Параллельная обработка в среде Oracle строится на двух продуктах: Oracle Parallel Query Option (PQO) и Oracle Parallel Server (OPS). Как мы увидим далее в этой главе, эти очень разные продукты предназначены для достижения одной и той же цели — задействовать для обслуживания текущей рабочей нагрузки все имеющиеся аппаратные средства. Хотя из-за схожести названий эти продукты иногда путают, в действительности они совершенно разные. Дополнительную путаницу в данный вопрос вносит еще и то, что Parallel Query Option может эксплуатировать Parallel Server, если последний имеется в наличии.
Что же делают эти продукты? Parallel Query Option стремится ускорить полное сканирование таблиц (и только полное сканирование таблиц), заставляя каждый из нескольких процессов выполнять часть этой работы. Это может оказаться выгодным даже на однопроцессорных машинах, а на машине с несколькими центральными процессорами и дисковыми контроллерами уменьшение времени выполнения запроса может быть просто потрясающим.
Oracle Parallel Server дает возможность отдельным экземплярам Oracle вместе использовать одну физическую базу данных. Такой подход позволяет Oracle поддерживать те аппаратные средства, в которых процессоры могут совместно использовать дисковые устройства (или читать и записывать данные на дисковые устройства, принадлежащие друг другу, в так называемых архитектурах shared nothing), но не могут совместно использовать оперативную память, в силу чего не могут одновременно обращаться к одним и тем же находящимся в оперативной памяти управляющим структурам.
Даже если не использовать ни один из этих продуктов, есть способы, при помощи которых можно (а в большинстве случаев и нужно) путем выполнения множества операций достичь хотя бы некоторой степени параллелизма в обработке. Замечательно то, что преимуществами параллелизма можно воспользоваться и без PQO и OPS, поскольку эти продукты, хотя и являются блестящими образцами техники программирования, дают реальную выгоду только в весьма специфических обстоятельствах.
Таким образом, многие рассматриваемые в этой главе подходы касаются сред с одним центральным процессором, а не только сред, где процессоров в избытке. Перед тем как изучать направления использования PQO и OPS, давайте очертим круг проблем, которые нам хотелось бы с их помощью решить.
Зачем нужен параллелизм?
Как правило, мы выполняем на сервере несколько процессов. Одни из них относятся к операционной системе (например, процесс, принимающий электронную почту), другие касаются работы базы данных (например, процесс записи в базу данных Oracle — DBWR), а третьи представляют собой пользовательские процессы, в которых интерпретируются и обрабатываются наши SQL-предложения.
Существует один жизненно важный процесс, который называется планировщиком и работает в двух весьма специфических обстоятельствах. В однопроцессорной машине планировщик вступает в игру, когда возникает одна из следующих ситуаций:
• процесс, использующий машину, решает передать управление — обычно потому, что ему требуется подождать ввода или вывода в той или иной форме;
• процесс, использующий машину, не передает управление, а пытается продолжать применять ее после истечения некоторого установленного срока. Период времени, в течение которого процессу разрешается работать, называется его квантом времени, а такая форма планирования изначально была известна как квантование времени.
Почти всем операциям обработки часто приходиться останавливаться и ждать ввода-вывода. При нормальной работе Oracle было бы очень странно, если даже такой процесс, как пакетный, использовал бы значительно больше, чем 50% ресурсов центрального процессора. Почему? Да потому, что остальное время он тратит на ожидание чтения блоков базы данных с диска и (в меньшей степени) на ожидание записи элементов журнала на диск.
Например, при выполнении центральным процессором такой операции, как показана в приведенном ниже предложении, процент использования процессора не превысит десяти, поскольку все больше и больше времени потребуется на ожидание чтения табличных блоков с диска.
SELECT sales_region, COUNT(*), SUM(order_value)
FROM orders
GROUP BY sales_region;
И это еще не все, потому что при наличие нескольких дисковых контроллеров существует возможность выполнять несколько операций с диском параллельно. Если мы распределим указанную в примере таблицу на несколько дисков (этот процесс, называемый стрипингом, описан ниже), то при помощи средства мониторинга (например, PATROL фирмы DМС) увидим, что центральный процессор практически простаивает, а все дисководы работают отнюдь не с полной нагрузкой. Без стрипинга (и при выполнении только одного запроса) вообще использовался бы только диск, содержащий таблицу, причем не на полную мощность, а процессор был бы задействован еще меньше. В этом случае центральный процессор и диск работают попеременно. Улучшить ситуацию поможет асинхронное чтение с упреждением, однако максимальная скорость, с которой центральный процессор сможет получать данные, будет ограничена возможностями одного диска.
Правило номер один "узкоместологии" гласит:
В любой момент времени: у системы исчерпываете только один ресурс.
Хотя это правило часто цитируется и принимается, оно не является абсолютно верным. Впрочем, его можно считать верным для всех нормальных действий по проектированию и настройке, потому что его следствия верны и полезны. Если у нас еще не исчерпался ни один ресурс, то мы могли бы использовать больше ресурсов и таким образом, укорить работу. Как только один ресурс исчерпываются, приходится сокращать уровень его потребления, чтобы опять-таки не сбавлять скорость.
Поскольку мы стремимся получать ответы на наши запросы как можно быстрее, то хотим иметь возможность довести эффективность работы или центрального процессора, или операций обмена с диском до максимальной. В приведенном выше примере мы почти наверняка достигнем предела возможностей системы ввода-вывода до того, как выйдем на предельную эффективность даже одного процессора. Тем не менее, при других запросах (особенно тех, в которых используются функции и есть сложные условия) иногда получается, что ресурсы нескольких процессоров истощаются, а предельная эффективность системы ввода-вывода еще не достигнута. И, конечно, динамика использования аппаратных ресурсов на протяжении цикла выполнения запроса не остается постоянной: Oracle традиционно обрабатывает такой запрос GROUP BY, как в приведенном примере, в три этапа:
1. Полное сканирование таблицы для получения значений.
2. Сортировка с целью группирования всех значений по каждому региону.
3. Агрегирование (фактически выполняется на заключительной фазе слияния этапа сортировки).
Если параметры настройки экземпляра позволяют выделить для сортировки большую рабочую область, то процесс из ограниченного скоростью ввода-вывода на этапе 1 может стать ограниченным возможностями процессора на этапах 2 и 3. Мы хотим организовать выполнение так, чтобы воспользоваться этой ситуацией.
Лишь недавно проектировщики были вынуждены обратить внимание на проблемы, вызванные недостаточной пропускной способностью ввода-вывода в Oracle, — за исключением очень больших систем, Oracle-приложения, применяющие параллельную обработку для максимально эффективного использования ресурсов, традиционно сталкивались с нехваткой ресурсов центрального процессора, а не системы ввода-вывода. Однако за последние несколько лет вследствие воздействия ряда важных факторов ситуация изменилась:
• процессоры стали работать значительно быстрее, а на серверах, как правило, используется больше процессоров, чем раньше;
• базы данных стали значительно более объемными, и для типичного запроса, предназначенного для генерации отчета или анализа, требуется больше операций ввода-вывода;
• диски стали значительно более емкими, что позволяет концентрировать больше операций ввода-вывода на одном устройстве;
• диски не стали работать значительно быстрее.
Подводя итог, скажем, что параллелизм необходим для того, чтобы, пока один процесс ожидает ввода-вывода, другой мог вступить в игру и начать использовать процессор или другой ресурс ввода-вывода. Нужен он и для того, чтобы одновременно задействовать не один, а несколько центральных процессоров и более одного устройства ввода-вывода. Для оптимальной работы одновременно должно работать столько процессов, сколько требуется для достижения предельного уровня загрузки устройства ввода-вывода или центрального процессора. Эмпирическое правило гласит: при оперативной обработке транзакций для этого требуется от четырех до восьми активных процессов на процессор.
Стрипинг
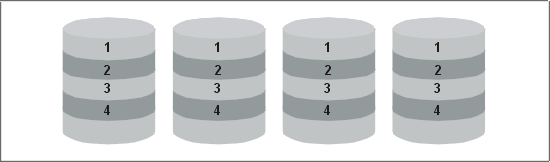
Стрипинг (striping) — это метод распределения данных по дискам. Допустим, что у нас есть четыре таблицы, каждая из которых расположена на отдельном выделенном диске, как показано на рис. 14.1. Представим, что наступил конец месяца и все начальники отделов отчаянно пытаются получить месячные результаты, а бухгалтеры, так же отчаянно, их проанализировать. Все эти данные хранятся в нашей базе данных в таблице 1, к которой производится большое число обращений. Настолько большое, что идет непрерывное соперничество за доступ к диску и пользовательские процессы стоят в очереди, ожидая освобождения диска. Ясно, что такой сценарий идеальным не назовешь!
Рис. 14.1. Четыре таблицы в традиционной конфигурации дисков
Как распределить операции ввода-вывода, чтобы не зависеть от частоты обращений к таблицам? Каждую из этих таблиц можно разместить на всех четырех дисках, как показано на рис. 14.2. Этот метод называют стрипингом.
Рис. 14.2. Те же четыре таблицы в конфигурации со стрипингом
При таком размещении не имеет значения, какая таблица "популярна" в данный момент времени — у нас есть хотя бы небольшой шанс распределить нагрузку ввода-вывода на несколько дисков. Естественно, что без таких специальных мер, как, например, использование Parallel Query Option, такое распределение таблиц будет выгодно только в плане использования центрального процессора и системы ввода-вывода в случае, когда наблюдаются одновременные обращения к таблице со стороны множества пользователей. С другой стороны, такое чередование можно было бы обеспечить, если организовать ряд "сырых" разделов в Unix (как показано на рис. 14.2), а затем создать с помощью команд CREATE TABLESPACE и ALTER TABLE-SPACE четыре табличных пространства, каждое из которых охватывает четыре физических устройства. Тогда каждая таблица может быть загружена в собственное табличное пространство. Для достижения хороших результатов важнейших эталонных тестов и тестов производительности настройщики даже постарались бы загружать каждую таблицу в заранее установленной последовательности, чтобы каждый процесс использовал "собственный" диск. Конечно, в реальных системах вряд ли существует такая идеальная схема загрузки. Метод стрипинга обладает одним известным недостатком: очень трудно управлять вставкой новых строк. В большинстве случаев все они будут размещены в текущем блоке (или блоках) таблицы и, возможно, будут иметь тенденцию размещаться на одном и том же физическом диске. В этом случае и в случае, когда интенсивность вставки в таблицу высока или чаще всего запрашиваются строки, которые вставлены последними, такой стрипинг окажется крайне неэффективным.
К счастью, операционные системы последнего поколения освобождают проектировщика от этих проблем. Во многих текущих версиях Unix есть менеджер логических томов, который позволяет системному администратору создавать логические диски, пользуясь всей совокупностью физических дисков. В большинстве случаев менеджер логических томов обеспечивает и стрипинг, распределяя блоки логического диска по физическим дискам так, что при случайной последовательности доступа к любым данным на этом логическом томе будет создаваться одинаковая нагрузка на каждый диск.
Существенная выгода от использования менеджера логических томов состоит в том, что он оперирует всеми файлами на дисках, а не только теми, которые содержат базу данных Oracle. Это ослабляет влияние других (не-Огacle) приложений на конкуренцию за право доступа к диску, а также может устранить узкие места при записи на диск файлов трассировки и отчетов.
С точки зрения проектировщика логический том можно представить так, как показано на рис. 14.3.
Рис. 14.3. Логический том
С этой моделью работать гораздо легче, чем делать стрипинг вручную, и во многих случаях она оказывается гораздо более эффективной. Мы не рекомендуем перекладывать задачи, связанные с организацией стрипинга вручную, на плечи системного администратора, за исключением случаев, когда общая пропускная способность ввода-вывода одного элемента становится проблемой, а в операционной системе нет возможности создания логических томов.
Технология
RAID, зеркальное копирование и производительность
Технология RAID (Redundant Arrays of Inexpensive Disks — избыточные массивы недорогих дисков) широко распространена как средство повышения целостности данных и производительности. Наш опыт работы с RAID показывает, что у этой технологии есть и преимущества, и недостатки.
Одна из особенностей таких массивов состоит в том, что RAID-контроллер реализует такие же "логические тома", как мы описывали ранее, однако преобразование в этом случае выполняется в контроллере, а операционной системе вовсе не обязательно знать о лежащей в их основе физической структуре.
RAID-контроллеры могут также использоваться для реализации зеркального копирования дисков — процесса, в котором каждая операция записи выполняется на двух отдельных дисках. Один из дисков в паре является зеркальным отражением другого, что снижает вероятность потери данных вследствие отказа дисковода. Когда сервер запрашивает блок данных на диске, его можно прочитать с любого из дисков, на которых он находится, благодаря чему уменьшается вероятность конфликта за право доступа к диску. Это — технология RAID 1.
Сторонники RAID также рекламируют достоинства технологии RAID 5, при которой блоки распределяются по специальному алгоритму на несколько дисков. Этот алгоритм обеспечивает возможность полного воссоздания записи в случае отказа одного из дисков. Такой механизм использует примерно на 40% меньше дисков, чем RAID 1, при той же номинальной емкости, сохраняя при этом способность выдерживать отказ диска без потери данных. Это хорошо.
Однако следует отметить, что для записи одного блока нужно задействовать пять дисков, а для чтения — четыре. В худшем случае мы можем уменьшить пропускную способность ввода-вывода примерно на 70%. Это плохо.
Наш вывод относительно технологии RAID таков: она может быть экономически выгодным способом создания внешней памяти. Но перед тем как использовать конфигурации, отличные от RAID 0 и RAID 1, следует тщательно проанализировать затраты и выгоды от внедрения этой технологии.
Проектирование с целью обеспечения параллелизма
Даже если приложение будет работать только на машине с одним центральным процессором и ограниченным числом дисков, все равно стоит посмотреть, можно ли увеличить производительность путем обеспечения параллелизма. В самом крайнем случае нужно проверить, обеспечит ли параллелизм повышение производительности приложения (а не поддержку ее на постоянном уровне) при модернизации аппаратных средств.
Вот очень приблизительное эмпирическое правило: для типичного приложения пакетной обработки или генерации отчетов, работающего автономно на сервере с процессорами средней производительности и быстродействующими дисками, мы рассчитывали бы получить не более чем следующие уровни использования ресурсов процессоров:
Количество процессов на процессор
Степень использования процессоров
1 2 3 свыше 3
<50% ~75% ~85% >90%
В десятипроцессорной системе один пакетный процесс будет использовать менее 50% ресурсов одного процессора, т.е. менее 5% общей мощности процессоров. Учитывая, что многие важные процессы в приложениях продолжают проектироваться как однопоточные пакетные задачи, мы видим, что использование параллельной обработки везде, где возможно, может дать значительные преимущества. Другими словами, вместо того чтобы заставлять один процесс использовать менее 50% ресурсов центрального процессора (который выполняет всю работу последовательно), мы рассчитывали бы на использование других центральных процессоров. Это позволит увеличить общую пропускную способность системы.
Создание и сопровождение индексов
Создание и сопровождение индексов — трудоемкие процессы, поэтому во многих организациях есть индексы, которые по соображениям производительности обычно удаляются, а в случае необходимости вновь создаются. Например, если большое пакетное задание собирается обновлять индексированный столбец каждой строки в таблице, насчитывающей миллион строк, но не использует этот индекс для запросов к таблице в пределах задания, то, конечно, лучше удалить индекс, прогнать пакетное задание, а затем пересоздать индекс.
А как быть, если требуется пересоздать три таких индекса для одной или нескольких таблиц? Если стрипинг таблиц организован при помощи менеджера логических томов, то почему бы не инициировать все операции пересоздания индексов параллельно? (Да, Oracle допускает построение одновременно нескольких индексов для одной таблицы, причем это возможно начиная с версии 6.)
Большинство системных администраторов и настройщиков не склонны делать это, боясь так называемого конфликта головок. Они считают, что при создании одного индекса таблица может сканироваться путем линейного перемещения головок диска, однако если одновременно выполняется несколько операций сканирования, то головки диска будут все время двигаться хаотично. Мы советуем попробовать применить этот метод на своих аппаратных средствах и со своими данными. Наш опыт почти всегда был положительным.
Если вы уже убедились, что параллельное построение индексов способствует повышению производительности, но все равно беспокоитесь о конфликте головок, придется построить модель более сложную, чем предполагает простое созерцание движения головок диска. В действительности при построении индексов чередуются фазы интенсивного ввода-вывода и фазы интенсивных вычислений. Потери от нерационального перемещения головок малы по сравнению с преимуществом, которое вы получите от того, что некоторые операции ввода-вывода будут выполняться в то время, когда первая задача, занимаясь вычислениями, оставит диск без работы.
Пакетная обработка
Пакетная обработка в приложениях Oracle традиционно задавалась и реализовывалась как один поток без учета того, необходима ли при этом определенная последовательность или нет. Как и при пересоздании индексов, самый простой способ организовать параллельную обработку — инициировать больше одного задания одновременно. Если говорить о shell-скрипте Unix, то для этого может понадобиться всего-навсего изменить скрипт с
Тем, кто не знаком с Unix, поясняем: символ "&" в конце строки команды обеспечивает асинхронное ее выполнение, а команда nohup делает затребованный процесс независимым от скрипта, который его запустил. Выполнение этого задания продолжится даже в том случае, если запустивший его пользователь выйдет из системы, не дождавшись завершения задания.
Если мы уверены, что между двумя этими задачами никакой зависимости нет, т.е. ни одна из них не запрашивает данные, которые могут изменяться другой задачей, то это абсолютно безопасная оптимизация. В зависимости от уровня конкуренции за право доступа к устройствам и центральным процессорам мы можем сэкономить время, приблизительно равное времени выполнения более короткого задания.
Однако если наш сервер представляет собой машину с симметричной многопроцессорной архитектурой и имеет, например, шесть процессоров, то для использования их возможностей нам необходимо как-то добиться того, чтобы параллельно работало гораздо больше, чем два процессора. Один из самых мощных приемов проектирования для достижения этой цели отказаться от концепции выполнения всего задания за один прогон и запускать одну и ту же программу много раз, заставляя каждый процесс выполнять часть задания. В организации, которая имеет четыре офиса и три склада, этот скрипт может быть приблизительно таким:
Если мы достаточно сообразительны, то на этом этапе начнем беспокоиться. Если добавится еще один офис или склад, то кто-то должен не забыть изменить скрипт, включив в него новый узел. Чтобы избежать этой проблемы, лучше организовать динамическое построение потока заданий:
rem must set define to avoid & being parsed be SGL*Plus
set echo off feedback off pagesize 0 define #
spool pick_list_print_init
SELECT 'nohup pick_list_print stores='
|| STORE_CODE
|| 'connect=scott/tiger &'
FROM stores;
!pick_list_print_init
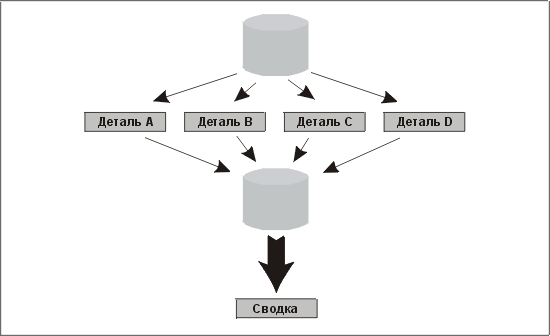
Реализовав на базе этого скрипта дополнительную управляющую логику, обеспечивающую обязательное выполнение необходимых прогонов, мы можем построить устойчивый управляемый данными механизм для выполнения практически любой задачи параллельно с самой собой. Даже в тех случаях, когда требуется завершающий этап подведения итогов, основной объем обработки выполняется параллельно, и вся операция осуществляется следующим образом:
• каждый из параллельных потоков вносит свой вклад в таблицу результатов;
• этап подведения итогов выполняется только после завершения предыдущей операции;
• на этапе подведения итогов строится сводка.
Этот процесс схематично изображен на рис. 14.4.
Рис. 14.4. Пакетная обработка параллельными потоками с процессом подведения итогов
Разбивка пакетного потока на параллельные процессы выгодна, когда имеется одна большая таблица, управляющая основным запросом. Разбивка может быть особенно эффективна, если в системе много центральных процессоров. Однако при ее использовании необходимо помнить следующее:
• Даже несмотря на то, что потоки можно организовать так, чтобы они обрабатывали разные сегменты данных, существует риск возникновения конкуренции за блокировку, например, в совместно используемой родительской строке с денормализованным столбцом, содержащим агрегированное значение.
• Если один из потоков столкнется с ошибкой и по какой-то причине откажет, то весь процесс придется считать потерпевшим неудачу, несмотря на то, что некоторые другие процессы, возможно, завершились и закончили обработку. Если пакетный поток разбивается на параллельные процессы, необходимо соблюдать осторожность при восстановлении и перезапуске.
• В этом случае довольно трудно добиться равномерного распределения нагрузки между потоками. В примере разбивка осуществлялась для офисов и складов, но она может быть очень неравномерной. В следующем разделе предлагается метод решения этой проблемы, однако для его реализации необходимы значительные затраты на разработку.
Повторим мысль, высказанную нами выше. Если распределить данные по нескольким дискам, к которым возможен одновременный доступ, то это увеличит скорость пакетной обработки независимо от того, какие ресурсы более важны для данной задачи: центрального процессора или системы ввода-вывода. Наша цель — задействовать как можно больше наличных ресурсов.
Анализ ситуации:
Oracle Payroll
Как мы упоминали в главе 5, первая редакция продукта Oracle Payroll работала под Oracle версии 6. Чтобы обеспечить необходимую степень специализации и гибкости, в этом продукте использовались анонимные блоки динамического PL/SQL, которые выполняли подробные расчеты заработной платы. Сказать, что этот подход изначально вызвал проблемы с производительностью — значит, сказать очень мало! Бета-тестировщики сообщали, что для расчета заработной платы требовалось до десяти секунд на одного сотрудника.
Исследования, проведенные группой, курирующей этот продукт, показали, что проблема отчасти состояла в синтаксическом анализе анонимных блоков PL/SQL. Они пришли к выводу, что эту проблему можно частично разрешить путем реализации большого кэша для курсоров. Тем не менее, было очевидно, что интерпретатор PL/SQL версии 1 при выполнении расчетов просто потребляет очень много ресурсов центрального процессора. Группа также отметила, что все заказчики бета-версии работали с аппаратными средствами Sequent, причем у каждого было минимум четыре процессора. Учитывая все это, было принято решение о параллельном выполнении процесса расчета.
Группа исследовала разную тактику, но в конечном итоге остановилась на динамическом распределении. Предварительное распределение сотрудников по конкретным процессам не имело смысла по двум причинам. Во-первых, для разных сотрудников могли понадобиться очень разные объемы операций обработки; во-вторых, существовала реальная опасность того, что одному процессу будут назначены все "трудные случаи" и он завершится через несколько часов после других. Эти опасения можно понять, если подумать о различиях в расчетах заработной платы следующих категорий работников:
• клерка, который отработал стандартный месяц и не платит ни местный, ни государственный подоходный налог;
• продавца, структура комиссионных у которого на протяжении месяца изменялась, который платит и местный, и государственный налог и у которого старая и новая схемы комиссионных предусматривают разные ставки по разным категориям товаров с дополнительным вознаграждением за выполнение плановых показателей.
Архитектура процесса, к которой в конечном итоге пришла вышеупомянутая группа, позволяла запускать любое число процессов расчета зарплаты. Каждый процесс производил вызов "распределителя", который устанавливал эксклюзивную блокировку на таблице распределения, выделял этому процессу 20 сотрудников, затем регистрировал выделение, завершал работу и возвращал управление процессу расчета. После расчета зарплаты этих 20 сотрудников процесс вновь вызывал распределитель и продолжал так работать до тех пор, пока распределитель не сообщал, что больше сотрудников нет. На этом этапе процесс вставлял итоговые данные в базу данных и завершался.
Естественно, процессы расчета зарплаты вполне могли столкнуться с конкуренцией на этапе распределения сотрудников, но такая блокировка обычно действовала в течение всего 10% общего времени и конкуренция за эту блокировку была незначительной. Параллельный расчет заработной платы сразу же принес успешные результаты — производительность возросла на порядок.
Но, к сожалению, была и ложка дегтя в бочке меда. Очень часто процесс расчета зарплаты неожиданно останавливался с весьма неприятным сообщением:
ORA-00060 :deadlock detected while waiting for resource
("при ожидании ресурса обнаружена взаимная блокировка")
Распределитель тратил много времени на определение того, как случилось, что он выделил одного и того же сотрудника более чем одному процессу расчета. Через несколько недель в группе поняли, что эти взаимоблокировки вызваны внутренними проблемами Oracle. Нужно было лишь выдать ROLLBACK, несколько секунд подождать, а затем повторить попытку. Этот прием обработки взаимоблокировок был хорошо известен членам группы, но они не стали утруждать себя его реализацией, поскольку убедили себя, что взаимоблокировка не возникнет. Это все равно что ехать на мотоцикле без шлема, убедив себя в том, что в аварию вы не попадете!
К сведению
Взаимоблокировки такого типа встречаются очень редко и имеют место лишь в случае, когда несколько процессов пытаются одновременно осуществить блокировку на уровне строк в одном и том же блоке. Наступает момент, когда Oracle не хватает места, для того чтобы записывать, кому принадлежит блокировка, и СУБД ожидает, пока один из других процессов не выполнит фиксацию или откат транзакции. Если вам очень не повезет, система выберет процесс, который уже ожидает одну из ваших блокировок, в результате чего возникнет взаимоблокировка.
Мы не говорим, что существует какой-то предел общего числа блокировок уровня строки (этот предел равен числу строк в распределенной базе данных). Мы говорим лишь, что существует ограничение на число разных процессов, которые могут одновременно удерживать блокировки в одном блоке. Это число зависит от объема свободного пространства в блоке и всегда больше или равно значению параметра INITRANS для данного объекта.
Эта проблема редко, но встречается, поэтому мы рекомендуем учитывать взаимоблокировки на всех этапах проектирования программ.
Parallel Query Option (PQO)
Parallel Query Option — это продукт, который может ускорить полное сканирование таблиц и связанную с ним обработку, разбивая сканирование на фрагменты и распределяя эти фрагменты между элементами пула процессов. PQO впервые появился в Oracle версии 7.1. Как и распределитель описанный в предыдущем разделе, последние версииPQO выполняют такое распределение динамически. Кроме того, процессам в пуле выделяются разные объемы работы. Это делается для уменьшения вероятности того, что несколько процессов одновременно попросят дополнительную работу.
Достоинства и недостатки
PQO
Давайте рассмотрим следующий запрос:
SELECT region_name
, count(*)
FROM customers
WHERE industry_code = 'HW'
GROUP BY region_name;
Если при помощи этого предложения выбирается, например, 5% строк таблицы и для этого требуется посетить 4% ее блоков, то может оказаться, что этот запрос можно быстрее выполнить с помощью PQO, чем с помощью индекса. Однако уменьшение времени выполнения имеет свою цену: запрос займет все ресурсы системы ввода-вывода или центрального процессора. Это приемлемо, если на машине работает один пользователь, но если там работают 50 пользователей, вводящих заказы, то они будут ждать возможности ввода, пока выполняется запрос.
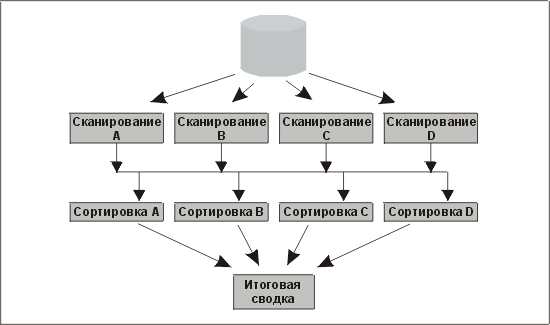
PQO идет дальше, чем распределитель в Oracle Payroll, — он берет запрос, подобный приведенному выше, и распараллеливает как выполнение сбора данных (полное сканирование таблицы), так и сортировку. PQO совмещает их так, что сортировка начинается, когда сканирование еще не окончено. Окончательное слияние результатов при сортировке выполняется на однопоточной фазе подведения итогов. Как мы говорили ранее, она необходима в случае, когда распараллеленный процесс должен выдать итоговый результат. Эта схема изображена на рис. 14.5.
Рис. 14.5. Схема работы Parallel Query Option
Каков результат всех этих операций? Мы не только можем задействовать все средства стрипинга, которые нам удалось применить к этой таблице, но и выполнить большую часть операций сортировки, не прекращая работу с данными.
Слово "query" (запрос) в названии этого продукта несколько обманчиво — одним из важных направлений использования PQO является обеспечение гораздо более быстрого построения индексов, чем с помощью традиционного полного сканирования таблицы. Как говорилось выше, при обычном сканировании работа привязана то к возможностям системы ввода-вывода, то к возможностям центрального процессора (в однопроцессорной машине).
PQO отлично справляется с задачей координации деятельности системы ввода-вывода и ЦП, а также позволяет задействовать несколько ЦП.
Если вы дочитали книгу до этого места, то должны были заметить, что мы никогда не заходим далеко в своих рекомендациях по поводу использования того или иного средства, не сделав необходимых предостережений и не разъяснив его недостатки. Наше первое предостережение состоит в том, что слово "option" (опция) в названии продукта не вводит в заблуждение. На текущий момент с PQO связаны значительные дополнительные затраты. Перед тем как делать вывод о том, что это средство решит все ваши проблемы производительности при обработке запросов, вы должны учесть следующее:
• PQO работает только при полном сканировании таблиц; большинство запросов (особенно те, которые используются в оперативной обработке) лучше всего выполняется с помощью индекса.
• PQO предназначен для "пожирания" ресурсов. Не забывайте об ограничениях механизма планирования Unix и учтите, что один пользователь PQO может фактически загрузить весь сервер.
• PQO может оказаться неудобным в установке и настройке. Например, его управляющий механизм не может воспринять инструкцию следующего типа: "Моя машина лучше всего работает с 20 серверами запросов, поэтому если выполняется только один параллельный запрос, выделите ему 20 серверов; при появлении других пользователей заберите процессы у первого пользователя и выделите каждому пользователю приблизительно равное число серверов — максимум пять параллельных запросов одновременно".
Где устанавливать степень параллелизма?
В текущей реализации Parallel Query Option требуется, чтобы прикладной процесс, выдающий запрос, запрашивал конкретное число параллельных потоков (через параметр PARALLEL). К сожалению, это вызывает необходимость встраивать важный настроечный параметр в код приложения. Приложение, выдающее запрос, вполне может определить, годится операция для использования параллельного сканирования или нет. Однако при выборе числа потоков (степени параллелизма) необходимо учесть ряд факторов, которые на момент написания запроса могут быть неизвестны и которые могут даже не входить в круг интересов автора запроса. К этим факторам относятся:
• характеристики аппаратных средств, на которых выполняется запрос, в частности:
— количество центральных процессоров;
— количество контроллеров ввода-вывода;
— количество дисков;
• степень стрипинга объектов;
• наличие другой нагрузки на машину.
В общем случае мы рекомендуем, чтобы фраза PARALLEL и подсказка оптимизатору PARALLEL не устанавливали ни степень параллелизма, ни число экземпляров. Вот рекомендуемые формы:
CREATE TABLE new_history
TABLESPACE temp
PARALLEL (DEGREE DEFAULT)
AS SELECT *
FROM history h
WHERE h.entry_date > SYSDATE - 730
OR h.active = 'Y'
OR h.type = 'SECURE'
SELECT /*+ FULL(H) PARALLEL (H, DEFAULT, DEFAULT) /
h.type
, count ()
FROM history h
WHERE h.active = 'Y'
GROUP BY h.type
GROUP BY 2 DESC;
Возможное исключение — использование INSTANCES 1 для предотвращения экспортирования операции на другие серверы в среде Oracle Parallel Server. Это особенно рекомендуется в тех случаях, когда вы строите индексы на сервере, зарезервированном для запросов ИУС или ИСР. Это значение можно свободно установить как параметр по умолчанию, например в файле INIT.ORA. Кроме того, можно установить степень параллелизма выше обычной инсталляционной для запросов и операций построения индексов, если их планируется выполнять на машине, которая в противном случае была бы недогруженной. Действительно, оператор CREATE TABLE вполне может быть первым этапом реорганизации таблицы в кластерной среде — в среде, где мы считаем, что для создания таблицы могут использоваться все ресурсы локального сервера, но экспортировать части запроса на другие серверы не допускается. При наличии в локальном сервере четырех процессоров, возможно, будет более предпочтительным следующее приложение:
CREATE TABLE new_history
TABLESPACE temp
PARALLEL (DEGREE 20 INSTENCES 1)
AS SELECT *
FROM history h
WHERE h.entry_date > SYSDATE - 730
OR h.active = 'Y'
OR h.type = 'SECURE'
PQO:
выводы
Мы считаем, что Parallel Query Option лучше всего использовать для создания индексов и выполнения итоговых запросов, при которых необходимо посещать значительную часть большой (или очень большой) таблицы (по причине отсутствия подходящего индекса или из-за того, что процессом охвачена значительная часть строк таблицы). Несмотря на то, что указать, как данный экземпляр должен выполнять распределение на сервере, сложно, PQO — очень разумная программная технология. В среде, где много центральных процессоров и каналов ввода-вывода, этот продукт дает проектировщику возможность просканировать и рассортировать большие объемы данных за гораздо меньшее время, чем при традиционном методе оптимизации запросов.
Oracle Parallel Server (OPS)
Как мы упоминали, Oracle Parallel Server — это совершенно самостоятельный продукт, не связанный с Parallel Query Option. Parallel Server позволяет нескольким отдельным экземплярам Oracle совместно использовать одну базу данных.
Симметричные многопроцессорные системы (СМП-системы)
Производители аппаратных средств разработали ряд архитектур, которые предназначены для создания более мощных машин из компонентов, выпускаемых в массовых количествах. Здесь имеет место определенный стоимостной императив. Всегда существуют процессоры с определенным быстродействием, которые предназначены для ПК и рабочих станций и изготавливаются в очень больших объемах. Из-за больших объемов выпуска цена таких процессоров невелика. Производство микросхемы с быстродействием в 10 раз выше может стоить в 10000 раз больше, а то и вообще оказаться невозможным при существующем уровне технологии. Поэтому путь к созданию очень мощных и в то же время относительно дешевых машин пролегает через обеспечение Параллельной работы множества дешевых процессоров.
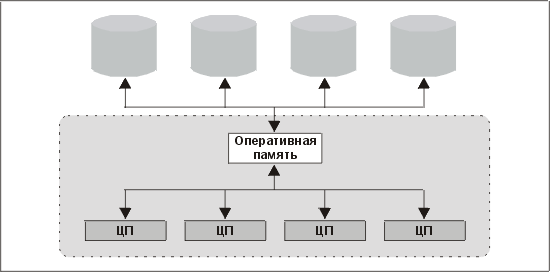
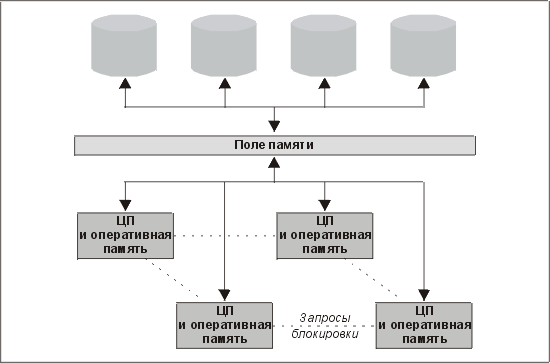
В симметричной многопроцессорной архитектуре несколько процессоров совместно используют шину памяти. Типичная конфигурация СМП-системы показана на рис. 14.6.
Рис. 14.6. Конфигурация СМП-системы
К сожалению, по мере увеличения числа процессоров в многопроцессорных системах начинает сказываться влияние конкуренции за доступ к шине памяти. Ситуация осложняется работой Oracle Server, который интенсивно использует системную глобальную область (SGA) в разделяемой памяти, что минимизирует влияние кэшей памяти на процессорном уровне. В некоторый момент (который для каждой архитектуры наступает в разное время) подключение новых процессоров становится неэффективным. Что тогда? Следующий способ наращивания общей вычислительной мощи без применения более быстродействующих процессоров — кластеризация нескольких узлов, которые, в свою очередь, могут быть СМП-машинами. Эта структура показана на рис. 14.7.
Рис. 14.7. Конфигурация кластера
Кластер, показанный на рис. 14.7, состоит из двух СМП-машин. Для простоты мы предположили, что каждая из них содержит одинаковое число процессоров и имеет доступ ко всем дисководам. Ни одна из этих характеристик не является обязательной и даже обычной. Когда две отдельные машины совместно используют диски, говорят, что они слабосвязанные. Если центральные процессоры совместно используют оперативную память (как два ЦП в машине B на рис. 14.7), то говорят, что они сильносвязанные. Если конфигурация состоит из комбинации сильносвязанных и слабосвязанных систем, ее часто называют гибридной.
Главная особенность данной конфигурации состоит в том, что здесь отсутствуют ячейки памяти, которые может "видеть" каждый процессор. По этой причине невозможно выполнять традиционный экземпляр Oracle одновременно на всех процессорах. Экземпляр базы данных, работающий в стандартном режиме Oracle, может работать на узле A или на узле В, но не на обоих узлах одновременно. Пунктирная линия, соединяющая процессоры, является частью локальной вычислительной сети (ЛВС), о роли которой мы поговорим позже.
Oracle Parallel Server позволяет экземплярам, работающим на отдельных узлах кластера, совместно использовать базу данных. О таких экземплярах говорят, что они работают в режиме разделения (shared mode). Сложность здесь заключается в том, что необходимо сделать так, чтобы процесс, просматривающий разделяемую область памяти Oracle (SGA) на одном узле, видел обновленную картину и знал обо всех соответствующих изменениях, сделанных в памяти на другом узле. Для достижения этой цели два (или более) экземпляра используют менеджер распределенных блокировок (Distributed Lock Manager, DLM). Этот менеджер, как правило, сигнализирует о запросах блокировок по локальной сети, которая обычно строится по технологии коммутируемых Ethernet-соединений.
Самый простейший случай выглядит так. Каждый раз, когда экземпляр хочет обратиться к чему-то, что находится в памяти и может быть изменено другим экземпляром, он устанавливает на этот ресурс разделяемую блокировку (share lock). Если экземпляр хочет изменить область в памяти, например блок базы данных в буферном пуле, он устанавливает эксклюзивную блокировку (exclusive lock). Если один экземпляр узнает, что другой экземпляр хочет установить блокировку на буфер базы данных, который был изменен первым экземпляром, то делается следующее. Экземпляр, изменивший блок, должен записать блок на диск и снять установленную им эксклюзивную блокировку. Эта процедура называется пингингом (pinging). Одна из главных особенностей Oracle Parallel Server с точки зрения проектирования состоит в том, что распределенные блокировки совершенно не зависят от транзакций и границ транзакций. Они принадлежат экземпляру, а не транзакции.
Впервые встречаясь с Parallel Server, большинство пользователей интуитивно предполагают, что пингинг может вызвать конкуренцию между экземплярами. В частности, они начинают беспокоиться по поводу объема дисковых операций при перемещении блоков из одного экземпляра в другой. К несчастью, эту проблему вряд ли можно назвать самой серьезной из тех, которые встречаются при работе с Parallel Server. Действительной проблемой является то, что каждый раз, когда экземпляр намеревается что-то просмотреть или изменить, он должен обеспечить правильную распределенную блокировку. Одно только это означает, что в режиме разделения экземпляр работает, как правило, приблизительно на 10% медленнее, чем в обычном режиме. Кроме того, если необходимая экземпляру блокировка отсутствует, он должен по локальной сети дать сигнал всем остальным экземплярам, а они должны ответить. Поэтому даже при отсутствии операций обмена с диском создается достаточно интенсивный сетевой трафик, связанный с распределенными блокировками. Однако, как мы видели в главах 11 и 12, существуют весьма реальные пределы скорости, с которой узел может передавать и принимать сообщения по сети Ethernet.
У OPS есть ряд проектных особенностей, которые позволяют уменьшить число блоков, которые необходимо передавать между экземплярами. В частности, таблицы могут иметь несколько наборов списков свободных блоков, называемых группами списков свободных блоков. Если каждый экземпляр пользуется собственной группой списков свободных блоков, то сводится к минимуму конкуренция как за список, так и за текущий блок для вставки. Кроме того, администратор БД может организовать блоки базы данных в группы по файлам данных. Это позволяет уменьшить число распределенных блокировок за счет того, что одной блокировкой охватывается группа блоков. Охват всех справочных таблиц одной блокировкой — широко распространенный прием. Если каждый экземпляр установит разделяемую блокировку на справочных данных, то все экземпляры смогут кэшировать эти данные в памяти без каких-либо дополнительных операций по блокированию. Конечно, если при этом кто-нибудь попытается обновить строку в справочных таблицах, всем остальным узлам придется отказаться от кэшированных ими справочных таблиц.
Серьезную проблему могут вызвать последовательности, поэтому мы рекомендуем быть внимательными при кэшировании последовательностей (значение параметра CACHE должно быть достаточно велико хотя бы для пятиминутной работы в периоды максимальной нагрузки) и все последовательности, используемые в пределах всего кластера, задавать как NOORDER. Более удачное решение — сделать так, чтобы на каждую последовательность ссылался только один экземпляр.
Еще одна проблема, которая обрекает многие OPS-системы на неудачу, связана с сопровождением индексов. К сожалению, при внесении изменения в индекс экземпляру Oracle может понадобиться выполнить пингинг для блока-ветви индекса. Эта процедура делает недействительными принадлежащие экземплярам копии всех блоков, находящихся ниже этой ветви в дереве индекса. Следовательно, в обычном кластере мы не можем позволить себе иметь один и тот же индекс, поддерживаемый более чем одним экземпляром. Если нарушить это правило, может получиться, что производительность системы с двумя узлами будет меньше, чем производительность той же системы с одним узлом. Все очень просто.
Как проектировщик, вы должны взять на себя ответственность за обеспечение распределения работы между узлами кластера. Мы не говорим, что другие узлы вообще не могут поддерживать индекс, который обычно сопровождается конкретным экземпляром, а подчеркиваем, что если они будут делать это очень часто, то результат будет катастрофическим. Для того чтобы определить значение выражения "очень часто" для конкретных аппаратных средств, нужны тесты, но вывод, скорее всего, будет таким: блокировку не следует передавать чаще двух-трех раз в секунду. Однако лучше, если она вообще не передается.
Как же спроектировать систему, чтобы не нарушить это ограничение и пользоваться возможностями ЦП кластера?
1. Приложите максимум усилий для распределения рабочей нагрузки. При необходимости выполните горизонтальное секционирование таблиц, в которые осуществляется ввод данных, и периодически их объединяйте.
2. Попробуйте воздействовать на пользователей, разъясните им, что кластеры и Oracle Parallel Server — не волшебство, а просто умная технология, которая старается работать как можно лучше в несовершенном мире.
Системы с массовым параллелизмом: попытка изменить правила
Системы с массовым параллелизмом (СМП) всегда кажутся технологией завтрашнего дня. Несмотря на миллиарды долларов, вложенные (по мнению некоторых — выброшенные) в попытки приблизить эту технологию к уровню коммерческой приемлемости, большим числом находящихся в эксплуатации СМП пока похвастаться нельзя. Хотя стандартов в мире СМП нет, в их архитектуре и методах построения проявляется ряд четких тенденций. Мир СМП также узнает, что скалярный мир (мы с вами) не готов переписывать каждую написанную строчку кода лишь для того, чтобы работать на машине с 8192 процессорами (и 64 Мбайт памяти на каждый процессор), размещенными в коробке почти такого же размера, как микроволновая печь (и почти такой же горячей на ощупь!).
Поскольку в ближайшем будущем вряд ли многие из вас столкнутся с необходимостью проектировать приложения для СМП, мы просто заметим, что СМП-архитектуры, помимо колоссального шума в расчете на каждый вложенный доллар, создают определенные выгоды для OPS:
• СМП, вообще говоря, рассчитаны на эффективную обработку распределенных блокировок. Для обработки блокировок здесь применяются более сложные способы, чем простое соединение каждого ЦП со всеми остальными ЦП, однако простые локальные сети там, конечно, не используются. Мы встречали заявления о скорости операций свыше 20000 операций блокировки в секунду — тогда как для типичного кластера эта скорость ограничена несколькими сотнями. С другой стороны, мы видели опытный образец СМП, который справлялся менее чем с сотней операций блокировки в секунду!
• СМП часто допускают пересылку данных из оперативной памяти одного процессора в оперативную память другого. В некоторых СМП-архитектурах лишь ограниченное число процессоров имеют доступ к дискам, поэтому операции "память-память" существенно необходимы для того, чтобы процессоры-исполнители могли выполнять ввод-вывод. Как мы уже говорили, архитектуры, где нет разделяемой памяти и разделяемых дисков, обычно называют архитектурами shared nothing.
• Мы видим все больше и больше машин с архитектурой NUMA (Non-Uniform Memory Architecture), позволяющих держать большие кэши в поле памяти, которое находится между оперативной памятью, расположенной на процессорной плате, и дисками. Простая машина с такой архитектурой схематично показана на рис. 14.8.
Рис. 14.8. Простая конфигурация с архитектурой NUMA
Некоторые мечтатели (в том числе Ларри Эллисон, основатель и руководитель Oracle Corporation) полагают, что при такой архитектуре дискам можно поручить роль резервных носителей. Однако для большинства приложений полностью резидентные базы данных являются пока еще чем-то недоступным.
Как только СМП начнут поддерживаться крупными приложениями, правила проектирования и реализации высокопроизводительных систем наверняка изменятся. Если же СМП сделают возможным создание больших резидентных баз данных, то наши нынешние принципы проектирования потребуют еще более фундаментального пересмотра.
А вот в проектировании систем оперативной обработки транзакций радикальные изменения могут и не потребоваться. Действительно, СМП-архитектура (вероятно, с 256 процессорами, а не с четырьмя, как показано на рис. 14.8) лучше, чем современные аппаратные средства, способна справиться с традиционным подходом "одно соединение на пользователя", который господствует сегодня в приложениях Огас1е и предполагается многими (если не большинством) высокопроизводительными средствами разработки приложений.
Главная проблема — найти способ распределения работы нескольких процессов между достаточным количеством процессоров, чтобы полностью задействовать все наличные вычислительные ресурсы. Такие алгоритмы сами по себе не обязательно должны быть эффективными. Если в традиционной стратегии реализации отчета или пакетного обновления используется лишь один из пусть даже четырех процессоров, то система, в которой имеется на 100% больше ЦП, но могут быть одновременно задействованы четыре процессора, должна позволять выполнить задачу в два раза быстрее. Возможно, это не очень понятно, но это так.
OPS
: выводы
Oracle Parallel Server — увлекательная технология, но она подходит не для всех случаев. Если структура приложения не позволяет держать под контролем эффекты пингинга (как правило, путем распределения нагрузки, связанной с обновлением, по узлам кластера), OPS использовать не рекомендуется. В архитектурах с массовым параллелизмом Oracle Parallel Server необходим для разделения данных, и эффективное распределение рабочей нагрузки здесь вряд ли возможно. Следовательно, неизбежна высокая интенсивность пингинга. В такой системе должен присутствовать как менеджер распределенных блокировок, так и механизм межпроцессорной пересылки блоков, достаточно быстрые для того, чтобы справиться с этим графиком. Если наличие этих средств не предусмотрено, то это решение использовать не следует.
Знаете ли Вы, что технология программирования, Инжиниринг ПО, Software engineering - это дисциплина, изучающая технологические процессы программирования и порядок их прохождения. (см. онлайн-курс "Технология программирования")