Эти вопросы часто считают второстепенными, забывая о том, что они имеют колоссальное значение для защиты наших драгоценных данных. Существует два основных направления защиты данных. Во-первых, данные следует защитить от несанкционированного или злонамеренного доступа. Во-вторых, данные необходимо держать в безопасности, чтобы они всегда были доступны для "законных" пользователей.
По поводу всех рассматриваемых в этой главе задач необходимо сказать следующее:
• При определении того, сколько сил и средств придется затратить на их реализацию, необходимо проанализировать не только степень риска потери данных, но и соотношение между затратами и результатами.
• К каждой из этих задач нужно относиться с полной серьезностью, включить их в план проекта и сделать одним из критериев приемки. Не пытайтесь уйти от проблем, связанных с этими задачами, и отложить их рассмотрение до того, пока разработка не развернется по-настоящему. Мы предпочитаем решать эти задачи как можно раньше и проектировать соответствующие средства в рамках общей архитектуры системы. Если вы проигнорируете наш совет (как часто бывает), то вероятность неудачи вашего предприятия будет очень высокой.
В этой главе мы рассмотрим самые разные решения — от простейшего (которое обычно и самое слабое в плане функциональности) до самого сложного и всеобъемлющего. Следует сказать, что в большинстве работающих систем реализованы решения, находящиеся посредине этого диапазона.
Архивация
Что такое архивация? Обычно она означает хранение данных без возможности немедленного доступа, но в форме, допускающей их выборку. Вероятно, самая распространенная из всех оплошностей, которые допускаются сегодня в Oracle-проектах, — это предположение, что архивация представляет собой нечто такое, о чем нужно начинать беспокоиться, когда диски почти заполнены, а средств на приобретение аппаратных средств нет. До этого момента мы продолжаем добавлять файлы в почти заполненные табличные пространства и надеемся, что все будет хорошо. Когда же свободное место найти не удается, мы начинаем думать, что делать.
Такой подход является рискованным по целому ряду причин. Вот наиболее важные из них.
• Большинство методов архивации требует, чтобы на период архивации приложение отключалось. Конечно, при хорошем проектировании эти перерывы можно свести к минимуму, но разумнее запланировать архивацию (и, следовательно, перерывы в работе) на приемлемые для пользователей периоды.
• Если приложение спроектировано без учета возможной архивации, то после удаления данных оно может работать неправильно. Это классическая проблема для случая с полностью нормализованными структурами данных, которые не содержат производные поля, например данные об остатках. Конечно, ее можно решить, введя транзакции для переноса остатков. Но если такие транзакции ранее не использовались, то перед вводом их в эксплуатируемую систему придется выполнить тестирование.
• Работа приложения может очень замедлиться из-за постоянной необходимости сканировать данные, не задействованные в получении результата. Примером может служить следующее SQL-предложение, имеющее дурную репутацию:
SELECT MAX(transaction_date)
FROM transactions
WHERE account_id = :account;
Чем больше транзакций выполнено для данного счета, тем медленнее работает этот запрос.
• Если пользователи не предупреждены о том, что устаревшие данные будут изыматься из приложения, и не поверили в преимущества архивации, то при изъятии данных возможна негативная реакция с их стороны. Это может случиться и тогда, когда вы предупредите их об этом, так как пользователи всегда заявляют, что никакого предупреждения не было.
Во многих приложениях данные стареют очень быстро. Новые данные часто запрашивают и обновляют. Затем, по мере их старения, они становятся ненужными, и пользователи обращаются к ним все реже и реже. Кандидатом на архивацию является не только журнал аудита (мы познакомимся с ним ниже). (Хотя в действительности в некоторых случаях журнал аудита — единственный тип данных, который желательно хранить бесконечно долго.) Данные транзакций также могут загромождать системы, даже в наши дни, когда объемы памяти на устройствах хранения исчисляются терабайтами. По мере увеличения емкости базы растет и объем данных, которые мы должны хранить. Во многих случаях объем этих данных увеличивается быстрее, чем емкость устройств хранения информации.
Варианты архивации
В зависимости от конкретных данных и конкретной среды архивация может означать разные действия. Это может быть:
• полное уничтожение данных (изъятие или удаление их без сохранения копий);
• исключение возможности немедленного доступа к данным с сохранением их на внешнем носителе, с которого их можно (по крайней мере, теоретически) восстановить;
• исключение возможности доступа к данным из промышленных систем с сохранением возможности доступа из информационно-управляющих систем (ИУС) и информационных систем руководителей (ИСР), например из хранилища данных или OLAP-сервиса;
• сохранение возможности полного доступа к данным при помощи запросов, но перевод их в неизменяемое состояние во избежание необходимости включать эти данные в стандартный цикл резервного копирования.
Полное уничтожение данных
Вы можете сказать, что полное уничтожение данных — совершенно неприемлемый вариант. Действительно, стоимость сэкономленной ленты можно считать единственным вознаграждением, которое можно когда-нибудь за это получить. Однако ни вы, ни мы не хотим очутиться в положении, когда придется признать, что мы сознательно выбросили несколько сот гигабайт корпоративных данных. Тем не менее, во многих приложениях, особенно в ИСР и хранилищах данных, стоимость хранения данных иногда перевешивает выгоды от возможности доступа к ним как к справочным данным. В таких случаях данные вежливо теряют.
Вот как может звучать одно из типичных требований, предъявляемых к ИСР:
"Подробные сведения обо всех вызовах, инициированных абоненте должны быть доступны для справки в течение минимум двух лет с момента вызова".
В результате проведенного исследования мы приходим к выводу, что эти сведения нужно хранить в течение максимум 27 месяцев и что каждые три месяца мы будем удалять строки, возраст которых превышает два года. Для конкретной компании это может означать, например, что нам придется удалять чуть больше десяти процентов строк из таблицы, содержащей 500 миллионов строк.
Есть, впрочем, очень эффективный метод, позволяющий упростить такой процесс удаления. Это горизонтальное секционирование таблицы на несколько таблиц, каждая из которых содержит данные о звонках за три месяца с последующим "овеществлением" всей совокупности данных при помощи представления с UNION ALL:
CREATE OR REPLACE VIEW calls AS
SELECT * FROM calls_95q1
UNION ALL
SELECT * FROM calls_95q2
UNION ALL
SELECT * FROM calls_95q3
UNION ALL
SELECT * FROM calls_95q4
UNION ALL
SELECT * FROM callS_96q1
UNION ALL
SELECT * FROM calls_96q2
UNION ALL
SELECT * FROM calls_96q3
UNION ALL
SELECT * FROM calls_96q4
UNION ALL
SELECT * FROM calls_97q1;
В версиях до 7.3 с таким представлением сопряжены определенные сложности, особенно если попытаться выполнить операцию соединения с ним. Может понадобиться ряд других представлений, в которых соединение используется в каждом запросе. Работая с версией 7.0, мы наблюдали случаи, когда единственным приемлемо работающим был метод, который заключался в индивидуальной выдаче запросов и выполнении объединения результатов внутри приложения. В версии 7.3 запросы, использующие этот метод (который называется ручным секционированием), оптимизируются очень хорошо при условии соблюдения ряда ограничивающих условий. По сути, эти ограничения сводятся к тому, что определения отдельных таблиц должны быть идентичны во всем, кроме имен и параметров хранения.
Если мы создадим такую структуру, удалить (заархивировать) данные будет легко. Для этого необходимо сделать следующее:
1. Создать новую таблицу (CALLS_97Q2).
2. Пересоздать представление, исключив ссылку на CALLS_95Q1 и добавив ссылку на CALLS_97Q2.
3. Исключить таблицу CALLS_95Q1.
На все это требуется меньше секунды, тогда как удаление 50 миллионов строк займет куда больше времени.
Кроме того, этот подход очень удобен при загрузке данных из операционных систем. Подробнее он описан в главе 13.
Отключение данных
Отключение данных сопряжено с рядом проблем. Помимо того, что это трудоемкий процесс, нет никакой гарантии, что мы сможем прочитать архив, если он через некоторое время будет извлечен из хранилища и принесен в машинный зал. Во-первых, может ухудшиться качество носителей, а, во-вторых, после длительного периода хранения трудно будет найти устройство, на котором можно прочитать эти носители. Даже если эту проблему мы и решим, то потом нужно будет найти программное обеспечение, способное обработать то, что записано на носителях. *
Чтобы быть справедливыми по отношению к корпорации Oracle, скажем, что начиная с версии 6 обеспечена достаточная совместимость сверху вниз, но это не означает, что можно просто взять копию данных для старой версии, сбросить ее на диск и рассчитывать, что текущая версия РСУБД или текущая версия приложения обработает данные без какой-либо доработки.
Возможно, кто-то посчитает разумным включить в архивную копию полную программную среду, включая не только Oracle и приложение, но и операционную систему. При этом, конечно, предполагается, что весь этот код сможет работать на любых аппаратных средствах, которые будут использоваться в данной организации через два месяца, два года или через двадцать лет.
Во многих организациях взяли за правило архивировать данные не на ленту, а на микрофильмы (точнее, на микрофиши), потому что эти носители можно читать на более простой технике, для них вообще не нужны никакие программы и, кроме того, считается, что их качество ухудшается гораздо медленнее, чем качество магнитных носителей. К сожалению, единственный способ поиска микрофишей — по прилагаемому к ним указателю (если он есть) или путем чтения каждой "страницы". Если необходимо найти один элемент в архиве, состоящем из десяти миллионов транзакций, или подготовить сводку, то микрофиши — явно неподходящее решение. Кроме того, плотность записи на современных магнитных и оптических цифровых носителях настолько высока, что фотографические носители, главной целью создания которых была экономия места и материала, сейчас выглядят массивными и дорогими.
Перенос данных в другое приложение
Перенос данных в другое приложение, возможно, покажется, легкой задачей, но ведь и в хранилище данных также может когда-нибудь не хватить места и в результате придется вернуться к одному из двух предыдущих вариантов. В крупной организации эта проблема может свалиться на кого-нибудь другого! А если серьезно, то перенос данных из действующих систем в ИУС или ИСР — вполне допустимая форма архивации с точки зрения администратора действующей системы.
Не забудьте, что если данные переданы в другое хранилище и известно что они загрузились там успешно, а также если эти данные в исходном хранилище больше не нужны, то их следует оттуда удалить.
Перенос данных в неизменяемое пространство в этом же приложении
Этот вариант вообще не является архивацией как таковой, если только в процессе переноса данные некоторым образом не реструктурируются. Тем не менее, это ценный метод уменьшения объема данных, подлежащих регулярному резервному копированию, так как табличное пространство только для чтения нужно копировать только один раз (сразу же после ALTER TABLESPACE...READ ONLY).
Как архивировать?
Какое решение самое лучшее? Вот наша рекомендация: создавать одну архивную копию данных на магнитном носителе в форме, для использования которой требуется минимальный объем программного обеспечения. И для структурированных, и для текстовых данных это означает извлечение данных в текстовом формате, т.е. представление архива в виде отчета, включающего все содержимое каждой записи. Необходимо побеспокоится о том, чтобы этот формат был хорошо описан (т.е. названия полей были информативными). Для создания архива в формате такого типа потребуется гораздо больше времени, чем для получения копии базы данных или экспортированного файла (с помощью утилиты ЕХР), а для загрузки его на какой-нибудь пока не существующей платформе могут понадобиться значительные усилия разработчиков. Однако этим вы хотя бы оставляете себе (или своим преемникам) надежду на успех.
В рамках этого проекта вы должны создать подпрограмму восстановления из архива, которая будет загружать данные в текстовом формате в таблицу, а затем протестировать средства архивации и восстановления.
Предположим, вы архивируете таблицу (OLD_X), а затем восстанавливаете ее в другую таблицу (NEW_X). Если приведенный ниже запрос выполняется без ошибки и возвращает нуль, то это означает, что подпрограммы архивации и восстановления работают нормально.
(SELECT * FROM new_x
MINUS
SELECT * FROM old_x
)
UNION ALL
(SELECT * FROM old_x
MINUS
SELECT * FROM new_x
);
Если таблица содержит много строк, то, несмотря на элегантность этого запроса, для его выполнения понадобится очень много времени и пространства для сортировки. Однако он работает значительно быстрее, чем реализация при помощи языка третьего поколения или PL/SQL.
Примечание
Набор операций над множествами из этого примера — это еще один образец полезного кода, который невозможно использовать, если таблица содержит столбцы типа LONG или LONG RAW.
Отметим также, что эту операцию нельзя нормально выполнить без сортировки, так как нет гарантии того, что порядок строк в исходной у таблице будет таким же, как порядок строк в восстановленной таблице. Более того, если для ускорения выгрузки и перезагрузки использовать средства параллельной обработки, то строки почти наверняка будут располагаться в другом порядке.
Когда архивировать?
Нужно не ждать, пока диски заполнятся, а выработать четкие правила, определяющие момент архивации данных, т.е. момент, когда затраты на хранение данных в памяти перестают окупаться. Большинство пользователей и аналитиков, как правило, выражают эти правила по-другому, например так:
"Данные строк заказа должны быть доступны для интерактивных запросов в течение двух лет, начиная со дня окончательной оплаты, и в течение четырех лет, начиная со дня отгрузки, при наличии невзысканного платежа".
В организации может действовать законодательное или юридическое требование о необходимости хранения определенных данных в течение некоторого периода времени, но оно дает нам лишь самый ранний срок, когда можно законно удалить данные, и не говорит, когда следует удалить их.
Если данные содержат метки времени, показывающие, когда они в последний раз изменялись, то можно по ним найти данные, которые не изменялись, скажем, три года. К сожалению, мы не сможем определить когда к этим данным последний раз обращались с запросом.
Возможно, пользователи захотят просмотреть эти данные и, руководствуясь бизнес-знаниями, отметят, какие клиенты прекратили деятельность, какие данные устарели и т.д. Затем при помощи подпрограмм можно сканировать эти данные, искать в них отмеченные элементы и архивировать их и все подчиненные данные (например, заказы клиентов). Конечно, и нам ясно, что пользователи никогда не соберутся сделать это, но мы этого не говорили.
Куда архивировать — в файл или в таблицу?
Хороший вопрос! Достоинства и недостатки обоих методов очевидны. Использование файлов освобождает драгоценное пространство базы данных (и место на дисках, если файл, в свою очередь, архивируется на ленту). Если извлечь данные из архива будет трудно, мы, вероятно, сможем воспользоваться шлюзом, чтобы запросить их с помощью SQL, хотя вряд ли найдется шлюз, позволяющий читать данные прямо с ленты или получить доступ к последовательным файлам, находящимся в формате отчета.
Архивация в таблицу — метод спорный, потому что, как мы уже говорили, ни создание резервной копии табличного пространства, ни даже экспорт не дают достаточной уверенности в том, что мы сможем извлечь данные спустя много лет.
Если вы передумали, то можно ли вернуть архивные данные обратно?
Еще один хороший вопрос! Если вы проектируете модули для архивации данных, то, конечно, можно создать модули и для "воскрешения" этих данных. Одна из множества опасностей, которых следует остерегаться в этом случае, связана с уникальными ключами. Может случиться, что к моменту возвращения данных появилась еще одна запись с тем же ключом.
Один из способов избежать дублирования ключей — оставить после архивации основную часть строки. Мы знакомы с этим подходом, но он нам не нравится. При таком способе приходится оставлять данные во всех обязательных столбцах, и строка все равно занимает место. Более того, даже если все запросы к таблице содержат условие, например ARCHIVED = 'N', при их выполнении, скорее всего, будут обрабатываться все остаточные строки.
Мы предпочитаем рассматривать архивацию как улицу с односторонним движением. Это существенно облегчает жизнь и позволяет избежать напрасных ожиданий.
Рекомендации по архивации
Как мы говорили выше, не следует предполагать, что архивация — легкая задача. Если вы задержались на этой работе дольше, чем на предыдущих, не рассчитывайте, что уйдете задолго до того, как архивация поднимет свою грозную голову! Подводя итоги, хочется дать вам следующие рекомендации:
• Планируйте архивацию с самого начала проекта.
• Выполняйте архивацию по сущностям, а не по таблицам. Если одной сущности соответствуют две таблицы, их следует архивировать в одной операции.
• Особенно тщательно следует учитывать влияние ссылочной целостности. Нельзя оставлять в базе данных "беспризорные" строки, архивируя родительские строки и забывая о дочерних — необходимо определять архивные группы связанных таблиц.
• Если используются файлы, то следует обеспечить хорошее описание формата (по сути дела, использовать файлы-отчеты).
• Реализуйте архивацию в рамках главного приложения, а тестируйте — в рамках приемо-сдаточных испытаний всего комплекта.
Аудит
Что такое аудит и как он связан с безопасностью? Аудит — это действия, позволяющие определить, кто что делал в системе и имел ли он право на эти действия. Обеспечение безопасности имеет целью, прежде всего, помешать пользователям делать недопустимые вещи. В любой системе, которая обслуживает денежные операции (например, в системе, где ведутся записи о ссудах), средства аудита и безопасности должны гарантировать надежную защиту информации. Конечно, очень хорошо, если надежность такой защиты будет стопроцентной. Хотя аудит и безопасность взаимосвязаны, эти задачи реализуются отдельно.
Под термином "аудит" в информационных технологиях часто подразумевают ведение журнала аудита. Журнал аудита — это специальный набор записей, создаваемых системой, который надежно защищён от несанкционированного доступа. Иногда эти понятия используют как синонимы. Однако мы постарались быть точными и применяем термин "журнал аудита", когда говорим о ведении записей, а термин "аудит" — когда имеем в виду использование журнала аудита для реализации функции генерации отчетов.
Основное назначение журнала аудита — выступать в роли средства, позволяющего обнаружить действия, которые могут нарушить целостность системы. Другими словами, с его помощью мы можем выявить как мошеннически введенные данные, так и несанкционированные запросы. (Почему-то во многих организациях уделяют одной из этих задач больше внимания, чем другой.)
Что содержит журнал аудита?
Какую информацию должна записывать система в журнал аудита? Теоретически кандидатом на регистрацию является любое происходящее системе событие. Особенно важны для аудита вход в систему и выход из системы, а также обновление данных. Аудит запросов несколько затруднен если запросы производятся не через хранимые процедуры, поскольку средства аудита можно встроить в сами процедуры.
В большинстве организаций регистрируются все случаи входа в систему и сообщается обо всех входах в систему, которые выполнены в нерабочее время или посредством коммутируемого доступа (если их можно отличить). Можно создать отдельную запись для всех финансовых операций, в ходе которых деньги отправлялись из системы. Один из способов реализации этого — случайный выбор "счетов" или "событий" и их сверка с принимающей системой на предмет того, не нарушается ли баланс в бухгалтерских книгах. Другой способ — выбор всех операций с большими суммами. Конечно, все обнаруживаемые в процессе аудита операции уже свершились. Как мы говорили, аудит неразрывно связан с безопасностью. Лучше предотвратить мошенничество или нарушение защиты путем введения жестких правил безопасности, чем затем, когда дело уже сделано, обнаруживать это средствами аудита.
В некоторых организациях средства аудита также используются для измерения объема документооборота и производительности подразделений и отдельных сотрудников. Например, по журналу аудита можно обнаружить, что заказ был впервые зарегистрирован в системе 21 апреля (из CREATED_DT для ORDERS), но товары не отгружались до 14 июня (из CREATED_DT для DISPATCHES). Определив среднее значение времени выполнения заказа, менеджеры могут сделать выводы о производительности труда. Однако нам кажется, что это опасная практика. Часто существуют вполне обоснованные причины того, почему ввод данных откладывается и не соответствует дате, когда произошло событие. Если необходимо определить статистические показатели работы, то в таблице должны быть столбцы (отдельные от столбцов аудита) для записи соответствующей информации (например, дат отгрузки).
Простейшая форма журнала аудита
Рассмотрим простейшее решение задачи аудита. В данном примере мы полагаем, что нас интересует только регистрация доступа к данным — в частности, сведения о том, кто создал каждую строку и кто последним изменил каждую строку (если это имело место). Для большинства наших таблиц мы можем добавить четыре столбца:
...
, created_by VARCHAR2(30) NOT NULL
, created_dt DATE NOT NULL
, updated_by VARCHAR2(30)
, updated_dt DATE
...
Эти столбцы заполняются автоматически при помощи триггеров на таблице:
СRЕАТЕ OR REPLACE TRIGGER t1_bir BEFORE INSERT ON t1
FOR EACH ROW
BEGIN
:new.created_by := USER;
:new.created_dt := SYSDATE;
END t1_bir;
/
CREATE OR REPLACE TRIGGER t1_bur BEFORE UPDATE ON t1
FOR EACH ROW
BEGIN
:new.updated_by := USER;
:new.updated_dt := SYSDATE;
END t1_bir;
/
При использовании этой формы журнала из аудита обычно исключаются таблицы с постоянными справочными данными — вероятно, считается, что время изменения таких данных не имеет значения. Как-то одному из нас сказали, что журналы аудита для таких данных не нужны, "потому что эти данные редко изменяются". Мы сразу же спросили, откуда наш собеседник знает это, не имея журнала аудита. Вразумительного ответа на свой вопрос мы не получили.
Вместо триггера BEFORE INSERT можно использовать фразы DEFAULT для столбцов CREATED_BY и CREATED_DT. Это решение очень просто реализовать, и оно не слишком дорого с точки зрения затрат периода выполнения и дополнительной памяти в базе данных.
Еще одно преимущество аудита этого уровня состоит в том, что вся информация хранится в обыкновенных таблицах. Это облегчает выполнение аудиторских запросов к данным, например, запросов на получение общей стоимости заказа для каждого его создателя. Каковы же недостатки? Давайте разберем их по отдельности.
1. По этим столбцам можно определить только создателя и последнего, кто изменил строку. Все следы промежуточных изменений навсегда исчезают.
2. Можно увидеть, кто последним изменил строку и когда он это сделал, но нельзя понять, какие столбцы были изменены. Мы не можем узнать, был ли обновлен столбец состояния заказа или же изменилась сумма (или и то, и другое).
3. Можно увидеть, кто создал строку и кто последним обновил ее, но если строка удалена, то все ее следы исчезают (включая сведения о создании и изменении).
4. Если есть пользовательские бюджеты общего назначения, например DATA ENTRY CLERK, которыми пользуются многие в системе, то маркирование записей с помощью этого имени не очень-то поможет выявлении реального лица, вошедшего в систему. Кроме того, если есть удаленные пользователи, которые обращаются к таблицам в нашей системе с помощью распределенных транзакций, то в качестве пользовательского бюджета, применяемого для маркирования записи, может оказаться общий бюджет, используемый удаленными пользователями. В этом случае данные аудита также скажут нам мало полезного.
5. Когда мы загружаем данные из другой системы (будь то одноразовый прием или регулярная загрузка), то при включенных триггерах все загруженные данные будут иметь пользовательское имя, которое использовал пакетный процесс для соединения с Oracle. Иногда это оправдано, но в большинстве случаев лучше отключить триггеры на время загрузки данных и перенести создателя (и время создания) записи из исходной системы.
6. Мы регистрируем только создание и вставку. Записей об операциях запроса данных у нас нет, и мы не знаем, кто и какие данные читал.
7. Журнал аудита не позволяет определить, что еще, кроме попытки соединиться с системой под данным пользовательским именем и в данное время, было сделано в рамках этой же транзакции.
Использование средств аудита
Oracle7
До настоящего момента мы говорили об аудите в общем. В этом разделе мы рассмотрим некоторые стандартные средства аудита, предусмотренные в Oracle7. Поначалу эти средства, возможно, покажутся очень мощными и гибкими. К сожалению, при близком рассмотрении оказывается, что многие из них не очень эффективны. Как правило, они регистрируют только события, не записывая значения данных, связанных с событием. В голову сразу приходят шоколадные чайники. ** Много лет назад один из авторов работал в английском отделении одной североамериканской софтверной компании, отдел исследований и разработок которой английские сотрудники называли фабрикой шоколадных чайников.)
Некоторые встроенные возможности аудита в Oracle7 могут быть довольно полезными. Если аудит включен на уровне экземпляров, то команда
AUDIT SESSION;
регистрирует все подключения к базе данных и отключения от нее, как успешные, так и неудачные. Это может оказаться полезным, если есть подозрения о присутствии взломщика, но, к сожалению, узнать, что делает пользователь между подключением и отключением, невозможно. Можно лишь увидеть, когда и как долго пользователь был подключен, а также когда и как часто некоторому неизвестному лицу не удавалось подключиться к базе данных.
Допустим, что все данные нашей БД, за исключением таблицы PAYROLL, содержащей секретную информацию, довольно малоинтересны для случайного (или не совсем случайного) пользователя. Очевидно, что мы введем правила защиты, которые ограничат круг пользователей, имеющих доступ к этой таблице (подробнее мы рассмотрим этот вопрос ниже, когда перейдем к обеспечению безопасности). Однако часто люди относятся к своим паролям очень беспечно. Некоторые вообще оставляют без присмотра свой экран после входа в систему. Чтобы обеспечить безопасность этой таблицы, мы задаем для нее аудит посредством следующей команды:
AUDIT ALL ON LIVE.PAYROLL BY ACCESS;
Эта команда заставляет Oracle регистрировать "детали" всех операций над таблицей PAYROLL. Фраза BY ACCESS обеспечивает наличие элемента для каждого случая доступа, а не только одного элемента на тип доступа для данного сеанса. Oracle заносит все аудиторские действия в одну таблицу SYS.AUD$, и, если включено много журналов аудита, эта таблица становится очень загроможденной. К счастью, Oracle обеспечивает ряд представлений, позволяющих просмотреть содержимое AUD$ в виде структурированных наборов (см. CATAUDIT.SQL).
Аудиторские представления позволяют запрашивать доступы к таблице PAYROLL по пользователям, по типам доступа, по дате и времени доступа. Однако мы не можем установить, что было изменено в таблице: персональные сведения (например, адрес) или данные о зарплате. Жаль, что это средство аудита Oracle может сообщить нам так немного. Если существует подозрение, что кто-то подключается как пользователь с ролью, позволяющей модифицировать таблицу PAYROLL, исправляет зарплату до начисления, а затем делает ее прежней, то для определения этого нам нужно намного больше информации, чем могут дать средства аудита Oracle.
Причина, по которой средства аудита в Oracle должны включаться как на уровне экземпляров, так и операторами AUDIT, предельно проста. Если табличное пространство SYSTEM при включенном аудите заполнилось и места для записей аудита уже нет, то освободить место невозможно. Почему? Потому что для этого пришлось бы создать запись аудита, а ее нельзя создать из-за отсутствия места.
Решение состоит в том, чтобы разрушить экземпляр (при таких обстоятельствах вряд ли можно будет выполнить SHUTDOWN NORMAL) и перезапустить его с отключенным аудитом на уровне экземпляров, чтобы вы (иди администратор БД) смогли заняться проблемой освобождения места. Конечно, пока все это происходит, работать придется без аудита.
Если такое с вами хоть раз случалось, вы понимаете, почему ПО анализа журналов так привлекает компьютерных аудиторов. При наличии такого анализатора каждое внесенное в БД изменение остается в журнале, и эти журналы имеют возрастающие порядковые номера, чтобы аудитор мог увидеть, какого именно журнала нет. Кроме того, журнал содержит старые и новые значения данных для операций обновления, а также старые значения удаленных записей. Бывалый пользователь сможет с помощью анализатора журналов проверить, изменялись ли какие-либо таблицы без отражения изменений в журнале аудита!
Как обычно, и в этом случае существуют одна-две проблемы. Нет никакой гарантии, что мы сможем узнать, какой пользователь внес изменение, потому что его идентификатор не регистрируется и данных о запросах нет. Сейчас один из авторов занимается исследованием возможности определения пользовательского идентификатора из журнала. К сожалению, вывод неутешителен: с достаточной степенью надежности это сделать нельзя.
Углубленный аудит с помощью триггеров
В этом разделе мы продолжим предыдущий пример, но расширим сферу аудита. На этот раз мы введем дополнительную таблицу, которая будет содержать полный хронологический журнал всех изменений, внесенных в столбец SALARY таблицы PAYROLL. Поскольку регистрация этой информации влечет за собой дополнительные расходы, в некоторых организациях эту таблицу можно включать периодически — для получения случайных выборок или только если есть подозрение, что возникла проблема. С технической точки зрения, второй метод можно назвать закрытием двери конюшни после того, как лошадь убежала. На наш взгляд, если вам нужен журнал аудита, то следует использовать его постоянно.
SQL-код для создания этой таблицы и код поддерживающего ее триггера приведены ниже. Отметим, что в первичном ключе таблицы аудита используются дата и время: предположение о том, что ничью зарплату нельзя изменить дважды за одну секунду, кажется разумным, а если все-таки это имеет место, то ваша озабоченность по поводу безопасности оправдана.
CREATE TABLE salary_change_log
(emp# NUMBER(10) NOT NULL
,transaction_dt DATE NOT NULL
,user_name VARCHAR2(30) NOT NULL
,old_sal_value NUMBER(8,2) NOT NULL
,new_sal_value NUMBER(8,2) NOT NULL
,CONSTRAINT scl_pk PRIMARY KEY (emp#, transaction_dt)
);
CREATE OR REPLACE TRIGGER pay_aur AFTER UPDATE ON payroll
FOR EACH ROW
BEGIN
IF :old.emp# <> ;new.emp#
THEN RAISE_APPLICATION_ERROR(-2000,
'Illegal primary key cange attempted on table PAYROLL');
END IF;
IF :old.salary <> :new.salary THEN
BEGIN
INSERT INTO salary_change_log ( emp#
, transaction_dt
, user_name
, old_sal_value
, new_sal_value
) VALUES
( :new.emp_no
, SYSDATE
, USER
, :old.salary
, :new.salary
);
END;
END IF;
END pay_aur;
/
Теперь, если кто-нибудь попытается изменить зарплату до или после вызова программы начисления, наш триггер должен отловить эту попытку. Но вот отловит ли? Альтернатива обновлению строки — ее удаление и повторная вставка, и, действительно, это будет делаться, если пользователь захочет изменить номер служащего. К сожалению, мы не перехватываем удаления и вставки, а, вероятно, следовало бы. В примере 10.1 приведены определение таблицы аудита для зарплаты и новый триггер, перехватывающий все три события.
Если вы не пожалеете времени и разберете этот пример, то увидите, что мы используем один триггер, который проверяет наличие вставки, обновления и удаления, а не отдельный триггер для каждого события. Существуют разные мнения по поводу того, какой метод лучше. Мы предпочитаем размещать реализацию правил аудита для таблицы в одном (и только одном) месте.
Наш пример можно усовершенствовать. В частности, многие аудиторы попросят, чтобы записи аудита имели порядковые номера по служащим. Это позволит установить, какие записи удалены. Здесь есть два момента: во-первых, необходимо подумать, как реализовать это требование, и, во-вторых, выяснить, почему аудиторы считают, что кто-то, знающий о системе достаточно для того чтобы удалить записи аудита, не сможет изменить в меньшую сторону даты последующих записей. Пока мы займемся только первым из них вопросов и пронумеруем записи. В результате первичный ключ будет выглядеть так: (ЕМР#, CHANGE#), и номера изменений будут начинаться с единицы (или с нуля) и непрерывно возрастать.
Пример 10.1. Таблица аудита и триггер для сбора информации
CREATE TABLE salary_change_log
(emp# NUMBER (10) NOT NULL
,transaction_dt DATE NOT NULL
,user_name VARCHAR2(30) NOT NULL
,dml_type CHAR(l) NOT NULL
,CONSTRAINT scl_dml_type CHECK (dml_type IN ('I', 'U', 'D'))
,old_sal_value NUMBER (8,2)
,CONSTRAINT scl_old_sal
CHECK ( DECODE(dml_type, 'I', 0, 'U', 1, 'D', 1, 0)
= DECODE(old_sal_value, null, 0, 1)
,new_sal_value NUMBER (8,2)
,CONSTRAINT scl_new_sal
CHECK ( DECODE(dml_type, 'I', 1, 'U', 1, 'D', 0, 0)
= DECODE(new_sal_value, null, 0, 1)
CONSTRAINT scl_pk PRIMARY KEY (emp#, transaction_dt)
);
CREATE OR REPLACE TRIGGER pay_aud
AFTER INSERT OR UPDATE OR DELETE ON payroll
FOR EACH ROW
DECLARE
l_dml_typ salary_change_log.dml_type%TYPE;
BEGIN
IF :old.emp# <> :new.emp# — ошибка, если
THEN RAISE_APPLICATION_ERROR(-2000,
'Illegal primary key change attempted on table PAYROLL');
END IF;
IF UPDATING ('SALARY') THEN
l_dml_type := 'U';
ELSIF INSERTING THEM
l_dml_type := 'I';
ELSE — удаление
l_dml_type := 'D';
END IF;
IF l_dml_typ IS NOT NULL
THEN INSERT INTO salary_change_log ( emp#
, transaction,dt
, user_name
, dml_type
, old_sal_value
, new_sal_value
) VALUES
( :new.emp_no
, SYSDATE
, USER
, l_dml_typ
, ;old.salary
, :new.salary
);
END IF;
END pay_aud;
/
Мы добавляем в таблицу PAYROLL столбец, содержащий максимальный номер изменения для каждого сотрудника. Затем, когда потребуется сделать запись аудита, мы прочитаем элемент таблицы PAYROLL для данного сотрудника, получим текущий номер, прибавим к нему единицу, обновим таблицу PAYROLL и вставим новую строку в таблицу аудита. Однако при этом проявится проблема мутирующих таблиц, способ борьбы с которой описан в приложении Б.
На данном этапе мы уверены, что продемонстрировали аудиторам свою способность регистрировать все операции, которые выполняются со строкой (за исключением, конечно, запросов к ней). Но предела их желаниям нет, и них возникает выдающаяся идея: мы должны расширить сферу аудита и обеспечить регистрацию всех изменений всех столбцов всех таблиц. Как вам это нравится? В этом случае нам не только придется задействовать огромный объем пространства БД для хранения этих данных и ресурсы центрального процессора на создание записей журнала аудита, но и написать (и протестировать) огромные объемы триггерного кода. (У нас ушло достаточно много времени на отладку триггера pay_aud в примере 10.1, а ведь оба мы имеем значительный опыт проектирования и написания триггеров для задач аудита.)
По этому поводу мы рекомендуем следующее:
1. Старайтесь избегать полного аудита вставки строк, так как строка сама обычно может регистрировать свои значения.
2. Не пытайтесь использовать всего одну таблицу аудита. SQL вообще плохо обрабатывает метаструктуры, и гораздо проще иметь отдельную таблицу аудита для каждой таблицы. Если есть две таблицы с одинаковыми определениями столбцов (секционированные данные), то при необходимости они могут совместно использовать одну таблицу аудита.
3. Для создания триггеров аудита используйте генератор. Если по какой-то причине их нужно исправить, не пытайтесь корректировать сгенерированный код, а исправьте генератор и постройте триггеры заново. Это один из случаев, когда, вы можете выбрать легкий путь (читая нашу книгу и следуя нашим советам) или трудный путь (и затем объяснять своему начальнику, почему простое изменение в спецификации повлекло за собой двухлетнее отставание от графика).
Альтернативный подход
Достаточно жизнеспособная альтернатива созданию журналов аудита для обновлений и удалений заключается в том, чтобы никогда не изменять никакие данные (т.е. не обновлять базовые данные) и никогда не удалять строки, кроме как в операциях архивации. Приняв эти два правила (и введя их триггерами), вы никогда не потеряете данные и не пропустите промежуточное состояние, которое существовало, может быть, всего несколько часов.
Как же такое возможно? Один из способов реализации этого метода состоит в хранении производных записей. Так, в нашем примере с зарплатой может существовать производная запись (ведомая только триггерами), содержащая текущее значение каждого атрибута для каждого сотрудника, и справочная таблица, отражающая все промежуточные состояния, в которых строка находилась за время своего существования, а также метку времени и идентификатор обновляющего пользователя. Другими словами, в данном случае приложение осуществляет запись в журнал аудита, а триггеры ведут "реальные данные". Многим очень тяжело принять такой подход, но он может оказаться весьма эффективным и при ближайшем рассмотрении создает меньше проблем в реализации, чем традиционное решение. Конечно, в этом случае используется очень много пространства и нет возможности непосредственно воспользоваться средствами ускоренной разработки приложений.
Другие вопросы, относящиеся к этому методу проектирования, описаны в главе 17.
Советы по аудиту
В этом разделе мы даем еще несколько советов по аудиту.
Не отключайте триггеры аудита
Триггеры можно, конечно, отключить, и возникает сильное искушение сделать это на время работы определенных "доверенных" пакетных процессов. Это может вызвать катастрофу, потому что нет надежного способа помешать другому (не доверенному) процессу получить доступ к данным, когда триггер отключен.
Более эффективный метод — подавление триггеров, управляемое данными, когда триггер спрашивает у пакетной процедуры, действовать ему или нет. Пакет содержит глобальную переменную, которую может устанавливать другая процедура, и если это делается корректно, то пакет может дать триггеру указание не делать записей аудита. Такой подход может показаться ненадежным, но он надежнее, чем отключение триггеров аудита. При необходимости можно воспользоваться паролями и криптографическими приемами, которые обеспечат предоставление прав на подавление действия триггеров уполномоченным на это пользователям.
Поиск пользовательского имени
На многих узлах Oracle используются регистрационные идентификаторы общего назначения (например, PRODUCTION), и все несколько сотен пользователей такого узла могут быть подключены к Oracle под одинаковым пользовательским именем. По сути дела, это является условием эффективного использования среды менеджера обработки транзакций. В этом случае аудит на базе пользовательского имени Oracle не всегда эффективен. Решение, как и в предыдущем подразделе, состоит в использовании пакета с глобальной переменной и обязательном представлении пользователя этому пакету до того, как триггеры аудита разрешат обновление контролируемых таблиц. Этот подход, который рассматривается ниже в разделе "Безопасность", не очень приветствуется в среде пользователей Oracle, но дает высокую эффективность.
Роль анализа журналов в аудите
Если вам доступен анализатор журналов, то одно из возможных направлений проверки состоит в том, чтобы установить, сработали триггеры или нет. Так, если использовать триггер для регистрации всех изменений в таблице PAYROLL, то путем анализа журнала можно убедиться, что каждая операция над таблицей сопровождалась записью аудита.
Журналы, которые сохраняются путем архивации почти на всех узлах, выполняющих обновление важнейших данных, предоставляют аудитору массу возможностей:
• Эти журналы находятся вне базы данных, поэтому никакой уровень привилегий в Oracle не даст возможности получать к ним доступ через SQL. К этим журналам можно обратиться только из операционной системы на файловом уровне.
• Журналы предполагают жесткое упорядочение, поэтому легко увидеть, отсутствует ли какой-нибудь из них или нет.
• Журналы содержат новые значения и старые значения, связанные с каждой DML-операцией, за исключением прямой загрузки и невосстановимых копий из одной таблицы в другую.
• Они ведутся практически независимо, так как Oracle записывает их независимо от того, будут они использоваться или нет.
Все это выглядит слишком хорошо для того, чтобы быть правдой, но это действительно правда. К сожалению, есть два существенных препятствия. Во-первых, Oracle формально не поддерживает обработку журналов, и, во-вторых, несмотря на наличие абсолютно всех значений данных, невозможно определить, какой пользователь выдал оператор.
Предупреждение
Нам приходилось видеть и попытки использовать тот факт, что представление V$SQLAREA в столбце SQL_TEXT содержит последний SQL-оператор. Настоятельно рекомендуем не делать так. Этот механизм позволяет увидеть только первые 1000 символов SQL-операторов. Сюда включаются все рекурсивные SQL-операторы, и их нельзя отличить от выданных пользователем. Связанные переменные не вычисляются, поэтому во многих случаях нельзя увидеть фактические значения столбцов. Кроме того, поскольку это представление содержит SQL-код, выданный всеми пользователями системы, то трудно разобраться в том, кто и что выдавал.
Безопасность
Если средства аудита — это наша системная полиция, то служба безопасности системы является подразделением по профилактике преступности. Проявите к безопасности своей системы то уважение, которого она заслуживает, — ведь лучше предотвратить нарушение, чем ловить нарушителя после него.
Средства безопасности Oracle7 можно разделить на две категории:
• безопасность доступа определяет, кто попадает в приложение и какую его часть этот кто-то может использовать (или какая часть доступна для него);
• безопасность данных определяет, к каким таблицам пользователь может обращаться и что он может делать с ними. В некоторых случаях безопасность данных может охватывать уровень строк и столбцов, но обычно она используется для предоставления прав доступа (для запроса, вставки обновления и удаления) ко всей таблице.
При наличии хороших правил безопасности, охватывающих и доступ, и данные, должна обеспечиваться приемлемо надежная среда эксплуатации, в которой исключается вероятность несанкционированного доступа к данным или к программам:
Примечание
Если вы проектируете систему, для которой требуется более высокий уровень безопасности, то описанные в этом разделе средства могут оказаться недостаточными. В этом случае необходимо использовать продукт Trusted Oracle. Мы не описываем его в нашей книге, но вы можете воспользоваться множеством материалов, предоставляемых Oracle по данному предмету.
Безопасность доступа
В Oracle7 имеется целый ряд механизмов для идентификации и верификации пользователей. Самый простой из них — заставить каждого пользователя при первом подключении указывать свое имя и пароль. Эта верификация должна выполняться независимо от того, какое внешнее интерфейсное средство используется для доступа к базе данных. Идея состоит в том, чтобы допустить пользователя к работе со средствами базы данных только после того, как он установит санкционированное соединение с ней. Имя пользователя и пароль сверяются с указанными в таблице SYS.USER$, куда пароль заносится в зашифрованной форме. Администраторы БД видят только зашифрованный пароль в таблице (расшифрованный не видит никто). Мы не знаем ни одного человека, который ухитрился расшифровать пароль в среде Oracle.
Большинство пользователей рассчитывают на то, что им придется входить в систему только один раз (и правильно делают). Если они указали имя и пароль при входе в операционную систему — особенно если средства безопасности этой ОС работают хорошо — то почему они должны указывать другое имя и другой пароль для подключения к Oracle? Для решения этой проблемы в Oracle введен механизм, известный как OPS$-регистрация: если пользователь ввел пустое имя (и не указал пароль), Oracle подключает его к базе данных как соответствующего Oracle-пользователя, принимая идентификационные данные, полученные операционной системой. Эти бюджеты называются OPS$-бюджетами, потому что в версии 5 именем пользователя Oracle всегда было пользовательское имя в операционной системе, снабженное префиксом OPS$. В текущих версиях этот префикс является параметром уровня экземпляра и может быть пустым, чтобы имена пользователей в операционной системе и в Oracle могли совпадать.
OPS$-бюджеты (мы будем продолжать называть их так) полезны во многих обстоятельствах, но у них все же есть определенные недостатки. Во-первых, в более старых операционных системах для ПК, например в Windows 3.1 и OS/2, средств регистрации пользователей нет. Для этой среды придется задать стандартное имя пользователя в файле конфигурации, но это безопасно лишь в той степени, которую обеспечивает физическая безопасность машины. Если не принять некоторые дополнительные меры, то любой человек, имеющий доступ к вашему ПК, может воспользоваться вашим стандартным именем пользователя Oracle.
OPS$-бюджеты могут также быть совершенно незащищенными в средах клиент/сервер, где клиентские машины требуют от пользователя регистрации. Пользователь может управлять несколькими рабочими станциями или, зная пароль системного администратора (в Unix — пароль root), может подключать к своей машине новых пользователей. Это открывает дверь для нападений на базу данных такими методами, как спуфинг (пародирование) и фрикинг (обманный маневр).
Спуфинг означает создание пользователя, о котором известно, что он существует и пользуется привилегиями где-то в сети. Это позволяет вам (или другому лицу, обладающему достаточными знаниями) создать для этого пользователя бюджет на машине, которую вы контролируете, а затем подключиться к другой машине, на которой это имя пользуется определенными привилегиями. В некоторых системах спуфинг частично блокируется благодаря тому, что соединения можно устанавливать только с определенных машин. Это привело к появлению второго метода, фрикинга, который заключается в том, что машину конфигурируют таким образом, чтобы она представлялась серверу как одна из машин, имеющих разрешение на установление соединения.
Поэтому не удивительно, что в Oracle есть параметр инициализации сервера, который не дает клиентским машинам пользоваться OPS$-регистрацией. Наш совет — отключите удаленную OPS$-регистрацию.
Необходимо также отметить еще одно достоинство OPS$-регистрации — она существенно затрудняет определенные типы воплощения. В частности, OPS$-регистрация не позволяет администраторам БД менять пользовательские пароли, чтобы подключиться к базе данных в качестве конкретного пользователя и внести какие-то полезные изменения (которые при последующем аудите определяются как сделанные этим пользователем, а не администратором). Знающий администратор может потом вернуть пароль пользователя в исходное значение, даже если оно ему не известно. Конечно, с проектирование м это практически не связано, но на случай, если в это верится с трудом, вот соответствующий код:
SQL> connect sys/whatever
SQL> col password new_value &pw
SQL> SELECT password FROM dba_users WHERE user-name = 'USER_A'
PASSWORD
-----------------
88f10186D82B38F2
SQL> alter user user_a identified by xx;
- изменение пароля
User altered.
SQL> connect user_a/xx
Connected.
SQL> alter user user_a identified by values '&pw'
User altered.
SQL>
- пароль пользователя user_a возвращен в исходное состояние
Еще одно замечание о безопасности систем клиент/сервер. Если разрешены соединения по глобальной сети, то решительный взломщик может проследить за данными между клиентом и сервером, увидеть запрос на соединение и прорваться с помощью такого же запроса в систему. В этом случае может помочь клиентский параметр ORA_ENCRYPT_LOGIN. Если он установлен, то регистрационная строка между клиентом и сервером шифруется. Отметим также, что продукт SQL*Net Secure Network Services версии 2.0 и выше поддерживает службы аутентификации промышленного стандарта, такие как Kerberos и Sesame.
К сожалению, в Oracle7 нет поддержки механизма старения паролей, который заставлял бы пользователя периодически определять новый пароль. Если вы хотите использовать такое средство в системе (а это очень хорошая идея), придется написать его код самому. Можно, кроме того, вести протокол паролей (или хотя бы их зашифрованных значений), чтобы они не использовались повторно.
В отличие от многих систем, в Oracle нет задержки при выдаче отказа в соединении вследствие ввода неправильного пароля. Это значит, что комбинаторные методы (или просто использование любого известного имени) могут быть эффективным способом прорыва в базы данных, где используется традиционная для Oracle аутентификация. Идеальный вариант — сделать так, чтобы во всех паролях было не меньше шести символов, из которых хотя бы один должен быть не буквой. К сожалению, для этого нужно в рамках приложения написать код, который будет обрабатывать изменения паролей. Если какой-нибудь изобретательный хакер вставит в этот код "журнал аудита", позволяющий регистрировать все изменения паролей, то серьезных проблем с безопасностью не избежать.
Несмотря на наши предостережения, идеальным решением для выполнения процесса регистрации все равно может показаться вызов пользовательской подпрограммы. Эта подпрограмма проверяла бы (в таблице) дату и время последнего изменения пароля пользователя и вносила бы изменение, если срок действия пароля истек. Еще одно преимущество такой инкапсуляции процесса регистрации состоит в том, что мы можем отключить пользовательский бюджет, если производятся многократные попытки регистрации по недействительному паролю. Главная проблема такого подхода в том, что он зависит от взаимодействующих клиентских процессов. Мы можем заставить подключаться таким образом все приложения, написанные в рамках нашего проекта, но средства создания нерегламентированных запросов и приложения третьих фирм нам в этом плане неподвластны.
Безопасность доступа и меню
В большинстве приложений баз данных существуют разные категории пользователей, которые работают с разными частями системы и имеют разные права на просмотр и изменение данных. В простом случае может быть всего два класса пользователей: те, кто вводит данные (операторы ввода данных), и менеджеры, выполняющие запросы к данным. Менеджеров не интересует ввод данных, а операторам ввода мы не позволим составлять отчеты. В этом случае у операторов ввода данных и менеджеров могут быть совершенно разные приложения, потому что их функциональные возможности не пересекаются, однако эти приложения могут совместно использовать одну базу данных.
Но в большинстве случаев существует несколько категорий пользователей, и функциональные возможности, к которым они должны иметь доступ, пересекаются. В таких ситуациях можно избежать дублирования работы, создав одно приложение с меню или панелью инструментов, вид и содержимое которой зависят от задач конкретного пользователя. Большинство инструментальных средств разработки позволяет динамически изменять содержимое меню во время выполнения в зависимости от пользователя. К сожалению, некоторые инструменты анализируют права доступа во время генерации, а не во время выполнения, поэтому мы рекомендуем использовать инструмент, который способен учесть права пользователя в оперативном режиме. Такой инструмент интенсивнее использует сеть и сервер, но позволяет значительно быстрее реагировать на проблемы, связанные с безопасностью.
Мы предпочитаем скрывать пункты меню от пользователей, не имеющих права на доступ к ним, а не просто делать их затененными. Наличие таких пунктов на экране в любой форме может послужить стимулом поиска "черного хода" к ним.
И еще несколько слов в отношении "черного хода". Мы рекомендуем не только пользоваться специализированным меню, но и сделать так, чтобы каждое приложение проверяло, имеет ли вызвавший его пользователь право на его выполнение. Если это не так, то приложение должно закрываться и регистрировать это нарушение в журнале контроля.
Пакетные процессы
Мы рассмотрели вопрос ограничения прав пользователей, работающих в интерактивном режиме, но, помимо этого, нужно обеспечить проверку при передаче пакетных заданий и отчетов. Например, можно запретить некоторым пользователям выполнять или планировать определенные задания или отчеты посредством пакетной очереди. Механизм, используемый для реализации этой схемы, зависит от того, какой планировщик пакетов используете в данной среде. Такое управление должно осуществляться как на этапе передачи заданий, так и во время выполнения. Проверку следует выполнять при передаче, потому что бессмысленно разрешить пользователям передавав задания, которые затем не будут выполнены из-за того, что у пользователя недостаточно прав. Однако в целях повышения уровня безопасности эту проверку следует также производить во время выполнения - на случай если кто-то сумел проникнуть через систему передачи.
Пакетные процессы, включая процессы, генерирующие отчеты не всегда могут работать, используя только бюджет запускающего их пользователя. Даже если у пользователя есть разрешение на выполнение задания он может не знать пароль базы данных, дающий достаточные привилегии для доступа к некоторым нужным таблицам. Вопрос о том, знают ли пользователи о паролях базы данных, используемых от их имени, приобретает важное значение на тех узлах, где конечным пользователям доступен SQL*Plus
Мы не перестаем удивляться тому, сколько существует узлов, на которых не обеспечена защита важнейших пакетных заданий на обновление данных от выполнения их неуполномоченными пользователями. Если вы опасаетесь что пользователи-мошенники могут навредить вам, работая в интерактивном режиме, то представляете, что они могут сделать, если получат возможность инициировать массовое обновление, используя собственные драйверные файлы.
Безопасность данных
Если мы уверены, что подключаться к нашей базе данных могут лишь уполномоченные пользователи и что они могут запускать только те модули на выполнение которых им явно предоставлено право, то нужно подумать о следующем уровне безопасности - ограничении доступа этих пользователей к данным.
Огромным шагом вперед в обеспечении безопасности данных стало введение ролей в Oracle7. До Oracle7 каждому пользователю приходилось явно предоставлять права доступа к каждому объекту базы данных, который ему разрешено было использовать. Этот процесс упрощается за счет того, что доступ к совокупности объектов предоставляется роли, а затем право на использование этой роли предоставляется соответствующим лицам. С помощью команды GRANT мы можем предоставить пользователям право выполнять над объектами ВД (например, над таблицами) операции SELECT, INSERT, UPDATE и DELETE. Однако само по себе это не обеспечивает значительной гибкости. Мы можем ограничить доступ пользователей частями таблицы, разделив ее по горизонтали (ограничив пользователя определенными строками), по вертикали (ограничив его определенными столбцами) или и по горизонтали, и по вертикали. Как это сделать?
Вернемся к нашему примеру с таблицей PAYROLL. Мы не хотим, чтобы все пользователи видели столбец SALARY, и желаем ограничить доступ пользователей так, чтобы они могли видеть только записи о сотрудниках их отдела. Видимая часть таблицы выделена в табл. 10.1 курсивом.
Таблица 10.1. PAYROLL
ID
NAME
DEPT
PAYMENT_PERlOD
SALARY
1 2 3 4 5 6
JONES KIRKUP DAVIES ARMSTRONG KEMP FISHER
10 10 10 20 20 30
WEEKLY MONTHLY WEEKLY MONTHLY MONTHLY WEEKLY
120 900 150 1030 1005 150
Мы можем определить представление и предоставить пользователям доступ к этому представлению, а не к базовой таблице (PAYROLL). Они смогут запрашивать данные этой таблицы лишь через представление, которое ограничивает их доступ. Определение такого представления приведено ниже.
CREATE VIEW v_payroll AS
SELECT id
, name
, dept
, payment_period
FROM payroll
WHERE dept = (SELECT dept
FROM mysys_users
WHERE username = USER)
WITH CHECK OPTION;
Столбец SALARY в этом примере не включен в представление, поэтому зарплату в нем увидеть нельзя, а фраза WHERE гарантирует, что пользователи смогут запрашивать данные из таблицы PAYROLL только по своему отделу.
По поводу этого решения надо сказать следующее. Во-первых, мы должны сделать так, чтобы пользователи не могли изменить свой отдел, обновив значение MYSYS_USERS, и затем запросить записи из другого отдела. Во-вторых, с помощью этого представления пользователи могли бы обновлять, вставлять и удалять даже не относящиеся к их отделу строки таблицы PAYROLL, если бы мы не отключили эту функцию с помощью фразы WITH CHECK OPTION.
Примечание
Вряд ли представление V_PAYROLL будет обновляемым, потому что к столбцу SALARY почти наверняка применено ограничение NOT NULL. Тем не менее, мы рекомендуем использовать опцию WITH CHECK OPTION во всех ограничивающих представлениях, так как в версии 7.3 значительно увеличилось число обновляемых представлений.
Ограничение на просмотр данных с помощью представлений работает очень хорошо. Но для большой таблицы со сложными требованиями к безопасности, возможно, придется создать несколько представлений и заставить приложения решать, какое из них необходимо для конкретного пользователя. Реализовывать это внутри приложения нежелательно, поэтому нужно исследовать другие решения. Мы можем инкапсулировать все операции над таблицей PAYROLL в хранимый пакет или же разработать несколько триггеров. Давайте рассмотрим первое решение.
Использование пакетов
В пакете есть методы (процедуры/функции), позволяющие оперировать таблицей или запрашивать из нее строки. Пользователю, у которого есть разрешение на выполнение пакета, но нет полномочий на доступ к таблице, содержимое и структура таблицы непосредственно недоступны. Владелец пакета имеет полный доступ к PAYROLL, а вызывающий пользователь — нет. Когда пользователь выполняет хранимую процедуру, т.е., по сути, использует представление, он действует с разрешением на доступ, предоставленным ее владельцу.
Наша первая попытка создать такой пакет представлена в примере 10.2. Пакет k_payroll гарантирует, что записи могут удаляться только начальником отдела и что устанавливать значение столбца SALARY может только начальник отдела.
Пример 10.2. Первая попытка построения пакета для обеспечения безопасности доступа к данным
CREATE OR REPLACE PACKAGE k_payroll AS
my_dept payroll.dept%TYPE;
mgr BOOLEAN;
PROCEDURE del (p_emp_id INTEGER);
PROCEDURE ins (p_emp_id INTEGER, p_name VARCHAR2
,p_dept INTEGER, p_payment_period VARCHAR2
,p_salary INTEGERS);
PROCEDURE upd (p_emp_id INTEGER, p_name VARCHAR2
,p_payment_period VARCHAR2 ,p_salary INTEGER);
END k_payroll;
/
CREATE OR REPLACE PACKAGE BODY k_payroll AS
mgr_flag payroll.mgr_flag%TYPE;
CURSOR c_me IS
SELECT dept,
mgr_flag
FROM mysys_users
WHERE username = USER;
FUNCTION checkdept (p_emp_id INTEGER) RETURN BOOLEAN IS
dept payroll.dept%TYPE;
CURSOR c_payroll IS
SELECT pay.dept
FROM payroll pay
WHERE id = p_emp_id;
BEGIN
OPEN c_payroll;
FETCH c_payroll INTO dept;
CLOSE c_payroll;
IF dept <> my_dept THEN
RETURN FALSE;
END IF;
RETURN TRUE;
END checkdept;
PROCEDURE del (p_emp_id INTEGER) IS
- Удалять сотрудников могут только начальники их отделов
- Записи таблицы Payroll
BEGIN
IF checkdept(p_emp_id) AND mgr THEN
DELETE payroll
WHERE id = p_emp_id;
ELSE
raise_application_error (-20001, 'Insufficient Privilege');
END IF;
END del;
PROCEDURE ins (p_emp_id INTEGER, p_name VARCHAR2
,p_dept INTEGER, payment_period VARCHAR2
,p_salary INTEGER) IS
- Можете вставлять записи Payroll только в свой отдел
- Устанавливать зарплату может только начальник отдела
(в противном случае устанавливается в пустое значение)
l_salary payroll.salary%TYPE;
BEGIN
IF NOT checkdept(p_emp_id) THEN
raise_application_error (-20001, 'Insufficient Privilege');
END IF;
IF NOT mgr THEN
l_salary := NULL;
ELSE
l_salary := p_salary;
END IF;
INSERT INTO payroll (id,name,dept,payment_period,salary)
VALUES (p_emp_id,p_name,p_dept,p_payment_period,l_salary);
END ins;
PROCEDURE upd (p_emp_id INTEGER, p_name VARCHAR2
,p_payment_period VARCHAR2 ,p_salary INTEGER) IS
- Можете обновлять записи Payroll только в своем отделе
- Обновлять зарплату может только начальник отдела
(в противном случае остается без изменений)
- Отдел изменять нельзя
l_salary payroll.salary%TYPE;
CURSOR c_old_salary IS
SELECT pay.salary
FROM payroll pay
WHERE id = p_emp_id;
BEGIN
IF NOT checkdept (p_emp_id) THEN;
raise_application_error (-20001, 'Insufficient Privilege');
END IF;
IF NOT mgr THEN
OPEN c_old salary;
FETCH c_old_salary INTO l_salary;
CLOSE c_old salary;
ELSE
l_salary := p_salary;
END IF;
UPDATE payroll
SET name = p_name
,payment_period = p_payment_period
,salary = l_salary
WHERE id - p_emp_id;
END upd;
- Код инициализации пакета
BEGIN
OPEN c_me;
FETCH c_me
INTO my_dept
,mgr_flag;
CLOSE c_me;
IF mgr_flag = 'Y' THEN
mgr := TRUE;
ELSE
mgr := FALSE;
END IF;
END k_payroll,
/
Использование триггеров
Несмотря на преимущества инкапсуляции, решение, приведенное в предыдущем разделе, не идеально, поскольку код очень "привязан" к таблице PAYROLL. Это означает, что при изменении структуры PAYROLL мы должны корректировать пакет. Кроме того, мы еще не касались самого "хитрого" вопроса — поддержки запросов с помощью данного пакета. По сути, функциональные возможности, предоставляемые этим пакетом, гораздо легче реализовать в виде триггеров — их применение позволяет уменьшить влияние изменений в структуре таблицы.
Очевидное достоинство пакета состоит в том, что мы можем хранить информацию о пользователе (его отделе и о том, начальник ли он) в глобальных переменных, а не запрашивать ее каждый раз. Однако мы можем обратиться к пакету из триггеров и таким образом добиться тех же преимуществ.
Однако действительное преимущество триггеров в данном случае (при условии, что они включены) заключается в том, что их действие неотвратимо, и это заставляет всех играть по одним правилам. Вспомните, ведь мы говорим о безопасности данных, а не о безопасности доступа, поэтому должны применять процедурные правила к данным. А для этого необходимы триггеры.
Перед тем как перейти к теме запросов, давайте изучим триггерное решение, в котором используется пакет k_payroll (пример 10.3). Эти триггеры заменяют функции INSERT, DELETE и UPDATE из k_payroll. Пакет сохраняется, чтобы можно было воспользоваться преимуществами общего кода и глобальных переменных.
Пример 10.3. Использование триггеров для обеспечения безопасности таблицы PAYROLL
CREATE OR REPLACE TRIGGER pay_bir BEFORE INSERT ON payroll
FOR EACH ROW
BEGIN
IF :new.dept <> k_payroll.my_dept THEN
raise_application_error (-20001, 'Insufficient Privileges');
END IF;
IF NOT k_payroll.mgr THEN
:new.salary := NULL;
END IF;
END pay_bir;
/
CREATE OR REPLACE TRIGGER pay_bdr BEFORE DELETE ON payroll
FOR EACH ROW
BEGIN
IF :new.dept <> k_payroll.my_dept
OR NOT k_payroll.mgr THEN
raise_application_error (-20001, 'Insufficient Privileges');
END IF;
END pay_bdr;
/
CREATE OR REPLACE TRIGGER pay_bur BEFORE UPDATE ON payroll
FOR EACH ROW
BEGIN
IF :new.dept <> k_payroll.my_dept THEN
raise_application_error (-20001, 'Insufficient Privileges');
END IF;
IF NOT k_payroll.mgr THEN
:new.salary := :old.salary;
END IF;
IF :new.dept <> :old.dept THEN
raise_application_error (-20002, 'Cannot transfer department');
END IF;
END pay_bur;
/
Теперь осталось решить вопрос о том, как получить процедурный контроль над доступом к данными, если в БД нет триггеров SELECT. Самое очевидное решение — инкапсулировать эти запросы в пакет, но оно имеет ряд существенных недостатков. Некоторые из них зависят от того, какая конкретно редакция Oracle7 используется. Вот самые важные недостатки:
• Очень немногие инструментальные средства разработки поддерживают использование процедур для выборки данных.
• Их поддерживает еще меньшее число средств создания нерегламентированных запросов (а, скорее всего, именно здесь нам понадобится максимально эффективная поддержка).
• Если при каждом вызове должны возвращаться все атрибуты (что может создать чрезмерную нагрузку на центральный процессор), то нужно решать ряд серьезных вопросов, связанных с тем, как задан список атрибутов и как он передается в вызывающую программу.
• Трудно спроектировать хороший интерфейс для пользовательских условий, который для выдачи эффективных запросов не требовал бы наличия в процедуре синтаксического анализатора.
• Массивная выборка с помощью процедур поддерживается только в последних версиях PL/SQL.
• Даже если синтаксис предикатов согласован, то процедура должна использовать динамический SQL внутри PL/SQL. Эта возможность доступна начиная с версии 7.1, но очень утомительна и трудна для программирования.
В высокотехнологичных проектах эти проблемы решаются весьма успешно, но для большинства проектов это — страшное препятствие. В PL/SQL версии 2.3 значительно улучшена поддержка передачи курсоров, но опыт работы с этой версией пока еще незначителен.
Впрочем, прежде чем окончательно разочароваться, вернемся к теме представлений и продемонстрируем, что начиная с версии 7.1 можно вызывать функции PL/SQL из SQL-предложений. В версии 7.1 в этой области существуют некоторые трудности (дефекты), но начиная с версии 7.2 можно смело использовать в SQL-предложениях вызовы пользовательских функций и заставлять эти функции выдавать SQL-запросы. Это иллюстрируется следующим примером:
CREATE VIEW v_payroll AS
SELECT id
, name
, dept
, payment_period
FROM payroll
WHERE v_util.check_access(dept_code => dept) = 'Y'
WITH CHECK OPTION;
Здесь мы предполагаем, что пользователь ранее вызывал другую часть пакета v_util для регистрации своего идентификатора. Огромное преимущество этого метода состоит в том, что он не зависит от того, какое пользовательское имя применялось для подключения к базе данных. Полагая, что в этой главе уже достаточно много SQL-кода, мы не привели текст функции v_util.check_access, но хотим отметить, что, в зависимости от конкретных целей, он может быть как простым, так и сложным.
Резервное копирование
Мы думаем, что каждому понятно, зачем нужны резервные копии. Если нет последней резервной копии, то в случае отказа или катастрофы нашей компьютерной системы или данных данные пропадут. Большинству организаций их данные необходимы для работы, а многие из них вообще прекратят свою деятельность, если данные безвозвратно пропадут или станут недоступными на длительный период. В некоторых случаях "период выживания" предприятия составляет всего четыре часа. Видов неисправностей очень много. Какими бы надежными не были аппаратные и программные средства, может случиться, что они не смогут защитить вас от террористов, наводнения или землетрясения.
Стратегия резервного копирования
Необходимость наличия в каждом проекте стратегии резервного копирования, учитывающей особенности конкретных приложений, может и не быть очевидной. Дело в том, что безопасность данных стоит дорого, и необходимо согласовать объем инвестиций в эту сферу как с важностью данных, так и с характером работы системы. Давайте рассмотрим две крайние с точки зрения требований к резервному копированию ситуации.
Самая сложная ситуация
Некоторые системы по самой своей природе требуют круглосуточной работы семь дней в неделю (так называемые системы 24х7). Любой простой обходится организации в большую сумму. В таких случаях необходимо вкладывать значительные средства в избыточные аппаратные средства. Если главная система отказывает, то резервная аппаратура немедленно принимает на себя управление. На работу пользователей этот переход влияет очень мало (если вообще влияет). В такой ситуации механизм резервного копирования должен обеспечивать непрерывную передачу транзакций с действующей машины на резервную, чтобы последняя всегда содержала актуальные данные. Эффективным, хотя и дорогостоящим способом такого резервного копирования является технология симметричной репликации, реализованная в Огас1е7 (см. главу 12). Если для организации приемлема потеря данных за последние несколько минут, то еще один эффективный вариант — архивация журналов на резервном узле и немедленное применение их в случае отказа.
Самая простая ситуация
Некоторые системы используются главным образом для запросов, и данные в них изменяются редко. В этих системах резервное копирование может вообще не требоваться, если все содержащиеся в них данные можно восстановить из других работающих систем (как это часто бывает с приложениями хранилищ данных). Тем не менее, нужно сопоставить стоимость такого восстановления всей базы данных (из многих источников, находящихся в разных местах) со стоимостью периодического резервного копирования.
В подавляющем большинстве систем требования к резервному копированию находятся где-то между двумя этими полюсами. Наша задача как проектировщиков — точно определить эти требования. Для этого необходимо опросить основных пользователей и обслуживающий персонал. Ниже приведен перечень примерных вопросов, которые могут помочь в решении этой задачи.
Вопросы к пользователям:
• В какое время суток и в какие дни недели система должна быть полностью доступна для работы?
• Приемлемы ли нерегулярные периоды запланированного простоя?
• Приемлемы ли периоды, когда доступ к системе ограничен?
• Есть ли данные, которые после аварии нельзя будет получить из других источников? (Это часто бывает в системах ввода заказов на телефонные переговоры, а также при сборе данных с датчиков и автоматизированных устройств.)
• Если данные получить можно, то каков объем данных, которые необходимо будет ввести повторно в случае серьезной неисправности?
• Каковы приемлемые временные рамки для возврата системы в рабочее состояние в случае отказа?
Вопросы к обслуживающему персоналу:
• Имеется ли график суточных пакетных заданий? (Вероятно, на этот вопрос должен ответить проектировщик.)
• Когда система будет (если будет) укомплектована обслуживающим и вспомогательным персоналом?
• Какие еще приложения работают на этом же оборудовании или в этой же сети?
• Существует ли план восстановления на случай аварии, и охвачена ли им данная система?
• Имеются ли резервные аппаратные средства или аппаратные средства с запасом мощности?
• На какую среднюю скорость передачи данных можно рассчитывать при резервном копировании? (Этот вопрос в корне отличается от вопроса о скорости передачи данных, которую может обеспечить устройство, и о полосе пропускания сети.)
• Имеется ли защищенное место для хранения резервных носителей?
• Имеются ли правила циклического использования резервных носителей?
Получив ответы на эти вопросы, мы должны рассмотреть поставленные требования и ограничения, а затем предлагать решения. Какие же варианты имеются в нашем распоряжении?
Создание образа базы данных
База данных Oracle хранится в совокупности файлов операционной системы. С точки зрения резервного копирования и восстановления самыми важными из них являются следующие:
• файлы данных;
• управляющие файлы;
• журнальные файлы.
Резервные копии этих файлов можно создавать с помощью стандартных средств резервного или обычного копирования, имеющихся в операционной системе. Этот вид резервного копирования мы будем называть созданием образа базы данных. Запомните, что каждая резервная копия образа базы данных должна включать все три набора файлов, эти наборы должны быть полными и восстанавливаться только как наборы. Попытка смешать файлы из разных наборов приведет к печальным результатам. Если у вас нет полного и достоверного набора файлов данных, управляющих и журнальных файлов, то большинство проблем, возникающих в этой ситуации, можно решить с помощью службы Oracle Worldwide Support, однако лучше все-таки обеспечить наличие полного набора.
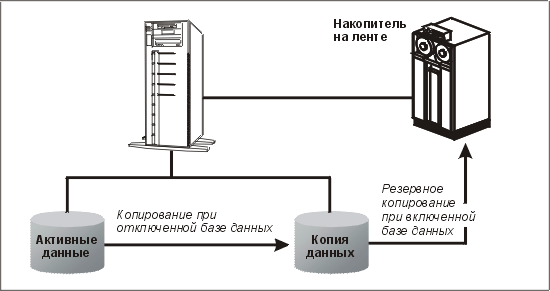
Если эти файлы копируются на съемные носители, например на ленту (а так и нужно делать), их можно вынести за пределы узла. При резервном копировании файлов базы данных существенно важно, чтобы копия представляла собой "снимок" в один момент времени. В противном случае резервные копии будут так же полезны, как шоколадный чайник или пепельница на мотоцикле. Это значит, что на время резервного копирования базу данных необходимо отключить (если только мы не работаем в режиме архивации журналов; см. ниже). Утилиты резервного копирования операционной системы обычно работают быстро, поэтому простой должен быть недолгим. Если мы собираемся копировать данные на медленнодействующее устройство, например на ленту, или сжимать файлы, лучше сначала выполнить быстрое копирование образа с диска на диск, чтобы базу данных можно было включить. Затем резервное копирование можно выполнять с полученной копии, как показано на рис. 10.1. Однако из-за дефицита пространства это возможно не всегда.
Рис. 10.1. Ускорение процесса резервного копирования с помощью промежуточной копии
На некоторых платформах этот же результат можно получить с помощью зеркальных дисков. Необходимо выполнить примерно такую процедуру:
1. Закрыть экземпляр базы данных.
2. Приостановить процесс создания зеркальной копии.
3. Перезапустить экземпляр базы данных, обновляя только одну копию данных.
Этот подход, на первый взгляд, выглядит привлекательно, но в действительности у него много недостатков. Перед тем как принять решение о его применении, необходимо выяснить, сколько времени понадобится на синхронизацию зеркальной копии в операции 5. Нам приходилось сталкиваться с системами, в которых этот процесс занимал несколько дней, и, конечно, в то время, пока система работает без зеркальной копии, никакой надежной защиты от отказов носителей нет.
Создание образа базы данных — относительно быстрый и легкий способ, но у него все же есть ряд недостатков. Когда дело доходит до восстановления с резервной копии, выполненной средствами операционной системы, пользователь получает все или ничего: база данных полностью восстанавливается в состояние, в котором она находилась в момент снятия резервной копии или в более поздний момент, если имеется набор заархивированных журналов. Это создает трудности, если нужно восстановить только одну таблицу. Если таблица "потерялась" либо из-за ошибки приложения или пользователя повреждены некоторые ее строки, то для восстановления таблицы необходимо выполнить следующие операции:
1. Снять резервную копию с текущей базы данных.
2. Восстановить данные с самой последней резервной копии (предшествующей только что снятой).
3. Сохранить копию таблицы (как правило, с помощью утилиты экспортирования Oracle).
4. Восстановить данные с резервной копии, снятой в операции 1.
5. Воссоздать таблицу, сохраненную в операции 3 (как правило, с помощью утилиты импортирования Oracle).
Мало того, что этот процесс занимает очень много времени, так он еще может остановиться из-за нарушений ограничений ссылочной целостности. Мы рекомендуем предпринимать такое восстановление только после глубокого анализа последствий для конкретной структуры таблицы. ***
Экспортирование и импортирование
В качестве альтернативы созданию образа базы данных (или дополнения к нему) можно использовать утилиту экспортирования Oracle (EXP). Эта утилита создает копию объектов базы данных Oracle во внешнем формате и обеспечивает большую гибкость, чем копии образа базы данных. С помощью этой утилиты можно выполнять следующие задачи:
• экспортировать отдельный объект базы данных, например таблицу;
• экспортировать избранные объекты базы данных, принадлежащие указанному пользователю;
• экспортировать всю схему базы данных пользователя;
• создавать резервную копию всей базы данных.
Полезной особенностью утилиты импортирования (IMP) является то, что нам не нужно импортировать все, что было экспортировано. Следовательно, если мы экспортировали всю базу данных, то сможем найти одну таблицу для несчастного пользователя, который случайно потерял ее или удалил 1000 крайне необходимых ему строк. Еще одно преимущество утилиты EXPort состоит в том, что она неявно проверяет логическую целостность данных. Поскольку эта утилита читает данные, обращаясь к таблицам построчно, она гарантирует, что все строки остаются целыми и никакие повреждения не возникают. А при создании образа базы данных испорченные блоки просто копируются, хотя в Oracle7 они встречаются редко, что весьма приятно.
Как и можно ожидать, экспортирование занимает гораздо больше времени, чем создание образа базы данных. Когда мы говорим "гораздо больше" мы имеем в виду именно это. Так, утилиту EXPort нельзя использовать с очень большими базами данных, потому что время экспортирования неприемлемо велико. Эта утилита также требует, чтобы база данных продолжала работать, и пользователь должен сделать так, чтобы в процессе экспортирования никто не изменял данные. Утилита EXPort может выполняться в режиме согласованности по чтению, чтобы к базе данных одновременно имели доступ и другие пользователи, но при обновлении это может привести к остановке экспорта спустя несколько часов из-за нарушения согласованности по чтению (snapshot too old). Ни один метод не позволяет предотвратить эту ошибку.
Для работы утилиты IMPort требуется невероятно много времени. Этот недостаток усугубляется требованием о повторном построении всех индексов для импортированных таблиц и повторном включении всех ограничений. Даже если вам удастся втиснуть экспорт в рабочий график, то время импорта (которое всегда больше, чем время экспорта) сделает экспорт бесполезным.
Кроме того, учтите, что всякий раз, когда запускается утилита EXPort, она рассчитывает на запись всей своей выходной информации в один файл. Если вы все еще работаете с одной из версий Unix, где размер файла не может превышать двух гигабайт, это может создать серьезную проблему при копировании 30-гигабайтной таблицы.
Режим архивации журналов
Допустим, что у нас относительно небольшая база данных, и мы можем позволить себе создавать еженедельные отчеты и каждый вечер снимать в автономном режиме резервные копии файлов. Что произойдет, если в пять часов вечера возникнет серьезная неисправность диска? Потеряем ли мы сделанную за день работу?
Нет, не потеряем, если работаем в режиме архивации журналов и сумели сохранить все файлы журналов, сгенерированные с момента предыдущего резервного копирования файлов. Этот режим устанавливается в файле инициализации Oracle (INIT.ORA) и при правильном использовании позволяет восстанавливать или повторно применять транзакции путем восстановления с повтором транзакций. Мы можем, таким образом, восстановить данные с резервной копии образа базы данных, а затем с помощью журналов (заархивированных) "прокатать" эту базу-копию либо до конца журналов, либо до заданного момента времени. (Подробное описание этого механизма можно найти в документе Oracle7 Server Administrator's Guide.)
Когда пользователь выдает SQL-команду COMMIT, все сделанные им изменения, вероятнее всего, еще находятся в памяти (в измененных или "грязных" буферах базы данных в системной глобальной области, SGA). Поскольку память энергозависима, то эти изменения необходимо записать на диск, иначе операцию фиксации нельзя будет считать завершенной. Поскольку запись потенциально большого количества блоков в базу данных может быть дорогостоящей (относительно) операцией, то в последовательный файл, называемый журналом, записываются изменения (и только изменения). После того как записаны все изменения, фиксация считается завершенной. Блоки базы данных записываются (в конце концов) обратно в нее фоновым процессом, который называется программой записи в базу данных (DBWR), но эта запись не синхронизирована с транзакцией.
Сам журнал представляет собой ряд файлов, запись в которые осуществляется циклически. Запись в первый файл производится до тех пор, пока он не заполнится, затем так же производится запись во второй файл — и так до заполнения последнего файла, после чего перезаписывается первый файл и все начинается сначала. Режим архивации журналов означает, что ни один файл журнала не перезаписывается до тех пор, пока он не будет скопирован (заархивирован). В случае серьезной аварии данные можно восстановить, смонтировав последнюю резервную копию. При запуске Oracle7 подсказывает, что нужно применить журналы в правильном порядке, и восстанавливает все данные вплоть до последней фиксации в последнем имеющемся журнале. В случае полного выхода из строя машины это будет последний журнал, заархивированный с нее на какой-нибудь съемный носитель, например на ленту.
Для большинства действующих узлов режим архивации журналов — абсолютная необходимость, потому что пользователи вряд ли захотят повторять сделанную за день работу. У этого режима есть и другое преимущество: это ключевой элемент механизма, позволяющего создавать резервные копии средствами операционной системы, не останавливая базу данных. Эти копии называют горячими резервными копиями. Администратор БД сообщает Oracle о предстоящем резервном копировании табличного пространства, указывая следующее SQL-предложение:
ALTER TABLESPACE...BEGIN BACKUP
Для одного или нескольких табличных пространств. Затем с файлов, образующих это пространство (пространства), снимаются резервные копии, и администратор БД информирует Oracle о завершении резервного копирования, для чего используется предложение
ALTER TABLESPACE...END BACKUP
Администраторы БД обычно довольно успешно работают с горячими резервными копиями, а вот для остальных членов группы проектировщиков они часто остаются тайной за семью печатями. Важно помнить, что в промежутке между ALTER TABLESPACE...BEGIN BACKUP и соответствующим ALTER TABLESPACE...END BACKUP экземпляр Oracle запишет данные в ряд журналов, и каждый из этих журналов необходимо применить после восстановления с горячей резервной копии.
К сведению
Горячую резервную копию можно использовать только для восстановления состояния на тот момент времени, после которого она была создана, тогда как традиционную автономную, или холодную, резервную копию можно использовать для восстановления состояния на тот момент времени, до которого она была создана, или, если имеется полный набор заархивированных журналов, то по состоянию на любой последующий момент времени.
Резервные узлы
Последний вариант резервного копирования, который мы рассмотрим, — это поддержка в оперативном режиме резервной конфигурации в полном соответствии с основным узлом. Это дорогой путь, требующий наличия "запасной" базы данных на другой машине, часто на другом узле. В случае отказа основной машины резервная машина принимает на себя обязанности отказавшего сервера и пользователи переключаются на нее.
Примечание
Не думайте, что это легко. Перед тем как планировать такой подход, необходимо точно выяснить, как пользователи переключаются, сколько работы лично они должны сделать (включая повторный вход в систему) и сколько времени на все это уйдет. Если обращать внимание на маркетинговую шумиху, которая все это окружает, то можно подумать, что решить эту задачу так же легко, как, скажем, позавтракать. На самом деле вас ждет здесь множество подводных камней.
На некоторых платформах резервную систему можно поддерживать в актуальном состоянии с помощью удаленных зеркальных дисков. В случае аварии на основном узле процессор резервного узла запускает экземпляр базы данных, работающий с зеркальным диском. При запуске этого экземпляра выполняется откат всех транзакций, которые выполнялись в момент отказа основной системы.
Менее приемлемый подход — использование предусмотренной в Oracle симметричной репликации, при которой таблицы на резервной машине повторяют таблицы на действующей машине. По этому поводу необходимо отметить следующее.
• В версиях 7.1.6 и 7.2 симметричная репликация — асинхронный механизм, и давать какую-то гарантию относительно максимального времени на распространение изменений невозможно.
• В версии 7.3 симметричная репликация выполняется синхронно (с использованием двухфазной фиксации), поэтому резервная машина поддерживается полностью в актуальном состоянии, но теперь, конечно, основной узел не может работать без подключенного резервного узла, если только не разрешить основному узлу работать без репликации.
• Симметричная репликация влечет за собой значительные расходы, влияющие на производительность, поэтому перед использованием этого метода необходимо оценить это влияние. Синхронная симметричная репликация по глобальной сети может оказывать неприемлемо большое влияние на время реакции системы.
Еще один вариант — перенести заархивированные журналы с одного узла на другой (как правило, по сети) и немедленно применить их. При этом абсолютная актуальность данных на резервной машине не обеспечивается, но этот путь имеет одно неоспоримое преимущество — активное участие основной машины требуется только при пересылке журналов. Эта стратегия, которая с большим успехом применяется еще со времен Oracle 6, теперь поддерживается Oracle официально при условии, что резервная база данных используется только в этих целях. Несмотря на асинхронность и на то, что резервная база данных может "отставать" от основной на один полный журнал, теперь можно ограничить максимальное время, выдавая с фиксированным интервалом SQL-команду ALTER SYSTEM SWITCH REDO LOG, a также ограничить максимальный объем потерянных обновлений, уменьшив размер файла журнала.
Резервное копирование: резюме
Ниже мы подытожили все сказанное в этом разделе.
• Копий образов базы данных (при использовании режима архивации журналов и оперативных резервных копий) достаточно для реализации стратегии резервного копирования на большинстве узлов. Как правило, стратегические решения принимает администратор БД, однако проектировщик может дать ценнейшую информацию о приложении, требованиях пользователей к резервному копированию и ограничениях. Приняв решение о механизме, необходимо подумать о том, сколько времени будут храниться старые резервные копии и, следовательно, как часто будут повторно использоваться резервные носители. Администратор БД и обслуживающий персонал должны также решить такие вопросы, как установка резервных носителей в нужное время и обеспечение надлежащих условий хранения резервных копий.
• Экспортирование (с помощью утилиты ЕХР), как правило, не является ключевым элементом стратегии резервного копирования (если речь не идет о маленькой базе данных). Нам трудно указать точный объем, но следует ожидать, что практически любая БД, измеряемая гигабайтами, создаст значительные проблемы с производительностью, если попытаться восстановить ее с помощью утилиты импортирования (IMP).
• Резервные базы данных можно поддерживать в абсолютно актуальном состоянии с помощью двухфазной фиксации. Этот процесс можно автоматизировать с помощью триггеров базы данных, как это делается при поддержке симметричной репликации в версии 7.3. Асинхронное распространение дает гораздо более высокую производительность за счет потери некоторых данных при отказе основного узла.
Передача заархивированных журналов практически не влияет на производительность основного узла. По этой причине такая схема весьма привлекательна, даже несмотря на очень высокую вероятность потери данных, с учетом того, что обычно временной промежуток составляет около пяти минут. Доступность параллельного восстановления начиная с версии 7.1 делает передачу архивных журналов более осуществимой, чем раньше. (В предыдущих версиях восстановление с помощью журнала часто занимало больше времени, чем его генерация.)
* Безусловно, мы — не единственные в мире, у кого до сих пор есть данные на 5-дюймовых дискетах (при том, что ни у одного из нас на домашних ПК нет дисководов для этих дискет). Кроме того, в надежных хранилищах, разбросанных по всему свету, находятся сотни копий баз данных Oracle версии 5.
** Ссылки на шоколадные чайники в этой книге встречаются неоднократно, и, конечно, ничего подобного не существует. Просто есть старая английская поговорка: As much use as a chocolate teapot ("Пользы, как от шоколадного чайника", т.е. вообще никакой пользы.
*** Поскольку один из нас работает на фирму ВМС Software, мы не можем удержаться от искушения отметить, что продукт SQL*Trax этой фирмы позволяет устранить повреждения этого типа путем выявления выполненного действия по журналу и отмены его.
Знаете ли Вы, что свойство объекта в объектно-ориентированном программировании - это характеристика объекта. Обычно свойства изменяются с помощью методов.