В этой главе рассматриваются проблемы, с которыми вы можете столкнуться при выборе ключей и индексов для таблиц проектируемой базы данных. Индексы исключительно важны и являются краеугольным камнем всякой стратегии достижения хорошей производительности. Попробуйте-ка найти все ссылки на слово "нормализация" в этой книге без помощи индекса! Однако при проектировании индексам часто не уделяется должное внимание, потому что многие думают так: "мы запросто сможем создать их в процессе тестирования или эксплуатации системы, когда станет очевидно, что возникли проблемы с производительностью". В этих рассуждениях есть доля правды, и мы не рекомендуем проектировщикам пытаться формулировать полную стратегию индексирования. Наш опыт показывает, что это неизбежно ведет к "перегрузке" индексами больших таблиц, что сопряжено со значительными затратами на достижение нормальной производительности при сохранении и обновлении. Тем не менее, мы полагаем, что ни в коем случае не следует бросать разработчиков на произвол судьбы и позволять им вводить индексы по своему усмотрению.
Группа проектировщиков отвечает за передачу всех методов индексирования, которые должны, по ее мнению, применяться в базе данных (например, использование для определенной задачи хеш-кластера или индексирования внешнего ключа с целью устранения проблем блокировки). Кроме того, группа проектировщиков полностью отвечает за задание ограничений. Индексы и ограничения по ключам очень тесно связаны, и ограничения по ключам так же важны для целостности базы данных, как индексы — для производительности. Без ограничений по ключам может быть нарушена логическая структура данных. Например, таблица ORDER_LINES может содержать строки заказа для несуществующего или удаленного заказа из таблицы ORDERS, что вызовет неожиданные аномалии в отчетах и экранных формах.
В правильно спроектированной базе данных каждая таблица должна иметь первичный ключ, который служит для уникальной идентификации любой ее строки. В одних таблицах естественного кандидата на эту роль нет, поэтому для этой цели специально вводится новый столбец — суррогатный ключ. В других таблицах есть несколько возможных ключей (или ключей-кандидатов), из которых приходится выбирать один. Для всех возможных первичных ключей должно быть установлено ограничение UNIQUE, обеспечивающее их уникальность в пределах таблицы. Таблица, играющая в отношении роль дочерней, для каждой связи имеет внешний ключ, соответствующий значению первичного ключа в родительской записи.
Столбцы и группы столбцов, которые регулярно используются в качестве критерия поиска при запросах к таблице, могут индексироваться, что повышает производительность поиска. В Oracle существует несколько типов индексов, и мы рассмотрим каждый из них отдельно.
Первичные ключи
Возможность однозначно определить строку в таблице является основополагающей для реляционного проектирования. Делается это путем назначения первичного ключа. Никакие две строки в одной таблице не могут иметь одинаковый первичный ключ. Однако сделать это не так просто, как кажется! В жизни все происходит несколько по-другому. В модели, поскольку она является лишь моделью, мы, может быть, и не сможем уловить отличительные черты каждого экземпляра сущности, однако реляционная теория говорит, что каждая таблица должна иметь первичный ключ. Иногда приходится вводить искусственный идентификатор в форме суррогатного ключа.Это может быть просто числовая последовательность, которая начинается с единицы, обозначающей первую создаваемую строку, и увеличивается на единицу для каждой последующей строки. В некоторых случаях используются абсолютно бессмысленные для большинства людей последовательности чисел и (или) букв (взгляните, к примеру, на порядковые номера банкнот).
Иногда бывает, что предполагаемый первичный ключ таблицы оказывается не достаточно уникальным, когда мы начинаем учитывать реализацию его в реляционной базе данных. Возьмем, к примеру, событие. Дата и время наступления события будут гарантированно уникальными, если определить их с достаточной степенью точности. Однако в базе данных Oracle время хранится с точностью до секунды, а наличие двух событий в секунду — явление весьма распространенное.
В некоторых ситуациях создают суррогатный ключ даже тогда, когда таблица имеет естественный первичный ключ. Это чисто проектное решение, принимаемое из практических соображений. Обычно так делают в случаях, если естественный ключ очень длинный или состоит из большого числа компонентов (столбцов).
Исследование синтетических,или суррогатных, ключей
На этапе анализа каждой сущности, определенной в концептуальной модели, должен быть присвоен уникальный идентификатор (УИД) — естественно, если концептуальная модель должным образом нормализована. В начале проектирования нужно внимательно изучить эти УИДы и проверить, действительно ли они уникальны. Ведь в большинстве случаев в процессе проектирования мы просто образуем первичные ключи из уникальных идентификаторов, определенных в ходе анализа.
В частности, необходимо проверить все синтетические УИДы (которые часто называют суррогатными ключами) данной сущности эти ключи легко узнаваемы, потому что соответствуют атрибуту ID (или подобному). Такой атрибут обычно представляет собой число, которое вне данной компьютерной системы не имеет никакого смысла. Во-первых, мы должны убедиться в том, что аналитик не создал эти суррогатные ключи просто для удобства или не применил какой-то общий метод к УИДам всех сущностей. Кроме того, мы должны проверить, не ли пропущенных или незамеченных УИДов.
Рассмотрим пример. Как идентифицировать человека без отпечатков пальцев или генетического кода? Споры об однозначной идентификации и социальных аспектах ее проведения идут уже многие годы. Во многих странах каждый гражданин должен получить идентификационный номер, например, номер социального страхования. В других странах эквивалента такому номеру нет, а там, где он есть (например, в Канаде), хранить этот номер можно лишь в том случае, если он имеет непосредственное отношение к системе. Если номер социального страхования использовать нельзя, то, может быть, взять полное имя человека и дату его рождения? Однако будет ли такая комбинация уникальной? Если не учитывать время рождения человека с точностью до наносекунды, то, скорее всего, не будет.
Перед тем как принять созданный в процессе анализа суррогатный ключ, ответьте на следующие вопросы:
• Есть ли или могут ли быть два экземпляра данной сущности с идентичными атрибутами и отношениями (кроме идентификатора)?
• Если да, то что, с точки зрения бизнеса, различает их?
• Должен ли пользователь в таких случаях записывать или запоминать эти идентификаторы?
• Если идентификаторы перепутать, будет ли это иметь значение?
Лучше, конечно, получить ответы на эти вопросы у аналитика. (Впрочем, в качестве упражнения попробуйте ответить на них, привязавшись к деньгам в своем кармане. Полезно знать, сколько у вас с собой денег, но следить за каждой банкнотой или монетой, наверное, бессмысленно.)
Важно понимать различие между суррогатными и сгенерированными ключами. Суррогатные ключи всегда являются сгенерированными (чаше всего при помощи последовательности), однако сгенерированные ключи — обязательно суррогатные. Если вы откроете в банке новый счет, то номер счета, вероятно, будет сгенерирован как следующий элемент последовательности некоторого вида. Однако после этого номер счета будет иметь значение и для вас, и для банка, поскольку он используется на протяжении всего периода отношений между сторонами. В противоположность этому, суррогатные ключи имеют значение только для базы данных.
Неуникальные (или почти уникальные) ключи
Сейчас мы опишем случаи, когда проектировщик изменяет уникальный идентификатор сущности, определенный при анализе. В частности, мы рассмотрим ключи, которые не обеспечивают уникальность экземпляра при реализации в базе данных Oracle7. Затем, в следующем разделе, будет показано, в каких случаях длинные каскадные ключи заменяются суррогатными.
"Столько говорили о важности уникальных ключей для нормализации информационной модели и в конце концов опять пришли к неуникальным ключам?" — скажете вы. Да, ключ может быть уникальным в концептуальной модели, но при преобразовании ее в логическую модель, которую мы хотим реализовать в виде таблиц Oracle, он теряет свою уникальность. Например, если в ключ была включена метка даты и времени, то возможны проблемы. Время в Oracle7 округляется до секунд, поэтому, если мы создадим за одну секунду две строки с идентичными ключами, никакая метка времени нам не поможет.
Рассмотрим пример, приведенный на рис. 6.1. Предположим, что мы можем создать несколько версий исходного кода с одним и тем же именем каталога и файла. Сделать каждую версию уникальной можно было бы путем ввода в ключ столбца INSERTDATETIME ("Вставить дату и время"), поскольку вручную создать две версии одного и того же исходного кода за одну секунду весьма сложно. Но если мы используем генератор кода, который очень быстро создает один за другим два варианта, то возможны проблемы. В таких случаях мы будем получать сообщения об ошибках периода выполнения о нарушении ограничения UNIQUE. Чтобы исправить ситуацию, можно изъять метку даты и времени из ключа и ввести в него простой Целочисленный номер версии, как показано на рис. 6.2.
Рис. 6.1. Таблица с первичным ключом, который "почти" уникален
Рис. 6.2. Таблица с первичным ключом, который полностью уникален
Теперь, даже если значения системных даты и времени по какой-то причине сдвинутся назад (например, при переходе на зимнее время), столбец VERSION# сообщит нам истинную последовательность версий. Учтите, что дефекты такого рода (когда записи могут "расположиться" в неправильном порядке) очень легко предотвратить, но довольно сложно исправить после сдачи системы в эксплуатацию.
Описанный нами подход обеспечивает уникальность первичного ключа. Однако при этом все равно остались ловушки, которые в некоторых ситуациях могут вызвать неприятности. Например, присвоить новый номер версии, имея такую структуру, не так просто, как может показаться на первый взгляд, особенно если вы хотите, чтобы номера версий каждого файла всегда назначались в возрастающем порядке без пропусков значений. Чаще всего номер следующей версии будут пытаться определить с помощью такого запроса:
SELECT MAX(version#) + 1
FROM source_code
WHERE directory = :id
AND filename = :f;
Операция чтения осуществляется здесь без блокировки, поэтому один и тот же ответ могут получить несколько пользователей. Даже если вы уже выполнили операцию SELECT FOR UPDATE над файлом, который вы считаете последней версией, это не помешает другому пользователю выдать запрос SELECT MAX()... и получить такой же номер версии. В результате два пользователя одновременно могут пытаться создать одну и ту же версию, и один из них потерпит неудачу из-за нарушения ограничения UNIQUE.
Возможна также ситуация, в которой нескольким модулям нужно извлечь последнюю (только последнюю) версию конкретного файла. Чтобы найти ее, придется воспользоваться приблизительно таким запросом:
SELECT ...
FROM source_code
WHERE directory = :id
AND filename = :f
AND version# = (SELECT MAX(s2.version#)
FROM source_code s2
WHERE s2.directory = :id
AND s2.filename = :f);
Давайте проанализируем этот запрос. Он не очень эффективен, хотя в последних версиях скорость его выполнения и увеличилась. Это является следствием того, что в нем производится два поиска в индексе по первичному ключу. Если вы читали предыдущую главу, то наверняка поймете, что, во-первых, таблицу SOURCE_CODE следует назвать SOURCE_CODE_VERSIONS (ВЕРСИИ_ИСХОДНОГО_КОДА) и, во-вторых, следует ввести новую таблицу SOURCE_CODE для хранения всех атрибутов файла, приемлемых для каждой версии. Теперь мы можем ввести в эту главную таблицу производный столбец для регистрации номера последней версии исходного кода.
Примечание
Обратите внимание на область определения сданного запроса. Учитывая то, как Oracle разрешает имена, рекомендуется всегда использовать такой подход для подзапросов. Отметим также, что в подзапросе связанные переменные должны использоваться повторно. Если сделать его коррелирующим, это повлечет за собой полное сканирование таблицы (по крайней мере, в версии 7.2).
После создания новой таблицы (а она почти наверняка потребуется в любом случае) и добавления производного столбца вместо предыдущего запроса можно использовать следующий:
SELECT ...
FROM source_code s
, source_code_versions v
WHERE s.directory = :d
AND s.filename = :f
AND v.directory = s.directory
AND v.filename = s.filename
AND v.version# = s.latest_version#;
Итак, теперь у нас есть абсолютно эффективный способ ведения номера версии. Если выполнить запрос SELECT FOR UPDATE к соответствующей строке таблицы SOURCE_CODE, то можно выполнить вставку в SOURCE_CODE_VERSIONS и обновление в SOURCE_CODE, обеспечив при этом и целостность данных, и эффективность действия. Если вы считаете это решение неэффективным, попробуйте написать запрос на поиск номера последней версии для каждого файла, используя как однотабличную реализацию, так и решение с двумя таблицами, главной и справочной.
Замена длинных каскадных ключей суррогатными
Выше мы говорили о том, что следует подвергать сомнению все синтетические, или суррогатные, первичные ключи, введенные в процессе анализа. Давайте рассмотрим противоположную ситуацию. Иногда в процессе проектирования оправданной является замена реального первичного ключа, полученного при анализе, суррогатным.
Зачем это делается? В реляционных системах первичный ключ играет двоякую роль. Он служит для обеспечения уникальности строк, благодаря чему две строки в одной таблице не могут иметь одинаковый первичный ключ. Кроме того, его значение используется для ссылки на строку - в частности, когда он является внешним ключом в другой таблице. В этом качестве он выполняет ту же функцию, что и указатель в сетевой базе данных.
Если первичный ключ состоит более чем из одного столбца, его называют составным, и каждый его компонент должен быть представлен во внешнем ключе. * Если ключ используется как внешний (данная таблица связана с родительской или главной) и состоит, например, более чем из четырех компонентов, то он становится громоздким как по объему данных, хранящихся в дочерних записях, так и по объему SQL-кода, необходимого для соединения этих таблиц.
В таком случае стоит рассмотреть возможность ввода в таблицу суррогатного первичного ключа. Его обычно называют <сокращенное_название_таблицы>_ID или просто ID, а значения этого ключа генерируются, как правило, при помощи последовательности.
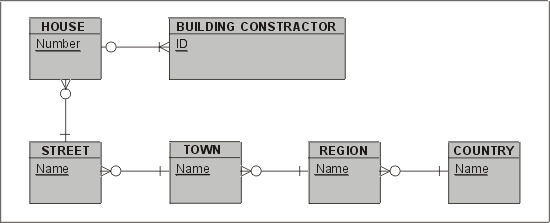
Таблицы с большими составными первичными ключами часто образуются из длинной иерархии сущностей, у которых ключи наследуются. Другими словами, когда для нескольких уровней иерархии внешний ключ родительской таблицы образует часть первичного ключа дочерней. Это иллюстрируется на рис. 6.3 (обратите внимание на переход от COUNTRY к BUILDING_CONTRACTOR).
В этом примере сущность COUNTRY ("Страна") имеет простой атомарный ключ — название страны. Сущность REGION ("Область") внутри страны уникально идентифицируется ее отношением с сущностью COUNTRY (столбец внешнего ключа F_CO_NAME) и названием области. Это необходимо потому,что в двух странах могут быть области с одинаковыми названиями. К тому времени, когда мы доберемся до города (TOWN), который идентифицируется комбинацией названия области (REGION) в пределах страны (COUNTRY) и названия города, ключ будет состоять из трех компонентов. Сущность STREET ("Улица") будет иметь четыре компонента, сущность HOUSE ("Дом") — пять и т.д. Чтобы сослаться на конкретный дом в таблице BUILDING CONTRACTOR ("Строительный подрядчик"), мы должны иметь пять компонентов внешнего ключа. Не кажется ли вам, что это многовато? В табл. 6.1 представлены таблицы, которые построены по схеме "сущность-отношение", изображенной на рис. 6.3, и содержат некоторые данные (по одной строке в каждой).
Таблица 6.1. Определения таблиц, демонстрирующие длинный каскадный ключ
COUNTRIES ( "Страны ")
NAME
POPULATION
Area
GNP
United Kingdom
57121000
94247
$758 billion
REGIONS ("Области ")
F_CO_NAME
NAME
METROPOLITAN_F
United Kingdom
57121000
94247
TOWNS ("Города")
F_CO_NAME
F_REG_NAME
NAME
United Kingdom
Surrey
Guildford
STREETS ("Улицы")
F_CO_NAME
F_REG_NAME
F_TN_NAME
NAME
United Kingdom
Surrey
Guildford
The Rise
HOUSES ("Дома")
F_CO_NAME
F_REG_NAME
F_TN_NAME
F_ST_NAME
NO
F_OWN_ID
United Kingdom
Surrey
Guildford
The Rise
10
2061
(Таблица BUILDING CONTRACTORS ("Строительные подрядчики") не показана.)
Как видно, в результате каждый столбец таблицы HOUSES является компонентом первичного ключа. Как упростить эту ситуацию? Конечно, можно снабдить таблицу HOUSES суррогатным ключом. Но предположим, требуется, чтобы по имени владельца можно было найти (с какой-то неясной целью) самый большой номер дома этого владельца на улице. При использовании представленной в табл. 6.1 структуры необходимый для этoro SQL-запрос будет выглядеть так:
SELECT MAX (hs1.no)
FROM houses hs1
WHERE EXISTS
(SELECT NULL
FROM houses hs2
WHERE hs2.f_own_id = 2061
AND hs1.f st_name = hs2.f_st_name
AND hs1.f_tn_name = hs2.f_tn_name
AND hs1.f_reg_name = hs2.f_reg_name
AND hs1.f_co_name = hs2.f_co_name);
Введем в таблицу STREETS суррогатный ключ и посмотрим, что изменилось. В табл. 6.2 представлены новые определения таблиц (определения, оставшиеся без изменений, не показаны).
Таблица 6.2. Новые определения таблиц. В таблицу STREETS введен суррогатный ключ
STREETS (Улицы)
ID
F_CO_NAME
F_REG_NAME
F_TN_NAME
NAME
41
United Kingdom
Surrey
Guildford
The Rise
HOUSES (Дома)
ID
NO
F_OWN_ID
41
10
2061
Теперь SQL-запрос для поиска максимального номера дома данного владельца на улице несколько упростился:
SELECT MAX (hs1.no)
FROM houses hs1
WHERE EXISTS
(SELECT NULL
FROM houses hs2
WHERE hs2.f_own_id = 2061
AND hs1.street_id = hs2.street_id);
Но получается, что ввод суррогатного ключа не дал нам ничего, кроме упрощения SQL-запроса. Однако не следует отказываться от преимуществ, которые дает такое упрощение, — этот запрос сжат и поэтому прост для чтения и понимания, его легче разбирать, и вероятность ошибок при вводе ниже.
Если использовать в качестве внешних ключей длинные, а не суррогатные ключи, то строки в дочерних таблицах будут длиннее. "Ну и что, ведь диски стоят дешево", — скажете вы. Однако следует учитывать, что, как бы ни были дешевы диски, на чтение данных с диска в память все равно нужно время. Чем длиннее строки, тем больше блоков придется просмотреть при сканировании. Это же можно сказать и об индексах, а диапазонное сканирование индекса является важной частью любой операции соединения, в которой используется внешний или частичный ключ. Кроме того, при более коротких ключах у некоторых индексов сокращается число уровней в В*-дереве, что приводит к еще большему росту производительности.
Итак, запомните простое правило: чем короче ключи, тем быстрее работают приложения.
Однако у каждого проектного решения всегда есть обратная сторона. Так, наличие суррогатных внешних ключей делает невозможным выполнение определенных типов запросов без прохождения по всей цепи соединений. Если мы представим самую невероятную задачу — поиск самого большого номера дома во всей Великобритании, то для исходной модели данных просто напишем следующий запрос:
SELECT MAX (hs1.no)
FROM houses hs1
WHERE hs1.f_co_name = 'United Kingdom';
Уменьшить степень влияния каскадных ключей можно с помощью сокращенных названий — например, в предыдущем примере вместо United Kingdom в качестве значения внешнего ключа использовать UK. Создание эквивалентного запроса для модели с суррогатными ключами оставляем вам в качестве упражнения, но поверьте, что изящным его не назовешь.
При использовании длинных каскадных ключей возникает еще одна проблема — в случае, когда ключевые столбцы где-то в цепочке нужно обновить. Естественно, чем выше уровень иерархии, на котором происходит это изменение, тем больше объем каскадно распространяющихся обновлений. В наше время ни в коем случае нельзя зависеть от статических вещей! Изменяются даже страны - об этом свидетельствует распад Советского Союза! Давайте рассмотрим не сложный пример, связанный с распадом или объединением, а более простой, когда страна изменяет свое название: Персия стала Ираном, Родезия - Зимбабве и т.д. В нашей модели данных нельзя обойтись простым обновлением таблицы COUNTRIES, обновление необходимо каскадно распространить на таблицы REGIONS, TOWNS STREETS, HOMES и т.д.
Реляционные пуристы скажут, что нельзя обновлять столбцы первичного ключа, поэтому нужно удалить все адреса в Родезии и вставить их в Зимбабве. Предоставляем вам право самим решить, можно обновлять первичный ключ или нет. У обеих сторон в этом споре есть достаточно веские аргументы достаточно сказать, что Oracle7 позволяет осуществить обновление первичного ключа без каскадного распространения изменений во внешние ключи некоторые другие реляционные системы управления базами данных обновление первичного ключа попросту запрещают. Если в таблице есть возможные первичные ключи (т.е. более одного обязательного уникального ключа), то, конечно, мы считаем, что в качестве первичного следует, выбрать тот, который не изменяется.
Естественно, распадаться, объединяться и изменять названия могут не только страны, но и области, города и улицы. Поэтому если давать всем им, которым из них или только некоторым из них суррогатные ключи, то каким образом их выбрать? Конечно, чем выше уровень в иерархии, на котором происходит изменение, тем больше объем каскадно распространяющихся изменений. Использование суррогатного ключа означает что мы будем свободны от реляционных ограничений, если захотим изменить исходный уникальный идентификатор.
Когда мы имеем дело с иерархией, которая подобна вышеописанной иногда кажется, что решение о том, где вводить суррогатный ключ, может быть произвольным. Однако вспомните, что проектирование базы данных тесно связано с функциональными требованиями. Для реализации некоторых функций может потребоваться "подъем" по иерархии. Если каскадные ключи ведутся, то такой подъем может быть трансформирован в "прыжок" при котором убираются посредники и выполняется более оптимальный запрос. Это можно продемонстрировать путем соединения таблицы HOUSES непосредственно с таблицей REGIONS (минуя таблицы STREETS и TOWNS).
SELECT MAX (hs.no)
FROM houses hs
,regions reg
WHERE hs1.f_reg_name = reg.name
AND hs.metropolitan_f = 'N';
Цель этого запроса — найти самый большой номер дома в немуниципальной области (еще один запрос из архива фирмы "Бесцельные запросы"),
Предупреждение
Будьте внимательны при проектировании и разработке такого SQL-запроса. Он может работать гораздо хуже, чем его более сложный собрат (в котором производится соединение всех промежуточных таблиц). В данном случае при соединении не будут применятся индексы по первичному или внешнему ключу на соответствующих таблицах, поскольку название области не является лидирующей частью ключа ни в одной из этих таблиц. Поэтому для оптимизации такого запроса вам потребуется определить дополнительные индексы. Во многих случаях стоимость этих дополнительных индексов не перевесит экономию, полученную от укорачивания цепочки соединений. В каждом конкретном случае при принятии решения необходимо сопоставлять нагрузку, вызванную сопровождением индексов, и нагрузку, связанную с обработкой запросов.
Еще одно замечание. Если вы все же решили использовать суррогатные ключи, обязательно спрячьте их. Не нужно отображать их в экранной форме и отчетах, потому что они только запутают пользователя.
Какие же еще принципы нужно здесь усвоить? Как определить, когда и где ввести суррогатный ключ в длинной цепочке составных ключей? Нужно принять взвешенное решение с учетом объемов и типов запросов, ожидаемых в системе. Исследуйте каждый случай, но помните об общих эмпирических правилах:
• Если первичный ключ таблицы имеет более четырех компонентов и с ней связаны подчиненные таблицы, то такой первичный ключ является хорошим кандидатом на замену суррогатным ключом.
• Если ключ имеет большую длину из-за описанного нами эффекта каскадирования, то некоторые критичные по времени функции могут выполняться быстрее за счет пропуска промежуточных таблиц в запросах. В таком случае рекомендуется сохранить длинный ключ.
Другие ключи
Выше мы подробно рассмотрели первичные ключи. Сейчас мы изучим еще два типа ключей — возможные и внешние.
Возможные ключи
Возможные ключи (или ключи-кандидаты) появляются при наличии у сущности более одного уникального идентификатора. Например, автомобиль можно уникально идентифицировать номерным знаком или заводским номером шасси. О номерном знаке и заводском номере шасси говорят, что они являются возможными ключами, так как оба могут играть роль первичного ключа.
В Oracle нет физической конструкции, которая непосредственно поддерживает возможный ключ. Поэтому в процессе проектирования необходимо решить:
• Какой ключ выбрать в качестве первичного?
• Что делать с ключом, который не является первичным?
Может случиться, что аналитик уже выбрал первичный ключ. Но мы не должны принимать его решение как окончательное, нам необходимо вынести свое мнение на этот счет. Один ключ можно предпочесть другим, например, по той причине, что он значительно короче других, — это позволяет плотнее упаковать ключи в блоке индекса и за счет этого уменьшить время поиска. Однако, как правило, мы предпочитаем проанализировать приложения, которые обращаются к данной таблице. Значение первичного ключа обычно применяется как внешний ключ в связанных подчиненных таблицах. Если значение ключа-кандидата важно для приложения, то, выбрав его в качестве первичного ключа, мы сможем избежать необходимости соединения таблиц. Допустим, в нашем примере с автомобилями требуется найти все нарушения правил дорожного движения конкретным транспортным средством. Весьма маловероятно, что, выполняя этот поиск, мы будем знать номер шасси. Если номер шасси будет первичным ключом, то для поиска по номерному знаку понадобится выполнить соединение с таблицей CARS.
Предположим, мы выбрали в качестве первичного ключа номерной знак автомобиля. Что же делать с номером шасси? Конечно, необходимо наложить на него ограничение UNIQUE, чтобы не было дубликатов. В некоторых случаях можно даже сделать его внешним ключом в подчиненных таблицах — хотя мы не большие сторонники такой практики, поскольку это вносит путаницу.
Внешние ключи
Внешние ключи используются в таблице, которая является подчиненной по отношению к другой таблице (или к самой себе). Проблем проектирования, связанных с внешними ключами, можно назвать только две — одна связана с дугами (см. главу 3), а вторая касается случая, когда и главная, и подчиненная таблицы действительны по дате (ее мы рассмотрим в главе 7).
В Oracle7 внешние ключи следует реализовывать с помощью ограничений FOREIGN KEY. В этих ограничениях можно задавать событие, которое произойдет, если удалить родительскую строку, т.е. должно ли удаление каскадно распространяться в подчиненную таблицу или же оно будет разрешено лишь при отсутствии связанных строк в подчиненной таблице. Каскадное распространение кажется привлекательным, потому что процесс удаления автоматизируется и о нем не нужно заботиться в приложении. Однако помните о пользователях, которые захотят выполнить удаление и потерпят неудачу из-за наличия блокировок на подчиненной строке или из-за того, что некоторые строки имеют огромное количество подчиненных строк, что существенно замедляет процесс. Остерегайтесь также удалять данные без выдачи пользователям информации об этом.
Индексы: обзор
Зачем создавать индекс для столбца или группы столбцов? До появления Oracle7 было три возможных причины:
• чтобы ускорить поиск в этих столбцах;
• чтобы обеспечить уникальное значение в этих столбцах (только индексы UNIQUE);
• чтобы извлекать строки в заданном порядке на основании индексированных столбцов.
Примечание
Третья причина редко бывает оправданной, если она является единственной причиной создания индекса. Однако она может служить веским аргументом в пользу добавления в индексный ключ дополнительного столбца.
В Oracle7 уникальность записи следует обеспечивать ограничениями PRIMARY KEY или UNIQUE. Мы, конечно, знаем, что если вводится ограничение, то эти ключи фактически используют уникальный индекс. Тем не менее, важно отметить, что в Oracle7 мы явно создаем ограничение, а не индекс.
До версии 7.3, кроме полного сканирования таблицы, в Oracle было всего два способа поиска записей:
• при помощи индексов, имеющих структуру В*-дерева (сбалансированного дерева) — для таблиц и кластеров;
• при помощи хеш-ключей — только для кластеров.
В версии 7.3 к этому списку добавились bitmap-индексы (только для таблиц).
На этапе проектирования необходимо принять ряд важных решений о том, что и как индексировать, а также о том, какой способ оптимизации использовать — стоимостной или основанный на правилах. Кроме того, на этапе проектирования важно четко сформулировать правила индексирования (см. врезку). Если для генерации скриптов создания базы данных используется CASE-средство, то есть шанс, что оно сгенерирует ограничения первичных и уникальных ключей для всех уникальных идентификаторов, а также обычные индексы для всех внешних ключей, которые найдет в своем репозитарии. Остальное, как правило, должны определить вы. Можно, например, подавить некоторые индексы для внешних ключей — чтобы сэкономить дисковое пространство или сократить затраты времени центрального процессора на сопровождение индекса.
Для чего нужны правила индексирования?
Для каждого проекта необходимо создать и оформить в письменном виде правила создания индексов для таблиц Oracle. (В некоторых организациях правила индексирования входят как отдельный раздел в общие правила обеспечения производительности.) Если этих правил нет, то дело может кончиться созданием произвольного набора индексов, который будет оптимален для одних программ и процессов и менее чем оптимален для других. Более того, программы, для которых эти индексы оптимизированы, могут не входить в число критичных для производительности системы в целом.
Как работает индекс?
Давайте повторим принципы работы индекса. Для этого рассмотрим следующий простой SQL-запрос:
SELECT emp.empno
,emp.ename
FROM employees emp
WHERE emp.ename = 'SMITH'
Способ, которым этот запрос выберет данные, зависит от того, индексирован ли (и как) столбец ENAME в таблице EMPLOYEES, а также от того, какая версия Oracle7 и режим оптимизатора используются. Вот некоторые возможные варианты.
1. Таблица не индексирована. Oracle читает каждый блок данных из таблицы EMPLOYEES и ищет в каждой строке каждого блока экземпляр SMITH. Данный метод известен как полное сканирование таблицы, и при этом используется гораздо больше тактов процессора, чем предполагают многие. Один из известных недостатков оптимизатора по стоимости Oracle состоит в том, что при сравнении стоимостей он не присваивает соответствующий удельный вес этому параметру использования процессора и поэтому слишком увлекается полным сканированием таблицы.
2. Имеется обычный индекс для столбца ENAME. Oracle последовательно читает уровни индекса по нисходящей до тех пор, пока не достигнет блока-листа, в котором значение SMITH либо присутствует, либо не присутствует Если обнаружен один или более экземпляров ключа SMITH, то за этими экземплярами следует идентификатор строки, что позволяет процессору запросов найти блоки данных, содержащие значение SMITH, и перейти прямо в эти строки. Имея эту информацию, процессор запросов может непосредственно обращаться к данным (предполагая, что не произошла миграция строки; миграцию строк мы рассмотрим в главе 9). Конечно, если вы используете оптимизатор по стоимости и статистика показывает, что данный столбец не является высоко избирательным, оптимизатор может выбрать полное сканирование таблицы. В версии 7.3, где строятся гистограммы значений столбцов, более вероятно, что для SMITH будет инициировано полное сканирование таблицы, а для ENSOR или STEVENSON — нет. В версиях 7.2 и ниже одно и то же действие будет выполнено для каждого значения; если индекс высокоизбирательный, он будет использован, а если нет, то не будет. Что делает индекс высокоизбирательным? Довольно эмпирическое вправило гласит: индекс будет классифицирован как высоко избирательный, если он содержит более двадцати разных ключевых значений.
3. Имеется составной индекс для нескольких столбцов, первым из которых является ENAME. Этот случай аналогичен описанному в п. 2, за тем исключением, что для индексированного поиска будет использоваться только лидирующая часть индексного ключа. У неуникальных индексов Oracle есть одна привлекательная особенность: идентификаторы строк с равными ключами (например, имеется много людей с фамилией Смит), хранятся в порядке их следования. Эта особенность дает следующее преимущество. Если строки для двух Смитов находятся в одном и том же физическом блоке базы данных, мы обратимся к ним по порядку. Почти во всех случаях это приводит к минимизации числа перемещений головок диска между блоками (если требуемые данные еще не находятся в системной глобальной области — SGA). К сожалению, несмотря на то, что мы используем лидирующую часть составного индекса, базовая последовательность будет соответствовать полному ключу. В результате можно ожидать, что операция поиска будет менее эффективна, чем при использовании одностолбцового индекса. Индекс также будет более длинным, что увеличивает объем сканирования. Однако эти факторы не оказывают заметного влияния и не оправдывают создание индекса по (ENAME), если уже есть и необходим индекс по (ENAME, INITIAL).
4. Имеется составной индекс для нескольких столбцов, но столбец ENAME не является первым из них. Этот индекс не используется, поэтому производится полное сканирование таблицы (как в п. 1).
5. Имеется хеш-ключ для столбца ENAME (таблица находится в хеш-кластере по столбцу ENAME). К SMITH применяется алгоритм хеширования, и хешированное значение используется для чтения блока кластеризованных данных. Если алгоритм хороший и размер кластера задан правильно, то этот блок должен содержать искомые строки. В противном случае, возможно, придется прочитать один или несколько связанных блоков, прежде чем будут найдены наши данные или обнаружится, что служащих по фамилии SMITH нет. В любом случае мы должны провести поиск хешированного значения во всех связанных блоках, которых может быть несколько (или, в патологических случаях, несколько тысяч).
6. ENAME является ключом индексного кластера. Индекс используется почти так же, как в п.2, за исключением того, что он либо вообще не будет содержать элемент для SMITH, либо будет содержать один такой элемент. Если элемент есть, то он указывает на первый блок цепочки связанных блоков, в котором могут находиться нужные строки. При хорошем качестве проектирования и определенной степени везения эта цепочка будет состоять всего из одного блока.
7. Таблица кластеризована, но столбец ENAME не является ни кластерным ключом, ни лидирующей частью другого индекса. Кластер сканируется почти так же, как в п. 1, за исключением того, что каталог строк в блоке-заголовке кластера используется для поиска в этом блоке строк, входящих в таблицу EMPLOYEES. Каждая из этих строк проверяется на наличие в ней фамилии SMITH.
8. Столбец ENAME является объектом bitmap-индекса. Для значения SMITH извлекается битовая карта (если таковая имеется), которая раскрывается в список идентификаторов строк, соответствующих условию запроса. Затем осуществляется чтение этих строк для выполнения запроса. Если ключевых значений всего несколько, то создание битовой карты для каждого значения ключа (по одному биту на строку в каждой карте) рационально в плане использования памяти и обеспечивает довольно эффективный поиск. Однако для индекса по фамилии может понадобиться большое число таких битовых карт, причем для большинства фамилий они наверняка будут очень разреженными (т.е. почти все биты будут "выключены").
Итак, какой же из восьми методов доступа нам предпочесть? Как вы, наверное, догадываетесь, все зависит от обстоятельств.
Полное сканирование таблицы — лучшее решение для случая, когда таблица EMPLOYEES содержит мало строк или значительная доля наших служащих имеют фамилию SMITH, хотя возможно, что во втором случае хорошо сработает bitmap-индекс. Если у нас имеется большое количество служащих с довольно равномерным распределением фамилий, то лучшим вариантом является хеш-ключ, особенно если нет фамилий, которые встречаются больше нескольких раз. Естественно, для фамилий служащих это вряд ли возможно.
Предположим, что не всегда в запросе выполняется сравнение на равенство (как в нашем примере) и нам приходится выдавать запросы, например, такого вида:
SELECT emp.empno
, emp.sal
FROM employees emp
WHERE emp.ename LIKE 'SM%';
В этом случае мы, вероятно, выбрали бы индекс, имеющий структуру В*-дерева, или полное сканирование таблицы. По мере того как искомое выражение будет сокращаться до "S%", полное сканирование таблицы будет выглядеть более приемлемым. Оптимизатор по стоимости в версии 7.3 сумеет выполнить оптимизацию правильно, но проектировщику следует помнить о проблеме связанной переменной, которую мы рассматриваем в разделе "Проблема связанной переменной" этой главы.
Почему бы не индексировать все?
Почему бы не индексировать в таблице каждый столбец, по которому возможен поиск? В ответ на это сразу же хочется возразить следующее:
1. Если существует несколько неуникальных индексов, которые можно использовать, то у оптимизатора по правилам нет приемлемого алгоритма выбора одного из них. У оптимизатора по стоимости такой алгоритм есть, но в версиях до 7.3 оценивается только избирательность индекса, а не значение ключа. **
Примечание
Oracle-наркоманы тратят впустую массу машинного времени, пытаясь определить, какой индекс выберет оптимизатор. Если вас интересует ответ на этот вопрос, то он звучит так: "первый, который найдет". Конечно же, этот ответ совершенно бесполезен, потому что определить, какой индекс оптимизатор найдет первым, очень трудно. Оптимизатор очень плохо определяет, какие неуникальные индексы могут замедлить запрос в тех или иных случаях, особенно для столбцов, которые не очень избирательны (т.е. спектр значений в них не очень велик).
2. Чем больше индексов, тем выше затраты на их сопровождение при обработке DML-операторов. Общее эмпирическое правило гласит: если работу по вставке строки в таблицу принять за единицу, то для создания элемента индекса требуется три такие единицы. Следовательно, при вставке строки в таблицу с тремя индексами нужно выполнить в десять раз больше работы, чем при вставке строки в неиндексированную таблицу. Вот вам и пища для размышлений!
3. Индексы занимают ценное пространство базы данных, причем блоки-листья, которые обычно занимают свыше 90% индексного пространства, никогда не сжимаются. Кроме того, повторяющиеся ключи хранятся в количестве, равном числу экземпляров (за исключением кластерных индексов).
Типы индексов и методы индексирования
Сейчас мы более подробно рассмотрим некоторые связанные с индексами вопросы, которые были затронуты в предыдущих разделах.
Индексы, имеющие структуру В*-дерева
Индексы, имеющие структуру В*-дерева (сбалансированного дерева), — это традиционная форма индексов для баз данных Oracle. Изображение этой структуры напоминает перевернутое дерево (отсюда и название). Она состоит из корневого блока, блоков-ветвей и блоков-листьев. Реализация этой структуры индексов в Oracle имеет ряд интересных особенностей, включая оптимизацию, допускающую наличие действительно одноуровневых индексов, в которых корневой блок также является единственным блоком-листом. (Здесь аналогия с деревом несколько нарушается.)
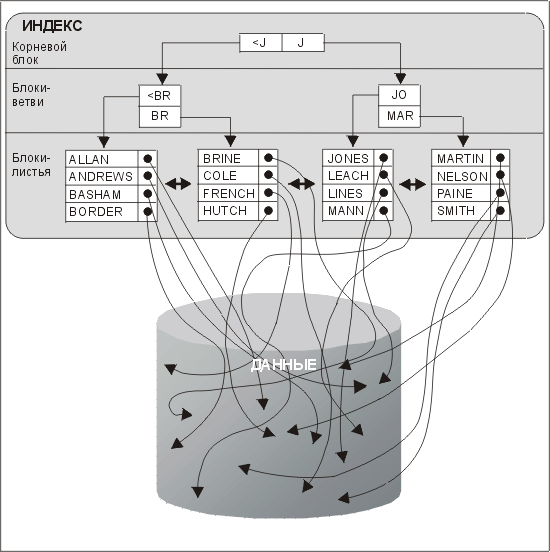
На рис. 6.4 изображен индекс, имеющий структуру В*-дерева, для примера из предыдущего раздела. Осуществляя поиск определенного ключевого значения, Oracle сначала читает корневой блок. Сравнивая значения в корневом блоке с искомым, Oracle определяет блок-ветвь для диапазона значений, в который входит искомое значение. Затем выполняются чтение блок-ветви и аналогичная операция по определению соответствующего блока-листа (или ветви следующего уровня — в зависимости от глубины индекса). Если нужный элемент находится в блоке-листе, то система выдает идентификатор строки соответствующего элемента данных в блоке данных, к которому затем можно обратиться посредством одиночного посещения блока. Если блок еще не находится в буферном кэше Oracle, то для этого понадобится операция чтения с диска.
Рис. 6.4. Индекс, имеющий структуру В*-дерева
Примечание
Следует отметить два случая, когда после выборки идентификатора строки из индекса может понадобиться несколько посещений блока. Первый — если строка имеет в длину более одного блока (так называемая расщепленная строка), и второй — когда строка за время своего существования увеличилась и ее пришлось переместить из исходного блока в другой (мигрировавшая строка). В редких случаях строка может сначала мигрировать, а затем опять увеличиться и стать расщепленной.
Рассмотрим некоторые свойства индексов, имеющих структуру В*-дерева.
1. Количество операций ввода-вывода, необходимых для получения идентификатора строки, зависит от числа уровней ветвления дерева. По мере того как индекс увеличивается в размерах, Oracle может добавлять в него новые уровни, чтобы обеспечить сбалансированность дерева. Однако в действительности практически невозможно получить более четырех уровней. Например, при двухкилобайтных блоках базы данных индекс для шестибайтных значений столбца вырастет до четырех уровней, когда число элементов индекса превысит 2000000, и (в зависимости от степени сжатия блоков-ветвей) останется на этом же уровне для миллиардов строк. Что касается чтения с диска, то, как правило, осуществляется чтение не более двух нижних уровней, поскольку первые два уровня часто используемых индексов обычно кэшируются в SGA.
2. Корневой узел и узлы-ветви индекса сжимаются, поэтому они содержат ровно столько начальных байтов значения, сколько нужно для того, чтобы отличить его от других значений. Узлы-листья содержат полное значение. Это позволяет выполнить некоторые запросы только при помощи индекса, т.е. без обращения к блоку данных:
SELECT COUNT(*)
FROM employees emp
WHERE emp.ename LIKE 'S%';
Однако это сработает лишь при условии, что столбец ENAME определен как NOT NULL (поскольку неопределенные значения не индексируются).
3. Значения в индексе упорядочиваются по ключевому значению, а блоки индексов связываются в двунаправленный список. Это обеспечивает последовательный доступ к индексу и позволяет использовать индекс для выполнения операции ORDER BY в запросе.
4. Индекс, имеющий структуру В*-дерева, можно применять как для поиска точного соответствия, так и для поиска диапазона значений:
ename < 'JONES', ename BETWEEN 'JONES' AND 'SMITH'
5. Индексы, имеющие структуру В*-дерева, могут охватывать несколько столбцов таблицы (такие индексы называются составными). Оптимизатор может использовать составные индексы только там, где задана лидирующая часть индекса. Например, индекс по столбцам (ENAME, JOB) при выполнении запроса
SELECT * from employee emp WHERE emp.job = 'SALES';
применяться не будет, поскольку лидирующая его часть (ENAME) в запросе не указана.
6. Оптимизатор Oracle сам примет решение о том, использовать индекс или нет, если мы не повлияем на него посредством подсказки или путем изменения SQL-запроса.
7. Неопределенные значения не индексируются. Если столбец, для которого рассматривается возможность индексирования, допускает неопределенные значения, то оптимизатор откажется применять его в определенных операциях, которые, по вашему мнению, могут выполняться с использованием индекса. Самый очевидный пример — ORDER BY.
Примечание
Oracle не хранит в индексах полностью неопределенные ключи, но сохранит в индексе частично неопределенный составной ключ. В этом случае СУБД классифицирует одно неопределенное значение как равное другому неопределенному значению с целью соблюдения ограничений PRIMARY KEY и UNIQUE. Она даже примет неопределенное значение как лидирующую часть составного индексного ключа и сохранит этот ключ в индексе, но откажется использовать этот индекс для поиска строк, у которых значение лидирующей части ключа не определено.
8. Блоки-ветви не удаляются (кроме как в операции TRUNCATE над базовой таблицей или кластером). Корпорация Oracle утверждает, что это ограничение существенно помогает в реализации настоящего блокирования на уровне строк. Но ведь этим свойством обладала и Oracle версии 5, где блокировки на уровне строк не было!
9. Блоки-листья повторно заполняются лишь в том случае, если становятся совершенно пустыми (и даже это — относительно недавнее новшество; пространство блоков-листьев обычно никогда не восстанавливалось). Таким образом, даже в текущих версиях индексы, страдающие от высокой интенсивности вставок и удалений, часто заполняются, главным образом, невосстановленным пространством из удаленных элементов.
Отключение индексов
Одно из важных качеств хорошего проектировщика — прагматизм. Что мы делаем, когда проектируем два модуля с совершенно разными требованиями к индексам для одной таблицы? Ущемляем один модуль в пользу другого? Нет, обычно мы стараемся обеспечить приемлемые условия для обоих модулей.
Самый простой конфликт, который приходится разрешать, — это конфликт между запускающейся раз в сутки пакетной программой, выполняющей интенсивное обновление таблицы (для быстрой работы этой программы нужно минимизировать число индексов), и оперативной программой, которой требуется множество индексов для поддержки гибкого поиска. В данном случае мы просто заставляем пакетную программу удалить индексы перед началом работы и пересоздать их после ее завершения. Если эта программа работает во время оперативного соединения, то, возможно, ей придется потерпеть.
Можно ли отключить индекс в запросе? Мы говорили, что индексы не всегда оказывают положительное влияние на производительность запросов. Давайте рассмотрим крайний случай. Представьте, что вся таблица EMPLOYEE, изображенная на рис. 6.4, читается с использованием индекса.
Читать индексные блоки достаточно легко, так как они связаны, а элементы индекса упорядочены. Однако, как видно из указателей на блоки данных на рис. 6.4, строки данных находятся в разных местах. Если читать таблицу с использованием индекса, то придется перечитывать один и тот же блок данных несколько раз. В данном случае эффективнее выполнить полное сканирование таблицы и читать блоки данных по одному. Благодаря имеющейся в Oracle7 возможности чтения с упреждением, при полном сканировании таблицы мы фактически читаем несколько блоков в одной операции ввода-вывода (точное количество задается в параметре инициализации сервера DB_FILE_MULTIBLOCK_READ_COUNT).
Должен существовать момент, когда более эффективным становится сканирование таблицы, а не использование индекса. Чтобы его установить, определите количество индексов и элементов данных в блоке и число уровней в индексе, а затем сравните количество логических операций ввода-вывода для каждого метода. Существует и общее эмпирическое правило — если ожидается, что число возвращаемых строк превысит 15—20% от числа строк в таблице, то, вероятно, лучше использовать полное сканирование таблицы. (Оптимизатор по стоимости, кажется, применяет в качестве точки отключения индексов значение 5%, что, конечно, очень мало.)
Как явно отключить индекс в запросе? В Oracle версии 6 это делалось путем определенной модификации индексированного столбца. Вот несколько примеров:
SELECT *
FROM employee emp
/* конкатенировать пустую строку с символьным столбцом */
WHERE emp.ename || '' = 'SMITH';
SELECT *
FROM employee emp
/* использовать функцию, которая не влияет на смысл */
WHERE UPPER (emp. ename) = 'SMITHS';
SELECT *
FROM employee emp
/* добавить нуль в числовые столбцы */
WHERE emp.empno + 0 = 1234;
Из-за методов упорядочивания индекса и проведения поиска в нем всякая трансформация, влияющая на значение столбца и, следовательно, на его положение в индексе, приводит к тому, что индекс для поиска данного элемента использоваться не будет.
В Oracle7 индекс отключается через подсказку оптимизатору. Этот метод имеет ряд существенных преимуществ:
• он более понятен и очевиден для читающего SQL-запрос;
• работает быстрее. Показанные в примерах выше лишние операции фактически выполняются, на что требуется довольно много процессорного времени.
Известных недостатков у него нет, особенно сейчас, когда версия 7.3 выдает предупреждение, если не может понять подсказку или отказывается принять ее. Вот пример подсказки оптимизатору:
SELECT /*+ FULL(EMP) */
FROM employees emp
WHERE emp.ename = 'SMITH';
Еще одно преимущество данного метода состоит в том, что оптимизатору можно указать, какие индексы использовать при наличии выбора и что оптимизировать — пропускную способность (ALL ROWS) или время реакции (FIRST ROWS).
Хочется верить, что когда оптимизатор по стоимости версии 7.3 окончательно "созреет", отключение индексов станет забытым искусством.
Составные индексы
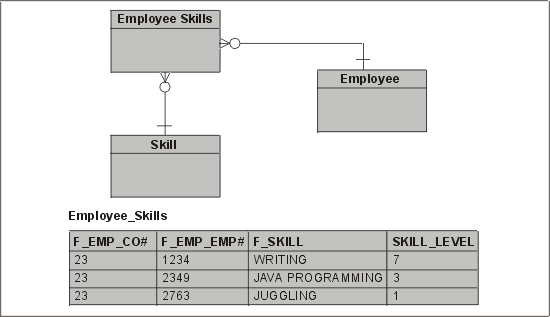
Как упоминалось выше, индексы, состоящие более чем из одного столбца, называются составными. Они встречаются очень часто и являются прямым следствием существования составного первичного ключа таблицы, особенно если таблица соответствует промежуточной сущности. Пример такой таблицы (EMPLOYEE_SKILLS) приведен на рис. 6.5.
Рис. 6.5. Таблица с составным индексом
Поскольку в этом примере мы обрабатываем данные о работниках разных компаний, то таблица EMPLOYEE_SKILLS имеет индекс для трех столбцов внешнего ключа (F_EMP_CO#, F_EMP_EMP#, F_SKILL). Важно, чтобы столбцы в этом индексе располагались в оптимальном порядке. Необходимо также рассмотреть возможность дополнения этого индекса еще одним. Многие годы в документации Oracle утверждалось, что столбцы в индексе должны располагаться по порядку их избирательности. Это совершенно бессмысленный совет, полностью игнорирующий цели, для которых создается и применяется индекс! Помните, мы говорили, что Oracle будет использовать индекс только в том случае, если в запросе указана лидирующая часть ключа. В нашем примере с таблицей EMPLOYEE_SKILLS Oracle будет использовать индекс для поиска конкретного работника в конкретной компании, а не для поиска конкретной специальности (если только не указан и конкретный работник). Ниже приведены примеры SQL-запросов, в которых применяется часть индекса, весь индекс и вообще не используется индекс:
select ems.* /* используются первые две части ключа */
FROM employee_skills ems
WHERE ems.f_emp_co# = 23
AND ems.f_emp_emp# = 1234;
SELECT ems.* /* используется весь индекс */
FROM employee_skills ems
WHERE ems.f_emp_co# = 23
AND ems.f_emp_emp# = 1234;
AND ems.f_skill = 'WRITING';
SELECT ems.* /* индекс не используется */
FROM employee_skills ems
WHERE ems.f_skill = 'WRITINGS';
SELECT ems.* /* используется лидирующая часть индекса для поиска компании, а затем производится прямое сканирование индекса - поиск 'WRITING' производиться не будет, 'WRITING' будет найдено в индексе при сканировании */
FROM employee_skills ems
WHERE ems.f_emp_co# = 23
ADD ems.f_skill = 'WRITING';
Если мы хотим произвести поиск в EMPLOYEE_SKILLS только по специальности или соединить эту таблицу с таблицей SKILLS, не соединяя ее с таблицей EMPLOYEES, то лучше создать неуникальный индекс для столбца F_SKILL. Можно создать уникальный индекс для столбцов (F_SKILL, F_EMP_CO#, F_ЕМР_ЕМР#), но мы не рекомендуем так делать. Это повлечет за собой лишние затраты при вставке новой строки, поскольку Oracle придется проверять два индекса на предмет наличия значения-дубликата. Если в вашем приложении (или в приложении, требующем оптимальной производительности) часто используется последняя из приведенных выше форм запроса, то рекомендуем создать неуникальный индекс для столбцов (F_SKILL, F_EMP_CO#).
В данном примере нам вряд ли когда-нибудь потребуется осуществлять поиск по столбцу F_ЕМР_ЕМР#, но бывают случаи, где такая "средняя часть" ключа полезна сама по себе. Руководящий принцип здесь — стремиться к так называемой треугольной модели*** индексных ключей, включающей наиболее часто используемые (или самые критичные для производительности) индексные ключи. Треугольная модель для нашего примера будет выглядеть так:
Принимая решение об индексировании, соблюдайте следующие общие правила.
• Должно быть в наличии ограничение PRIMARY KEY (которое, конечно, сгенерирует уникальный индекс).
• Нельзя создавать для таблицы несколько индексов, содержащих одинаковые, но расположенные в другом порядке столбцы (индексы необходимо сократить или придать им треугольную форму). Исключением из этого правила могут быть классические промежуточные таблицы.
• Ни в коем случае нельзя допускать, чтобы у нескольких индексов для одной таблицы была одинаковая лидирующая часть.
Впрочем, это всего лишь общие правила. Всегда смотрите на то, как модули кода обращаются к таблице. Это означает, что решение об индексировании (кроме индексов по первичному и уникальному ключу) следует принимать после того, как код написан и можно посмотреть, как он работает с реальными объемами данных.
К сожалению, часто проектировщики принимают крайне неудачные решения об индексировании. Это обычно приводит к тому, что в схеме базы данных слишком много индексов. В результате центральный процессор "сжигается" на сопровождение индексов, время его работы с оптимизатором тратится впустую, дисковое пространство расходуется неэффективно и (при использовании оптимизатора по правилам) значительно возрастает вероятность того, что оптимизатор выберет неверный индекс.
Выбор оптимизатора
Среди новых особенностей Oracle7, анонсированных с большой помпой, было появление оптимизатора по стоимости (или статистического оптимизатора) в качестве альтернативы старому оптимизатору по правилам. (Оптимизатор по правилам можно использовать, но Oracle планирует в конечном итоге отказаться от него.) Выбор оптимизатора существенно влияет на применение индексов и в значительной степени является проектным решением. Несмотря на громкую рекламу оптимизатора по стоимости, внедрение его в эксплуатацию осуществляется довольно медленно, вследствие "болезней роста" и недостатков функциональности. Oracle версии 7.3 — это, вероятно, первый выпуск, где мы действительно советуем использовать этот оптимизатор.
Примечание
Одним из факторов, препятствующих планам Oracle отправить оптимизатор по правилам "в отставку", является большой объем собственного прикладного кода компании, который должен подвергнуться широкомасштабной и дорогостоящей настройке под использование оптимизации по правилам. Пока Oracle не решит вложить средства в переработку этого кода или не наделит оптимизатор по стоимости способностью генерировать эффективные пути доступа, оптимизатор по правилам, скорее всего, останется в строю.
Чем различаются эти режимы оптимизации? Оптимизация по правилам инвариантна: оптимизатор выбирает пути доступа согласно набору конкретных правил, отраженных в документации на Oracle7. Оптимизатор по стоимости учитывает статистику как по таблицам, так и по индексам и принимает управляемое данными решение о том, какой индекс использовать (если вообще использовать). Вспомните эмпирическое правило о котором мы упоминали выше (в разделе "Отключение индексов"): индекс отключается в случае, если в запросе возвращается более 15—20% строк таблицы. Но как на этапе разработки кода определить, сколько процентов строк будет возвращено? Даже если наш прогноз окажется верным, можно ли с уверенностью сказать, что распределение данных со временем не изменится?
Существует компромисс: предоставить право принять это решение оптимизатору, влияя на него там, где мы посчитаем необходимым (посредством подсказки). Как это сделать и каковы недостатки такого подхода?
Оптимизатор по стоимости работает путем оценки стоимости всех обоснованных вариантов оптимизации запроса и выбора варианта с минимальной стоимостью. "Стоимость" в данном контексте есть оценка числа посещений блоков базы данных и числа операций сетевого ввода-вывода. Использование центрального процессора при этом не учитывается. Расчет производится на основании статистической информации о таблице, хранящейся в словаре данных, которая вычисляется или оценивается по случайной выборке с помощью команды ANALYZE. Эта информация отражает хранение и распределение данных в разрезе таблиц, кластеров и индексов. Собирается следующая статистическая информация:
О таблице:
Общее количество строк
Количество блоков со строками
Количество пустых блоков
Средний объем свободного пространства на блок
Количество связанных блоков
Средняя длина строки
О столбце:
Количество различных значений
Наименьшее значение в столбце
Наибольшее значение в столбце
Об индексе:
Глубина (количество ветвей плюс лист)
Количество блоков-листьев
Количество различных ключевых значений
Среднее Количество блоков-листьев индекса на ключ
Среднее количество блоков данных на ключ
Количество логических блочных операций ввода-вывода при чтении всей таблицы с использованием индекса
(Только в версии 7.3) 75-точечная гистограмма, на которой отражаются индексные ключи; по этим данным степень избирательности любой индексной операции можно оценить с точностью до 2,5%
Даже при наличии столь обширной статистической информации оптимизатору по стоимости приходится делать ряд серьезных предположений относительно ее применимости и надежности (помните: есть ложь, гнусная ложь и статистика!).
Первое предположение состоит в том, что эта статистика точно отражает реальность. Эта информация не собирается автоматически, а вычисляется SQL-командой ANALYZE. Регулярный запуск этой команды является обязанностью администратора базы данных. Это означает, что данная информация, будучи сохраненной в словаре данных, подвержена старению и со временем становится менее надежной (вероятно, это грустное отражение нас самих). В худшем (и невероятном) случае может оказаться, что мы вычислили статистическую информацию, полностью удалили данные из таблицы и загрузили в нее новые данные. Это даст нам статистическую информацию, абсолютно не связанную с данными! Опыт показал, что даже таблицы, подверженные интенсивному обновлению, не проявляют тенденции к сильному изменению своей общей "формы" — поэтому это не очень ужасный кошмар. Тем не менее, следует планировать регулярное обновление статистической информации.
Еще одно предположение, которое неявно делает оптимизатор по стоимости (в версиях до 7.3), состоит в том, что значения в индексе распределены равномерно. Другими словами, если в таблице 500 тысяч строк и индексированный столбец может иметь два значения (например, Y и N), то оптимизатор по стоимости предполагает, что каждое значение встречается 250 тысяч раз, и вообще не будет использовать индекс. Если же N встречается только 100 тысяч раз, то, естественно, более эффективно выбирать эти значения при помощи индекса. На устранение этого недостатка направлены гистограммы в версии 7.3.
Итак, подытожим наши впечатления от оптимизатора по стоимости.
• В версиях до 7.2 его вообще не следует использовать.
• Если вы все же решили его использовать, регулярно выполняйте для всех таблиц команду ANALYZE с целью обновления статистики, если только вы не выполняли глобальный прием или удаление данных; раз в месяц будет достаточно.
• Если вы не работаете с версией 7.3, то применяйте оптимизатор по стоимости только в случае, если индексы, которые, вероятно, будут использоваться для выполнения запроса, имеют довольно равномерное распределение значений.
• Помните о том, что оптимизатор по правилам генерирует очень хорошие пути доступа для хорошо индексированных, высоконормализованных таблиц, к которым обращается аккуратно написанный код. С другой стороны, чем в меньшей степени вы контролируете структуру данных и SQL-код, тем выше вероятность того, что вы должным образом оцените оптимизатор по стоимости.
Проблема связанной переменной
Несмотря на то, что оптимизатор по стоимости в версии 7.3 имеет доступ к гистограммам значений, существуют ситуации, когда эти гистограммы очень нужны, но не используются. В этих случаях оптимизатор выбирает путь доступа до получения реальных значений ключа. Самый простой пример такой ситуации — проблема связанной переменной, которая иллюстрируется следующим примером:
SELECT c.cust#
, c.cust_name
FROM custs с
WHERE c.country_code = :country;
SELECT c.cust#
, c.cust_name
FROM report_driver r
, custs с
WHERE r.report# = :report_num
AND country_code LIKE r.param;
Если эта таблица находится в базе данных какой-нибудь американской корпорации, то может случиться, что из 50000 клиентов 48000 имеют код страны US и лишь 300 клиентов — код страны FR (Франция). Если построен индекс по столбцу COUNTRY_CODE, то весьма разумно использовать его в запросе, когда связанная переменная имеет значение, отличное от US, так как мы знаем, что при этом будет извлекаться менее 4% строк таблицы. Но поскольку решение об оптимизации принимается до того, как станет известно значение связанной переменной, то знание распределения значений в данном случае совершенно бесполезно.
Проблема становится более сложной для решения, если значение выбирается из другой таблицы, так как в этом случае нам известно только то, что в таблице REPORT_DRIVER для любого номера отчета может быть несколько строк. Действительно, интеллектуальный оптимизатор посмотрел бы, является ли столбец REPORT# первичным ключом таблицы REPORT_DRIVER, чтобы определить возможность наличия нескольких значений. Однако в любом случае к тому моменту, когда оптимизатор определит, что в столбце CUSTS ищется значение US, процесс обработки запроса зайдет довольно далеко. Для всех версий Огас1е7 эта проблема разрешается просто — значения связанных переменных никогда не используются в решениях об оптимизации. Вместо этого оптимизатор делает "интеллектуальное предположение" о вероятных свойствах этого значения.
Наш опыт показывает, что для каждой операции LIKE оптимизатор предлагает полное сканирование таблицы (на случай, если значение начинается метасимволом), а для любого равенства по полному индексному ключу — поиск при помощи индекса.
Хеш-ключи
Выше мы подробно рассмотрели индексы, имеющие структуру В*-дерева. Давайте остановимся на более специализированном способе поиска, в котором применяется не индекс, а хеш-ключ. В Oracle этот механизм часто называют хеш-кластером, так как хеш-ключи можно использовать только для табличных кластеров. Основная идея, на которой строится работа хеш-ключей, состоит в следующем. Когда пользователь выполняет вставку строки в любую таблицу кластера (или обновление в кластерном ключе), значение хеш-столбца в новой строке обрабатывается специальной функцией (хеш-функцией), возвращающей числовое значение. Это значение затем используется для физического размещения строки в таблице.
В процессе поиска строки значение индексного столбца обрабатывается хеш-функцией, которая выдает хеш-значение, указывающее местоположение этой строки. Это позволяет за одну операцию чтения получить блок, который должен содержать данные. Если блок находится в кэше, то операция ввода-вывода вообще не выполнятся. Естественно, это более эффективно, чем индекс, имеющий структуру В*-дерева, который требует выборки как минимум одного индексного блока и одного блока данных и который может (в большой таблице) потребовать посещения четырех индексных блоков и одного блока данных (в сумме пять посещений блоков), а также, вероятно, трех операций ввода-вывода — при нормальной эффективности кэша.
Примечание
Должны признаться, что мы использовали хеш-кластеры только в тестовых средах и никогда не сталкивались с живой системой, в которой применялось бы хеширование. Однако мы общались с людьми, получившими при использовании хеш-кластеров неутешительные результаты. По их словам, на загрузку хеш-кластеров, как и всех кластеров, уходит чертовски много времени.
Свойства хеш-ключей
Давайте рассмотрим некоторые свойства хеш-ключей.
• Хеш-ключ можно применять только при поиске по равенству.
• Если хеш-ключ используется эффективно, то должна быть одна операция чтения на выборку.
• Для эффективной работы хеш-ключа необходимо точно задать размеры таблицы.
• Для эффективной работы хеш-ключа необходим хороший алгоритм хеширования.
• При заниженных размерах таблицы или плохом алгоритме приходится связывать несколько блоков в хеш-кластере, что влечет за собой выполнение дополнительных операций ввода-ввода как при выборке, так и при вставке.
• Завышение размеров таблицы приводит к появлению разреженных блоков и, следовательно, к неэффективному полному сканированию таблицы.
• Общий объем необходимого пространства в хеш-кластере с нормально установленными размерами должен быть меньше, чем сумма объемов данных и индексов, имеющих структуру В*-дерева.
• Вместо хеш-функции, которая предлагается в Oracle, можно написать свою. (В версиях начиная с 7.2 этот процесс проще, чем в предыдущих версиях.)
• Если столбец таблицы содержит целочисленные значения, имеющие равномерное распределение, его можно использовать в качестве хеш-ключа, не применяя никаких функций (с помощью HASH_IS). Именно это позволяет задавать собственную хеш-функцию в версиях 7.0 и 7.1.
• Загрузка данных в хеш-кластеры всегда выполняется намного дольше, особенно по сравнению с таблицей, из которой индексы перед загрузкой удаляются, а после загрузки пересоздаются. Эту проблему помогает решить сортировка по хеш-ключу перед загрузкой.
• Хеш-ключи не следует использовать в случае, если ключ подвержен изменениям, так как при этом понадобится переставлять всю строку. Это, конечно, характерно для всех кластерных ключей.
• Хеш-ключи вряд ли стоит применять, если один и тот же ключ используется и для сканирования. Этот механизм не поддерживает сканирование, и, возможно, придется строить по этому же ключу обычный индекс.
• Хеш-ключи нельзя объявлять уникальными. Это серьезный недостаток, потому что, если ключ уникален и пользователь хочет, чтобы Oracle в обеспечила его уникальность, он должен либо применить ограничение UNIQUE или PRIMARY KEY (которое построит традиционный индекс), либо создать триггеры BEFORE INSERT и BEFOR UPDATE, проверяющие этот ключ.
Чтобы основанное на триггерах решение работало надежно, а не просто большую часть времени, требуется эксклюзивная блокировка. Обычно она устанавливается на кластеризованной таблице, но — если это может вызвать серьезное снижение производительности — решение можно построить с помощью пакета DBMS_LOCK (который есть в Огас1е7) путем блокирования хешированного ключевого значения. Хотя при этом решении используется кооперативная блокировка, которую мы обычно не рекомендуем (из-за того, что какая-нибудь программа может отказаться от совместной работы) и при которой блокировка помещается в триггер, единственный путь избежать его - выполнять программу с отключенным триггером.
Пример хеш-кластера
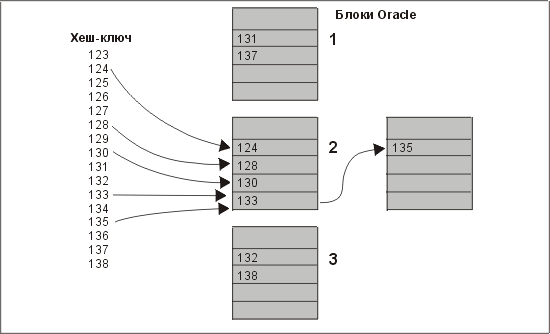
Позже мы еще остановимся на некоторых затронутых нами проблема а сейчас давайте рассмотрим, как выглядит кластер. На рис. 6.6 иллюстрируется упрощенный пример хеширования. В этом примере у нас три основных блока. Поскольку в каждом блоке может располагаться в среднем всего четыре строки, а во второй блок хешируются пять строк, то имеется блок переполнения, содержащий одно значение — 135. Осуществляя поиск по ключу 135, Oracle применит алгоритм хеширования, который укажет, что строка находится в блоке два. Система прочитает блок два, просмотрит все находящиеся в нем строки, но нужного значения не обнаружит. Однако она отметит, что данный блок является связанным, прочитает следующий связанный блок и просмотрит его. Этот процесс будет продолжаться до тех пор, пока строка не будет найдена или пока не будет просмотрен последний связанный блок, но нужная строка обнаружена не будет.
Рис. 6.6. Определение местонахождения строки с помощью хеш-ключей
Как мы говорили ранее, хеш-ключи можно использовать только для поиска по полностью заданному ключу (который может состоять более чем из одного столбца). Для поиска в диапазоне, поиска неэквисоединений и частичных совпадений с ключом их применять нельзя. Впрочем, ничто не мешает вам построить индекс, имеющий структуру В*-дерева, для хеш-столбца и сделать возможными и эти методы поиска. Но поскольку в плане производительности хеш-поиск не намного лучше поиска по индексу (по крайней мере, по нашим наблюдениям), использование комбинаций хеша и В*-дерева для одного и того же столбца (столбцов) не дает ощутимой выгоды. Единственный случай, когда превосходство хеш-поиска над поиском по обычному индексу весьма существенно, — использование функции HASH IS. (При этом числовое значение столбца является хеш-ключом, и никакой алгоритм не задействуется).
Можно рассмотреть возможность использования хеш-ключа в банковской системе, где мы всегда извлекаем данные по уникальному числовому номеру счета, количество счетов довольно статично и где необходим быстрый доступ. Однако, перед тем как принимать решение в данном случае, следует проанализировать и время загрузки, и время реакции на запросы.
Подытоживая наши впечатления от хеш-ключей, скажем, что сначала нужно всесторонне оценить недостатки и затраты, связанные с этим методом, и лишь после этого можно определить, дадут ли хеш-ключи более высокую производительность при выборке данных, чем традиционные (и гораздо более гибкие) индексы.
Индексные кластеры
В предыдущем разделе мы упоминали о кластерах (поскольку для хеширования необходимо, чтобы таблица находилась в кластере), но так и не объяснили, что же это такое. Кластеризация — это попытка разместить рядом, в одном блоке данных, строки, доступ к которым осуществляется при помощи одинакового значения ключа. Ключ может быть либо хеш-ключом, либо индексным. Если это хеш-ключ, то физическое размещение строк определяется хеширующей функцией. Если это индексный ключ, то для идентификации адреса блока данных (как всегда) используется индекс, имеющий структуру В*-дерева, но строки с одинаковым ключевым значением размещаются в одном блоке или нескольких связанных блоках. Строки, которые хранятся в индексном кластере, не обязательно должны принадлежать одной таблице. Индексные кластеры можно использовать для хранения дочерних строк с родительской, что должно существенно повысить производительность при выполнении соединения этих таблиц.
С физической точки зрения, кластер находится отдельно от таблиц. Он создается с указанием параметров хранения, а затем в нем последовательно создаются кластеризованные таблицы. Размещение нескольких таблиц в одном кластере требует дополнительных затрат при выполнении полного сканирования любой таблицы в кластере, так как строки других таблиц нужно пропускать. Поэтому здесь при сканировании, как правило, приходится обрабатывать больше блоков, чем в случае некластеризованной таблицы.
Многие аргументы против использования хеш-ключей в равной степени можно отнести и к кластерам любого вида. Индексные кластеры эффективны какой-то одной специализированной схеме поиска (например, при поиске строк с идентичными ключами), но при этом другие операции (в частности, операции), как правило, производятся медленнее. Следовательно, кластеризацию не рекомендуется применять к таблицам, подверженным, интенсивному обновлению. Если вы хотите использовать кластеризацию, обязательно правильно задайте размер кластера на основании ожидаемого содержимого и потребуйте, чтобы администратор базы данных регулярно контролировал его использование.
Мы рекомендуем применять кластеры только в следующих, очень специфических случаях:
• Данные по кластерным ключам распределены относительно равномерно и плотно, а их объем почти всегда меньше размера блока базы данных (поскольку в противном случае будут образовываться кластерные цепочки).
• На кластерный ключ всегда приходится более одной строки (поскольку в противном случае сгодится и обычная индексированная таблица).
• Все данные для заданного кластерного ключа необходимы при каждом доступе по кластерному ключу (поскольку в противном случае сгодятся и обычные индексированные таблицы).
• Частота DML-обращений к данным мала (поскольку в противном случае плохая производительность DML-операций в кластеризованных таблицах повлияет на всю систему).
Даже в этих случаях выигрыш в производительности, как правило, не очень высок. В то же время плохо построенный кластер может существенно снизить производительность приложения. Поэтому будьте осторожны! Однако несмотря на это, Oracle интенсивно использует индексные кластеры в оперативном словаре данных. Если хотите посмотреть, насколько интенсивно, — найдите файл sql.bsq, который на Unix-платформах находится в каталоге $ORACLE_HOME/dbs, и просмотрите его.
Есть один особый случай, где мы иногда рекомендуем использовать индексный кластер для хранения одной таблицы, например такой, как определена в следующем примере:
CREATE CLUSTER cust_comments_cluster (cust_id_ VARCHAR2(8))
STORAGE . . .
INDEX;
CREATE INDEX cust_comments_cust_id ON CLUSTER cust_comments_cluster
STORAGE ...
CREATE TABLE cust_comments
( cust_id VARCHAR2(8) NOT NULL REFERENCES customers
, enrty# NUMBER NOT NULL
, date_entered DATE NOT NULL
, entered_by VARCHAR2(8) NOT NULL REFERENCES operators
, comment_text VARCHAR2(80) NOT NULL
, PRIMARY KEY (cust_id, entry#)
) CLUSTER cust_comments_cluster (cust_id);
Эта таблица кластеризована по столбцу CUST_ID, и все комментарии для любого данного клиента будут расположены либо в одном блоке, либо (если их много) в связанных блоках, и их можно выбрать за одну операцию поиска по индексу с помощью следующего запроса:
SELECT date_entere
, entered_by
, comment text
FROM cust_comments
WHERE cust_id = :this_cust
ORDER BY entry# DESC;
Обратите внимание, что ограничение PRIMARY KEY в операторе CREAТЕ TABLE закомментировано, чтобы избежать создания второго индекса. Этот прием следует применять очень осторожно: он заметно снижает затраты при вставке строк в таблицу, но оставляет эту структуру уязвимой для ошибок приложений. Такая форма однотабличного кластера для очень больших таблиц обычно не используется, но может быть полезна в приложении, где:
• очень немногие записи о клиентах имеют комментарии;
• снабженные комментарием записи имеют, как правило, более одного комментария;
• при выборке комментариев для данного клиента выбираются все комментарии.
* С некоторыми неочевидными исключениями, которые мы опишем в главе 7.
** Это намеренное упрощение индексной статистики, применяемой в версиях с 7.0 по 7.2. Данный алгоритм учитывает как число отдельных значений, так и фактор их кластеризации-(Однако нужно ли вам это знать?)
*** Этот подход к индексированию официально предложен Крисом Эллисом, бывшим сотрудником Oracle Corporation UK Ltd., а термин "треугольная модель" изобретен Дейвом Энсором для описания визуального эффекта, получаемого при записи этих ключей один над другим. Если вам кажется, что на треугольник это не похоже, можете выдумать свой собственный термин.
Знаете ли Вы, что аспектно-ориентированное сборочное программирование - это разновидность сборочного программирования, основанная на сборке полнофункциональных приложений из многоаспектных компонентов, инкапсулирующих различные варианты реализации.