В этой главе описаны факторы, которые необходимо учитывать при проектировании хранилищ данных на основе базы данных Oracle. Мы узнаем, почему хранилища данных стали столь популярными в последние годы, и разберем конкретные вопросы проектирования хранилищ данных — некоторые из них ставят под сомнение многие глубоко укоренившиеся принципы реляционного проектирования. Кроме того, мы изучим, какие особенности отличают хранилища данных от систем оперативной обработки транзакций (ООТ). Наконец, мы изложим методику загрузки данных в хранилище и извлечения данных из него.
Почему хранилища данных?
Хранилища данных — одна из самых актуальных тем в современной индустрии информационных технологий. Как и в случае с другими актуальными темами, поставщики стараются не отстать от моды и предлагают решения проблем, о существовании которых несколько лет назад мы даже не подозревали! Что это — массовая истерия? Или все-таки все разговоры о хранилищах данных имеют под собой реальную почву? Читайте и делайте собственные выводы.
Чтобы вы лучше поняли, откуда возникли хранилища данных, необходимо очень кратко изложить историю вычислительной техники. Когда авторы начали свою карьеру в этой области, королем был мэйнфрейм, приложения писались на языке ассемблера "настоящими" программистами и постоянно существовал огромный объем незавершенной работы. В 80-х годах мини-ЭВМ доросла до того уровня, когда она смогла бросить вызов мэйнфрейму и низвергнуть его с престола. Новый король породил технологию вычислений масштаба подразделения или рабочей группы, в рамках которой разрабатывались приложения, ориентированные на конкретную бизнес-функцию. Эти приложения могли работать в блаженной изоляции от окружающего мира (правда, время от времени они — с большой неохотой — все-таки общались со "старой технологией"). Даже организации, которые оставались верны централизованному мэйнфрейму (например, крупные авиакомпании), в полной изоляции друг от друга начали разрабатывать собственные комплекты приложений.
Вот здесь и стали возникать проблемы. Многие организации пришли к тому, что у них существует масса несовместимых файлов и таблиц с данными о клиентах, ни одна из которых не содержит полную информацию и не синхронизирована с другими. Каждая версия данных принимается кодом конкретного приложения как верная (даже если у пользователей есть сомнения). В результате, например, одни продавцы программного обеспечения просто не в состоянии выдать полный список своих клиентов, а другие компании могут сделать это лишь путем составления нескольких отчетов и последующего их объединения. Если подобная ситуация вам знакома, то, вероятно, вам также необходимо хранилище данных.
Однако вернемся к нашему уроку истории. На смену мини-ЭВМ пришел вездесущий ПК. В равной степени важным был значительный прорыв в сетевой технологии, что привело к распространению глобальных и локальных сетей. Интероперабельность стала важным фактором. Приложения, которые были написаны с помощью разных инструментальных средств для различных баз данных (а может быть, и для разных платформ), теперь могли совместно использовать данные и (или) обмениваться ими. Между островками данных внезапно появились мосты. Был достигнут прогресс и в технологии запоминающих устройств, в результате чего сильно упала стоимость хранения старых и избыточных данных. Цены на быстродействующие многопроцессорные серверы также стали доступными. Сочетание таких серверных архитектур с интеллектуальным ПО баз данных позволило реализовать поддержку сложных запросов к очень большим базам данных.
В идеале, конечно, можно попробовать переписать многое из унаследованного ПО для мини-ЭВМ и мэйнфреймов, чтобы пользоваться новейшими технологиями, такими как клиент/сервер и распределенные базы данных. Попутно при этом можно очистить данные и усовершенствовать их структуру. К сожалению, для большинства организаций это практически нереализуемо. Поэтому многие считают, что несмотря на то, что некоторые существующие системы и не являются высокотехнологичными, они делают свою работу и незачем тратить деньги на их переработку.
Примечание
Вообще-то, существует достаточно веская причина для того, чтобы переделать старые системы, — это грядущее наступление следующего тысячелетия и все проблемы, связанные с тем, как компьютерные системы будут интерпретировать данные в следующем столетии. Этот вопрос рассматривается в приложении Б.
Отсутствие интегрированных и непротиворечивых данных — не единственная проблема, стоящая перед пользователями и руководителями. Многие системы, которые проектировались с использованием традиционных методов и приемов, недостаточно хорошо оптимизированы для выполнения запросов к данным. В частности, нерегламентированные запросы, возможность появления которых не учтена при проектировании, могут выполняться плохо или не выполняться вовсе. Так, на обработку предложений GROUP BY, обобщающих данные, может потребоваться масса процессорного времени и большое число обращений к дискам. Современным руководителям необходимы системы, которые помогут им принимать стратегические решения. Им нужна возможность просмотра данных под самыми разными углами и во множестве измерений. Для достижения этой цели требуется не просто умный инструмент для запросов — нужны данные в формате, который оптимизирован под конкретную задачу.
Традиционные методы моделирования данных рассчитаны на достижение высокой производительности в системах ООТ. Если обратиться на узел, спроектированный таким способом, и попытаться найти ответ на вопрос о том, насколько рентабельно работала данная организация на Среднем Западе в прошлом году, то, вероятно, придется помучиться. Во-первых, понадобится профессионал в области ИУС (хорошо разбирающийся в структурах данных и сложных взаимосвязях между ними), который сконструирует запрос. Затем обнаружится, что запрос предполагает соединение огромного числа таблиц и содержит множество сложных условий в предложении WHERE. В результате запрос начинает бегать, как медведь в сиропе! Хуже того, этому медведю приходится делиться и без того небольшим количеством меда (ресурсами центрального процессора и системы ввода-вывода) с интерактивными пользователями.
Что такое хранилище данных?
Хранилище данных — прекрасный способ решения проблем, описанных в предыдущем разделе. Можно считать, что хранилище данных расположено в центре всех ориентированных на приложения систем организации. Хранилище регулярно получает данные из этих систем и формирует сводное представление. Данные могут быть простой копией транзакционных данных (в этом случае их называют атомарными) или же подвергаться на пути от источника к пункту назначения (хранилищу) трансформации либо агрегированию. При этом в хранилище может помещаться только какое-то их подмножество, или же данные могут подвергаться конвертированию для того, чтобы обеспечить их совместимость с данными из других источников. Для обозначения процесса отсечения и извлечения данных обычно используются термины расслоение (slicing) и расщепление (dicing). Внутренняя структура хранилища данных построена так, чтобы запросы можно было легко создавать и эффективно выполнять. О том, как это достигается, мы поговорим ниже.
Почти для всех успешно работающих приложений хранилищ данных используются выделенные серверы. Благодаря этим серверам "запросы из ада" (типичные для хранилищ данных) влияют только на пользователей информационного сервиса и не замедляют критичные по времени операции.
Выше мы говорили о необходимости наличия мощных инструментальных средств, при помощи которых пользователи, не сведущие в языке SQL, смогут создавать запросы и выполнять многомерный анализ данных (главным образом анализ возможных ситуаций). Должна быть обеспечена возможность постановки таких, например, запросов: "Как изменится объем продаж, если наш главный конкурент уйдет с рынка?" Для формирования таких прогнозов и содействия пользователям в поиске в базе данных с последующей детализацией разработано новое поколение инструментальных средств, ориентированных на конечных пользователей и известных как средства оперативной аналитической обработки данных (OLAP-средства). Однако следует знать, что OLAP-средства Oracle, входящие в версии 7.3 в состав Universal Server, не используют механизм реляционной базы данных Oracle напрямую. (См. дополнительную информацию в заключительном разделе этой главы.)
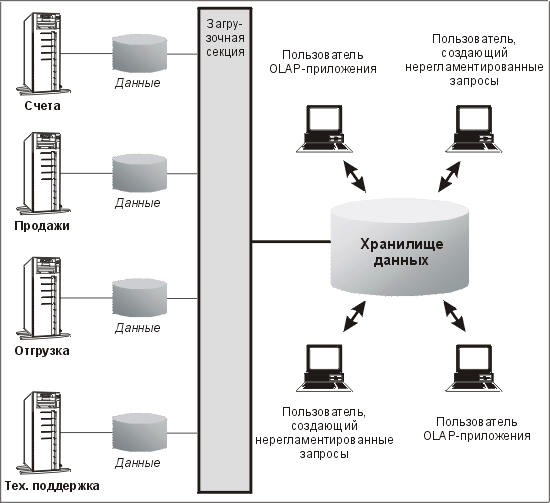
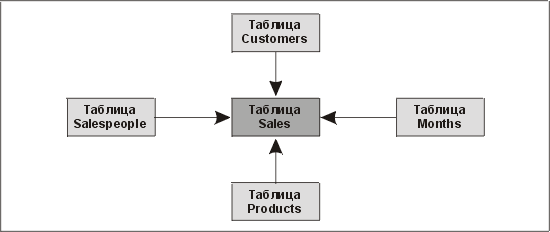
Наше определение хранилища данных иллюстрируется примером на рис. 13.1. Как видите, систем-источников данных у нас много, причем разных; данные переносятся из них в загрузочную секцию, оттуда они поступают на трансформацию и интеграцию, а затем загружаются в хранилище. Попав в хранилище, данные становятся доступными пользователям, выполняющим исследование данных с помощью OLAP-приложений.
Загрузочная секция на рис. 13.1 представляет собой логический объект, при помощи которого обозначено место, где входящие данные содержатся в необработанном формате до передачи их в хранилище. Данные загрузочной секции физически могут храниться отдельно как двумерные ASCII-файлы или в базе данных в виде временных промежуточных таблиц, которые могут быть снимками или реплицированными из других источников таблицами. Данные загрузочной секции могут храниться даже во внутреннем формате системы, обеспечивающей пересылку данных. Пока данные находятся в загрузочной секции, для анализа они не доступны, поскольку еще не попали в хранилище.
Рис. 13.1. Типичная конфигурация хранилища данных
Процесс трансформации (изображен тонкой линией) на приведенной выше схеме должным образом не представлен, хотя именно он обеспечивает пересылку данных из загрузочной секции в хранилище. Именно здесь располагается логика, осуществляющая трансформацию и интеграцию. Если две подающие системы содержат подробные сведения о клиентах, но используют разные идентификаторы, то эти данные необходимо согласовать, а некоторые из них, возможно, дополнить или отбросить. Этот процесс часто называют очисткой данных (data scrubbing).
Само хранилище показано в виде устройства хранения данных, но очевидно, что оно располагается на компьютере. Скорее всего, это будет мощная симметричная многопроцессорная машина или машина с массовым параллелизмом. Хранилище данных может быть реализовано в виде распределенной среды или трехуровневой архитектуры, где между клиентом и сервером данных находится сервер приложений. Проектировщик обязательно должен участвовать в выборе и определении параметров компьютера, на котором будет размещаться хранилище данных. Как мы уже говорили, хранилище данных лучше располагать на выделенной системе, поскольку в противном случае сложные запросы к хранилищу будут отрицательно сказываться на производительности других приложений.
Наиболее важным для хранилища аспектом является структура его данных. Ее хранителем является сервер. В самом простом случае структура данных хранилища является копией структуры одной эксплуатируемой базы данных, в которой выполнена интенсивная денормализация. Она может быть и довольно сложной и представлять собой результат слияния нескольких эксплуатируемых баз данных с последующим выполнением обобщения результатов и денормализацией. В таких случаях процесс очистки или загрузки данных почти наверняка будет происходить при участии механизма разрешения несоответствий.
Если речь идет о "серьезном" хранилище данных, то модель данных будет представлять собой очень сложную звездообразную схему, полученную путем комбинирования данных из внутренних и внешних источников с вероятным включением данных текстур и (или) мультимедийных данных. (О звездообразных схемах мы поговорим ниже.)
Многомерные и пространственные модели
База данных, на которой строится хранилище данных, не обязательно должна быть реляционной. Многие такие базы данных основаны не на реляционной, а на многомерной модели. Многомерные серверы предназначены для оптимизации хранения и выборки многомерных данных с тем уровнем производительности, которого трудно достичь с помощью реляционной архитектуры. Тем не менее, как оказывается, многомерные базы данных не очень хорошо масштабируются и не дают ожидаемых результатов при больших объемах данных и большом числе измерений.
В версии 7.3 Oracle успешно реализовала ряд расширений своей реляционной базы данных с тем, чтобы при использовании Oracle Spatial Data Option система непосредственно поддерживала пространственные запросы. К сожалению, многие сотрудники Oracle (включая даже некоторых специалистов по маркетингу!), кажется, не могут разобраться в различиях между многомерной поддержкой (обращением к данным по нескольким внешним ключам) и пространственной поддержкой (обращением к данным по координатам). В этой главе рассматривается проблема многомерных данных; данные, конечно, могут иметь и пространственные свойства, но это уже другая тема.
Чтобы вы поняли, почему проблема пространственных данных так остра для реляционной базы данных, давайте посмотрим, как выполнить индексацию для поддержки запроса, который ищет все нефтяные скважины в данной местности:
SELECT welled, latitude, longitude, total_barreles_produced
FROM oil_wells
WHERE latitude BETWEEN :lat1 AND :lat2
AND longitude BETWEEN :long1 AND :long2;
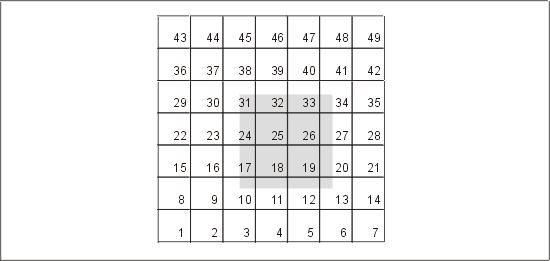
Единственный эффективный путь решения этой задачи состоит в следующем. Необходимо разделить двумерное пространство на некоторое (большое) число блоков, имеющих размер, например, 500 на 500 метров. Для каждой нефтяной скважины придется хранить данные о блоке, в котором она расположена. Условие запроса можно преобразовать в список уточняющих блоков, который будет служить основой индексного доступа. Каждая нефтяная скважина, находящаяся в уточняющем блоке, проверяется на предмет того, располагается ли она в пространстве, описанном в условии запроса. (Эта схема изображена на рис. 13.2.)
Риc. 13.2. Переход от двух измерений к одному
Условие
WHERE x BETWEEN 3.8 AND 5.3 AND
у BETWEEN 2.2 AND 5.3;
теперь станет таким:
WHERE block IN (10,11,12,17,18,19,24,25,26,31,32,33)
AND x BETWEEN 3.8 AND 5.3 AND у BETWEEN 2.2 AND 5.3;
К сожалению, список уточняющих блоков для некоторых запросов может быть очень длинным, поэтому в Oracle Spatial Data Option используется иерархический подход. Oracle Spatial Data Option — умная штуковина, и вам почти наверняка придется ее купить, если вы столкнулись с проблемой пространственных данных. (Но к теме нашей главы это не относится).
Что отличает хранилище данных?
Вы можете подумать, что хранилище данных — это дорогая роскошь. На первый взгляд может показаться, что мощные средства запросов, работающие с действующей ООТ-базой данных, способны дать нужный результат. Но в большинстве случаев это совсем не так. Причин тому много. Вот только некоторые, самые существенные, из них:
• Данные в ООТ-системе постоянно изменяются, поскольку в процессе ввода все время появляются новые и обновленные данные. С нестатичными данными нельзя выполнять анализ возможных ситуаций и другие формы анализа, потому что невозможно правильно сравнить результаты. В процессе моделирования пользователю может потребоваться одни данные изменять, а другие — нет, чтобы увидеть, какой от этого получается эффект. Но если за это время изменятся базовые данные, то любые сравнения абсолютно бесполезны. В Oracle7 есть метод, который позволяет просмотреть данные, обеспечив при этом непротиворечивость по чтению. Этот метод заключается в использовании предложения SET TRANSACTION READ ONLY. Но просматривать данные таким образом можно лишь в течение относительно короткого промежутка времени (его длительность ограничена размером сегментов отката).
• Данные в организации часто рассредоточены и хранятся в разнородных вычислительных средах далеко друг от друга. Даже если использовать преимущества технологии распределенных баз данных, то все равно создать интегрированное представление для таких данных без предварительного их переноса технически очень сложно. Последствия от выполнения запросов, создающих эти представления, для производительности системы просто ужасны!
• ООТ-база данных обычно проектируется и оптимизируется под задачу ввода и сопровождения данных. Перемещение по этим данным осуществляется главным образом под управлением ООТ-приложений. Не всегда можно обеспечить возможность незапланированного доступа или перемещения, а там, где удается этого добиться, скорость вряд ли будет высокой.
• Многие ООТ-системы хранят данные только за короткий промежуток времени (или вообще не хранят исторические данные). В силу этого они вряд ли будут полезны для анализа тенденций.
• Поскольку данные большей частью используются приложениями, созданными специалистами по информационным технологиям, они часто содержат закодированные значения и непонятные имена. Кроме того, эти данные могут включают таблицы, которые не имеют реальной ценности для бизнеса, а созданы для реализации какого-то проектного решения. Все это делает данные трудными для понимания конечными пользователями. За деревьями они не могут увидеть леса, а если и увидят этот лес, то без конвертирования он никакого смысла для них не имеет. Этот недостаток в некоторой степени можно устранить с помощью представлений. Однако длины имен представления и столбцов в представлении ограничены 30-ю символами, и это часто не позволяет понятно описать назначение тех или иных данных. Например, столбец AUTO_ACK_YN таблицы в представлении можно назвать SEND_AUTOMATIC_ACKNOWLEDGEMENT, но хороший пользовательский инструмент для запросов должен поддерживать более информативные имена, а иногда и имена с пробелами.
• Во многих ООТ-системах доступ к данным и их защита реализованы в самом приложении, что делает использование средств создания нерегламентированных запросов небезопасным, если только в них нет удовлетворительной подсистемы защиты. В общем случае эта проблема решается путем использования представлений.
• Если необходимо выполнять нерегламентированные запросы к "живым" данным, то, вероятно, потребуется назначить для этого определенное время суток, не критичное для деятельности предприятия. Ведь нельзя рассчитывать, что создающие такие запросы пользователи хорошо знакомы с методами повышения производительности и не напишут какой-либо невероятный запрос. В этом случае другие пользователи сразу почувствуют, что система работает медленно. Эти проблемы можно попытаться решить, если ввести порядок, согласно которому нерегламентированные запросы можно делать до 8 утра и после 6 вечера. Однако в этом случае будет сложно характеризовать систему как сервис запросов по требованию, особенно если эти запросы приходится планировать через группу сопровождения.
Хранилища данных не возникли за один день, а развились из систем поддержки принятия решений (СППР — DSS) и информационных систем руководителей (ИСР— EIS). Эти системы традиционно работали с данными, которые были идентичны данным, в той операционной системе, где сопровождались эти данные; такие системы обращались либо к "живым" данным, либо к их последней неизменяемой копии. Хранилища данных не обязательно берут непосредственные копии рабочих данных из ООТ-систем. Их таблицы строятся на рабочих данных, но, как правило, включают только те детали, которые касаются процесса принятия решений. Принадлежащие вашей организации данные, конечно, представляют интерес, но если их объединить с общими данными о рынке, в том числе о ваших конкурентах, то такая информация приобретает совершенно новое значение. Источниками данных для хранилища могут являться маркетинговые агентства, а также различного рода сервисные системы, например система агентства Рейтер.
Почему же хранилища данных приобрели такую популярность, какую выгоду они дают и как оправдать расходы на их создание и поддержку? Для принятия стратегических решений обязательно нужно иметь доступ к представлению рабочих данных корпорации, а в некоторых случаях — и к данным всего рынка. Чтобы составить, полную картину состояния бизнеса, пользователи должны иметь возможность "пересекать" границы подразделений, а также иметь в своем распоряжении внешние данные, например сведения о конкурентах. В такой среде архивные данные так же важны, как и текущие, следовательно, сопровождать нужно и те, и другие. Сводная информация о бизнесе вместе с интеллектуальными средствами анализа данных, позволяющими выполнять нерегламентированные запросы, дает нам в руки мощный инструмент для принятия решений. Например, по данным, находящимся в хранилище, специалист по маркетингу может выполнить анализ тенденций и выявить на рынке потенциальный дефицит, который можно будет затем устранить.
Проблемы проектирования
По своей природе хранилища данных — пожиратели ресурсов, и для обеспечения их эффективной работы необходимо тщательное проектирование с самых ранних этапов и наличие навыков администрирования баз данных. Эти требования обусловлены следующими свойствами хранилищ данных:
• Хранилища данных, как правило, представляют собой большие (часто очень большие) базы данных.
• От них требуется высокая скорость обработки данных.
• Физическое расположение данных должно выполнятся так, чтобы обеспечивать оптимальное выполнение запросов.
• Многие традиционные методы проектирования неприменимы к хранилищам данных, поскольку предполагают, что проектировщик хочет добиться оптимальной работы для системы ООТ или обновления (данные в хранилище никогда не обновляются непосредственно, а только косвенно — путем приема в загрузочную секцию новых данных). Эта характеристика имеет важное следствие: для хранилищ может оказаться полезным и безопасным нарушение третьей нормальной формы (ЗНФ).
То, что хранилище данных обычно формируется как продукт нескольких эксплуатируемых систем, означает, что оно наверняка будет содержать колоссальный объем данных, часто измеряемый терабайтами. Поэтому на этапе проектирования очень важно правильно определить как начальный объем хранилища, так и его рост по мере увеличения количества данных. Нередки случаи, когда в хранилище данных каждый день помещают несколько гигабайтов новых данных. Это выдвигает жесткие требования к коду, который перемещает данные из загрузочной секции в хранилище.
Такие традиционные методы, как нормализация данных, основаны в первую очередь на том, чтобы избежать избыточности данных, а также сбалансировать требования к выполнению запросов и требования к выполнению DML-операций. Как мы видели в главе 3, в процессе нормализации порождается большое число таблиц. Однако большое число маленьких таблиц, как правило, является полной противоположностью тому, что лучше всего обслуживает хранилище данных. По этой причине для хранилищ данных неприменимы некоторые ключевые принципы традиционного реляционного проектирования. Даже моделирование сущностей не совсем подходит для хранилищ данных, и это породило метод, известный как многомерное моделирование, который позволяет получать базы данных, более удобные для перемещения и запросов. Многомерное моделирование мы рассмотрим позже, а пока просто введем понятие таблицы фактов. Это таблица, которая предназначена для хранения всех фактов, представляющих интерес для хранилища, например перемещения запасов, продажи товаров и т.д.
Итак, вы, должно быть, уже поняли, что реализовать хранилище данных — это не значит просто пойти и купить какие-то инструменты для запросов. Необходима серьезная работа по определению объема и проектированию хранилища, без проведения которой даже нельзя думать о том, какие инструменты лучше всего подходят для запросов к данным. Если рассматриваемый проект хранилища данных — первый для вас или вашей организации, рекомендуем сначала ограничиться небольшим объемом. Если вы при первой попытке будете нацелены на разработку общекорпоративного решения, то ситуация сложится явно не в вашу пользу. Поэтому лучше сконцентрироваться на узкой, четко ограниченной области бизнеса, для которой можно выполнить поставленную задачу в разумные сроки и которая характеризуется небольшим объемом данных, поддающихся управлению. Решив эту задачу, можно начинать завоевывать мир!
Достижения
Oracle в технологии хранилищ данных
Oracle осваивала технологию хранилищ данных на удивление медленно. В начале 90-х годов, когда покупатели ее СУБД уже начали реализовывать у себя хранилища данных, Oracle несколько запаздывала с обеспечением прямой поддержки этой технологии. Когда стало ясно, что компания отстает от таких поставщиков, как Redbrick, она выступила с рядом инициатив, целью которых было догнать и перегнать конкурентов. Среди этих мероприятий было приобретение у фирмы IRI Software OLAP-продукта PC Express (который сейчас известен как Oracle Express). Кроме того, Oracle призвала третьи фирмы к объединению усилий и создала организацию Warehouse Technology Initiative (WITI). Сейчас у компании свыше 30 партнеров в данной области.
Oracle признала, что версия 7.0 не удовлетворяла требованиям к хранилищам данных, и с каждым последующим выпуском стала уделять этой технологии все больше и больше внимания.
В версии 7.1 появились дополнения, обеспечивающие как обработку запросов данных, так и прием данных в хранилищах. Использование Parallel Query Option в многопроцессорной среде позволяет задействовать при больших и сложных запросах несколько процессоров. В этой версии также имеются средства параллельной загрузки данных и параллельного построения индексов. SQL*Loader допускает ускоренный прием данных. Несколько сеансов SQL*Loader могут одновременно загружать данные в одну таблицу с помощью механизма прямой загрузки, что позволяет сэкономить много времени.
Средство репликации данных позволяет реплицировать таблицу из любой действующей базы данных. Это служит альтернативой "всасыванию" данных в хранилище в форме двумерных файлов. Конечно, формат этой таблицы может не соответствовать требованиям, но реплицированную таблицу можно подвергнуть преобразованиям и получить другую таблицу, нужной формы. Реплицированная таблица фактически находится в загрузочной секции хранилища.
Появление версии 7.2 сопровождалось заявлениями о двукратном повышении производительности при создании индексов и при выполнении сложных запросов некоторых типов. Создание индексов происходит лучше за счет того, что система обходит буферный пул, т.е. по команде CREATE INDEX запись осуществляется непосредственно в блоки базы данных. Усовершенствования в методе выполнения предложения CREATE TABLE...AS SELECT... также позволяют параллельно выполнять операции вставки и запроса. Это выгодно при создании таблиц итоговых данных.
Оптимизатор версии 7.3 имеет специальную логику для обработки соединений по схеме "звезда". Здесь отсутствуют ограничения на количество экстентов в объекте базы данных. В этом выпуске также сделаны значительные усовершенствования, повышающие эффективность обработки соединений с представлениями, созданными с использованием UNION ALL. Это особенно важно для случаев, когда таблица фактов в хранилище секционирована, но для некоторых запросов, которым нужно сводное представление данных, требуется выполнить объединение. Однако наиболее важным является то, что в версии 7.3 наконец-то реализованы гистограммы распределения значений. Это позволяет оптимизатору запросов вычислять избирательность при индексировании данных, в распределении значений которых наблюдается перекос.
В Огас1е7 есть еще ряд возможностей, которые не предназначены специально для хранилищ данных, но которые мы можем использовать в этой области. Например:
• В, больших неоднородных сетях многие продукты Oracle класса Gateway и Interchange (например, Transparent Gateway для IBM DB2) могут избавить пользователя от утомительной выгрузки в двумерный файл и последующей перезагрузки, а опция UNRECOVERABLE в INSERT... SELECT... еще более уменьшает затраты, связанные с такими операциями.
• Данные, которые необходимо держать в хранилище, не обязательно являются классическими данными в форме записей. Это могут быть большие объемы чисто текстовых данных (например, документы, созданные при помощи текстовых процессоров) или мультимедийные презентации. С такими неструктурированными данными можно работать в хранилище, если интегрировать приложение с Oracle Text Server и Oracle Media Server. Например, Oracle Text Server обеспечивает ускоренный поиск слов в тексте при больших объемах неструктурированных данных и может быть мощным инструментом исследования данных.
• У Oracle есть с чем выступить и на арене средств исследования данных. Речь идет о группе продуктов Discoverer/2000. Предлагаются два очень похожих по своей природе продукта — Oracle Data Query 4 и Oracle Data Browser 2. Однако, по нашему мнению, в этой области Oracle еще не достигла зрелых результатов.
Не забывайте об осторожности
Теперь, когда мы установили, в чем состоят основные достоинства хранилищ данных, нелишним будет выяснить, чего же следует опасаться при работе с ними. Перед тем как вливаться в ряды приверженцев технологии хранилищ данных, ознакомьтесь с нашими предостережениями.
• Хранилища данных — это технология, в которую нужно погружаться плавно. Необходимо действовать постепенно, вводя по одному механизму подачи данных за раз. Если вы изберете метод "большого взрыва", то почти наверняка столкнетесь с серьезными проблемами. Полную неудачу вы, конечно, не потерпите, но всегда будете сожалеть о тех или иных решениях. Итеративный же подход позволяет использовать опыт, приобретенный на предыдущих этапах, и сделать всю задачу более управляемой. Тем не менее, даже в небольшом проекте сначала нужно создать базовую инфраструктуру, и вы должны разъяснить своим пользователям, что реальная выгода от хранилища данных будет ощущаться по мере роста его сложности и объема, однако за один шаг этой цели достичь нельзя.
• Помните, что в хранилище стягиваются данные из всей организации. В большинстве организаций наблюдается следующая картина: то, что в отделе сбыта называют прибором, в отделе эксплуатации могут называть устройством. Более того, продавцы используют для обозначения экземпляра этого прибора-устройства трехзначный код, а группа эксплуатации — шестизначный. Если вы хотите, чтобы и приборы, и устройства фигурировали в отчетах как один и тот же объект (а именно так и бывает в реальной жизни), то придется заставить организацию принять стандартный набор терминов и формат обозначений. Конечно, можно в этом случае ввести синонимы, но это тоже чревато опасностью. На предприятии должны "проникнуться" технологией, быстро принимать решения о стандартах данных и быть готовыми к компромиссам.
• В предыдущем замечании мы упомянули о различиях в наименованиях и форматах данных. Могут иметь место и более тонкие, но глубокие аномалии. Например, покупатель для одной части организации может быть филиалом или подразделением материнской компании-покупателя для другой части организации. Различия такого типа трудно выявить, а там, где это сделать удается, их бывает тяжело разрешить без ущерба для той или иной части организации. Подчеркиваем: чем больше используется механизмов подачи данных, тем больше времени нужно отводить на урегулирование проблем, связанных с несоответствиями такого типа. Кроме того, конечно, наличие строгой, четко обставленной ограничениями модели данных — несомненный плюс, но это возможно не всегда, потому что данные из несоизмеримых источников могут стыковаться не очень хорошо. Например, если нет гарантии, что какой-то источник всегда будет поставлять данные, то придется допустить неопределенные значения в столбце, который в нормальных условиях был бы определен как NOT NULL. Чтобы этого не делать, можно помещать в столбец текстовую строку UNKNOWN.
• Мы советуем перед проектированием хранилища данных предусмотреть меры по проверке качества данных в каждой из подающих систем. Для вас крайне нежелательно, чтобы ваше начальство принимало смелые корпоративные решения на основании данных, достоверность которых вызывает сомнения. Можно, например, фильтровать данные, поступающие из определенных источников, или полностью отключить источник, пока не будет проведена очистка данных.
• Помните о том, что данных в вашем хранилище сразу же будет очень много и со временем их объем будет только расти. Поэтому еще на ранних этапах обязательно выполните планирование того, как вы будете управлять этим постоянно увеличивающимся объемом данных. Необходимо учитывать и вопросы системного управления, связанные с администрированием такого большого количества данных. Администратору БД и системному администратору наверняка понадобится помощь в уходе за этим ребеночком! Администратор БД должен участвовать в проекте с самых первых этапов.
• Вновь повторим — нужно начинать с малого. Первым упражнением с хранилищем данных может быть следующее. Создайте денормализованную копию одной эксплуатируемой базы данных, а затем снабдите ее интерфейсом для загрузки двумерных файлов и простыми средствами выполнения запросов.
Вопросы проектирования для хранилищ данных
Теперь, когда мы понимаем, что такое хранилище данных, давайте рассмотрим факторы, влияющие на методы проектирования хранилищ.
Многомерное моделирование и звездообразные схемы
Выше мы вскользь упомянули о том, что хранилища данных можно моделировать методами многомерного моделирования с использованием звездообразной схемы. Повторим, что традиционные методы моделирования данных и проектирования баз данных, как правило, не позволяют получить структуры данных, оптимизированные для массовых запросов. Поэтому придется отбросить некоторые традиционные идеи о проектировании и выучить ряд новых приемов. В этом разделе частично затрагиваются вопросы анализа, потому что это важно для понимания того, как определяются эти модели.
Как и большинство понятий в компьютерном мире, звездообразная схема имеет несколько синонимов: многомерная схема, куб данных и соединение по схеме "звезда". Причина, по которой эту схему называют звездообразной, заключается в том, что ее графическое представление напоминает звезду.
Факты и измерения
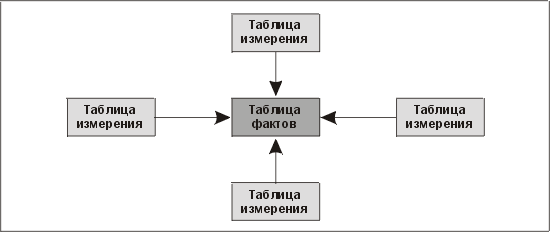
Звездообразная модель состоит из центральной таблицы фактов (fact table), которая окружена несколькими таблицами измерений (dimension table) (рис. 13.3). Физически таблица фактов часто представляет собой несколько секционированных таблиц. (О секционировании мы поговорим ниже.)
Рис. 13.3. Звездообразная схема
Отношения между таблицей фактов и таблицами измерений должны быть простыми, чтобы существовал только один возможный путь соединения любых двух таблиц и чтобы смысл этого соединения был очевиден и хорошо понятен. Всегда необходимо помнить о том, что мы разрабатываем эту систему для того, чтобы пользователи могли определять свои собственные запросы. Ориентированные на конечного пользователя средства нерегламентированных запросов не прижились в традиционной реляционной базе данных. Даже если столбцам этой базы дать информативные имена, проблема не исчезнет: отношения внутри модели данных останутся сложными, а число этих отношений — большим. Здесь мы имеем в виду, что, как правило, существует более одного способа соединения двух таблиц. Иногда в запросе должны быть использованы таблицы, не имеющие отношения к данному бизнесу, потому что они содержат ссылки на другие нужные для запроса таблицы. (Некоторые программные продукты, например HP Intelligent Warehouse и Business Objects, решают эту проблему с помощью преобразующего слоя.) Еще одно преимущество простоты отношений состоит в том, что это помогает повысить производительность.
Все, что аналитик должен сделать при многомерном моделировании, — это выявить факты и их измерения! Факты обычно представляют собой основные виды бизнес-деятельности организации и факторы, влияющие на данный бизнес или его сектор. Если у организации (или подразделения) есть сформулированная цель, то требуется определить, какие элементы ее бизнеса играют главную роль в достижении этой цели. Чтобы найти кандидатов на включение в этот список, исследуйте модели сущностей ООТ-систем и проверьте отчеты, которые выдают действующие системы для руководителей и специалистов по маркетингу. Список, который вы предложите, пройдет процедуру уточнения и в конечном итоге будет согласован.
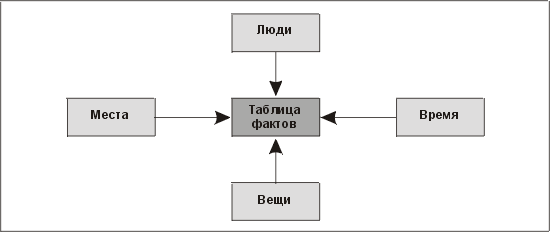
Что можно сказать о таблицах измерений? В широком смысле слова — это элементы, которые могут оказывать определенное влияние или порождать различные тенденции в развитии наших фактов. Исходя из этого измерения можно разбить на следующие категории: люди, места, вещи и время (рис. 13.4).
Рис. 13.4. Классификация измерений: люди, места, вещи и время
Рассматривайте таблицу фактов в свете реляционной теории: у нее есть внешний ключ к каждой соответствующей таблице измерения. Она объединяет измерения в нечто, представляющее собой значимое событие, и содержит качественную и количественную информацию об этом событии. Эти внешние ключи можно использовать двумя способами:
1. Для соединения с таблицей измерения с целью выбрать описательную информацию об этом измерении.
2. Как правило, они являются основой для выполнения обобщений в таблице фактов. Например, мы можем суммировать содержащиеся в таблице фактов количественные показатели, которые относятся к конкретному покупателю. Если имя покупателя является частью утверждения о факте, то такое суммирование можно выполнить без последующего соединения с какой-либо другой таблицей.
Таблица фактов может включать и описательную информацию, но это бывает нечасто — обычно описания находятся в таблицах измерений. В сценарии продаж таблица фактов может содержать данные о том, сколько товара реализовано и на какую сумму, а также внешние ключи к таблицам измерений, характеризующих операцию продажи (какой товар, когда он был продан, кто продал его и какой способ платежа был использован).
Временное измерение в звездообразной схеме обладает рядом интересных свойств. Факт, скорее всего, будет связан не с одним моментом времени, а с каким-то временным промежутком. Следовательно, временное измерение обычно является обобщающим. Например, в хранилище вряд ли будут регистрироваться подробности каждой продажи каждого товара в каждом пункте каждым продавцом (хотя это и возможно). Более вероятно, что понадобится объем продаж за месяц по данному товару, пункту и продавцу. В данном случае выбор месяца как единицы измерения, конечно, не является обязательным — единицей может быть и день, и неделя, и квартал. Как правило, для этого используется отчетный период, принятый в данной организации. При выборе единицы изменения времени приходится выбирать между хранением огромного числа фактов в хранилище (которые в большинстве запросов необходимо будет обобщать) и отсутствием данных о сезонных тенденциях вследствие того, что при обобщении выбран слишком большой период времени.
Временное измерение часто выступает в качестве основы для секционирования таблицы фактов. Во многих случаях секционирование необходимо для уменьшения объема таблицы фактов и облегчения управления ею. Время же используется потому, что при этом, как правило, получают приблизительно равные по объему кванты и оно часто является наиболее логичным для секционирования измерением. Кроме того, время — наиболее вероятная основа для усечения таблицы фактов (если когда-нибудь удастся заставить предприятие согласиться на удаление данных из его любимого хранилища).
Выбор степени детализации временного измерения (неделя, день, месяц и т.д.) может иметь исключительную важность. Если, например, выбрать месяц, то средство анализа, возможно, сможет обобщить данные в еще большей степени и показать результаты по годам. Затем с помощью различных методов детализации можно представить данные по кварталам нужного года, а потом вновь по месяцам. Очевидно, что в этом случае нельзя выполнить более подробную временную детализацию, поскольку для этого нет данных. Выбор степени детализации по времени имеет большое значение, потому что позволяет уравновесить два фактора — необходимость в более детальной разбивке и объем хранилища данных. Если вы решите загружать в хранилище каждую транзакцию из разных ООТ-баз данных, то ваши пользователи, скорее всего, будут выдавать действительные по дате запросы к таблице временного измерения со всеми вытекающими отсюда проблемами (сложный SQL и потенциальные ловушки). (Эта перспектива рассматривается в главе 7.)
Некоторые интеллектуальные OLAP-средства могут сами формулировать запросы, но "за кулисами" при этом генерируется неэффективный запрос. Необходимо помнить, что при обобщении некоторая часть информации всегда теряется. Например, возможна ситуация, когда в определенных регионах объем продаж значительно растет из-за того, что торговые точки открыты до позднего вечера. Обобщая данные о продажах по дате (и времени) в месячном разрезе, это важную особенность можно упустить.
Таким образом, при проектировании хранилища данных необходимо уделять должное внимание временным измерениям и в каждом конкретном случае принимать решение о необходимой для обобщения степени детализации.
Звездообразная схема: пример
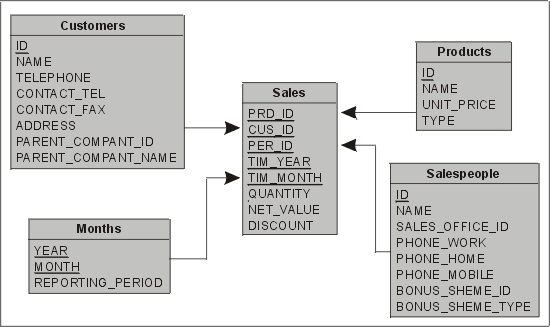
На рис. 13.5 показана звездообразная схема системы сбыта продукции. Таблица фактов (SALES) в данном случае обобщает данные по месяцу (MONTH, время), товару (PRODUCT, вещь), продавцу (SALESPERSON, лицо) и покупателю (CUSTOMER, лицо). Прежде всего рассчитаем количество строк в нашей таблице данных за год (12 месяцев). Предположим, что у нас 100 покупателей, пять продавцов и три товара. Максимально возможное количество строк будет равно произведению всех этих чисел (100х5х3х12=45000). Однако вряд ли все наши продавцы каждый месяц продают все товары каждому покупателю, поэтому в действительности размер таблицы будет гораздо меньше. Таким образом, размер таблицы фактов в данном случае равен значению декартового произведения измерений минус число неприемлемых комбинаций. Если бы все строки были заполнены, то многие проектировщики выбрали бы вариант, при котором для всех маловероятных случаев хранилась бы запись с нулевым объемом продажи.
Рис. 13.5. Звездообразная схема системы сбыта продукции
На рис. 13.6 показаны определения таблиц, которые используются для реализации звездообразной схемы, изображенной на рис. 13.5. По поводу таких таблиц необходимо отметить следующее:
1. В таблицах измерений часто применяются суррогатные ключи. Это объясняется тем, что таблицы измерений нередко формируются при помощи разных источников. Они могут создаваться как соединение нескольких таблиц из ООТ-системы или строиться из похожих таблиц, принадлежащих нескольким разным ООТ-системам, не имеющим идентичных ключей. Иногда полезно назначить для таблицы измерения "реальный" ключ, как в случае с таблицей MONTHS в нашем примере. Это повышает эффективность внешнего ключа в таблице фактов, так как позволяет анализировать данные по годам, не выполняя соединение с таблицей месяцев.
2. Некоторые таблицы измерений содержат элементы, которые в традиционной модели были бы реализованы при помощи внешних ключей к другим таблицам. К примеру, в таблице продавцов имеются поля ВОNUS_SCHEME_ID и SALES..OFFICE_ID. Поскольку система премий и отдел сбыта не считаются измерениями таблицы фактов SALES (по крайней мере в этой интерпретации), как отдельные таблицы они не создаются. Все необходимые подробности можно включить в таблицу измерения, к которой они относятся. Так, таблица SALESPEOPLE в нашем случае содержит информацию о типе системы премий. Наличие избыточных и ненормализованных данных типично для таблиц измерений.
Рис. 13.6. Определения таблиц для реализации звездообразной схемы сбыта продукции
В типичном запросе к звездообразной схеме указываются детальные сведения о точках этой схемы (измерение), а затем данные, соответствующие этим точкам, обобщаются. Как правило, производится несколько таких итераций с целью выявления тенденций изменения данных. Для этого можно несколько измерений держать постоянными, а другие изменять либо соединять таблицу фактов с другими таблицами, чтобы увидеть корреляцию между таблицей фактов и измерениями, не указанными в условии запроса. Этот прием, который часто называют детализацией данных (drill-down), поддерживается многими OLAP-средствами просмотра данных. Приведенное ниже предложение SELECT демонстрирует типичный запрос к звездообразной схеме. Изменяя данные о регионе, месяце или товаре, при помощи запроса этого типа можно выявить тенденции в данных. Обратите внимание на характерную для звездообразной схемы простоту этого запроса; здесь выполняются только простые односторонние эквисоединения таблиц измерений с таблицей фактов. Таблицы измерений не соединяются друг с другом — это признак хорошего проектирования хранилища.
SELECT SUM(sls.quantity)
, sis.month,
, per.name
FROM sales sls
, salespeople per
WHERE sales.per_id = per_id
AND sales.year = 1997
AND sales.month BETWEEN 6 AND 7
AND sales.prd_id = 33
AND per.sales_office_id = 6
GROUP BY sls.month, per.name;
Этот запрос должен хорошо оптимизироваться, хотя, возможно, и придется немного поэкспериментировать, чтобы Oracle правильно выбрала ведущую таблицу. Однако "звездообразные" запросы (запросы, в которых имеются условия по более чем одной таблице измерения) оптимизируются крайне плохо во всех версиях Oracle до 7.3. Если необходима поддержка таких запросов в более ранних версиях, мы рекомендуем реализовать процедурное решение.
Развертывание измерений
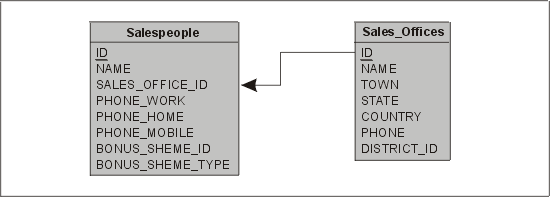
Хотя приведенный выше запрос прост, он несколько похож на шифр. Например, не ясно, что представляет собой товар с идентификатором 33. Эту проблему можно решить, если выполнить соединение с измерением Products (товары) и указать вместо идентификатора наименование товара. Однако задать отдел сбыта по наименованию, а не по идентификатору нельзя, поскольку измерения Sales Office (отдел сбыта) нет. Существует несколько вариантов выхода из этой ситуации:
1. Включить в таблицу SALESPEOPLE и идентификатор, и наименование отдела сбыта.
2. Создать новое измерение и назвать его Sales Office.
3. Создать таблицу развертывания измерения.
Варианты 1 и 2 особых пояснений не требуют. Если запросы этого типа встречаются часто, то рекомендуется создать для отдела сбыта отдельное измерение. Давайте исследуем третий вариант — развертывание измерения. Этот метод заключается в том, что мы нарушаем классическую звездообразную структуру и создаем таблицу развертывания измерения, которая связана с данной таблицей измерения (рис. 13.7).
Рис. 13.7. Ввод таблицы развертывания измерения
Этот метод подозрительно похож на нормализацию звездообразной схемы. Он приемлем в случае, когда необходимо хранить большой объем информации об отделе сбыта и часто выполнять обобщение данных по продавцам в данном отделе сбыта. Число таблиц развертывания измерения следует сводить к минимуму; в идеале их вообще следует избегать, так как они усложняют SQL-предложения для запроса данных.
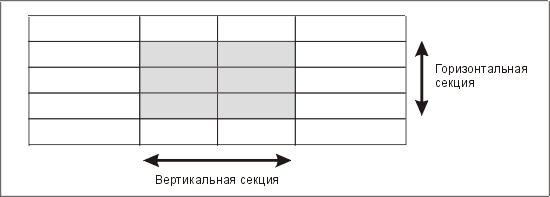
Секционирование
Термин "секционирование" очень широко используется специалистами по базам данных и в общем случае означает формирование подмножеств данных. Различают горизонтальные секции, состоящие из подмножества строк, и вертикальные секции, представляющие собой подмножество столбцов (рис. 13.8). Когда в этой главе мы говорим о секции, не уточняя, какая она, то мы имеем в виду горизонтальную секцию.
Рис. 13.8. Горизонтальное и вертикальное секционирование
Большинство таблиц фактов в хранилище имеет источник данных, подверженный интенсивным транзакциям. В примере на рис. 13.5 и 13.6 таблицей фактов является таблица продаж. Надеемся, что каждый день через наши отделы сбыта будет идти мощный поток новых продаж! Эти новые продажи нужно периодически заносить в хранилище данных. (Ниже в этой главе мы рассмотрим механизмы занесения новых данных.) Предположим, что у нас семь региональных отделов сбыта и мы решили загружать данные о новых продажах в хранилище один раз в сутки. Эти файлы можно загружать в одну таблицу продаж, но этот метод имеет ряд недостатков:
• Очень скоро она станет очень большой, что затруднит ее администрирование и управление.
• В процессе загрузки данных эта таблица может оказаться недоступной для пользователей, выполняющих запросы. Это зависит от того, какие методы применяются для загрузки.
• Если не создать специальную утилиту очистки и не запускать ее периодически, то отделить и выбросить данные, которые устарели и утратили свою актуальность, будет сложно.
Чтобы решить эти проблемы, мы можем секционировать таблицу фактов на более мелкие таблицы. В примере будет не одна таблица с именем SALES для всех данных о продажах, а по одной таблице для каждого дня — SALES_010197, SALES_010297, SALES_010397 и т.д. Каждая таблица будет содержать сводные данные о продажах по семи региональным отделам сбыта за соответствующий день. Можно секционировать таблицу и по регионам (SALES_NORTH, SALES_MIDWEST и т.д.), но в данном случае это не имеет смысла, потому что такой подход не решит все описанные в нашем списке проблемы. В большинстве случаев очевидным кандидатом на роль ключа секции является временное измерение.
Выбирая отличительный столбец для секции, вы обнаружите, что лучше всего использовать ключ, который позволяет облегчить загрузку данных. По этой причине столбец Data Processed ("Дата обработки") или столбец Data Created ("Дата создания"), как правило, лучше подходят на эту роль, чем столбец Data Applicable ("Дата применения"), потому что они более естественно вписываются в процесс циклической загрузки. В этом случае можно будет ввести в систему заказ, фактически принятый от покупателя на прошлой неделе, или же будущие либо повторяющиеся заказы. Когда дело доходит до извлечения данных для загрузки в хранилище, то нельзя гарантировать, что все данные для секции будут получены за один раз, если секция основана на дате заказа, однако это можно гарантировать, если секция основана на дате обработки заказа.
Мы продемонстрировали положительное влияние, которое секционирование оказывает на процесс загрузки. Теперь давайте посмотрим, как оно влияет на запросы данных. На первый взгляд, при этом должны существовать проблемы. Чтобы запросить или обобщить данные за январь 1997 года, нужно объединить 31 таблицу: SALES_010197, SALES_010297, SALES_010397. Естественно, такое объединение будет трудным для программирования и неэффективным в работе. С его громоздкостью можно справиться, если определить представления, в которых и будут осуществляться большие объединения таблиц (при этом обязательно нужно применять операцию UNION ALL, a не UNION).
Некоторые сложные средства запросов позволяют создать метамодель данных, которая описывает отношение между секционированными таблицами, определяющими таблицу фактов. Проблемы с производительностью в значительной мере решены в версии 7.3, где условия соединения можно "сваливать" в представления с UNION ALL. При этом необходимо соблюдать некоторые условия — представление должно строиться на "чистых" секциях, т.е. логические определения секций должны быть полностью идентичны.
Помимо этого, версия 7.3 может с помощью гистограмм значений столбцов определять, в каких секциях производить поиск по индексу, а в каких — путем полного сканирования таблицы. Это позволяет устранить упомянутый выше серьезный недостаток, связанный с включением "лишних" секций, и вынуждает генераторы запросов предыдущего поколения выполнять эту оптимизацию в процессе генерации запросов, а не перекладывать ее на плечи оптимизатора запросов. В версиях до 7.2 секционирование все равно дает те преимущества, которые мы обсуждали в главе 10, посвященной архивации. Тем не менее, мы не советуем пытаться выполнять соединение с представлением, содержащим UNION ALL; лучше взять генератор запросов, который создает полный запрос по каждой секции и формирует объединение UNION ALL полученных результатов.
Возможно секционирование и более чем по одному атрибуту (SALES_NORTH_0197, SALES_NORTH_0297, SALES_SOUTH_0197 и т.д.) Однако этот метод уводит нас в сторону от идеи упрощения структуры и порождает сложности при комбинировании таблиц.
Для хранилища данных можно разработать специальную программу, которая будет выполняться в конце каждого месяца, извлекать данные за этот месяц и создавать новую таблицу (SALES_0197). Очевидно, что этот метод характеризуется избыточностью, но его можно эффективно использовать, если над извлеченными данными выполняются агрегирующие операции, обобщающие их для месячного представления. Когда пользователь детализирует данные, вы начинаете применять секции для каждого дня, содержащие более подробные сведения.
Правила агрегирования
Как мы уже говорили, большинство хранилищ данных содержит данные двух типов:
• атомарные данные, соответствующие данным из систем ООТ;
• агрегированные данные, т.е. обобщения данных, хранящихся в системах ООТ;
Необходимо определить, когда, что и как агрегировать.
Когда
Давайте сначала посмотрим, когда следует агрегировать данные, потому чтo это относительно простой вопрос. Лучше всего это делать на этапе перехода из загрузочной секции в хранилище. Следующий удобный (и более привычный) метод — загрузить данные в таблицу фактов и выполнять агрегирование там. Существует и другой вариант — одновременно с созданием загрузочного файла атомарных данных создать загрузочный файл обобщенных данных. Однако он имеет ряд недостатков:
• Нет стопроцентной гарантии, что все данные при загрузке в хранилище успешно пройдут проверку. Кроме того, между агрегированными и атомарными данными могут возникнуть противоречия, поскольку часто для их проверки нельзя применять одинаковые методы.
• В этом случае довольно часто возникают ситуации, когда пытаются агрегировать данные, поступившие из разных источников или загрузочных наборов.
Что
Теперь рассмотрим более сложную проблему: агрегатные данные какого типа создавать. Для ответа на этот вопрос лучше всего изучить вероятные направления использования данных. Это трудно, потому что, пока хранилище данных не введено в эксплуатацию, никто не знает, как оно будет использоваться. Однако если при сборе информации о потребностях пользователей удалось получить какие-то мнения на этот счет, эти сведения могут оказать большую помощь. Посмотрите на некоторые потенциальные группы агрегированных значений для нашего примера с продажами (табл. 13.1). Если мы будем формировать все возможные сочетания агрегированных значений, то создадим в таблице фактов огромное число новых фактов. Естественно, мы должны выбрать из них важные, а остальные удалить.
Учтите, что любое не созданное в хранилище агрегированное значение можно получить в процессе выполнения из других агрегированных или атомарных данных. Так, любое агрегированное значение, имеющее небольшое число подчиненных агрегированных значений, является вероятным кандидатом на "вылет". Например, показатели за квартал можно определить путем простого суммирования данных за три месяца, а значения по всем товарам — путем суммирования данных по основным и не основным товарам (если при этом выполнена взаимоисключающая и исчерпывающая группировка).
Таблица. 13.1. Агрегированные значения
Products
Sales Person
Customer
Period
ВСЕ ТОВАРЫ
Основные/ неосновные ТОВАРЫ
Серии ТОВАРОВ
ВСЕ ПРОДАВЦЫ
По странам, регионам и отделам сбыта
На ставке/на комиссионных
Прямые/через дистрибьютора
ВСЕ ПОКУПАТЕЛИ
По вертикальному рынку
Многонациональные/ национальные
Первые 20, 10, 5
Год
Квартал
Месяц
Неделя
День
Возникает искушение исключить агрегаты с более низкой степенью детализации, так как на первый взгляд кажется, что это даст самую большую экономию. Например, учитывая, что в году 365 дней, исключение дней может показаться выгодным вариантом (если умножать их на число товаров, продавцов, покупателей и т.д.). Однако в нашем примере данные на этом уровне, скорее всего, будут очень разрежены (если только каждый товар не продается каждым продавцом каждому покупателю каждый день), и в действительности уменьшение объема данных может и не быть столь значительным.
Может случиться, что ни одну из категорий, показанных в табл. 13.1, полностью удалить нельзя из-за их важности для различных аспектов бизнеса. Тем не менее, весьма вероятно, что можно будет удалить определенные комбинации. Например, данные о том, сколько продаж произведено непосредственно, а сколько — через дистрибьютора, могут потребоваться только за квартал и только по некоторым сериям товаров, потому что, скорее всего, не все товары продаются через оба канала. Анализ управленческих отчетов, получаемых из ООТ-систем, может дать информацию, которая поможет принять решение о том, какие сочетания агрегированных значений важны.
Как
Теперь посмотрим, как выполнять агрегирование. Под этим мы подразумеваем следующее: где физически хранить агрегированные данные. Есть три возможных варианта:
1. В той же таблице, что и базовые (неагрегированные) данные о фактах.
2. В таблице фактов, но отдельно от базовой таблицы фактов.
3. Выделить для каждой категории агрегированных значений отдельную таблицу.
Как и следовало ожидать, у каждого из них есть достоинства и недостатки.
1. Вариант 1 влечет за собой создание очень больших таблиц, которые могут стать неуправляемыми. В случае, когда таблица фактов секционирована, он вообще нежизнеспособен. В процессе агрегирования данные читаются из потенциально огромной таблицы и записываются в нее же. В результате этот процесс может протекать очень медленно. Кроме того, структура строк, содержащих агрегированные значения, может отличаться от структуры атомарных строк, поскольку некоторые столбцы на обобщенном уровне не нужны.
2. Вариант 2 может привести к тому, что таблица, содержащая агрегированные значения, очень увеличится. Он годится только для случая, когда разные агрегированные значения для одной таблицы фактов имеют одинаковый формат. Это может стать серьезным ограничением, если вы потом захотите добавить новые агрегированные значения.
3. Вариант 3, вероятно, самый привлекательный, но здесь требуются хорошие правила именования, позволяющие отслеживать имена всех таблиц, и хорошая метамодель, описывающая их инструментам запросов и конечным пользователям. Вообще говоря, необходимо побеспокоиться о том, чтобы инструментальные средства конечных пользователей и промежуточное ПО обладало информацией об агрегированных значениях. В противном случае пользователям самим придется выявлять возможности использования производных данных.
Объединение таблиц фактов
Таблицы фактов, определенные в схеме, не обязательно должны рассматриваться изолированно друг от друга. В некоторых случаях их необходимо соединять. Например, при наличии таблицы фактов "Счет-фактура" и таблицы фактов "Элемент строки" анализ объединенной информации из этих двух таблиц может быть весьма полезным. Эту задачу можно решить путем создания представления, которое соединяет эти таблицы. О нем можно проинформировать промежуточное ПО или инструмент запроса и использовать это представление как полноправную таблицу фактов.
Извлечение и загрузка данных
Вероятно, самый длительный и чреватый неприятностями этап построения хранилища данных — это создание средств извлечения данных из подающих систем. Очень легко недооценить возможности и проблемы, с которыми связано планирование переноса данных. В главе 8 мы изучали некоторые общие вопросы переноса и загрузки данных, а в этой главе внимание обращено на проблемы, характерные в этой связи для хранилища данных.
Процесс извлечения и загрузки данных состоит из нескольких этапов. Одни из них выполняются подающей системой, а другие — системой хранилища данных.
Этап 1: Чтение данных
Сначала нужно посмотреть, в каких системах есть данные, имеющие отношение к хранилищу данных и представляющие для него интерес. На первый взгляд эта задача может показаться очень простой, однако в действительности это не так. В некоторых организациях существуют базы данных на ПК, созданные для устранения недостатков, обнаруженных в системах промышленного уровня. Эти базы данных расположены на жестких дисках ПК отдельных пользователей и часто содержат очень полезную информацию. Требуется решить, следует ли загружать информацию из таких баз данных в хранилище. При этом необходимо учесть следующие факторы:
• полезность этих данных;
• сложность их получения — ПК выключаются и переносятся с монотонной регулярностью, а когда они подключаются к сети, то их IP-адреса таинственным образом исчезают;
• потенциальное отсутствие целостности и аутентичности данных. Написанные пользователями приложения для ПК часто предусматривают еще менее масштабную проверку данных, чем приложения, выпускаемые отделом информационных технологий или службой информационно-управляющих систем.
На данный момент давайте пренебрежем этими персональными БД и сконцентрируем внимание на основных системах организации. В большинстве случаев самая сложная часть нашей задачи состоит в поиске документации, описывающей элементы данных так, чтобы можно было определить, какие из них важны и в каком формате они существуют. Это особенно актуально в случае, если прикладная система была приобретена у третьей фирмы и подробное описание системы отсутствует (этому вопросу уделено серьезное внимание в приложении А).
Если у вас нет ни малейшего представления о внутренней структуре, приложения, это не обязательно означает, что оно не может предоставить данные для использования в хранилище. Вероятно, вы сможете пользоваться содержимым отчета или же (если вам сопутствует удача) прикладная система уже будет содержать средство выгрузки данных в хорошо описанном формате. Возможно, это и не идеальный вариант, потому что могут быть выданы не совсем те данные, которые вас интересуют, но это все же лучше, чем ничего.
Определившись с тем, какие данные нужны, необходимо решить, как и в каком формате мы будем их "вытягивать". Наиболее распространенным форматом до сих пор является двумерный файл. Двумерные файлы бывают двух типов: с записями фиксированной длины и с записями переменной длины (см. главу 8). Как правило, есть большой выбор инструментов для создания таких файлов. Например, если данные находятся в ООТ-системе Огас1е7, то можно использовать SQL*Plus, 3GL с прекомпилятором или Oracle Reports. Существует и целый ряд средств для создания двумерных файлов от третьих фирм. Наш опыт показывает, что самый лучший вариант — 3GL, но это и самый дорогостоящий путь. Конечно, можно попробовать написать программу извлечения на PL/SQL, но может случиться, что по ряду причин (в первую очередь из-за производительности) об этом придется пожалеть. Во многих простых ситуациях — особенно при отсутствии длинных текстовых полей — для извлечения столбцов трудно придумать что-нибудь лучшее, чем следующий подход с использованием SQL*Plus:
set echo off termout off arraysize 100 pagesize 0
spool extract.lis
SELECT cust_id, order_no, order_value, sales_code, order_date
FROM orders
/
spool off
exit
Если требуется выравнивать и ограничивать потенциально длинные поля, мы не рекомендуем использовать для этих операций SQL — 3GL-средства делают эту работу гораздо лучше.
Существует ряд альтернатив двумерным файлам, которые заслуживают внимания. Например, используя средства работы с распределенными базами данных, имеющиеся в SQL*Net и некоторых продуктах Oracle категории Gateway, можно читать данные из системы промышленного уровня и осуществлять их запись непосредственно в таблицы другой системы. В большинстве случаев помещать данные прямо в хранилище данных нельзя, потому что при этом будут пропущены некоторые описанные ниже этапы. Вставлять данные следует в загрузочную секцию.
Этап 2: Фильтрация данных
Нам вряд ли понадобятся все извлеченные данные, за исключением случая, когда выполняется первичное заполнение хранилища. В идеале нам необходимы только те записи, которые изменились или добавились после последнего извлечения. Некоторые хранилища данных полностью очищают и перезагружают при каждой регенерации, но это подходит только для относительно небольших хранилищ, в которых данные регенерируются редко, или для случаев, когда между загрузками подвергается изменению большая доля данных.
Необходимо определить, какие данные изменились с момента последнего извлечения. Если вам очень повезет, то в исходной базе данных будут столбцы DATE_CHANGED и DATE_CREATED и, извлекая данные, вы сможете построить фильтр на базе этих столбцов. Однако даже это не поможет выявить записи, удаленные с момента последней загрузки, если только вам не исключительно повезет и в системе не будет выполняться логическое удаление, при котором создается столбец DATE_DELETED.
Если такой роскоши, как этот столбец, у вас нет, единственный способ определить, что изменилось, — сравнить полный дамп данных с предыдущим. Это можно осуществить путем сортировки файлов по ключам и построчного сравнения. Есть инструменты, которые специально рассчитаны на выполнение этой задачи. Если же вы предпочитаете работать по принципу "сделай сам", то неоценимую помощь вам окажет Unix-команда diff.
Этап 3: Предотвращение потерь ретроспективных данных
Как мы уже говорили, одно из различий между хранилищем данных и традиционной прикладной системой состоит в том, что в хранилище данных, как правило, важно обеспечить поддержку полной ретроспективной картины. Тот факт, что наименование товара когда-то изменилось с Marathon на Snickers, для систем сбыта и ввода заказов практически незаметен. Однако для хранилища данных он имеет колоссальное значение, поскольку изменение фабричной марки может оказать существенное влияние на сбыт и долю рынка — а это как раз то, что мы надеемся узнать при помощи хранилища данных. Давайте предположим, что наименование — просто атрибут в приложениях, обслуживающих сбыт и ввод заказов, а ключом товара является числовой код. При внесении изменения в значение важного атрибута рабочих данных важно не просто переписать эту запись в таблице измерения хранилища данных, а создать ее производную.
Здесь-то и возникает проблема. В одних запросах потребуется рассматривать все факты двух наименований товара как относящиеся к одной строке таблицы измерения, а в других — различать их. Мы рекомендуем создать в таблице измерения столбец вторичного внешнего ключа (номер версии), хотя следует признать, что для пользователя, работающего со средством создания нерегламентированных запросов, это — не очевидное решение.
Такое кодирование смысла при помощи ключей таблиц измерений может оказаться полезным при выполнении многомерного анализа, так как в данном случае мы сможем выбирать, использовать или нет сходство этих ключей в запросах (т.е. рассматривать элементы как один товар или как разные товары) без влияния на производительность. Нужно определить номера версий в мета-данных хранилища (мета-модели мы рассмотрим ниже).
Этап 4: Обработка данных
Формат данных, поступающих из механизмов подачи действующих систем, наверняка будет не тем, который необходим для хранилища, где структуры данных очень денормализованы. Таблицы фактов могут быть довольно близки к требуемой форме, но таблицы измерений, вероятно, потребуют дополнительной обработки и, возможно, объединения. Например, в нашем примере с таблицей продаж (SALES) атрибут Sales Office не создается как отдельное измерение, а содержится в измерении Sales Person. На этом этапе также может выполняться обобщение и агрегирование данных. Тем не менее, как мы уже упоминали, это лучше оставить до момента появления в хранилище новых данных.
Излишне подчеркивать, что, объединяя данные из разных приложений, вы будете вынуждены искать компромиссы, а иногда и принимать волевые решения. Например, может получиться, что данные о продажах, поступившие из одной дочерней компании, содержат только прейскурантную цену, действовавшую на момент сделки, а не полученную сумму, тогда как данные, пришедшие из другой дочерней компании, содержат только цену реализации, а не прейскурантную цену (которая уже не действует). Третья компания, возможно, передаст обе цены, но эти структуры данных не позволяют определить, были получены деньги или нет.
Решение, которое мы выберем для имеющихся в этом примере вариантов, будет в значительной степени зависеть от того, как пользователи будут интерпретировать данные в хранилище. Другими словами, однозначных рекомендаций по этому поводу нет.
Этап 5: Перемещение данных
На этом этапе осуществляется перемещение данных из исходной системы в загрузочную секцию хранилища. Есть много способов достижения этой цели, но, как правило, используется какая-нибудь форма пересылки файлов, особенно если машины находятся на большом расстоянии. Часто данные необходимо перемещать до их преобразования, поскольку в проекте хранилища данных выставляется требование как можно скорее установить полный контроль над данными. Проблемой является также то, что часто очень сложно добиться, чтобы было создано новое 3GL-приложение для мэйнфрейма, а затем найти время для его запуска в рабочем цикле. Однако во многих случаях самым лучшим местом для выполнения по крайней мере первоначальных трансформаций является исходная система.
Этап 6: Загрузка данных в хранилище
Наконец, данные переходят из загрузочной секции непосредственно в хранилище и становятся доступными. Если данные не подлежат "загрузке вразброс" (т.е. когда данные из одной исходной записи направляются в несколько таблиц), то SQL*Loader — почти наверняка самый лучший вариант. Как мы уже говорили, новые возможности параллельной работы SQL*Loader должны обеспечить достаточно эффективную загрузку, особенно когда используется прямая загрузка, позволяющая практически обойтись без дополнительных расходов, связанных с вставкой данных в таблицу Oracle. (Возможности SQL*Loader рассматриваются в главе 8.)
У вас может возникнуть искушение перед загрузкой выбросить индексы и отключить ограничения целостности для таблицы, а потом вновь включить их. Однако не забывайте, что в процессе прямой загрузки слияние старых и новых индексных значений выполняется эффективно. Проблема ограничений весьма сложна, и многие хранилища попросту работают без них. Если проверка реализована нормально, то нарушений ограничений целостности быть не должно. В конце рабочего дня затраты ресурсов центрального процессора и времени на повторное включение ограничений будут огромными.
Этап 7: Сортировка отклоненных записей
Наш опыт показывает, что очень часто при загрузке генерируются исключения. Это может происходить по самым разным причинам. Вот некоторые из них:
• В исходной системе имеются "нечистые" данные, которые не удовлетворяют более жестким ограничениям хранилища (хотя этот вопрос должен быть решен путем очистки данных).
• Неправильный порядок загрузки, например попытка загрузить строку фактов со значением измерения, которое еще предстоит загрузить. Это может указывать на то, что были допущены серьезные просчеты при проектировании процесса загрузки.
• Внутренние проблемы, например недостаток места в хранилище и недостаточный объем области сортировки для перестройки индексов.
• Прерванная, остановленная или частично завершенная загрузка.
• Наличие дублированных данных, что также указывает на просчеты при проектировании или на ошибки в реализации проверки данных.
Хранилище, содержащее не полностью загруженные данные, должно иметь в таблице явный предупреждающий признак. Он должен проверяться пользовательской системой. Это важно, потому что как только неполные данные начинают применяться для анализа, возникают неприятности. На базе этих данных будут принимать стратегические решения, и пользователи будут считать, что они достоверны. Вице-президент вашей компании вряд ли обрадуется, если его уволят за плохие показатели сбыта, которые получены из-за того, что некоторые данные о продажах по его региону не загрузились.
При появлении отброшенных данных на этапе загрузки их нужно проработать, оценить их важность и попытаться исправить. Если исправить данные нельзя, то рекомендуется иметь план экстренных действий — например, восстановления хранилища данных по недавней резервной копии. При принятии таких решительных мер следует помнить, что подающие системы нужно каким-то образом уведомить о том, что они должны вновь включить эти данные при следующем извлечении.
Этап 8: Создание агрегированных значений
Этот этап описан выше в разделе "Правила агрегирования".
Этап 9: Верификация
Если загрузка прошла без ошибок или если исключения были устранены, то система почти готова к работе. Однако мы рекомендуем перед допуском пользователей к системе прогнать несколько верификационных тестов. Цель таких проверок — получить уверенность в надежности данных. Это может быть набор простых SQL-скриптов, проверяющих некоторые очевидные вещи, например:
• если вы суммируете все продажи, используя одно измерение, то полученный результат должен совпадать с суммой, полученной при помощи другого измерения;
• объем продаж за данный месяц должен равняться сумме объемов продаж по дням этого месяца;
• сумма объемов продаж по всем регионам за данный месяц должна равняться сумме объемов продаж по всем продавцам за этот месяц;
• и так далее.
Из-за избыточности, присущей хранилищу данных, должно существовать довольно много вариантов таких проверок. Рекомендуем выбрать необходимое их число и по возможности автоматизировать этот процесс.
Метаданные
Если в хранилище данных используется промежуточное программное обеспечение (middleware), то вам обязательно потребуются метаданные, или метамодель. Метаданные — это данные, описывающие другие данные. Если говорить о проектировании хранилища данных, то это — набор структур данных, которые описывают данные, находящиеся в хранилище, и идентифицируют их источники. Они содержат логику преобразования и трансформации и могут описывать или именовать процессы, выполняющие эту трансформацию и интеграцию (см. рис. 13.9). Метаданные могут также содержать преобразующий уровень для средства создания нерегламентированных запросов или отчетов, используемого для исследования данных. Они могут описывать данные терминами, понятными конечному пользователю, и скрывают все сложности в основных структурах базы данных. Метаданные содержат подробные сведения о том, как пользователь секционировал свои таблицы фактов и какие агрегированные данные имеются для каждой из этих таблиц. С помощью этой информации интеллектуальный инструмент запроса или процессор промежуточного ПО может принимать осмысленные решения о том, как лучше построить эффективный запрос на основании критериев поиска, заданных пользователем. Качественно сопровождаемая метамодель — неоценимый инструмент, даже если не используется промежуточное ПО, которое требует ее наличия.
Рис. 13.9. Важная роль метаданных
Определив структуру рабочих данных, сопоставив ее с исходными данными, поступившими из подающего механизма, и определив правила трансформации данных, можно приступать непосредственно к извлечению и загрузке, как мы говорили выше. Для этого можно приобрести какое-нибудь инструментальное средство, позволяющее автоматизировать процесс, или сделать всю работу самостоятельно.
Типы и методы трансформации данных
Рецепт на все случаи жизни здесь дать очень трудно, потому что мы гарантируем, что в каждом новом проекте хранилища данных вы обнаружите новый тип преобразования. Давайте все же рассмотрим перечень типичных преобразований данных, которые могут вам встретиться.
Закодированные значения
Во многих системах таблицы имеют ключи или идентификаторы, с помощью которых кодируется то или иное значение. Так, номер полиса в системе страхования может образовываться следующим образом:
Policy Number = 92SWMV092,
где:
92= год;
SW = регион или территория;
MV = тип полиса;
092 = порядковый номер.
В этом ключе скрыта очень полезная информация. Мы называем эту информацию скрытой, потому что по ней трудно построить условие запроса. Конечно, можно использовать стандартные метасимволы Oracle и искать все строки, совпадающие с последовательностью "_SW%", чтобы найти все полисы на Юго-Западе, но это очень мудреный и крайне неэффективный способ. Тем не менее, в некоторых старых унаследованных системах, из которых вы будете брать данные, вам может встретиться очень много таких структур и с ними придется что-то делать.
В рамках процесса трансформации можно раскрыть это поле в несколько полей, используя справочные таблицы. Номер полиса в нашем примере можно раскрыть так:
Номер полиса
Год оформления
Регион продажи
Тип полиса
92SWBC092
1992
Юго-Запад
На легковой автомобиль
Эта новая структура содержит ту же информацию (с некоторым избытком), но теперь она дана в гораздо более удобном формате. Такое преобразование часто имеет очень важное значение, потому что некоторые из этих сведений станут измерениями в хранилище данных.
Флаги в многоязычных системах
Многие хранилища данных обеспечивают глобальное представление рынка. В организациях, которые действуют в разных странах, при этом объединяют данные, полученные из многих стран, в том числе и неанглоязычных. Сам по себе факт присутствия описательных данных на иностранном языке может не представлять проблемы, но с кодированными значениями могут быть сложности. Каким бы странным это ни казалось англо-говорящим пользователям, многие их франкоязычные коллеги, кажется, предпочитают использовать "О" и "N" там, где первые используют "Y" и "N", приводя в качестве оправдания тот неоспоримый факт, что oui по-французски — это yes по-английски. Поэтому при помощи метаданных необходимо идентифицировать все столбцы, значения которых берутся из определенного списка, и определить эквивалентные значения для каждого поддерживаемого языка. На этапе трансформации нужно будет перевести все эти значения на один язык.
Манипулирование числовыми данными
Числовые данные могут поступать в самых разнообразных форматах. Возможно, понадобится конвертировать вещественные числа в целые, избавиться от избыточной точности представления и включить экспоненциальный формат (например, 6.2е17). Мэйнфреймовые системы, выдающие двоичные файлы, могут включать в них упакованные десятичные поля, и их символьные строки более чем вероятно будут в формате EBCDIC. Если для обеспечения необходимой конверсии нельзя будет развернуть FTP или SQL*Net, то придется написать для этой цели специальную утилиту.
Манипулирование датами
Oracle справляется с большинством внешних форматов дат, но не со всеми. Есть ряд очень туманных представлений, например количество дней, прошедших с фиксированного момента времени (к примеру, с 1 января 1970 года), которые, возможно, придется преобразовывать в формат, подходящий для Oracle.
Преобразование и слияние ключей
Вот здесь нам и приходится иметь дело с проблемой несовпадения данных, поступающих из разнородных подающих систем. Если речь идет о такой тривиальной вещи, как товары, которые в системе продаж имеют 7-символьный буквенно-цифровой код, а в административной системе — 9-символьный числовой код, то можно обойтись простой справочной таблицей (при условии, что между этими кодами существует однозначное соответствие). В противном случае вновь придется искать компромиссы.
Более неприятная проблема связана с внешними данными, например с данными о покупателях. Самый худший сценарий здесь — когда приходится объединять несколько несравнимых таблиц покупателей из нескольких механизмов подачи данных в одну сводную таблицу измерения. Прежде всего нужно согласовать структуру этой сводной таблицы и первичного ключа. Таблица будет содержать все общие столбцы и ряд столбцов, поступающих только из некоторых механизмов подачи. Ключ, как правило, будет суррогатным. В метамодели должна присутствовать информация, позволяющая преобразовать каждое поле из всех механизмов подачи данных в столбец сводной таблицы измерения. Самое трудное — автоматизировать процесс преобразования так, чтобы Abс Inc. из одной системы соответствовало А. В. С. Inc. из другой. Очевидно, если нельзя выполнить преобразование автоматически, то потребуется вручную преобразовывать записи из механизмов подачи друг в друга. Обязательно сохраняйте все детали этого преобразования в справочных целях для последующих загрузок. Держите все эти детали в метамодели.
Примечание
Преобразование имен и адресов — сложная проблема, имеющая большое значение как для индустрии прямой почтовой рекламы, так и для ряда систем, предназначенных для выявления попыток мошенничества. Это очень специальная область, и есть несколько фирм, которые в ней специализируются.
Выборка данных путем исследования и с помощью
OLAP-инструментов
Инструментальные средства, которые помогают влиятельным пользователям принимать как стратегические, так и тактические бизнес-решения, известны под общим названием средства оперативной аналитической обработки данных (OLAP). Они дают возможность перемещаться по данным, не зная их базовых структур, и представлять эти данные с помощью знакомых пользователям бизнес-терминов. Эти средства позволяют рассматривать данные с нескольких точек зрения, в нескольких измерениях (этот прием называется вращением), а также изменять одно измерение, оставляя другие измерения постоянными, благодаря чему можно моделировать возможные ситуации. OLAP-средства также позволяют пользователю детализировать данные, если необходим более глубокий анализ.
OLAP-средства можно разделить на две категории:
• многомерные (MD-OLAP);
• реляционные (ROLAP).
Отличие между ними состоит в том, что многомерное OLAP-средство взаимодействует с базой данных, имеющей многомерную архитектуру, тогда как реляционное OLAP-средство поддерживает реляционную базу данных. Мы рассматриваем только ROLAP-средства, хотя и подтверждаем, что в некоторых OLAP-средствах между базой данных (реляционной) и внешним интерфейсом имеется многомерный процессор.
Примечание
В Oracle версии 7.3 в Universal Server встроен многомерный процессор (Oracle Express Server). Этот новый процессор работает в совершенно отдельном от реляционного процессора пространстве и в настоящее время не очень хорошо интегрирован. Он выступает в роли независимого склада данных и кэша для данных, находящихся в реляционной базе данных. Поскольку предмет нашей книги — реляционная база данных Oracle, в детали работы многомерного процессора мы углубляться не будем.
Выбор OLAP-средства — важный этап процесса разработки хранилищ данных. Рекомендуем сделать этот выбор как можно раньше, потому что от него могут зависеть некоторые проектные решения. Например, может встать вопрос о том, сколько атомарных данных хранить и сколько агрегированных значений сопровождать. Некоторые OLAP-средства могут выдавать агрегированные значения "на лету" в процессе выполнения. Если в хранилище данных содержатся сведения о продажах по месяцам (но не по кварталам), то цифры за месяц можно получить простым суммированием по группам. Более вероятный сценарий — когда обеспечивается необходимое агрегирование, но нужно показать конкретный экземпляр измерения в процентах к общему итогу или в совокупности с другим измерением. Например:
• Какая доля объема продаж товаров недлительного пользования обеспечена азиатско-тихоокеанским регионом в сентябре?
• Какие подразделения перерасходовали бюджет в прошлом году?
• Кто наши десять ведущих покупателей в мировом масштабе и какой процент доходов получен за счет продаж этим покупателям?
Мораль: чем более сведуще ваше OLAP-средство в получении этих данных, тем меньше вероятность того, что возникнут вопросы такого типа.
Знаете ли Вы, что Программный сниппет (англ. snippet — фрагмент, отрывок) в практике программирования — небольшой фрагмент исходного кода или текста, пригодный для повторного использования. Сниппеты не являются заменой процедур, функций или других подобных понятий структурного программирования. Они обычно используются для более лёгкой читаемости кода функций, которые без их использования выглядят слишком перегруженными деталями, или для устранения повторения одного и того же общего участка кода. Интегрированные среды разработки (IDE) содержат встроенные средства для ввода конструкций языка. Например, в Microsoft Visual Studio, Borland Developer Studio, для этого необходимо ввести ключевое слово и нажать определённую клавишную комбинацию. В IDE Geany существует специальный файл snippets.conf (путь к файлу: /home/user/.config/geany) позволяющий создавать свои сниппеты. Другие программы, такие как Macromedia Dreamweaver и Zend Studio, позволяют использовать сниппеты в Веб-программировании.