
В этой главе предлагается краткое обсуждение элементарных статистических понятий, лежащих в основе процедур в любой области статистического анализа данных. Выбранные нами темы иллюстрируют основные допущения, принимаемые в большинстве статистических методов для описания «численной природы» действительности, а изложение ведется на языке, доступном для широкого круга читателей.
Мы начнем с самых простых, интуитивно ясных понятий и рассмотрим связи между ними, фактически представим описание языка, на котором говорят при проведении анализа данных.
Переменная (английский термин variable) — это то, что можно измерять, контролировать или чем можно манипулировать в исследованиях. Иными словами, переменная — это то, что варьируется, изменяется, а не является постоянным (от английского корня var).
Например, измеряя давление или содержание лейкоцитов в крови, вы получаете различные значения у разных пациентов или значения для одного и того же пациента в разное время суток. Измеряя уровень осадков, получаете различные значения в разные дни недели, а также различные значения в одни и те же дни в разных точках географической карты.
Другие примеры переменных из разных областей: анкетные данные, систолическое давление пациентов, количество лейкоцитов в крови, цена акций, товаров, услуг, потребление, инвестиции, доход, государственные закупки товаров и услуг, инструмент государственного регулирования (в экономике); рейтинг программ, доля зрителей, количество посещений сайта (в рекламе); скорость, температура, объем, масса в (физике) и т. д.
Очевидно, что это очень разные по своим свойствам переменные, и поэтому можно сказать, что переменные отличаются характеристиками, в частности, той ролью, которую они играют в исследованиях, типом измерений и т. д.
Простейшие описательные статистики
Так как значения переменных не постоянны, нужно научиться описывать их изменчивость.
Для этого придуманы описательные или дескриптивные статистики: минимум, максимум, среднее, дисперсия, стандартное отклонение, медиана, квартили, мода и т. д.
Идея этих статистик очень проста: вместо того чтобы рассматривать все значения переменной, а их может быть очень много (тысячи и миллионы), вначале стоит просмотреть описательные статистики. Они дают общее представление о значениях, которые принимает переменная.
Минимум и максимум — это минимальное и максимальное значения переменной.
Среднее — сумма значений переменной, деленная на n (число значений переменной).
Дисперсия (от английского variance) и стандартное отклонение (от английского standard deviation) — наиболее часто используемые меры изменчивости переменной. Дисперсия меняется от нуля до бесконечности. Крайнее значение 0 означает отсутствие изменчивости, когда значения переменной постоянны.
Стандартное отклонение вычисляется как корень квадратный из дисперсии. Чем выше дисперсия или стандартное отклонение, тем сильнее разбросаны значения переменной относительно среднего. Часто стандартное отклонение — более удобная характеристика, т. к измерена в тех же единицах, что исходная величина.
Медиана разбивает выборку на две равные части. Половина значений переменной лежит ниже медианы, половина — выше.
Медиана дает общее представление о том, где сосредоточены значения переменной, иными словами, где находится ее центр. В некоторых случаях, например при описании доходов населения, медиана более удобна, чем среднее.
Квартили представляют собой значения, которые делят две половины выборки (разбитые медианой) еще раз пополам.
Таким образом, медиана и квартили делят диапазон значений переменной на четыре равные части.
Различают верхнюю квартиль, которая больше медианы и делит пополам верхнюю часть выборки (значения переменной больше медианы), и нижнюю квартиль, которая меньше медианы и делит пополам нижнюю часть выборки.
Нижнюю квартиль часто обозначают символом 25%, это означает, что 25% значений переменной меньше нижней квартили.
Верхнюю квартиль часто обозначают символом 75%, это означает, что 75% значений переменной меньше верхней квартили.
Мода представляет собой максимально часто встречающееся значение переменной (иными словами, наиболее «модное» значение переменной), например, популярная передача на телевидении, модный цвет платья или марка автомобиля и т. д.
С описательными статистиками связаны статистические графики, например, приведенный ниже график наглядно показывает, как распределены значения переменной (подробнее см. главу Визуальный анализ данных):
Взгляните на график.
На графике приведены описательные статистики для переменной Уровень осадков. Хорошо видно, как распределены значения переменной: от минимального уровня (16 дюймов) до максимального уровня (39 дюймов).
Половина значений переменной лежит ниже 27,5 дюйма, то есть в половине всех наблюдаемых месяцев уровень осадков был меньше 27,5 дюйма. Половина значений осадков лежит выше 27,5 дюйма, соответствуя тому, что в половине наблюдаемых месяцев уровень осадков был выше 27,5 дюйма.
Свойства описательных статистик
Опишем более формальные определения описательных статистик и их свойства.
Среднее xbar, или, точнее, оценка среднего, вычисляется просто как среднее арифметическое наблюдений. Оценку среднего называют также выборочным средним. Пусть вы наблюдаете значения Х(1), ..., X(N), например, отмечаете время, когда просыпаетесь утром.
Формула для выборочного среднего имеет вид: (xbar - (Х(1)) + ... +X(N))/N
Если в течение трех дней вы просыпались в 7.00, 8.30 и 6.15, то среднее время вашего подъема равно 7 час. 15 мин.
Выборочное среднее является той точкой, сумма отклонений наблюдений от которой равна 0. Формально это записывается следующим образом:
(xbar - Х(1)) + (xbar - Х(2)) + ... + (xbar - X(N)) = 0
Упражнение: используя определение среднего, убедитесь, что данное свойство действительно имеет место, то есть сумма отклонений наблюдаемых значений от среднего арифметического действительно равна 0.
Выборочное среднее — единственная точка, которая обладает данным свойством, и это выделяет ее среди всех других.
Кроме того, выборочное среднее обладает еще одним замечательным свойством: сумма квадратов расстояний между наблюдаемыми значениями и их средним арифметическим является минимальным. Если вместо среднего арифметического взять любую другую величину, то сумма квадратов расстояний между наблюдаемыми значениями и этой величиной будет только больше, но никак не меньше.
Дисперсия выборки, или выборочная дисперсия (термин впервые введен Фишером, 1918), вычисляется по формуле:
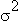 = (Xj - xbar)2/n - 1, где хbar — выборочное среднее,
n — число наблюдений в выборке.
= (Xj - xbar)2/n - 1, где хbar — выборочное среднее,
n — число наблюдений в выборке.
Стандартное отклонение равно корню квадратному из выборочной дисперсии.
Медиана выборки (термин был впервые введен Гальтоном, 1882) — значение, которое разбивает выборку на две равные части. Половина наблюдений лежит ниже медианы, и половина наблюдений лежит выше медианы.
Медиана вычисляется следующим образом. Выборка упорядочивается в порядке возрастания. Получаемая последовательность ak, где k=l,..., 2 х +1, называется вариационным рядом или порядковыми статистиками. Если число наблюдений нечетно, то медиана выборки оценивается как аm+1. Если число наблюдений четно, то медиана оценивается как (am+am+1)/2.
Медиана обладает следующим замечательным свойством: сумма абсолютных расстояний между точками выборки и медианой минимальна.
Квантиль (термин был впервые использован Кендаллом в 1940 г.) выборки представляет собой число хр, ниже которого находится р-я часть (доли) выборки.
Например, квантиль 0,25 для некоторой переменной — это такое значение (хр), ниже которого находится 25% значений переменной.
Аналогично квантиль 0,75 — это такое значение, ниже которого попадают 75% значений выборки.
Квартили. Нижняя и верхняя квартили, от слова кварта — четверть (термин впервые использовал Гальтон в 1882) равны соответственно 25-й и 75-й процентилям распределения.
25-я процентиль переменной — это значение, ниже которого располагаются 25% значений переменной.
Аналогично, 75-я процентиль равна значению, ниже которого расположено 75% значений переменной.
Итак, 3 точки — нижняя квартиль, медиана и верхняя квартиль — делят выборку на 4 равные части.
1/4 наблюдений лежит между минимальным значением и нижней квартилью, 1/4 — между нижней квартилью и медианой, 1/4 — между медианой и верхней квартилью, 1/4 — между верхней квартилью и максимальным значением выборки.
Квартальный размах. Квартальный размах переменных (термин был впервые использован Галтоном в 1882 г.) равен разности значений 75-й процентили и 25-й процентили. Таким образом, это интервал, содержащий медиану, в который попадает 50% наблюдений.
Мода. Мода (термин был впервые введен Пирсоном, 1894) — это наиболее часто встречающееся (наиболее модное) значение переменной.
Мода хорошо описывает, например, типичную реакцию водителей на сигнал светофора о прекращении движения.
Классический пример использования моды — выбор размера выпускаемой партии обуви или цвета обоев.
Если распределение имеет несколько мод, то говорят, что оно мультимодально или многомодально (имеет два или более «пика»).
Мультимодальность распределения дает важную информацию о природе исследуемой переменной.
Например, в социологических опросах, если переменная представляет собой предпочтение или отношение к чему-то, то мультимодальность может означать, что существуют несколько определенно различных мнений.
Мультимодальность также служит индикатором того, что выборка не является однородной и наблюдения, возможно, порождены двумя или более «наложенными» распределениями.
Асимметрия, или коэффициент асимметрии (термин был впервые введен Пирсоном, 1895), является мерой несимметричности распределения. Если этот коэффициент значительно отличается от 0, распределение является асимметричным (то есть несимметричным). Формально имеем:
Асимметрия = n x М3/[(n - 1) х (n - 2) x s3],
где
М3 равно (xi — среднееx)3,
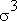 — стандартное отклонение (сигма), возведенное в третью степень,
— стандартное отклонение (сигма), возведенное в третью степень,
n — число наблюдений.
Эксцесс, или коэффициент эксцесса (термин был впервые введен Пирсоном, 1905), измеряет остроту пика распределения. Оценка эксцесса, или выборочный эксцесс, вычисляется по формуле:
Эксцесс = [n x (n+1)xМ4 - 3xМ2хМ2х(n -1)]/[(n -1)х(n -2)x(n -3)xs4],
где
Mj равен (Xj - среднееx)j,
n — число наблюдений,
 — стандартное отклонение (сигма), возведенное в четвертую степень.
— стандартное отклонение (сигма), возведенное в четвертую степень.
Переменные различаются тем, «насколько хорошо» они могут быть измерены, или, другими словами, как много измеряемой информации обеспечивает шкала их измерений, поскольку в каждом измерении присутствует некоторая ошибка, определяющая границы «количества информации», которую можно получить в данном измерении.
Другим фактором, определяющим количество информации, содержащейся в переменной, конечно, является тип шкалы, в которой проведено измерение. Вы можете считать, что шкала — это просто линейка: очень грубая, менее грубая, точная.
Обычно используют следующие типы шкал измерений:(а) номинальная, (b) порядковая (ординальная), (с) интервальная, (d) относительная (шкала отношения). Соответственно имеются четыре типа переменных: (а) номинальная, (b) порядковая (ординальная), (с) интервальная и (d) относительная.
(а) Номинальные переменные используются только для качественной классификации. Это означает, что данные переменные могут быть измерены только в терминах принадлежности к некоторым существенно различным классам, при этом вы не сможете определить количество или упорядочить эти классы. Тиличными примерами номинальных переменных являются фирма-производитель, тип товара, признак (болен — здоров) и т. д. Часто номинальные переменные называются категориальными. Близким к ним являются категоризованные переменные, то есть переменные, искусственно превращенные в категориальные (см. ниже).
(b) Порядковые переменные позволяют ранжировать (упорядочить) объекты, если указано, какие из них в большей или меньшей степени обладают качеством, выраженным данной переменной. Однако они не позволяют определить «на сколько больше» или «на сколько меньше» данного качества содержится в переменной.
Порядковые переменные иногда также называют ординальными. Типичный пример — социоэкономический статус семьи. Мы понимаем, что верхний средний уровень выше среднего уровня, однако сказать, что разница между ними равна, допустим, 18%, мы не можем. Само расположение шкал в порядке возрастания их информативности — номинальная, порядковая, интервальная — является хорошим примером порядковой переменной. Например, можно сказать, что измерения в номинальной шкале предоставляют меньше информации, чем в порядковой шкале, а в порядковой — меньше, чем в интервальной. Однако невозможно придать термину «меньше» точный количественный смысл или сравнить между собой эти различия.
Другой пример порядковой переменной — это интенсивность использования определенного цвета в картине художника.
Категориальные и порядковые переменные особенно часто возникают при анкетировании, т. к. естественно отражают характер мышления человека. Например, измерение интенсивности посещение ресторанов можно проводить в следующей шкале: не посещаю, посещаю редко, посещаю, посещаю часто.
Как легко понять, категориальные и порядковые шкалы часто используются для описания качественных признаков.
(c) Интервальные переменные позволяют не только упорядочивать объекты измерения, но и численно выражать и сравнивать различия между ними. Такого рода переменные часто возникают в естественных науках, при снятии показателей с физических приборов, в медицине и т. д. Например, температура, измеренная в градусах Фаренгейта или Цельсия, образует интервальную шкалу. Вы можете не только сказать, что температура 40 градусов выше, чем температура 30 градусов, но и то, что увеличение температуры с 20 до 40 градусов вдвое больше увеличения температуры от 30 до 40 градусов.
(d) Относительные переменные очень похожи на интервальные переменные. В дополнение ко всем свойствам переменных, измеренных в интервальной шкале, их характерной чертой является наличие определенной точки абсолютного нуля, таким образом, для этих переменных являются обоснованными утверждения типа: х в два раза больше, чем у. Например, температура по Кельвину образует шкалу отношения, и вы можете не только утверждать, что температура 200 градусов выше, чем 100 градусов, но и то, что она вдвое выше. Интервальные шкалы (например, шкала Цельсия) не обладают данным свойством шкалы отношения. Однако в большинстве статистических процедур не делается тонкого различия между свойствами интервальных шкал и шкал отношения.
Заметим, что всегда можно перейти от более богатой шкалы к менее богатой. Так, непрерывные переменные можно искусственно превратить в категориальные, то есть категоризоватъ.
Например, непрерывная переменная «рост человека в сантиметрах» может быть превращена в порядковую переменную с градациями: низкий, средний, высокий или очень низкий; низкий, средний, высокий, высокий*; или очень низкий, средненизкий, низкий, средний, высокий, очень высокий; для размера одежды используют следующую порядковую шкалу: S, M, L, XL, XXL, XXXL, XXXXL и т. д.
Категоризованные данные часто представляют в виде частот наблюдений, попавших в определенные категории или классы. Для описания категориальных переменных полезной оказывается мода.
В реальной жизни, например при проведении массовых опросов, мы имеем все типы переменных, представленных в одном исследовании.
Среднее и медиана оценивают положение центра выборки, вокруг которого группируются значения переменной.
Среднее обладает рядом замечательных свойств. Однако эта оценка чувствительна к выбросам, которые вносят в нее сдвиг. Чтобы избежать сдвига, иногда используют взвешенное среднее (каждому значению переменной приписывают определенный вес в соответствии с его важностью, а затем для взвешенных наблюдений вычисляется обычное среднее).
Медиана является средней точкой вариационного ряда, поэтому она не так чувствительна к выбросам.
В официальной статистике США именно медиана используется в качестве оценки центральной точки доходов населения.
Если распределение несимметрично (сдвинуто влево или вправо), то медиана л межквартильный размах могут дать больше информации о том, в какой области концентрируются наблюдения.
Если медиана меньше среднего, то распределение сдвинуто вправо. Если медиана больше среднего, то распределение сдвинуто влево.
Обычно имеется следующая схема выбора (при условии, что распределение имеет одну моду). Если данные категоризованы, то используйте моду. Если не все имеющиеся значения переменной представляют интерес, распределение несимметрично и имеются выбросы, используйте медиану. В противном случае работайте со средним.
Самый простой вопрос, который естественно задать, анализируя значения переменной — какова вероятность того, что переменная примет данное значение или значение из данного интервала. Иными словами, мы интересуемся тем, как распределены значения переменной.
Например, оценивается вероятность того, что брошенная монета выпадет гербом, вероятность того, что пациент проживет дольше определенного времени, или вероятность того, что доля дефектных изделий в партии меньше 95%.
Описательные статистики дают общую информацию о распределении переменной. Например, медиана отражает то, что с вероятностью 0,5 значение переменной будет больше данного значения или, наоборот, меньше этого значения.
Полный ответ дает функция распределения.
Пусть X — некоторая переменная, принимающая значения на прямой. Тогда функция распределения этой переменной, обозначаемая F(x), есть вероятность того, что Х<х.
Для описания реальных явлений статистиками используются различные распределения: нормальное, Стьюдента, хи-квадрат, Коши, биномиальное, отрицательное биномиальное и др. Распределения вероятностей, возникающие на практике, подробно описываются в отдельной главе.
Независимо от типа две или более переменных связаны (зависимы) между собой, если наблюдаемые значения этих переменных распределены согласованным образом.
Другими словами, мы говорим, что переменные зависимы, если их значения каким-то образом согласованы друг с другом в имеющихся наблюдениях. Заметьте, мы не определяем, как именно происходит это согласование, возможно, его вовсе нельзя записать в явном виде.
Например, переменные Пол и WCC (число лейкоцитов) могли бы рассматриваться как зависимые, если бы большинство мужчин имело высокий уровень WCC, а большинство женщин — низкий WCC, или наоборот. Итак, если бы у мужчин число лейкоцитов в крови было бы больше, чем у женщин, то можно сделать вывод: категориальная переменная Пол связана с переменной число лейкоцитов.
Если вы измеряете температуру человека сверхточными датчиками, то регистрируемые значения зависят от точки, в которой проводится измерение.
Рост человека очевидно связан с Весом, потому что обычно высокие индивиды тяжелее низких; IQ (коэффициент интеллекта) связан с Количеством ошибок в тесте, т. к. люди с высоким значением IQ, как правило, делают меньше ошибок, и т. д.
Другими типичными примерами связей являются: зависимость между объемом винчестера и его ценой. Если вы рассмотрите предложения в Интернет, то увидите, что логарифмическая зависимость хорошо описывает связь цена — объем для винчестеров, зависимость между длиной диагонали монитора и ценой монитора, зависимость между зерном и длиной диагонали экрана. В том же ряду находятся: зависимость между количеством транспортных средств и количеством аварий в городе, зависимость между эластичностью спроса и доходов, числом преступлений против собственности и душевым доходом, зависимость между количеством рассылок по почте и посещений сайта и т. д. Более экзотическим примером является зависимость рождаемости от дня недели.
Исследования зависимости между парой переменных, естественно, распространяется на исследование зависимостей между переменной и списком переменных,
между двумя или несколькими множествами переменных и т. д. (цена монитора зависит от фирмы-производителя, от диагонали, зерна, развертки, разрешения и других параметров).
Исследование связей между наблюдаемыми переменными в сравнении с экспериментальными исследованиями
Большинство эмпирических исследований данных можно отнести к одному из двух типов: либо это сбор данных и оценка связей между ними, либо прямой эксперимент, в котором фиксируются некоторые воздействия на объект исследования и регистрируется отклик.
В первом случае вы не влияете (или, по крайней мере, пытаетесь не влиять) на какие-либо переменные, а только собираете их значения и хотите найти зависимости (корреляции) между некоторыми измеренными переменными, например, между кровяным давлением и уровнем холестерина. Типичный пример здесь — космическая съемка больших участков Земли и попытка оценить или спрогнозировать урожайность (см., например, сайт американского госдепартамента с данными о сельхозпродукции http://www.nass.usda.gov/census/).
В экспериментальных исследованиях вы непосредственно и целенаправленно варьируете некоторые переменные и измеряете воздействия этих изменений на объект. Например, можете искусственно увеличить кровяное давление, а затем измерить уровень холестерина и проделать это несколько раз на ряде объектов.
В исследованиях зависимости спроса на товар от рекламы вы можете активно менять свою рекламную политику, но такая возможность отсутствует при исследовании большинства экономических данных в маркетинговых исследованиях, где вы просто собираете данные, а затем находите связи между ними (типичный пример — оценка доходов телевизионных компаний).
Анализ данных в экспериментальном исследовании также приходит к вычислению «корреляций» между переменными, а именно между переменными, на которые воздействуют, и теми переменными, на которые влияет воздействие. Тем не менее экспериментальные данные потенциально снабжают исследователей более качественной информацией.
Ключевым понятием, описывающим связи между переменными, является корреляция (от английского correlation — согласование, связь, взаимосвязь, соотношение, взаимозависимость); термин впервые введен Гальтоном (Gallon) в 1888 г.
Корреляция между парой переменных (парная корреляция).
Если имеется пара переменных, Тогда корреляция между ними — это мера связи (зависимости) именно между этими переменными.
Например, известно, что ежегодные расходы на рекламу в США очень тесно коррелируют с валовым внутренним продуктом, коэффициент корреляции между этими величинами (с 1956 по 1977 гг.) равен 0,9699. Число посещений сайта торговой компании тесно связано с объемами продаж и т. д.
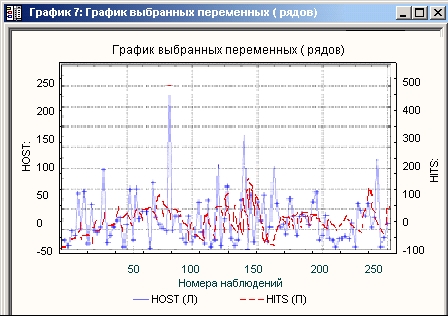
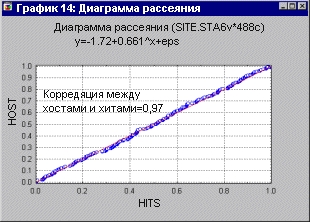
Также тесно коррелировано число хостов и число хитов на сайте (см. графики ниже).
Тесно связаны между собой такие, например, переменные, как температура воздуха и объем продажи пива, среднемесячная температура в данном месте текущего и предыдущего года, расходы на рекламу за предыдущий месяц и объем торговли в текущем месяце и т. д.
Корреляция между парой переменных называется парной корреляцией. Статистики предпочитают говорить о коэффициенте парной корреляции, который изменяется в пределах от -1 до +1.
В зависимости от типа шкалы, в которой измерены переменные, используют различные виды коэффициентов корреляции.
Если исследуется зависимость между двумя переменными, измеренными в интервальной шкале, наиболее подходящим коэффициентом будет коэффициент корреляции Пирсона г (Pearson, 1896), называемый также линейной корреляцией, так как он отражает степень линейных связей между переменными. Эта корреляция наиболее популярна, поэтому часто, когда говорят о корреляции, имеют в виду именно корреляцию Пирсона.
Итак, коэффициент парной корреляции изменяется в пределах от -1 до +1. Крайние значения имеют особенный смысл. Значение -1 означает полную отрицательную зависимость, значение +1 означает полную положительную зависимость, иными словами, между наблюдаемыми переменными имеется точная линейная зависимость с отрицательным или положительным коэффициентом.
Значение 0,00 интерпретируется как отсутствие корреляции.
Корреляция определяет степень, с которой значения двух переменных пропорциональны друг другу. Это можно проследить, анализируя графики (см. ниже).
На графике в левом верхнем углу значения парного коэффициента корреляции равно 0,0, на графике в правом верхнем углу коэффициент корреляции постепенно увеличивается и становится равным 0,3.
На нижних графиках коэффициент корреляции увеличивается и становится равным 0,6 и 0,9. Обратите внимание на то, как меняется наклон прямой линии и как группируются точки вокруг этой прямой.
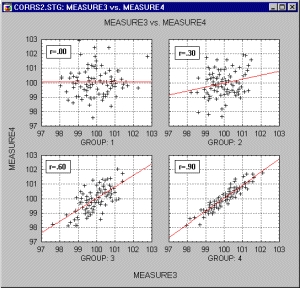
Заметьте, что чем ближе коэффициент корреляции к крайнему значению 1, тем теснее группируются данные вокруг прямой. Та же картина наблюдалась бы и при отрицательных значениях корреляции, только наклон прямой, вокруг которой группируются значения переменных, был бы отрицательным.
При значении коэффициента корреляции, равном ±1, точки точно легли бы на прямую линию, а это означает, что между данными имеется точная линейная зависимость.
Внимательно посмотрите на эти графики. Корреляция — важное понятие, постарайтесь привыкнуть к нему и научиться визуально определять по расположению данных, насколько тесно они коррелированы.
Говорят, что две переменные положительно коррелированы, если при увеличении значений одной переменной увеличиваются значения другой переменной.
Две переменные отрицательно коррелированны, если при увеличении одной переменной другая переменная уменьшается (см. рисунки выше).
Говорят, что корреляция высокая, если на графике зависимость между переменными можно с большой точностью представить прямой линией (с положительным или отрицательным наклоном).
Если коэффициент корреляции равен 0, то отсутствует отчетливая тенденция в совместном поведении двух переменных, точки располагаются хаотически вокруг прямой линии (см. график в левом верхнем углу).
Важно, что коэффициент корреляции — безразмерная величина и не зависит от масштаба измерения. Например, корреляция между ростом и весом будет одной и той же независимо от того, проводились ли измерения в дюймах и футах или в сантиметрах и килограммах.
Проведенная прямая (см. графики), вокруг которой группируются значения переменных, называется прямой регрессии, или прямой, построенной методом наименьших квадратов. Последний термин связан с тем, что сумма квадратов расстояний (вычисленная по оси Y) от наблюдаемых точек до прямой действительно является минимальной из всех возможных.
Формально коэффициент корреляции Пирсона вычисляется следующим образом:
r12 = [S(Yi1 - Y_1) x (Yi2 - Y_2)] / [S (Yi1 - Y_1)2 x S(Yi2 - Y_2)2]1/2,
Y_1 — среднее переменной Y1
Y_2 — среднее переменной Y2
Если переменные измерены в интервальной шкале, то используются ранговые корреляции, которые будут рассмотрены ниже.
Для анализа зависимостей категориальных переменных обычно используют таблицы сопряженности и соответствующие статистики, например, хи-квадрат, V-квадрат, точный критерий Фишера, статистика фи-квадрат (альтернатива корреляции) и др.
Если требуется измерить связи между списками переменных, используются следующие типы корреляции:
Если вычисляется корреляция между значениями одной переменной, сдвинутыми на некоторый лаг, то говорят об автокорреляции.
Ранговые корреляции. Эти корреляции используются в тех ситуациях, когда наблюдаемые данные ранжированы.
Статистика Спирмена R. Статистика R Спирмена предполагает, что рассматриваемые переменные измерены как минимум в порядковой шкале, иными словами — индивидуальные наблюдения ранжированы.
Статистика Кендалла тay. Статистика тay Кендалла эквивалентна R Спирмена при выполнении некоторых основных предположений. Критерии, основанные на этих статистиках, также сравнимы по мощности. Однако обычно значения R Спирмена и тay Кендалла различны, потому что они существенно отличаются как по своей внутренней логике, так и по способу вычисления. Имеется следующее соотношение между этими статистиками:
-1 _< 3 x тау Кендалла и 2 x R Спирмена < 1
Более важно, что тay Кендалла и R Спирмена по-разному интерпретируются. R Спирмена можно мыслить как прямой аналог г Пирсона, вычисленный по рангам (а не по исходным наблюдениям), тогда как тay Кендалла представляет вероятность, точнее, вероятность того, что значения двух переменных располагаются в одном и том же порядке, минус вероятность того, что значения переменных располагаются в различном порядке (или вероятность того, что ранги двух переменных совпадают, минус вероятность того, что они различны).
Гамма. Гамма -статистика предпочтительнее статистики R Спирмена или тay Кендалла в тех случаях, когда в данных имеется много совпадающих значений. С точки зрения основных предположений, статистика гамма эквивалентна R Спирмена или тay Кендалла. Ее интерпретация и вычисление более похожи на тay Кендалла, чем на R Спирмена. Гамма также представляет собой вероятность; более точно — вероятность того, что ранговый порядок двух переменных совпадает, минус вероятность того, что не совпадает, деленная на выражение 1 минус вероятность совпадений. Таким образом, статистика гамма в основном эквивалентна тay Кендалла за исключением того, что совпадения рангов явно принимаются во внимание.
Нелинейные зависимости между переменными. Корреляция Пирсона г хорошо подходит для описания линейной зависимости. Отклонения от линейности увеличивают общую сумму квадратов расстояний от регрессионной прямой, даже если она представляет «истинные» и очень тесные зависимости между переменными. Поэтому хорошим тоном после вычисления корреляций является построение диаграмм рассеяния, которые позволяют понять, действительно ли между двумя исследуемыми переменными имеется связь.
Например, показанная ниже высокая корреляция плохо описывается линейной функцией.

Однако, как видно на графике ниже, полином пятого порядка достаточно хорошо описывает зависимость.

Ложные корреляции. Нужно иметь в виду, что на свете существуют ложные корреляции, и это нарушает идиллическую картину корреляционного анализа.
Другими словами, если вы нашли переменные с высокими значениями коэффициентов корреляции, то отсюда еще не следует, что между ними действительно существует причинная связь; нужна уверенность, что на исследуемые переменные не влияют другие переменные.
Лучше всего понять ложные корреляции на следующем шутливом примере.
Известно, что существует корреляция между ущербом, причиненным пожаром, и числом пожарных, тушивших его. Однако эта корреляция ничего не говорит о том, насколько уменьшатся потери, если будет вызвано меньшее число пожарных.
Задумавшись над полученным результатом, вы будете искать и найдете причину высокой корреляции: причина состоит в том, что имеется третья переменная (величина пожара), которая влияет как на причиненный ущерб, так и на число вызванных пожарных. Если вы будете «контролировать» эту переменную (например, рассматривать только пожары определенной величины), то исходная корреляция (между ущербом и числом пожарных) либо исчезнет, либо, возможно, даже изменит свой знак.
В реальной жизни проводить такие рассуждения и находить «причинные» переменные, конечно, гораздо сложнее.
Основная проблема ложной корреляции состоит в том, что вы не знаете, чем она вызвана или, фигурально выражаясь, кто является ее агентом. Тем не менее, если вы знаете, где искать, то можно воспользоваться частными корреляциями, чтобы контролировать (частично исключенное) влияние определенных переменных.
Почему зависимости между переменными являются важными
Вообще говоря, цель всякого исследования или научного анализа состоит в нахождении связей (зависимостей) между измеряемыми переменными. Далее почти не проводится различия между терминами связь и зависимость, и во многих ситуациях они рассматриваются как синонимы, хотя поклонники строгих определений, возможно, усмотрят в этом вольность.
Заметим, что не существует иного способа представления знания, кроме как в терминах зависимостей между количествами или качествами.
Таким образом, развитие знаний всегда заключается в нахождении новых зависимостей между переменными. Исследование корреляций по существу состоит з измерении таких зависимостей непосредственным образом. Тем не менее экспериментальное исследование не является в этом смысле чем-то отличным. Например, отмеченное экспериментальное сравнение WCC у мужчин и женщин может быть описано как поиск связи между двумя переменными: Пол и WCC. Назначение статистики состоит в том, чтобы помочь оценить зависимости между переменными. Действительно, множество статистических процедур может быть рассмотрено в терминах оценки различных типов взаимосвязей между переменными. Итак, специалиста по статистике прежде всего интересует оценка связи между измеренными переменными.
Зависимые и независимые переменные
В повседневной жизни мы хорошо понимаем, что одни величины зависят от других, например, потребление, конечно, зависит от дохода, цена квартиры — от площади, число посетителей магазина зависит от количества рекламных объявлений, предпочтение в выборе платья связано с содержимым кошелька, число посетите-[: лей ресторана зависит от времени суток и т. д.
Проведем более строго различие между независимыми и зависимыми переменными. Независимыми переменными называются переменные, которые варьируют-; с я исследователем, тогда как зависимые переменные — это переменные, которые [ измеряются или регистрируются. Очевидно, варьируя интенсивность рекламной [ рассылки, вы можете наблюдать изменение спроса и потока посетителей в магазин, в этом примере интенсивность рекламы — независимая переменная, поток посетителей — зависимая. Изменяя рекламную кампанию, вы можете заставить покупателя перейти из пассивного состояния (спячки) в активное и т. д. В электронной торговле очень важна оценка момента перехода покупателя из категорий пассивный, активный, суперактивный, чтобы иметь возможность влиять на этот процесс.
На первый взгляд, может показаться, что проведение этого различия создает путаницу в терминологии, поскольку, как иногда говорят в шутку студенты, «все переменные зависят от чего-нибудь». Тем не менее, однажды отчетливо проведя это различие, вы поймете его необходимость.
Термины зависимая и независимая переменная применяются в экспериментальном исследовании, где экспериментатор манипулирует некоторыми переменными, и в этом смысле они «независимы» от реакций, свойств, намерений и т. д., присущих объектам исследования. Некоторые другие переменные, как предполагается, должны «зависеть» от действий экспериментатора или от экспериментальных условий. Иными словами, зависимость проявляется в ответной реакции исследуемого объекта, ее можно назвать откликом объекта на воздействие, поэтому термин отклик (response) также иногда используется как синоним зависимой переменной. Отчасти в противоречии с данным разграничением понятий находится использование их в исследованиях, где вы не варьируете независимые переменные, а только
приписываете объекты к «экспериментальным группам», основываясь на некоторых их априорных свойствах. Например, если в эксперименте мужчины сравниваются с женщинами относительно числа лейкоцитов (WCC), то Пол можно назвать независимой переменной, a WCC — зависимой переменной; вложения в рекламу является независимой (варьируемой) переменной, а число клиентов — зависимой и т. д.
Как измерить величину зависимости между переменными
Статистиками разработано много различных мер, позволяющих оценить или измерить степень зависимости между наблюдаемыми переменными.
Выбор определенной меры в конкретном исследовании зависит от числа включенных в анализ переменных, используемых шкал измерения, природы зависимостей и т. д. Большинство этих мер тем не менее подчиняется одному общему принципу: они являются попыткой оценить наблюдаемую зависимость, сравнивая ее с «максимально возможной зависимостью» между рассматриваемыми переменными.
Обычный способ выполнить такие оценки заключается в том, чтобы посмотреть, как варьируются значения переменных, и затем подсчитать, какая часть всей имеющейся вариации может быть объяснена наличием «общей» («совместной») вариации двух (или более) переменных.
Проще говоря, сравнивается то, «что есть общего в этих переменных», с тем, «что потенциально было бы у них общего, если бы переменные были абсолютно зависимы». Рассмотрим простой пример.
Пусть в вашей выборке средний показатель (число лейкоцитов) WCC равен 100 для мужчин и 102 для женщин. Следовательно, вы могли бы сказать, что отклонение каждого индивидуального значения от общего среднего (101) содержит компоненту, связанную с полом субъекта, и средняя величина ее равна 1. Это значение, таким образом, представляет некоторую меру зависимости между переменными Пол и WCC. Конечно, это очень бедная мера, так как она не дает никакой информации о том, насколько велика эта компонента, скажем, относительно общего изменения значений WCC. Рассмотрим две крайние возможности:
(a) Если все значения WCC y мужчин были бы точно равны 100, а у женщин 102, то все отклонения значений от общего среднего в выборке всецело объяснялись бы полом. Поэтому вы могли бы сказать, что пол абсолютно коррелирует с WCC, иными словами, 100% наблюдаемых различий между субъектами в значениях WCC объясняются полом субъектов.
(b) Если же значения WCC лежат в пределах 0-1000, то та же самая разность (2) между средними значениями WCC y мужчин и женщин, обнаруженная в эксперименте, составляла бы столь малую долю общей вариации, что полученное различие считалось бы пренебрежимо малым. Например, введение в рассмотрение еще одного субъекта могло бы изменить разность или даже изменить ее знак. Поэтому хорошая мера зависимости должна принимать во внимание полную изменчивость индивидуальных значений в выборке и оценивать зависимость по тому, насколько эта изменчивость объясняется изучаемой зависимостью.
Две черты зависимости между переменными
Можно отметить два самых простых свойства зависимости между переменными:
(a) величину зависимости и (b) надежность зависимости.
(а) Величина. Величину зависимости легче понять и измерить, чем надежность. Например, если любой мужчина в вашей выборке имел значение М7Свыше, чем любая женщина, то вы можете сказать, что величина зависимости между двумя переменными (Пол и WCC) очень высокая. Другими словами, вы могли бы предсказать значения одной переменной по значениям другой.
(b) Надежность («истинность»). Надежность взаимозависимости — менее наглядное понятие, чем величина зависимости, однако чрезвычайно важное. Оно непосредственно связано с репрезентативностью той определенной выборки, на основе которой строятся выводы. Другими словами, надежность говорит, насколько вероятно, что зависимость, подобная найденной, будет вновь обнаружена (подтвердится) на данных другой выборки, извлеченной из той же самой популяции. Следует помнить, что конечной целью почти никогда не является изучение данной конкретной выборки; выборка представляет интерес лишь постольку, поскольку она дает информацию обо всей популяции. Если ваше исследование удовлетворяет некоторым специальным критериям (об этом будет сказано позже), то надежность найденных зависимостей между переменными выборки можно количественно оценить и представить с помощью стандартной статистической меры (называемой р-уровенъ, или статистический уровень значимости, см. следующий раздел).
Что такое статистическая значимость (р-уровень)?
Статистическая значимость результата представляет собой оцененную меру уверенности в его правильности.
Говоря проще, не на статистическом жаргоне, уровень значимости показывает, насколько значим для вас полученный результат. Предположим, вы врач, исследующий пациента. Проводя всесторонние исследования (измеряя давление, беря анализы крови и т. д.) вы приходите к выводу, что пациент с большой вероятностью болен, следовательно, полученные результаты значимы.
Выражаясь формально, уровень значимости, или, как еще говорят, р-уровень, — это показатель, находящийся в убывающей зависимости от надежности результата. Более высокий р-уровень соответствует более низкому уровню доверия к найденной в выборке зависимости между переменными. Именно р-уровень представляет собой вероятность ошибки, связанной с распространением наблюдаемого результата на всю популяцию. Например, р-уровень = 0,05 (то есть 1/20) показывает, что имеется 5%-я вероятность того, что найденная в выборке зависимость между переменными является лишь случайной особенностью данной выборки. Иначе говоря, если данная зависимость в популяции отсутствует, а вы многократно проводите подобные эксперименты, то примерно в одном из
двадцати повторений эксперимента можно ожидать такой же или более сильной зависимости между изучаемыми переменными. Во многих исследованиях р-уpoвень, равный 0,05, рассматривается как «приемлемая граница» уровня ошибки.
На уровень значимости можно посмотреть с другой стороны. Предположим, что вы врач и выдвигаете гипотезу: пациент болен. Тогда, если вы назначили уровень 0,05, то в среднем в 5 случаях из 100 будете совершать ошибку (то есть принимать неправильную гипотезу — признавать человека больным, когда на самом деле он здоров).
Как определить, является ли результат действительно значимым
Не существует никакого способа избежать произвола при принятии решения о том, какой уровень значимости следует действительно считать «значимым». Однако...
Однако статистическую значимость можно перевести в потери (например, финансовые), используя подходящую функцию потерь. Представьте, что вы многократно принимаете решение, то есть проверяете гипотезу о направлении изменения курса акций, выбрав некоторый уровень значимости, тогда уменьшение денег в вашем кошельке покажет ошибочность вашего выбора.
Выбор определенного уровня значимости, выше которого результаты отвергаются как ложные, является достаточно произвольным. На практике окончательное решение обычно зависит от того, был ли результат предсказан априори (т. е. до проведения опыта) или обнаружен апостериорно, в результате многих анализов и сравнений, выполненных с множеством данных, а также по традиции, имеющейся в данной области исследований.
Обычно, что во многих областях результат р = 0,05 является приемлемой границей статистической значимости, однако следует помнить, что этот уровень все еще включает довольно большую вероятность ошибки (5%). Результаты, значимые на уровне р = 0,01, обычно рассматриваются как статистически значимые, а результаты с уровнем р = 0,005 или р - 0,001 как высокозначимые. Но следует понимать, что в данной классификации уровней значимости имеется произвол и это является всего лишь неформальным соглашением, принятым на основе практического опыта.
Статистическая значимость и количество выполненных анализов
Понятно, что чем большее число анализов вы провели над некоторыми группами данных, тем большее число результатов среди них имеют шанс удовлетворить выбранному уровню значимости. Например, если вычисляются корреляции между 10 переменными (то есть имеется 45 различных коэффициентов корреляции), можно ожидать, что примерно два коэффициента корреляции (один на каждые 20) случайно окажутся значимыми на уровне р = 0,05, даже если переменные совершенно случайны и некоррелированы в популяции. Иными словами, имея серию экспериментов, вы всегда можете подтасовать результаты, выбирая только те опыты, результаты которых подтвеждают вашу гипотезу.
Некоторые статистические методы, включающие множественные, то есть многократные, сравнения и, следовательно, имеющие хороший шанс повторить такого рода ошибки, используют специальную корректировку или поправку на общее число сравнений. Тем не менее многие статистические методы (особенно простые методы разведочного анализа данных) не предлагают какого-либо способа решения этой проблемы. Поэтому исследователь должен с осторожностью оценивать надежность неожиданных находок. Многие примеры, обсуждаемые в данном руководстве, предлагают специальные советы по поводу того, как это сделать.
Величина зависимости между переменными в сравнении с надежностью зависимости
Величина и надежность представляют собой две различные характеристики зависимостей между переменными. Тем не менее нельзя сказать, что они совершенно независимы. В общем, можно утверждать, что чем больше величина зависимости (связи) между переменными в выборке обычного объема, тем она надежней.
Почему более сильные зависимости между переменными являются более значимыми
Если предполагать отсутствие зависимости между соответствующими переменными в популяции, то с наибольшей вероятностью следует ожидать, что в исследуемой выборке связь между этими переменными также будет отсутствовать. Таким образом, чем более сильная зависимость обнаружена в выборке, тем менее вероятно, что этой зависимости нет в популяции, из которой она извлечена. Как можно заметить, величина зависимости и значимости тесно связаны между собой, и можно попытаться вывести значимость из величины зависимости и наоборот. Однако указанная связь между зависимостью и значимостью имеет место только при фиксированном объеме выборки, поскольку при различных объемах выборки одна и та же зависимость может оказаться как высокозначимой, так и не значимой вовсе (см. следующий раздел).
Почему объем выборки влияет на значимость зависимости
Общая идея статистических методов состоит в том, чтобы по некоторой части популяции вынести суждения о свойствах популяции в целом. Именно такого рода результаты и представляют основной интерес, т. к. являются объективными.
Если количество наблюдений невелико, то есть выборка из популяции мала, то соответственно имеет место малое количество возможных комбинаций значений этих переменных и, таким образом, вероятность случайно обнаружить комбинацию значений, показывающую сильную зависимость, относительно высока. Рассмотрим следующий пример. Если вы исследуете зависимость двух переменных (Пол: мужчина/женщина и WCC: высокий/низкий) и имеете только 4 субъекта в выборке (2 мужчины и 2 женщины), то вероятность того, что чисто случайно вы найдете 100%-ю зависимость между двумя переменными, равна 1/8. А именно вероятность того, что оба мужчины имеют высокий WCC, а обе женщины — низкий WCC, или наоборот, равна 1/8. Теперь рассмотрим вероятность подобного совпадения для 100 субъектов; легко видеть, что эта вероятность равна практически нулю.
Рассмотрим более общий пример. Представим популяцию, в которой среднее значение WCC для мужчин и женщин одно и тоже. Если теперь вы начнете повторять эксперимент, состоящий в извлечении пары случайных выборок (одна — мужчины, другая — женщины) и вычислении разности выборочных средних WСС для каждой пары, то в большинстве экспериментов результат будет близок к 0. Однако время от времени будут встречаться пары выборок, в которых различие между мужчинами и женщинами будет существенно отличаться от 0. Как часто будет это происходить? Чем меньше объем выборки в каждом эксперименте, тем более вероятно появление таких ложных результатов, которые показывают существование зависимости между полом и WCC в данных, полученных из популяции, где такая зависимость на самом деле отсутствует.
Почему слабые зависимости могут быть значимо доказаны только на больших выборках
Предыдущий пример показывает, что если зависимость между переменными «объективно» (другими словами, в популяции) мала, не существует иного способа проверить такую зависимость, кроме как исследовать выборку достаточно большого объема. Даже если ваша выборка совершенно репрезентативна, эффект не будет статистически значимым, если выборка мала. Аналогично если зависимость «объективно» (в популяции) очень сильная, то она может быть обнаружена с высокой значимостью даже на очень маленькой выборке. Рассмотрим следующий иллюстративный пример. Если монета слегка несимметрична и при подбрасывании орел выпадает чаще решки (например, 60% против 40%), то 10 подбрасываний монеты было бы недостаточно, чтобы убедить кого бы то ни было, что монета асимметрична, даже если был бы получен совершенно репрезентативный результат, 6 орлов и 4 решки.
Не следует ли отсюда, что 10 подбрасываний вообще не могут доказать что-либо? Нет, не следует, потому что если эффект в принципе очень сильный, 10 подбрасываний может быть вполне достаточно. Представьте, что монета настолько несимметрична, что всякий раз, когда вы ее бросаете, выпадает орел. Если вы бросаете такую монету 10 раз и всякий раз выпадает орел, большинство людей сочтут это убедительным доказательством того, что с монетой что-то не то.
Другими словами, это послужило бы убедительным доказательством того, что в популяции, состоящей из бесконечного числа подбрасываний этой монеты, орел будет встречаться чаще, чем решка. Таким образом, если зависимость сильная, она может быть обнаружена с высоким уровнем значимости даже на малой выборке.
Можно ли рассматривать отсутствие связей как значимый результат?
Чем слабее зависимость между переменными, тем большего объема требуется выборка, чтобы значимо ее обнаружить. Например, представьте, как много бросков монеты необходимо сделать, чтобы доказать, что отклонение от равных вероятностей составляет только 0,000001%! Таким образом, необходимый минимальный размер выборки возрастает, когда степень эффекта, который нужно доказать, убывает. Когда эффект близок к 0, необходимый объем выборки для его отчетливого доказательства приближается к бесконечности. Другими словами, если зависимость между переменными почти отсутствует, объем выборки, необходимый для ее значимого обнаружения, почти равен объему всей популяции, который предполагается бесконечным. Статистическая значимость представляет вероятность того, что подобный результат был бы получен при проверке всей популяции в целом. Таким образом, все, что получено после тестирования всей популяции, было бы по определению значимым на наивысшем возможном уровне, и это относится ко всем результатам типа «нет связи».
Общая конструкция статистических тестов
Так как конечная цель большинства статистических тестов состоит в оценке зависимости между переменными, большинство статистических тестов следует некоторому общему принципу. Говоря техническим языком, эти тесты представляют собой отношение групповой изменчивости к полной изменчивости. Например, такой тест может представлять собой отношение той части изменчивости WCC, которая определяется полом, к полной изменчивости WCC (вычисленной для объединенной выборки мужчин и женщин). Это отношение обычно называется отношением объясненной вариации к полной вариации.
В статистике термин объясненная вариация не обязательно означает, что вы даете ей «теоретическое объяснение». Он используется только для обозначения общей вариации рассматриваемых переменных, то есть для указания на то, что часть вариации одной переменной «объясняется» определенными значениями другой переменной, и наоборот.
Как вычисляется статистическая значимость
Предположим, вы уже вычислили меру зависимости между двумя переменными (как объяснялось выше). Следующий вопрос, стоящий перед вами: «насколько значима эта зависимость?» Например, является ли 40% объясненной дисперсии между двумя переменными достаточным, чтобы считать зависимость значимой? Ответ будет таким: «в зависимости от обстоятельств». Именно значимость зависит в основном от объема выборки. Как уже объяснялось, в очень больших выборках даже очень слабые зависимости между переменными будут значимыми, в то время как в малых выборках даже очень сильные зависимости не являются надежными (значимыми). Таким образом, для того чтобы определить уровень статистической значимости, вам нужна функция, которая представляла бы зависимость между «величиной» и «значимостью» зависимости между переменными для каждого объема выборки. Данная функция указала бы вам точно «насколько вероятно получить зависимость данной величины (или больше) в выборке данного объема, в предположении, что в популяции такой зависимости нет». Другими словами, эта функция давала бы вам уровень значимости (р-уровень) и, следовательно, вероятность ошибочно отклонить предположение об отсутствии данной зависимости в популяции. Эта «альтернативная» гипотеза (состоящая в том, что нет зависимости в популяции) обычно называется нулевой гипотезой. Было бы идеально, если бы функция, вычисляющая вероятность ошибки, была линейна и имела только различные наклоны для разных объемов выборки. К сожалению, эта функция существенно более сложная и не всегда одна и та же. Тем не менее в большинстве случаев ее форма известна, и это можно использовать для определения уровней значимости при исследовании выборок заданного размера. Большинство этих функций связано с очень важным классом, называемым нормальным.
Значимость коэффициента корреляции
Допустим, вы оценили коэффициент корреляции между двумя переменными. Очевидно, чем больше по абсолютной величине значение коэффициента, тем больше вероятность, что между переменными имеется связь, то есть с тем меньшей вероятностью ошибки можно отвергнуть гипотезу об отсутствии связи между переменными.
Иными словами, чем больше абсолютное значение коэффициента корреляции, тем более обоснованно опровергается гипотеза, что между переменными нет связи. Спрашивается: «Какие именно значения значимы?»
Ответ зависит как от величины коэффициента корреляции, так и от объема выборки, по которой он вычислен.
Например, анализируя данные о годовых урожаях в Восточной Англии за 20 лет, Фишер вычислил коэффициент корреляции между годовым урожаем пшеницы и осенним уровнем дождей. Этот коэффициент, как и ожидалось, оказался отрицательным (чем выше уровень осенних осадков, тем меньше урожай, то есть переменные отрицательно коррелированны) и равным...0,629, что значимо на уровне 0,01.
Если бы выборочный коэффициент корреляции оказался равен 0,45, то результат был бы значим на уровне 0,1, но не значим на уровне 0,01, и т. д.
Как определить, являются ли два коэффициента корреляции значимо различными
Имеется критерий, позволяющий оценить значимость различия между двумя коэффициентами корреляциями. Результат применения критерия зависит не только от величины разности этих коэффициентов, но и от объема выборок и величины самих этих коэффициентов. Вообще говоря, в соответствии с общим принципом надежность коэффициента корреляции увеличивается с увеличением его абсолютного значения; относительно малые различия между большими коэффициентами могут быть значимыми. Например, разница 0,10 между двумя корреляциями может не быть значимой, если коэффициенты равны 0,15 и 0,25, хотя для той же выборки разность 0,10 может оказаться значимой для коэффициентов 0,80 и 0,90.
В системе STATISTICA имеется специальное средство — статистический калькулятор — в диалоговом окне Другие критерии значимости, доступном из стартовой панели модуля Основные статистики и таблицы. Калькулятор позволяет быстро сравнить коэффициенты корреляции, вычисленные по разным выборкам.
Почему важно нормальное распределение
Нормальное распределение (термин был впервые введен Гальтоном в 1889 г.) иногда называемое гауссовским, важно по многим причинам. Распределение большого числа статистик является нормальным или может быть получено из нормального с помощью некоторых преобразований.
Рассуждая философски, можно сказать, что нормальное распределение представляет собой одну из эмпирически проверенных истин относительно общей природы действительности и его положение может рассматриваться как один из фундаментальных законов природы. Точная форма нормального распределения (характерная «колоколообразная кривая») определяется только двумя параметрами: средним и стандартным отклонением.
Характерное свойство нормального распределения состоит в том, что 68% из всех его наблюдений лежат в диапазоне 1 (стандартное отклонение от среднего), а диапазон 2 стандартных отклонений включает 95% значений. Другими словами, при нормальном распределении стандартизованные наблюдения, меньшие -2 или большие +2, имеют относительную частоту менее 5% (стандартизованное наблюдение означает, что из исходного значения вычтено среднее и результат поделен на стандартное отклонение.) Это и есть знаменитое правило 2-сигма или 2-стан-дартных отклонения, вместе с правилом 3-сигма чрезвычайно популярное на практике.
Формально плотность нормального распределения определяется следующим образом:
f(x)=1/[2×p)1/2×exp{-1/2×[(x-µ)/s]2}
где
µ-среднее;
õ-стандартное отклонение;
е- число Эйлера;
Множество величин на практике имеют нормальное распределение, например, распределение приращений индексов развитых стран, курсы акций и т. д.
Двухмерное нормальное распределение. Две переменные имеют двухмерное нормальное распределение, если для каждого фиксированного значения одной переменной соответствующие значения другой переменной нормально распределены.
Функция плотности двухмерного нормального распределения определяется следующим образом:
где µ1,µ2 - соответствующие средние случайных величин X и Y;f(x,y)={1/[2s1s2×(1-r)1/2]}×exp{-1/2(1-r2)((x-µ1)/s1)2+((y-µ2)/s2))2-
2r(x-µ1)/s1 ×(y-µ2)/s2}
õ1, õ2 - соответствующие стандартные отклонения случайных величин X и Y;
r (ро)-коэффициент корреляции между случайной величиной X и случайной величиной Y;
е-число Эйлера;
График двухмерного распределения показан ниже:
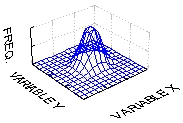
Иллюстрация того, как нормальное распределение используется в статистических рассуждениях
Напомним пример, обсуждавшийся ранее, когда пары выборок мужчин и женщин выбирались из совокупности, в которой среднее значение WСС для мужчин и женщин было в точности одно и то же. Хотя наиболее вероятный результат таких экспериментов (одна пара выборок на эксперимент) состоит в том, что разность между средними WCC для мужчин и женщин для каждой пары близка к 0, время от времени появляются пары выборок, в которых эта разность существенно отличается от 0. Как часто это происходит? Если объем выборок достаточно большой, то разности «нормально распределены» и, зная форму нормальной кривой, вы можете точно рассчитать вероятность случайного получения результатов, представляющих различные уровни отклонения среднего от 0, — значения гипотетического для всей популяции. Если вычисленная вероятность настолько мала, что удовлетворяет принятому заранее уровню статистической значимости, то можно сделать лишь один вывод: ваш результат лучше описывает свойства популяции, чем «нулевая гипотеза». Следует помнить, что нулевая гипотеза рассматривается только по техническим соображениям как начальная точка, с которой сопоставляются эмпирические результаты.
Как проверить нормальность наблюдаемых величин
При проверке нормальности выборки часто руководствуются следующим принципом Фишера: «Отклонения от нормального вида, если только они не слишком заметны, можно обнаружить лишь для больших выборок, однако сами по себе эти отклонения вносят малое отличие в статистические критерии и другие вопросы», (см. например, Справочник по прикладной статистике под редакцией Э. Ллойда и У. Линдермана, М: Финансы и статистика, 1989, с. 270).
На практике для проверки нормальности обычно применяют визуальные методы, например, гистограммы, нормальные вероятностные графики или численные методы с помощью оценки коэффициентов асимметрии и эксцесса; используется также критерий хи-квадрат.
Пример (проверка нормальности с помощью оценок коэффициентов асимметрии и эксцесса).
Рассмотрим классические данные Р. Фишера о количестве осадков в одном из районов Англии (см. Fisher R. А. (1970). Statistical methods for research workers, 15-th edition, Macmillan):
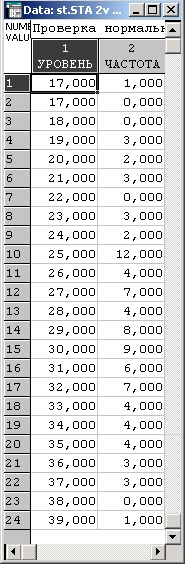
Далее приводится последовательность действий, которую лучше всего повторить, используя систему STATISTICA.
Шаг 1. Создайте файл STATISTICA и введите в него данные, представленные в таблице. В первом столбце приведено количество осадков в дюймах. Во втором столбце записана частота, с которой данное значение встречалось в измерениях. Например, уровень 16 дюймов наблюдался 1 раз, уровень 17 дюймов — 0 раз, уровень 18 дюймов — 0 раз и т. д.
Шаг 2. Запустите модуль Основные статистики и таблицы.
Шаг 3. В стартовой панели модуля выберите Основные статистики и нажмите ОК.
Шаг 4. В появившемся окне Описательные статистики нажмите кнопку Переменные и выберите переменную УРОВЕНЬ.
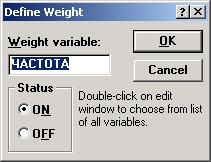
Шаг 5. Далее в правом верхнем углу окна нажмите кнопку В . В появившемся окне Задание веса выберите вес из переменной ЧАСТОТА. Нажмите ОК.
Шаг 6. Нажмите кнопку Другие статистики и дайте указание системе, что вам нужно вычислить асимметрию и эксцесс, а также их стандартные ошибки (см. рисунок).

Шаг 7. Нажмите OK в окне Статистики и далее нажмите ОК в появившемся окне Описательные статистики. Следующая таблица с результатами появится на экране:

Из этой таблицы видно, что по абсолютной величине оценки асимметрии и эксцесса имеют тот же порядок, что их ошибки. Следовательно, ни одна из полученных величин не значима. Поэтому можно сказать, что данные согласованы с гипотезой нормальности.
Продолжение примера (использование критерия хи-квадрат для проверки нормальности).
Мы работаем с теми же данными по осадкам, что и в предыдущем примере.
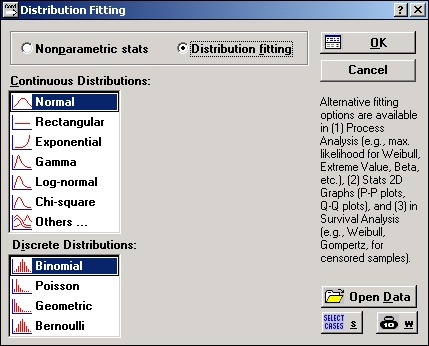
Шаг 1. Запустите модуль Непараметрические статистики.
В стартовой панели модуля выберите опцию Подгонка распределения.
Так как нужно проверить согласие данных с нормальным распределением, в списке Непрерывные распределения выберите Нормальное. Далее нажмите кнопку ОК.
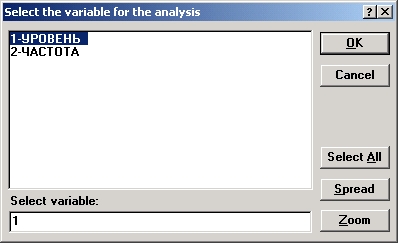
Шаг 2. В появившемся диалоговом окне Подгонка непрерывных распределений нажмите кнопку Переменные и выберите переменную УРОВЕНЬ. Нажмите ОК.
Шаг 3. Далее в правом верхнем углу окна нажмите кнопку В. Выберите веса из переменной ЧАСТОТА.

Шаг 4. В диалоговом окне Подгонка непрерывных распределений нажмите кнопку ОК.
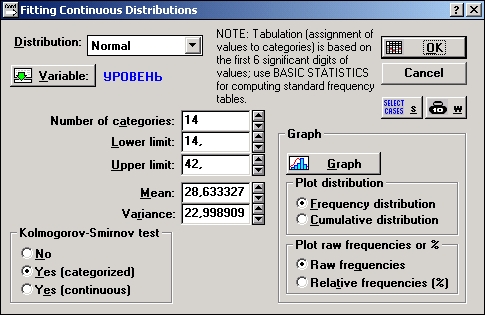
На экране появится следующая электронная таблица с результатами:
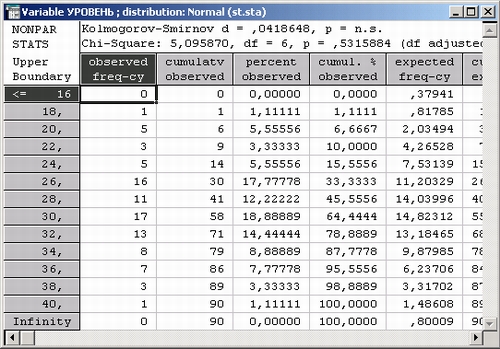
Во второй строке заголовка таблицы показано значение статистики хи-квадрат и уровень значимости р = 0,532.
Снова мы можем сказать, что данные согласованы с гипотезой нормальности. Результат согласуется с тем, который был получен в первой части примера, когда в качестве критерия нормальности использовались коэффициенты асимметрии и эксцесса.
ЗАМЕЧАНИЕ
В первой строке заголовка таблицы указаны значения статистики Колмогорова—Смирнова. Этот критерий также можно использовать для проверки нормальности. Результат также не значим.
Посмотрим на результаты в графическом виде.
Шаг 5. В диалоговом окне Подгонка непрерывных распределений нажмите кнопку График.
На экране появится гистограмма значений переменной Осадки. Из графика также видно хорошее согласие данных с нормальным распределением.
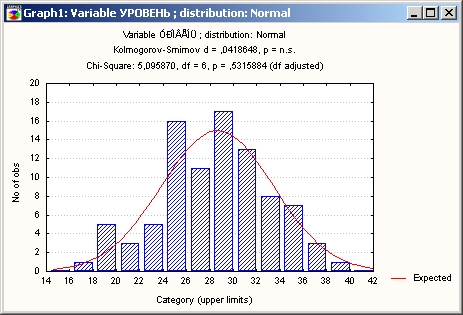
Этот классический пример иллюстрирует схему действий в системе STATISTICA при проверке нормальности данных.
Все ли статистики критериев нормально распределены?
Не все, но большинство из них либо имеют нормальное распределение (особенно при большом числе наблюдений), либо имеют распределение, связанное с нормальным и вычисляемое на основе нормального, такое как t,F или хи-квадрат. Обычно эти статистики требуют, чтобы анализируемые переменные сами были нормально распределены в совокупности, то есть удовлетворяли бы «предположению».
Многие наблюдаемые переменные действительно нормально распределены, что является еще одним аргументом в пользу того, что нормальное распределение представляет «фундаментальный закон». Проблема может возникнуть при попытке применить тесты, основанные на предположении нормальности, к данным, не являющимся нормальными. В подобных случаях вы можете выбрать одно из двух.
Во-первых, вы можете использовать альтернативные «непараметрические» тесты (или так называемые «свободно распределенные тесты»), особенно полезные, если число наблюдений мало.
Как альтернативу во многих случаях вы можете все же использовать тесты, основанные на предположении нормальности, если уверены, что объем выборки достаточно велик.
Последняя возможность основана на чрезвычайно важном принципе, позволяющем понять популярность тестов, основанных на нормальности: при возрастании объема выборки форма распределения статистики критерия приближается к нормальной, даже если распределение исследуемых переменных не является нормальным. Этот принцип называется центральной предельной теоремой.
Как узнать последствия нарушений предположений нормальности?
Хотя многие утверждения предыдущих параграфов можно доказать математически, некоторые из них не имеют теоретического обоснования и могут быть продемонстрированы только эмпирически, с помощью так называемых экспериментов Монте-Карло. В этих экспериментах большое число выборок генерируется на компьютере, а результаты, полученные из этих выборок, анализируются с помощью различных тестов. Этим способом можно эмпирически оценить тип и величину ошибок или смещений, которые вы получаете, когда нарушаются определенные теоретические предположения используемых тестов, например, вы можете искусственно изменить распределение выборки, сделать его отличным от нормального и проверить результат.
Монте-Карловские исследования интенсивно использовались для того, чтобы оценить, насколько тесты, основанные на предположении нормальности, чувствительны к различным нарушениям предположений нормальности.
Общий вывод этих исследований состоит в том, что последствия нарушения предположения нормальности менее фатальны, чем первоначально предполагалось. Хотя эти выводы не означают, что предположения нормальности можно игнорировать, они увеличили общую популярность тестов, основанных на нормальном распределении.
|
|
