Основная тема этой книги — проектирование баз данных, однако даже самая качественно спроектированная база данных в мире ничего не стоит без кода, обеспечивающего доступ к ней. Причем не просто кода! Современные, умудренные опытом пользователи ждут программ, которые отличаются как мощью, так и скоростью. Поэтому в этой части книги наше внимание концентрируется на проектировании модулей кода, которые дополняют базу данных.
В этой главе мы сначала рассмотрим, какая информация о функциях передается на этап проектирования из этапа анализа. Затем мы опишем порядок отображения функций, организованных по бизнес-требованиям, в набор определений модулей, которые структурированы так, что их можно встроить в программу, не создавая лишнего или дублирующего кода и не используя огромных сложных модулей, если это возможно. Кроме того, мы посмотрим, какие нужно проектировать и генерировать модули, не относящиеся непосредственно к обеспечению выполнения бизнес-требований. Мы называем их системными модулями и включаем в эту категорию такие модули, как диспетчер печати и программу архивации. Наконец, мы рассмотрим преимущества использования CASE-средств при проектировании и генерации модулей, уделив особое внимание генераторам кода.
Как правило, проектирование модулей осуществляется параллельно с проектированием базы данных. Если эти задачи выполняют две отдельные группы, необходимо обеспечить хорошую связь между ними, потому что проектирование модулей и базы данных взаимосвязаны. Так, например, зачем держать в таблице производный столбец TOTAL_DEBITS, если ни один модуль не будет его запрашивать? Очень немногие решения по моделированию данных можно принять в изоляции — любое решение почти всегда выгодно для одних модулей и создает проблемы для других. Как проектировщики мы должны учесть эти последствия и выбрать компромиссный вариант.
Как проектировать модули кода? Обычно это делается в несколько этапов, причем на каждом вносятся уточнения, основанные на опыте и знании того, как будет работать система. Часто уточнение является прямым следствием создания макетов в процессе проектирования.
Результаты анализа
Давайте рассмотрим конкретные функциональные результаты анализа, которые станут для нас отправной точкой в проектировании моделей. Как говорилось в главе 3, мы должны взять эти результаты в той форме, в которой они даны, и преобразовать их в набор точных определений модулей. Начинать, как правило, следует с набора спецификаций функций, которые задают необходимые требования в форме бизнес-категорий. Нам может быть выдан и список зависимостей между функциями и вызывающими их событиями. Аналитик может подготовить также перечень выявленных в ходе анализа проблем, касающихся проектирования. Полезность этого перечня зависит от конкретного аналитика. Вообще-то, мы предпочитаем, чтобы аналитики занимались анализом, а не проектированием (точно так же, как аналитики и программисты предпочли бы, чтобы проектировщики занимались проектированием!).
Объем и содержание информации, полученной при функциональном анализе, очень зависят как от методики, так и от особенностей проекта. Некоторые аналитики любят рисовать планы экранных форм. Если это сделает их счастливыми — прекрасно, но наш опыт показывает, что окончательный продукт может быть совершенно не похож на эти чертежи. Точно так же окончательный код, вероятно, совершенно не будет похож на SQL-предложения и псевдокод, так заботливо предоставленный проектировщиками.
Иерархии функций
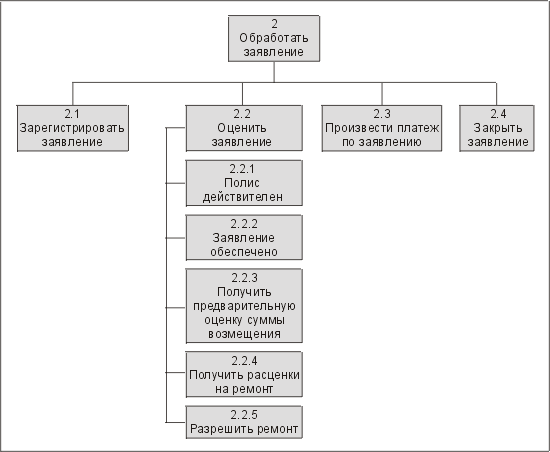
Начнем с рассмотрения иерархии функций. Этот прием анализа позволяет сформулировать требования на самом высоком уровне, а затем разбивать каждое утверждение на более мелкие составляющие до тех пор, пока не будут выявлены "атомарные" функции. На рис. 15.1 показан фрагмент иерархии функций для заявлений о выплате страхового возмещения, обрабатываемых гипотетическим страховым приложением. На этой упрощенной схеме показана только одна функция этого приложения — обработка заявлений, и в тексте мы также описываем только одну из функций (шаг 2.2).
Рис. 15.1 Иерархия функций для обработки заявлений о выплате страхового возмещения
Если понятие атомарных функций для вас новое, то самый простой метод определения атомарности — выяснить, имеет ли смысл выполнить только часть функции. Так, на шаге 2.2.5 ("Разрешить ремонт") мы имеем атомарную функцию. Ремонт либо разрешается, либо нет. Промежуточного варианта нет. Таким образом, атомарные функции, как правило, связаны с фиксациями в окончательных модулях, и если обнаруживается, что вы выполняете фиксацию в середине работы атомарной функции, то такую ситуацию требуется всесторонне исследовать.
Рассматривая иерархию функций, необходимо помнить о следующих важных моментах:
1. На этапе анализе описываются бизнес-функции, и не все они будут прямо или даже косвенно поддерживаться компьютерным приложением. Некоторые из них будут выполняться как чисто ручные процедуры.
2. Поскольку мы имеем дело с иерархией, а не с сетевой или решетчатой структурой, существует сильная тенденция к наличию функций более чем в одном месте иерархии. Конечно, разные экземпляры одной функции будут иметь разные номера, что объясняется методом описания дерева.
В классическом приложении Oracle Method такое дублирование означает ошибку анализа. Если говорить более конкретно, то дублирование обычно является признаком того, что аналитик спутал функцию с механизмом. Например, может обнаружиться, что уведомление о заявлении по почте описано не в той части иерархии, где описано уведомление по телефону. Естественно, эта ошибка означает, что механизм (почтовая служба, телефонная сеть) спутан с функцией (получение уведомления о заявлении). Если в процедуре обработки уведомлений этих типов есть различия, то их можно детализировать в рамках одной функции — "Получить уведомление о заявлении".
Определения функций
Помимо разработки иерархии функций (в которой есть только краткие их описания), аналитик должен написать текстовое пояснение к каждой функции. На каждом уровне иерархии это, возможно, и не понадобится, но вот для верхнего уровня (в нашем примере — "Обработать заявление") и для нижнего, или атомарного, уровня (2.2.1—2.2.5) это обязательно. Пример описания приведен ниже.
Пример 15.1. Краткий пример функционального определения
2.2.2. Проверить, обеспечено ли заявление
Получить и зарегистрировать все подробные сведения о заявлении (Claims Details), включая все подробные сведения о третьих сторонах (Third Party) и свидетелях (Witness). Изучить полис (Policy) на предмет наличия исключений (Exclusion Clauses) и определить, действуют ли они для данного заявления (Claim).
Если есть исключение, закрыть заявление и сгенерировать стандартное письмо (Standard Letter) заявителю (Claimant). Если такого исключения нет, изменить статус заявления на "ожидающее оценки " (Awaiting Estimate), назначить и уведомить оценщика размера убытка (Loss Adjuster).
Названия сущностей в этом описании заключены в скобки, чтобы их сразу было видно. Если вам повезет, то аналитики, готовящие для вас спецификации, поступят так же. В противном случае эта работа будет для вас полезным упражнением, выполняемым в рамках приемки спецификации, поскольку даст ясную картину того, на какие сущности ссылается функция. Убедитесь в том, что вы полностью понимаете эти описания, и проверьте, чтобы они были четкими, краткими и однозначными. Эта процедура является частью процесса контроля качества анализа и сдачи результатов, который был описан в общих чертах в главе 1.
Примечание
Имена сущностей, используемые в примере 15.1, не стандартизованы. Они сформулированы так, чтобы пример был понятен, а не в расчете на соответствие какой-либо конкретной методике.
Другие результаты анализа
Еще один важный результат анализа, без которого даже не стоит начинать проектирование, — модель сущностей. Необходимо знать, что данное предприятие пытается сделать (функции) и какую информацию нужно обработать для достижения этой цели (сущности).
Конечно, выделение имен сущностей в описаниях функций помогает понять назначений функций, однако существует более строгий подход к достижению этого понимания — построение полной матрицы "функции-сущности". Форма матрицы позволяет найти информацию о конкретной функции или конкретной сущности и провести проверку качества, т.е. проверку того, имеет ли каждая сущность конструктор, или источник (функцию, которая создает ее экземпляры), есть ли ссылки на эту сущность (т.е. используется ли она) и имеет ли она деструктор. Во многих случаях деструктором является комплект программ архивации, однако гораздо чаще он просто отсутствует. Процесс анализа ссылок на сущности обозначают аббревиатурой CRUD (Create, Reference, Update, Delete — создание, ссылка, обновление, удаление).
Иногда эту информацию разбивают дальше, получая в итоге матрицу "функции-атрибуты". Для достижения этого уровня детализации нужно много времени, и мы сомневаемся, что эти затраты всегда оправданы. В результате трансформации, выполняемой на этапе проектирования, часто получается, что матрица "функции-атрибуты" мало чем напоминает итоговую матрицу "модули-столбцы". Тем не менее, такая работа все же полезна, так как позволяет еще раз проверить качество анализа, а именно — убедиться, что каждый атрибут в модели сущностей имеет источник и используется. Она также может оказаться очень полезной при определении обоснованности разбиения одной таблицы на две (т.е. вертикального секционирования). Если видно, что два набора атрибутов используются разными наборами функций, то вполне можно создать две сущности, совместно использующие первичный ключ.
Полезными для понимания назначения функций и того, как они вписываются в общий цикл обработки, могут быть диаграммы потока данных и диаграммы жизненных циклов сущностей (мы рассматривали их в главе 3).
Отображение функций в модули
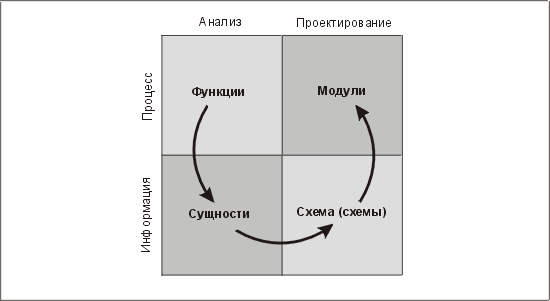
Аналитики должны концентрировать внимание на результатах, важных для пользователей, т.е. на функциональной стороне. Нам же, как проектировщикам, следует делать акцент на операционной стороне — базе данных, вторая является основой приложения. Такое различие в акцентах не всегда плохо. Чтобы защититься от опасностей, вызванных этим различием, мы рекомендуем использовать следующий четырехэтапный подход (рис. 15.2):
1. Начать анализ с рассмотрения функций.
2. Завершить анализ построением модели сущностей, поддерживающей эти функции.
3. Начать проектирование с предложения схемы, поддерживающей модель сущностей.
4. Завершить проектирование выработкой спецификаций модулей, которые реализуют вышеупомянутые функции по предложенной схеме.
Рис. 15.2. Шаги, необходимые для выхода на этап проектирования модулей
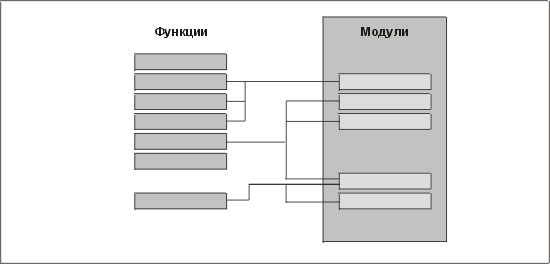
Разобравшись в описаниях функций и проверив их, можно приступать к отображению функций в модули. В некоторых случаях отображение атомарной функции в модуль дает однозначное соответствие, но это, скорее, исключение, чем правило. Действительно, чем больше однозначных соответствий мы обнаруживаем, тем сильнее подозрение, что анализ был выполнен некачественно и что этот якобы анализ на самом деле был проектированием. Типичный вариант отображения показан на рис. 15.3.
Рис. 15.3. Эффект лабиринта при отображении функций в модули
Одни функции достаточно похожи друг на друга по выполняемым действиям, и их можно и нужно объединить в общий модуль, даже если их результат или контекст — абсолютно разные. Другие функции сложны, и их нужно разбивать на более мелкие и управляемые компоненты. Иногда в функциональные описания "завернуты" правила обработки данных, которые можно реализовать как ограничения на таблицах или триггеры, а не как прикладные модули. Это распространит их действие на всю систему (а не только на приложение). Некоторые функции будут реализованы как чисто ручной процесс и вообще не будут отображены ни в какие модули.
К сожалению, никаких унифицированных и простых способов выполнения этой задачи не существует. Необходимо время, терпение и опыт. В первый раз мы вряд ли получим абсолютно "правильную" разбивку функций на модули (независимо от того, что в данном случае подразумевается под "правильной" разбивкой). Скорее всего, наше мнение относительно количества и состава модулей будет в процессе проектирования изменяться несколько раз. Тем не менее, крайне важно получить правильный (или хотя бы близкий к правильному) ответ до начала создания модулей. Если эту задачу не выполнить надлежащим образом, то в лучшем случае вы получите плохо работающее и трудное в сопровождении приложение. Более вероятно, что это будет приложение, которое просто не работает как требуется.
В процессе отображения функций в модули (и, следовательно, при проектировании модулей) необходимо постоянно прилагать усилия к тому, чтобы задействовать возможности Oracle, позволяющие создать более качественное приложение (и избегать тех, что могут ухудшить его качество). Вот некоторые средства, на которые нужно рассчитывать:
• ограничения — для реализации правил обработки данных без процедурного кода;
• триггеры базы данных — для процедурного ввода правил обработки данных для всех частей приложения;
• хранимые процедуры — для инкапсуляции общих бизнес-функций;
• идентичность SQL. (лучше всего достигается с помощью хранимых процедур) — для использования разделяемой области SQL.
Не забудьте о системных модулях
Целью проектирования модулей является реализация функциональных возможностей, удовлетворяющих бизнес-требованиям, выявленным в ходе анализа. При этом требуется рассмотреть довольное большое число периферийных процессов, не вытекающих непосредственно из сформулированной бизнес-функции. Например, необходимо обеспечить возможность печати из большинства предполагаемых приложений. Эта задача часто далеко не проста, и если вы должны реализовать решение сами, то позаботьтесь, чтобы это было учтено в ваших оценках и спецификациях. Учтите, что во многих случаях системные функции оказываются самыми требовательными в приложении.
Объем работ по проектированию и разработке системных функций зависит от конкретных требований, возможностей операционной системы и инфраструктуры, а также от наличия подходящих по назначению и цене готовых утилит, которые можно приобрести для выполнения поставленной задачи. Вот типичные кандидаты:
• средство предоставления доступа пользователям и аннулирования доступа;
• средство настройки среды для нового пользователя;
• средство, позволяющее пользователям изменять свой пароль;
• средства управления приложениями.
Некоторые из этих функций может выполнять операционная система, но операционные системы в этом отношении очень отличаются. Например, возникает вопрос, насколько гибко построена в той или иной системе обработка очередей на печать? Необходимо также подумать о том, а будут ли пользователи иметь доступ к средствам операционной системы. Даже если будут, то должны ли они будут выходить из приложения для того, чтобы посмотреть на очередь на печать, а затем вновь вызывать его? Будут ли пользователи иметь возможность доступа к Unix-очереди на печать из команды lpstat? (А действительно, может ли кто-нибудь это сделать?) Даже если на первый взгляд кажется, что операционная система поддерживает некоторые необходимые пользователю функции, как правило, все равно приходится выполнять дополнительный объем работы (особенно с очередями на печать) хотя бы для создания удобной для пользователя надстройки над некоторыми системными функциями.
Следует также учитывать, что проектирование может выполняться для неоднородной среды (т.е. для более чем одной операционной системы). В среде клиент/сервер одни приложения будут осуществлять локальную печать, а другие — печать на удаленном сервере. Необходимо решить, можно (или даже нужно) ли с технической точки зрения сделать это прозрачным для пользователей.
Наличие средств доступа к данным является обязательным требованием в современных проектах. Сегодня пользователи более сведущи в вычислительной технике, чем раньше, и они хотят иметь на своих рабочих места самые новейшие средства. Они рассчитывают на обработку информации новаторскими, необычными способами, и вам предстоит принять здесь важное решение. Хотите ли вы, чтобы ваши пользователи направляли ИУС-запросы к рабочим данным, которые могут замедлить другие текущие операции? Или же лучше извлечь данные и поместить их в копию базы данных либо в хранилище данных? Эта тема рассматривается в главе 13.
Вернемся к средствам создания запросов. Таких продуктов сейчас очень много: Oracle Data Query, Oracle Data Browser (вместе они называются Discoverer/2000), Business Objects, Cognos Impromptu и т.д. Не допускайте ошибку, предполагая, что можно просто инсталлировать эти средства на ПК пользователей и отправиться гулять. Чтобы с этими продуктами можно было работать, требуется значительный объем работ по настройке. Например, необходимо присвоить столбцам подходящие псевдонимы и создать логические представления (либо в рамках продукта, либо как представления Oracle), чтобы отчасти скрыть сложность базы данных. Пример — предварительное соединение двух и более таблиц в представлении. Эту операцию иногда называют созданием уровня отображения для данного продукта (в Business Objects его называют universe — "вселенная", просто чтобы подчеркнуть, насколько он важен).
Многие посмотрят на некоторые элементы этого списка модулей и скажут: "Это администраторская, исполнительная функция. Почему мы должны писать код для выполнения таких функций, как резервное копирование, восстановление, настройка среды, предоставление доступа новым пользователям?" Возможно, вы поддержите эту точку зрения, если работаете на крупном сервере, но если вы разрабатываете маленькие системы для рабочих групп и настольные системы, которые должны сдаваться "под ключ", это мнение, вероятно, будет ошибочным.
Ваш конечный пользователь, скорее всего, не собирается выделять ассигнования на приглашение постоянного администратора БД для управления СУБД Personal Oracle 7 на однопользовательском ПК или в сети Novell NetWare с тремя пользователями. Если у вас на предприятии 10000 таких систем, можете быть совершенно уверены, что у ваших постоянных администраторов БД не будет свободного времени, чтобы смотреть друг за другом. Поэтому сегодня существует общее требование: создать для таких функций удобный интерфейс, который будет выполнять простую работу и скрывать лежащую за ней сложность. Oracle сама признала этот факт и стремится предоставить как можно больше этих возможностей в базовом продукте, но конечная цель пока не достигнута, поэтому вам, возможно, придется самому добавлять те или иные функции. Для большой сети со множеством узлов можно попробовать приобрести средство для удаленного управления приложениями (например, PATROL фирмы ВМС), которое дополнит сервисы, имеющиеся в Oracle Enterprise Manager.
Управление приложениями
Управление приложениями — это тема для отдельного большого разговора. * Не вызывает сомнений, что производительность приложений, критичных для функционирования предприятия, является слишком важной для того, чтобы бросить ее на произвол судьбы, и ею необходимо управлять. Нужно контролировать не только общее состояние серверных платформ и экземпляров БД. Иногда необходим регулярный мониторинг различных аспектов работы приложений (например, длины разных очередей работ) и автоматическое выполнение определенного действия в случае, если эти значения превышают установленные пороговые величины. Во многих организациях имеется несколько десятков (а в некоторых случаях и несколько сотен) серверов приложений и серверов баз данных, которые необходимо непрерывно контролировать силами небольшой группы администраторов.
Одна из функций средства управления приложениями — использование интеллектуальных агентов, которые локально работают на каждом сервере и пересылают необходимую информацию на один или несколько пультов управления. Среди критериев, по которым можно оценивать средство управления, — возможность адаптации для решения разных управленческих задач, нагрузка, создаваемая в управляемых системах, сетевой трафик, который оно создает при взаимодействии с пультами управления, и способность его агентов работать автономно (т.е. управлять сервером при отсутствии пульта управления).
Во многих случаях локальный агент на сервере может осуществлять непроникающий мониторинг и управление, контролируя различные проблемы с помощью обычных возможностей системы. Простейший пример — ежеминутная выдача приведенного ниже запроса и отправка пользователю (пользователям) электронно-почтового сообщения при обнаружении невыполненных заданий:
SELECT job
, log_user
FROM dba_jobs
WHERE broken = 'Y';
Примечание
Этот запрос для ясности специально оставлен незавершенным. В реальном приложении-мониторе, на котором основан этот запрос, используется фильтр, позволяющий избежать повторного выбора заданий, о которых уже было сообщено как об поврежденных. Кроме того, этот запрос сообщает о заданиях, которые ранее помечены как поврежденные, но теперь не находятся в этом состоянии.
Во многих системах непроникающий мониторинг удовлетворяет все потребности в управлении приложениями, однако в некоторых случаях желательно, чтобы приложение само могло вызывать средство управления для уведомления об определенных событиях, которые очевидны в логике программы, но либо не поддаются выявлению из базы данных, либо их исключительно сложно или дорого найти через запросы к базе данных.
Управление исходным кодом и версиями
Для любого проекта очень важна способность эффективно управлять его исходным кодом. В противном случае возможна катастрофа. Например, если два разработчика могут одновременно работать над одним фрагментом кода, то изменения, внесенные одним из них, наверняка будут удалены и утеряны. В проекте на базе Oracle в равной степени важно контролировать варианты определений базы данных, управлять ими и поддерживать их в соответствии с версиями исходного кода.
Управление исходным кодом сводится к контролю за кодом в процессе его разработки. Управление версиями — это объединение совместимых версий кода и определения базы данных с целью создания редакции для тестирования или эксплуатации системы.
Управление базой данных
Мы считаем, что в большинстве случаев первый вариант проекта базы данных нужно создать как можно быстрее. Это может быть полностью нормализованная логическая модель, полученная в ходе анализа, со всеми структурами, которые нельзя непосредственно реализовать в реляционной модели. В главе 3 мы подробно рассматривали эти структуры и объясняли, как их можно разрешать при проектировании таблиц. Цель этого — обеспечить макетирование, демонстрацию и эксперименты. Весьма полезно также разработать скрипты для заполнения таблиц некоторыми или всеми постоянными либо долговременными данными, например справочными значениями, и заполнения некоторых базовых таблиц тестовыми данными. Качество тестовых данных может иметь очень важное значение — они могут ослабить зависимости между модулями, не позволяющие выполнить автономный тест одного модуля из-за того, что он сильно зависит от данных, созданных другим модулем, который еще не разработан.
И так понятно (но мы все равно это подчеркнем), что любой код, Разработанный по этому первому варианту, имеет все шансы окончить свое существование в мусорной корзине! По этой причине мы иногда используем термин "итеративная разработка" вместо слова "макетирование", чтобы привлечь внимание руководителей к тому неприятному факту, что как бы им ни нравился первый вариант, его придется выбросить. Если они будут сопротивляться, спросите, не хотели бы они полетать на макете самолета.
Учетной записи в действующем экземпляре базы данных где-то в корпоративной сети, как правило, недостаточно для организации рабочего места разработчика. Он должен иметь свой собственный экземпляр Oracle7, желательно — свой собственный выделенный сервер. В процессе проектирования необходимо учитывать требования предстоящей генерации и тестирования где, вероятно, понадобится несколько экземпляров, в каждом из которых может быть несколько схем. Однако мы не рекомендуем давать каждому разработчику свой экземпляр, поскольку поддержка совместимости схем в этом случае может оказаться очень трудной задачей. Код, разработанный по устаревшей структуре таблицы, вряд ли будет работать с новой, правильной структурой. Вопрос выдачи версий базы данных разработчикам требует особого внимания.
Мы обнаружили, что самый лучший метод (конечно, в среде разработки Oracle) — дать каждому разработчику свою собственную схему (в Oracle7 это то же самое, что и пользовательское имя) и настоять на том, чтобы разработчики применяли синонимы для обращения к объектам в совместно используемой схеме, которую сопровождает администратор БД группы разработчиков. Это — относительно простой способ проверки того, на какие приватные объекты ссылается та или иная схема.
Один из основных моментов, который вы должны согласовать, — как часто повторять команды обновления базы данных и какой механизм использовать для выполнения повторной выдачи. Удовлетворить всех и каждого здесь просто невозможно! Всегда найдется кто-нибудь, кто просто ждет изменений, и кто-нибудь, кто отлаживает критический фрагмент кода и угрожает убить вас, если вы только попробуете сейчас обновить базу данных!
Хороший метод — составить циклический список экземпляров или схем, чтобы администратор БД разработчиков сопровождал, скажем, пять последних определений и при выдаче нового определения затирал самое старое. Для этого нужно обеспечить тесное взаимодействие, и члены бригады должны получать соответствующие уведомления о предполагаемых изменениях и полный их перечень. Достоинство такого подхода в том, что он не дает действовать по методу "смешивания и сопоставления", который может быть результатом описанной выше стратегии использования синонимов (хотя кому-то и может показаться, что именно эта особенность делает стратегию, основанную на синонимах, столь полезной).
Управление исходным кодом
Перед началом генерации необходимо определить, инсталлировать и протестировать систему управления исходным кодом. Понадобятся также make-файлы, проектные файлы или какие-либо иные методы, позволяющие полностью управлять частичной или полной регенерацией приложения. Управление исходным кодом — относительно изученная область, если речь идет о коде, написанном на С или С++, однако редко какие средства УРП хорошо стыкуются (если вообще стыкуются) с системами управления исходным кодом и с make.
Если используются генераторы исходного кода, то в действительности "исходный код" может представлять собой репозитарий или словарь проектирования, а не исходный код, хранящийся в чисто текстовых файлах. Примеры — Oracle Developer/2000 и Microsoft Visual Basic. Даже там, где используются чисто текстовые файлы (например, INP-файлы SQL*Forms версий 2.х и 3.0), система управления исходным кодом может не знать, как вставить свою управляющую информацию в файл, не сделав этот файл недействительным для программы, которая предназначена для его чтения.
Управление исходным кодом может оказаться еще более сложной задачей в средах клиент/сервер, где одна часть кода должна компилироваться на клиенте, а остальные части — на сервере. Чтобы обеспечить синхронность этих двух сред, необходимо планирование и новаторские технические приемы.
Итак, управление исходным кодом — сложная задача, но без нее не обойтись. Если два программиста могут одновременно работать над одним файлом, возникает серьезный риск потери ключевых изменений, поэтому вы должны сделать все возможное для управления этим риском. В менее масштабных проектах достаточно будет простого приложения-реестра. В этом случае члены группы договариваются регистрировать в базе данных имена всех файлов, которые они модифицируют, и никогда не изменяют копию файла, если он указан в реестре как подлежащий изменению другим пользователем. Этот подход очень прост, он основан на сотрудничестве, но, тем не менее, успешно используется в проектах.
Рекомендуем держать под таким контролем все скрипты создания объектов базы данных. Это позволяет возвращаться к старым версиям и определять, какая версия базы данных соответствует той или иной версии исходного кода программы. Существуют методы кодирования контрольной суммой, позволяющие присваивать определению схемы базы данных уникальный номер и определять его значение во время выполнения. **
В рамках системы контроля исходного кода следует также вести скрипты или экспортные файлы для создания постоянных данных (например, справочных кодов). К сожалению, ни один из методов кодирования контрольной суммой, которые мы видели, не поддерживает статические компоненты данных — все они работают только со структурой.
Администратор и (или) администратор БД должны будут предоставить разработчикам и тестировщикам регистрационные имена и учетные записи. Группа проектировщиков, поддерживая постоянную связь с администратором БД, должна обеспечить, чтобы каждый класс пользователей был представлен в целевой системе и мог использоваться в системном тесте.
Шаблоны кода
Генерация скелета, или шаблона, приложения с помощью некоторых или всех выбранных средств генерации может быть весьма продуктивной проектной задачей. Благодаря ей можно исключить из процесса генерации рутинную работу и обеспечить определенный уровень согласованности модулей. Идея состоит в том, что проектировщик создает программу, состоящую из "кожи да костей" (отсюда и название "скелет") со всем кодом или объектами, общими для всех модулей. Компоновщик затем начинает каждый новый модуль с этого скелета. Конечно, если вы пользуетесь объектно-ориентированной методикой, то создадите классы объектов, из которых компоновщики будут получать свои собственные классы.
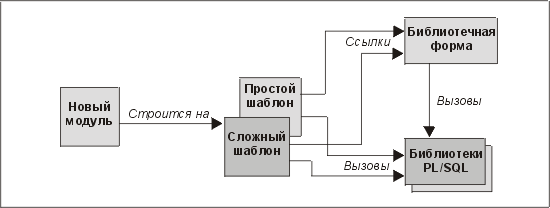
Рассмотрим пример, в котором экранные формы разрабатываются с помощью Oracle Forms, а для упрощения этого процесса применяется схема, изображенная на рис. 15.4. У нас есть два шаблона, по которым можно построить новую экранную форму. Один предназначен для простых форм, а другой — для более сложных. Кроме того, мы имеем каталог библиотек PL/SQL, которые могут использоваться и другими приложениями (не Oracle Forms).
Рис. 15.4. Типичная конфигурация шаблонов для разработки в Oracle Forms
Новые модули кода (экранные формы) строятся из копии шаблона и, как таковые, наследуют от него общие функциональные возможности (например, панель инструментов). Объекты в шаблоне в основном представляют собой ссылки на библиотеки и библиотечную форму. Это означает, что мы можем вносить изменения в некоторые из этих общих объектов и что экранные формы, построенные на шаблоне, для наследования этих изменений нужно просто перекомпилировать.
К сведению
Существует общее правило: по возможности делать ссылку на общий код, а не копировать его. Если используются ссылки на код, то его можно изменить в одном месте и эти изменения будут наследоваться всеми приложениями после выполнения перекомпиляции (а то и вообще без какого-либо явного действия!). Если же вы скопируете код, то это приведет к наличию разных его версий. Никакое тестирование шаблона до того, как разработчики начнут пользоваться им, не гарантирует, что впоследствии его не придется изменять. Поэтому не усложняйте себе жизнь — используйте, где можно, ссылки.
Проектирование процесса тестирования
Существует мнение, что планирование системного теста и приемо-сдаточных испытаний необходимо начинать в процессе анализа. В этом есть смысл, поскольку потом спонсоры проекта и основные пользователи могут взять и отказаться от ранее принятых критериев испытаний. Однако на практике такое планирование часто откладывают до этапа проектирования, а то и до генерации. И в этом случае часто дело кончается тем, что используется совокупность тестов, которые проверяют, действительно ли вы создали то, что, на ваш взгляд, требовалось. Чем раньше сформулированы приемо-сдаточные критерии, тем больше вероятность того, что они будут отражать требование, а не решение. Мы видели достаточно много систем, которые прошли все приемо-сдаточные испытания, но, тем не менее, не делали то, что от них требовалось.
В процессе проектирования необходимо предложить стандарты для модульного (автономного) тестирования и стратегию (или план) комплексного и системного тестирования. Да, это скучное занятие, но это необходимо сделать. Нужно быть человеком определенного склада, чтобы получить настоящее удовольствие от всего, связанного с тестированием!
Разработка стратегии тестирования
При тестировании должны использоваться тесты следующих категорий:
• автономные тесты (тесты модулей);
• тесты связей (проверка стыковки двух и более взаимосвязанных модулей);
• системный тест;
• приемо-сдаточные испытания (часто выполняются пользователем);
• регрессивные тесты (серия "старых" тестов, позволяющих проверить, не привели ли ваши усовершенствования к появлению неожиданных проблем);
• тесты производительности или нагрузочные тесты.
Необходимо также разработать стандарты документов для плана тестирования и результатов отдельных тестов согласно этому плану.
Разработка вспомогательных средств тестирования
Некоторые модули нельзя проверить автономно (если они являются сугубо внутренними подпрограммами). Для их автономного тестирования могут понадобиться вспомогательные программные средства, которые необходимо определить в рамках результатов этапа генерации. Необходимо также обеспечить, чтобы для каждого такого средства была выполнена оценка времени, необходимого для его написания и тестирования. Создание вспомогательных средств тестирования может занять 25% общего времени программирования проекта, причем во многих случаях сами эти программы крайне трудно тестировать.
Отметим также, что если во внутренних подпрограммах начинают проявляться дефекты или если их нужно модернизировать, то вам (или вашим несчастным преемникам) придется вновь тестировать вышеупомянутые средства. По этой причине в хороших проектах вспомогательный тестовый код часто считается "еще одной частью системы" и легко доступен из ГПИ для любого пользователя, имеющего право с ним работать. Здесь уместно еще раз напомнить наше кредо: работать умно, а не напряженно.
Использование
CASE-средств
Что можно сказать об использовании CASE-средств в проектировании приложений? Давайте рассмотрим, какой уровень функционального описания должен быть введен в CASE-продукт и насколько полезны генераторы кода. Мы также попытаемся сравнить объем работ по обеспечению такой детализации в CASE-средствах и выгоды, которые можно получить от их использования.
Вообще говоря, CASE-средства в гораздо большей степени поддерживают ту часть анализа и проектирования, которая касается моделирования данных, нежели функциональную часть. Грустно, но многие из наиболее популярных средств поддерживают только моделирование данных, но не моделирование сущностей. По этой причине часто проекты начинаются с проектирования, а не с формального анализа.
Большинство CASE-средств способны генерировать код, но могут создавать только очень "датацентрические" приложения. Например, если в репозитарии определена таблица заказов, то большинство таких средств сгенерируют маленькую сопровождающую программу, которая может запрашивать, вставлять, обновлять и удалять заказы. Некоторые CASE-средства могут даже генерировать простое приложение, способное сопровождать и заказы, и строки заказов. Идти дальше позволяют лишь немногие средства.
Эта критика в меньшей степени относится к пакету Oracle Designer/2000. Несмотря на название, он обеспечивает явную поддержку аналитической деятельности, которая должна предварять проектирование. Кроме того, этот продукт предназначался для обеспечения генерации кода и поэтому силен в определении модулей и создании перекрестных ссылок между модулями и атрибутами.
Оценивая возможность использования технологии CASE в своем проекте, обязательно определитесь с тем, как вы собираетесь ее применять:
• Хотите ли вы использовать ее просто как репозитарий определений данных?
• Хотите ли вы распространить ее и на хранение определений модулей?
• Хотите ли вы генерировать из определений модулей код?
Выбирая репозитарий, нужно ответить на следующие вопросы:
• Сколько приложений выполняют простые манипуляции с базой данных, а сколько — содержат сложную логику, которую нельзя сгенерировать?
• Какой объем рутинной работы можно реализовать с помощью шаблонов и библиотек кода?
• Какова вероятность того, что внесение изменений в схему можно будет облегчить, если аккуратно создать перекрестные ссылки в репозитарий или, что еще лучше, регенерировать код, который затронут этими изменениями?
• Используете ли вы методы ускоренной разработки приложений (УРП), и окажет ли генератор помощь в поэтапном макетировании?
Генераторы становятся все более и более мощными, и Oracle ставит целью обеспечить 100%-ную генерацию 100% кода в основных приложениях. Это великая цель, но в мире полной генерации достижение, например, уровня 99,95% означает полный провал (даже если это может оказаться исключительно полезным для запуска проекта). Oracle и ее конкуренты пока далеки от достижения показателя 100% — отчасти из-за крайней сложности получения соответствующей функциональным требованиям модели данных. Вернемся, однако, к реальности... Если вам требуется создать большое число простых модулей, то генератор вполне может сэкономить время и дать более согласованный код. Если же перед вами стоит задача создания небольшого числа сложных модулей, то генератор будет тормозом, поскольку первой работой при этом, несомненно, будет изъятие ненужного сгенерированного кода.
Тем не менее, генераторы сейчас применяются гораздо шире, чем раньше. В большинстве проектов, где используются генераторы, они служат для создания простых модулей сопровождения данных и выработки первых вариантов более сложных модулей. После внесения разработчиками исправлений в этот код он редко подвергается обратному преобразованию в репозитарий для последующей корректировки и регенерации.
К сведению
Вы, возможно, помните наш принцип — "работать умно, а не напряженно". Сражаться три месяца с генератором, чтобы заставить его сделать то, что он не хочет, а затем признать свое поражение — не очень умно если для написания модуля вручную понадобилось бы меньше трех недель!
Большинство из нас беспокоятся о том, что генераторы сделают с нашим кодом, и просто не доверяют им в достаточной степени!
Ответ на вопрос ценой $64000 о соединении CASE-средства с генератором, звучит так. Если можно установить, что генератор способен генерировать модули необходимой сложности, то будут ли затраты на ввод данных в репозитарий меньшими, чем затраты на создание этих же модулей с полной документацией традиционными методами?
* Один из авторов работает в подразделении PATROL Research and Development фирмы BMC Software, поэтому его мнение в этой области вполне можно считать предвзятым.
** См. "Database Fingerprinting" by Chris Johnson, Database Programming and Design, September 1995.
Знаете ли Вы, что класс, Class - Класс в программировании - это множество объектов, которые обладают одинаковой структурой, поведением и отношением с объектами из других классов.