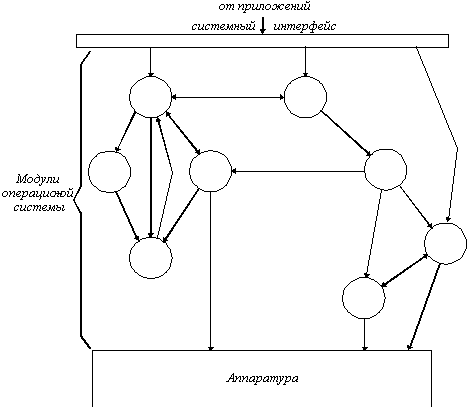
Как уже отмечалось выше, для удовлетворения требований, предъявляемых к современной ОС, большое значение имеет ее структурное построение. Операционные системы прошли длительный путь развития от монолитных систем к хорошо структурированным модульным системам, способным к развитию, расширению и легкому переносу на новые платформы.
В общем случае "структура" монолитной системы представляет собой отсутствие структуры (рисунок 4.1). ОС написана как набор процедур, каждая из которых может вызывать другие, когда ей это нужно. При использовании этой техники каждая процедура системы имеет хорошо определенный интерфейс в терминах параметров и результатов, и каждая вольна вызвать любую другую для выполнения некоторой нужной для нее полезной работы.
Рис. 4.1. Монолитная структура ОС
Для построения монолитной системы необходимо скомпилировать все отдельные процедуры, а затем связать их вместе в единый объектный файл с помощью компоновщика (примерами могут служить ранние версии ядра UNIX или Novell NetWare). Каждая процедура видит любую другую процедуру ( в отличие от структуры, содержащей модули, в которой большая часть информации является локальной для модуля, и процедуры модуля можно вызвать только через специально определенные точки входа).
Однако даже такие монолитные системы могут быть немного структурированными. При обращении к системным вызовам, поддерживаемым ОС, параметры помещаются в строго определенные места, такие, как регистры или стек, а затем выполняется специальная команда прерывания, известная как вызов ядра или вызов супервизора. Эта команда переключает машину из режима пользователя в режим ядра, называемый также режимом супервизора, и передает управление ОС. Затем ОС проверяет параметры вызова для того, чтобы определить, какой системный вызов должен быть выполнен. После этого ОС индексирует таблицу, содержащую ссылки на процедуры, и вызывает соответствующую процедуру. Такая организация ОС предполагает следующую структуру:
1. Главная программа, которая вызывает требуемые сервисные процедуры.
2. Набор сервисных процедур, реализующих системные вызовы.
3. Набор утилит, обслуживающих сервисные процедуры.
В этой модели для каждого системного вызова имеется одна сервисная процедура. Утилиты выполняют функции, которые нужны нескольким сервисным процедурам. Это деление процедур на три слоя показано на рисунке 4.2.
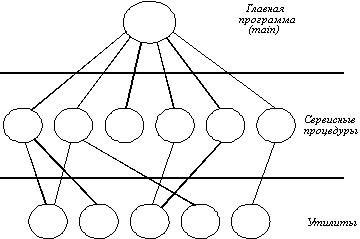
Рис. 4.2. Простая структуризация монолитной ОС
Обобщением предыдущего подхода является организация ОС как иерархии уровней. Уровни образуются группами функций операционной системы - файловая система, управление процессами и устройствами и т.п. Каждый уровень может взаимодействовать только со своим непосредственным соседом - выше- или нижележащим уровнем. Прикладные программы или модули самой операционной системы передают запросы вверх и вниз по этим уровням.
Первой системой, построенной таким образом была простая пакетная система THE, которую построил Дейкстра и его студенты в 1968 году.
Система имела 6 уровней. Уровень 0 занимался распределением времени процессора, переключая процессы по прерыванию или по истечении времени. Уровень 1 управлял памятью - распределял оперативную память и пространство на магнитном барабане для тех частей процессов (страниц), для которых не было места в ОП, то есть слой 1 выполнял функции виртуальной памяти. Слой 2 управлял связью между консолью оператора и процессами. С помощью этого уровня каждый процесс имел свою собственную консоль оператора. Уровень 3 управлял устройствами ввода-вывода и буферизовал потоки информации к ним и от них. С помощью уровня 3 каждый процесс вместо того, чтобы работать с конкретными устройствами, с их разнообразными особенностями, обращался к абстрактным устройствам ввода-вывода, обладающим удобными для пользователя характеристиками. На уровне 4 работали пользовательские программы, которым не надо было заботиться ни о процессах, ни о памяти, ни о консоли, ни об управлении устройствами ввода-вывода. Процесс системного оператора размещался на уровне 5.
В системе THE многоуровневая схема служила, в основном, целям разработки, так как все части системы компоновались затем в общий объектный модуль.
Дальнейшее обобщение многоуровневой концепции было сделано в ОС MULTICS. В системе MULTICS каждый уровень (называемый кольцом) является более привилегированным, чем вышележащий. Когда процедура верхнего уровня хочет вызвать процедуру нижележащего, она должна выполнить соответствующий системный вызов, то есть команду TRAP (прерывание), параметры которой тщательно проверяются перед тем, как выполняется вызов. Хотя ОС в MULTICS является частью адресного пространства каждого пользовательского процесса, аппаратура обеспечивает защиту данных на уровне сегментов памяти, разрешая, например, доступ к одним сегментам только для записи, а к другим - для чтения или выполнения. Преимущество подхода MULTICS заключается в том, что он может быть расширен и на структуру пользовательских подсистем. Например, профессор может написать программу для тестирования и оценки студенческих программ и запустить эту программу на уровне n, в то время как студенческие программы будут работать на уровне n+1, так что они не смогут изменить свои оценки.
Многоуровневый подход был также использован при реализации различных вариантов ОС UNIX.
Хотя такой структурный подход на практике обычно работал неплохо, сегодня он все больше воспринимается монолитным. В системах, имеющих многоуровневую структуру было нелегко удалить один слой и заменить его другим в силу множественности и размытости интерфейсов между слоями. Добавление новых функций и изменение существующих требовало хорошего знания операционной системы и массы времени. Когда стало ясно, что операционные системы живут долго и должны иметь возможности развития и расширения, монолитный подход стал давать трещину, и на смену ему пришла модель клиент-сервер и тесно связанная с ней концепция микроядра.
Модель клиент-сервер - это еще один подход к структурированию ОС. В широком смысле модель клиент-сервер предполагает наличие программного компонента - потребителя какого-либо сервиса - клиента, и программного компонента - поставщика этого сервиса - сервера. Взаимодействие между клиентом и сервером стандартизуется, так что сервер может обслуживать клиентов, реализованных различными способами и, может быть, разными производителями. При этом главным требованием является то, чтобы они запрашивали услуги сервера понятным ему способом. Инициатором обмена обычно является клиент, который посылает запрос на обслуживание серверу, находящемуся в состоянии ожидания запроса. Один и тот же программный компонент может быть клиентом по отношению к одному виду услуг, и сервером для другого вида услуг. Модель клиент-сервер является скорее удобным концептуальным средством ясного представления функций того или иного программного элемента в той или иной ситуации, нежели технологией. Эта модель успешно применяется не только при построении ОС, но и на всех уровнях программного обеспечения, и имеет в некоторых случаях более узкий, специфический смысл, сохраняя, естественно, при этом все свои общие черты.
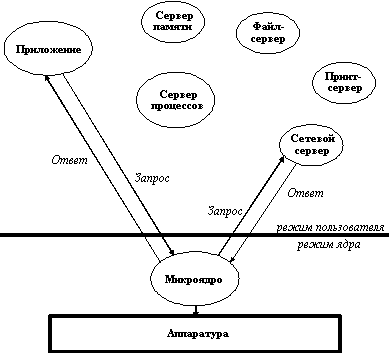
Рис. 4.3. Структура ОС клиент-сервер
Применительно к структурированию ОС идея состоит в разбиении ее на несколько процессов - серверов, каждый из которых выполняет отдельный набор сервисных функций - например, управление памятью, создание или планирование процессов. Каждый сервер выполняется в пользовательском режиме. Клиент, которым может быть либо другой компонент ОС, либо прикладная программа, запрашивает сервис, посылая сообщение на сервер. Ядро ОС (называемое здесь микроядром), работая в привилегированном режиме, доставляет сообщение нужному серверу, сервер выполняет операцию, после чего ядро возвращает результаты клиенту с помощью другого сообщения (рисунок 4.3).
Подход с использованием микроядра заменил вертикальное распределение функций операционной системы на горизонтальное. Компоненты, лежащие выше микроядра, хотя и используют сообщения, пересылаемые через микроядро, взаимодействуют друг с другом непосредственно. Микроядро играет роль регулировщика. Оно проверяет сообщения, пересылает их между серверами и клиентами, и предоставляет доступ к аппаратуре.
Данная теоретическая модель является идеализированным описанием системы клиент-сервер, в которой ядро состоит только из средств передачи сообщений. В действительности различные варианты реализации модели клиент-сервер в структуре ОС могут существенно различаться по объему работ, выполняемых в режиме ядра.
На одном краю этого спектра находится разрабатываемая фирмой IBM на основе микроядра Mach операционная система Workplace OS, придерживающаяся чистой микроядерной доктрины, состоящей в том, что все несущественные функции ОС должны выполняться не в режиме ядра, а в непривилегированном (пользовательском) режиме. На другом - Windows NT, в составе которой имеется исполняющая система (NT executive), работающая в режиме ядра и выполняющая функции обеспечения безопасности, ввода-вывода и другие.
Микроядро реализует жизненно важные функции, лежащие в основе операционной системы. Это базис для менее существенных системных служб и приложений. Именно вопрос о том, какие из системных функций считать несущественными, и, соответственно, не включать их в состав ядра, является предметом спора среди соперничающих сторонников идеи микроядра. В общем случае, подсистемы, бывшие традиционно неотъемлемыми частями операционной системы - файловые системы, управление окнами и обеспечение безопасности - становятся периферийными модулями, взаимодействующими с ядром и друг с другом.
Главный принцип разделения работы между микроядром и окружающими его модулями - включать в микроядро только те функции, которым абсолютно необходимо исполняться в режиме супервизора и в привилегированном пространстве. Под этим обычно подразумеваются машиннозависимые программы (включая поддержку нескольких процессоров), некоторые функции управления процессами, обработка прерываний, поддержка пересылки сообщений, некоторые функции управления устройствами ввода-вывода, связанные с загрузкой команд в регистры устройств. Эти функции операционной системы трудно, если не невозможно, выполнить программам, работающим в пространстве пользователя.
Есть два пути решения этой проблемы. Один путь - разместить несколько таких, чувствительных к режиму работы процессора, серверов, в пространстве ядра, что обеспечит им полный доступ к аппаратуре и , в то же время, связь с другими процессами с помощью обычного механизма сообщений. Такой подход был использован, например, при разработке Windows NT: кроме микроядра, в привилегированном режиме работает часть Windows NT, называемая executive управляющей программой. Она включает ряд компонентов, которые управляют виртуальной памятью, объектами, вводом-выводом и файловой системой (включая сетевые драйверы), взаимодействием процессов, и частично системой безопасности.
Другой путь, заключается в том, чтобы оставить в ядре только небольшую часть сервера, представляющую собой механизм реализации решения, а часть, отвечающую за принятие решения, переместить в пользовательскую область. В соответствии с этим подходом, например, в микроядре Mach, на базе которого разработана Workplace OS, размещается только часть системы управления процессами (и нитями), реализующая диспетчеризацию (то есть непосредственно переключение с процесса на процесс), а все функции, связанные с анализом приоритетов, выбором очередного процесса для активизации, принятием решения о переключении на новый процесс и другие аналогичные функции выполняются вне микроядра. Этот подход требует тесного взаимодействия между внешним планировщиком и резидентным диспетчером.
Здесь важно сделать различие - запуск процесса или нити требует доступа к аппаратуре, так что по логике - это функция ядра. Но ядру все равно, какую из нитей запускать, поэтому решения о приоритетах нитей и дисциплине постановки в очередь может принимать работающий вне ядра планировщик.
Кроме уже представленных соображений, перемещение планировщика на пользовательский уровень может понадобиться для чисто коммерческих целей. Некоторые производители ОС (например, IBM и OSF со своими вариантами микроядра Mach) планируют лицензировать свое микроядро другим поставщикам, которым может потребоваться заменить исходный планировщик на другой, поддерживающий, например, планирование в задачах реального времени или реализующий какой-то специальный алгоритм планирования. А вот другая ОС - Windows NT, также использующая микроядерную концепцию - воплотила понятие приоритетов реального времени в своем планировщике, резидентно расположенном в ядре, и это не дает возможности заменить ее планировщик на другой.
Как и управление процессами, управление памятью может распределяться между микроядром и сервером, работающим в пользовательском режиме. Например, в Workplace OS микроядро управляет аппаратурой страничной памяти. Пейджер (система управления страничной памятью), работающий вне ядра, определяет стратегию замещения страниц (т.е. решает, какие страницы следует удалить из памяти для размещения страниц, выбранных с диска в ответ на прерывание по отсутствию необходимой страницы), а микроядро выполняет перемещение выбранных пейджером страниц. Как и планировщик процессов, пейджер является заменяемой составной частью.
Драйверы устройств также могут располагаться как внутри ядра, так и вне его. При размещении драйверов устройств вне микроядра для обеспечения возможности разрешения и запрещения прерываний, часть программы драйвера должна исполняться в пространстве ядра. Отделение драйверов устройств от ядра делает возможной динамическую конфигурацию ОС. Кроме динамической конфигурации, есть и другие причины рассматривать драйверы устройств в качестве процессов пользовательского режима. СУБД, например, может иметь свой драйвер, оптимизированный под конкретный вид доступа к диску, но его нельзя будет подключить, если драйверы будут расположены в ядре. Этот подход также способствует переносимости системы, так как функции драйверов устройств могут быть во многих случаях абстрагированы от аппаратной части.
В настоящее время именно операционные системы, построенные с использованием модели клиент-сервер и концепции микроядра, в наибольшей степени удовлетворяют требованиям, предъявляемым к современным ОС.
Высокая степень переносимости обусловлена тем, что весь машинно-зависимый код изолирован в микроядре, поэтому для переноса системы на новый процессор требуется меньше изменений и все они логически сгруппированы вместе.
Технология микроядер является основой построения множественных прикладных сред, которые обеспечивают совместимость программ, написанных для разных ОС. Абстрагируя интерфейсы прикладных программ от расположенных ниже операционных систем, микроядра позволяют гарантировать, что вложения в прикладные программы не пропадут в течение нескольких лет, даже если будут сменяться операционные системы и процессоры.
Расширяемость также является одним из важных требований к современным операционным системам. Является ли операционная система маленькой, как DOS, или большой, как UNIX, для нее неизбежно настанет необходимость приобрести свойства, не заложенные в ее конструкцию. Увеличивающаяся сложность монолитных операционных систем делала трудным, если вообще возможным, внесение изменений в ОС с гарантией надежности ее последующей работы. Ограниченный набор четко определенных интерфейсов микроядра открывает путь к упорядоченному росту и эволюции ОС.
Обычно операционная система выполняется только в режиме ядра, а прикладные программы - только в режиме пользователя, за исключением тех случаев, когда они обращаются к ядру за выполнением системных функций. В отличие от обычных систем, система построенная на микроядре, выполняет свои серверные подсистемы в режиме пользователя, как обычные прикладные программы. Такая структура позволяет изменять и добавлять серверы, не влияя на целостность микроядра.
Иногда имеется потребность и в сокращении возможностей ОС. На Windows NT или UNIX перешло бы большее число пользователей, если бы для этих операционных систем не требовалось 16 Мб оперативной памяти и 70 Мб и более пространства на жестком диске. Микроядро не обязательно подразумевает небольшую систему. Надстроенные службы, типа файловой системы и системы управления окнами, добавят к ней немало. Конечно же, не всем нужна безопасность класса C2 или распределенные вычисления. Если важные, но предназначенные для определенных потребителей свойства можно исключать из состава системы, то базовый продукт подойдет более широкому кругу пользователей.
Использование модели клиент-сервер повышает надежность. Каждый сервер выполняется в виде отдельного процесса в своей собственной области памяти, и таким образом защищен от других процессов. Более того, поскольку серверы выполняются в пространстве пользователя, они не имеют непосредственного доступа к аппаратуре и не могут модифицировать память, в которой хранится управляющая программа. И если отдельный сервер может потерпеть крах, то он может быть перезапущен без останова или повреждения остальной части ОС.
Эта модель хорошо подходит для распределенных вычислений, так как отдельные серверы могут работать на разных процессорах мультипроцессорного компьютера или даже на разных компьютерах. При получении от процесса сообщения микроядро может обработать его самостоятельно или переслать другому процессу. Так как микроядру все равно, пришло ли сообщение от локального или удаленного процесса, подобная схема передачи сообщений является элегантным базисом для RPC. Однако такая гибкость не дается даром. Пересылка сообщений не так быстра, как обычные вызовы функций, и ее оптимизация является критическим фактором успеха операционной системы на основе микроядра. Windows NT, например, в некоторых случаях заменяет перенос сообщений на коммуникационные каналы с общей памятью, имеющие более высокую пропускную способность. Хотя это и стоит дороже в смысле потребления фиксированной памяти микроядра, данная альтернатива может помочь сделать модель пересылки сообщений более практичной.
Коммерческие версии микроядер
Одной из первых представила понятие микроядра фирма Next, которая использовала в своих компьютерах систему Mach, прошедшую большой путь развития в университете Карнеги-Меллона при помощи агентства Министерства обороны США DARPA. Теоретически, ее небольшое привилегированное ядро, окруженное службами пользовательского режима, должно было обеспечить беспрецедентную гибкость и модульность. Но на практике это преимущество было несколько уменьшено наличием монолитного сервера операционной системы BSD 4.3, который выполнялся в пользовательском пространстве над микроядром Mach. Однако Mach дал Next возможность предоставить службу передачи сообщений и объектно-ориентированные средства, которые предстали перед конечными пользователями в качестве элегантного интерфейса пользователя с графической поддержкой конфигурирования сети, системного администрирования и разработки программного обеспечения.
Затем пришла Microsoft Windows NT, рекламировавшая в качестве ключевых преимуществ применения микроядра не только модульность, но и переносимость. Конструкция NT позволяет ей работать на системах на основе процессоров Intel, MIPS и Alpha (и последующих), и поддерживать симметричную многопроцессорность. Из-за того, что NT должна была выполнять программы, написанные для DOS, Windows, OS/2 и использующих соглашения POSIX, Microsoft использовала модульность, присущую микроядерному подходу для того, чтобы сделать структуру NT не повторяющей ни одну из существующих операционных систем. Вместо этого NT поддерживает каждую надстроенную операционную систему в виде отдельного модуля или подсистемы.
Более современные архитектуры микроядра были предложены Novell, USL, Open Software Foundation, IBM, Apple и другими. Одним из основных соперников NT на арене микроядер является микроядро Mach 3.0, которое и IBM и OSF взялись привести к коммерческому виду. (Next в качестве основы для NextStep пока использует Mach 2.5, но при этом внимательно присматривается к Mach 3.0.). Основной соперник Mach - микроядро Chorus 3.0 фирмы Chorus Systems, выбранный USL за основу для своих предложений. Это же микроядро будет использоваться в SpringOS фирмы Sun, объектно-ориентированном преемнике Solaris.
Сегодня стало ясно, что имеется тенденция движения от монолитных систем в сторону подхода с использованием небольших ядер. Именно такой подход уже использовался компаниями QNX Software и Unisys, в течение нескольких лет поставляющих пользующиеся успехом операционные системы на основе микроядра. QNX фирмы QNX Software обслуживает рынок систем реального времени, а CTOS фирмы Unisys популярна в области банковского дела.
Хотя технология микроядер и заложила основы модульных систем, способных развиваться регулярным образом, она не смогла в полной мере обеспечить возможности расширения систем. В настоящее время этой цели в наибольшей степени соответствует объектно-ориентированный подход, при котором каждый программный компонент является функционально изолированным от других.
Основным понятием этого подхода является "объект". Объект - это единица программ и данных, взаимодействующая с другими объектам посредством приема и передачи сообщений. Объект может быть представлением как некоторых конкретных вещей - прикладной программы или документа, так и некоторых абстракций - процесса, события.
Программы (функции) объекта определяют перечень действий, которые могут быть выполнены над данными этого объекта. Объект-клиент может обратиться к другому объекту, послав сообщение с запросом на выполнение какой-либо функции объекта-сервера.
Объекты могут описывать сущности, которые они представляют, с разной степенью детализации. Для обеспечения преемственности при переходе к более детальному описанию разработчикам предлагается механизм наследования свойств уже существующих объектов, то есть механизм, позволяющий порождать более конкретные объекты из более общих. Например, при наличии объекта "текстовый документ" разработчик может легко создать объект "текстовый документ в формате Word 6.0", добавив соответствующее свойство к базовому объекту. Механизм наследования позволяет создать иерархию объектов, в которой каждый объект более низкого уровня приобретает все свойства своего предка.
Внутренняя структура данных объекта скрыта от наблюдения. Нельзя произвольно изменять данные объекта. Для того, чтобы получить данные из объекта или поместить данные в объект, необходимо вызывать соответствующие объектные функции. Это изолирует объект от того кода, который использует его. Разработчик может обращаться к функциям других объектов, или строить новые объекты путем наследования свойств других объектов, ничего не зная о том, как они сконструированы. Это свойство называется инкапсуляцией.
Таким образом, объект предстает для внешнего мира в виде "черного ящика" с хорошо определенным интерфейсом. С точки зрения разработчика, использующего объект, пока внешняя реакция объекта остается без изменений, не имеют значения никакие изменения во внутренней реализации. Это дает возможность легко заменять одну реализацию объекта другой, например, в случае смены аппаратных средств; при этом сложное программное окружение, в котором находятся заменяемые объекты, не потребует никаких изменений.
С другой стороны, способность объектов представать в виде "черного ящика" позволяет упаковывать в них и представлять в виде объектов уже существующие приложения, ничего в них не изменяя.
Использование объектно-ориентированного подхода особенно эффективно при создании активно развивающегося программного обеспечения, например, при разработке приложений, предназначенных для выполнения на разных аппаратных платформах.
Полностью объектно-ориентированные операционные системы очень привлекательны для системных программистов, так как, используя объекты системного уровня, программисты смогут залезать вглубь операционных систем для приспособления их к своим нуждам, не нарушая целостность системы.
Но особенно большие перспективы имеет этот подход в реализации распределенных вычислительных сред. В то время, как сейчас разные пакеты, работающие в данный момент в сети, представляют собой статически связанные наборы программ, в будущем, с использованием объектно-ориентированного подхода, они могут превратиться в единую совокупность динамически связываемых объектов, где каждый объект оперативно устанавливает и разрывает связи с другими объектами для выполнения актуальных в данный момент задач. Приложения, созданные для такой сетевой среды, основанной на объектах, могут выполняться, динамически обращаясь к множеству объектов, независимо от их местонахождения в сети и независимо от их операционной среды.
Поскольку любое объектно-ориентированное приложение представляет собой набор объектов, разработчику желательно иметь стандартные средства для управления объектами и организации их взаимодействия. При использовании и разработке объектно-ориентированных приложений в неоднородных распределенных средах, нужны также средства, упрощающие доступ к объектам сети. При возникновении запроса к какому-либо объекту распределенной среды, независимо от того, находится требуемый объект на том же компьютере или на одном из удаленных, прозрачным образом должен быть выполнен поиск объекта, передача ему сообщения, и возврат ответа. Для обеспечения прозрачного обнаружения объектов, все они должны быть снабжены ссылками, хранящимися в каталогах. Отсюда вытекает очень сложная проблема организации службы каталогов, позволяющей программистам именовать и искать объекты в сети, которая, вообще говоря, может быть разбросана по всему миру.
Однако, несмотря на упомянутые сложности и проблемы, объектно-ориентированный подход является одной из самых перспективных тенденций в конструировании программного обеспечения.
Коммерческие объектно-ориентированные средства
Объектно-ориентированный подход к построению операционных систем, придающий порядок процессу добавления модульных расширений к небольшому ядру был принят на вооружение многими известными фирмами, такими как Microsoft, Apple, IBM, Novell/USL (UNIX Systems Laboratories) и Sun Microsystems - все они развернули свои операционные системы в этом направлении. Taligent, совместное предприятие IBM и Apple, надеется опередить всех со своей от начала до конца объектно-ориентированной операционной системой. Тем временем Next поставляет Motorola- и Intel-версии NextStep, наиболее продвинутой объектно-ориентированной операционной системы из имеющихся. Хотя NextStep и не имеет объектной ориентированности сверху донизу, как это планируется в разработках Taligent, но она доступна уже сегодня.
Одним из первых применений объектных систем для большинства пользователей станут основанные на объектах прикладные программы. К объектно-ориентированным технологиям этого уровня, уже имеющимся сейчас или доступным в ближайшем будущем относятся:
Средства OLE
Для пользователей Windows объектно-ориентированный подход проявляется при работе с программами, использующими технологию OLE фирмы Microsoft. В первой версии OLE, которая дебютировала в Windows 3.1, пользователи могли вставлять объекты в документы-клиенты. Такие объекты устанавливали ссылку на данные (в случае связывания) или содержали данные (в случае внедрения) в формате, распознаваемом программой-сервером. Для запуска программы-сервера пользователи делали двойной щелчок на объекте, посредством чего передавали данные серверу для редактирования. OLE 2.0, доступная в настоящее время в качестве расширения Windows 3.1, переопределяет документ-клиент как контейнер. Когда пользователь щелкает дважды над объектом OLE 2.0, вставленным в документ-контейнер, он активизируется в том же самом месте. Представим, например, что контейнером является документ Microsoft Word 6.0, а вставленный объект представляет собой набор ячеек в формате Excel 5.0. Когда вы щелкнете дважды над объектом электронной таблицы, меню и управляющие элементы Word как по волшебству поменяются на меню Excel. В результате, пока объект электронной таблицы находится в фокусе, текстовый процессор становится электронной таблицей.
Инфраструктура, требуемая для обеспечения столь сложных взаимодействий объектов, настолько обширна, что Microsoft называет OLE 2.0 "1/3 операционной системы". Хранение объектов, например, использует docfile, который в действительности является миниатюрной файловой системой, содержащейся внутри обычного файла MS-DOS. Docfile имеет свои собственные внутренние механизмы для семантики подкаталогов, блокировок и транзакций (т.е. фиксации-отката).
Наиболее заметный недостаток OLE - отсутствие сетевой поддержки, и это будет иметь наивысший приоритет при разработке будущих версий OLE. Следующая основная итерация OLE появится в распределенной, объектной версии Windows, называемой Cairo (Каир), ожидаемой в 1995 году.
Стандарт OpenDoc
Apple, совместно с WordPerfect, Novell, Sun, Xerox, Oracle, IBM и Taligent, известными вместе как Component Integration Laboratory (Лаборатория по объединению компонентов), также занимается архитектурой объектно-ориентированных составных документов, называемой OpenDoc. Создаваемый для работы на разных платформах, этот проект значительно отстает по степени готовности от OLE 2.0.
Ключевыми технологиями OpenDoc являются механизм хранения Бенто (названный так в честь японской тарелки с отделениями для разной пищи), технология сценариев (scripting), позаимствованная в значительной степени из AppleSript, и SOM фирмы IBM. В Бенто-документе каждый объект имеет постоянный идентификатор, перемещающийся вместе с ним от системы к системе. Хранение не только является транзакционным, как в OLE, но и позволяет держать и отслеживать многочисленные редакции каждого объекта. Если имеется несколько редакций документа, то реально храниться будут только изменения от одной редакции к другой. Верхняя граница числа сохраняемых редакций будет определяться пользователем.
Команда Apple планирует сделать OpenDoc совместимым с Microsoft OLE. Если план завершится успехом, система OpenDoc сможет окружать объекты OLE слоем программ трансляции сообщений. Контейнер OpenDoc будет видеть встроенный объект OLE как объект OpenDoc, а объект OLE будет представлять свой контейнер, как контейнер OLE. Утверждается, что будет допустима также и обратная трансляция по этому сценарию, когда объекты OpenDoc функционируют в контейнерах OLE. Слой трансляции разрабатывается WordPerfect при помощи Borland, Claris, Lotus и других.
В основе OLE и OpenDoc лежат две соперничающие объектные модели: Microsoft COM (Component Object Model - компонентная объектная модель) и IBM SOM. Каждая определяет протоколы, используемые объектами для взаимодействия друг с другом. Основное их различие заключается в том, что SOM нейтральна к языкам программирования и поддерживает наследование, тогда как COM ориентирована на С ++ и вместо механизма наследования использует альтернативный механизм, который Microsoft называет агрегацией.
Семейство CORBA
Hewlett-Packard, Sun Microsystems и DEC экспериментируют с объектами уже много лет. Теперь эти компании и много других объединились вместе, основав промышленную коалицию под названием OMG (Object Management Group), разрабатывающую стандарты для обмена объектами. OMG CORBA (Common Object Request Broker Architecture - Общая архитектура посредника обработки объектных запросов) закладывает фундамент распределенных вычислений с переносимыми объектами. CORBA задает способ поиска объектами других объектов и вызова их методов. SOM согласуется с CORBA. Если вы пользуетесь DSOM под OS/2, вы сможете вызывать CORBA-совместимые объекты, работающие на HP, Sun и других архитектурах. Означает ли это возможность редактировать объект OpenDoc, сделанный на Macintosh, в документе-контейнере на RISC-рабочей станции? Вероятно, нет. CORBA может гарантировать только механизм нижнего уровня, посредством которого одни объекты вызывают другие. Для успешного взаимодействия требуется также понимание сообщений друг друга.
В то время как некоторые идеи (например, объектно-ориентированный подход) непосредственно касаются только разработчиков и лишь косвенно влияют на конечного пользователя, концепция множественных прикладных сред приносит пользователю долгожданную возможность выполнять на своей ОС программы, написанные для других операционных систем и других процессоров.
И сейчас дополнительное программное обеспечение позволяет пользователям некоторых ОС запускать чужие программы (например, Mac и UNIX позволяют выполнять программы для DOS и Windows). Но в зарождающемся поколении операционных систем средства для выполнения чужих программ становятся стандартной частью системы. Выбор операционной системы больше не будет сильно ограничивать выбор прикладных программ. Хотя столкновение пользовательских интерфейсов программ для Mac, Windows и UNIX на одном и том же экране и заставит пользователя немного потрудиться, но все равно, множественные прикладные среды операционных систем скоро станут такими же стандартными, как мыши и меню.
Множественные прикладные среды обеспечивают совместимость данной ОС с приложениями, написанными для других ОС и процессоров, на двоичном уровне, а не на уровне исходных текстов. Для пользователя, купившего в свое время пакет (например, Lotus 1-2-3) для MS DOS, важно, чтобы он мог запускать этот полюбившийся ему пакет без каких-либо изменений и на своей новой машине, построенной, например, на RISC-процессоре, и работающей под управлением, например, Windows NT.
При реализации множественных прикладных сред разработчики сталкиваются с противоречивыми требованиями. С одной стороны, задачей каждой прикладной среды является выполнение программы по возможности так, как если бы она выполнялась на "родной" ОС. Но потребности этих программ могут входить в конфликт с конструкцией современной операционной системы. Специализированные драйверы устройств могут противоречить требованиям безопасности. Могут конфликтовать схемы управления памятью и оконные системы. Чисто экономические вопросы (например, стоимость лицензирования программ и угроза судебного преследования) также могут повлиять на дизайн чужих прикладных сред. Но самой большой потенциальной проблемой является производительность - прикладная среда должна выполнять программы с приемлемой скоростью.
Этому требованию не могут удовлетворить широко используемые ранее эмулирующие системы. Для сокращения времени на выполнение чужих программ прикладные среды используют имитацию программ на уровне библиотек. Эффективность этого подхода связана с тем, что большинство сегодняшних программ работают под управлением GUI (графических интерфейсов пользователя) типа Windows, Mac или UNIX Motif, при этом приложения тратят большую часть времени, производя некоторые хорошо предсказуемые вещи. Они непрерывно выполняют вызовы библиотек GUI для манипулирования окнами и для других связанных с GUI действий. И это то, что позволяет прикладным средам возместить время, потраченное на эмулирование команды за командой. Тщательно сделанная прикладная среда имеет в своем составе библиотеки, имитирующие внутренние библиотеки GUI, но написанные на родном коде, то есть она совместима с программным интерфейсом другой ОС. Иногда такой подход называют трансляцией для того, чтобы отличать его от более медленного процесса эмулирования кода по одной команде за раз.
Например, для Windows-программы, работающей на Mac, при интерпретировании команд 80x86 производительность может быть очень низкой. Но когда производится вызов функции открытия окна, модуль прикладной среды может переключить его на перекомпилированную для 680x0 подпрограмму открытия окна. Так как библиотекам GUI не нужно дешифрировать и имитировать каждую команду, то в частях программы, относящихся к вызовам GUI ABI (Application Binary Interface - двоичный интерфейс прикладного программирования), производительность может резко вырасти. В результате на таких участках кода скорость работы программы может достичь (а возможно, и превзойти) скорость работы на своем родном процессоре.
Сегодня в типичных программах значительная часть кода занята вызовом GUI ABI. Apple утверждает, что программы для Mac тратят до 90 процентов процессорного времени на выполнение подпрограмм из Mac toolbox, а не на уникальные для этих программ действия. SunSelect говорит, что программы для Windows тратят от 60 до 80 процентов времени на работу в ядре Windows. В результате при эмуляции программы на основе GUI потери производительности могут быть значительно меньше. SunSelect заявляет, что его новая прикладная среда Windows, WABI (Windows Application Binary Interface - двоичный интерфейс прикладных программ Windows), благодаря сильно оптимизированным библиотекам, на некоторых платформах при исполнении одних и тех же тестов может обогнать настоящий Microsoft Windows.
С позиции использования прикладных сред более предпочтительным является способ написания программ, при котором программист для выполнения некоторой функции обращается с вызовом к операционной системе, а не пытается более эффективно реализовать эквивалентную функцию самостоятельно, работая напрямую с аппаратурой. Отбить у программистов охоту "обращаться к металлу" сможет наличие в библиотеках мощных и сложных программ, к которым гораздо проще обращаться, чем писать самому.
Модульность операционных систем нового поколения позволяет намного легче реализовать поддержку множественных прикладных сред. В отличие от старых операционных систем, состоящих из одного большого блока для всех практических применений, разбитого произвольным образом на части, новые системы являются модульными, с четко определенными интерфейсами между составляющими. Это делает создание дополнительных модулей, объединяющих эмуляцию процессора и трансляцию библиотек, значительно более простым.
К усовершенствованным операционным системам, явно содержащим средства множественных прикладных сред, относятся: IBM OS/2 2.x и Workplace OS, Microsoft Windows NT, PowerOpen компании PowerOpen Association и версии UNIX от Sun Microsystems, IBM и Hewlett-Packard. Кроме того, некоторые компании переделывают свои интерфейсы пользователя в виде модулей прикладных сред, а другие поставщики предлагают продукты для эмуляции и трансляции прикладных сред, работающие в качестве прикладных программ.
Существует много разных стратегий по воплощению идеи множественных прикладных сред, и некоторые из этих стратегий диаметрально противоположны. В случае UNIX, транслятор прикладных сред обычно делается, как и другие прикладные программы, плавающим на поверхности операционной системы. В более современных операционных системах типа Windows NT или Workplace OS модули прикладной среды выполняются более тесно связанными с операционной системой, хотя и обладают по-прежнему высокой независимостью. А в OS/2 с ее более простой, слабо структурированной архитектурой средства организации прикладных сред встроены глубоко в операционную систему.
Использование множественных прикладных сред обеспечит пользователям большую свободу выбора операционных систем и более легкий доступ к более качественному программному обеспечению.
Распределенные вычисления имеют дело с понятиями более высокого уровня, чем физические носители, каналы связи и методы передачи по ним сообщений. Распределенная среда должна дать пользователям и приложениям прозрачный доступ к данным, вычислениям и другим ресурсам в гетерогенных системах, представляющих собой набор средств различных производителей. Стратегические архитектуры каждого крупного системного производителя базируются сейчас на той или иной форме распределенной вычислительной среды (DCE). Ключом к пониманию выгоды такой архитектуры является прозрачность. Пользователи не должны тратить свое время на попытки выяснить, где находится тот или иной ресурс, а разработчики не должны писать коды для своих приложений, использующие местоположение в сети. Никто не заинтересован в том, чтобы заставлять разработчиков приложений становиться гуру коммуникаций, или же в том, чтобы заставлять пользователей заботиться о монтировании удаленных томов. Кроме того, сеть должна быть управляемой. Окончательной картиной является виртуальная сеть: набор сетей рабочих групп, отделов, предприятий, объединенных сетей предприятий, которые кажутся конечному пользователю или приложению единой сетью с простым доступом.
Одной из технологий, которая будет играть большое значение для будущего распределенных вычислений является технология DCE (Distributed Computing Environment) некоммерческой организации Open Software foundation (OSF). DCE OSF - это интегрированный набор функций, независимых от операционной системы и сетевых средств, которые обеспечивают разработку, использование и управление распределенными приложениями. Из-за их способности обеспечивать управляемую, прозрачную и взаимосвязанную работу систем различных производителей и различных платформ, DCE является одной из самых важных технологий десятилетия.
Большинство из ведущих фирм-производителей ОС договорились о поставках DCE в будущих версиях своих системных и сетевых продуктов. Например, IBM, которая предлагает несколько DCE-продуктов, базирующихся на AIX, распространила их и на сектор сетей персональных компьютеров. В сентябре 1993 года IBM начала поставлять инструментальные средства для разработки DCE-приложений - DCE SDK для OS/2 и Windows, и в это же время выпустила на рынок свой первый DCE-продукт для пользователей персональных компьютеров - DCE Client for OS/2. Компания IBM достаточно далеко продвинулась в реализации спецификации DCE в своих продуктах, обогнав Microsoft, Novell и Banyan. Сейчас она продает как отдельный продукт клиентскую часть служб DCE для операционных сред MVS, OS/400, OS/2, AIX и Windows. IBM собирается реализовать отсутствующую в LAN Server единую справочную службу и новую службу безопасности в соответствии со спецификацией DCE и выпустить интегрированный вариант DCE/LAN Server в конце этого года.
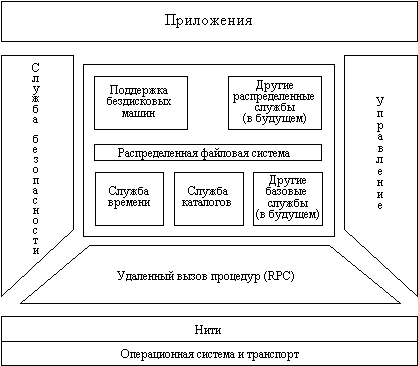
Рис. 4.4. Архитектура средств OSF DCE
Некоторые крупные фирмы-потребители программных продуктов обращаются непосредственно в OSF за лицензиями на первые версии DCE OSF.
В настоящее время DCE состоит из 7 средств и функций, которые делятся на базовые распределенные функции и средства разделения данных. Базовые распределенные функции включают:
Функции разделения данных строятся над базовыми функциями и включают:
На рисунке 4.4 показана архитектура DCE OSF. Эта архитектура представляет собой многоуровневый набор интегрированных средств. Внизу расположены базисные службы, такие как ОС, а на самом верхнем уровне находятся потребители средств DCE приложения. Средства безопасности и управления пронизывают все уровни. OSF резервирует место для функций, которые могут появиться в будущем, таких как спулинг, поддержка транзакций и распределенная объектно-ориентированная среда.
Нити
Обычно приложения имеют дело с процессами, каждый из которых состоит из одной нити управления.
Нити - это важная модель для выражения параллелизма внутри процесса, особенно для распределенного окружения. Например, возможности многонитевой обработки становятся особенно важными в контексте RPC. RPC является синхронным механизмом по своей природе: клиент делает вызов удаленной функции и ожидает выполнения вызова. При использовании нитей одна нить может сделать запрос, а другая начать обрабатывать данные от другого запроса. Следовательно, использование нитей может существенно улучшить производительность распределенного приложения.
Нитевая модель предъявляет меньшие требования к искусству программиста, чем другие альтернативы параллелизма, такие как асинхронные операции или разделение памяти.
Поскольку поддержка нитей дает большой выигрыш в производительности, большинство современных операционных систем является многонитевыми. Однако многие используемые в настоящее время операционные системы таковыми не являются. DCE OSF предлагает специальный пакет, предназначенный для обеспечения многонитевости для организации распределенных приложений в ОС, не имеющих собственных встроенных средств поддержки многонитевости. Этот пакет выполнен как библиотека функций работы с нитями.
По сравнению со встроенными в ядро ОС функциями поддержки нитей, библиотечная их реализация имеет некоторые функциональные ограничения. С другой стороны, в этом случае предоставляются хорошие шансы для обеспечения совместимости свойств нитей в гетерогенных средах.
Все остальные службы DCE OSF - RPC, службы безопасности, каталогов и времени, распределенная файловая система - используют сервис этого пакета.
Рассмотрим пакет, реализующий нити в DCE OSF, более подробно. Как и большинство программного обеспечения DCE, этот пакет большой и сложный. Он состоит из 51 библиотечной функции, относящейся к нитям, которыми могут пользоваться прикладные программы. Многие из них не являются необходимыми, а разработаны только для удобства. Мы рассмотрим только основные.
Эти функции удобно разделить на 7 категорий, каждая из которых имеет дело с определенным аспектом работы с нитями. Первая категория имеет дело с управлением нитями. В нее входят вызовы:
CREATE - создает новую нить
EXIT - вызывается нитью при завершении
JOIN - подобен системному вызову WAIT в UNIX
DETACH - отсоединение нити-потомка
Эти вызовы позволяют создавать и завершать нити. Родительская нить может ждать потомка, используя вызов join, подобно вызову wait в UNIX'е. Если родительская нить не планирует этого, то она может отсоединиться от потомка, сделав вызов detach. В этом случае, когда нить-потомок завершается, ее память освобождается немедленно, вместо обычного ожидания родителя, который издал вызов join.
Вторая категория функций позволяет пользователю создавать, разрушать и управлять шаблонами для нитей, для семафоров (в данном случае имеются ввиду бинарные семафоры, имеющие два состояния, называемые мьютексами). Шаблоны могут использоваться с соответствующими начальными условиями. При создании объекта один из параметров вызова create является указателем на шаблон. Например, шаблон нити имеет по умолчанию размер стека 8 К. Все нити, созданные с помощью этого шаблона имеют размер стека 8 К. Смысл использования шаблонов в том, что они позволяют не задавать все параметры создаваемого объекта.
Существуют системные вызовы добавления новых атрибутов к шаблонам. Вызовы attr_create и attr_delete создают и удаляют шаблоны нитей. Другие вызовы позволяют программе читать и модифицировать атрибуты шаблона, такие как размер стека или параметры планирования. Имеются также шаблоны для создания и удаления семафоров.
Третья группа вызовов содержит пять функций для управления мьютексами: создание, удаление, блокирование, разблокирование.
При работе с семафорами возникает очевидный вопрос, что случится, если использовать операцию "разблокировать" по отношению к мьютексу, который не заблокирован. Сохранится ли эта операция или будет потеряна? Эта проблема и вынудила Дейкстру ввести в свое время семафоры, при использовании которых порядок выполнения операций блокирования и разблокирования не имеет значения. В результате не возникает эффекта гонок. Логика работы мьютекса в DCE зависит от реализации, что, конечно, не позволяет писать переносимые программы.
Существует два типа мьютексов в DCE - быстрые и дружественные. Быстрый мьютекс является аналогом блокировки в СУБД. Если процесс пытается заблокировать незаблокированную запись, то эта операция выполняется успешно. Однако, если он попытается применить эту блокировку второй раз, то он сам заблокируется, ожидая, пока кто-нибудь не снимет блокировку с мьютекса.
Дружественный мьютекс позволяет нити заблокировать уже заблокированный мьютекс. Предположим, что главная программа блокирует семафор, а затем вызывает функцию, которая также блокирует мьютекс. Чтобы избежать клинча, принимается и вторая блокировка. Если количество открытий и закрытий мьютекса совпадает, связанные операции блокирования-разблокирования могут иметь произвольную глубину вложения. Разработчики пакета, очевидно не пришли к согласию относительно того, что делать с повторной блокировкой от той же нити, и решили реализовать обе версии.
RPC
Хорошо известный механизм для реализации распределенных вычислений, RPC, расширяет традиционную модель программирования - вызов процедуры - для использования в сети. RPC может составлять основу распределенных вычислений. Теоретически программист не должен становиться экспертом по коммуникационным средствам для того, чтобы написать распределенное сетевое приложение. При использовании RPC программист будет применять специальный язык для описания операций. Данное описание обрабатывается компилятором, который создает код как для клиента, так и для сервера. Для обеспечения такого типа функций средства RPC должны быть простыми, прозрачными, надежными и высокопроизводительными.
Средства RPC пакета DCE OSF обладают простотой. Они приближаются к модели вызова локальных процедур насколько это возможно. Они почти не требуют изменения концептуального мышления программиста, и поэтому уменьшают время его переподготовки. Это особенно важно для коллективов программистов, работающих в фирмах, которые не являются производителями коммерческих программных продуктов.
Неизменность протокола - это другая особенность RPC DCE OSF. Этот протокол четко определен и не может изменяться пользователем (в данном случае разработчиком сетевых приложений). Такая неизменность, гарантируемая ядром, является важным свойством в гетерогенных средах, требующих согласованной работы. В отличие от OSF, некоторые другие разработчики средств RPC полагают, что гибкость и возможность приспосабливать эти средства к потребностям пользователей являются более важными.
Средства RPC DCE OSF поддерживают ряд транспортных протоколов и позволяют добавлять новые транспортные протоколы, сохраняя при этом свои функциональные свойства.
DCE RPC эффективно используется в других службах DCE: в службах безопасности, каталогов и времени, в распределенной файловой системе. DCE RPC интегрируется с системой идентификации для обеспечения защиты доступа и с нитями клиента и сервера для того, чтобы, сохраняя синхронный характер выполнения вызова, обеспечить параллелизм. Способность RPC посылать и получать потоки типизированных данных неопределенной длины используется в распределенной файловой системе.
Распределенная служба каталогов
Задачей службы каталогов в распределенной сети является поиск сетевых объектов, то есть пользователей, ресурсов, данных или приложений. Служба каталогов (или иначе, имен ) должна отобразить большое количество системных объектов (пользователей, организаций, групп, компьютеров, принтеров, файлов, процессов, сервисов) на множество понятных пользователю имен. Эта проблема сложна даже для гомогенных сетей, так как персонал и оборудование перемещается, изменяет свои имена, местонахождение и т.д. В гетерогенных глобальных сетях служба каталогов становится намного более сложной, из-за необходимости синхронизации различных баз данных каталогов. Более того, при появлении в сети распределенных приложений служба каталогов должна начать отслеживание всех таких объектов и всех их компонентов.
Хорошая служба каталогов делает использование распределенного окружения прозрачным для пользователя. Пользователям не нужно знать расположение удаленного принтера, файла или приложения.
OSF определяет двухярусную архитектуру для службы каталогов для целей адресации межячеечного и глобального взаимодействия. Ячейка (cell) - это фундаментальная организационная единица для систем в DCE OSF. Ячейки могут иметь социальные, политические или организационные границы. Ячейки состоят из компьютеров, которые должны часто взаимодействовать друг с другом - это могут быть, например, рабочие группы, отделы, или отделения компаний. В общем случае компьютеры в ячейке географически близки. Размер ячеек изменяется от 2 до 1000 компьютеров, хотя OSF считает наиболее приемлемым диапазон от десятков до сотен компьютеров.
Некоторые производители и пользователи агитируют за реализацию X.500 как общей службы каталогов на всех уровнях. Но OSF полагает, что использование X.500 на уровне рабочей группы (то есть ячейки) было бы слишком громоздким из-за требований к программному обеспечению по производительности - особенно, когда более гибкие средства службы каталогов уровня ячейки уже существуют на рынке.
Служба каталогов DCE состоит из 4-х элементов:
Распределенная служба безопасности
Имеется две больших группы функций службы безопасности: идентификация и авторизация. Идентификация проверяет идентичность объекта (например, пользователя или сервиса). Авторизация (или управление доступом) назначает привилегии объекту, такие как доступ к файлу.
Авторизация - это только часть решения. В распределенной сетевой среде обязательно должна работать глобальная служба идентификации, так как рабочей станции нельзя доверить функции идентификации себя или своего пользователя. Служба идентификации представляет собой механизм передачи третьей стороне функций проверки идентичности пользователя.
Служба безопасности OSF DCE базируется на системе идентификации Kerberos, разработанной в 80-е годы и расширенной за счет добавления элементов безопасности. Kerberos использует шифрование, основанное на личных ключах, для обеспечения трех уровней защиты. Самый нижний уровень требует, чтобы пользователь идентифицировался только при установлении начального соединения, предполагая, что дальнейшая последовательность сетевых сообщений исходит от идентифицированного пользователя. Следующий уровень требует идентификацию для каждого сетевого сообщения. На последнем уровне все сообщения не только идентифицируются, но и шифруются.
Система безопасности не должна сильно усложнять жизнь конечного пользователя в сети, то есть он не должен запоминать десятки паролей и кодов.
Весьма полезным сетевым средством для целей безопасности является служба прав доступа или, другими словами, авторизация. Служба авторизации OSF базируется на POSIX-совместимых списках прав доступа - ACL.
В то время как система Kerberos основана на личных ключах, в настоящее время широкое распространение получили методы, основанные на публичных ключах (например, метод RSA). OSF собирается сделать DCE-приложения переносимыми из Kerberos в RSA.
Распределенная файловая система DFS OSF
Распределенная файловая система DFS OSF предназначена для обеспечения прозрачного доступа к любому файлу, расположенному в любом узле сети. Главная концепция такой распределенной файловой системы - это простота ее использования.
Распределенная файловая система должна иметь единое пространство имен. Файл должен иметь одинаковое имя независимо от того, где он расположен. Другими желательными свойствами являются интегрированная безопасность, согласованность и доступность данных, надежность и восстанавливаемость, производительность и масштабируемость до очень больших конфигураций без уменьшения производительности и независимое от места расположения управление и администрирование.
Распределенная файловая система DFS OSF базируется на известной файловой системе AFS (The Andrew File System).
Файловая система AFS
AFS была разработана в университете Карнеги-Меллона и названа в честь спонсоров-основателей университета Andrew Carnegie и Andrew Mellon. Эта система, созданная для студентов университета, не является прозрачной системой, в которой все ресурсы динамически назначаются всем пользователям при возникновении потребностей. Несмотря на это, файловая система была спроектирована так, чтобы обеспечить прозрачность доступа каждому пользователю, независимо от того, какой рабочей станцией он пользуется.
Особенностью этой файловой системы является возможность работы с большим (до 10 000) числом рабочих станций.
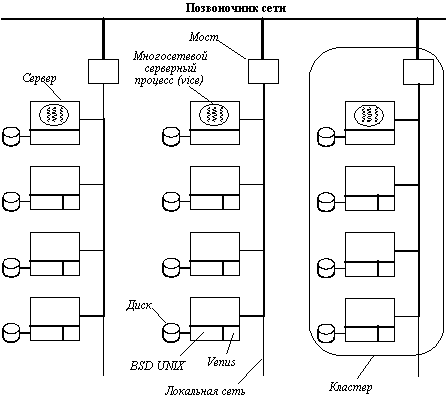
Рис. 4.5. Конфигурация системы, используемая AFS в университете Карнеги-Меллона
Конфигурация системы показана на рисунке 4.5. Она состоит из кластеров, каждый из которых включает файловый сервер и несколько десятков рабочих станций. Идея состоит в том, чтобы распределить большую часть трафика в пределах отдельных кластеров и тем самым уменьшить загрузку позвоночника сети.
Так как студенты могли входить в систему и в университете, и в общежитии, то иногда они оказывались далеко от сервера, который содержал их файлы. Несмотря на это, пользователь должен иметь возможность работать на произвольно выбранной рабочей станции, как на своем персональном компьютере.
Физически нет разницы между машиной клиента и сервера, и все они выполняют одну и ту же ОС BSD UNIX с его большим монолитным ядром. Однако над ядром выполняются совершенно различные программы серверов и клиентов. На клиент-машинах выполняются менеджеры окон, редакторы и другое стандартное программное обеспечение системы UNIX. Каждый клиент имеет также часть кода - venus, которая управляет интерфейсом между клиентом и серверной частью системы, называемой vice. Вначале venus выполнялся в пользовательском режиме, но позже он был перемещен в ядро для повышения производительности. Venus работает также в качестве менеджера кэша. В дальнейшем мы будем называть venus просто клиентом, а vice - сервером.
Пространство имен, видимое пользовательскими программами, выглядит как традиционное дерево в ОС UNIX с добавленным к нему каталогом /cmu (рисунок 4.5). Содержимое каталога /cmu поддерживается AFS посредством vice-серверов и идентично на всех рабочих станциях. Другие каталоги и файлы исключительно локальны и не разделяются. Возможности разделяемой файловой системы предоставляются путем монтирования к каталогу /cmu. Файл, который UNIX ожидает найти в верхней части файловой системы, может быть перемещен символьной связью из разделяемой файловой системы (например, /bin/sh может быть символьно связан с /cmu/bin/sh).
В основе AFS лежит стремление делать для каждого пользователя как можно больше на его рабочей станции и как можно меньше взаимодействовать с остальной системой. При открытии удаленного файла весь файл (или его значительная часть, если он очень большой) загружается на диск рабочей станции и кэшируется там, причем процесс, который сделал вызов OPEN, даже не знает об этом. По этой причине каждая рабочая станция имеет диск.
После загрузки файла на локальный диск он помещается в локальный каталог /cash, так что он выглядит для ОС как нормальный файл. Дескриптор файла, возвращаемый системным вызовом OPEN, соответствует именно этому файлу, так что вызовы READ и WRITE работают обычным путем, без участия клиента и сервера. Другими словами, хотя системный вызов OPEN значительно изменен, реализация READ и WRITE не изменилась.
Безопасность - это главный вопрос в системе с 10 000 пользователей. Так как пользователи вольны перегружать свои рабочие станции, когда захотят и могут выполнять на них модифицированные версии ОС, то главный принцип сервера - не доверять клиентским рабочим станциям. Все сообщения между рабочими станциями шифруются на уровне аппаратуры.
Защита выполнена несколько необычным путем. Каталоги защищаются списками прав доступа (ACL), но файлы имеют обычные биты RWX UNIX'а. Разработчики системы предпочитают механизм ACL, но так как многие UNIX-программы работают с битами RWX, то они оставлены для совместимости. Списки прав доступа могут содержать и отсутствие прав, так что можно, например, потребовать, чтобы доступ к файлу был разрешен для всех, кроме одного конкретного человека.
Диски рабочих станций используются только для временных файлов, кэширования удаленных файлов и хранения страниц виртуальной памяти, но не для постоянной информации. Это существенно упрощает управление системой, в этом случае нужно управлять и архивировать только файлы серверов, а рабочие станции не требуют никаких забот. Концептуально они могут начинать каждый рабочий день с чистого листа.
AFS сконструирована для расширения до масштабов национальной файловой системы. Система, показанная на рисунке, на самом деле представляет собой отдельную ячейку (cell). Каждая ячейка - это административная единица, такая как отдел или компания. Ячейки могут быть соединены друг с другом с помощью монтирования, так что дерево разделяемых файлов может покрывать многие города.
В дополнение к концепциям файла, каталога и ячейки AFS поддерживает еще одно важное понятие - том. Том - это собрание каталогов, которые управляются вместе. Обычно все файлы какого-либо пользователя составляют том. Таким образом поддерево, входящее в /usr/john, может быть одним томом, поддерево, входящее в /usr/mary, может быть другим томом. Фактически, каждая ячейка представляет собой ничто иное, как набор томов, соединенных вместе некоторым, подходящим с точки зрения монтирования, образом. Большинство томов содержат пользовательские файлы, некоторые другие используются для двоичных выполняемых файлов и другой системной информации. Тома могут иметь признак "только для чтения".
Семантика, предлагаемая AFS, близка к сессионной семантике. Когда файл открывается, он берется у подходящего сервера и помещается в каталог /cash на локальном диске на рабочей станции. Все операции чтения-записи работают с кэшированной копией. При закрытии файла он выгружается назад на сервер. Следствием этой модели является то, что когда процесс открывает уже открытый файл, то версия, которую он видит, зависит от того, где находится процесс. Процесс на той же рабочей станции видит копию в каталоге /cash, при этом выполняется вся семантика UNIX.
В то же время процесс на другой рабочей станции продолжает видеть исходную версию файла на сервере. Только после того, как файл будет закрыт и отослан обратно на сервер, последующая операция открытия увидит новую версию. После того, как файл закрывается, он остается в кэше, на случай, если он скоро будет снова открыт. Как мы видели ранее, повторное открытие файла, который находится в кэше, порождает проблему: "Как клиент узнает, последняя ли это версия файла?" В первой версии AFS эта проблема решалась прямым запросом клиента к серверу. К сожалению эти запросы создавали большой трафик и впоследствии алгоритм был изменен. В новом алгоритме, когда клиент загружает файл в свой кэш, то он сообщает серверу, что его интересуют все операции открытия этого файла процессами на других рабочих станциях. В этом случае сервер создает таблицу, отмечающую местонахождение этого кэшированного файла. Если другой процесс где-либо в системе открывает этот файл, то сервер посылает сообщение клиенту, чтобы тот отметил этот вход кэша как недействительный. Если этот файл в настоящее время используется, то использующие его процессы могут продолжать делать это. Однако, если другой процесс пытается открыть его заново, то клиент должен свериться с сервером, действителен ли все еще этот вход в кэше, а если нет, то получить новую копию. Если рабочая станция терпит крах, а затем перезагружается, то все файлы в кэше отмечаются как недействительные.
Блокировка файла поддерживается с помощью системного вызова UNIX FLOCK. Если блокировка не снимается в течение 30 минут, то она снимается по тайм-ауту. Тома, предназначенные только для чтения, такие как системные двоичные файлы, реплицируются, а пользовательские файлы - нет.
Хотя прикладные программы видят традиционное пространство имен UNIX, внутренняя организация сервера и клиента использует совершенно другую схему имен. Они используют двухуровневую схему именования, при которой каталог содержит структуры, называемые fids (file identifiers), вместо традиционных номеров i-узлов.
Fid состоит из трех 32-х битных полей. Первое поле - это номер тома, который однозначно определяет отдельный том в системе. Это поле говорит, на каком томе находится файл. Второе поле называется vnode, это индекс в системных таблицах определенного тома. Оно определяет конкретный файл в данном томе. Третье поле - это уникальный номер, который используется для обеспечения повторного использования vnode. Если файл удаляется, то его vnode может быть повторно использован, но с другим значением уникального номера, для того, чтобы обнаружить и отвергнуть все старые fids.
Протокол между сервером и клиентом использует fid для идентификации файла. Когда fid поступает в сервер, по значению номера тома производится поиск в базе данных, управляемой всеми серверами, чтобы обнаружить нужный сервер. Тома могут перемещаться между серверами, но не части томов, так что эта база данных требует периодического обновления, но перемещения томов случается редко, так что трафик обновления невелик. Перемещение тома является неделимым - сначала на сервере назначения делается копия тома, а затем удаляется оригинал. Этот механизм также используется для репликации томов только для чтения за исключением того, что исходный том не удаляется после его копирования. Этот же алгоритм используется для резервного копирования. Когда делается копия, то она помещается в файловую систему как том только для чтения. В течение последующих 24 часов процесс скопирует этот том на ленту. Дополнительное преимущество этого метода - пользователь, который случайно удалил файл, все еще имеет доступ ко вчерашней копии.
Теперь рассмотрим общий механизм доступа к файлам в AFS. Когда приложение выполняет системный вызов OPEN, то он перехватывается оболочкой клиента, которая первым делом проверяет, не начинается ли имя файла с /cmu. Если нет, то файл локальный, и обрабатывается обычным способом. Если да, то файл разделяемый. Производится грамматический разбор имени, покомпонентно находится fid. По fid проверяется кэш, и здесь имеется три возможности:
В первом случае используется кэшированный файл. Во втором случае клиент запрашивает сервер, изменялся ли файл после его загрузки. Файл может быть недостоверным, если рабочая станция недавно перезагружалась или же некоторый другой процесс открыл файл для записи, но это не означает, что файл уже модифицирован, и его новая копия записана на сервер. Если файл не изменялся, то используется кэшированный файл. Если он изменялся, то используется новая копия. В третьем случае файл также просто загружается с сервера. Во всех трех случаях конечным результатом будет то, что копия файла будет на локальном диске в каталоге /cash, отмеченная как достоверная.
Вызовы приложения READ и WRITE не перехватываются оболочкой клиента, они обрабатываются обычным способом. Вызовы CLOSE перехватываются оболочкой клиента, которая проверяет, был ли модифицирован файл, и, если да, то переписывает его на сервер, который управляет данным томом.
Помимо кэширования файлов, оболочка клиента также управляет кэшем, который отображает имена файлов в идентификаторы файлов fid. Это ускоряет проверку, находится ли имя в кэше. Проблема возникает, когда файл был удален и заменен другим файлом. Однако этот новый файл будет иметь другое значение поля "уникальный номер", так что fid будет выявлен как недостоверный. При этом клиент удалит вход (pass, fid) и начнет грамматический разбор имени с самого начала. Если дисковый кэш переполняется, то клиент удаляет файлы в соответствии с алгоритмом LRU.
Vice работает на каждом сервере как отдельная многонитевая программа. Каждая нить обрабатывает один запрос. Протокол между сервером и клиентом использует RPC и построен непосредственно на API. В нем есть команды для перемещения файлов в обоих направлениях, блокирования файлов, управления каталогами и некоторые другие. Vice хранит свои таблицы в виртуальной памяти, так что они могут быть произвольной величины.
Так как клиент идентифицирует файлы по их идентификаторам fid, то у сервера возникает следующая проблема: как обеспечить доступ к UNIX-файлу, зная его vnode, но не зная его полное имя. Для решения этой проблемы в AFS в UNIX добавлен новый системный вызов, позволяющий обеспечить доступ к файлам по их индексам vnode.
Реализация DFS на базе AFS дает прекрасный пример того, как работают вместе различные компоненты DCE. DFS работает на каждом узле сети совместно со службой каталогов DCE, обеспечивая единое пространство имен для всех файлов, хранящихся в DFS. DFS использует списки ACL системы безопасности DCE для управления доступом к отдельным файлам. Потоковые функции RPC позволяют DFS передавать через глобальные сети большие объемы данных за одну операцию.
Распределенная служба времени
В распределенных сетевых системах необходимо иметь службу согласования времени. Многие распределенные службы, такие как распределенная файловая система и служба идентификации, используют сравнение дат, сгенерированных на различных компьютерах. Чтобы сравнение имело смысл, пакет DCE должен обеспечивать согласованные временные отметки.
Сервер времени OSF DCE - это система, которая поставляет время другим системам в целях синхронизации. Любая система, не содержащая сервера времени, называется клерком (clerk). Распределенная служба времени использует три типа серверов для координации сетевого времени. Локальный сервер синхронизируется с другими локальными серверами той же локальной сети. Глобальный сервер доступен через расширенную локальную или глобальную сети. Курьер (courier) - это специальный локальный сервер, который периодически сверяет время с глобальными серверами. Через периодические интервалы времени серверы синхронизируются друг с другом с помощью протокола DTS OSF. Этот протокол может взаимодействовать с протоколом синхронизации времени NTP сетей Internet.
Многие фирмы-потребители программного обеспечения уже используют или собираются использовать средства DCE, поэтому ведущие фирмы-производители программного обеспечения, такие как IBM, DEC и Hewlett-Packard, заняты сейчас реализацией и поставкой различных элементов и расширений этой технологии.
Одной из главных особенностей и достоинств пакета DCE OSF является тесная взаимосвязь всех его компонентов. Это свойство пакета иногда становится его недостатком. Так, очень трудно работать в комбинированном окружении, когда одни приложения используют базис DCE, а другие - нет. В версии 1.1 совместимость служб пакета с аналогичными средствами других производителей улучшена. Например, служба Kerberos DCE в текущей версии несовместима с реализацией Kerberos MIT из-за того, что Kerberos DCE работает на базе средств RPC DCE, а Kerberos MIT - нет. OSF обещает полную совместимость с Kerberos MIT в версии 1.1. Имеются и положительные примеры совместимости пакета DCE со средствами других производителей, например со средствами Windows NT. Хотя Windows NT и не является платформой DCE, но их совместимость может быть достигнута за счет полной совместимости средств RPC. Поэтому, после достаточно тщательной работы на уровне исходных кодов, разработчики могут создать DCE-сервер, который сможет обслуживать Windows NT-клиентов, и Windows NT-сервер, который работает с DCE-клиентами.
Для того, чтобы стать действительно распространенным базисом для создания гетерогенных распределенных вычислительных сред, пакет DCE должен обеспечить поддержку двух ключевых технологий - обработку транзакций и объектно-ориентированный подход. Поддержка транзакций совершенно необходима для многих деловых приложений, когда недопустима любая потеря данных или их несогласованность. Две фирмы - IBM и Transarc - предлагают дополнительные средства, работающие над DCE и обеспечивающие обработку транзакций. Что же касается объектно-ориентированных свойств DCE, то OSF собирается снабдить этот пакет средствами, совместимыми с объектно-ориентированной архитектурой CORBA, и работающими над инфраструктурой DCE. После достаточно тщательной работы на уровне исходных кодов, разработчики могут создать DCE-сервер, который сможет обслуживать Windows NT-клиентов, и Windows NT-сервер, который работает с DCE-клиентами.
Для того, чтобы стать действительно распространенным базисом для создания гетерогенных распределенных вычислительных сред, пакет DCE должен обеспечить поддержку двух ключевых технологий - обработку транзакций и объектно-ориентированный подход. Поддержка транзакций совершенно необходима для многих деловых приложений, когда недопустима любая потеря данных или их несогласованность. Две фирмы - IBM и Transarc - предлагают дополнительные средства, работающие над DCE и обеспечивающие обработку транзакций. Что же касается объектно-ориентированных свойств DCE, то OSF собирается снабдить этот пакет средствами, совместимыми с объектно-ориентированной архитектурой CORBA и работающими над инфраструктурой DCE.
Часть II. Примеры
реализации операционных
систем
|
|
