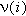 , которое сравнивается со средней или ожидаемой при гипотезе частотой, обозначение
, которое сравнивается со средней или ожидаемой при гипотезе частотой, обозначение
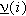 .
.
Подгонкой (английский термин fitting) называют аналитические процедуры, позволяющие подобрать распределение, которое с достаточной степенью точности описывает наблюдаемые данные. Типы различных распределений описаны выше в главе Вероятностные распределения.
Итак, имея значения переменной X, мы проверяем гипотезу, согласно которой распределение X описывается вероятностным законом F.
Одним из популярных и простых критериев согласия наблюдаемых данных с гипотезой является критерий хи-квадрат Пирсона.
Для применения этого критерия область значений переменной X вначале разбивается на некоторое число интервалов N. Затем подсчитывается число наблюдений, попавших в i-й интервал, обозначение
, которое сравнивается со средней или ожидаемой при гипотезе частотой, обозначение
.
Формально статистика хи-квадрат вычисляется как:
Хи-квадрат = S((n(i) - n(i))**2)/_n(i).
В этой формуле суммирование распространяется на все интервалы, на которые разбита область значений переменной.
Взглянув на формулу, вы легко поймете, что статистика хи-квадрат разумно сравнивает наблюдаемые и ожидаемые частоты. Статистика принимает значения от нуля до бесконечности. Чем меньше значение статистики хи-квадрат, тем более вероятно, что гипотеза верна, чем больше значение статистики хи-квадрат, тем меньше вероятность того, что гипотеза соответствует данным.
Итак, статистика хи-квадрат — это разумная мера согласия (соответствия) данных с гипотезой. Конечно, вы можете предложить собственную меру, например, вместо квадрата в приведенной формуле использовать модуль или четвертую степень.
Замечательно, что выборочное распределение статистики хи-квадрат при гипотезе приближенно является распределением хи-квадрат с числом степеней свободы N - 1 (число интервалов группировки минус 1) и не зависит от закона F. Точность приближения, грубо говоря, зависит от числа наблюдений (что вполне естественно).
Итак, предположив на минуту, что у вас имеется достаточно данных, вы можете считать, что статистика хи-квадрат имеет в точности распределение хи-квадрат, и рассчитать вероятность ошибки, связанной с отклонением правильной гипотезы.
Тонкости применения:
В системе STATISTICA все необходимые вычисления и поправки на число степеней свободы производятся автоматически.
Пример подгонки к данным нормального распределения был описан ранее в главе 2. В данной главе покажем, как с помощью системы STATISTICA подгоняются другие распределения.
Пример 1. Подгонка распределения к данным: посещение непопулярного сайта
Рассмотрим данные о числе посетителей нераскрученного сайта.
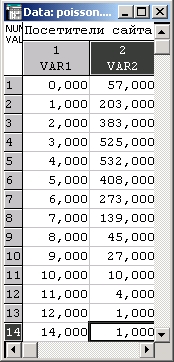
Из файла видно, что за 57 часов — сайт не посетило ни одного человека (первая строка файла), за 203 часа — на сайте находился 1 человек (вторая строка), за 383 часа —2 человека и т. д.
Спрашивается, какой вероятностный закон описывает эти данные?
Графически данные представляются в виде:
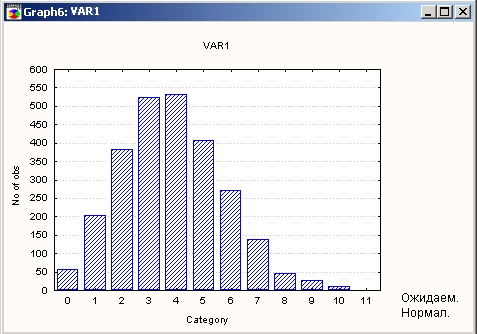
Переменная, описывающее число посетителей (переменная varl), принимает дискретные значения.
Проведем анализ в модуле Непараметрические статистики и подгонка распределений.
Шаг 1. Откройте модуль Непараметрические статистики и подгонка распределений.
Выберите опцию Подгонка распределения.
В окне Дискретные распределения выберите распределение Пуассона (дважды щелкните мышью).
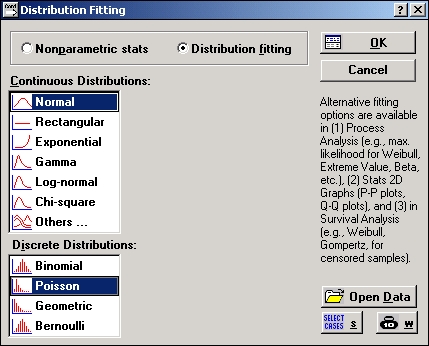
Шаг 2. На экране появится следующее окно:
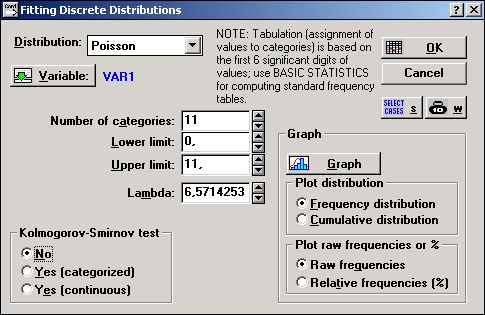
Нажмите кнопку Переменная и выберите переменную varl для анализа.
Шаг 3. Нажмите кнопку веса В, расположенную в правом верхнем углу диалогового окна Подгонка дискретных распределений.
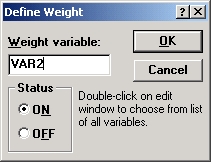
В появившемся окне Задание веса сделайте установки, как показано на рисунке ниже; веса, в данном случае частоты, взяты из переменной var2. Нажмите ОК. Затем нажмите ОК в диалоговом окне Подгонка дискретных распределений.
Шаг 4. Программа вычислит оценку параметра распределения Пауссона, равную 3,864, а также представит результаты в следующих таблицах.
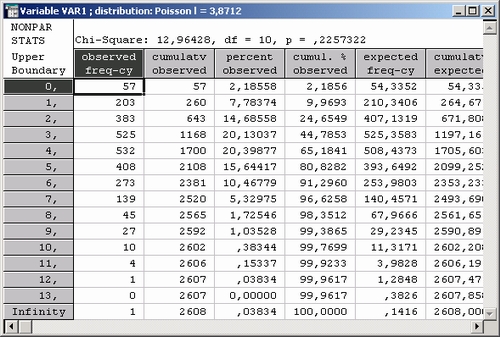
По уровню значимости р = 0,194 можно сделать вывод о том, что данные не противоречат гипотезе о пуассоновском распределении. Вероятность ошибиться при отклонении гипотезы довольно велика, примерно 0,2. Риск ошибиться достаточно велик!
Для построения гистограммы установите переключатель в положение Гистограмма.
Нажмите кнопку График в диалоговом окне Подгонка дискретных распределений. На экран будет выведена гистограмма с наложенным графиком ожидаемых пуассоновских частот.
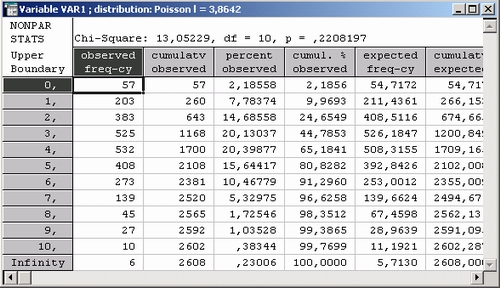
Проверим, как согласуются другие распределения с данными. В качестве примера рассмотрим биномиальное распределение.
Шаг 1. Вновь войдите в стартовую панель модуля. Проведем для биномиального распределения тот же анализ и сравним полученные результаты. В окне Распределение выберите биномиальное распределение.
Шаг 2. Нажмите кнопку Переменные и, как и в первом случае, выберите для анализа переменную varl.
Шаг 3. В случае биномиального распределения также необходимо задать веса наблюдениям. Нажмите кнопку веса В в правом верхнем углу диалогового окна. В появившемся окне Задание веса сделайте установки, как показано на рисунке ниже, где веса, в данном случае частоты, взяты из переменной var2. Нажмите ОК.
Затем нажмите ОК в диалоговом окне Подгонка дискретных распределений.
Шаг 4. Биномиальное распределение имеет один параметр — вероятность успеха р. Программа оценит эту вероятность, используя метод максимального правдоподобия. Оцененное значение 0,35129 появится в верхней полосе таблицы.
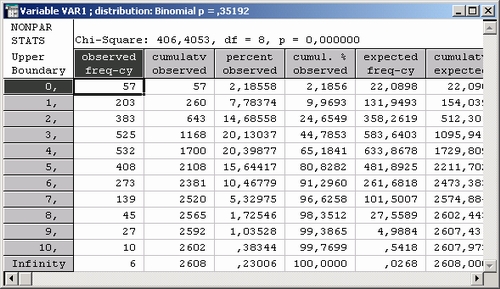
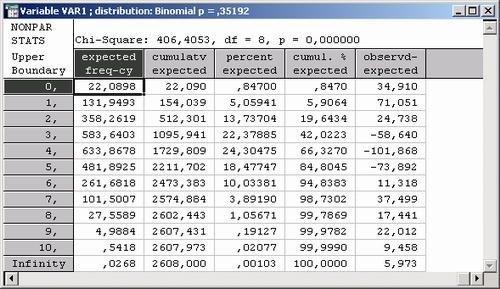
Шаг 5. Обратите внимание на значение статистики хи-квадрат, число степеней свободы и уровень значимости в данном данном примере.
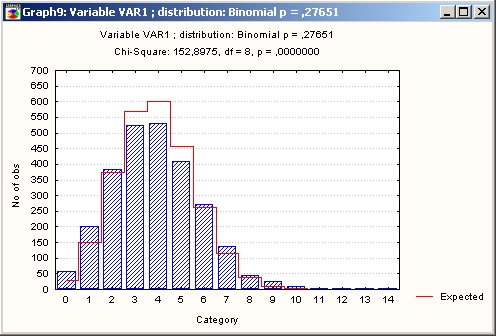
Статистика хи-квадрат принимает очень большое значение, а именно 383 (см. заголовок таблицы).
Число степеней свободы равно 8 (количество интервалов группировки минус 1 минус один оцененный параметр).
Из заголовка таблицы также видно следует, что гипотезу о согласии данных с биномиальным распределением можно отвергнуть на уровне 0,0000. Иными словами, отвергая гипотезу о биномиальном распределении, мы рискуем ошибиться с практически нулевой вероятностью.
Таким образом, делаем вывод: данные абсолютно не согласуются с биномиальным распределением.
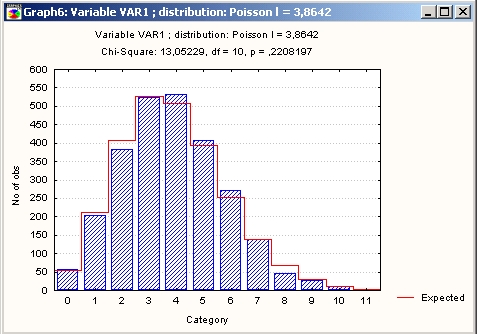
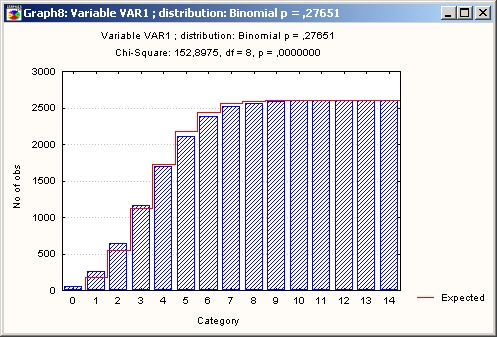
Тот же результат можно увидеть, конечно, и на графике.
Нажав кнопку График (см. окно Подгонка дискретных распределений), постройте гистограмму и график накопленных (кумулятивных) частот (выберите соответствующие опции в правой части окна).
Для того чтобы построить график распределения, установите переключатель в положение Кумулятивное распределение и нажмите кнопку График.
Как видите, наблюдаемые частоты далеки от ожидаемых частот.
Таким образом, биномиальное распределение не подходит для описания данных о числе посетителей нераскрученного сайта. Посещения нераскрученного сайта по сути являются редкими событиями, и для их описания следует использовать пуассоновское распределение.
Пример 2. Подгонка распределения к данным: посещение популярного сайта
В течение нескольких сотен часов регистрировалось число посетителей популярного сайта. Результаты приведены в таблице:
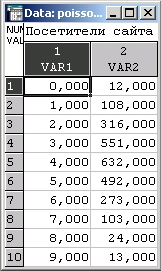
Интерпретация этих данных проста: за 12 часов — сайт не посетило ни одного человека (первая строка файла), за 108 часов — на сайте находился 1 человек (вторая строка), за 316 часов — 2 человека и т. д.
Графически данные представляются в следующем виде:
Переменная, описывающее число посетителей, принимает дискретные значения.
Спрашивается, какой вероятностный закон описывает эти данные?
Проведем анализ в модуле Непараметрические статистики и подгонка распределений.
Шаг 1. Откройте модуль Непараметрические статистики и подгонка распределений.
Выберите опцию Подгонка распределения.
В окне Дискретные распределения выберите биномиальное распределение (дважды щелкните мышью).
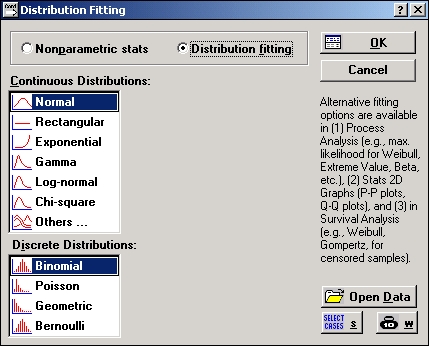
Шаг 2. На экране появится следующее окно:
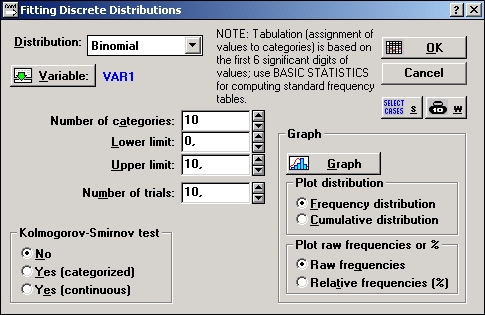
Нажмите кнопку Переменные и выберите переменную varl для анализа.
Шаг 3. Нажмите кнопку веса В в правом верхнем углу диалогового окна Подгонка дискретных распределений.
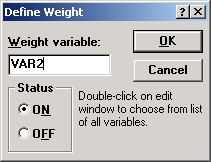
В появившемся окне Задание веса сделайте установки, как показано на рисунке ниже; веса, в данном случае частоты, взяты из переменной var2. Нажмите ОК. Затем нажмите ОК в диалоговом окне Подгонка дискретных распределений.
Шаг 4. Программа вычислит оценку параметра биномиального распределения и представит результаты в следующих таблицах:
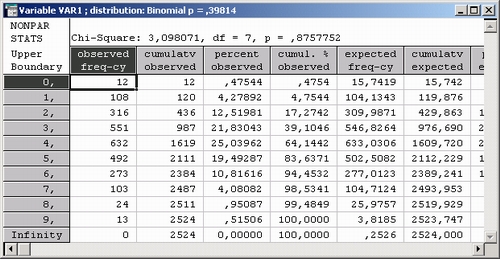
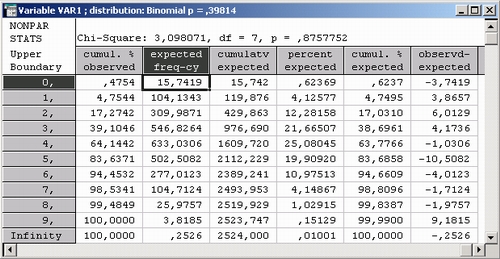
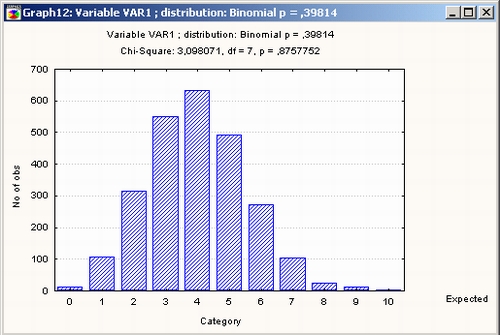
Значение статистики хи-квадрат очень небольшое, всего 4,16. Вспомните, что небольшие значения статистики хи-квадрат свидетельствуют в пользу гипотезы. Вопрос, что такое большое и что такое небольшое значение статистики, снимается понятием уровня значимости.
По уровню значимости р = 0,7612366 окончательно заключаем, что данные хорошо согласуются с гипотезой о биномиальном распределении.
Мы настоятельно рекомендуем вам еще раз прочитать ту часть главы Элементарные понятия, где обсуждается понятие статистического критерия.
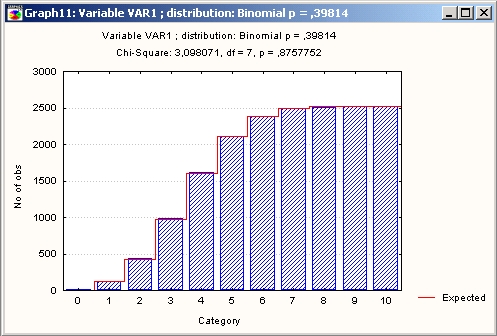
Проиллюстрируем приведенные выше таблицы графиком кумулятивного распределения. Для этого установите переключатель в положение Кумулятивное распределение и нажмите кнопку График.
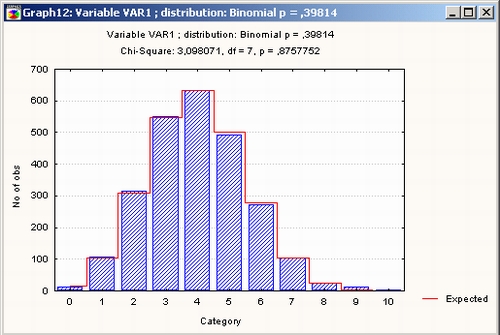
Для получения простой гистограммы установите переключатель в положение Гистограмма.
Нажмите кнопку График в диалоговом окне Подгонка дискретных распределений. На экране появится гистограмма наблюдаемых частот с наложенным графиком ожидаемых частот.
В качестве легкого упражнения мы рекомендуем вам попробовать подогнать пуассоновское распределение к данным о числе посетителей популярного сайта.
Пример 3. Скачки вверх и вниз курса акций
Ниже показан фрагмент файла, содержащего колебания курса акций в течение дня. Единица показывает, что курс пошел вверх (скачок вверх), 0 — курс акций пошел вниз (скачок вниз).
В течение дня таких скачков может быть несколько сотен. Выдвигается гипотеза, что частота тех и других скачков одинакова. Как быстро проверить эту гипотезу в системе STATISTICA?
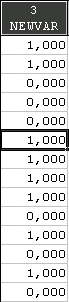
Выделите данные и вызовите Быстрые основные статистики... Вы увидите следующую таблицу результатов:

Точечная оценка частоты появления 1 равна 0,39, 95% доверительный интервал: (0,292732,0,487268). Следовательно, гипотеза о том, что частота скачков уровня вверх и вниз одинакова, должна быть отвергнута.
Пример 4. Количество покупок в магазине
Ниже показан файл с информацией о числе покупателей разной категории в супермаркете.
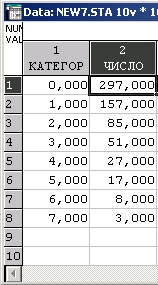
Мы разбили покупателей на классы по числу сделанных покупок.
К категории 0 относятся покупатели, сделавшие не более 4 покупок, к категории 1 — покупатели, сделавшие 5-6 покупок, к категории 2 — покупатели, сделавшие 7-8 покупок, и т. д.
Найдем вероятностный закон, который описывает эти данные. Вы можете подготовить файл данных и повторить за нами все действия.
Шаг 1. Откройте модуль Непараметрические статистики и подгонка распределений.
Выберите опцию Подгонка распределения. В окне Дискретные распределения выберите геометрическое распределение (дважды щелкните на его названии мышью).
Шаг 2. На экране появится следующее окно:
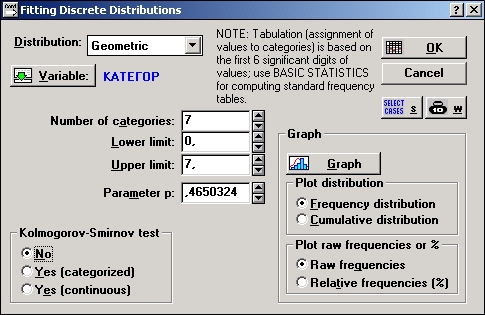
Нажмите кнопку Переменные и выберите переменную КАТЕГОР для анализа.
Шаг 3. Нажмите кнопку веса В в правом верхнем углу диалогового окна Подгонка дискретных распределений.
В появившемся окне Задание веса сделайте установки, как показано на рисунке ниже; веса (в данном случае — частоты) взяты из переменной ЧИСЛО. Нажмите ОК. Затем нажмите ОК в диалоговом окне Подгонка дискретных распределений.
Шаг 4. Система вычислит оценку параметра геометрического распределения и представит результаты в следующих таблицах.
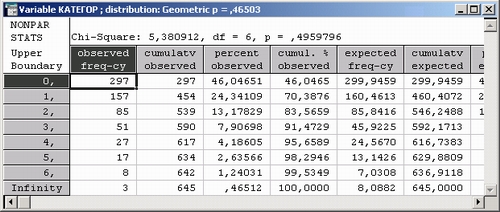
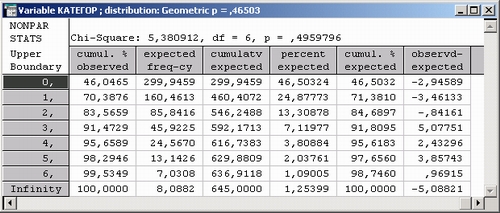
По уровню значимости р = 0,4959796 можно сделать вывод, что данные совместимы с гипотезой о геометрическом распределении.
Иными словами, наш риск ошибиться составляет примерно 50%, если мы отвергаем гипотезу.
Визуально качество подгонки можно увидеть на графике.
Нажмите кнопку График, и следующая гистограмма появится на экране:
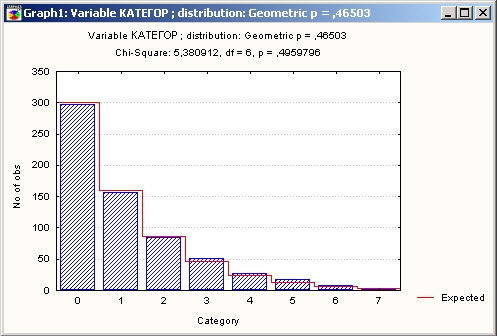
Вы можете попробовать другие распределения для описания этих данных и убедиться, что они очень плохо подходят к ним.
Итак, геометрическое распределение вполне адекватно описывает число покупателей разных категорий в супермаркете.
Пример 5. Подгонка распределения Вейбулла к данным об отказах
Одним из основных понятий качества продукции является ее надежность. Для оценки надежности и времени жизни разработаны различные статистические методы.
Надежность продукции является важным показателем качества. Покупая магнитофон, пылесос, кофеварку, вы, конечно, хотите иметь представление об их надежности. Особенный интерес представляет количественная оценка надежности, позволяющая оценить ожидаемое время жизни, или, в инженерных терминах, время безотказной работы купленного прибора.
Надежность связана с маркетинговой политикой, зная оценки надежности продаваемых вами бытовых приборов и объемы продаж, вы можете рассчитать количество гарантийных мастерских в городе.
Пример из другой области позволяет по-иному взглянуть на ту же ситуацию. Предположим, вы летите на маленьком личном самолете с единственным двигателем. Тогда для вас жизненно важно знать вероятность отказа двигателя на различных этапах его эксплуатации (например, после 500 часов, после 1000 часов и т. д.) Очевидно, имея хорошую оценку надежности двигателя и доверительный интервал, можно принять рациональное решение о том, когда следует заменить двигатель или отправить его на капитальный ремонт. Конечно, вы можете положиться на волю случая и летать, сколько угодно, однако цель нашей книги — научить вас рационально анализировать случайность.
Обычно времена жизни описываются распределением Вейбулла (см. предыдущую главу), поэтому одним из основных этапов статистических процедур, связанных с оценкой надежности, является оценка параметров этого распределения.
Для большинства исследуемых приборов функция интенсивности отказов имеет форму U-образной кривой; на ранней стадии жизни изделия риск выхода из строя (отказ) достаточно велик, далее интенсивность отказов уменьшается до определенного предела (оптимальный режим функционирования), затем вновь увеличивается из-за износа изделия.
Например, автомобили в начале эксплуатации часто имеют несколько мелких дефектов и выходят из строя. После того как автомобиль прошел обкатку, риск поломки существенно уменьшается. Затем интенсивность отказов (выходов из строя) возрастает, достигая своего максимального значения, например, после 20 лет эксплуатации и 250 000 миль пробега, когда практически любой автомобиль выходит из строя.
Распределение Вейбулла позволяет гибко моделировать возникающие на практике функции интенсивности отказов.
Задавая разные параметры распределения, можно получить практически любые функции риска.
Ранняя фаза кривой аппроксимируется распределением Вейбулла с параметром формы меньше 1, постоянная фаза — распределением Вейбулла с параметром формы 1, а фаза старения или износа моделируется распределением Вейбулла с параметром формы больше 1.
После того как на основе реальных данных оценены параметры распределения Вейбулла, можно вычислить различные характеристики надежности, например, когда откажет заданная доля тестируемых приборов.
Функция надежности, обычно обозначаемая R(t), представляет собой вероятность того, что объект проживет больше t временных единиц.
Формально функция надежности определяется равенством R(t)=1-F(t)), где F — функция распределения времени жизни. Иногда функция надежности называется также функцией выживания.
Цензурирование. В большинстве исследований по надежности не все объекты завершаются отказами. Иными словами, к концу исследования известно, что определенное количество приборов не отказало, но исследование завершено и точные времена жизни этих приборов неизвестны. Такие наблюдения называются неполными или цензурированными. Заметим, что цензурирование может осуществляться разными способами, так же как имеется много различных планов тестирования приборов.
Например, так называемое цензурирование типа I применяется в ситуации, когда заранее фиксируется время наблюдения отказов (допустим, мы берем 100 ламп и оканчиваем эксперимент, например, после 120 часов после начала).
В этом случае время эксперимента фиксировано, и число отказавших (перегоревших) ламп представляет собой случайную величину.
При цензурировании типа II заранее определяется доля отказов, но время наблюдения не ограничивается (например, мы проводим эксперимент, пока не выйдут из строя 50% компьютеров при данных критических условиях). Очевидно, что при таком подходе время, в течение которого проводится эксперимент, является случайной величиной.
Можно задать также направление цензурирования. При испытании компьютеров или ламп цензурирование происходит в правом направлении по временной оси (правое цензурирование), потому что исследователь точно фиксирует начало
эксперимента и знает, что неотказавшие компьютеры будут еще жить некоторое время после окончания эксперимента. Другой вариант возникает, когда исследователю неизвестно начало времени жизни объекта, например, врачу известен момент поступления пациента в госпиталь с данным диагнозом, но неизвестен момент, когда данный диагноз был поставлен, и тем более неизвестно, когда болезнь началась. Такое цензурирование называется левым.
Конечно, если тестируются старые компьютеры или мониторы, то это тоже пример левого цензурирования, т. к. не известен момент начала их эксплуатации.
Наконец, возможны ситуации, в которых цензурирование происходит в различные моменты времени (многократное цензурирование) или только в один момент времени (однократное цензурирование).
Возвращаясь к эксперименту с тестированием компьютеров в экстремальных словиях, заметим, что если эксперимент заканчивается в определенный момент времени, то мы имеем однократное цензурирование.
Конечно, имеются нетривиальные ситуации, например, данные, собранные директором фирмы по продаже подержанных копировальных аппаратов. Балансируя между необходимостью продаж и выдачей гарантий покупателю, ему следует национально организовать процесс продаж.
Рассмотрим, как оцениваются параметры распределения Вейбулла в системе STATISTICA при простейшем правом однократном цензурировании. Данные содержатся в файле Dodson25.sta.
Запустите модуль Анализ процессов и повторите вслед за нами наши действия.
Шаг 1. Откройте файл Dodson25.sta, затем выберите Анализ Вейбулла... на стартовой панели.
Рассмотрим опции окна.
Тип анализа.
Исходные данные: Используйте этот диалог, если вы анализируете исходные времена отказов с цензурированием или без него.
Группированные данные: Используйте диалог для исследования агрегированных или табулированных времен отказов, например, таблиц жизни.
Распределение Вейбулла, вероятностный график: Открывается диалоговое окно, в котором вы можете построить вероятностный график распределения Вейбулла, аналогичный нормальному вероятностному графику (графику на нормальной вероятностной бумаге в старой терминологии).
В данном примере используйте анализ исходных данных.
Времена отказов: Эта опция выбирается в том случае, когда данные содержат действительные времена отказов.
Единственная переменная для времен отказов (жизни), переменные с началом и концом, переменные с датами: Опция выбирается в тех случаях, когда данные содержат даты с началом или концом каждого наблюдения. Из файла данных программа вычислит разность между временем конца и временем начала, чтобы получить чистые времена отказов для каждого наблюдения, и затем подгонит к ним распределение Вейбулла.
Если выбран Список переменных с временами, программа ожидает ввода одной или нескольких переменных с временами отказов и дополнительного ввода индикатора цензурирования (группирующей) переменной, которая позволяет определить, какие времена полные, а какие цензурированы.
Если выбрана опция Одна t отказов, две (начало и конец) или шесть (даты), то вы можете в первом списке переменных: 1) выбрать одну переменную с временами отказов, 2) выбрать две переменные с временами начала и конца (наблюдения объекта), 3) выбрать 6 переменных, которые также будут рассматриваться как времена начала и конца (как и в случае 2 выше). Эти 6 переменных рассматриваются как месяц, день, год начала и как месяц, день, год окончания испытания.
Выберите переменные для анализа, цензурирующие переменные (индикаторы цензурирования) и коды. Затем нажмите ОК; по умолчанию программа вычислит оценки максимального правдоподобия параметров для двухпараметического распределения Вейбулла и перейдет в диалоговое окно Результаты анализа Вейбулла. Заметим, что если оценки максимального правдоподобия не существуют, процедура использует 0, 1, 1 для оценки параметров положения, формы и масштаба соответственно.
Близкие процедуры содержатся в модуле Анализ выживаемости; для нецензрированных или полных данных можно использовать визуальные методы графики Квантиль-квантиль и Вероятность-вероятность (см. главу Визуальные методы анализа).
Выберите переменную Time, содержащую времена отказов, и переменную Cens — индикатор цензурирования.
Эта переменная содержит два значения, показывающие, полностью или нет наблюдались изделия до момента отказа. Заметим, что такая ситуация (наличие двух типов наблюдений) отличается от той, с которой мы имели дело в модуле непараметрические статистики. Точно с такими же типами наблюдений мы имеем дело в модуле анализ выживаемости.
Коды для полных и цензурированных наблюдений.
Эта опция доступна, если выбран индикатор цензурирования. Определите коды или текстовые значения для полных (нецензурированных) и неполных (цензурированных ) наблюдений. Чтобы просмотреть все коды соответствующей переменной, дважды щелкните на поле ввода. Первые два различных значения, обнаруженных в индикаторе цензурирования, используются по умолчанию как коды для полных и цензурированных данных соответственно.
Выберите Complete для полных времен и Censored для цензурированных времен. Нажмите ОК, чтобы начать анализ.
Опция: Прибавить пост, к нулевым t отказов/цензур, значениям.
Распределение Вейбулла ограничено слева, это означает, что все значения выборки должны быть больше параметра положения, по умолчанию равного 0. Если опция выбрана, программа перед подгонкой или построением графика заменит нулевые времена отказов константой из поля. Если опция не выбрана, все наблюдения с нулевыми временами отказов исключаются из анализа (рассматриваются как пропущенные данные).
Шаг 2. По умолчанию программа вычислит оценки максимального правдоподобия для двухпараметрического распределения Вейбулла, предполагая, что параметр положения равен 0. В окне Результаты анализа эти оценки можно увидеть в зоне Значения/оценки текущих параметров.
Оценки параметров. Окно результатов позволяет интерактивно провести подгонку к данным распределения Вейбулла с различными параметрами.
После того как вы нажмете кнопку Форма & масштаб, программа считает текущее значение параметра положения и вычислит оценки максимального правдоподобия параметров формы и масштаба.
Если вы нажмете кнопку Форма, масштаб, положение, программа вычислит оценки максимального правдоподобия для трехпараметрического семейства. В любом случае оценки будут отображены в полях значения/оценки текущих параметров.
Шаг 3. Просмотр результатов. Все опции, доступные в окне результатов на текущих значениях параметров, указанных в полях значения/оценки текущих параметров независимо от того, определены эти параметры пользователем или оценены программой (например, методом максимального правдоподобия). Однако стандартные ошибки функции надежности можно вычислить только для оценок максимального правдоподобия.
Оценки максимального правдоподобия двухпараметрического распределения Вейбулла равны 3,034 и 216,9 для параметров формы и масштаба (см. рисунок).
Вы можете сравнить эти оценки с оценками, построенными с помощью графиков: выберите опцию Непараметрические рамке Дов. интервалы (нижний левый угол). Тогдa все графики будут построены на основе непараметрических (ранговых) оценок функции распределения F(t), и результирующий график может быть использован для оценки ;: параметров распределения Вейбулла. Нажмите кнопку График распределения и построите график.
Этот график показывает наблюдаемые времена отказов, линейную подгонку и 5%-й непараметрический доверительный интервал функции надежности (более точно, log-log-преобразование; доверительный интервал показан прерывистой линией).
Оценки параметров формы и масштаба вычисляются из коэффициента наклона и свободного члена линейной подгонки: параметр формы равен коэффициенту наклона, параметр масштаба оценивается как exp(-intercept/slope).
Эти оценки параметров очень близки к оценкам максимального правдоподобия. Т. к. точки достаточно точно ложатся на прямую, мы можем поверить, что распределение Вейбулла с оцененными параметрами вполне адекватно данным.
Нажмите кнопку Функция надежности и доверительные интервалы, и вы увидите результаты в численном виде.
Критерии согласия. Если вы нажмете кнопку Критерии согласия, то увидите таблицу со статистиками Холландера—Прошана или Манна—Шойера — Фертига и их уровнями значимости.
Критерий Холлендера—Прошана. Этот критерий сравнивает теоретическую функцию надежности с оценкой Каплана-Мейера. Точные формулы вычисления достаточно сложны. Критерий Холлендера-Прошана применяется к полным, однократно цензурированным и многократно цензурированным данным, однако имеет место недостаток этого критерия в некоторых случаях, например, когда данные сильно цензурированы. STATISTICА вычисляет значение критериальной статистики и двухсторонний уровень значимости р.
Критерий Манна—Шойера—Фертига. Критерий был предложен Манном, Шойером, Фертигом в 1973 г.
Нулевая гипотеза состоит в том, что данные имеют распределение Вейбулла с оцененными параметрами. Нельсон (см.: Nelson (1982) Applied life data analysis. New York: Wiley) отмечает большую мощность этого критерия. Критические значения вычислены методом Монте Карло и табулированы для объемов выборки от 3 до 25; для больших объемов выборок критерий не применяется.
Шаг 4. Оценки параметра положения. Хотя подгонка двухпараметрического распределения Вейбулла кажется очень хорошей, предположим, что у вас имеются некоторые доводы в пользу того, что параметр положения больше 0. Иными словами, вы уверены, что имеется интервал, в течение которого вероятности отказов нет. Оценим этот параметр положения. Нажмите кнопку R-квадрат и параметр положения. Этот график показывает зависимость коэффициента детерминации R-квадрат от параметра положения.
Далее нажмите кнопку Форма, масштаб, положение, чтобы вычислить оценки максимального правдоподобия для трехпараметрического распределения Вейбулла.
Для этих данных лучше применять более простую двухпараметрическую модель с параметром положения, равным 0.
Шаг 5. Процентили и доверительные интервалы. Нажмите кнопку Процентили и доверительный интервал, чтобы построить таблицу с процентными точками функции надежности.
Таблица содержит процентили с приращением 1%: 1, 2,3,4 и т. д.
Прокрутив таблицу, вы увидите, например, что оценка медианы равна 192,2, а 95% доверительный интервал имеет границы от 154,9996 до 238,437.
Другими словами, можно ожидать, что 50% отказов происходит до момента времени t=192,2 (с соответствующим доверительным интервалом).
|
|
