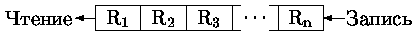В данном разделе рассмотрены три основных способа работы с данными: последовательный доступ, непосредственный доступ, и списки. Данные могут быть организованы в виде:
· элементов данных (data item) - единичная информация, перерабатываемая системой,
· запись (record) - совокупность некоторого числа элементов данных,
· файл (file) - совокупность некоторого числа записей.
В общем случае структура данных образуется посредством упорядочивания записей и связей между ними в файл. В зависимости от требуемых операций данные в файле организуются различным образом.
Зачастую требуется простейшая последовательная обработка записей. Для этого достаточна последовательная организация данных, когда записи запоминаются в файле в последовательности поступления.
Выбор требуемой записи в файле с последовательной организацией возможен только путем его сканирования от начала до требуемой записи.
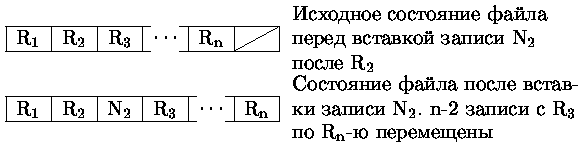
Удаление и/или вставка не последней записи приводят к большим перемещениям данных (рис. 0.4.32, 0.4.33).
Частными, широко используемыми случаями последовательного доступа, являются очереди и стеки. Наиболее широко используются стеки.
Очередь - файл данных с дисциплиной обслуживания первым пришел - первым обслужен (FIFO - First Input First Output) (рис 0.4.34).
Стек (магазин, гнездовая память, память LIFO) - файл данных с дисциплиной обслуживания первым пришел - последним обслужен (LIFO - Last Input First Output).
Состояние стека определяется значением указателя стека, инициируемом при его создании. Для работы с созданным стеком достаточны две операции:
· PUSH - помещение записи в стек,
· POP - получение записи из стека.
Эти операции заносят/читают данные и модифицируют значение указателя стека. Стек может быть организован двумя способами, отличающимися правилами продвижения указателя стека:
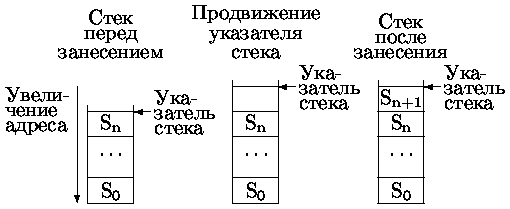
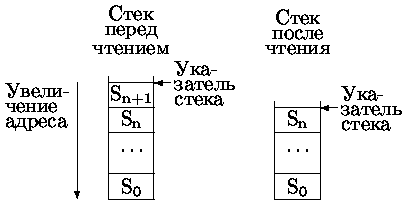
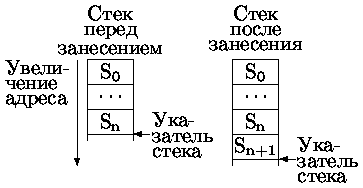
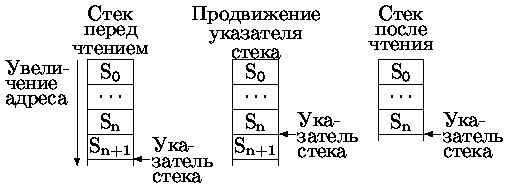
Наиболее часто используется первый способ организации стека.
При необходимости непосредственного доступа (random access) устанавливается связь между адресом запоминания и ключом, по которому ищется запись.
В простейшем случае ключ поиска - просто номер записи. Чаще ключ - некоторая совокупность данных из записи. По значению ключа либо непосредственно вычисляется адрес записи (например, адрес расположения физического блока фиксированной длины на диске вычисляется по его номеру), либо ключ используется для доступа к справочнику, в котором отыскивается адрес (например, адрес начала расположения i-го файла задается i-й записью в директории). Метод очень быстрый - мы немедленно получаем доступ к записи. Но он может быть очень расточительным по использованию памяти, когда из полного возможного набора в N ключей, по которым вырабатываются адреса в диапазоне от 0 до N-1, фактически будет иметься только K << N ключей, т.е. из всего диапазона адресов 0-(N-1) будет использоваться только K адресов, раскиданных по всему объему от 0 до N-1.
В таких случаях значение ключа используется для вычисления функции расстановки (hash code), определяющей адрес расположения данных. Причем функция расстановки подбирается такой, чтобы для K ключей из полного допустимого набора в N ключей, генерируемое количество адресов L было возможно более близко к K. Этот подход обычно используется при поиске информации об объекте по его имени, например, для поиска информации об объекте по его наименованию, для поиска информации в базе данных о сотруднике по его фамилии, для работы с таблицей идентификаторов в трансляторах и т.д. В этом случае функция расстановки вычисляется из символов ключа. Идеальная функция расстановки должна вычислять уникальный адрес для каждого из фактических ключей. Реальные же функции расстановки могут для разных ключей давать один и тот же адрес. Рассмотрим частный пример (табл. 9.1) занесения информации в таблицу из 10 элементов (L равно 10). В качестве ключа используем наименование объекта. Для вычисления хеш-адреса Hn в диапазоне 0-9 суммируем коды символов ключа, из которых предварительно вычитаем 65. В качестве хеш-адреса берем остаток от деления полученной суммы на 10. (На самом деле число 10 не годится, а выбрано для наглядности).
| Пример вычисления хеш-адреса. | Таблица 9.1 | |||||||
| Ключ | Коды символов ключа | Хеш-адрес | ||||||
| GALLERY | 71 | 65 | 76 | 76 | 69 | 82 | 89 | 3 |
| HOUSE | 72 | 79 | 85 | 83 | 69 | 3 | ||
| MIRROR | 77 | 73 | 82 | 82 | 79 | 82 | 5 | |
| RING | 82 | 73 | 78 | 71 | 4 | |||
| SCENE | 83 | 67 | 69 | 78 | 69 | 1 | ||
Из табл. 9.1. видно, что для двух разных ключей GALLERY и HOUSE вычислен одинаковый хеш-адрес, равный 3. Предложен ряд способов разрешения таких коллизий. Рассмотрим один из них, называемый рехешированием.
Перед занесением очередной строки в таблицу проверяем занят ли элемент. Если элемент таблицы свободен, то выполняем занесение. Если же элемент таблицы уже занят, то сравниваем ключи So уже занесенного и Sn заносимого элементов. Если они совпали, то выполняем какую-либо процедуру реагирования на одинаковые ключи и завершаем занесение. Например, для базы данных по кадрам выдаем диагностику о том что информация о данном сотруднике уже есть, для таблицы идентификаторов формируем сообщение о повторном описании и т.п. Если же ключи So и Sn не совпали, то вычисляется новый адрес в таблице по формуле:
| (0.1.1) |
где Hn - исходный хеш-адрес, Pi - некоторое число, L - длина таблицы.
Если этот элемент также оказался занятым, то задается новое значение Pi и по формуле (0.4.26) вычисляется следующий адрес т.д., пока не будет найден некоторый элемент, который либо пуст, либо содержит ключ Sn, либо не будет получен исходный хеш-адрес. В последнем случае работа прекращается из-за переполнения таблицы. Используются несколько основных способов рехеширования [12,]:
Линейное рехеширование.
В этом, наиболее распространенном и простом случае P1 равно 1,
P2 равно 2 и т.д.
Число сравнений E » (1 - V/2)(1-V),
где V - коэффициент заполненности таблицы.
10% - E = 1.06 сравнений,
50% - E = 1.50 сравнений,
90% - E = 5.50 сравнений.
Случайное рехеширование.
При этом способе Pj - псевдослучайное число.
Способ хорош при L = 2m где m - целое.
Число сравнений E » - (1/V)log(1-V).
10% - E = 1.05 сравнений,
50% - E = 1.39 сравнений,
90% - E = 2.56 сравнений.
Рехеширование сложением с выбором.
При этом способе Pi = i ×Hn (i = 1јL-1),.
Способ хорош когда L - простое число.
Квадратичное рехеширование.
При этом способе Pi = A×(i2) + B×i + C.
Здесь A, B, C - произвольные числа, выбор которых определяется
эффективностью вычисления формулы на конкретной машине.
Время вычислений хеш-адреса меньше чем при случайном рехешировании.
Если L - простое число, то E Ј L/2.
Третья форма организации данных - списки, когда логическая и физическая организация данных разделены и для доступа к данным используются указатели на данные.
Далее будем рассматривать структуры данных с использованием списков указателей.
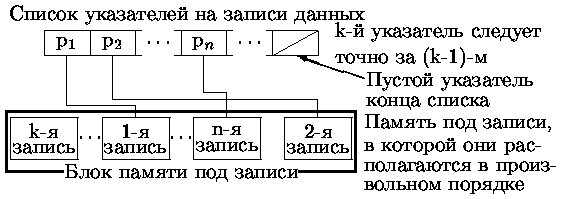
Линейный список - множество элементов с помощью которых свойства структуры задаются посредством линейного (одномерного) относительного расположения элементов. При этом k-й указатель непосредственно находится после (k-1)-го.
С таким списком возможны следующие операции:
Пример линейного списка показан на рис. 0.4.39.
Очевидно, что процесс удаления может приводить к большим перемещениям данных. Пусть, например, надо удалить запись номер 1 (см. рис. 0.4.39). Это потребует удаления указателя p1 и переписи всех далее расположенных указателей на освобождаемое место списка. Аналогичные проблемы возникают и при вставке в требуемое место.
Поэтому естественным шагом является построение так называемых комбинированных списков, содержащих кроме указателей на записи данных также и дополнительные указатели, указывающие на на следующий элемент списка указателей (рис. 0.4.40).

Достоинства таких списков:
· много проще вставка в требуемое место, например, вставка нового элемента между (n-1)-м и n-м сводится к перестройке двух указателей (рис. 0.4.41)

· много проще удаление (рис. 0.4.42), которое сводится к
перестройке трех указателей - одного указателя для собственно
удаления и перестройке двух указателей для включения удаляемого
элемента в список свободной памяти.
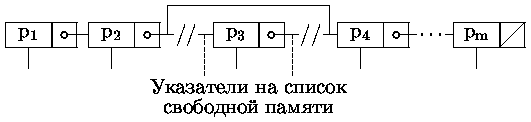
· разделение и соединение списков упрощается,
· возможно формирование сложных структур данных,
· можно надстраивать переменное число списков различных длин,
· любой из элементов списка может быть заголовком некоторого
другого списка, когда указатель на данные указывает на
некоторый другой список,
· за счет использования нескольких указателей возможно формирование подсписков.
Недостатки:
· увеличивается потребность в памяти из-за дополнительных указателей,
· обычно требуемая последовательная обработка замедляется,
· выбор нужного элемента списка требует последовательного прохода по всем предшествующим элементам списка, начиная с начального.
Последнего недостатка лишены списки с указателями не только вперед, на следующий элемент, но и назад, на предшествующий элемент. Эти списки чаще всего используются в виде циклических, когда первый элемент указывает на последний, как предшествующий ему. В свою очередь последний элемент списка как на последующий указывает на начальный элемент. Доступ к началу списка обеспечивает специальный элемент - заголовок списка, который может сопровождаться данными, характеризующими список в целом (рис. 0.4.43). Например, если список представляет собой описание какой-либо фигуры (тела), то дополнительными данными могут быть идентификатор и тип фигуры или иная семантическая информация.
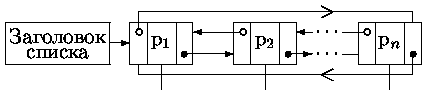
Ясно, что удаление или вставка элемента в таком списке также упрощаются.
1. Электромагнитная волна (в религиозной терминологии релятивизма - "свет") имеет строго постоянную скорость 300 тыс.км/с, абсурдно не отсчитываемую ни от чего. Реально ЭМ-волны имеют разную скорость в веществе (например, ~200 тыс км/с в стекле и ~3 млн. км/с в поверхностных слоях металлов, разную скорость в эфире (см. статью "Температура эфира и красные смещения"), разную скорость для разных частот (см. статью "О скорости ЭМ-волн")
2. В релятивизме "свет" есть мифическое явление само по себе, а не физическая волна, являющаяся волнением определенной физической среды. Релятивистский "свет" - это волнение ничего в ничем. У него нет среды-носителя колебаний.
3. В релятивизме возможны манипуляции со временем (замедление), поэтому там нарушаются основополагающие для любой науки принцип причинности и принцип строгой логичности. В релятивизме при скорости света время останавливается (поэтому в нем абсурдно говорить о частоте фотона). В релятивизме возможны такие насилия над разумом, как утверждение о взаимном превышении возраста близнецов, движущихся с субсветовой скоростью, и прочие издевательства над логикой, присущие любой религии.
4. В гравитационном релятивизме (ОТО) вопреки наблюдаемым фактам утверждается об угловом отклонении ЭМ-волн в пустом пространстве под действием гравитации. Однако астрономам известно, что свет от затменных двойных звезд не подвержен такому отклонению, а те "подтверждающие теорию Эйнштейна факты", которые якобы наблюдались А. Эддингтоном в 1919 году в отношении Солнца, являются фальсификацией. Подробнее читайте в FAQ по эфирной физике.
|
|