Предыдущая глава | Оглавление | Следующая глава
Хотя данный материал предлагает некоторые рекомендации по конфигурированию систем, полезность этих рекомендаций в значительной степени зависит от анализа самого приложения. Важность такого анализа невозможно переоценить! Эффективность работы самого приложения и СУБД намного важнее, чем конфигурация хост-машины. Имеются буквально сотни примеров небольших изменений, проведенных в приложении или в схеме базы данных, которые обеспечивали 100- или 1000-кратное (или даже большее!) увеличение производительности системы. Например, в зависимости от того индексируется или нет таблица с помощью ключа просмотра (lookup key), выполнение оператора select, который запрашивает одну определенную запись, может приводить к тому, что СУБД будет читать из таблицы всего одну запись, либо каждую запись в таблице, содержащей 10 Гбайт данных. Часто для того чтобы оптимально обрабатывать несколько различных шаблонных обращений, генерируемых приложением, таблица должна индексироваться более чем одним ключом или набором ключей. Хорошо осмысленная индексация может иметь весьма существенное воздействие на общую производительность системы (см. разд. 2.2.6.1). После начальной инсталляции системы обязательно нужно произвести сбор статистики о ее работе, чтобы выяснить необходимость внесения изменений в базу данных, даже для приложений собственной разработки или приложений третьих фирм. Часто оказывается возможным улучшить производительность приложения путем реорганизации базы данных даже без обращения к исходному коду приложения.
Другим соображением, которому уделяется недостаточно внимания, но которое часто оказывает огромные воздействие на результирующую производительность системы, являются конфликты по внутренним блокировкам. СУБД должна блокировать доступ к данным при наличии конфликтующих одновременных обращений. Любой другой процесс, который требует доступа к этим данным должен быть отложен до тех пор, пока блокировка не будет снята. Если выбрана неоптимальная стратегия блокировок, то система может оказаться очень плохо работающей.
Каждая СУБД имеет огромное число настраиваемых параметров, некоторые из которых могут серьезно воздействовать на общую производительность системы. Приводимые здесь рекомендации предполагают разумную настройку приложений и СУБД.
Ниже перечислены вопросы, ответы на которые позволяют обобщить процесс достижения разумной точности конфигурации СУБД:
В большинстве прикладных систем СУБД можно выделить три логических части: пользовательский интерфейс (средства представления), обеспечивающий функции ввода и отображения данных; некоторую прикладную обработку, характерную для данной предметной области; и собственно сервисы СУБД. Пользовательский интерфейс и прикладная обработка обычно объединены в одном двоичном коде, хотя некоторые из наиболее продвинутых приложений теперь обеспечивают многопотоковую фронтальную обработку, которая отделена от средств представления. Как правило, по мере роста базы данных сервер СУБД реализуется на выделенной системе, чтобы гарантировать минимизацию помех для его работы.
Если в системе можно реализовать модель вычислений клиент/сервер, отделяющую фронтальную (прикладную) обработку и средства представления от поставщика услуг СУБД, ее использование обычно обеспечивает существенное улучшение общей производительности системы. Такая организация системы позволяет наиболее важному ресурсу (серверу СУБД) работать без помех на своей собственной хост-машине. Это в первую очередь справедливо для систем, в которых работа средств представления связана с управлением сотнями или тысячами терминалов в режиме cbreak. Большинство программ, базирующиеся на curses- (screen-), сегодня используют cbreak-поддержку терминалов.
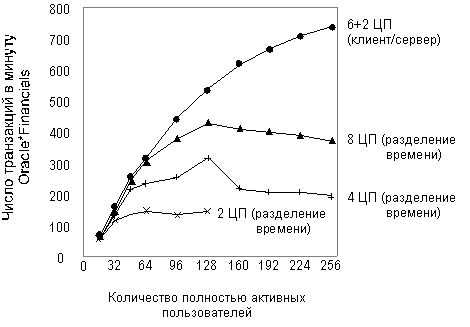
Режим разделения времени, в отличие от режима клиент/сервер, обычно обеспечивает большую производительность только тогда, когда требования к компоненту представления оказываются очень легкими, или когда одновременная пользовательская нагрузка невелика. Существенно что приложения, в основе компонента представления которых лежат формы, никогда не бывают легковесными. Даже приложения, работающие в диалоговом режиме printf/get обычно значительно более тяжелые, что позволяет оправдать использование конфигураций клиент/сервер. Тест TPC-A определяет возможно наиболее легкое требование приложения/представления (он включает ровно по одному вызову scaf(n) и printf(n)). Следует отметить, что даже тест TPC-A работает только на 5% быстрее в режиме разделения времени. Некоторые сравнительно недавние исследования компании Sun с использованием Oracle*Financials и Oracle 7 показали, что 6-процессорный сервер СУБД на базе SPARCserver 1000 с фронтальной системой на базе SPARCstation 10 Model 512 может поддерживать почти на 40% пользователей больше, чем 8-процессорный SPARCserver 1000, работающий в режиме разделения времени (рис. 2.3).
Рекомендации:
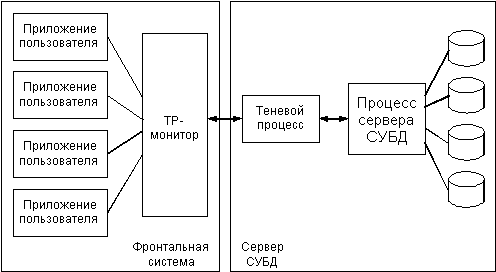
Использование мониторов обработки транзакций является одним из методов достижения более высокой производительности для имеющейся конфигурации, особенно в режиме клиент/сервер. Иногда мониторы обработки транзакций оказываются очень полезными для создания гетерогенных баз данных, позволяющих хранить некоторые данные в одном формате (например, Oracle на Sun), а другие данные в другом (возможно Ingres на VAX или IMS на мейнфрейме IBM). Кроме того, некоторые TP-мониторы предоставляют сервис для легковесного компонента представления. Хорошо известен TP-монитор компании IBM - Customer Information Control System (CISC). Несколько реализаций CICS (MicroFocus, XDB, VI Systems, Integris) доступны в настоящее время на большинстве аппаратных платформ. Другими известными мониторами являются Tuxedo/T компании USL, TopEnd от NCR и Encina от Transarc.
TP-мониторы представляют собой промежуточный слой программного обеспечения, который располагается между приложением и системой или системами СУБД. При этом приложение должно быть модифицировано так, чтобы оно могло выдавать транзакции, написанные на языке монитора транзакций, а не обращаться прямо к базе данных посредством обычных механизмов (подобных различным формам встроенного SQL). Программисты прикладных систем являются также ответственными за составление файла описания, который отображает транзакции в определенные обращения к базе данных на родном языке обращений нижележащей СУБД (почти для всех СУБД под UNIX это SQL).
Использование мониторов транзакций практически не накладывает каких-либо ограничений на многообразие или сложность запросов доступа к нижележащей СУБД. Например, вполне осмысленной оказывается транзакция, выдающая запрос на набор данных из базы данных DB2 на мейнфрейме IBM, работающей под управлением ОС MVS, а другой набор данных из локальной базы данных Sybase, и затем сливающая оба набора вместе для представления приложению. В результате создается иллюзия того, что данные хранятся в унифицированной базе данных, размещенной в одном и том же "хранилище данных" (data warehause).
В связи с тем, что во многих "старых" (legacy) системах используются мониторы обработки транзакций CICS, мигрирующая часть или все базы данных, связанные с этими системами, могут работать с небольшими изменениями существующих приложений. Все что требуется - это физический перенос данных на новую платформу и модификация описания транзакций для использования данных на новом месте. Однако сложность такого переноса не должна недооцениваться, поскольку он часто требует внесения изменений в представление данных (трансляцию COBOL "PIC 9(12)V99S" в C++ float) и организацию данных (например, из сетевой архитектуры IMS в реляционную архитектуру, используемую почти повсеместно СУБД на базе UNIX). Но возможность сохранить части, связанные с прикладной обработкой и представлением существующих приложений существенно сокращает сложность и риск, связанные с таким переносом.
Помимо достижения определенной
гибкости за счет использования
TP-мониторов, такая организация
оказывается выгодной и с точки
зрения увеличения
производительности системы.
TP-монитор всегда представляет
собой многопотоковую программу.
Поскольку TP-монитор открывает свое
собственное соединение с СУБД,
одновременно устраняя
необходимость выполнения каждым
прикладным процессом прямых
запросов к СУБД, число одновременно
работающих пользователей СУБД
существенно сокращается. В
подавляющем большинстве случаев
СУБД обслуживает только одного
"пользователя" -
TP-монитор. Это особенно важно, когда
СУБД относится к классу "2N",
поскольку в этом случае
используется только один теневой
процесс (для обеспечения
соединения с TP-монитором), а не по
одному процессу на каждый процесс
конечного пользователя (рис. 2.4). Это
может существенно сократить
накладные расходы, связанные с
переключением контекста на сервере
СУБД.
TP-мониторы позволяют также улучшить производительность за счет сокращения объема информации, пересылаемой между СУБД и прикладным процессом. Поскольку определенную часть каждой транзакции составляют только минимально требуемые данные, общий объем пересылки данных обычно может быть сокращен. Это особенно важно, когда клиент и сервер соединены между собой посредством достаточно занятой сети и/или сети с низкой полосой пропускания, подобной глобальной сети на спутниковых каналах связи.
Рекомендации:
Среди различных компонентов аппаратуры сервера СУБД конфигурация памяти системы обычно имеет самое большое воздействие на ее производительность. Хотя для многих людей память представляется только хранилищем выполняемых программ, большая часть основной памяти в системах СУБД используется в качестве буфера (кэша) данных, позволяющего во многих случаях устранить необходимость выполнения физического ввода/вывода с диска. Поскольку обращение к основной памяти выполняется примерно в 30000 раз быстрее, чем обращение к быстрому диску, минимизация дискового в/в является первостепенно важной задачей. (Обращение к памяти выполняется примерно за 500 нсек даже в самых худших условиях (при наличии промаха при обращении к кэш-памяти, требующего выталкивания модифицированной строки в основную память)). Возможно не будет преувеличением сказать, что "возня" с другими конфигурационными параметрами бесполезна, если в системе не хватает основной памяти. Если нужно создать конфигурацию системы без наличия достаточной информации (обычный случай при покупке новой системы), возможно лучше закупить избыточный объем памяти, чем недооценить его. К счастью, обычно ошибки по конфигурации памяти сравнительно легко исправляются.
Каждая СУБД называет свои буфера данных по разному, но все они выполняют одну и ту же функцию. Oracle называет эту память Глобальной Областью Системы (SGA - System Global Area), в то время как Sybase называет ее Кэшем Разделяемых Данных (Shared Data Cashe). Обычно буфер реализуется как большой массив разделяемой памяти, и его размер определяется специальным параметром в управляющем файле или таблицах СУБД. Размер памяти, необходимый для организации дискового кэша СУБД, меняется в широких пределах от приложения к приложению, но для примерной оценки размера буфера могут быть использованы следующие эмпирические правила.
Практические опыты различных компаний с СУБД Oracle и Sybase показали, что в зависимости от размера базы данных размер области памяти под буфера может варьироваться в очень широких пределах (от 4 Мбайт до более чем 1 Гбайт). Даже указанный больший размер буфера сегодня может быть превышен, поскольку начинают появляться реализованные на базе современных аппаратных платформ значительно большие по размеру базы данных (объемом 50 - 300 Гбайт). Однако следует иметь в виду, что как и при использовании любой кэш-памяти, увеличение размера буфера в конце концов достигает точки насыщения. Очень грубо размер кэша данных можно оценить, выделяя от 50 до 300 Кбайт на каждого пользователя. Каждая из известных систем СУБД имеет механизм сообщений об эффективности использования кэша разделяемых данных. Большинство систем могут также обеспечивать оценку того, какой эффект будет давать увеличение или уменьшение размера кэша.
Возможно самым простым и наиболее полезным является эмпирическое правило, которое называется "правилом пяти минут". Это правило широко используется при конфигурировании серверов баз данных, значительно большая сложность которых делает очень трудным точное определение размера кэша. Существующее в настоящее время соотношение между ценами подсистемы памяти и дисковой подсистемы показывает, что экономически целесообразно кэшировать данные, к которым осуществляются обращения более одного раза каждые пять минут.
Это означает, что данные, к которым обращения происходят более часто, чем один раз в пять минут, должны кэшироваться в памяти. Соответственно, чтобы оценить размер кэша данных необходимо просуммировать объемы всех данных, которые приложение предполагает использовать более часто, чем один раз в пять минут на уровне всей системы. Поэтому при определении необходимого объема памяти системы следует предусмотреть по крайней мере этот размер кэша данных. Дополнительно, следует зарезервировать еще 5-10% для хранения верхних уровней индексов B-деревьев, хранимых процедур и другой управляющей информации СУБД.
Не стоит волноваться из-за того, что чрезмерное увеличение размера кэша обычно не дает существенного эффекта. Указанные прогнозируемые объемы должны использоваться только для получения грубой оценки необходимой конфигурации системы. Каждая коммерческая СУБД обеспечивает механизм для определения стоимости или преимуществ изменения размера различных кэшей СУБД. Когда система инсталлирована и начинает работать, необходимо использовать эти механизмы для определения эффекта от изменения размеров кэша ввода/вывода СУБД. Следует отметить, что результаты часто могут оказаться удивительными. Например, выделение слишком большого объема памяти для кэша разделяемых данных может лишить пользовательское приложение (или, что еще хуже, сам сервер СУБД) требуемой для нормальной работы памяти. Память может также перераспределяться между кэшем разделяемых данных и пулом виртуальной памяти, используемой операционной системой для буферизации операций файловой системы UNIX (UFS).
Хотя основной целью СУБД на макроуровне является управление томами данных, которые по определению имеют очень большой объем и неизбежно во много раз превышают объем основной памяти, буквально десятки исследований многократно показали, что доступ к данным в общем случае подчиняется правилу "90/10": 90% всех обращений выполняются к 10% данных. Более того, совсем недавние исследования показали, что к "горячим" данным, обращения к которым составляют 90% всех обращений, снова применимо правило 90/10. Таким образом, примерно 80% всех обращений к данным связаны с доступом к примерно 1% агрегатированных данных. Следует отметить, что это отношение включает обращения к внутренним метаданным СУБД (включающих индексы B-деревьев и т.п.), обращения к которым обычно скрыты от прикладного программиста. Хотя желательно иметь коэффициент попаданий в кэш примерно на уровне 95%, по экономическим соображениям невозможно слепо обеспечить объем кэша в памяти, позволяющий разместить 10% всех данных: даже для скромных баз данных объемом 5 Гбайт это потребовало бы увеличения размера основной памяти до 500 Мбайт. Однако обычно всегда возможно обеспечить кэш объемом в 1% всех данных даже для очень больших баз данных. Те же самые 500 Мбайт основной памяти, таким образом, позволяют обслужить базу данных объемом 50 Гбайт, а максимальный размер памяти, например, SPARCcenter 2000 (5 Гбайт) компании Sun достаточен для поддержки баз данных объемом 400-500 Гбайт. (При наличии баз данных такого размера для поддержки неизбежно большого числа пользовательских приложений и т.д. очевидно также потребуется существенная часть этой памяти).
Рекомендации:
Естественно конфигурация системы должна обеспечивать также пространство для традиционного использования памяти. В СУБД на базе UNIX всегда необходимо обеспечить по крайней мере 16 Мбайт для базовой операционной системы. Далее, необходимо предусмотреть пространство объемом 2-4 Мбайт для ряда программ СУБД (программ ведения журнала, проверки согласованного состояния, архиваторов и т.п.) и достаточно пространства для размещения в памяти двоичных кодов приложения. Объем двоичных кодов приложения составляет обычно 1-2 Мбайт, но иногда они могут достигать 16-20 Мбайт. Операционная система обеспечивает режим разделения двоичных кодов между множеством пользующихся ими процессов, поэтому необходимо резервировать пространство только для одной копии. Пространство для размещения самого кода сервера СУБД зависит от общей архитектуры сервера. Для архитектуры "2N" следует выделять по 100-500 Кбайт на пользователя. Многопотоковые архитектуры требуют только 60-150 Кбайт, поскольку они имеют намного меньше процессов и намного меньшие накладные расходы.
Существует также эмпирическое правило, которое гласит, что неразумно конфигурировать менее, чем примерно 64 Мбайт памяти на процессор. Обрабатываемая каждым ЦП дополнительная информация требует выделения некоторого пространства для того, чтобы обойти интенсивную фрагментацию памяти.
Потребление процессорных
ресурсов очень сильно варьируется
в зависимости от используемого
приложения, СУБД, индивидуальных
пользователей и даже от времени
дня.
Например, результаты теста TPC-A
показывают, что восьмипроцессорный
SPARCserver 1000 способен обрабатывать
запросы от 4000 пользователей, или от
500 пользователей на процессор. (Эти
результаты были достигнуты на
многопотоковом сервере Oracle Version 7,
работающим в режиме клиент/сервер,
причем в качестве фронтальной
системы использовался монитор
обработки транзакций Tuxedo/T.) Следует
отметить, что этот результат был
достигнут специалистами компании
Sun и Oracle путем очень тщательной
настройки ОС Solaris, СУБД Oracle и самого
оценочного теста. Возможности этих
специалистов по настройке системы,
очевидно значительно превосходят
возможности большинства
пользователей. Более
реалистическая верхняя граница
числа пользователей на процессор
возможно составляет порядка 100-200
пользователей на один процессор 50
МГц SuperSPARC, даже для легких
транзакций типа TPC-A. Более крупные
приложения естественно приводят к
меньшему числу пользователей на
процессор.
Работа прикладного пакета Oracle*Financials создает для системы значительно более тяжелую рабочую нагрузку, чем работа теста TPC-A. Это связано с несколькими причинами. Во-первых, по сравнению с одной транзакцией, выполняемой тестом TPC-A, пакет Financials генерирует множество различных транзакций. Во-вторых, после того как данные найдены, сама основная СУБД должна выполнить нетривиальный объем прикладной обработки. В-третьих, пакет Financials не может работать с монитором обработки транзакций. Эксперименты компании Sun с этим пакетом показали, что процессор 50 МГц SuperSPARC может обрабатывать примерно 15 полностью активных пользователей в режиме разделения времени и 40-60 полностью активных пользователей в режиме клиент/сервер, даже с минимальным временем обдумывания.
Таблица 2.3. Примерное число поддерживаемых пользователей на ЦП
| Тип приложения | Количество процессоров 50 Мгц SuperSPARC | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1 | 2 | 4 | 8 | 16 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| TP-монитор | клиент/ сервер | 200-300 | 350-500 | 550-850 | 800+ | 1000+ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Легковесное | клиент/ сервер | 150-200 | 250-350 | 450-550 | 725+ | 800+ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| многопотоковое | Разделение времени | 50-80 | 85-135 | 150-225 | 200-300 | 250-300 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Тяжеловесное | Клиент/ сервер | 50-100 | 85-170 | 150-250 | 200-350 | 350-600 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| многопотоковое | Разделение времени | 20-60 | 35-100 | 60-175 | 100-300 | 150-250 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Тяжеловесное 2N | клиент/ сервер | 40-75 | 70-125 | 120-220 | 200-600 | 300-750 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Разделение времени | 15-40 | 25-70 | 45-120 | 75-200 | 110-230 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Ни операционная система Solaris 2, ни СУБД не масштабируются линейно (то же самое происходит и с конкурирующими операционными системами). Поскольку как Solaris 2, так и версии СУБД под Solaris 2 являются относительно новыми, таблица 2.3 отражает коэффициент масштабирования на уровне 70% (т.е. дублирование процессоров дает 70% увеличение производительности). Ожидается, что эти цифры со временем будут улучшаться по мере дальнейшей настройки как Solaris 2, так и СУБД особенно в направлении достижения лучшей многопроцессорной масштабируемости.
Эти цифры заявлены компанией Sun исключительно для интерактивной пользовательской нагрузки. В действительности рабочие нагрузки, подобные показанным здесь, редко возникают (если вообще возникают) без пакетной обработки. В общем случае для обработки пакетных заданий в конфигурацию системы необходимо включить дополнительный процессор. До сих пор на этот счет доступно очень мало данных. Приведенное здесь эмпирическое правило должно использоваться только в качестве первой оценки.
Как уже было отмечено при обсуждении требований к основной памяти, обращения к диску выполняются примерно в 30000 медленнее, чем к памяти. В результате, лучший способ оптимизации дискового ввода/вывода - вообще его не выполнять! Однако экономически это не оправдано. Таким образом, обеспечение достаточной пропускной способности (емкости доступа) подсистемы ввода/вывода, является решающим фактором для обеспечения высокой устойчивой производительности СУБД. Множество технических соображений приводят к некоторым удивительным результатам.
Без понимания приложения заказчика, стратегии индексации, принятой администратором базы данных, а также механизмов поиска и хранения СУБД сложно сделать точное утверждение о том, какого типа доступ к диску данная транзакция будет навязывать системе. Особенно трудно количественно определить сложные транзакции, которые имеют место в приложениях третьих фирм, например, в продукте R/3 SAP, который надстроен над Oracle. Однако в отсутствие фирменной информации стоит предположить, что любая транзакция, которая находит небольшое число специально поименованных записей из индексированной таблицы "по индексному ключу" будет представлять собой операцию произвольного доступа к диску. Например, транзакция
select name, salary from employee
were phone-number = "555-1212" or
ssn = "111-111-1111";
почти наверняка будет осуществлять произвольное обращение к диску, если таблица служащих индексируется с помощью phone-number и ssn. Однако, если таблица индексируется только именем и номером служащего, то такая транзакция будет выполняться путем последовательного сканирования таблицы, вполне возможно затрагивая каждую ее запись.
Запросы, которые содержат целый ряд значений ключей, могут генерировать комбинацию произвольного и последовательного доступа, в зависимости от имеющей место индексации.
Рассмотрим запрос
select part_no, description, num-on-hand from stock
where (part_no > 2000 and part_no < 24000);
Если складская таблица индексируется с помощью part_no (что очень вероятно), этот запрос будет вероятно генерировать последовательное сканирование индексов (а возможно только частичное сканирование, если индексы физически хранятся в некотором способом отсортированном порядке), за которым последует произвольная выборка подходящих строк из таблицы данных. Однако, если по каким-то причинам эта таблица не индексировалась бы с помощью part_no, то запрос почти наверняка приводил бы к полному сканированию таблицы.
Напомним, что любое обновление базы данных связано и с обновлением всех затронутых индексов, а также с выполнением записи в журнал. К сожалению, вся эта техника уходит далеко за рамки данной части курса, требуя основательного понимания работы конкретной используемой СУБД, сложной природы запросов и методов оптимизации запросов. Оценка требований к выполнению дисковых операций оказывается неточной без детальной информации о том, как СУБД хранит данные, даже для показанных здесь простых транзакций. Вычисление количества и типа дисковых обращений для операции соединения пяти таблиц, ограниченной коррелирующим подзапросом был бы сложен даже для авторов приложения!
Замечание. В случаях, когда ожидается, что такие запросы будут определять общую производительностью прикладной системы, следует настаивать на консультациях экспертов. Диапазон ошибок для такого рода запросов часто составляет 1000:1!
Одной из наиболее общих проблем в СУБД является обеспечение большой емкости дисковой памяти для хранения данных при достаточной пропускной способности дисковой подсистемы. На большинстве серверов при выполнении обращений к диску доминируют операции произвольного доступа. Сегодня на рынке доступны множество дисков, но их производительность при выполнении операций произвольного доступа почти одна и та же:
Таблица 2.4.Временные параметры некоторых дисков
| НМД | Задержка вращения (мс) |
Среднее время поиска (мс) | Скорость обращений к диску оп/с, Мб/с (объем блока данных - 8 Кб) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Полностью произвольные |
Полностью последовательные |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 424 Мб | 6.8 | 14 | 50, 0.400 | 323, 2.6 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 535 Мб | 5.56 | 12 | 57, 0.456 | 451, 3.6 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1.05 Гб | 5.56 | 11.5 | 67, 0.536 | 480, 3.8 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 2.1 Гб | 5.56 | 11.5 | 62, 0.496 | 494, 4.0 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Хотя диск 2.1 Гб имеет впятеро
большую емкость, чем диск 424 Мб, он
обеспечивает только на 24% лучшую
скорость выполнения операций
произвольного доступа. В
действительности диск 1.05 Гб
быстрее, чем диск 2.1 Гб. (Хотя их
характеристики очень близки, диск
1.05 Гб имеет дополнительное
фирменное обеспечение в своем
встроенном контроллере. Главное
отличие состоит в том, что
контроллер диска 1.05 Гб способен
соединяться и разъединяться с
шиной SCSI намного быстрее, чем
контроллер диска
2.1 Гб). По этим причинам наилучшие
результаты почти всегда
достигаются при использовании
наименьшего по емкости диска, даже
когда больший диск имеет
превосходные спецификации по всем
параметрам. Например, сервер SPARCserver
1000 может оснащаться дисками
емкостью 535 Мб, 1.05 Гб и 2.1 Гб. Как
видно из таблицы 2.5, для заданного
объема дисковой памяти (16 Гбайт),
общая пропускная способность
дисковой подсистемы существенно
выше при использовании дисков 535 Мб
(больше чем в три раза).
Использование дисков такой малой емкости не всегда практично, поскольку общие требования к емкости дисковой подсистемы могут привести к использованию дисков большей емкости, или возможно в системе окажется недостаточно доступных слотов периферийной шины для конфигурирования необходимого числа главных адаптеров SCSI. Тем не менее, целесообразно рассмотреть возможность использования дисковых подсистем с большей пропускной способностью в таких системах, где о действительной нагрузке ввода/вывода известно, что она носит взрывной характер, либо полностью неизвестна, или где общий объем данных относительно невелик по сравнению с количеством имеющих к ним доступ пользователей.
Таблица 2.5. Пропускная способность ввода/вывода для дисковой памяти емкостью 16 Гб
| НМД | Требуемое количество | Общая скорость оп/с |
Строк SCSI | Стоимость (1994 г.) | Цена за операцию |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 535 Мб | 32 | 1824 | 8 | $50360 | $27 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1.05 Гб | 16 | 1072 | 4 | $39580 | $37 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 2.1 Гб | 8 | 496 | 2 | $37390 | $75 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Было бы серьезной ошибкой подбирать для системы дисковые накопители исключительно исходя из требуемой общей емкости дисковой памяти. Хотя эта проблема не нова, со временем она становится все более серьезной, поскольку емкость дисковых накопителей и требования к общей емкости дисковой памяти начинают увеличиваться значительно более быстрыми темпами, чем пропускная способность дисков.
Рекомендации:
Большинство СУБД позволяют администратору системы выбрать способ размещения файлов СУБД (на "чистых" дисках или в стандартной файловой системе UNIX). Некоторые системы, наиболее известными из которых являются Ingres и Interbase, навязывают использование файловой системы UNIX. Для систем, которые допускают выбор указанных возможностей, приходится оценивать целый ряд разных критериев.
Хранение данных в файловой системе оказывается менее эффективным (отличие составляет по крайней мере 10%), поскольку при выполнении каждого обращения к диску со стороны СУБД в работу включается дополнительный слой системного ПО. Поскольку в больших СУБД часто одним из ограничивающих ресурсов является мощность процессора, использование "чистых" разделов (raw partition) улучшает производительность системы при пиковой нагрузке. Только по этой причине большинство администраторов баз данных обычно предпочитают хранение данных на "чистых" разделах дисков. Если ожидается, что система достигнет своих пределов производительности, особенно в части использования мощности ЦП, то это может быть наиболее подходящий выбор. Однако следует отметить, что эффективность процессора в действительности становится под вопрос только под пиковой нагрузкой. Большинство же систем испытывают эти пиковые нагрузки только в очень редких случаях.
Хранение данных в файловой системе имеет также определенную цену в терминах потери емкости памяти. Файловая система UNIX потребляет примерно 10% от форматированной емкости дисков для метаданных о файлах и файловой системе. Более того, файловая система резервирует 10% оставшегося пространства, чтобы обеспечить быстрый поиск свободного пространства в случае расширения файлов (этот дополнительный объем памяти в принципе может быть использован, но за счет потенциально значительных дополнительных задержек, которые возникнут при открывании или расширении файлов файловой системы). Если СУБД работает с данными через файловую систему, то по сравнению с "чистым" диском емкость дисковой памяти в целом уменьшается на 19%.
Если хранение данных в файловой системе обходится дороже как с точки зрения потребления мощности процессора, так и с точки зрения потерь емкости памяти, возникает вопрос: "А зачем все это нужно?". Имеется несколько важных причин, по которым в СУБД используется хранение данных в файловой системе. Большинство из них связано с обеспечением гибкости или относятся к разряду более знакомой для пользователя технологии.
Во-первых, и что возможно наиболее важно, использование файловой системы позволяет работать с памятью с помощью стандартных утилит UNIX. Например, стандартные утилиты UNIX ufsdump и ufsrestore могут использоваться для того, чтобы производить надежное резервное копирование и восстановление памяти СУБД. Для этого могут также использоваться не связанные с операционной системой инструментальные средства резервного копирования, подобные Online:Backup 2.0 компании Sun. Кроме того, гораздо проще осуществлять манипулирование отдельными частями базы данных. Например, можно осуществлять прямое перемещение таблицы с одного диска на другой, даже если используются диски разного размера и типа. Поскольку каждый из поставщиков СУБД предлагает свои собственные внутренние утилиты резервного копирования и восстановления, все они различны. Более того, некоторые из них выполняются настолько медленно, что заказчики часто прибегают к использованию копирования физических томов (т.е. используют команду dd(1)) со всеми присущими такому копированию сложностями. Хранение данных в файловой системе позволяет выполнять единообразные, надежные процедуры для того, чтобы работать через систему и сеть. При этом, если необходимо, могут также использоваться инструментальные средства поставщиков СУБД.
При некоторых обстоятельствах операции через файловую систему дают возможность оптимизации, которую сама СУБД не может реализовать. В частности, файловая система UNIX пытается кластеризовать данные в более крупные физические единицы, чем большинство СУБД. Поскольку дисковое пространство для таблиц часто заранее распределено, файловой системе обычно удается агрегатировать данные в блоки объемом по 56 Кб, в то время как менеджеры памяти СУБД обычно оперируют только страницами размером в 2 (или иногда 8) Кб. Последовательное сканирование таблиц или индексов, хранящихся таким образом часто может оказаться более эффективным, чем эквивалентных таблиц, хранящихся более традиционным способом. Если в операциях системы доминирует последовательное сканирование (или операции соединения (joins), которые часто подразумевают последовательное сканирование), хранение данных в файловой системе обеспечивает более высокую производительность.
Рекомендации:
Обычно пользователи рассматривают СУБД как средство хранения и последующего поиска своих данных и вовсе не задумываются о том, что же в действительности хранится на диске. На практике, программное обеспечение СУБД поддерживает значительное количество дополнительной информации. Было бы серьезной ошибкой предполагать, что для размещения заданного количества данных пользователя потребуется тот же самый объем дискового пространства. Схема базы данных, табличные индексы, B-деревья узлов каталогов, временные таблицы, заранее выделенное пространство для хеш-таблиц и индексов, пространство для сортировки, файлы журнала, архивы и мириады других функций - все это включается в дисковое пространство системы.
Если отсутствует более точная информация, то обычно разумно было бы предусмотреть примерно удвоенный объем дискового пространства по сравнению с объемом "чистых" данных. Это обеспечивает некоторую гибкость для создания индексов и т.п., и в итоге позволяет улучшить производительности приложения. Хотя коэффициент 2 на первый взгляд кажется чрезмерным, следует, например, иметь в виду, что индексация, навязываемая предложенным тестом TPC-D потребляет более 400 Мб. При этом объем "чистых" данных составляет примерно 650 Мб. При использовании устанавливаемых по умолчанию параметров памяти СУБД Oracle, объем "чистых" данных, необходимых для реализации теста TPC-C, увеличивается на 30% при хранении их в базе данных Oracle даже без индексации. Поэтому можно легко потребовать для системы даже гораздо больше, чем 100% дополнительного пространства.
Рекомендации:
Другим фактором, влияющим на конфигурацию подсистемы ввода/вывода, является предполагаемое распределение данных по дискам. Даже минимальная по объему система должна иметь по крайней мере четыре диска: один для операционной системы и области подкачки (swap), один для данных, один для журнала и один для индексов. Конфликты по этим ресурсам в системе с ограничениями ввода/вывода являются самым большим отдельным классом проблем обеспечения производительности в среде, в которой приложение в определенной степени было настроено (т.е. в наиболее продуктивных средах). Более крупные системы должны учитывать даже большее количество переменных, такие как зеркалирование дисков, расщепление дисков и перекрытие ресурсов. Вообще говоря, наиболее продуктивным и достаточно эффективным по стоимости способом распределения данных является обеспечение всех основных логических сущностей отдельным набором дисков.
Хотя технически возможно объединить по несколько логических функций на одних и тех же (физических или логических) дисках, для подсистемы ввода/вывода это оказывается очень разрушительным и почти всегда приводит к неудовлетворительной производительности. Например, рассмотрим базу данных, которая состоит из таблицы данных размером 1.5 Гбайт и индексов объемом 400 Мбайт, и которая требует 40 Мбайт для размещения журнального файла. Соблазнительно просуммировать эти объемы вместе и обнаружить, что вся эта информация может поместиться на одном диске емкостью 2.1 Гбайт. Если реализовать такую конфигурацию системы, то при выполнении приложением практически любого обновления базы данных, каретка диска все время будет сновать челноком по диску для каждой транзакции. В частности, процесс формирования журнала, который должен писаться синхронно и медленно, в действительности будет выполняться в режиме произвольного доступа, а не в режиме последовательного доступа к диску. Уже только это одно будет существенно задерживать каждую транзакцию обновления базы данных.
Кроме того, выполнение запросов, выбирающих записи из таблицы данных путем последовательного сканирования индекса, будет связано с сильно увеличенным временем ожидания ввода/вывода. Обычно сканирование индекса выполняется последовательно, но в данном случае каретка диска должна перемещаться для поиска каждой записи данных между выборками индексов. В результате происходит произвольный доступ к индексу, который предполагался последовательным! (В действительности индекс мог специально создаваться с целью последовательного сканирования). Если таблица данных, индекс и журнал находятся на отдельных дисках, то произвольный доступ к диску осуществляется только при выборке данных из таблицы и результирующая производительность увеличивается вдвое.
Последним пунктом обсуждения возможности объединения разных функций на одних и тех же физических ресурсах является то, что подобное объединение часто создает ситуации, в которых максимизируются времена подвода головок на диске. Хотя время позиционирования в спецификациях дисковых накопителей обычно приводится как одно число, в действительности длительность позиционирования сильно зависит от необходимого конкретного перемещения головок. Приводимое в спецификациях время позиционирования представляет собой сумму времен всех возможных позиционирований головок, деленное на количество возможных позиционирований. Это не то время, которое затрачивается при выполнении "типичного" позиционирования. Сама физика процесса перемещения дисковой каретки определяет, что позиционирование на короткое расстояние занимает гораздо меньше времени, чем на длинное. Позиционирование на смежный цилиндр занимает всего несколько миллисекунд, в то время как позиционирование на полный ход каретки длится значительно больше времени, чем приводимое в спецификациях среднее время позиционирования. Например, для диска 2.1 Гб позиционирование головки на соседний цилиндр обычно занимает 1.7 мс, но длится 23 мс для полного хода каретки (в 13 раз дольше). Поэтому длительное позиционирование головок, возникающее при последовательности обращений к двум разным частям диска, необходимо по возможности исключать.
Рекомендации:
При разработке подсистемы ввода/вывода должно быть уделено внимание не только максимальной емкости ее компонентов, но также уровню использования (загруженности) каждого ресурса. Большинство параметров, используемых для описания емкости ресурсов, так или иначе связаны с пропускной способностью. Например, шина SCSI характеризуется пропускной способностью в 10 Мбайт/с. Это скорость пересылки битов по шине. Такой параметр не дает информации о том, насколько занята сама шина и, следовательно, не дает также информации о том, сколько времени будет потрачено на обслуживание данного запроса. Приводить в качестве параметра ресурса рейтинг максимальной пропускной способности - все равно, что говорить, что предел скорости автомагистрали равен 130 км в час: если въезды и съезды с нее так перегружены, что это занимает длительное время, то общая скорость вероятно будет намного ниже установленного предела.
Точно такие же принципы применимы к различным периферийным устройствам и периферийным шинам. В частности, это справедливо и для шин SCSI. Экспериментальные результаты показывают, что если должна поддерживаться пиковая производительность, то степень загруженности шины SCSI должна поддерживаться на уровне 40%. Аналогичным образом, степень загрузки дисков должна поддерживаться на уровне 60%. Диски могут выдерживать значительно большую степень загрузки чем шина SCSI, поскольку во встроенных дисковых контроллерах имеется интеллект и средства буферизации. Это позволяет координировать работу буферов дорожек, каретки диска и очереди запросов такими способами, которые не возможны на достаточно примитивных главных адаптерах шины SCSI.
Обычно невозможно оценить, какова будет средняя степень загрузки дисков или шины SCSI до тех пор, пока система не начнет работать. В результате, достаточно приемлемой оказывается такая конфигурация, которая позволяет распределить часто используемые данные и индексы по стольким дискам и шинам SCSI, сколько позволяют бюджет и технические ограничения. Для данных, доступ к которым происходит не очень часто, например, только во время ночной пакетной обработки (или других полуархивных данных подобных транзакциям годовой давности), можно рекомендовать как можно более плотную упаковку на накопителях.
Как только система начнет работать, можно измерить действительную степень загрузки дисков и соответствующим образом перераспределить данные. Как указывалось выше, перераспределение данных должно выполняться с учетом других параметров доступа к диску: везде надо поддерживать баланс.
В контексте СУБД имеется по крайней мере два механизма для распределения данных по дисковым накопителям. Для эффективного распределения доступа к данным все известные СУБД имеют возможность осуществлять конкатенацию нескольких дисковых накопителей или файлов UNIX. (В СУБД Ingres, например, реализовано истинное расщепление дисков, ограниченное стандартным размером чередования 16 Кбайт). Похожие возможности (помимо горячего резервирования и расщепления дисков) предлагают и специальные программные средства типа Online:DiskSuite. Если работа с таблицей ограничивается возможностями подсистемы ввода/вывода, следует исследовать запросы, которые вызывают ввод/вывод. Если эти запросы реализуют произвольный доступ к дискам, например, если многие пользователи независимо запрашивают индивидуальные записи, то имеющиеся возможности конкатенации дисков в СУБД полностью адекватны распределению нагрузки доступа по множеству дисков (при достаточно полном заполнении пространства таблицы). Если обращения по своей природе последовательны, например, если один или несколько пользователей должны просматривать каждую строку таблицы, то больше подходит механизм расщепления дисков.
Основное преимущество
использования расщепления с
помощью средств, подобных
Online:DiskSuite, заключается в том, что
задача распределения обращений к
данным становится гораздо более
простой для администратора базы
данных. При действительном
расщеплении эта задача тривиальна
и почти всегда дает оптимальные
результаты. Часто это не тот случай,
когда логически разделение данных
по пространствам таблицы
использует внутренние механизмы
СУБД. Задача заключается в том,
чтобы распределить тяжело
используемые таблицы по отдельным
дисковым ресурсам, однако часто
невозможно принять решение
относительно конфликтующих
комбинаций запросов при обращениях
к этим таблицам, приводящих к
неровной нагрузке. При
использовании
DiskSuite степень загруженности дисков
сама будет стремиться к
естественному уровню.
Обычно СУБД делят таблицу на несколько относительно больших сегментов и размещают данные равномерно по этим сегментам. Главное отличие между конкатенацией СУБД и функцией расщепления Online:DiskSuite заключается в размещении смежных данных. Когда диски конкатенируются друг с другом, последовательное сканирование представляет собой тяжелую нагрузку для каждого из дисков, но эта нагрузка носит последовательный характер (только один диск участвует в обслуживании запроса). Истинное расщепление дисков, реализованное в Online:DiskSuite, осуществляет деление данных по гораздо более мелким границам, позволяя тем самым всем дискам участвовать в обслуживании даже сравнительно небольшого запроса. Как результат, при использовании расщепления загрузка дисков при выполнении последовательного доступа существенно уменьшается. К архивным и журнальным файлам всегда осуществляется последовательный доступ и они являются хорошими кандидатами для расщепления, если реализация обращений к таким файлам ограничивает общую производительность системы.
По мере продолжения роста размеров и важности баз данных, процедуры резервного копирования, которые выполняются с блокировкой доступа к СУБД, становятся практически неприемлемыми. При реализации резервного копирования в оперативном режиме (режиме online) могут возникнуть достаточно сложные вопросы по конфигурированию соответствующих средств, поскольку резервное копирование больших томов данных, находящихся в базах данных, приводит к очень интенсивной работе подсистемы ввода/вывода. Резервное копирование в оперативном режиме часто вызывает очень высокий уровень загрузки дисков и шины SCSI, что приводит к низкой производительности приложений. Следует уделять особое внимание конфигурациям всех устройств, вовлеченных в процессы резервного копирования.
Рекомендации:
Если СУБД работает в режиме клиент/сервер, то сеть или сети, соединяющие клиентов с сервером должны быть адекватно оборудованы. К счастью, большинство клиентов работают с вполне определенными фрагментами данных: индивидуальными счетами, единицами хранящихся на складе изделий, историей индивидуальных счетов и т.п. При этих обстоятельствах скорость сети, соединяющей клиентов и серверы редко оказывается проблемой. Отдельной сети Ethernet или Token Ring обычно достаточно для обслуживания 100-200 клиентов. На одном из тестов Sun конфигурация клиент/сервер, поддерживающая более 250 пользователей Oracle*Financial, генерировала трафик примерно 200 Кбайт/с между фронтальной системой и сервером базы данных. По очевидным причинам стоит более плотно наблюдать за загрузкой сети, особенно когда число клиентов превышает примерно 20 на один сегмент Ethernet. Сети Token Ring могут поддерживать несколько большую нагрузку, чем сети Ethernet, благодаря своим превосходным характеристикам по устойчивости к деградации под нагрузкой.
Даже если с пропускной способностью сети не возникает никаких вопросов, проблемы задержки часто приводят к тому, что более удобной и полезной оказывается установка отдельной, выделенной сети между фронтальной системой и сервером СУБД. В существующих в настоящее время конфигурациях серверов почти всегда используется большое количество главных адаптеров шины SCSI; поскольку как правило эти адаптеры спарены с портами Ethernet, обеспечение выделенного канала Ethernet между клиентом и сервером выполняется простым их подключением к дешевому хабу с помощью кабельных витых пар. Стоимость 4-портового хаба не превышает $250, поэтому причины, по которым не стоило бы обеспечить такое выделенное соединение, практически отсутствуют.
Однако в ряде случаев
возможностей сетей Ethernet или Token Ring
может оказаться недостаточно. Чаще
всего это случается, когда данные
хранятся в базе в виде очень
больших массивов. Например, в
медицинских базах данных часто
хранятся образы рентгеновских
снимков, поскольку они могут быть
легко быть объединены с другими
данными истории болезни пациента;
эти образы рентгеновских снимков
часто бывают размером в 3-5 Мбайт.
Другими примерами приложений с
интенсивным использованием данных
являются системы хранения/выборки
документов, САПР в области механики
и системы мультимедиа. В этих
случаях наиболее подходящей
сетевой средой является FDDI, хотя в
сравнительно ближайшем будущем она
может быть будет заменена на ATM или
100 Мбит Ethernet.
Для систем, требующих большей
пропускной способности сети, чем
обеспечивают
Ethernet или Token Ring, по существу до конца
1994 года FDDI была единственным
выбором. Хотя концентраторы FDDI
имеют значительно большую
стоимость по сравнению с хабами
Ethernet, установка выделенной сети
между фронтальной системой и
сервером СУБД оказывается
достаточно простой и недорогой. Как
определено в стандарте FDDI,
минимальная сеть FDDI состоит только
из двух систем, соединенных между
собой с помощью единственного
кабеля. Никаких концентраторов не
требуется, а цены на некоторые
интерфейсы FDDI в настоящее время
упали до уровня менее $1500.
В последнее время резко увеличилось число приложений, в которых фронтальные системы и серверы СУБД могут или должны размещаться в географически разнесенных местах. Такие системы должны соединяться между собой с помощью глобальных сетей. Обычно средой передачи данных для таких сетей являются арендованные линии с синхронными последовательными интерфейсами. Эти линии обычно работают со скоростями 56-64 Кбит/с, 1.5-2.0 Мбит/с и 45 Мбит/с. Хотя скорость передачи данных в такой среде значительно ниже, чем обычные скорости локальных сетей, подобных Ethernet, природа последовательных линий такова, что они могут поддерживать очень высокий уровень загрузки. Линия T1 предлагает пропускную способность 1.544 Мб/с (2.048 Мбит/с за пределами США). По сравнению с 3.5 Мбит/с, обеспечиваемых Ethernet в обычном окружении, линия T1 предлагает пропускную способность, которая количественно практически не отличается от Ethernet. Неполные линии T3 часто доступны со скоростями 10-20 Мбит/с, очевидно соперничая с сетями Ethernet и Token Ring. В ряде случаев можно найти приложения, которые могут работать успешно в конфигурации клиент/сервер даже через сеть со скоростью 56 Кбит/с.
Для традиционных бизнес-приложений трафик конфигурации клиент/сервер обычно содержит сравнительно низкий объем данных, пересылаемых между фронтальной системой и сервером СУБД, и для них более низкая пропускная способность сети может оказаться достаточной. В большинстве случаев задержка сети не является большой проблемой, однако если глобальная сеть имеет особенно большую протяженность, или если сама среда передачи данных имеет очень большую задержку (например, спутниковые каналы связи), приложение должно быть протестировано для определения его чувствительности к задержкам пакетов.
Для сокращения трафика клиент/сервер до абсолютного минимума могут использоваться мониторы обработки транзакций.
Общей ошибкой пользователей является представление о том, что сетевой трафик, связанный с терминальными серверами, может перегрузить Ethernet. Это неправильно. Рассмотрим, например, 64-портовый сетевой терминальный сервер, который может управлять каждым портом, работающим со скоростью 38400 бод, или 38400 символов в секунду. (В каждом байте данных содержится 8 бит информации, но рейтинг бод включает биты старта и стопа). Если каждый порт работает на полной скорости 38400 бод, то всего за одну секунду по сети будет пересылаться 2457600 байт данных (или примерно 1.9 Мбит, т.е. около 20% максимальной загрузки Ethernet) с главной системы в терминальный сервер для дальнейшего распределения. Конечно имеются некоторые накладные расходы (дополнительные байты TCP/IP), связанные с этим уровнем трафика, но они составляют примерно 50 байт на пакет, т.е. примерно 4% для этого уровня трафика. Это сценарий наихудшего случая, например, когда на полной скорости работают 64 принтера. Типичный же уровень трафика намного ниже: один 2000-символьный экран может отображаться один раз в минуту. При этих условиях 64-портовый терминальный сервер обрабатывает примерно 35 байт в секунду на один порт или всего примерно 2 Кбайт/с.
Операции по вводу символов с клавиатуры терминала можно вообще не рассматривать, поскольку даже самая быстрая машинистка печатает только 20 символов в секунду (более типичный случай 1.0 - 1.5 символов в секунду). Даже если операции ввода обрабатываются в режиме cbreak, наибольшая нагрузка, которая будет генерироваться всеми пользователями, может составлять 1300 символов в секунду (по 20 символов в секунду на каждый порт при 64 портах). После учета максимальных накладных расходов TCP/IP это дает общий поток в 80 Кбайт/с . Типичные нагрузки (64 порта по 1.5 символа в секунду) будут составлять порядка 15 Кбайт/с с учетом накладных расходов.
По определению семантики оператора SQL COMMIT_WORK любая СУБД должна гарантировать, что все обновления базы данных должны направляться и фиксироваться в стабильной памяти (т.е. любой памяти, которая обеспечивает устойчивое хранение данных даже в условиях сбоев системы или отказов питания). Чтобы СУБД могла дать такую гарантию, она должна выдавать для выполнения по крайней мере некоторые из своих операций записи синхронно. Во время выполнения таких записей операционная система блокируется и не возвращает управление вызвавшей программе до тех пор, пока данные не будут зафиксированы в стабильной памяти. Хотя эта стратегия очень надежна, вместе с тем она приводит к существенному замедлению операций, поскольку при выполнении синхронных записей обязательно требуется, чтобы данные были записаны непосредственно на дорожку диска. Синхронная запись на "чистый" диск занимает примерно 20 мс, а синхронная запись в файловую систему может занять в несколько раз больше времени (если должны быть выполнены обновления в косвенные блоки или блоки с двойной косвенностью).
Обычно СУБД осуществляют синхронную запись только в свои журналы - в случае отказа системы сама база данных может быть реконструирована из синхронно записанного журнала. Иногда система в целом становится узким местом в процессе заполнения журнала. Обычно это случается в среде тяжелой обработки транзакций, которая выполняет многочисленные обновления базы данных (приложения, выполняющие только чтение базы данных, подобные системам поддержки принятия решений, осуществляют немного записей в журнал). Этот эффект еще более усиливается при использовании для журнальных дисков зеркальных пар. В этих случаях для ускорения процесса журнализации часто полезно использовать PrestoServe или NVSIMM. Фиксация записей в немеханических NVRAM, устанавливаемых на PrestoServe или в NVSIMM может существенно расшить узкое горло в некоторых системах.
Рекомендации:
Поскольку обычно базы данных бывают очень большими и в них хранится исключительно важная информация, правильная организация резервного копирования данных является очень важным вопросом. Объем вовлеченных в этот процесс данных обычно огромен, особенно по отношению к размеру и обычной скорости устройств резервного копирования. Просто непрактично осуществлять дамп базы данных объемом 20 Гбайт на 4 мм магнитную ленту, работающую со скоростью 500 Кбайт/с: это займет примерно 12 часов. В этой цифре не учтены даже такие важные для работы системы соображения, как обеспечение согласованного состояния базы данных и готовность системы.
Составить расписание для резервного копирования системы, которая используется главным образом в течение нормального рабочего времени, обычно сравнительно просто. Для выполнения процедур резервного копирования после завершения рабочего дня часто используются скрипты. В некоторых организациях эти процедуры выполняются автоматически даже без привлечения обслуживающего персонала, в других в неурочное время используют операторов. Для выполнения автоматического резервного копирования без привлечения обслуживающего персонала требуется возможность его проведения в рабочем режиме (режиме online).
Если система должна находиться в рабочем режиме 24 часа в сутки, или если время, необходимое для выполнения резервного копирования превышает размер доступного окна (временного интервала), то планирование операций резервного копирования и конфигурирование соответствующих средств значительно усложняются.
В некоторых случаях необходимо выполнять "резервное копирование в режиме online", т.е. выполнять резервное копирование в то время, когда база данных находится в активном состоянии с подключенными и работающими пользователями.
При выполнении резервного копирования базы данных предполагается, что она находится в согласованном состоянии, т.е. все зафиксированные обновления базы данных не только занесены в журнал, но и записаны также в таблицы базы данных. При реализации резервного копирования в режиме online возникает проблема: чтобы резервные копии оказались согласованными, после того как достигнута точка согласованного состояния базы данных и начинается резервное копирование, все обновления базы данных должны выполняться без обновления таблиц самой базы до тех пор, пока не завершится ее полное копирование. Большинство основных СУБД обеспечивают возможность резервного копирования в режиме online.
Продолжительность процедур резервного копирования возможно является наиболее важным вопросом для организаций с большими базами данных (объемом более 10 Гбайт), и выбор методики резервного копирования может определяться именно этим. Резервное копирование небольших баз данных может легко осуществляться при наличии всего одного накопителя на магнитной ленте Exabyte или DAT. Хотя выпускаемые в настоящее время накопители на МЛ позволяют копировать данные со скоростью примерно 1.25 Гбайт в час, для больших баз данных это очевидно неприемлемо. Для увеличения пропускной способности несколько устройств могут работать параллельно, хотя конфликты по ресурсам делают этот способ недостаточно эффективным при использовании одновременно более трех-четырех НМЛ.
Некоторые НМЛ на 8 мм ленте с аппаратной компрессией способны обеспечивать скорость до 3 Гбайт/час, т.е. более чем вдвое превышают скорость стандартных устройств. Некоторые из этих устройств имеют емкость до 25 Гбайт, но более типичной является емкость 8-10 Гбайт. Совместимые с IBM 3480 устройства, например, Fujitsu Model 2480, могут обеспечивать скорость около 10 Гбайт в час, но ограниченный объем носителя (200-400 Мбайт до компрессии) означает, что для обеспечения эффективности они должны устанавливаться в механических стекерах. Некоторые относительно новые устройства используют носитель информации в формате VHS и предлагают исключительно высокую пропускную способность и емкость. В сообщении об одном из таких устройств (от Metrum) указана скорость передачи в установившемся режиме почти 15 Мбайт/с при подключении с помощью выделенных каналов fast/wide SCSI-2. Емкость этого устройства составляет 14 Гбайт на одну ленту без компрессии.
Если недоступно устройство, которое поддерживает аппаратную компрессию, возможно стоит рассмотреть возможность использования программной компрессии. Скорость резервного копирования обычно определяется скоростью физической ленты, поэтому любой метод сокращающий количество данных, которые должны быть записаны на ленту, должен исследоваться, особенно при использовании быстрых ЦП. Базы данных являются хорошими кандидатами для компрессии, поскольку большинство таблиц и строк включают значительную часть свободного пространства (обычно используются даже коэффициенты заполнения, обеспечивающие определенный процент свободного пространства с целью увеличения производительности). Некоторые таблицы могут содержать также текст или разбросанные поля двоичных данных и готовы для компрессии.
Простым, но эффективным способом сокращения времени резервного копирования является выполнение копирования на отдельный зеркальный диск. ПО Online:DiskSuite предлагает зеркалирование с очень небольшими накладными системными расходами. Если зеркальная копия сделана непосредственно после контрольной точки, или после того как база данных выключена, она действительно становится онлайновой дисковой резервной копией, которая сама может быть скопирована в любое удобное время. Можно даже выполнить рестарт базы данных, чтобы продолжить нормальную обработку, хотя с меньшей избыточностью. Если доступно достаточное количество дисковых накопителей, то может быть использован и второй набор зеркальных дисков, что позволяет сохранить полное зеркалирование даже, когда один набор зеркальных дисков отключается (во время нормальных операций диски будут зеркалироваться по трем направлениям). В этом случае резервное копирование в режиме online может продолжаться после копирования на ленту, что обеспечивает в случае необходимости очень быстрое восстановление. Этот дополнительный набор зеркальных дисков мог бы быть заново подключен перед следующей контрольной точкой, обеспечив достаточно времени (примерно 30 минут), которое позволит этому набору зеркальных дисков синхронизоваться с зеркальными дисками, работавшими в режиме online.
Большинство пользователей выполняют полное резервное копирование ежедневно. Полагая, что резервное копирование выполняется на тот случай, когда понадобится восстановление, важно рассмотреть составляющие времени восстановления. Оно включает время перезаписи (обычно с ленты) и время, которое требуется для того, чтобы выполнить изменения, внесенные в базу данных с момента резервного копирования. Учитывая необходимость средств такой "прокрутки" вперед, очень важно зеркалировать журналы и журналы архивов, которые и делают этот процесс возможным.
В рабочей среде, где большое количество транзакций выполняют записи в базу данных, время, требуемое для выполнения "прокрутки" вперед от последней контрольной точки может существенно увеличить общее время восстановления. Это соображение само по себе может определить частоту резервного копирования.
При использовании "чистых"
дисковых разделов, выбор прост: в
действительности единственными
командами UNIX, работающими с
"чистыми" разделами, являются
dd и
compress. При хранении таблиц СУБД в
файловых системах USF можно выбрать,
например, команды tar, cpio и usfdump.
Большинство пользователей
предпочитают usfdump(1) (dump(1) для Solaris 1.X),
или ее эквивалент в Online Backup (hsmdump для
Solaris 2.X). Большинство СУБД имеют
утилиты для выделения из базы
данных "чистых" данных и их
копирования на внешний носитель, но
эти операции обычно выполняются
намного медленнее, чем простое
копирование "чистых" разделов
диска.
Резервные копии очень важны. Выполнение процедур резервного копирования должно соответствующим образом отслеживаться, чтобы гарантировать, что они завершились успешно. Также важно документировать и тестировать процедуры восстановления. Момент аварии не слишком удачное время для обнаружения того, что в стратегии резервного копирования пропущены некоторые ключевые элементы.
Предыдущая глава | Оглавление | Следующая глава
|
|
