В этой главе исследуются проблемы загрузки "чужих" данных (данных из внешнего источника) в базу данных Oracle и выгрузки данных из нее для последующей загрузки в другие базы данных. Мы рассмотрим загрузку исходных данных, в ходе которой происходит заполнение наших таблиц данными из так называемых унаследованных систем, а также периодическую загрузку, целью которой является приведение наших данных в соответствие с другим источником данных. Кроме того, будут обсуждены проблемы, возникающие в случаях, когда входящие данные неполны или в каком-то отношении недопустимы. Мы рассмотрим вопросы преобразования данных и разные подходы к синхронизации преобразования и трансформации. Наконец, мы познакомимся с форматами файлов и средствами, используемыми для загрузки данных.
Работа с внешними системами
В наше время лишь немногие компьютерные системы могут работать "в вакууме". Практически все они нуждаются во взаимодействии с другими системами — как минимум для загрузки исходных данных из унаследованной системы. Поэтому можно сказать, что успех системы в значительной степени зависит от ее способности обмениваться данными с другими компьютерными системами.
Несмотря на то, что почти во всех проектах требуется обеспечить интерфейсы к внешним системам (часто называемые механизмами подачи данных), только немногие аналитики и проектировщики уделяют достаточно внимания проблемам загрузки и выгрузки данных. Большинство аналитиков считают эти проблемы "физическими", и поэтому им кажется, что они не являются предметом анализа. В итоге проектировщик базы данных вынужден принять на себя всю ответственность за проектирование этой части приложения. Часто внешние интерфейсы рассматриваются в рамках отдельных проектов или подсистем, которые не включают в проект базы данных.
Типы интерфейсов
Внешние интерфейсы можно разбить на две категории:
• осуществляющие одноразовый (не считая тестовых прогонов) прием исходных данных;
• поддерживающие периодический обмен данными с другими действующими системами.
Если обмен данными должен осуществляться в условиях, приближенных к режиму реального времени, и не может выполняться регулярно, то его следует рассматривать как составную часть общей стратегии распределенной базы данных, а не просто как задачу подачи данных. Этой теме посвящена глава 12. Здесь же мы просто отметим, что использование реально-временного канала связи с унаследованными данными позволяет исключить из операций обмена определенную группу сущностей, если требуемая скорость доступа может быть обеспечена распределенной технологией.
Отметим, что преобразование унаследованных структур данных имеет исключительно важное значение в проектах хранилищ данных. Эти вопросы подробно освещаются в главе 13.
Задачи проектировщика
При рассмотрении задач, связанных с загрузкой и выгрузкой данных, проектировщик должен:
• определить, каким системам нужен интерфейс;
• определить периодичность использования интерфейса и объем передаваемых через него данных (например, 1000 записей в день);
• установить, какая требуется степень синхронизации двух систем;
• исследовать методы транспортировки данных (файловые, коммуникационные и т.д.);
• согласовать с проектировщиками других систем формат данных для обмена. Сюда относятся тип файла и форматы полей для дат, целых и вещественных чисел и т.п.;
• составить перечень зависимостей между операциями по загрузке или выгрузке данных, например, отметить, что некоторые из них необходимо выполнять в определенном порядке;
• установить правила обработки входящих "нечистых" данных, т.е. данных, которые частично разрушены или утратили целостность;
• для каждой загрузки составить планы перехода в аварийный режим и режим восстановления на случай неудачного и неполного приема данных;
• сформулировать правила отклонения ошибочных и недопустимых входных записей;
• создать общие правила регистрации операций пересылки данных (в систему и из системы);
• начать составление плана ночных пакетных операций для периодического обмена. Закончить составление плана можно только при рассмотрении его в контексте с другими пакетными операциями в системе;
• согласовать график разработки, стратегию и план тестирования с проектировщиками другой системы;
• согласовать стратегию и план передачи для разовой загрузки данных.
Как мы уже отмечали, в результате исследования проектировщики могут прийти к выводу, что некоторые интерфейсы следует развить до уровня распределенных баз данных, которые взаимодействуют в режиме реального времени без использования механизмов подачи данных.
Работая вместе с "противоположной стороной"
Важным фактором, определяющим успешную реализацию внешнего интерфейса, являются хорошие взаимоотношения с коллегами, обслуживающими другие системы. Работая над новой Oracle-системой, которая должна прийти на смену любимому мэйнфрейм-приложению, вы можете столкнуться с недоброжелательным отношением — ведь ваши коллеги зарабатывают на жизнь, сопровождая старую систему. В большинстве случаев такое отношение можно преодолеть, если вы будете дружелюбным, продемонстрируете понимание, а также убедите людей, что новая система обладает неоспоримыми достоинствами.
Если это не помогает и никак не удается добиться активного содействия от тех, кто думает, что в день завершения проекта потеряет работу, то вам придется избрать другой подход к решению этой проблемы. Почти все программы трансформации данных придется писать не для старой, а для новой среды. Другими словами, данные будут преобразовываться и транспонироваться на входе, а не на выходе. Это решение может показаться трудным, но опыт показывает, что чаще всего именно к нему и прибегают. Причин тому несколько. Вот наиболее важные из них:
• Перечень незавершенных заданий по разработке в унаследованной системе часто бывает таким длинным, что руководство не разрешает в него ничего добавлять. Даже если оно и позволит включить в список требований подпрограмму извлечения данных, вы, вероятно, никогда ее не увидите.
• График эксплуатации старой системы может быть таким, что невозможно выделить время для тестирования и прогона новой программы извлечения данных.
• В унаследованной системе уже может быть какое-нибудь средство извлечения данных, и обслуживающий ее персонал скажет: "Если вам действительно нужны наши данные, почему бы не воспользоваться тем, что уже есть?" Самый разумный выход из этой ситуации — именно так и поступить. Считайте это просто еще одним проектным ограничением.
Вопросы совместимости данных
При переносе данных из старой системы в новую в большинстве случаев возникает еще одна серьезная проблема. Большинство старых систем (среди которых не только нереляционные системы, но и Oracle версии 6) содержат не полностью нормализованные данные и не работают с защитой ограничений целостности на уровне базы данных. Чем старее технология, тем меньше степень нормализованности данных. *
Обработка неочищенных данных
Отсутствие ограничений целостности базы данных, неизбежные ошибки приложений, ночные "заплаты" на данных — все это приводит к тому, что с годами в приложениях накапливается огромный объем "нечистых" данных. Если в новой базе данных полностью реализованы декларативные ограничения и проверка более сложных условий в триггерной логике, то унаследованные данные, скорее всего, в нее не загрузятся. На вас почти наверняка будут оказывать давление, имеющее целью ослабить некоторые ограничения и "впустить" неочищенные данные. Если вы не предпримите мер по "ремонту" и очистке данных или не измените модель данных, то в большинстве случаев обнаружите, что для загрузки хотя бы сколько-нибудь приемлемой части данных придется ослабить почти все ограничения.
Если вы поддадитесь давлению, то можете попасть в сложное положение. Ограничения нельзя включить, если таблица содержит данные, нарушающие их. Учитывая другие возможные формы давления, дело может кончиться тем, что операция по очистке данных станет рассматриваться как пустое занятие, отнимающее время. Чем дольше ограничения остаются выключенными, тем выше вероятность появления еще более "нечистых" и недопустимых данных.
Наш совет в этой ситуации — бороться за чистоту базы данных. Несколько дней отставания от графика проекта — ничто в сравнении с последствиями хранения данных, не обладающих элементарной целостностью. Один из авторов работал в организации, где однажды обнаружилось, что из-за отсутствия целостности данных итоговые цифры за несколько лет "ушли" на много миллионов долларов.
Загрузка устаревших кодов
Иногда обнаруживается, что в унаследованных наборах имеются данные, которые когда-то были допустимыми, но сейчас таковыми уже не являются. Например, могут встретиться значения, которые закодированы с использованием кодов, давно вышедших из употребления. Иногда существует возможность восстановить их исходные значения, но во многих случаях понадобится специальный алгоритм, который превратит старый код в нечто, понятное для новой системы.
Один из подходов, который признан удачным, предполагает решение задачи "в лоб" и состоит в реализации старых кодов при помощи справочных таблиц. В эти таблицы можно добавить столбец, который будет показывать, применим ли данный код к новым записям. Этот метод может работать довольно хорошо, но требует некоторых затрат на реализацию, поскольку для проверки и отображения используются различные наборы данных.
Таблица, которая обычно определялась следующим образом:
может быть трансформирована в таблицу, поддерживающую и устаревшие, и текущие коды с помощью дополнительного столбца и ограничения:
CREATE TABLE cancellation_reasons
( reason_code CHAR(l) PRIMARY KEY
, reason_text VARCHAR2(30) NOT NULL
, current CHAR(l) DEFAULT 'N' NOT NULL
CONSTRAINT canc_reason_current
CHECK (current IN ('Y','N'))
);
Может оказаться полезным создать представление, которое будет использоваться для работы экранных форм ввода и "скроет" старые коды. Но поскольку обновлять данные в представлении нельзя, их сопровождение должно осуществляться в таблице. Вот определение представления для нашего примера:
CREATE OR REPLACE VIEW current_cancellation_reasons
( reason_code
, reason_text
) AS
SELECT reason_code
, reason_text
FROM cancellation_reasons
WHERE current = 'Y';
Если не реализовать преобразование или поддержку старых кодов, то загрузить унаследованные данные, удовлетворив ограничения по внешнему ключу, будет невозможно. Эти ограничения должны содержать ссылку на таблицу (к которой хранятся все значения), а не на представление (содержащее только новые значения). По этой причине на любой таблице, имеющей внешний ключ к CANCELLATION_REASONS, необходимо определить триггер, который обеспечит ввод только действующих в новой системе причин. Очевидно, что на период загрузки данных из унаследованной системы такие триггеры придется отключать.
Загрузка данных с нарушенной ссылочной целостностью
В унаследованных данных почти всегда имеются разного рода нестыковки. Например, могут существовать строки заказа без соответствующего заказа, заказы, в которых невозможно определить покупателя, заказы без строк и т.д. В одних случаях данные вообще отсутствуют, а в других внешний ключ или указатель поврежден вследствие ошибки в приложении, аппаратного или программного сбоя или в результате ручной корректировки данных. При проектировании мы должны найти выход из этого положения.
Конечно, можно найти решение для каждого конкретного случая. Однако мы настоятельно рекомендуем вам выполнить проектирование так, чтобы при загрузке данных были удовлетворены все установленные ограничения. Для этого в процессе проектирования можно использовать следующие приемы:
• Отбрасывать данные, которые не удовлетворяют требованиям ссылочной целостности. Это, конечно, самый простой для реализации вариант, но он может оказаться неприемлемым, если, например, эти данные могут понадобиться для аудита.
• "Изобрести" отсутствующие сущности. Например, строки заказа без заказа можно связать с синтетическим заказом, который содержит комбинацию стандартных данных и данных, выведенных из строк заказа. Если вы используете этот метод, то необходимо разработать четкий механизм идентификации синтетических заказов, чтобы можно было написать SQL-код, исключающий эти строки из некоторых пакетных процессов и отчетов. Это позволит избежать, например, ситуации, когда товары резервируются для заказа, который не может быть выполнен, поскольку покупатель неизвестен. Некоторые проектировщики пользуются для этой цели специальными диапазонами первичных ключей, но лучше использовать отдельный атрибут (столбец).
• Разместить все данные с нарушениями ссылочной целостности в отдельных таблицах и потом попытаться "подогнать" их. Такая подгонка обычно выполняется комплексно, путем обработки по правилам и с помощью данных, вводимых опытными пользователями. Прикладную поддержку этой подгонки реализуют в полноценном системном компоненте (даже если для него планируется короткий срок службы). Его разработка должна быть включена в план. Это может быть всего одна экранная форма или несколько экранных форм и отчетов.
Загрузка поврежденных данных
Много лет назад один из авторов отвечал за преобразование более полутора миллионов записей с металлических адресных табличек, бумажных платежных документов и лент банковских операций. Первичный ключ (членский номер) и фамилия члена должны были быть в каждой записи. Однако во многих случаях не было одного компонента, а в некоторых случаях — обоих. Прием данных выполнялся как повторяющийся процесс и по первоначальному плану должен был занять год.
Несовпадающие данные хранились как "ожидающие" и регистрировались с помощью набора правил идентификации возможных совпадений. Раз в месяц у нас проходила встреча с командой клерков, которые использовали оперативные транзакции для присвоения записей о членах платежным записям. На этой встрече мы корректировали правила, применяемые программами генерации отчетов, с учетом обратной связи с конечными пользователями. В результате прием данных был завершен менее чем за девять месяцев, причем с почти стопроцентным качеством.
Мы не смогли преобразовать менее чем 1000 записей, но эта цифра не включает около тысячи членов, проскользнувших сквозь сеть ручной системы, которым никогда ничего не платили и от которых никогда не требовали оплаты.
Это было достигнуто ценой написания крупной подсистемы, которая генерировала отчеты и выполняла оперативные переназначения. После завершения приема данных подсистему вывели из эксплуатации, взяв из нее небольшую часть, которую перенесли в систему обработки платежей с неверно указанным членским номером.
Один из ключей к успеху в такой детективной работе состоит в том, чтобы найти данные, являющиеся надежными. Мы обнаружили, что банки и компании-эмитенты кредитных карточек почти всегда указывают свои собственные справочные номера правильно. Поэтому если у нас есть платеж, но мы не знаем, за что он, то ищем члена, на счет которого уже поступали платежи с данного банковского счета или кредитной карточки. Если мы найдем только один такой счет, программа сообщит о нем как о возможном совпадении. Если с этого счета нам причиталась сумма, равная полученному платежу, то о нем сообщается как о вероятном совпадении.
Всегда следует ожидать, что в работе встретятся и "нечистые" данные, и неприемлемые с точки зрения бизнеса ситуации. Сюда следует отнести такие случаи, как платежи за несуществующие товары, невыполненные проверки безопасности, ошибки согласования и т.д. Если из анализа не ясно, как решить эти проблемы, то рассчитывать только на свою инициативу опасно. Проблему следует довести до сведения аналитиков и конечных пользователей.
Загрузка данных, не удовлетворяющих ограничениям сущностей
Ограничение сущности — это ограничение, которое может применяться в контексте одной сущности. Этот термин используется также для описания ограничений, применяемых к отдельной строке. Вот два примера ограничений сущностей:
discuont NUMBER NOT NULL
CONSTRAINT ordr_discount
CHECK ((discount = 0) OR
((discount_approval IS NOT NULL) discount < ordr_value)))
В некоторых загружаемых данных неизбежно будут недопустимые значения. Одни из них можно просто откорректировать (например, ввести для строк верхний регистр). В других случаях может требоваться работа, аналогичная той, которая проводилась для данных, не удовлетворяющих требованиям ссылочной целостности (см. предыдущий раздел).
Загрузка неопределенных значений
Часто при преобразовании данных возникает проблема трактовки неопределенных значений. Поскольку традиционные системы (и последовательные файлы) не поддерживают неопределенные значения явно, они могут присутствовать в данных как пустая строка, очень маленькое или очень большое значение даты или, в некоторых случаях, как число нуль. Мы не большие любители неопределенных значений, но понимаем, что они существуют в среде Oracle и очень важно правильно загрузить их.
Как мы говорили в главе 5, Oracle сейчас не поддерживает пустые строки, поэтому все пустые строки, присутствующие во входных данных, неявно конвертируются в неопределенные значения, если только приложение не делает их непустыми (как правило, вставляя всего один пробел).
Более серьезная проблема возникает при загрузке числовых полей. Если в числовом поле допускается значение нуль или пустое значение, то механизм подачи данных в первом случае должен загрузить его как нуль, а во втором — как пустую строку. Если механизм подачи работает в текстовом формате, эта задача решается относительно просто. Если же данные подаются как двоичное значение, то решение о том, как их регистрировать — как нуль или как неопределенное значение, — приходится принимать в зависимости от контекста (т.е. в зависимости от значений других полей записи или даже путем поиска во внешних ключах). Самый лучший выход — спроектировать схему так, чтобы все, что может поступать как цифра нуль, загружалось как значение нуль.
Мы
— за разумный подход
Реакция руководства и пользователей на все эти проблемы может быть выражена таким вопросом: нельзя ли загрузить данные с ошибками, а затем отсортировать их позже, когда будет время? Во-первых, времени на это у них никогда не найдется, а во-вторых, весь код обычно проектируется и пишется в расчете на то, что данные достоверны. Если данные не будут соответствовать правилам, то приложение просто не будет работать. Более того, поскольку вы наверняка не сможете протестировать приложение с использованием полного набора дефектных данных, оно не просто будет отказывать — оно будет отказывать непредсказуемо и часто вводить в заблуждение. Поэтому перед вами открываются два возможных пути:
• либо изменить данные,
• либо изменить правила.
В большинстве проектов приходится делать и то, и другое.
Триггеры и декларативные ограничения
Существует очень важное различие между декларативными ограничениями и правилами обработки данных, вводимыми с помощью триггеров. Триггеры можно включать и отключать когда угодно, и "единственный" эффект состоит в том, что в отключенном состоянии они не выполняют проверку. Конечно, при необходимости можно отключить и ограничение, но при попытке вновь включить его произойдет следующее:
• Ограничение будет применяется к каждой строке всей таблицы или, по меньшей мере, до тех пор, пока не встретится строка, не соблюдающая его. В таблицах со значительными объемами данных для этого понадобится много времени.
• Ограничение будет включено лишь в случае, если ему удовлетворяют все строки таблицы. Следовательно, если вы захотите загрузить неочищенные данные, то с декларативными ограничениями придется распрощаться.
На первый взгляд может показаться, что триггеры имеют большое преимущество перед декларативными ограничениями, потому что их можно отключить для выполнения необходимой обработки, а затем вновь включить, причем с очень малыми затратами на обработку, тогда как при повторном включении декларативных ограничений затраты на обработку очень высоки, а успех не гарантирован. Мы же рекомендуем использовать декларативные ограничения, несмотря на этот "недостаток". На самом деле это достоинство, потому что не дает пользователю повредить базу данных. Нужно лишь максимально очистить входящие данные и работать с ограничениями, которые можно выполнить.
Ослабление ограничений
Foreign Key с помощью неопределенных значений
Приняв решение об ослаблении правил обработки данных (ограничений), нужно позаботиться о том, чтобы каждый модуль приложения "знал" о новых правилах. Так, если вы предполагаете сделать определенные столбцы внешнего ключа необязательными (допускающими неопределенные значения), то следует учесть некоторые последствия этого шага.
Например, при загрузке из внешней системы таблицы CUSTOMERS можно сделать столбец SALES_ID необязательным, чтобы загрузить клиентов, не имеющих назначенного менеджера по торговле. Однако в результате запрос
SELECT e.emp_name
, c.cust_name
FROM customers с
, emoloyees е
WHERE c.country = 'USA'
AND c.sales_id = e.employee_id;
не возвратит клиентов, у которых в столбце SALES_ID стоит неопределенное значение, даже если клиент находится в США. Чтобы получить правильный ответ, необходимо изменить этот запрос так:
SELECT NVL(e.emp_name, 'NOT assigned')
, c.cust_name
FROM customers с
, emoloyees e
WHERE c.country = 'USA'
AND c.sales_id = e.eniployee_id(+);
Приложив немного усилий, мы, конечно, внесем соответствующие изменения во все программы, которые разрабатываются в рамках нашего проекта, но мы не сможем заставить использовать внешние соединения в нерегламентированных запросах. Лучше сделать так, чтобы продавец был назначен, по крайней мере формально, каждому клиенту, даже если этот "продавец" оказывается фиктивной записью. (У некоторых продавцов эту разницу заметить очень трудно!)
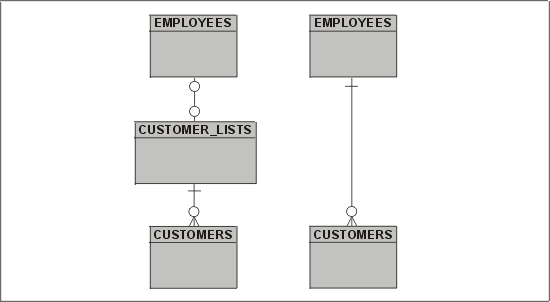
Однако, если мы попробуем ввести служащего, который называется Not assigned ("He назначен") и не имеет ни номера социального страхования, ни адреса, ни зарплаты, то это может вызвать проблемы при обработке платежных ведомостей. Правильное решение — признать, что наша исходная модель была неверной. Нам нужна новая сущность, которую мы можем назвать "список клиентов". Введя такой список, в котором нет назначений продавцов, мы можем переписать первоначальный запрос так, чтобы работать без внешнего соединения. (Измененная модель данных показана на рис. 8.1.) Теперь мы можем выдать такой запрос:
SELECT l.list_responsiBility
, c.cust name
FROM customers с
, cust_lists l
WHERE c.country = 'USA'
AND c.list_id = l.list_id;
Однако отметим, что в данном случае мы имеем отношение "один к одному" между сущностями CUSTOMER_LISTS и EMPLOYEES, необязательное на обеих сторонах. Помните — прежде чем ставить под сомнение модель данных, необходимо много поработать с приемом унаследованных данных.
Рис. 8.1. Новая модель данных
Этапы переноса данных
Процесс переноса данных можно разбить на следующие этапы:
Извлечение
Чтение данных из места их хранения.
Трансформация
Внесение необходимых корректировок.
Перемещение
Передача данных из одной системы в другую
Загрузка
Вставка данных в базу данных.
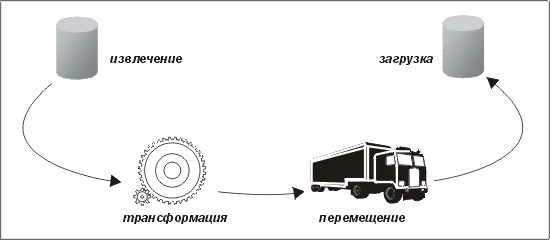
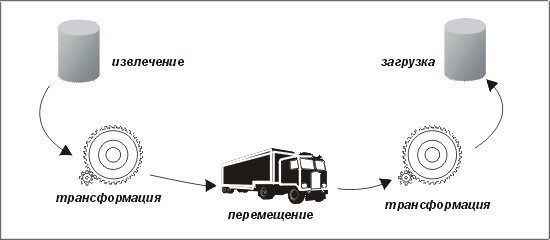
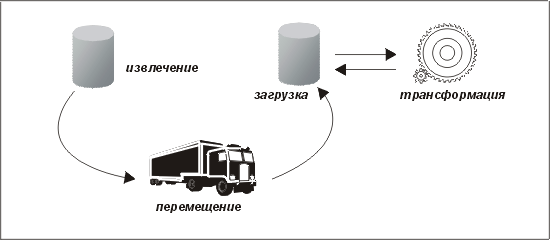
Как видно из рис. 8.2, рис. 8.3 и рис. 8.4, эти этапы могут быть организованы по-разному — в зависимости от того, когда и где выполняется трансформация. Иногда необходимо использовать несколько этапов трансформации. Это имеет смысл в случаях, когда имеются отдельные задачи трансформации, которые лучше выполнять на разных хостах. Во многих случаях задачи, для выполнения которых необходимы справочные данные с хоста-источника (например, подстановку значения внешнего ключа вместо указателя), можно делать частью этапа извлечения.
Рис. 8.4. Извлечение, перемещение, загрузка, трансформация (стандартный метод Oracle)
Вообще-то, самый эффективный способ организации обработки — когда трансформация выполняется до перемещения данных, однако любая попытка увеличить рабочую нагрузку на унаследованную систему обычно встречает сопротивление (по причинам, которые мы рассматривали в начале этой главы). Следовательно, мы должны исходить из того, что после перемещения данные будут находиться практически в том же состоянии, что и после извлечения. Возможно, нам удастся выполнить символьное преобразование из EBCDIC в ASCII, и, конечно, можно надеяться, что все десятичные значения будут конвертированы в текст, но остальные задачи трансформации лягут на наши плечи.
Желательно все данные передавать в текстовом формате. Это значительно облегчит жизнь участвующим в этом процессе, и лишь немного усложнит ее машинам, осуществляющим преобразование данных на передающей стороне. Если использовать числовой формат, то из-за особенностей внутреннего представления дат и чисел в Oracle на принимающей стороне обязательно потребуется выполнять преобразование типов данных.
Примечание
(Бывший гуру Oracle no SQL и вопросам производительности Крис Эллис когда-то уговорил одного консультанта представить все столбцы таблицы регистрации данных как VARCHAR, хотя все значения в таблице были числовыми. Логика его была такой: поскольку весь доступ осуществлялся из 3GL-кода и преобразование типов было неизбежным, его вполне можно было выполнять под управлением этого 3GL-средства. Конечно, в символьной форме данные загружались гораздо быстрее!
Трансформация данных
Основной упор в этом разделе делается на то, чтобы убедить читателя в том, что, вопреки распространенной практике, самый лучший подход — полностью выполнить трансформацию до загрузки данных в Oracle. Если отложить трансформацию на период после загрузки (первоначальной), то мы гарантируем, что большую часть данных придется загружать дважды — один раз неправильно, а второй раз правильно. Производительность операции вставки в Oracle7 довольно высока, но лучше выполнить лишь только такое число этих операций, которое необходимо для выполнения поставленной задачи. Стандартный метод Oracle, изображенный на рис. 8.4 (извлечение перемещение, загрузка, трансформация), особенно неэффективен, потому что при этом выполняются минимум одна ненужная вставка и одна ненужная выборка для каждой загружаемой записи. На практике же часто проходится выполнять несколько проходов по таблице.
Вы должны исходить из того, что в процессе загрузки данных придется выполнять как изменение структуры, так и изменение значений данных. Выполняя трансформацию, необходимо также учесть ряд других факторов, в частности:
• ссылочную целостность;
• объем данных, передаваемых в транзакции;
• размещение данных.
Давайте рассмотрим простой случай.
Вам предстоит загрузить заказы и строки заказов из корпоративной базы данных на мэйнфрейме, в которой допускается максимум 20 строк на заказ. Обслуживающий персонал мэйнфрейма предложил вам текстовый файл, содержащий по одной записи на каждый заказ; за данными заголовка заказа сразу же располагаются строки заказа (максимум двадцать). Файл содержит разделители, позволяющие загрузить данные в таблицу с помощью SQL*Loader, но нужно откорректировать код статуса заказа, преобразовав его в значения, используемые в Oracle-приложении, а также конвертировать строки заказа так, чтобы они содержали цену единицы вместо произведения цены единицы на количество. Как вы поступите?
Наиболее часто встречается такое решение данной задачи. После загрузки текстового файла в рабочую таблицу с помощью SQL*Loader запускается скрипт SQL*Plus, который берет данные заголовка заказа из таблицы WORK_TABLE и вставляет их в таблицу ORDERS, используя, например, такой SQL-оператор:
B данном случае все записи заказа создаются в одной транзакции, поэтому при больших объемах данных объем сегмента отката будет также значительным. За этим оператором придется использовать еще двадцать операторов следующего вида:
INSERT INTO orders ( order_no
, line_no
, product_code
, quantity
, unit_price
)
SELECT order_no
, product_code_01
, quantity_01
, round (line_price_01
/ quantity_01
, ...
FROM work_table
WHERE product_code_01 IS NOT NULL;
В итоге мы правильно загрузили данные в таблицы ORDERS и ORDER_LINES, но:
• Провели двадцать одно полное сканирование рабочей таблицы.
• Либо выполнили всю операцию за одну транзакцию, либо выполняли фиксацию, не дожидаясь передачи всех строк заказа. Вспомните, что если загрузка осуществляется в рамках одной транзакции, то может понадобиться большой сегмент отката и один отказ (например, из-за нарушения ограничений) может свести на нет всю загрузку.
• Сделали так, что почти наверняка строки заказа будут находиться в разных физических блоках базы данных.
Существует и другой способ — вообще не использовать SQL*Loader, a написать 3GL-программу, которая читает текстовый файл и из каждой строки этого файла образует одну строку в таблице ORDERS и от одной до двадцати строк в таблице ORDER_LINES. Операции вставки выполняются с помощью массивного интерфейса, и программа выполняет фиксацию, например, через каждые 50 строк, чтобы удерживать размер сегмента отката на приемлемом уровне.
И наконец третий способ ** — использовать промежуточную С-программу а то и просто awk-скрипт. Этот скрипт обрабатывает текстовый файл, полученный от мэйнфрейма, преобразовывает код статуса заказа и делит цену на количество, чтобы полученный в результате текстовый файл можно было обработать средствами SQL*Loader.
Эти решения сложнее, так как требуют наличия 3GL-программы (или по крайней мере, awk-скрипта), но гораздо эффективнее и надежнее. Их использование дает несколько преимуществ:
• В базе данных выполняются только действительно необходимые операции (например, операция вставки в две таблицы).
• Размер сегмента отката и время восстановления поддаются контролю. (Для перезапуска экземпляра в случае неконтролируемого останова в ходе описанного выше процесса с использованием SQL*Plus может потребоваться несколько часов.)
• Не выполняется фиксация для неполных заказов.
• Существует тенденция к тому, что строки, относящиеся к одному заказу, будут располагаться рядом.
Особенностью двух последних методов является использование 3GL-средства как для преобразования кодов, так и для корректировки значений полей. Многие проектировщики пытаются сэкономить время и деньги, выполняя корректировку значений с помощью скрипта на SQL*Plus после загрузки, и во многих случаях еще более усложняют проблему, используя справочную таблицу, например:
INSERT INTO orders ( order_no
, cust_no
, order_status
, ...
)
SELECT w.order_no
, w.cust_no
, о.new_code
, ...
FROM work_table w
, order_status_codes о
WHERE o.old_code = w.order_status;
Если в условии используется только одно соединение, этот код будет работать достаточно хорошо, однако при вводе еще двух-трех соединений производительность заметно ухудшится.
Если нельзя считать хорошим стилем жесткое программирование преобразования кодов в 3GL-программе, то соединение вообще очень просто сделать управляемым данными. Перед чтением файла 3GL-программа прочтет таблицу ORDER_STATUS_CODES в память (в виде массива или связного списка) и будет выполнять замену кодов, используя собственный механизм табличного поиска. Эта программа также может сообщить о записях с недопустимыми кодами. В SQL-решении все строки заказов, чей ORDER_STATUS в таблице ORDER_STATUS_CODES отсутствует, будут попросту проигнорированы. А это, конечно, совсем не то, что нужно.
Большинство этих недостатков решения на базе SQL*Plus можно избежать путем использования PL/SQL. Преимущество этого подхода в том, что данные все равно загружаются в рабочую таблицу, но вместо 21 прохода по ней делается один проход в курсорном цикле PL/SQL с выполнением всех необходимых операций. С точки зрения программирования и тестирования, этот метод гораздо дешевле 3GL-nporpaммы. Он позволяет управлять интервалом между фиксациями, избежать фиксации противоречивых данных и разместить рядом строки одного заказа (как 3GL-метод). Это — хорошие новости. Плохая новость заключается в том, что цикл в PL/SQL выполняется очень медленно. Если речь идет менее чем о 100000 строк, то можно бросить на решение этой проблемы дополнительные силы и время, но если необходимо принять больший объем данных за короткое время, то курсорные циклы PL/SQL попросту не справятся с возложенными на них задачами.
Форматы файлов
Двумерные (плоские) файлы, используемые для загрузки данных, могут иметь два формата: с записями фиксированной длины или с записями переменной длины. В записях переменной длины поля отделяются ограничителями. Примеры данных в формате фиксированной и переменной длины приведены в примере 8.1.
Пример 8.1. Записи фиксированной и переменной длины
Записи фиксированной длины
Widdington Tommy 11-11-72 164 04-26-90 Y
Magilton James 01-24-68 195 02-19-23 N
Hopper Neil 05- 4-70 180 12-06-91 Y
Записи переменной длины
"Widdington","Tommy","11-11-72","164","04-26-90","Y"
"Magilton","James","01-24-68","195","02-19-23","N"
"Hopper","Neil","05-4-70","180","12-06-91","Y"
Первыми показаны записи фиксированной длины. Каждое поле такой записи набивается пробелами до некоторой фиксированной длины, и соответствующие поля начинаются во всех строках файла в одной позиции. Файлы с записями фиксированной длины — излюбленный формат большинства программирующих на Коболе.
Затем в примере приведены те же данные в переменном формате. Длина записи зависит от длины полей. Каждое поле заключается в ограничители (в двойные кавычки) и отделяется от других полей специальным разделителем (запятой). Если символ ограничителя может использоваться и в тексте данных, необходимо указать программе-загрузчику, чтобы в тексте она интерпретировала этот символ буквально. Например, если нужно загрузить значение Nicholas "Nic" Banger, то следует использовать что-нибудь вроде Nicholas \"Nic\" Banger, где \ — управляющий символ, предписывающий программе рассматривать следующий символ буквально. Конечно, нужно сделать так, чтобы программа загрузки данных понимала эти обозначения.
Пустые значения в записях фиксированной длины обычно представлены пробелами, а в записях переменной длины — парой ограничителей ("" в данном примере).
Будет очень хорошо, если вы организуете поддержу комментариев в файлах данных. Это особенно эффективно при создании тестовых данных для утилит загрузки, потому что каждую строку можно предварить информацией о том, что именно тестируется и каким должен быть результат. Вы можете выбрать формат комментариев по своему усмотрению при условии, что программа-загрузчик поймет его. Широко используется формат, в котором строка комментария начинается двумя дефисами:
-- Это комментарий
SQL*Loader поддерживает комментарии этого типа.
Существует еще одна проблема, с которой вы можете столкнуться. Во многих программах установлено ограничение на длину строки. Обычно его определяли исходя из возможностей матричных принтеров, и чем старше система, тем меньшее значение в ней используется. В этом случае можно просто заносить записи в транспортный файл в виде нескольких строк. В зависимости от характера конкретной операции можно применять фиксированное или переменное число строк. Возможно, значения некоторых полей будут размещаться в нескольких строках.
Еще одной проблемой является обработка данных со встроенными символами новой строки. Вот наши любимые методы ее решения (в порядке предпочтения):
• не иметь в строковых данных встроенных символов новой строки;
• использовать обозначение Unix — \n, а встроенные знаки табуляции записывать как \t.
Столкнувшись с какой-либо из вышеупомянутых проблем, вы можете прийти к выводу, что лучше выполнять загрузку с помощью 3GL-программы или, по крайней мере, использовать 3GL-программу для предварительной обработки загружаемого файла с тем, чтобы его могла обработать программа SQL*Loader.
Упорядочение, восстановление и частота фиксации
Обработку больших объемов данных рекомендуется разбивать на несколько менее объемных и более управляемых операций загрузки. В такой ситуации может потребоваться, чтобы эти операции выполнялись в определенном порядке. Этого можно достичь путем включения порядкового номера операции загрузки в заголовок загрузочного файла и сверки его с данными специальной таблицы в базе данных.
Заголовок файла может иметь, например, такой вид — HDR,,CUST LOAD, 4. Цифра 4 указывает, что это четвертая операция загрузки и она не должна начинаться до завершения третьей загрузки. Пример таблицы, которая используется для управления загрузкой данных, содержится в табл. 8.1. Здесь каждой операции загрузки присвоен порядковый номер и имя. Кроме того, для каждой операции указаны полное имя внешнего файла, из которого были взяты данные, и ее статус. В этом примере также регистрируется позиция во входном файле, до которой "дошла" активная операция загрузки, Это число обновляется в каждой точке фиксации. Такой подход позволяет упростить процедуру восстановления в случае сбоя при загрузке большого объема данных. При перезапуске процесса загрузки программа может определить из этой таблицы достигнутую позицию, а затем просто "перемотать ленту" в эту точку файла и возобновить процесс. Однако использование файла управления загрузкой и описанного здесь механизма восстановления возможно лишь в случае, если вы напишете собственную 3GL-программу загрузки. Возможно, стоит применить 3GL лишь для обеспечения контроля, чтобы затем возобновить процесс загрузки и не нарушить в результате ссылочную целостность.
Оценив требования к входным внешним интерфейсам, необходимо решить, с помощью какого средства можно обеспечить выполнение загрузки. В этом разделе мы остановимся на программе SQL*Loader.
Сравнение
SQL*Loader и 3GL
Мы уже рассматривали ряд вопросов, касающихся выбора инструментальных средств для приема данных, но еще не проводили непосредственное сравнение двух самых эффективных из них. Это:
• программа SQL*Loader, выполняющая непосредственный ввод данных в "живые" таблицы. Обеспечение целостности осуществляется либо путем предобработки, либо с помощью ограничений базы данных, либо с использованием обоих этих компонентов;
• 3GL-программа, например, на Рго*С или Pro*COBOL, обеспечивающая чтение данных из среды передачи, а также их проверку, корректировку вставку и обновление.
Лучшей характеристикой по производительности обладает первое средство, а опция прямой загрузки SQL*Loader — несомненно, самый быстрый способ вставки данных в Oracle-таблицу.
Программы на Рго*С, как правило, более трудоемки в плане создания и тестирования, чем, например, код на PL/SQL, но они почти наверняка работают в несколько раз быстрее PL/SQL с любыми объемами данных, если выполняются на той же платформе, что и экземпляр базы данных, и используют массивный интерфейс (array interface) Oracle.
По причинам, которые описаны выше, мы не рекомендуем для больших объемов данных выполнять обработку таблиц после загрузки.
Одно замечание о предварительной обработке. Если имеется индексный ключ, по которому приложение выполняет выборку большого количества строк, будет очень полезно перед загрузкой рассортировать входные данные по этому ключу. Это существенно повысит эффективность запросов при выборке по методу, который в Oracle называется сканированием индекса.
Сильные и слабые стороны
SQL*Loader
SQL*Loader — это зрелый и широко используемый продукт. Он поддерживает записи фиксированной и переменной длины и может обрабатывать смесь символьных (как правило, ASCII) и двоичных данных. Кроме того, он имеет внутренний генератор последовательности, генерирующий уникальные идентификаторы строк. Учтите, что это не то же самое, что последовательность в Oracle7, поэтому после загрузки каждую последовательность, используемую приложением для назначения ключей таблице, нужно изменить так, чтобы она начиналась с максимального значения в таблице после завершения загрузки. SQL*Loader является идеальным средством для выполнения простой загрузки данных с проверкой целостности сущностей. Так, например, SQL*Loader отклоняет записи с отсутствующими значениями в столбцах NOT NULL и недопустимым форматом данных.
К основным недостаткам SQL*Loader следует отнести:
• неспособность выполнять обновление;
• неспособность выполнять трансформацию данных;
• неспособность обеспечить ссылочную целостность; но так как Oracle7 позволяет вводить ограничения FOREIGN KEY и UNIQUE на уровне базы данных, этот недостаток не является критичным.
SQL*Loader не позволяет задавать никакой другой логики, кроме условий, обеспечивающих фильтрацию из загружаемых данных определенных строк. Если требуется установить для загрузки сложные условия или получить производные значения, то SQL*Loader бессилен. Проектировщики и программисты пытались преодолеть эти недостатки самыми разными способами, в том числе путем написания специальных триггеров на таблице, которые включались только на период загрузки. Такие методы редко обеспечивают необходимую производительность, а фокус с триггером вообще опасен, так как при этом невозможно обеспечить, чтобы триггер срабатывал только тогда, когда нужно.
Самое большое преимущество SQL*Loader состоит в способности этой программы выполнять прямую загрузку. В процессе прямой загрузки SQL*Loade записывает целые блоки прямо в базу данных, пропуская промежуточные этапы, такие как выполнение SQL и управление кэшами данных. Это нарушает правило подрыва функциональности, сформулированное Тедом Коддом для реляционных баз данных, но дает такой рост производительности, что никто не обращает на это никакого внимания!
Опция прямой загрузки SQL*Loader — это, без сомнения, хороший метод загрузки больших объемов данных для тех случаев, когда важна высокая производительность и необходима параллельность. Чтобы ускорить загрузку, средство прямой загрузки использует ряд алгоритмов, повышающих эффективность обновления индексов и проверки ограничений. Триггеры при прямой загрузке не срабатывают, а все ограничения ссылочной целостности отключаются. Новые элементы индекса попросту "проталкиваются" в бункеры или буфер. После того как все блоки данных созданы, эти бункеры сортируются по индексному ключу и объединяются в соответствующие индексы.
На этом этапе можно попробовать вновь включить ограничения (например, с помощью опции EXCEPTIONS INTO) для регистрации всех введенных нарушений и опять пользоваться всеми выгодами, которые дают триггеры базы данных на таблице.
Предупреждение
Принимая решение об использовании прямой загрузки, помните о двух важных ограничениях. Во-первых, при прямой загрузке не срабатывают даже включенные триггеры, и во-вторых, обращаться к таблице, загружаемой методом прямой загрузки, могут только другие потоки SQL*Loader.
Из
Oracle 7 в Oracle 7: особый случай
Существует один метод переноса данных, который мы еще не обсуждали и который в действительности касается случая с распределенными базами данных, рассматриваемого в главе 12. Если мы можем непосредственно, при помощи запроса, извлечь данные, которые хотим принять, то должны учесть несколько иных факторов. Очевидно, что такая ситуация возникает в случае когда данные уже находятся в таблицах, принадлежащих другому приложению этой же базы данных. Данные также могут находиться в другой базе данных Oracle где-то в сети или в базе данных, доступ к которой возможен через SQL*Net и шлюзовую технологию Oracle или через один из картриджей данных, выпускаемых для архитектуры NCA. С помощью синонимов можно сделать так, что, с точки зрения программиста, все эти варианты (кроме последнего, процедурного) будут одинаковыми на вид. То есть мы можем писать запросы для обращения к объекту PRICE_MASTER, будь это:
• таблица в локальной схеме базе данных;
• синоним таблицы, относящейся к другой схеме этой же физической базы данных, к которой нам предоставлен доступ при помощи запросов;
• синоним, в котором используется канал базы данных для обращения к таблице в другой базе данных Oracle;
• синоним, в котором используется канал базы данных для обращения к объекту в не-0гас1е-базе данных, доступ к которой осуществляется через прозрачный шлюз.
Хотя в двух последних случаях используются синоним и канал базы данных, необходимо учитывать тот факт, что сервер внешних данных в последнем случае может иметь совершенно другую производительность, чем сервер Oracle. Поэтому определенные операции с запросами, которые опытному Oracle-программисту кажутся абсолютно нормальными, в "чужой" среде могут повлечь за собой огромные затраты.
Кроме того, необходимо помнить, что для всех случаев, кроме первого, важными являются быстродействие сетевого канала и время "оборота" сообщений в нем. Привлекательность следующего метода приема данных
INSERT INTO local_orders
SELECT *
FROM orders@hg
WHERE processing_office = 'my location';
DELETE FROM orders@hg
WHERE processing_office = 'my location';
COMMIT;
уменьшается, если для передачи таблицы по сети требуется больше времени, чем для ввода ее вручную. Мы должны также предупредить о том, что удалять значительную часть строк из таблицы обычно не рекомендуется.
Как и прежде, в данном случае все зависит от того, получаем ли мы данные из SQL-запроса в нужном виде или же понадобится выполнить их пред- или постобработку. Оператор INSERT... SELECT... очень эффективен, поскольку нет необходимости конвертировать данные из внутреннего формата Oracle, а также потому, что (на таких платформах, как Unix, где Oracle использует двухзадачную архитектуру) для переключения из пользовательского процесса в Oracle-процесс и обратно никакое переключение контекста не требуется. Если же необходимы преобразование или проверка данных, то помещение данных в рабочую таблицу и обмен ими может оказаться неприемлемо неэффективным.
Поскольку данные можно получить при помощи SQL-запроса, то можно написать 3GL-пpoгpaммy, которая вместо чтения текстового файла сгенерирует удаленный запрос, выполнит необходимую обработку, а затем вставит данные в локальную базу данных.
Если такая процедура делается часто, а не от случая к случаю, то мы, вероятно, говорим уже о распределенной базе данных, а не о механизме подачи или приема данных. Если вы захотите перейти сразу к главе 12 и узнать подробности, то мы должны предупредить, что распределенные базы данных и архитектуры клиент/сервер имеют общие особенности в методах проектирования, которые описаны в главе 11. Рекомендуем поэтому сначала прочитать главу 11.
Выходные данные
До сих пор мы рассматривали в этой главе входные данные, потому что с ними больше проблем. Однако хочется верить, что данные, содержащиеся в нашем приложении, тоже полезны и иногда нас попросят предоставить их в том или ином формате другим приложениям.
Все сказанное в предыдущих разделах можно в равной степени отнести и к выходным данным. Если мы хотим предоставить другой БД Oracle доступ для чтения наших данных, то можно воспользоваться каналом или снимком базы данных — в зависимости от того, насколько актуальными должны быть передаваемые данные. Однако здесь мы опять попадаем в сферу распределенных баз данных и отсылаем читателя к главе 12.
Если принимающая база данных — не Oracle или если вариант с сетью не годится, то нам придется извлечь данные и передать их, вероятно, как текстовый файл. Для этого можно использовать один из следующих механизмов:
• Oracle-утилиту EXPort;
• скрипты SQL*Plus;
• 3GL-пpoгpaммy;
• генератор отчетов.
Выбор будет зависеть от сложности требований. Например, SQL*Plus — хороший вариант для создания простых текстовых файлов с записями фиксированной длины. Если вам нужно взять всю таблицу из одной БД Oracle и просто перенести ее в другую БД, то достаточно будет утилиты EXPort. Вероятно, не стоит использовать для этого сложное полнофункциональное средство генерации отчетов. Кроме того, некоторые генераторы отчетов работают только на клиентской платформе, и вы наверняка не захотите выполнять задачу получения "дампа данных" по сети. Мы предпочитаем опять-таки 3GL -средство, которое может эффективно работать с массивами и обеспечивает более высокую степень контроля.
Если требуется несколько раз из одних и тех же данных извлечь информацию в денормализованном виде, то может оказаться эффективным следующий метод. Данные из "живых" таблиц размещаются в денормализованные таблицы, специально предназначенные для этих целей, а затем из этих таблиц создаются необходимые файлы. Кроме того, в этом случае вы будете иметь в файлах непротиворечивые данные (это требуется в некоторых приложениях генерации отчетов).
Если вы периодически выполняете перекрестную загрузку, то необходимо решить, будет ли при этом каждый раз выполняться полное обновление данных или же будут передаваться только изменения, внесенные после предыдущей загрузки. Мы рекомендуем полное обновление по ряду причин:
• Все данные, подлежащие извлечению, должны при каждом изменении получать метку времени, и эти метки должны вестись либо приложением, либо триггерами. Другой вариант — использовать для регистрации данных с метками времени управляемую триггерами таблицу-журнал.
• Удаление необходимо выполнять либо посредством логического удаления, либо с помощью управляемого триггерами журнала изменений (мы рекомендуем журнал).
Конечно, использовать журнал изменений для таблицы технически возможно, но это серьезная задача. При этом также возникают проблемы с производительностью на принимающей стороне, если в период между загрузками значительная часть данных исходной таблицы изменяется. Можно разработать механизм перехода к полному обновлению при достижении некоторой точки безубыточности. Чтобы разобраться в том, какие действия нужно предпринять для реализации работоспособного решения, изучите механизм снимков Oracle, возможности которого позволяют обеспечить надежный перенос изменений из одной таблицы в другую.
Наш совет — по возможности осуществляйте полное извлечение, даже если участвующие в нем таблицы объемны, а число изменений невелико. Впрочем, тот, кому приходится иметь дело с вводом данных на противоположном конце, может с этим и не согласиться.
* Тем не менее, один из авторов этой книги впервые участвовал в дискуссии по важности 3НФ в 1973 году, работая над проектом с использованием ассемблера IBM System/370 и ISAM-фаилов.
** Это одно из многих ценных дополнений и исправлений, сделанных Грэмом Вудом в процессе рецензирования этой книги.
Знаете ли Вы, что событийно-управляемое программирование - это объектно-ориентированное программирование, при котором задаются реакции программы на различные события.