Архитектура клиент/сервер в последние пять-шесть лет является одной из самых популярных тем. В мире
Oracle многие ранние приложения клиент/сервер работали прямо-таки катастрофически плохо — одно внутреннее Oracle-приложение давало ответ на тривиальнейший запрос через три минуты. Оно просуществовало в рабочем состоянии всего около трех часов и было отправлено "на свалку". Многие из тех, кто участвовал в разработке этого приложения, до сих пор работают в корпорации Oracle, но предпочитают об этом не вспоминать — это факт просто стерли из корпоративного знания. Большинство причин, приведших к этой катастрофе, устранены благодаря усовершенствованию аппаратных средств и нововведениям в последних версиях ПО, но некоторые из ключевых причин существуют до сих пор. В этой главе мы не раз будем упоминать это неудачное приложение, чтобы напомнить вам, как важно для проектировщиков учитывать особенности среды клиент/сервер.
Два ключевых момента являются залогом успешного проектирования приложений клиент/сервер:
• учет числа операций обмена (пар сообщений), особенно там, где может использоваться глобальная сеть, — именно это и вызвало неудачу упомянутого выше приложения;
• отделение задачи управления пользовательским интерфейсом (роли клиента) от задачи управления данными (роли сервера) — нарушение этого принципа является основной причиной высокоинтенсивного графика сообщений между клиентом и сервером.
Архитектура клиент/сервер — не волшебное средство от перегрузки серверов, но и пренебрегать ей не следует. При разумном применении она дает проектировщику экономически эффективный способ предоставить пользователю высококачественный оперативный интерфейс.
Почему клиент/сервер?
Когда
Microsoft Windows 3.1 стала доминирующей настольной операционной системой, широкое распространение получили привлекательные, удобные в работе персональные приложения, например текстовые процессоры и электронные таблицы. Диапазон средств подготовки документов быстро расширился, в нем появились как средства DTP, так и пакеты создания презентаций. Интерфейсы на базе командной строки, которые продолжали использовать для доступа к приложениям, работающим на корпоративных серверах и серверах подразделений, стали выглядеть менее привлекательно, чем интерфейсы настольных приложений. Кроме того, во многих случаях такие серверы были катастрофически перегружены. Сервер не только нес большую нагрузку, связанную с базой данных, — часто каждое нажатие клавиши на подключенном к нему терминале вызывало прерывание центрального процессора, необходимое для обработки операции ввода-вывода и отображения введенного символа на экране.
Возникло ощущение, что достаточно поставить на рабочий стол дешевый ПК — и нагрузка на сервер тотчас же упадет. К сожалению, это не всегда так. Более точным утверждением будет следующее: при тщательном проектировании архитектура клиент/сервер может обеспечить значительно улучшенный пользовательский интерфейс без значительного повышения рабочей нагрузки на сервер. Одна из ошибок, допускаемых при работе с этой архитектурой, — ожидание резкого повышения пропускной способности сервера.
Переход к архитектуре клиент/сервер все-таки дает одно очень важное преимущество — возможность предоставить графический пользовательский интерфейс (7770), не модернизируя сервер. Стало очевидным, что во многих (даже, может быть, в большинстве) приложениях ГПИ стал считаться обязательным (а не просто желательным) по той простой причине, что пользователи персональных приложений к нему привыкли. Собираясь выполнять серверные приложения на своих ПК, пользователи рассчитывают, что эти приложения будут вести себя, как Windows-приложения, а не как серверные программы.
В большинстве сред архитектура клиент/сервер стала обязательной. Задача проектировщика — реализовать ее так, чтобы она работала, обеспечивала достаточную производительность и была удобной в сопровождении. В этой главе мы рассмотрим вопросы, без решения которых нельзя создать удовлетворительно работающее приложение клиент/сервер. Однако сначала нам нужно уяснить смысл термина "клиент/сервер".
Что такое архитектура клиент/сервер?
Термином "архитектура клиент/сервер" обозначают модель, в которой доступ к базе данных подразделения или к корпоративной базе данных осуществляется с персонального компьютера или рабочей станции. Однако особенных аппаратных средств для архитектуры клиент/сервер не требуется. Это программная архитектура, в которой один набор программных компонентов (клиенты) с помощью сообщений просит другой
набор программных компонентов (серверы) выполнить различные действия. Серверы выполняют затребованные действия и возвращают полученные результаты клиентам (также с помощью сообщений). И клиенты, и серверы посылают свои сообщения не по адресам (как можно предположить), а по именам. В частности, клиенты посылают свои запросы именованным сервисам, а не конкретным машинам, рассчитывая при этом, что в результате разрешения имен будет определен необходимый физический сервер.
Поскольку связь между клиентами и серверами осуществляется с помощью сообщений, клиентская программа и сервис могут работать на разных машинах. Кроме того, поскольку клиентская программа "знает" сервис только по имени, она не осведомлена о местоположении сервера, предоставляющего данный сервис. Все это реализуется благодаря целому ряду уровней программного обеспечения. Естественно, где-то в глубине машины что-то должно знать, где на самом деле находится нужный сервис. В среде
Oracle SQL*Net версии 2 эта информация обычно находится в файле с именем msnames.ora.
Главной чертой архитектуры клиент/сервер является то, что клиент посылает сообщения именованным сервисам. Это дает ряд важных преимуществ:
1. Клиентский и серверный процессы не обязательно должны находиться на одной и той же машине, хотя это вполне допустимо (по данному определению).
2. Клиентский и серверный процессы не обязательно должны работать на однотипных аппаратных средствах или даже под управлением одинаковых операционных систем, если они могут посылать друг другу сообщения. Более того, клиент и сервер не обязательно должны "знать" об аппаратных и программных средах друг друга. Привязка к этим средам — основной источник проблем в приложениях клиент/сервер, потому что какие-либо изменения на клиенте или сервере могут сделать всю систему неработоспособной.
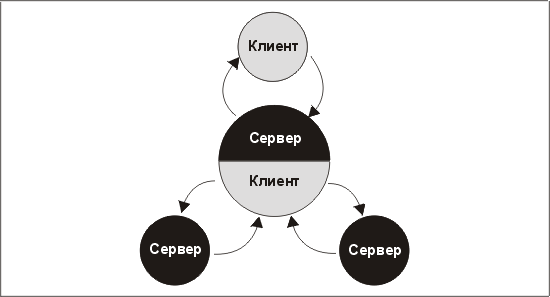
3. Этот процесс может продолжаться до бесконечности: клиент направляет запрос к именованному сервису, который передает его другому именованному сервису, и так далее, как показано на рис. 11.1. Клиент совсем не знает, что первый сервер задействовал других участников (конечно, если не учитывать, что все сетевые операции занимают время и такой "субподряд" часто увеличивает время реакции до неприемлемого). Одна из задач картриджей, которые включаются в архитектуру сетевых вычислений Oracle (NCA), рассмотренную в главе 12, состоит в том, чтобы упростить проектировщикам и программистам такое распределение функций.
Рис. 11.1. Схема вложенной архитектуры клиент/сервер
Все эти положения описывают инкапсуляцию, которая является одним из ключей к успешному проектированию вообще и необходимым условием хорошей работы любого приложения, построенного на клиент-серверных методах. Обработка сообщений, используемая в архитектуре клиент/сервер, знакома каждому, кто работал с Web-броузерами Netscape Navigator или Microsoft Internet Explorer (это приложения клиент/сервер, применяющие протокол HTTP). Web-броузеры также иллюстрируют ту мощь, которую дает возможность работать с несколькими серверами. В более традиционных приложениях клиент/сервер, особенно в тех, которые пользуются инструментальными средствами и серверами БД Oracle, наблюдается тенденция к соединению каждого клиента с одним и только одним сервером.
Об аппаратных средствах
В системах клиент/сервер конца 80-х, начала и середины 90-х годов обычно использовалась довольно мощная рабочая станция, на которой работало ПО на базе оконного интерфейса и которая взаимодействовала с сервером, реализованным на миникомпьютере среднего класса. Первоначально это были Unix-станции с ПО
Motif, а сейчас это чаще всего ПК на элементной базе Intel с операционной системой MS Windows 3.х или MS Windows 95. В настоящее время в качестве клиентской операционной системы все чаще используется Windows NT Workstation. Мы наблюдаем также более активное внедрение Web-технологии, делающей природу клиентского устройства невидимой — не только для сервера, но, при наличии языков вроде Java, и для разработчика кода, предназначенного для работы на этом клиенте.
Во многих ранних реализациях модели клиент/сервер сервером была большая ЭВМ
VAX фирмы Digital с операционной системой VMS. Сегодня сервер в большинстве случаев представляет собой Unix-систему (как правило, с ОС SVR4 и процессором SPARC, Alpha, Intel или PowerPC) с высоким MIPS-показателем и большими объемами внешней (дисковой) памяти. Все чаще в этой роли выступает и ОС Windows NT Server. Чем новее сервер, тем вероятнее, что он будет иметь несколько центральных процессоров и поддерживать несколько гигабайтов оперативной памяти. Многие из первых серверов были существенно ограничены как в мощности процессоров, так и в объемах оперативной памяти.
И клиент, и сервер подключаются к локальной сети, которая используется как магистраль для передачи сообщений. В некоторых случаях клиент и сервер находятся в одной ЛВС, но чаще они общаются через интрасеть — ограниченную совокупность связанных сетей. Доминирующей технологией в Oracle-системах клиент/сервер является
Ethernet, но встречаются и кольцевые сети с маркерным доступом. Клиент и сервер могут использовать любой из множества коммуникационных протоколов, включая вездесущий TCP/IP. Благодаря программам многопротокольного обмена Oracle, клиент и сервер могут пользоваться разными протоколами, при этом ПО обмена предоставляет услуги по преобразованию. В настоящее время лишь ограниченное число приложений по-настоящему работают по Internet — говоря простым языком, по неограниченной совокупности связанных сетей, пользующихся общими протоколами. По мере перехода к Internet появляются клиентские устройства, подключенные по коммутируемым линиям, часто с очень маленькой полосой пропускания.
Такая сильная зависимость от технологии локальных сетей стала проблемой для многих организаций, которым требуется обеспечить поддержку удаленных пользователей, входящих в систему из дома или с клиентского узла. Часто в этих организациях разрабатывали два комплекта приложений, выполняющих одни и те же базовые задачи. Один набор приложений поддерживал интерактивных пользователей, которые подключались непосредственно к ЛВС. Второй набор мог включать высокоуровневый протокол выгрузки-загрузки, обеспечивающий обмен информацией между клиентом и сервером за относительно короткий сеанс и позволяющий пользователям работать в значительной степени автономно. Все было бы намного проще, если бы удаленных пользователей можно было рассматривать как локальных. Поскольку
SQL*Net поддерживает много протоколов, включая WinSock, то существует потенциальная возможность работать, скажем, с Oracle Forms no коммутируемой линии. Проблема в том, что быстродействие линии и задержки при передаче сообщений часто делали это приложение неработоспособным. С появлением более скоростных модемов и технологий (например ISDN) ситуация несколько улучшилась, но, тем не менее, ее всегда следует учитывать при проектировании — приложение должно обеспечивать приемлемую скорость работы по самому медленнодействующему из поддерживаемых им каналов.
Если клиент и сервер находятся в разных сетях, то эти сети нужно каким-то образом связать, для чего часто применяется мост, работающий по глобальной сети. Мосты иногда работают на три порядка медленнее, чем локальные сети, которые они связывают. Однако, как мы увидим, пропускная способность сети обычно не является фактором, ограничивающим производительность систем клиент/сервер. Гораздо большее влияние оказывает время ответа. Именно большое время ответа обрекло на неудачу Oracle-приложение, о котором мы упоминали в начале главы.
Основные задачи проектирования для архитектур клиент/сервер
Проектируя любое приложение клиент/сервер, необходимо обратить особое внимание на две задачи — минимизацию числа операций обмена между клиентом и сервером и тщательный выбор места обработки.
Все операции, в которых участвует аппаратное устройство (диск, дисплей или клавиатура) должны обслуживаться системой, к которой это устройство подключено. Это справедливо даже в случае, когда такая операция выполняется по прямому запросу другой системы. В архитектуре клиент/сервер это происходит довольно часто: одной системе (обычно клиенту) требуется что-то сделать, и она запрашивает сервер. Почти в каждом случае клиенту для продолжения работы приходится ждать ответа сервера.
Теперь мы начинаем понимать, почему число операций обмена и время ответа так важны для производительности систем клиент/сервер. Если время ответа составляет полсекунды и в процессе обработки сервис запрашивается десять раз, то мы потратим минимум пять секунд на ожидание, даже если сервер ответит на каждый отдельный запрос мгновенно. Возможно, вам приходилось встречаться с такой ситуацией, работая с Web-броузером, который выдает 15—20 сообщений о завершении загрузки документа, прежде чем вы наконец увидите результат.
Решение проблемы, связанной с операциями обмена, состоит в том, чтобы свести число запросов к минимуму или, что более правильно, составить сложные запросы типа: "Сделать А, сделать В, сделать С, а затем передать мне ответ". Использование хранимых процедур
PL/SQL в базе данных позволяет упростить реализацию запросов этого вида средствами Oracle. Что же касается Web-броузеров, то, скорее всего, здесь все зависит от способа доставки ответа сервером.
Нам постоянно приходится слышать, как руководители и технические специалисты говорят о быстродействии или пропускной способности сети как о критическом факторе для систем клиент/сервер. Это не всегда так. При использовании
SQL*Net большинство сообщений между клиентом и сервером довольно короткие (десятки или сотни байтов, а не тысячи и миллионы). Поэтому скорость, с которой сеть может передать файл объемом 1 Мбайт, практически не имеет значения — может быть, поэтому поставщики сетей так любят указывать ее! Ключевыми статистическими данными являются время ответа и максимальная скорость передачи пакетов сервером. Время ответа в большинстве TCP/IP-сетей можно измерить с помощью команды ping имя_хоста (или ping -s имя_хоста, если ping просто сообщает о том, что данный хост работает). Это время находится в диапазоне от 1 мс (если клиент и сервер находятся в одной локальной сети) до 400 мс (когда используется мост Х.25). Максимальная скорость передачи пакетов обычно колеблется в пределах от 1000 до 2000 пакетов в секунду, что является абсолютным аппаратным пределом для сетевой интерфейсной платы.
Полоса пропускания сети становится критичной только тогда, когда с сервера на клиент приходится посылать объемные сообщения. Поэтому в любой нормальной структуре клиент/сервер должно быть минимизировано число передаваемых изображений. Разработчики Web-страниц отмечают, что большинство посетителей Web-страницы приходят туда в надежде найти данные, а не графику. У большинства пользователей традиционных приложений клиент/сервер такие же мотивы.
Проектирование для архитектур клиент/сервер
Наша цель как проектировщиков приложений клиент/сервер проста и привлекательна — спроектировать систему так, чтобы и клиент, и сервер выполняли задачи, в которых они сильны (и, следовательно, были освобождены от задач, которые им даются трудно). Клиент обычно качественно обеспечивает работу прикладного интерфейса, а сервер хорошо выполняет обработку совместно используемых данных. Очевидное решение состоит в следующем — реализовать на клиенте прикладной интерфейс, а на сервере (серверах) выполнять все операции над совместно используемыми данными. Чтобы число пакетов было минимальным, запросы к совместно используемым данным объединяются, и многие из них
выполняются за один проход. Звучит это очень просто, но в действительности все гораздо сложнее.
Модель рабочей нагрузки в архитектуре клиент/сервер
Модель, представленная на рис. 11.2, была предложена специалистами
Gartner Group для того, чтобы показать разнообразие вариантов распределения рабочей нагрузки между клиентом и сервером.
Рис. 11.2. Типы вычислений клиент/сервер
Эта модель распределения рабочей нагрузки оказалась полезной, и ее можно распространить на трехуровневые архитектуры, но она не дает возможности увидеть общую ошибку, которая заключается в попытке распределить все функции — представления данных, логики и управления данными — между клиентом и сервером. Чем жестче вы примените инкапсуляцию к своей схеме, тем меньше вероятность того, что
маленькие фрагменты логики управления представлением окажутся глубоко запрятанными в коде управления данными (во многих случаях и довольно большие сегменты задачи управления данными оказываются закодированными непосредственно в уровне представления). В противном случае вы получите сложный, очень "чувствительный" к изменениям прикладной код, который часто невозможно сопровождать с какой-либо степенью надежности. К сожалению, такой стиль очень распространен в проектах на базе Oracle. В значительной степени это является наследием SQL*Forms версий 2 и 3, способствующих созданию так называемых ключевых триггеров (для управления представлением или интерфейсами), которые свободно могли содержать SQL-предложения и вызовы процедур базы данных.
Поскольку возможности
SQL*Forms версии 2 в плане трансформации данных были ограничены, программисты также сочли необходимым встраивать правила форматирования в код управления данными (на SQL). Эта практика все еще преобладает сегодня в триггерах Oracle Forms, и они содержат, например, такие предложения:
SELECT INITCAP(cust_name)
INTO cust_name
FROM custs
WHERE cust_id = :cust_id;
В этом примере смешаны требование к представлению данных (интересующее только клиент) и операция управления данными (которая должна выполняться на сервере). Если теперь инкапсулировать выборку данных на
то окажется, что мы прячем трансформацию данных внутри пакета или стоим перед необходимостью передавать форматирующий код на сервер. Гораздо проще просто возвращать данные с сервера в той форме, в которой они там хранятся, и выполнять необходимое форматирование на клиенте.
Кроме того, на рис. 11.2 не отражены
n-уровневые архитектуры. В этих архитектурах уровни управления приложениями, содержащие прикладную логику, находятся между клиентом и сервером данных.
Важность "тонких клиентов"
О различиях между интерфейсом и процессом мы поговорим в главе
16. Наш подход к вычислениям клиент/сервер полностью соответствует изложенной там концепции. В приложении клиент/сервер на базе Oracle нам следует стремиться к чему-то среднему между распределенной логикой и удаленным представлением данных (см. рис. 11.2) и попытаться добиться, чтобы клиент решал только непосредственно относящиеся к пользовательскому интерфейсу задачи, а сервер — все остальные, включая всю обработку запросов и обновлений, а также внедрение правил обработки данных и бизнес-правил.
Ясно, что клиент "сведущ" в управлении представлением данных пользователю, будь то данные в графической форме, электронная таблица или экран на базе форм. Клиент обрабатывает все события, связанные с клавиатурой и мышью, рисует изображение экранной формы и позволяет манипулировать объектами, представленными на экране,
и перемещаться по ним, Конечно, вы не захотите, чтобы клиентское ПО запрашивало с сервера массу необработанных данных (например, целые таблицы), а затем отбирало нужные вам данные. Это не только приведет к увеличению графика в сети, но и значительно увеличит нагрузку на сервер. Тем не менее, мы встречали многих проектировщиков с иррациональной верой в то, что данные можно извлекать из базы данных и передавать по сети, не создавая сколько-нибудь значительной нагрузки на сервер.
Сервер БД
Oracle оптимизирован для селективной выборки, т.е. для выполнения реляционных операций, таких как фильтрация, проецирование и соединение, над большими объемами данных. Серверное ПО рассчитано на прием запросов, их обработку и возвращение статуса и (или) данных за минимальное время.
Не нужно, чтобы сервер решал такие задачи, как рисование экранных изображений и выполнение программ повышения производительности клиента. Никто, находясь в здравом уме, не порекомендовал бы такой подход. Однако просто удивительно, как много мы встречали организаций, где все клиентское ПО содержат на совместно используемом диске сервера. Почему? Потому что это облегчает распространение ПО и гарантирует, что все клиенты используют одну и ту же версию. Клиентское ПО обычно состоит из ядра, выполняющего базовые функции (оно реализовано в исполняемом файле), и набора подпрограмм в библиотеках связей (в
Microsoft Windows они называются динамически загружаемыми библиотеками, или DLL). Если при обращении к подпрограмме DLL не находится в памяти, приходится загружать с сервера довольно большой двоичный файл. Это может происходить регулярно, если на клиенте недостаточно памяти.
Здесь мы говорим о том, что проблема с подгрузкой исполняемых файлов характерна для ПК, однако необходимо признать, что именно в этом направлении движется компьютерная индустрия. Сначала это движение стимулировала
World Wide Web, а теперь — поддержка, которую Oracle оказывает концепции сетевого компьютера.
Традиционные системы клиент/сервер, как правило, включают клиентов только одного типа, но все чаще и чаще возникает потребность в оказании прикладных услуг как традиционным рабочим станциям, так и через
Web-броузеры. В среде такого типа лучше вообще не иметь на клиенте никакой прикладной логики.
Сетевой компьютер
Oracle
Что представляет собой сетевой компьютер? Идея состоит в том, что если вы используете Web-броузер, поддерживающий
Java, то устройство-клиент может содержать только программы для загрузки клиента. Остальная часть нужного кода поступает по сети вместе с данными в форме апплетов. Для успешной работы размер апплетов должен соответствовать пропускной способности сети, а устройство-клиент должно энергично кэшировать принимаемые им апплеты, чтобы, когда они потребуются, их не пришлось загружать вновь. При этом возникает вопрос о непротиворечивости кэша, т.е. об обеспечении того, чтобы кэш клиента всегда содержал самую последнюю информацию. Если вы используете Netscape, то это обычно делается путем установки времени, по истечении которого элементы кэша считаются устаревшими, равным одним суткам. Таким образом, клиент будет использовать устаревшую страницу максимум 24 часа.
Основы SQL*Net
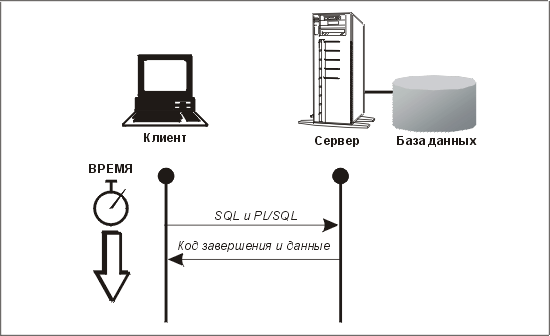
Высокоуровневый протокол, с которым работает
SQL*Net, очень прост. По сути дела, клиент передает SQL-предложения или анонимные блоки PL/SQL на сервер для выполнения, сервер обрабатывает их и посылает данные обратно клиенту. Если предложением является SELECT, то возвращаются строки (в ответ на команду FETCH, посланную клиентом). Для DML-операторов и блоков PL/SQL возвращаемые данные представляют собой код завершения оператора и выходные параметры, если они есть. Это показано на рис. 11.3.
Рис. 11.3. Высокоуровневый протокол архитектуры клиент/сервер
Oracle
В
Oracle полная архитектура клиент/сервер реализована начиная с версии 5, и эта архитектура используется даже в случае, если клиент и сервер находятся на одной машине. Как правило, Oracle применяет двухзадачную архитектуру, в которой клиент и сервер представляют собой два отдельных процесса (даже если они расположены на одной машине). На некоторых платформах их можно объединить в один процесс, хотя обычно это не рекомендуется из-за того, что прикладная программа может повредить SGA и, следовательно, саму базу данных. Многие операционные системы, включая MVS разработки IBM и VMS разработки Digital, допускают использование привилегированных библиотек. При их наличии приложение может вызвать библиотечную программу, например сервер БД, которая обладает привилегией просматривать SGA, даже несмотря на то, что вызывающая программа этого права не имеет. Отметим, что при оперативной обработке транзакций однозадачная архитектура Oracle во многих случаях работает приблизительно на 20% быстрее, чем двухзадачная, благодаря существенному сокращению числа переключений контекста в операционной системе.
В
Oracle7 разработчики корпорации сделали ряд важных шагов для повышения эффективности своей архитектуры клиент/сервер. Во многих случаях число сетевых пар (сообщений от клиента к серверу и обратно) необходимое для выполнения одного оператора, сокращено с четырех до одной.
Анатомия SQL-предложения
Чтобы понять, какое влияние оказывают наши приложения на сетевой трафик, необходимо изучить механизм обработки SQL-предложений в базе данных
Oracle.
Рассмотрим следующее предложение
SELECT:
SELECT ord.id
, ord.value
INTO :ord_id
, ;ord_val
FROM orders ord
WHERE ord.cust_id = :ord.cust_id
AND ord.value > :threshold;
Процесс обработки этого простого предложения можно разбить на пять этапов: разбор, определение, привязка, выполнение, выборка. Если не используются средства отложенных вызовов
Oracle, то для выполнения каждого этапа требуется минимум одна пара сетевых сообщений. Например, для выполнения этапа разбора клиент обычно посылает текст предложения на сервер, а сервер отвечает кодом статуса, сигнализирующим об успехе или неудаче. (Этапы, перечисленные в этом разделе, должны быть хорошо знакомы всем, кто программировал с помощью Oracle Call Interface (OCI), где их приходится программировать явно.)
Примечание
Большинство клиентских программ
Oracle перед выдачей SQL-предложений серверу выполняют над ними ряд преобразований. Обычно они удаляют ненужные пробельные символы, переводят предложение в верхний регистр и нумеруют ссылки на связанные переменные. Помимо этого, они обычно удаляют фразу INTO, потому что часть этой операции выполняется клиентом. Так, приведенный выше оператор можно послать на сервер и в таком виде:
SELECT ord.id,ord.value
FROM orders ord
WHERE ord.cust_id = :1 AND ord.value > :2
SQL*Plus, SQL*DBA и Server Manager никаких преобразований не производят.
Ниже следует краткое описание каждого из пяти этапов обработки SQL-предложения.
Разбор (Parse)
SQL-предложение посылается на сервер в виде текстовой строки. Сервер изучает строку, разбивает ее на составные части и проверяет. Проверка касается не только синтаксиса
; Oracle проверяет, чтобы все указанные в предложении объекты действительно существовали в базе данных и были доступны для вызывающего пользователя. Очевидно, проверяются имена таблиц, столбцов, представлений и последовательностей. В результате разбора создается дерево разбора — внутреннее представление SQL-предложения, которое хранится на сервере.
Определение (Define)
Клиент запрашивает свойства всех переменных в списке
SELECT (в примере — ORDERS.ID и ORDERS.VALUE). Чтобы ответить на запрос, сервер использует дерево разбора, построенное на предыдущем этапе.
Привязка (Bind)
Клиент определяет фактические значения всех связанных переменных в предложении (в данном примере —
:ord_id) и передает эти значения на сервер.
Выполнение (Execute)
Клиент просит сервер обработать предложение и создать совокупность результатов. В этой точке никакие данные-результаты клиенту не возвращаются, а передается лишь статус. Если запрос содержит фразу
FOR UPDATE, то для завершения этапа выполнения необходимо посетить и заблокировать все соответствующие строки. Однако совокупность результатов все равно размещается на сервере. Если есть связанные переменные, то первое действие сервера — попросить клиента предоставить их текущие значения. В очень старых версиях это делалось по одной переменной за раз, но в версии 5.1 была введена быстрая привязка, при которой все необходимые значения запрашиваются в одной операции. В Oracle7 библиотечные программы на клиенте (зная, что для выполнения оператора необходимы значения связанных переменных) посылают их автоматически с запросом на выполнение.
Выборка (Fetch)
Клиент просит сервер передать подмножество данных, полученное при выполнении запроса. Объем возвращаемых данных зависит от величины (размерности) массива переменных в списке
SELECT. В общем случае выборка данных-результатов повторяется до тех пор, пока не будет выбран необходимый (например, для заполнения буфера или экранной формы) объем данных или пока не будет возвращен признак окончания выборки. Все это контролируется приложением.
Теперь давайте несколько уточним эту модель выполнения SQL-предложения и выясним, как она влияет на проектирование для архитектуру клиент/сервер.
1. Если SQL-предложение выполняется несколько раз, то обычно нет необходимости разбирать или определять его каждый раз, потому что и клиент, и сервер могут запомнить ранее выполненное предложение. Повторная привязка необходима лишь в случае, когда после предыдущего выполнения адреса (а не значения) каких-либо связанных переменных изменились.
2. DML-операторы (INSERT, UPDATE и DELETE) не требуют выборки. Оператор завершается после выполнения.
3. В Oracle есть механизм, известный как Deferred Call Interface (интерфейс отложенных вызовов), который иногда называют UPIALL. Он позволяет объединить этапы разбора, определения и привязки с выполнением, хранить результаты на клиенте и выдавать их только при получении запроса на выполнение. Это может значительно снизить сетевой трафик, а также повысить общую пропускную способность и уменьшить время реакции в системе клиент/сервер благодаря меньшему числу пакетов данных (правда, те, которые используются, большего размера). Этот протокол применяется в более новых инструментальных средствах Oracle, например Oracle Forms версий 4.0 и 4.5. Если для разработки используется Рго*С, следует инсталлировать версию 1.6, 2.0 или выше, иначе эту технологию применять будет невозможно.
4. Блоки PL/SQL похожи на DML-операторы тем, что не требуют выборки. Такой блок просто выполняется. Все ссылки на внешние переменные в блоке PL/SQL трактуются как связанные переменные (даже если они выбираются в пределах блока). Использование блока PL/SQL для группировки SQL-предложений — хороший способ сокращения сетевого графика. В качестве примера возьмем клиентское приложение, которое изменяет сальдо двух бухгалтерских таблиц на 10%:
UPDATE checking_accounts cac
SET cac.balance = cac.balance * 1.1
WHERE cac.cus_id = :cus_id;
UPDATE savings_accounts sac
SET sac.balance = sac.balance * 1.1
WHERE sac.cus_id = :cus_id;
Даже при полном объединении вызовов это потребует двух пар сообщений — по одной для каждого SQL-предложения. Если эти два предложения заключить в операторы
BEGIN ... END, образующие блок PL/SQL, то в лучшем случае нужна будет всего одна пара сообщений. (Еще лучше инкапсулировать это действие и перенести эти два предложения на сервер как хранимую процедуру. Чтобы выполнить действие, программа запустит анонимный блок, содержащий вызов хранимой процедуры.) Выполнение операции клиент/сервер в одной паре сообщений дает хороший результат во всех случаях. Это всегда должно быть целью, проектировщика, если предполагается, что связь между клиентом и сервером будет осуществляться через глобальную сеть.
Появляется промежуточное звено
Термин "промежуточное ПО" сейчас очень моден, и, как многими модными терминами, им злоупотребляют. Производители программ, стараясь не отстать от новых веяний, выпускают такие "промежуточные" продукты, как драйверы
ODBC.
Что же понимать под промежуточным ПО в контексте нашей главной темы — проектирование баз данных? В архитектуре клиент/сервер мы рассматривали внешнее приложение (клиент), которое инициирует выполнение
SQL и PL/SQL в базе данных (на сервере). Промежуточное ПО — это слой программного обеспечения, находящийся между клиентом и сервером. Оно может располагаться на компьютере-сервере, компьютере-клиенте или на отдельной машине. Для повышения пропускной способности в нем может использоваться менеджер транзакций, такой как Tuxedo или CICS-система.
Одно из главных обоснований существования промежуточного ПО — обеспечение независимости внешнего приложения от базы данных. В этом случае клиент может использовать собственный язык высокого уровня или протокол для взаимодействия с промежуточным ПО. Ему будет совершенно безразлично, куда передает информацию это промежуточное ПО — в базу данных
Oracle или в базу данных Sybase. Если же такое ПО генерирует SQL, строго соответствующий стандарту ANSI-92, то становится простой замена одной СУБД на другую. Даже если такая совместимость с базами данных других производителей не требуется, промежуточное ПО может оградить клиентское ПО от влияния изменений, вносимых в структуру базы данных на сервере. Другими словами, здесь мы имеем еще один способ инкапсуляции.
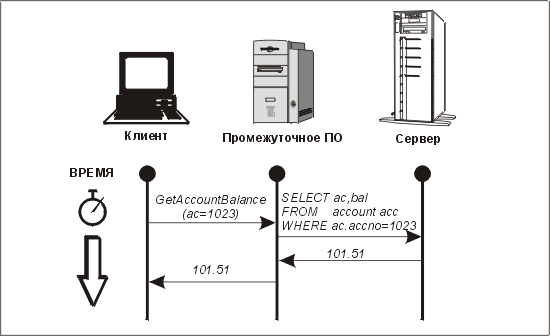
Это демонстрирует простой пример на рис. 11.4. Промежуточное ПО принимает высокоуровневый вызов от клиента через интерфейс прикладного программирования
(API) и конвертирует его в SQL-предложение. В этом простом примере промежуточному ПО не нужно конвертировать возвращаемые с сервера данные — оно просто передает их клиенту. Промежуточное ПО должно обладать значительным интеллектом или иметь исключительно сложный преобразующий уровень, предназначенный для конвертирования вызовов в SQL.
Рис. 11.4. Использование промежуточного ПО между клиентом и сервером
Одним из относительно дешевых и простых вариантов реализации решения с промежуточным ПО является использование на клиенте только вызовов хранимых процедур и функций и разработка библиотеки или пакета процедур либо функций для обслуживания всех запросов приложения. Иногда это решение реализуют частично и сохраняют в клиентском приложении все предложения SELECT, которые могут возвращать несколько строк. В версии 7.2 появилась возможность передавать курсоры между приложениями, что позволяет достаточно изящным способом послать "многострочные" предложения SELECT для выполнения на сервер и передать результаты обратно. В версии 7.3 и в PL/SQL версии 2.3 поддержка этих функциональных возможностей значительно усовершенствована. Помимо сокращения сетевых затрат, этот подход к проектированию позволяет использовать разделяемые курсоры и уменьшить затраты на синтаксический анализ.
Предупреждение
Как мы говорили, создание пакетов прикладных сервисов с целью сокращения объема необходимых преобразований в промежуточном ПО становится более сложной задачей, когда речь заходит о поддержке запросов, возвращающих группу строк. Задача становится на порядок сложнее, если конечному пользователю требуются полные возможности для создания нерегламентированных запросов. Рекомендуем на уровне проектирования этим не заниматься.
Преимущество промежуточного ПО — способность избежать зависимости от базы данных для наших приложений, однако каковы при этом затраты и риски? Конечно, с появлением нового уровня, который может быть потенциальным источником проблем, становится более сложной диагностика. Может пострадать и производительность, поскольку промежуточное ПО должно обслуживать запросы индивидуально и многозадачную работу может не обеспечить. В результате запросы могут попадать в очередь и ждать освобождения промежуточного ПО. Эти риски можно уменьшить с помощью менеджера транзакций, управляющего промежуточным ПО.
Один из побочных эффектов от использования промежуточного ПО, который может вызвать проблемы с производительностью, касается применения подсказок в предложениях SQL. Во-первых, некоторые драйверы ODBC "рационализируют" SQL, вырезая комментарии перед направлением предложений на сервер. Но ведь в комментариях содержатся подсказки для оптимизатора по стоимости в Огас1е7. Во-вторых, драйверы ODBC часто переформатируют SQL, и при этом могут быть исключены другие использованные методы настройки. И кроме того, иногда приложение на клиенте обладает сведениями об объеме или содержимом ожидаемых данных, которые нельзя просто так передать промежуточному ПО или конвертировать с его помощью. Вследствие этого возникает мысль о написании промежуточных программных компонентов для конкретных приложений, а это противоречит концепции промежуточного ПО. Очень разумным подходом является ввод уровня прикладной логики, который изолирует управление интерфейсом на клиенте от управления данными на сервере базы данных.
Однако наличие такого среднего уровня означает, что мы уже перешли от простой архитектуры клиент/сервер к трехуровневой архитектуре. Эта архитектура обладает значительными теоретическими преимуществами, но инструментальные средства Oracle поддерживают ее плохо. Кроме того, она не очень популярна в сообществе пользователей Oracle, несмотря на то, что архитектура сетевых вычислений Oracle должна обеспечивать непосредственную поддержку трехуровневой обработки. (Эта тема также обсуждается в главе 16.)
Приемы проектирования для архитектур клиент/сервер
В этом разделе описываются возможности среды клиент/сервер, о которых необходимо знать при проектировании приложений для этой среды.
Кэширование неизменяемых данных на клиенте
Рассмотрим статическую справочную таблицу, например таблицу, определяющую границы финансовых месяцев на предприятии, которое слишком привержено собственным правилам и не пользуется обычными календарными месяцами.
Таблица 11.1. Таблица финансовых месяцев
FISCAL MONTHS
FISCAL_MONTH
START
END
1 2 3 и т.д.
5 апреля 1996 г. 6 мая 1996 г. 5 июня 1996 г. и т.д.
5 мая 1996 г. 4 июня 1996 г. 7 июля 1996 г. и т.д.
Предположим, что многие основные сущности имеют значения столбца
FISCAL_MONTH в качестве внешнего ключа. В клиентских приложениях часто необходимо выдать перечень финансовых месяцев, чтобы пользователь мог щелчком указать нужный месяц. При каждом выполнении этой операции клиент запрашивает данные с сервера, даже несмотря на то, что со времени предыдущего использования они не изменились.
Ясно, что для этой совершенно ненужной пересылки данных мы задействуем ресурсы сети и центрального процессора сервера. Очевидное решение — извлечь эти данные при первом обращении к ним пользовательского интерфейса, а затем хранить их на клиенте для обслуживания последующих запросов. Если объем этих данных невелик, то клиентское ПО может направлять запрос на их получение при запуске приложения на клиенте. Таким образом
, программа пользовательского интерфейса всегда может рассчитывать на их наличие. Реализация этого механизма зависит от клиентскогоПО. Например, в приложении на Visual C++ можно выделять память динамически и хранить эти данные в связанных списках. В Oracle Forms 4.5 для хранения кэшированных значений можно пользоваться группами записей.
У вас может возникнуть идея хранить кэшированные табличные данные в файле на локальном диске, особенно в случае, если клиентское приложение создается на языке третьего поколения. Обычно мы не рекомендуем такой подход, потому что, по сути, это реализация сервера распределенной базы данных. Кроме того, объем кэшированных данных, как правило, относительно мал (несколько килобайтов), так что для кэширования требуется очень небольшой объем дополнительной памяти. Причина, по которой кэши можно делать маленькими, состоит в том, что мы основываем их существование на утверждении, что в них хранятся многократно отображаемые данные. А часто отображаемые данные, за исключением мультимедийных, должны иметь маленький объем.
Давайте в качестве примера рассмотрим таблицу, содержащую описание деталей. Может оказаться, что из перечисленных в ней 100000 деталей один клиент часто выбирает лишь 100. Если описания деталей в процессе обработки системой клиент/сервер никогда не изменяются (или допускается использование устаревшего описания), то можно реализовать на клиенте механизм движущегося кэша
(rolling cache), или исключения давно использовавшихся данных (least recently used).
Этот механизм работает так. Каждый запрос сначала проверяется на предмет того, есть ли данные в кэше. Если данные есть, то они извлекаются из кэша. В противном случае данные передаются с сервера, добавляются в кэш, а затем их получает программа интерфейса. Таким образом, данные вызвавшей программе всегда передаются из кэша, а не прямо с сервера. Каждый элемент данных (в примере — описание детали) выбирается в клиентском сеансе только один раз. К сожалению, если длительность этого сеанса очень велика, то кэш не только может устареть, но и значительно увеличиться в объеме. Однако эти проблемы можно решить, если у вас есть время
и энергия на проектирование и создание подходящего решения.
Проблему увеличения кэша можно решить, если ограничить объем кэша и хранить в нем лишь самые последние из использовавшихся элементов. Этот метод обычно называют исключением давно использовавшихся данных, потому что при добавлении нового элемента в полный кэш элемент, который не использовался дольше всех, затирается.
Более серьезная задача — обеспечение непротиворечивости данных кэша. Ее можно попытаться решить, применив автоматическое удаление кэшированных элементов по истечении заданного временного промежутка (например, 30 минут) либо при помощи триггера на сервере, который будет заносить дату и время последнего изменения в базовой таблице. Клиентская программа может периодически проверять это производное поле и делать соответствующий кэш недействительным, если данные на сервере с момента начала загрузки кэша изменились. Если клиентская операционная система поддерживает удаленные запросы
(RPC), то сервер может автоматически делать кэш недействительным, когда вносится изменение. Однако это решение очень сложное в техническом плане и может вызвать значительные проблемы с производительностью, если число клиентов очень велико или если в кэшированные объекты часто вносятся изменения.
Самая серьезная проблема при любом виде кэша — простом или сложном — заключается в том, что если отсутствует промежуточное ПО, "скрывающее" кэш, то программа пользовательского интерфейса должна знать о существовании кэша и уметь запрашивать из него данные. Таким образом, независимо от того, используется промежуточное ПО или нет, выборка данных, которые могут быть локально кэшированы, не должна осуществляться через
SQL, за исключением случая, когда на клиенте работает экземпляр базы данных — однако при этом мы уже имеем дело не только с архитектурой клиент-сервер, а еще и с распределенной базой данных. (Эта тема изложена здесь с точки зрения вычислений клиент/сервер. Более подробно распределение данных рассматривается в главе 12.)
Кэши приложений дают наибольшую выгоду в тех приложениях клиент/сервер, где задействуется глобальная сеть. При этом методе также экономятся ресурсы центрального процессора, даже если и клиент, и сервер работают на одной машине. Однако если ожидается большой объем кэша и сложный алгоритм управления им, то мы рекомендуем рассмотреть альтернативные проектные решения; они могут предполагать наличие распределенной базы данных. Помимо всего прочего, рассматриваемый нами кэш является, по сути, созданной в рамках проекта резидентной базой данных, а
Oracle уже затратила массу времени и денег на реализацию серверного кода для сервера базы данных. Сервер Oracle, несмотря на потенциально огромную потребность в памяти и административном внимании, все же работает, тогда как очень сложный администратор кэшей, созданный в рамках проекта, может и не работать.
Кэш на стороне клиента — анализ проблемы
Если вы знакомы с броузером
Netscape Navigator, то уже должны были привыкнуть к концепции движущегося кэша на стороне клиента. Вполне вероятно, что вы сталкивались и с проблемой непротиворечивости кэша. Опции Navigator позволяют определить, сохранять ли загруженные страницы локально (на диске) и сколько их можно хранить. Эта возможность исключительно полезна, потому что позволяет избежать задержек, которые наблюдаются при загрузке Web-страниц, содержащих несколько сотен килобайтов растровой графики.
Клиент/сервер и распределенные базы данных
Что делать, если мы имеем большие объемы неизменных данных (например, описаний товаров), где нет часто используемых записей, которые можно кэшировать? Если нельзя предсказать, какие записи потребуются, то единственный способ устранить передачу сообщений для этих данных — это держать их копию в хранилище на клиенте или, как мы скоро увидим, ближе к клиенту, чем к центральному серверу.
Если данные извлечь из базы данных и поместить во внешние файлы, могут возникнуть очень сложные проблемы. Конечно, мы можем обновлять эти файлы каждый вечер, чтобы обеспечить актуальность данных, однако преимущество хранения их в базе данных состоит в том, что РСУБД сама гарантирует их целостность. Как только мы начинаем полагаться на данные, хранящиеся вне базы данных, мы открываем путь нарушению целостности. Например, кто-нибудь может отредактировать — случайно или намеренно — локальный файл. Если вечером часть сети выйдет из строя и мы не выполним обновление, может оказаться, что наш файл не будет соответствовать файлам других пользователей. Конечно, можно написать скрипты, которые будут "ползать" по сети и проверять актуальность каждой копии, но ведь цель всех наших усилий — уменьшить сетевой трафик.
К тому же, очень немногие ориентированные на базы данных клиентские средства сильны в файловом вводе-выводе. Необходимо подумать и том, как достичь приемлемой производительности при обработке запросов. Допустим, что при необходимости хранить важные данные локально, мы будем хранить их в базе данных (либо
Oracle, либо не-Oracle). Кроме того, предположим, что локальная база данных представляет собой версию Oracle, которая либо поддерживает Distributed Database Option, либо способна работать с этой опцией. Это очень важно, поскольку очень немногие разработчики умеют хорошо обращаться с несколькими одновременно открытыми соединениями с базой данных. Кроме того, насколько мы знаем, только немногие широко используемые средства ускоренной разработки приложений (УРП) обеспечивают полную поддержку открытия одновременно нескольких соединений с базой данных. Как правило, множественные соединения поддерживаются только из языков третьего поколения (и, как ни странно, с помощью редко используемой команды COPY из SQL*Plus).
Если у нас есть и локальная, и удаленная базы данных и мы должны работать только с одним соединением, то должны соединяться с локальной базой данных, потому что это — единственный путь, которым мы можем добраться до нее без создания графика сообщений. Ведь мы пытаемся уменьшить трафик сообщений. Таким образом, для каждого пользователя его экземпляр локальной базы данных становится пунктом управления всей его работой. Из этого следует, что любая попытка обеспечить прозрачность расположения может вызвать (и, вероятно, вызовет) появление сетевых соединений
(cross-network joins) и распределенных транзакций, требующих использования двухфазной фиксации (описанной в главе 12).
Хотя в каждом последующем выпуске
Oracle7 производительность сетевых соединений улучшалась, мы не советуем слепо верить в то, что эти соединения будут оптимизированы, как планировалось. Рекомендуем также точно оценить уровень оптимизации в версии (версиях), которая у вас работает. Если же имеется не-0гас1е-сервер с доступом через шлюзовые продукты, то необходимо еще более тщательное исследование.
Самый крайний случай, с которым мы встречались, — когда приложение
Microsoft Access соединяло локальную таблицу Access с таблицей Oracle на удаленном сервере. Оказалось, что вся таблица Oracle пересылалась на клиент, где выполнялось соединение, несмотря на то, что SQL-предложение содержало условие, по которому сервер возвращал всего одну строку.
Примечание
Последние версии оптимизатора
Oracle способны экспортировать операцию соединения на удаленный сервер, тогда как в ранних версиях соединение всегда выполнялось в управляющем экземпляре.
Появление базы данных второго уровня
Наверно, многие читатели уже обеспокоены тем, что мы предлагаем инсталлировать
Oracle на каждом клиенте в сети клиент/сервер. Помимо затрат на лицензии Oracle и приобретение аппаратных средств, достаточных для работы этих экземпляров с приемлемой производительностью, есть еще и стоимость обслуживания, которая, вероятно, сделает такой подход непрактичным, так как придется администрировать слишком много баз данных Oracle. Кроме того, даже незначительное обновление в распределенных справочных таблицах может повлечь за собой серьезное повышение нагрузки на сеть.
Есть компромиссный подход, который уже успешно используется на ряда узлов. Если допустить, что время ответа по локальной сети не оказывает отрицательного влияния на производительность, то можно осуществлять обращение по локальной сети для поиска в справочных таблицах. Таким образом, в любой среде, где есть группы пользователей, подключенных к одной локальной сети или к смежным локальным сетям, имеет смысл разместить справочную базу данных на сервере в локальной сети и обрабатывать все обращения к главному серверу через этот промежуточный сервер. Такая конфигурация показана на рис. 11.5.
Рис. 11.5. Использование локальных серверов БД для справочных данных в сети
Актуальность справочных данных на промежуточных серверах можно обеспечивать либо с помощью снимков, либо путем симметричной репликации. Этот подход позволяет освободить главный, центральный сервер от значительной доли нагрузки, связанной с обработкой запросов, сократив при этом число операций обмена через глобальную сеть. Если предположить, что в большинстве обновляющих транзакций с клиента обновления будут выполняться только на главном сервере, то расходы на двухфазную фиксацию будут низкими, так как промежуточный сервер попросит главный сервер выполнить однофазную фиксацию. (Снимки и симметричная репликация подробно описаны в главе 12.)
Если вы внедряете эту архитектуру, настоятельно рекомендуем сделать ее прозрачной путем использования синонимов в промежуточных базах данных. Это позволит клиентам на удаленных узлах, которые недостаточно многочисленны для того, чтобы оправдать наличие локального сервера, связываться непосредственно с главным сервером и использовать идентичную версию данного приложения. Кроме того, если обеспечена прозрачность распределения данных для приложения, то администратор БД сможет изменять стратегию распределения, не меняя само приложение.
К сведению
В некоторых средах клиент/сервер может понадобиться аутентификация приложений, т.е. обеспечение того, чтобы приложение защищенным способом указывало свою версию серверному коду. Эти проблемы можно свести к минимуму, используя в качестве клиентской технологии
Web-броузеры или сетевые компьютеры, потому что при этом клиентская логика представляет собой апплет, загружаемый с сервера. Хотя это и не относится к теме нашей книги, отметим все же, что использование других форм промежуточных серверов, особенно файловых серверов, может существенно снизить административные расходы на распределение прикладного программного обеспечения. Кроме того, эти серверы делают более сложной для пользователя замену разрешенной версии клиентского приложения неразрешенной.
Сокращение сетевого трафика с помощью представлений
Давайте рассмотрим проблему графика сообщений. Допустим, у нас есть приложение, отображающее сетку (иногда называемую многострочным блоком) заказов. В таблице
ORDERS есть столбец CUS_ID, который содержит уникальный идентификатор покупателя, разместившего заказ. Нашему приложению нужно отобразить имя покупателя, которое должно быть выбрано из таблицы CUSTOMERS. Предположим, что это приложение предстоит разрабатывать в Oracle Forms 4.0/4.5.
Поскольку
Customer Name не является столбцом таблицы ORDERS, нам потребуется написать (или сгенерировать) код для управления этим полем. Нам нужно указать имя покупателя, когда мы отображаем заказ, и, возможно, представить в этом поле список значений, чтобы при создании нового заказа пользователь мог выбрать покупателя из списка.
Вероятно, первое, что приходит вам в голову (особенно если вы такой же старый Forms-хакер, как мы), — это мысль реализовать эти функциональные возможности как триггер
POST-QUERY:
POST-QUERY
SELECT cus.name
INTO :ord.cus_name
FROM customers cus
WHERE cus.id = :ord.cus_id;
При этом производится простой и высокоэффективный индексный поиск, однако он осуществляется один раз для каждой отображаемой в форме строки. Таким образом, в этом простом случае придется выполнять одну дополнительную операцию обмена сообщениями с сервером на каждую строку многострочной формы лишь для того, чтобы получить имя покупателя. Последствия этого гораздо
серьезнее, чем может показаться на первый взгляд, поскольку в Oracle Forms интенсивно используется массивная выборка, позволяющая выбрать все строки для заполнения формы за одно обращение. Таким образом, если в форме необходимо отобразить 10 строк, то наш простой триггер может увеличить трафик сообщений с одной пары сообщений до одиннадцати.
Примечание
Здесь предполагается, что десять строк выбирается и десять отображается. По умолчанию
Oracle Forms выбирает на одну строку больше, чем может быть отображено в блоке формы. Это делается для более эффективного использования массивного интерфейса и для того, чтобы корректно показать, есть ли дополнительные строки.
Добиться того, чтобы выборка всех данных для множества строк вновь осуществлялась за одну операцию обмена с сервером, можно так: необходимо определить представление и построить форму на базе представления, а не на базе таблицы
ORDERS. В этом представлении будет выполняться соединение таблиц CUSTOMERS и ORDERS, и оно будет определено следующим образом:
CREATE OR REPLACE VIEW v orders
( id
, cus_id
, cus_name
, date_taken
, pending_reason
...
) AS
SELECT ord.id
, ord.cus_id
, cus.name
, ord.date_taken
, ord.pending_reason
...
FROM orders ord
, customers cus
WHERE ord.cus_id = cus.id;
Столбец с именем клиента,
CUS_NAME, теперь является базовым полем формы, и сервер может передать клиенту эти данные за одну операцию выборки. Однако при этом возникает ряд проблем, которые связаны с эффективностью выполнения запросов и обновляемыми представлениями. Наша позиция по каждому из них зависит от используемой версии — как вы, наверно, догадались, чем новее версия, тем менее серьезна проблема.
Во всех версиях
Oracle до 7.3 представления, которые содержат соединения, не могут быть объектом DML-операций. Это означает, что операции INSERT, UPDATE и DELETE для них не разрешаются. Версия 7.3 поддерживает обновляемые представления, хотя, как следует ожидать, и здесь существует ряд ограничений. В любом представлении обновляемые столбцы должны принадлежать одной таблице, и эта таблица должна быть защищена по ключу (key preserved). В самом простом случае это означает, что ключ (ключи), по которому выполняется соединение, обновлять нельзя.
Пока вы не станете работать с версией 7.3 (или более новой), вам придется программировать или генерировать триггеры
ON-INSERT, ON-UPDATE и ON-DELETE в экранной форме для того, чтобы выполнить обновление через блок, построенный на представлении, содержащем соединение, или фактически на любом необновляемом представлении. Эти триггеры, которые, как правило, создать очень легко, просто явно выдают DML-операции для базовых таблиц представления. В нашем примере это почти наверняка будет таблица ORDERS, так как совершенно невероятно, что мы будем использовать многострочный блок на базе таблицы ORDERS для корректировки имен покупателей.
Предупреждение
Эти явные ON-триггеры будут, конечно, нормально работать даже после перехода на версию 7.3, независимо от того, окажется представление обновляемым или нет. Однако здесь просматривается некая тяжеловесность, потому что форма (или, точнее, блок) теперь зависит от определения представления. Если по какой-то причине вы переопределили представление
V_ORDERS для выбора данных из таблицы ORDERS2 и не переписали триггеры в Forms, то эти триггеры попытаются обновить не ту таблицу. В лучшем случае вы отделаетесь ошибкой. Если же вам не повезет, то обновление будет выполнено не в той таблице, что, конечно весьма неприятно.
Операция
UPDATE или DELETE, вероятно, выполнена не будет, поскольку она ссылается на целевую строку при помощи идентификатора строки (ссылка по идентификатору строки — стандартный метод для Forms-операций UPDATE и DELETE в строках базовой таблицы), но операция INSERT почти наверняка будет выполнена успешно!
Оптимизация представлений
Вопросы оптимизации выполнения запросов более проблематичны. Для большинства сложных многострочных блоков должен выполняться поиск не в одной таблице, а в нескольких. Часто бывает, что внешний ключ допускает неопределенные значения (т.е. эта связь не обязательна), поэтому в
таком представлении должно осуществляться внешнее соединение. Первоначальная реакция как разработчика, так и пользователя на блоки, построенные на представлении, почти всегда положительна. Это объясняется тем, что они могут использовать любое из полей как основу для запроса и это устраняет традиционные проблемы, связанные с "запросами к небазовым таблицам". К сожалению, хотя это решение богато функциональными возможностями и создает минимальный трафик сообщений, оно может серьезно увеличить нагрузку на сервер и время ответа.
В качестве примера рассмотрим простое представление, определение которого приведено ниже. Чтобы пример был короче, мы опустили некоторые столбцы, которые читатель рассчитывал увидеть в таблице
ORDERS. Однако здесь выполняется соединение по схеме "звезда" и продемонстрировано использование внешних соединений для обработки кодовых полей, значения которых могут быть неопределенными.
CREATE OR REPLACE VIEW v_orders
( id
, settlement_currency
, quotation_currency
, sales_office
, customer_name
) AS
SELECT ord.id
, cc1.name
, cc2.name
, sof.name
, cus.name
FROM orders ord
, currencies cc1
, currencies cc2
, sales_offs sof
, customers cus
WHERE ord.cus_id = cus.id
AND ord.se_cur = cc1.code
AND ord.qu_cur = cc2.code(+)
AND ord.sof_id = sof.id(+);
Соединение по схеме "звезда "
называется так потому, что для него очевидна аналогия с соответствующей топологией локальной сети. В следующем примере приводится запрос к представлению V_ORDERS, в котором используется такое соединение.
SELECT id
, customer_name
FROM v_orders
WHERE se_cur = 'UK Pounds'
AND qu_cur = 'US Dollars'
AND sof_id = 'North America';
У нас есть условия для выбора данных из трех таблиц; каждая из этих таблиц соединяется с таблицей
ORDERS, но связей с другими таблицами не имеет. Таким образом, таблица ORDERS находится в центре "звезды". Лучше всего при выполнении этой операции использовать следующую стратегию:
1. Произвести запросы к таблицам валют (дважды) и таблице отдела сбыта.
2. Получить декартово произведение результатов этих запросов (в этом случае декартово произведение будет состоять всего из одной строки).
3. Используя это декартово произведение, выполнить соединение с таблицей
ORDERS.
4. Выполнить соединение таблицы
ORDERS с таблицей CUSTOMERS.
Шаги 1, 2 и 3 — это соединение по схеме "звезда", а версии до 7.3 выдают неудачные планы выполнения запросов, использующих такое соединение. К сожалению, не особенно помогают в этом случае даже подсказки. Причин этому две. Во-первых, механизмы выполнения запросов в ранних редакциях располагают нормальной стратегией для реализации подсказки. Во-вторых, в большинстве Forms-приложений трудно предсказать, какие из допустимых аргументов будут указаны (потому что они вводятся как критерии запроса), а от этого зависит план. Например, нельзя использовать ту же последовательность табличных ссылок, если заданы два наименования валют и имя покупателя (а не
Sales Office). При отсутствии поддержки для соединений по схеме "звезда" в механизме выполнения запросов самый лучший подход к такому соединению — кодировать его при помощи процедур.
Проблема с внешними соединениями состоит в том, что оптимизатор запросов
Oracle никогда не выдаст план запроса, который выполняется "неверно" по внешнему соединению. Это имеет место даже в случае, если имеется условие, показывающее, что для выбираемых данных не нужно создавать внешнее соединение вообще. Следовательно, наличие внешних соединений в этом примере означает, что запросы с соединением по схеме "звезда" фактически использовать нельзя. Поэтому порядок соединения будет таким:
1. Произвести запрос к таблице
CURRENCIES для получения кода валюты в которой указана стоимость заказа.
2. Используя этот код, выполнить соединение с таблицей
ORDERS.
3. Произвести соединение таблицы
ORDERS с таблицей CUSTOMERS таблицей CURRENCIES и таблицей SALES_OFFS, применяя после этих соединений фильтры для второй и третьей таблиц.
Если лишь очень немногие заказы регистрируются в долларах США, а оплачиваются в английских фунтах (а это весьма вероятно), то этот план выполнения запросов будет крайне неэффективным. Решение, как всегда, заключается в осуществлении процедурного контроля за соединением. Это можно сделать на клиенте или на сервере.
Если реализовать процедурное решение на клиенте, то этим мы увеличим трафик сообщений — а ведь главным мотивом построения блока на представлении было снижение числа сообщений в сети. Если построить блок на представлении, но при этом предотвратить использование этого представления, добавив триггеры
ON-SELECT, ON-FETCH и ON-LOCK, вызывающие процедуры PL/SQL на стороне сервера, то таким образом мы полностью инкапсулируем логику запросов на сервере. При этом число пар сообщений будет таким: одна — для инициирования обработки и одна — на каждую строку. Этот метод подходит для блока, содержащего одну строку. Если же речь идет о многострочном блоке, то, чем больше строк нужно в нем заполнить, тем менее приемлемым он становится. Однако этот метод все равно обеспечивает значительное сокращение числа сообщений по сравнению с другим вариантом, который заключается в поиске с помощью нескольких триггеров уровня поля. Кроме того, он позволяет справиться со сложностью запросов к небазовым таблицам силами логики на стороне сервера, а не на стороне клиента.
Необходимы три процедуры, и они должны находиться в пакете, который пользуется глобальным пакетным курсором. В нашем примере эти процедуры можно объявить так:
CREATE OR REPLACE PACKAGE order_query IS
PROCEDURE params
( ord_id IN NUMBER
, settlement_currency IN VARCHAR2
, quotation_currency IN VARCHAR2
, sales_office IN VARCHAR2
, customer_name IN VARCHAR2
);
FUNCTION fetch_row
( row_id OUT VARCHAR2
, ord_id OUT NUMBER
, settlement_currency OUT VARCHAR2
, quotation_currency OUT VARCHAR2
, sales_office OUT VARCHAR2
, customer_name OUT VARCHAR2
)RETURN BOOLEAN;
FUNCTION lock_row
( row_id IN VARCHAR2
)RETURN BOOLEAN;
...
END order_query;
Стоимость реализации такой полной инкапсуляции высока, поскольку процедура на стороне сервера должна использовать динамический
SQL для построения запросов, необходимых для каждого сочетания заданных значений полей. Однако эти приемы хорошо описаны, и в большинстве случаев позволяют добиться приемлемого сокращения трафика сообщений. Кроме того, такой подход позволяет уменьшить затраты на выполнение запросов.
Мы рекомендуем рассмотреть возможность применения этой методики для всех интенсивно используемых клиентских приложений, где на первый план выходит проблема с числом операций обмена и необходимо поддерживать запросы к небазовым таблицам. Если у всех запросов в качестве параметров указаны поля базовой таблицы, то, вероятно, эффективным окажется более простой вариант — строить формы на базе представления, содержащего соединение.
Нам известен один проект, в котором проектировщики собираются уменьшить трафик сообщений, заставив функцию
FETCH_ROW возвращать несколько строк таблицы. Это делается за счет того, что каждая переданная обратно переменная будет содержать список значений, упакованный в одну строку. Для этого потребуется создать дополнительный код и на стороне сервера, и на стороне клиента. Хотя этот метод недостаточно изящен и потребляет много ресурсов центрального процессора, он все же может сократить число операций обмена до того же уровня, что и представления (до одной для заполнения экранной формы).
Проверка данных в среде клиент/сервер
В дни Огас1е6 у разработчиков вошло в привычку реализовывать все бизнес-правила и ограничения в приложениях, потому что больше девать их было некуда. В большинстве случаев один и тот же код приходилось повторять в нескольких приложениях, в результате чего возникали проблемы с сопровождением и согласованностью.
Благодаря
Oracle7 у нас есть возможность определять процедуры, ограничения и триггеры в базе данных, поэтому их достаточно создать всего один раз и затем ввести в действие глобально. Однако даже сейчас существуют веские аргументы в пользу того, чтобы осуществлять проверку данных не только на сервере базы данных, но и в пользовательском приложении,
Клиентские приложения могут либо проверять данные по мере ввода либо откладывать проверку до тех пор, пока оператор не решит выполнить фиксацию изменений. Выбор метода в значительной степени зависит от характера приложения и компетентности конечных пользователей. В большинстве приложений используется сочетание двух этих методов, при котором отдельные поля проверяются при вводе, а перекрестная проверка полей и записей откладывается до получения сигнала о фиксации.
Конечно, для пользователя неприятно, что он потратил время на ввод в экранную форму массы деталей лишь затем, чтобы при фиксации узнать, что первое введенное им поле неверно. Если исправить ошибку нельзя, то пользователю придется переделывать всю работу. Все это, конечно, не прибавляет пользователю оптимизма, а системе — популярности. С другой стороны, если данные проверяются в экранной форме по мере ввода, то проектировщику приходится выбирать между дублированием проверки на клиенте и частыми обращениями к серверу, увеличивающими сетевой трафик. На наш взгляд, дополнительный трафик лучше, чем дублирование кода, и мы отдаем предпочтение проверке на стороне сервера, где это возможно. Использование промежуточных серверов (описанных ранее) может помочь уменьшить влияние этого подхода на трафик сообщений.
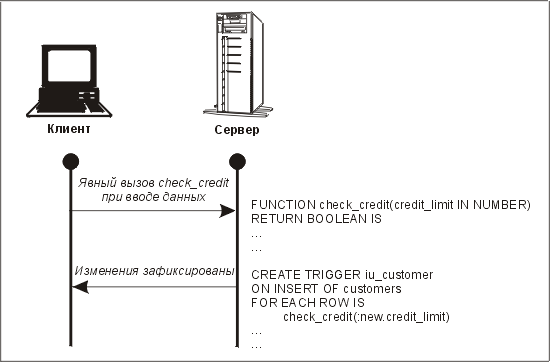
Недостаток немедленной проверки данных заключается в том, что правильные данные (а мы надеемся, что их подавляющее большинство) могут проверяться дважды. Вторая проверка выполняется, когда строка зафиксирована и срабатывает триггер проверки на таблице. Как мы уже подчеркивали ранее, мы не хотим снимать этот триггер, так как он — главный страж целостности нашей базы данных. В частности, он защищает базу данных от пользователей, имеющих доступ к средствам создания нерегламентированных запросов. Это показано на рис. 11.6, где лимит кредита не может превысить указанную сумму.
Функция
check_credit вызывается дважды — сначала явно из экранной формы для обеспечения немедленной обратной связи в, процессе ввода данных, а затем неявно триггером, когда в таблице выполняется вставка или обновление.
Иногда реализацию проверки на стороне клиента оправдывают еще и такой причиной: дескать это позволяет дать пользователю более информативные сообщения об ошибках, чем те, которые поступают с сервера при нарушении ограничения или отказе триггера. Нам кажется, что это не очень серьезный аргумент. Клиентское ПО может и должно перехватывать и преобразовывать сообщения, а не содержать и выполнять логику проверки.
Рис. 11.6. Пример дублирования проверки на клиенте и сервере
Важно, чтобы у вас был набор стандартов на разработку ГПИ, четко определяющих подход к проверке в масштабах всего приложения. Экранные формы, которые разработаны в
Oracle Forms версии 3 или более старой, а затем конвертированы с помощью какого-либо инструмента, все равно склонны вести себя, как программа, написанная в Oracle Forms версии 3, хотя и выглядят, как ГПИ. В них продолжает выполняться обширная проверка навигационных событий. Такие конвертированные экранные формы, как правило, плохо сочетаются с формами, которые "с нуля" разработаны в Oracle Forms версии 4.5, и весьма вероятно, что их придется переписывать; Привлекательно выглядит еще одна идея (особенно для отделов маркетинга фирм-поставщиков приложений): иметь один и тот же исходный код как для текстовых, так и для ГПИ-версий одного приложения. Но мы считаем эту идею несбыточной — из-за компромиссов, которые она предполагает.
К сведению
Помните, что, пока целостность данных обеспечивается с помощью триггеров, при проверке на стороне клиента не обязательно применять блокировки. Если ваше приложение не устанавливает блокировки до самого последнего момента, то менее вероятно, что пользователи столкнуться с конфликтами блокировки, хотя иногда они и будут получать сообщения периода фиксации о том, что транзакцию невозможно завершить, так как что-то изменилось. Эта тема рассматривается в главе 18.
Который час?
Время — это еще одна проблема в приложениях клиент/сервер. От большинства проектировщиков требуют (по крайней мере, они так думают) чтобы на клиенте можно было работать с текущими датой и временем. Во всех средах, за исключением распределенных вычислительных сред, у каждого клиента и каждого сервера есть свои системные часы, и эти часы выдают широкий диапазон несогласованных значений времени. Какое из них должно использовать приложение? Неразбериха возникает и потому, что один и тот же момент времени в разных часовых поясах представлен разным значением.
Примечание
Распределенная вычислительная среда (Distributed Computing Environment, DCE) — это стандарт, который определяет, как может взаимодействовать ячейка связанных сетью машин. Ячейку в данном контексте можно упрощенно представить как группу машин с общим назначением. Одно из требований DCE состоит в том, что ячейка должна содержать минимум три сервера времени и иметь алгоритм, позволяющий запрашивать время способом, который гарантированно дает непротиворечивое значение в пределах всей ячейки.
Oracle поддерживает использование DCE, и эту СУБД можно конфигурировать на получение SYSDATE с помощью сервисов времени DCE. Конечно, использование DCE влечет за собой дополнительные затраты на обеспечение необходимого уровня производительности.
Если вы просто хотите снабдить меткой даты или времени новую или обновленную строку, то можно отправить на сервер SQL-предложение с псевдостолбцом, содержащим SYSDATE для определения даты. SYSDATE будет вычислена, и для строки будет применена дата и время сервера. Этот метод хорошо работает для установки меток времени и приемлем для подавляющего большинства приложений. Вот пример SQL-предложения такого типа:
UPDATE orders or
SET ord.tot_amount = ord.tot_amount * 1.01
, ord.latest_update_dt = SYSDATE
WHERE ord.cus_id = 1024;
Однако предположим, что от приложения требуется, чтобы пользователь видел метку времени на записи перед тем, как решать, фиксировать запись или нет. Теперь появляется выбор — приложение может запросить дату и время с сервера или воспользоваться локальными часами клиента. Причем результат в данном случае будет зависеть от того, какое средство применялось при его создании. Многие пользователи удивляются, обнаружив, что, когда локальная процедура на PL/SQL, работающая в приложении, созданном в Oracle Forms, обращается к SYSDATE, это приводит к вызову сервера для выборки текущего значения. Единственный путь обратиться к локальным часам — по умолчанию использовать для элементов Forms $$DATE$$ или $$EDATETIME$$.
К сведению
Не смешивайте эти два метода, т.е. не применяйте $$DATETIME$$ как значение даты и времени по умолчанию с последующим обращением к SYSDATE для выполнения его проверки. У этих значений мало общего — разве что формат.
Во многих клиентских инструментальных средствах предусмотрен вызов, позволяющий получить текущее время из часов клиента (например, в Visual Basic есть функция Now).
Принимая решение о том, откуда брать время, обязательно учтите, что делает приложение и для чего нужно время. Рекомендуем во всех случаях, когда время необходимо передавать в базу данных, использовать серверное время. Если база данных является распределенной, следует брать время с самого центрального сервера. Общее правило (имеющее к архитектуре клиент/сервер отдаленное отношение) звучит так: любая процедура, в которой используется время, должна получать его один и только один раз, чтобы передавать одно и то же время. Вряд ли вы обрадуетесь, когда, закодировав соединение по метке времени, увидите, что данное конкретное время отличается на две-три секунды из-за того, что SYSDATE использовалось в одной долгой транзакции не один, а несколько раз.
Если приложение содержит планирующие компоненты, в которых события должны координироваться между узлами сети, то еще более важно использовать одни часы или какой-нибудь сетевой сервис времени. Здесь также нужно помнить о том, что если применяются одни часы, то это должны быть часы самого центрального сервера.
Знаете ли Вы, что диаграмма развертывания, Диаграмма применения, Диаграмма размещения Deployment diagram - это метод объектно-ориентированного проектирования, отображающий физические взаимосвязи между программными и аппаратными компонентами системы.