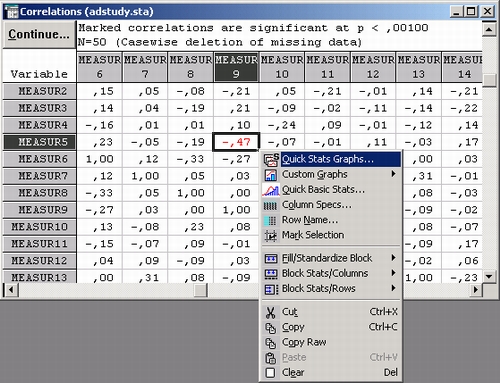
Теперь перейдите в подменю Быстрые статистические графики и выберите Диаг. рассеяния/довер.
Будет построен график с параметрами, заданными по умолчанию (диаграмма рассеяния для выбранного коэффициента корреляции с прямой регрессии, 95%-я доверительная полоса и уравнение регрессии в заголовке).
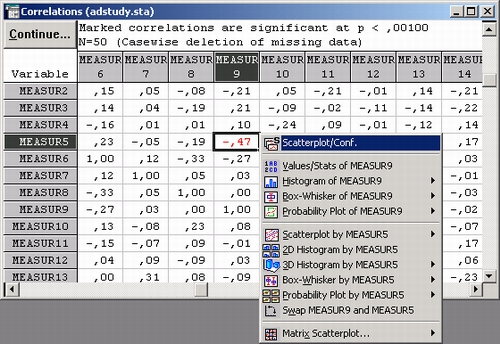
Мы вернемся к этому примеру и рассмотрим зависимость между Measur 5 и Measur 9 для группированных данных.
А сейчас опишем некоторые возможности для настройки построенного графика зависимости.
Если вы щелкнете где-нибудь на свободном месте снаружи осей графика, появится меню глобальных опций.
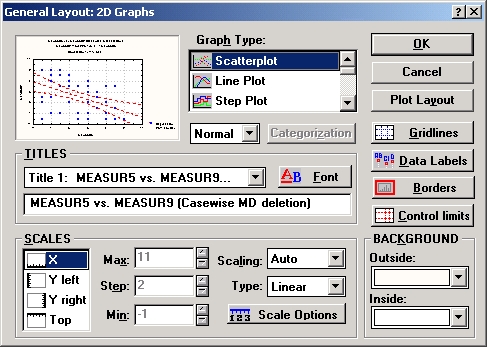
Большинство основных настроек формата графика доступно в диалоговом окне Общая разметка (см. выше первую опцию контекстного меню).
Ниже показаны основные соглашения по использованию мыши для настройки графиков.
Вычисление описательных статистик для группированных данных
Развитие сюжета далее довольно естественное. Вначале мы вычисляем описательные статистики и корреляции для всего массива данных, затем для групп данных. Сравнивая полученные результаты, приходим к мысли, что группировка — это действительно то, чем следует заниматься на первых этапах дескриптивного анализа данных. Проводя группировку, мы стараемся выделить группы однородных объектов (исходные реальные данные, как правило, неоднородны).
В системе STATISTICA вы можете вычислить разнообразные описательные статистики (например, средние, стандартные отклонения) для данных, разбитых на группы одной или несколькими группирующими переменными (например, переменными Пол — Gender vi Реклама — Adv). Мы рассмотрим, как это можно сделать.
Но если бы мы задали вопрос: как вообще провести группировку исходных данных, то мы не могли бы на него ответить. Ответ лежит в предметной области исследования. Итак, интуитивно вы ощущаете, что бы хотелось найти, далее, используя систему STATISTICA, сравниваете различные способы группировки (возможно, это займет довольно много времени) и находите нужный вариант.
Внутригрупповые описательные статистики вычисляются с помощью процедуры Группировка и однофакторная ANOVA, доступной из стартовой панели модуля Основные статистики и таблицы.
После выбора процедуры Группировка и однофакторная ANOVA в стартовой панели нажмите кнопку Переменные и выберите группирующие переменные GENDER (МУЖЧИНА - MALE и ЖЕНЩИНА - FEMALE) и ADVERT.
В данном примере выбор группирующей переменной не представляет никакой проблемы.
Щелкните по кнопке Коды для группирующих переменных и выберите коды для группирующих переменных в диалоговом окне Коды для независимых факторов.
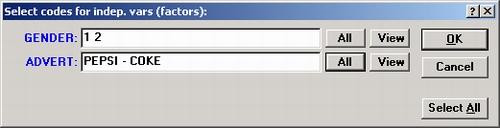
Чтобы выбрать все коды переменной, можно либо ввести номера кодов в соответствующем поле ввода, либо нажать кнопку Все, либо поставить* в соответствующем поле ввода.
Щелкнув по кнопке Выбрать все в этом диалоговом окне, вы выберете все коды для каждой переменной. Нажатие ОК без задания каких-либо значений эквивалентно определению всех значений для всех переменных.
Нажмите ОК здесь и в диалоговом окне Внутригрупповые описательные статистики и корреляции для того, чтобы открыть диалоговое окно Внутригрупповые описательные статистики и корреляции — Результаты.
Диалог Внутригрупповые описательные статистики и корреляции предоставляет различные процедуры и настройки для внутригруппового анализа данных (анализ данных внутри групп). Цель такого анализа — лучшее понимание различий между группами.
Вы можете выбрать нужные статистики для того, чтобы отобразить их на экране в Итоговой таблице средних или Подробных двухвходовых таблицах.
В этом примере выберите все пять возможных статистик (сделайте соответствующие установки в группе опций Статистики).
Затем щелкните по кнопке Подробные двухвходовые таблицы, чтобы увидеть таблицу результатов.
В приведенной таблице результатов имеются описательные статистики для выбранных переменных, разбитых на группы (прокрутите таблицу, чтобы увидеть результаты для остальных переменных).
Изучим эту таблицу. В первом столбце показаны средние переменной Measur 1 для различных групп данных:
Заметьте, если общее среднее, без учета группировки, равно 5,9, то среднее в группах — уже другое.
Спрашивается, велико или мало отличие среднего в разных группах? В анализе данных для ответа на вопрос имеется специальный критерий, известный как t-критерий Стьюдента, который позволяет прояснить ситуацию. Этот критерий подробно описан в отдельной главе.
Сейчас можно лишь сказать, что имеется слабое различие переменной Measur 1 в группах MALES и FEMALES.
Как можно заметить, имеется слабое различие между группами PEPSI и СОКЕ в пределах одного пола. Группы, получающиеся разделением по полу, кажутся достаточно однородными. Максимальное отличие в средних имеет место между группой MALES — PEPSI (среднее равно 6,54) и группой FEMALES — COKE (среднее равно 5,38).
Корреляции измеряют степень зависимости между переменными. Если данные разбиты на однородные группы, то есть надежда, что зависимости станут более отчетливыми. Именно за это и идет борьба.
Итак, если у вас имеется массив данных, то часто первое, с чего можно начать, — это группировка данных. Очевидно, если у вас мало данных, то поле действий резко сокращается. Рассматриваемая нами группировка достаточно проста и проводится с помощью лишь двух группирующих переменных. Однако если, например, изучаете зависимость суммарной покупки в супермаркете от дохода покупателей или проводите сегментацию рынка, то вам придется достаточно поработать, чтобы эффективным образом разбить данные на классы.
Итак, проведем группировку данных, рассмотрим зависимости внутри групп и сравним с результатами для негруппированных наблюдений.
Нажмите кнопку Внутригрупповые корреляции и откройте диалоговое окно Выберите группу или все группы, в котором можно выбрать группу (или Все группы) для корреляционных матриц.
В частности, нас интересует внутригрупповая корреляция между переменными Measur 5 и Measur 9.
Ранее мы вычислили ее (r = - 0,47) для всех данных и увидели, что она высокозначима (р<0,001).
В диалоговом окне Выберите группу или все группы дважды щелкните на строке Все группы, чтобы получить следующие 3 корреляционные матрицы:
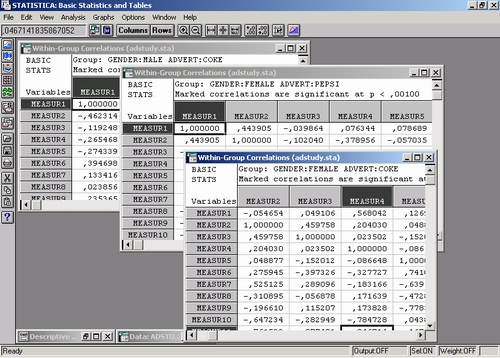
Как можно заметить, корреляции в отдельных группах заметно отличаются друг от друга, следовательно, отличаются зависимости в разных группах.
Следующий наш шаг состоит в представлении зависимости на графиках.
Внутригрупповые корреляции можно представить графически, используя команду Категоризованпые диаграммы рассеяния в диалоговом окне Внутригрупповые описательные статистики и корреляции — Результаты.
Нажав эту кнопку, вы сможете выбрать переменные для графиков.
Выберем, например, переменную Measur 5 в первом списке и переменную Меа-sur 9 во втором списке.
Далее нажмите ОК, чтобы построить график.
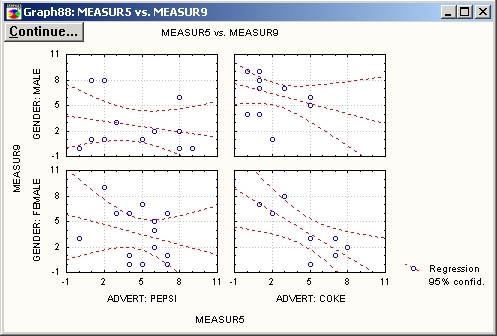
Из графика отчетливо видна сильная зависимость между переменными Measur 5 и Measur 9 для группы СОКЕ — FEMALE. Эта группа состоит из женщин, предпочитающих коку.
Для всех остальных групп зависимость не значима.
Итак, мы нашли группу, в которой отчетливо проявилась зависимость между переменными Measur 5 и Measur 9.
Таким образом, с уверенностью можно сказать, что именно эта группа отвечает за зависимость между Measur 5 и Measur 9.
Подобное клише анализа применимо и к другим исследованиям.
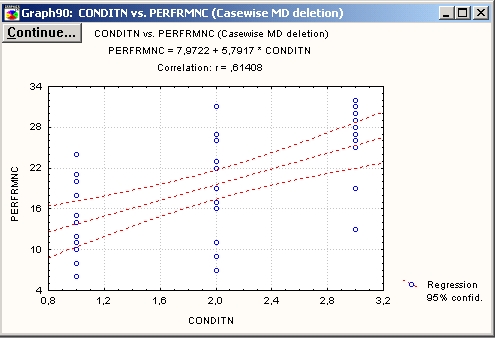
Рассмотрим, например, корреляционную матрицу данных о продажах в супермаркете. Фрагмент ее показан ниже:
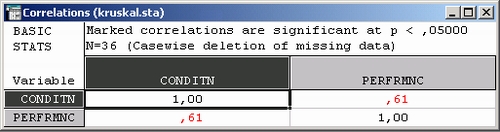
В этой матрице показаны корреляции между различными покупками. Рассмотрим, например, первую строку. Она относится к кондитерским изделиям.
В этой строке несколько корреляций значимы. На экране они выделяются красным цветом. Рассмотрим максимальную из корреляций — корреляцию между переменными Кондитерские изделия и Спиртное (r = 0,61).
Хотя корреляция большая, из диаграммы рассеяния видно, что никакой зависимости между продажами спиртного и кондитерских изделий нет.
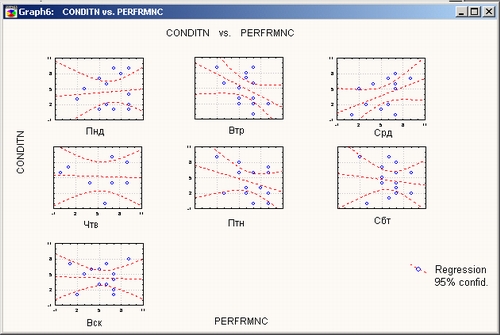
Продолжая исследование, проведем группировку, разбив данные на дни недели.
Обратим внимание на внутргрупповые зависимости, в данном случае — зависимости для каждого дня недели.
На диаграмме рассеяния зависимости для каждого дня недели имеют уже более привлекательный вид:
Очень полезны также графики взаимодействий:
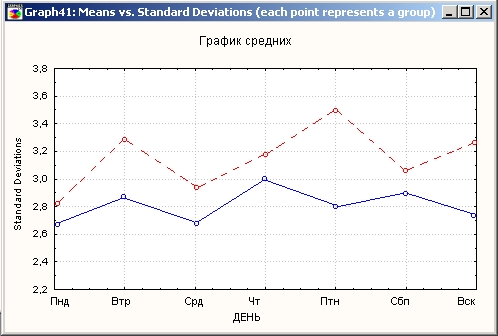
Из этого графика отчетливо видно, что пик продаж спиртного в течение недели приходится на пятницу, а средние продажи кондитерских изделий максимальны в четверг и пятницу. Такого рода описательный анализ, совмещенный с группировкой, является типичным первым шагом анализа данных.
|
|
