Как всегда, мы начинаем главу с обзора всевозможных графиков, преследуя очевидную цель — дать читателю максимально полное представление о способах визуализации категоризованных данных с тем, чтобы привести к осознанному, а не спонтанному выбору необходимого метода. Дополнительный материал и примеры содержится также в других главах по визуальному анализу. Вначале поймем идею категоризованных графиков.
Что такое категоризованные графики?
Категоризованные графики, также называемые Casement plots (см. фундаментальный труд по визуализации Chambers, et al., (1983) Graphical methods for data analysis. Belmont, С A: Wadsworth), позволяют визуализировать категоризованные данные, иными словами, данные, разбитые на группы (категории) с помощью одной или нескольких группирующих (категоризующих) переменных (от английского categorized variables — категориальные переменные). В качестве группирующих переменных обычно используют категориальные (см. описание типов переменных в главе Элементарные понятия).
Отметим, что разбиение данных на группы и проведение анализа внутри групп является чрезвычайно важным приемом анализа, постоянно используемом в практической работе. Например, известный прием сегментации рынка представляет собой частный случай категоризации.
Итак, с помощью группирующих переменных наблюдения из исходного файла данных разбиваются на несколько однородных групп (например, клиенты супермаркета разбиваются по уровню дохода или по признаку: имеет — не имеет машину), и для каждой группы строится свой график, показывающий специфику данных.
Так как групп несколько, то создаются серии двухмерных и трехмерных графиков (гистограммы, диаграммы рассеяния, линейные графики, графики поверхности и др.), по одному для каждой выбранной группы — category случаев (непересекающихся подмножества наблюдений). Например, такими группами могут быть пользователи Интернет из Нью-Йорка, Чикаго, Далласа или Москвы, Санкт-Петербурга и Смоленска. Такие «составные» графики помещаются последовательно, один за другим, на экране компьютера, позволяя сравнивать данные в каждой группе (например, в группе городов или среди клиентов с разным уровнем дохода). Часто удобно собрать категоризованные графики в один составной график, для чего в STATISTICA имеются все необходимые средства.
Для выбора групп обычно предоставляется широкий набор опций, наиболее типичная из которых использует категоризующую переменную, то есть переменную, производящую разбиения на группы своими собственными значениями, например, переменная Город — City с тремя значениями Нью-Йорк — New York, Чикаго — Chicago и Даллас — Dallas.
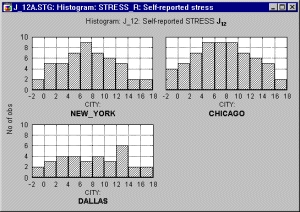
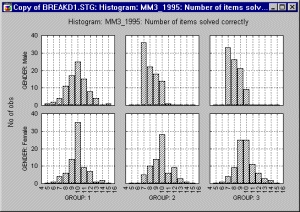
На следующем графике показаны гистограммы модельной переменной, измеряющей уровень стресса жителей в трех городах США.
Взглянув на графики, можно сделать вывод, что стресс людей, живущих в Далласе, более равномерно распределен, чем стресс жителей Нью-Йорка или Чикаго (данные носят модельный характер).
Очевидно, что вместо одной группирующей переменной можно использовать две или больше. Далее показаны графики с двумя группирующими переменными.
Такие категоризованные графики можно рассматривать как «кросстабуляцию» или «сопряжение» графиков (сравните с таблицами сопряженности). На них каждая из зависимостей представлена на пересечение одного уровня одной группирующей переменной (например, Город — City) и одного уровня другой группирующей переменной (например, Время — Time). Таким образом, имеем 6 графиков (3 уровня переменной Город умножить на 2 уровня переменной Время).
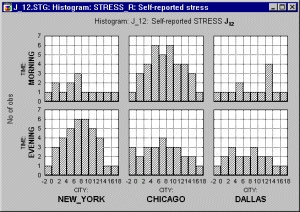
Добавление второго фактора (второй группирующей переменной) показывает, что схемы сообщений о стрессах в Нью-Йорке и Чикаго на самом деле очень сильно различаются, если принять во внимание Время опроса. Иными словами, существенно зависят от того, когда именно проводился опрос, утром или вечером. Заметьте, что в Далласе фактор времени суток вносит незначительные изменения.
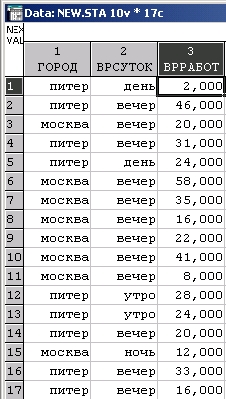
Рассмотрим также модельные данные о работе в Интернет пользователей из различных городов (фрагмент файла см. ниже):
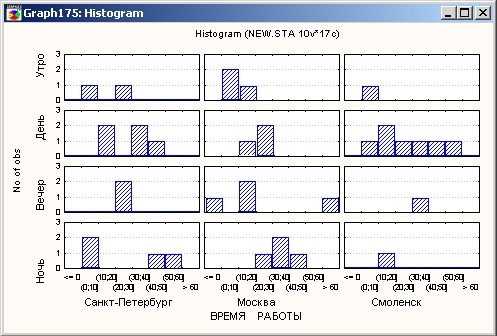
Ниже показан категоризованный график, позволяющий визуально представить интенсивность работы в различных городах в зависимости от времени суток.
Категоризованные графики и матричные графики
Внешне матричные графики похожи на категоризованные, однако матричные графики строятся для одних и тех же подмножеств наблюдений, тогда как категоризованные графики строятся для разных, более того, непересекающихся групп наблюдений.
Наличие непересекающиеся группы наблюдений и составляет главную особенность категоризованных графиков. Собственно, идея в том и состоит, чтобы разбить данные на естественные группы и визуально исследовать зависимости между группами.
В категоризованных графиках нужно указывать, по меньшей мере, одну группирующую переменную — grouping variable, которая содержит информацию о групповой принадлежности каждого наблюдения (например, Чикаго — Chicago, Даллас — Dallas). Эта группирующая переменная не будет непосредственно включена в график, не будет отображаться на нем, но будет служить критерием разбиения наблюдений на группы.
Выше мы познакомились с категоризованными гистограммами — гистограммами, построенными отдельно для каждой группы наблюдений, определяемой значениями группирующей переменной.
В основном гистограммы используются для того, чтобы исследовать распределение значений переменных. Например, гистограммы показывают, какие конкретно значения или диапазоны значений исследуемой переменной встречаются наиболее часто, как отличаются значения в разных интервалах, сосредоточено или нет наибольшее число наблюдений вокруг среднего или медианы, имеет место симметрия распределения и т. д.
Гистограммы также используются для оценки сходства (согласия) наблюдаемого или эмпирического распределения с теоретическим распределением.
Существуют две основные причины, по которым гистограммы представляют интерес.
Если вы описали тип распределения переменных, то можете построить математическую модель и провести нужные расчеты.
Часто в качестве первого шага в анализе нового набора данных следует построить гистограммы для всех переменных и всех наблюдений и далее подходящим образом их категоризовать.
Гистограммы и описательные статистики
Категоризованные гистограммы — Categorized Histograms предоставляют информацию, схожую с описательными статистиками (например, среднее, медиана, минимальное значение, максимальное значение и т. д.). Несмотря на то, что некоторые (числовые) описательные статистики легче читаются в таблице, общий вид и глобальные описательные статистики проще исследовать визуально.
График предоставляет качественную информацию о распределении, которая не может быть полностью представлена одним или двумя параметрами.
Например, общее асимметричное распределение дохода может показывать, что большинство людей имеет доход, который гораздо ближе к минимальному значению диапазона дохода, чем к максимальному. Кроме того, при разбиении по половому или этническому признаку эта характеристика распределения дохода может оказаться более выраженной в определенных подгруппах. Хотя эта информация будет содержаться в коэффициенте асимметрии (для каждой подгруппы) при представлении в графическом виде на гистограмме, она обычно распознается и запоминается более легко.
Имея свой сайт, вы анализируете статистику посещений и по гистограмме определяете пик интереса к сайту в течение суток.
Гистограмма может также показать «изгибы», которые представляют важную информацию об определенной социальной стратификации исследуемого поколения или аномалий в распределении дохода в конкретной группе, вызванной, например, налоговой реформой.
Категоризация значений в каждой гистограмме
Все процедуры гистограмм, доступные в STATISTICA, предоставляют большой набор способов разбиения данных на группы.
Эти методы категоризации разделяют весь диапазон значений переменной (от минимума до максимума, если переменная числовая) на некоторое число групп или диапазонов, для которых подсчитываются частоты (просто считается количество значений, попавших в данный диапазон). Далее полученные частоты представляются на графике в виде отдельных столбцов или полос.
Например, можно создать гистограмму, на которой каждый столбец будет представлять диапазон из 10 единиц шкалы, которая используется для представления переменной; если минимальное значение равно 0, а максимальное — 120, то будет создано 12 столбцов. Кроме того, можно сделать так, чтобы весь диапазон значений переменной был разделен на указанное число интервалов равной длины (например, 10); в последнем случае, если минимальное значение равно 0, а максимальное — 120, каждый интервал будет равен 12 единицам шкалы.
Имеются опции, которые поддерживают более сложные категоризации, например, позволяют создать неравные диапазоны с заданными пользователем границами для каждого диапазона (чтобы создать более понятные диапазоны или объединить выброс и увеличить читаемость средней части гистограммы). Диапазоны можно также создать, определив критерии включения и исключения с помощью логических операторов (например, первый столбец гистограммы может представлять людей, которые за последний год летали на самолете более 10 раз, причем не более 50% этих поездок были связаны с бизнесом).
Категоризация значений в составных графиках
Составные графики можно создать для уровней категоризующей переменной (например, переменной пол или переменной стресс, характеризующей различные уровни стресса).
Значения непрерывных переменных (например, возраст, доход, цена) можно разбить на заданное число интервалов или создать группы наблюдений с помощью логических условий.
Последняя возможность особенно эффективна, так как позволяет провести разбиение на группы с помощью «правил», которые используют более одной переменной, с заданием логических соотношений между этими переменными (например, таким способом можно выбрать группу, состоящую из всех людей мужского пола старше 30 лет и играющих в гольф и не любящих попсу).
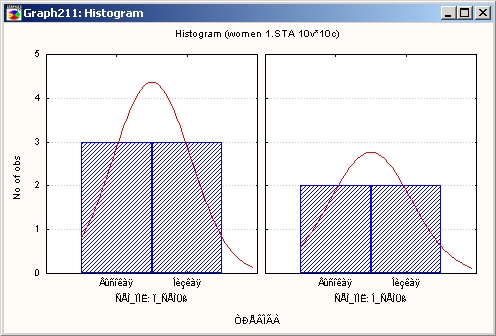
В качестве еще одного примера рассмотрим данные, характеризующие стресс женщин. Значения первой переменной описывают семейное положение опрошенных женщин, значения второй переменной измеряют уровень тревоги. Известно, что личностная тревожность представляет собой устойчивую склонность личности воспринимать жизненную ситуацию как угрожающую и реагировать на нее соответствующим образом (см., например, Кокс Т. (1981) Стресс). Обычно используют шкалу тревожности: низкая тревожность, умеренная и высокая. Для простоты ограничимся шкалой «низкая — высокая» тревожность. Файл данных показан ниже.
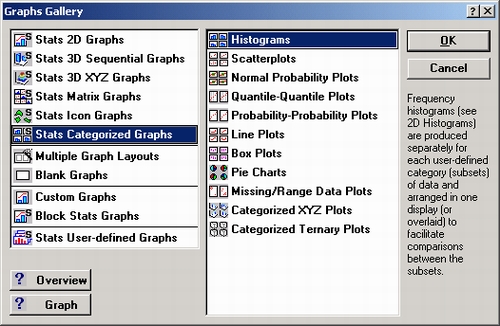
Откройте окно галерея графиков, в котором выберите статистические категоризованные графики (левое меню) и гистограммы (правое меню). Сделав выбор, нажмите кнопку ОК.
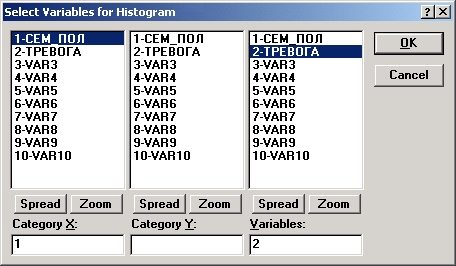
В появившемся далее окне нажмите кнопку переменные, чтобы выбрать переменные для графика.
Выберем в качестве группирующей переменной семейное положение женщины. Значения этой переменной разбивают данные на две группы: женщины, живущие в полной семье, и женщины, живущие в неполной семье, включая одиноких женщин. Анализируемой переменной будет переменная тревога, выбранная в третьем столбце.
Далее сделайте установки для настройки графика, как показано в окне 2М категоризованные гистограммы.
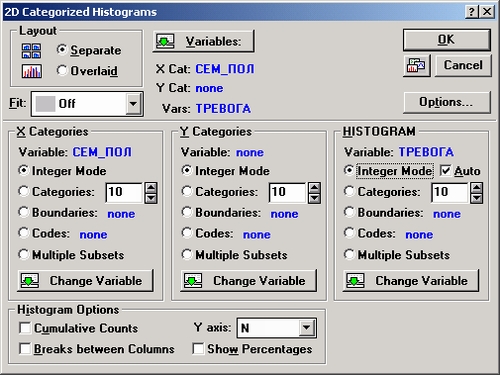
Возможны два способа размещения гистограмм «а графике в зависимости от выбора, сделанного в опциях Размещение этого диалогового окна (см. графики ниже).
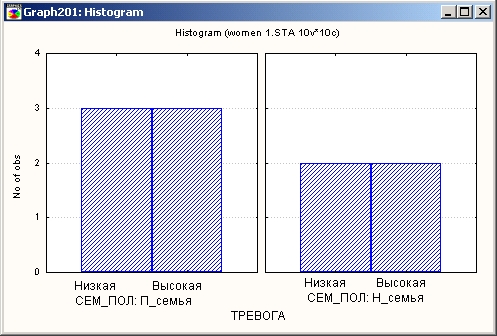
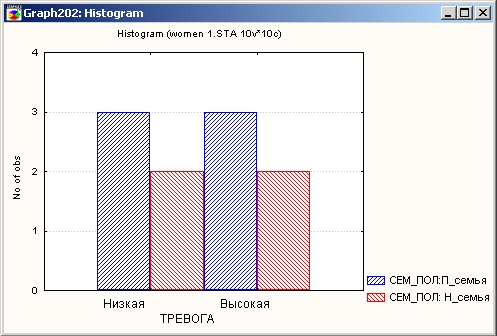
Из графиков видно, что уровень тревоги женщин в неполных семьях выше, чем в полных. Насколько значимо это различие, можно оценить с помощью специальных статистических критериев, например, с помощью критерия хи-квадрат.
В данном примере это различие небольшое, однако и число наблюдений мало. Если бы подобное различие (одно наблюдение) имело место для 100 респондентов, то, очевидно, мы отнесли бы его за счет случайной ошибки и не приняли бы во внимание.
В этом и состоит существо дела: если визуально вы видите отчетливый эффект, то его не имеет смысла доказывать статистически; если эффект не столь ясен, то применяют статистические критерии.
Категоризованные гистограммы и диаграммы рассеяния
Эффектным приложением методов категоризации для непрерывных переменных может оказаться представление связей между тремя переменными на плоскости.
Наверняка приведенный нами пример визуализации удивит даже искушенных аналитиков. Ниже показана диаграмма рассеяния для двух переменных Load 1 и Load 2.
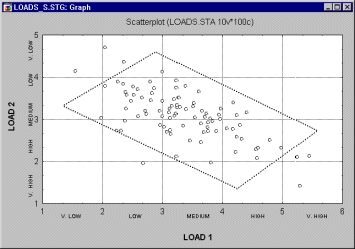
Теперь предположим, что необходимо добавить третью переменную (Output} и рассмотреть ее распределение на различных уровнях совместного распределения Load 1 и Load 2. Этого можно достичь, например, с помощью следующего графика.
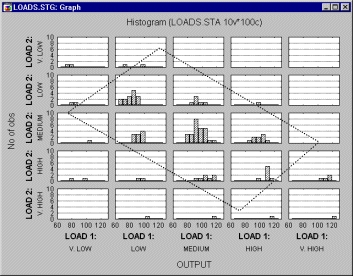
На графике значения переменных Load 1 и Load 2 разбиты на 5 уровней, и для каждой комбинации уровней построена гистограмма переменной Output.
Подгонка теоретических распределений к наблюдаемым распределениям
Функции подгонки распределений STATISTICA, встроенные в гистограммы, позволяют сравнивать распределение наблюдаемых данных с такими распределениями, как нормальное, бета-, экспоненциальное, экстремальных значений, гамма-, геометрическое, Лапласа, логистическое, логнормальное, Пуассона, Релея и Вейбулла.
Это наиболее часто возникающие на практике распределения, и проверка согласия с ними данных иногда представляет интерес.
Обратите внимание, что программа STATISTICA также включает специальный модуль подгонки распределения (см. Непараметрическая статистика и подгонка распределений), который предоставляет широкий набор теоретических функций распределения, графиков и статистик для проверки согласия исходных данных с выбранным распределением.
Подгонка распределений к множественным гистограммам
Несколько архаичный термин «множественный» в анализе данных часто эквивалентен слову несколько или много, таким образом, множественная гистограмма означает всего лишь, что несколько гистограмм отображены на одном графике.
При построении нескольких гистограмм на одном графике переменные представлены смежными полосами, поэтому для каждой группы (обычно построенной вдоль горизонтальной оси X) строится несколько полос.
Аппроксимирующие кривые могут либо точно соответствовать гистограммам, либо быть сравнимыми друг с другом.
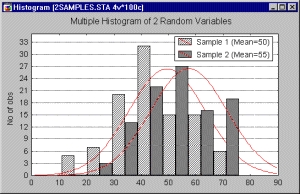
Поскольку множественные гистограммы создаются для визуального сравнения распределений в разных группах, например, мужчин и женщин (а не для анализа качества подгонки для отдельных переменных), то STATISTICA использует второе решение: ожидаемая теоретическая кривая будет «прикреплена» к числовым значениям (а не к меткам групп) оси X. На практике это обычно не влияет на объяснение графика, то есть очевидное отклонение переменной от ожидаемого распределения по-прежнему будет очевидно.
Если вам нужно «прикрепить» функции распределения к меткам групп, то можно изменить соответствующие формулы, так что подогнанные распределения будут сдвинуты по оси X, чтобы компенсировать сдвиг столбцов гистограмм.
Категоризованные диаграммы рассеяния
2М диаграммы рассеяния используются для визуализации зависимости между двумя переменными X и Y (например, вес и рост, цена и качество). В диаграммах рассеяния отдельные данные представлены точками в двумерном пространстве. Две координаты (X и Y), определяющие расположение каждой точки, соответствуют определенным значениям двух переменных.
Если две переменные сильно связаны, то точки имеют некоторую систематическую форму (например, группируются вдоль прямой линии или гладкой кривой). Если переменные не связаны, то точки образуют круглое «облако» (более подробно см. главу Элементарные понятия).
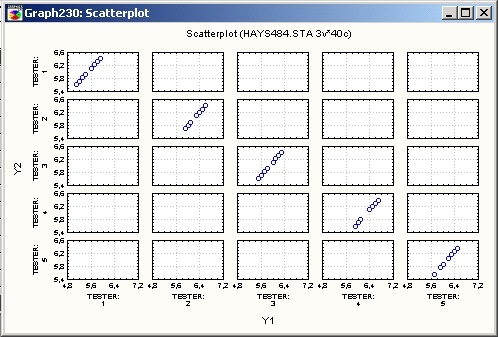
Категоризованные диаграммы рассеяния предоставляют мощные исследовательские и аналитические методы исследования соотношений между двумя и более переменными в различных подгруппах.
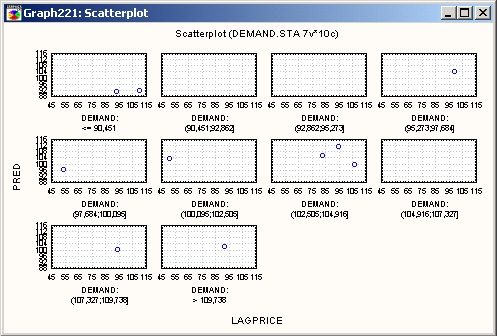
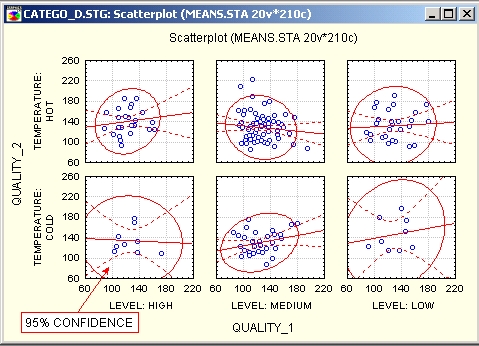
Нелинейность — это другая сторона зависимости между переменными, которую можно исследовать на диаграммах рассеяния. Для измерения нелинейных зависимостей между переменными не существует простых в использовании тестов: стандартный коэффициент корреляции Пирсона г позволяет измерять линейную зависимость, а некоторые непараметрические корреляции, такие как корреляция Спирмена R, позволяют измерять также монотонные нелинейные связи.
Исследование диаграмм рассеяния дает возможность определить форму зависимости, так что в дальнейшем можно выбрать соответствующее преобразование данных, чтобы «линеаризовать» зависимость или выбрать соответствующее уравнение для нелинейного оценивания.
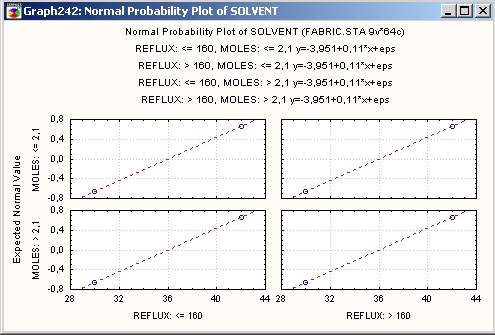
Категоризованные вероятностные графики
С помощью категоризованных вероятностных графиков можно определить, насколько близко распределение переменной следует нормальному распределению в различных подгруппах.
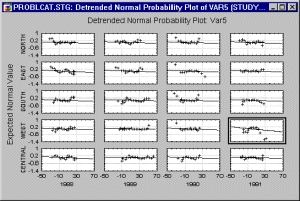
Категоризованные нормальные вероятностные графики представляют эффективный инструмент для проверки нормальности распределения данных в отдельных группах.
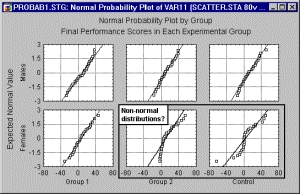
Если подгонка в основном неверна и данные образуют какую-либо ясную форму (например, букву 5) вокруг прямой линии, то переменную, возможно, необходимо каким-то образом преобразовать до того, как она будет использована в процедуре, предполагающей нормальность (например, логарифмическое преобразование часто используется, чтобы «втянуть» конец распределения (см. Neter, Wassermafl* and Kutner (1985) Applied linear statistical models: Regression analysis of variance and experimental designs, Homewood IL: Irwin).
Нормальные вероятностные графики без тренда строятся так же, как и стандартные нормальные вероятностные графики, за исключением того, что линейное смещение (тренд) убирается до того, как строится график.
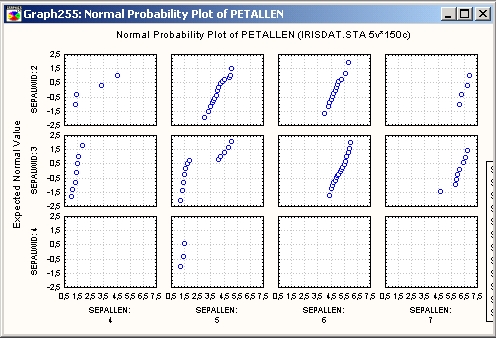
Это часто «разбрасывает» график, что позволяет пользователю легко обнаружить отклонения от нормальности, например, если распределение равномерное, то возникает S-образная кривая.
Категоризованные графики квантиль-квантиль
Категоризованные графики квантиль-квантиль (К-К) используются для поиска наилучшего распределения в заданном параметрическом семействе распределений.
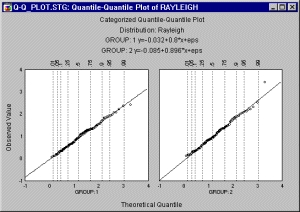
Вначале нужно выбрать, какое из теоретических распределений аппроксимирует данные. Т. к. выбранные семейства вероятностных распределений зависят от параметров, например, среднее и стандартное отклонение для семейства нормальных распределений, то задача состоит в том, чтобы оценить неизвестные параметры по имеющимся наблюдениям.
Чтобы оценить аппроксимацию или качество подгонки наблюдаемых данных теоретическим распределением, наблюдаемые значения переменной (х1 < ... < хn) упорядочиваются, строится вариационный ряд, а затем эти значения (х) строятся по обратной функции распределения вероятности, обозначенной как F-1 (точнее, F-1 (i - rankadj/n + nadj), где F-1 зависит от распределения, a rankadj и nadj задаются пользователем).
На графиках проверка согласия проводится визуально.
Если наблюдаемые значения попадают на линию регрессии, то можно сделать вывод, что наблюдаемые значения согласуются с выбранным распределением. Уравнение аппроксимирующей линии ( Y=a + bx, приводится в заголовке К-К графика) дает оценки параметров (а и b, где а — параметр положения, b — параметр масштаба) распределения.
Категоризованные графики вероятность-вероятность
Категоризованные графики вероятность-вероятность (В-В) используются для определения того, насколько хорошо определенное теоретическое распределение аппроксимирует наблюдаемые данные.
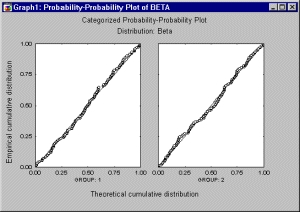
На В-В графике наблюдаемая эмпирическая функция распределения (доля значений переменной < х) сравнивается с теоретическим (предполагаемым) распределением. Если все точки графика ложатся на прямую с тангенсом угла наклона 1, то можно заключить, что теоретическое распределение хорошо аппроксимирует эмпирическое распределение.
Чтобы построить такой график, нужно полностью задать теоретическую функцию распределения. Поэтому параметры распределения должны либо быть заданы пользователем, либо оценены.
Категоризованные линейные графики
На линейных графиках отдельные точки соединены линиями. Линейные графики предоставляют простой способ визуального представления последовательности большого числа значений (например, уровня цен на бирже за несколько дней).
Опция катетеризованных Линейных графиков — Line Plots используется; если нужно посмотреть эти данные, разбитые группирующей переменной на группы (например, цены при закрытии по понедельникам, вторникам и т. д.) или другими логическими критериями, включая одну или более переменных (например, цены при закрытии только в те дни, когда индекс на двух других биржах и Dow Jones поднялся, по сравнению с остальными расценками при закрытии).
В системе STATISTICA можно экспериментировать с различными стилями визуализации категоризованных последовательностей значений, изменяя Тип графика — Graph Type в диалоговом окне Разметка графика — Plot Layout.
Процедуры сглаживания доступны также и для категоризованных линейных графиков, например, как показано на следующем рисунке:
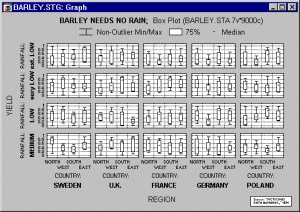
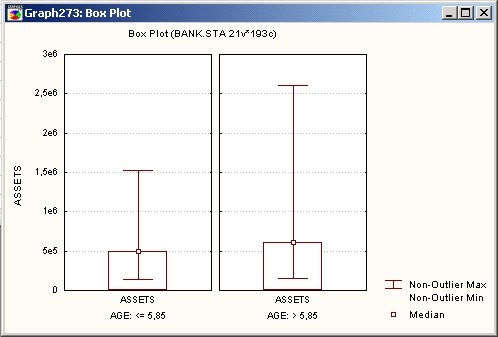
Категоризованные прямоугольные диаграммы
На Прямоугольных диаграммах — Box Plots (термин впервые использовал известный статистик Тьюки (Tukey) в 1970 году — см.: Tukey J.W. (1972) Some graphic and semigraphic displays. In7 Statistical Papers in Honor of George W. Snedecor; ed. T. A. Bancroft, Arnes, I A: Iowa State University Press, p. 293-316) диапазоны значений выбранной переменной (или нескольких переменных) строятся отдельно для групп наблюдений, определенных значениями категоризующих переменных.
Положение центра данных (медианы или среднего) и диапазон вокруг него, а также, например, квартили, стандартные ошибки или стандартные отклонения вычисляются для каждой группы наблюдений.
На приведенном графике видны выбросы (в данном случае точки, отстоящие больше или меньше, чем в 1,5 раза по отношению в межквартильному диапазону):
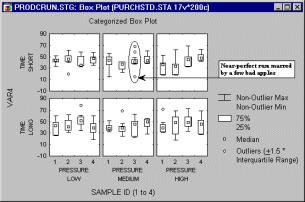
Однако на следующем графике нет очевидного выброса или экстремальных значений.
Для прямоугольных диаграмм существует два типа приложений: а) отображение диапазонов значений для отдельных объектов наблюдений (например, обычная Минимаксная диаграмма — MIN-MAXplot для акций или товаров, или составные последовательные графики — sequence dataplots с диапазонами) и b) отображение изменчивости данных в отдельных группах или примерах (например, диаграммы «ящики и усы» или диаграммы размахов, в которых среднее — это точка внутри «ящика», плюс-минус стандартная ошибка «ящик», а плюс-минус стандартное отклонение от среднего — более узкий «ящик», или, как иногда говорят, пара «усов»).
Прямоугольные диаграммы позволяют быстро вычислить и «интуитивно представить» силу связи между группирующей и зависимой переменной.
Предполагая, что зависимая переменная распределена нормально, и зная, какая часть наблюдений попадает, например, в ±1 или ±2 стандартных отклонения от среднего, можно легко вычислить результаты эксперимента и сказать, например, что около 95% наблюдений в экспериментальной группе 1 принадлежат диапазону, отличному от 95% наблюдений группы 2.
Кроме того, можно строить так называемые усеченные средние значения (trimmed means), исключая заданный пользователем процент наблюдений из экстремальных значений.
 «Ящики и усы», или диаграммы размаха
«Ящики и усы», или диаграммы размаха
Этот тип Статистических категоризованных графиков по умолчанию помещает «ящик» вокруг центра (то есть среднего или медианы), который представляет собой выделенный диапазон (то есть стандартную ошибку, стандартное отклонение, минимакс или константу), и «усы» снаружи «ящика», которые отображают другой выбранный тип диапазона.
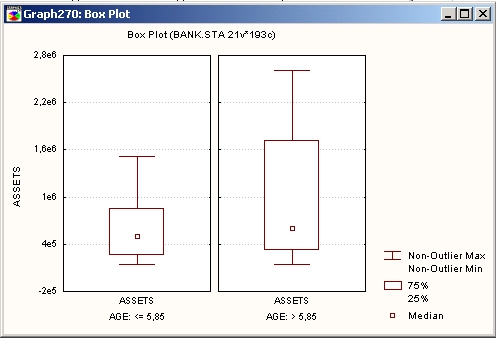
Ширину «ящика» и засечек «усов», конечно, можно менять.
 «Усы», или диаграммы диапазонов
«Усы», или диаграммы диапазонов
В этом типе прямоугольных диаграмм диапазон (то есть внутригрупповая стандартная ошибка, стандартное отклонение, минимакс или константа) представлен «усами» (отрезком прямой с засечками на обоих концах).
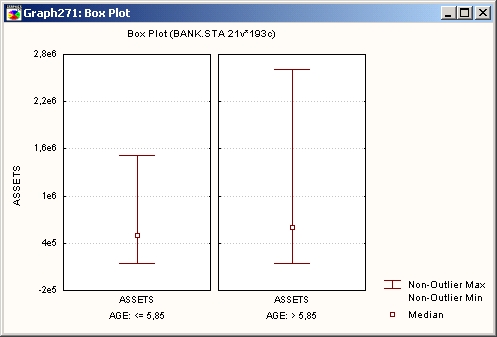
 «Ящики», или прямоугольники
«Ящики», или прямоугольники
В этом типе прямоугольных диаграмм вокруг средней точки (то есть среднего группы или медианы) помещается «ящик», который представляет выбранный диапзон (внутригрупповая стандартная ошибка, стандартное отклонение, минимакс или константа).
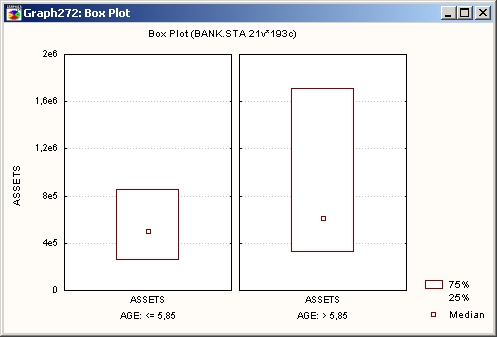
 Столбцы
Столбцы
В этом виде прямоугольных диаграмм для представления средней точки (среднего группы или медианы) используются вертикальные столбцы.
Можно создавать другие типы прямоугольных диаграмм, изменяя типы зависимостей соответствующих компонент графиков.
 Верхние и нижние засечки
Верхние и нижние засечки
В этом виде прямоугольных диаграмм «засечки» на «усах» не симметричны, а сдвинуты влево, представляя традиционный график «цен на акции».
Категоризованные круговые диаграммы
Круговые диаграммы являются одним из наиболее часто используемых форматов графиков, которые используются для представления пропорций или значений переменных.
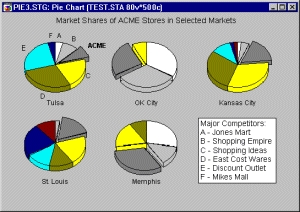
Построенные категоризованные круговые диаграммы всегда будут рассматриваться как частотные — frequency круговые диаграммы (в противоположность круговым диаграммам данных). Этот тип круговых диаграмм иногда называют частотной круговой диаграммой — frequency pie chart.
Относительные частоты представлены как секторы круга пропорциональных размеров. Поэтому круговые диаграммы предоставляют альтернативный гистограммам метод визуализации данных.
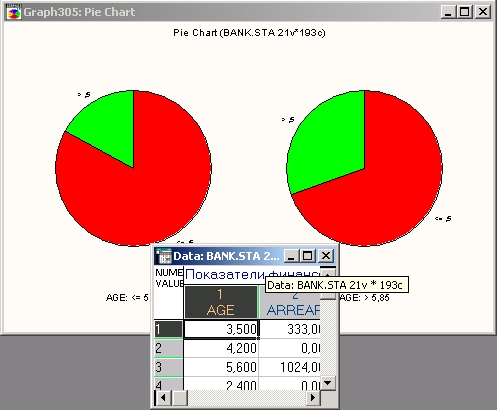
Секторы круга можно пометить числовыми или текстовыми значениями; метки могут включать непосредственные или относительные значения частот.
Полезным приложением категоризованных круговых диаграмм является представление относительной частоты распределения переменной в каждой точке совместного распределения двух других переменных. Следующий график наверняка удивит вас.
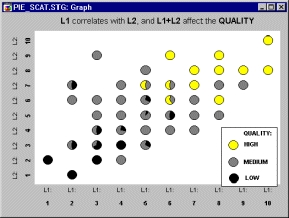
Обратите внимание, круги нарисованы только в тех «местах», в которых есть данные. Поэтому приведенный выше график выглядит как диаграмма рассеяния (переменных L1 и L2) с отдельными кругами в качестве указателей точек.
Кроме информации, содержащейся в простой диаграмме рассеяния, каждый круг показывает относительное распределение третьей переменной на соответствующем месте (например, Низкое — Low, Среднее — Medium, Высокое качество — High Quality).
Представленный график служит прекрасным образцом совмещения диаграмм рассеяния и круговых диаграмм. Он также показывает, в каком направлении следует двигаться в визуальном анализе данных, чтобы получить действительно эффективный результат.
Категоризованные диаграммы пропущенных данных и диаграммы диапазонов
Эти графики позволяют определить шаблон распределения пропущенных данных и заданных пользователем точек, лежащих «вне диапазона», для каждой категории наблюдений.
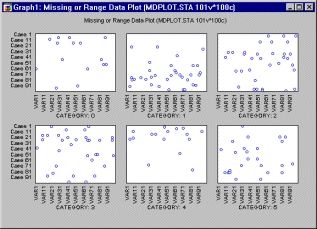
Подобные графики используются в разведочном анализе для того, чтобы определить протяженность и «выход из диапазона» данных.
В большинстве процедур пропущенные данные удаляются, используя попарное или построчное удаление пропущенных данных или подстановку среднего значения вместо пропуска.
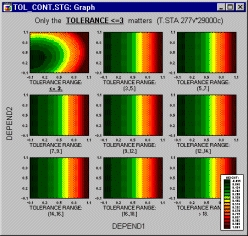
Категоризованные трехмерные графики
К этому типу относятся трехмерные диаграммы рассеяния (пространственные графики, спектральные графики, диаграммы отклонения и трассировочные графики), диаграммы линий уровня и графики поверхности для наборов случаев, заданных определенными группами выбранной переменной или группами, определенными заданными пользователем условиями выбора случая (наборы можно определить с помощью логических выражений, использующих любые переменные текущего набора данных).
Информация, представленная на этом графике, в точности та же, что и на некатегоризованной трехмерной диаграмме рассеяния, или диаграмме линий уровня, или графике поверхности, за исключением того, что для каждой заданной пользователем группы наблюдений строится один график.
Основное назначение данного графика — облегчить сравнение групп или категорий независимо от соотношений между тремя или более переменными.
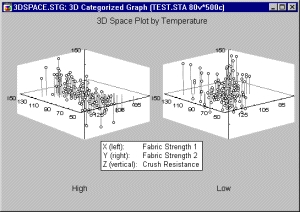
В основном трехмерные XYZ графики обобщают соотношения между тремя переменными. Различные способы, которыми могут быть категоризованы данные, позволяют посмотреть состав этих соотношений с помощью какого-либо другого критерия (например, групповой принадлежности).
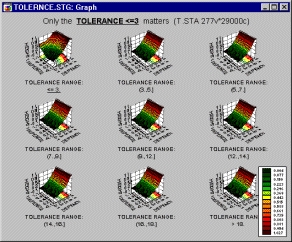
Заметьте, что эффект более заметен, если переключиться на режим отображения линий уровня.
Категоризованные тернарные графики
Категоризованные тернарные графики можно использовать для исследования соотношений между компонентами смеси, сумма значений которых равна константе, для каждого уровня группирующей переменной.
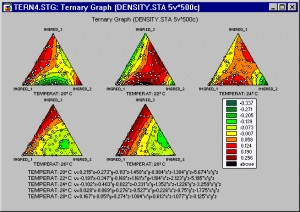
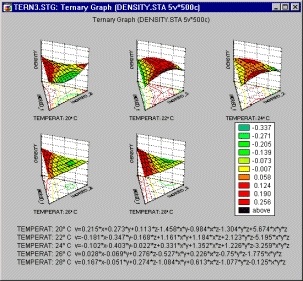
На тернарных графиках для построения четырех (или более) переменных (компоненты X, Y, и Z, отклики V1, V2 и т. д.) в двух (тернарные диаграммы рассеяния или линии уровня) или трех измерениях (тернарные графики поверхности) используются треугольные системы координат.
В категоризованных тернарных графиках для каждого уровня группирующей переменной (или заданного пользователем набора данных) строится один составной график, и все составные графики отображаются на одном экране, чтобы можно было производить сравнения наборов данных (групп).
Типичным приложением этих графиков является эксперимент с результатами, зависящими от относительных пропорций компонентов, входящих, например, в состав нового лекарства, моющего вещества или духов, которые варьируются с целью определения оптимального состава.
Этот тип графиков также можно использовать в случаях, когда соотношения между связанными переменными нужно сравнить внутри групп данных.
|
|
