
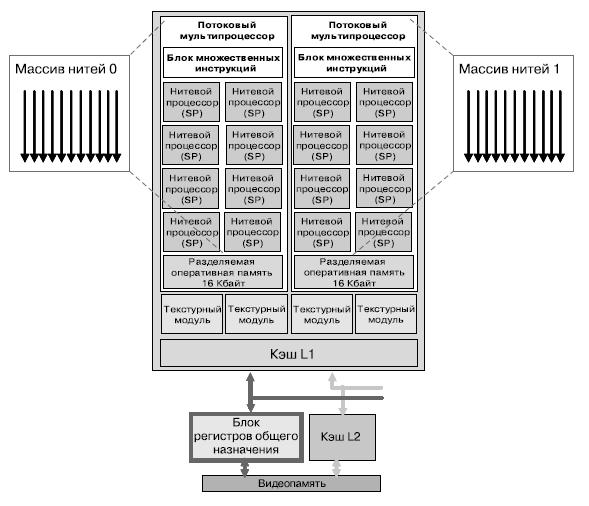
В состав процессора G80 входят 128 вычислительных ядер (далее - нитевые ядра) общей пиковой производительностью 518 ГФлопс на тактовой частоте 1.35 ГГц, поддерживающих 12288 аппаратно управляемых потоков/нитей (рис. 5.1). Нитевые ядра объединены в 8 блоков по 16 в каждом, управляемых менеджером потоков и называемых потоковыми мультипроцессорами.
Ядра являются скалярными, что позволяет легко использовать их в вычислениях общего назначения, ведь в этом плане они ничем не отличаются от центрального процессора. В G80 вычислительные ядра объединены в группы (так называемые потоковые мультипроцессоры) по 8 ядер в каждой группе, каждая группа имеет кэш-память первого и второго уровней (причем кэш второго уровня доступен для обращения всем остальным группам) (рис. 5.2). Все восемь блоков имеют доступ к любому из шести L2-кэшей и к любому из шести массивов регистров общего назначения (РОН). Таким образом, данные, обработанные на одном процессоре, могут быть использованы другим процессором.

Потоковый мультипроцессор содержит 8 процессоров нитей пиковой производительностью 32 ГФлопс на частоте 1,35 ГГц с поддержкой операций с числами в формате с плавающей точкой стандарта IEEE 754. Также в него входят:
Нитевые ядра, составляющие потоковый мультипроцессор, поддерживают выполнение инструкций с плавающей точкой стандарта IEEE 754. Потоковому мультипроцессору доступен также регистровый файл размером 32 Кбайта и кэш второго уровня размером также 32Кбайта (только для чтения).
Основные операции, поддерживаемые вычислительными ядрами, следующие:
Выполнение инструкций конвейеризировано.
В состав нитевых ядер также входит блок специальных функций, который осуществляет поддержку выполнения трансцендентных функций: RCP, RSQRT, EXP2, LOG2, SIN, COS.
Блок специальных функций позволяет выполнять аппроксимацию функций при помощи квадратичной аппроксимации. Точность вычислений — порядка 22,5-24,0 бит.
Два блока специальных инструкций на потоковый процессор производят 1/4 потока инструкций.
Результаты вычислений отдельной группы потоковых процессоров записываются в кэш второго уровня и становятся доступны всем остальным группам. Таким образом, данные циркулируют внутри процессора и покидают его, только когда все вычисления завершены. Это устраняет задержки, возникающие при обращении к видеопамяти.
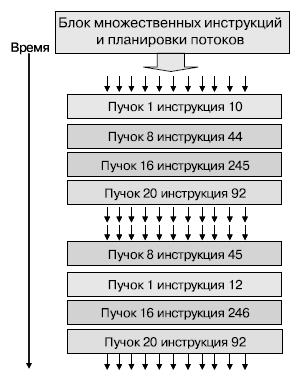
Блок множественных инструкций поддерживает 768 нитей, выполняющихся параллельно и объединенных в 24 пучка / группы / вэрпа (warp) нитей (по 32 нити в каждом). Над каждой нитью в пучке в один момент времени выполняется одна операция — SIMD. При этом каждый пучок нитей независим от других (над разными пучками могут выполняться различные операции — MIMD). Блок осуществляет аппаратный контроль за выполнением нитей. Конкурирующие нити могут разделять данные. Наилучшая производительность достигается, когда все нити в пучке выполняются вместе, без различий в ходе исполнения кода (рис. 5.3).
При решении прикладных задач на графическом процессоре разработчик должен предварительно разбить задачу на разделы (grids), причем один раздел представляет собой один шаг из последовательности шагов решения задачи. В разделе задачи выделяются блоки, результаты выполнения которых могут быть получены параллельно — раздел распараллеливается. В блоках выделяются элементы/нити, которые выполняются параллельно в режиме взаимодействия, — эти элементы будут соответствовать нитям, выполняющимся на нитевых ядрах (рис. 5.4).
Техника выполнения задач на графическом процессоре носит название массив взаимодействующих/конкурирующих нитей (CTA — Cooperative Threads Array). Программист определяет параметры CTA — количество нитей (от 1 до 512), размерность массива нитей (1-3), количество нитей в каждом измерении массива. Нити в CTA выполняют одну программу, каждая нить имеет свой идентификационный номер, нити разделяют данные и синхронизованы между собой. Программа использует номер нити для выбора активной нити и адресации разделяемых данных.
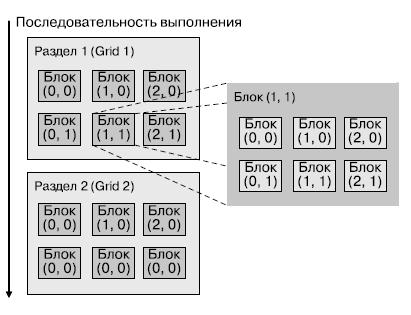
Нити в СТА выполняются совместно. Потоковый мультипроцессор получает идентификатор нити и контролирует ее выполнение. СТА-нити разделяют данные и результаты, как в глобальной памяти и разделяемом блоке памяти, так и при выполнении инструкций синхронизации (рис. 5.5). Хранение данных в разделяемой памяти позволяет увеличить скорость доступа процессора к данным и минимизировать количество обращений в глобальную память. Скорость доступа нитей СТА в глобальную память составляет порядка 76 Гбайт/с по интерфейсу GDDR DRAM.
Можно выделить следующую иерархию памяти: локальная, разделяемая и глобальная.
Локальная память (используется нитью) — распределение переменных, использование регистров. Разделяемая память применяется массивом нитей СТА для обмена данными между нитями. Глобальная память используется приложением для обмена данных между разделами задачи.
Для выполнения расчетов на графических процессорах компанией NVIDIA предлагается специализированная среда программирования — CUDA (Compute Unified Device Architecture) — архитектура с унифицированными вычислениями, иногда называемая GPU Computing. Среда представляет собой надстройку над языком С, которая вводит несколько новых операторов и процедур, значительно облегчающих программирование расчетов общего назначения, а также компилятор.
Процессор выполняет последовательность т. н. программных ядер. Каждое программное ядро выполняется как раздел (grid) с блоками нитей.
Нити в блоке могут выполняться совместно, синхронизованы и разделяют одни и те же данные в разделяемой памяти. Блоки нитей выполняются как массивы взаимодействующих нитей (СТА) на потоковых мультипроцессорах (рис. 5.6).
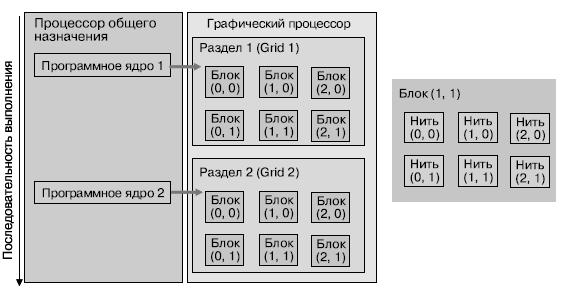
Среда CUDA реализует технологию Single-Program Multiple-Data — SPMD, интегрируя в программе работу и процессора общего назначения, и графического процессора.
Последовательные блоки кода выполняются на процессоре общего назначения, параллельные — на графическом. Условно программа в CUDA выглядит следующим образом:
CPU Serial Code Grid 0 GPU Parallel Kernel KernelA<<< nBlk, nTid >>>(args); CPU Serial Code Grid 1 GPU Parallel Kernel KernelB<<< nBlk, nTid >>>(args); .....
Распараллеленная архитектура G80 отлично подходит для выполнения трудоемких математических задач. Большое количество скалярных потоковых процессоров (до 128, а в перспективе еще больше), использование кэш-памяти первого и второго уровней для более эффективной повторной обработки данных, аппаратный диспетчер потоков, осуществляющий оптимизацию загрузки GPU, — все эти особенности делают G80 серьезным помощником в научных расчетах высокой сложности.
Компанией NVIDIA создан проект Tesla, предназначенный для создания компактных систем для высокопроизводительных вычислений (HPC). На рис. 5.7 представлена типовая структурная схема вычислительного сервера Tesla.
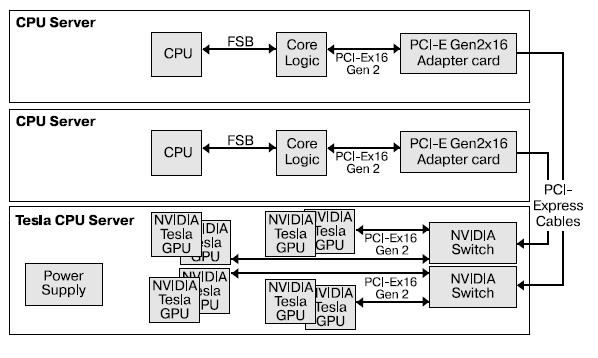
Графические процессоры на данный момент предлагают интересное сочетание MIMD- и SIMD-подходов к обработке данных. Переход компаниями-производителями к скалярным ядрам помимо балансировки нагрузки на процессор расширяет области применения графических процессоров.
Несмотря на потоковую архитектуру, слегка ограничивающую круг эффективно решаемых задач, графические процессоры серии G80 обладают большим запасом производительности. Благодаря своей доступности в составе видеокарт они дают толчок к развитию и массовому использованию параллельного программирования.
Основной подход к программированию данных процессоров — выделение в задачах участков с относительно независимыми потоками данных.
|
|
