В предыдущей главе мы описали некоторые из тех решений, которые должен принять проектировщик, выполняя отображение сущностей в таблицы. Если мы осуществили такое отображение и оно нас удовлетворяет, можно ли сказать, что стадия проектирования, связанная с данными, завершена? К сожалению, нет, остался целый ряд нерешенных вопросов. Один из них — денормализация. "Что же это? После всех хлопот с преобразованием информационной модели в третью нормальную форму (или в нормальную форму Бойса-Кодда) мы собираемся ее разрушить!" — скажете вы. Однако скоро вы убедитесь, что мы "разрушаем" модель, жестко контролируя этот процесс, и только в таких местах, где это повышает производительность.
В этой главе описаны различные типы денормализации и методы реализации этого процесса. Кроме того, мы рассмотрим, как использовать для поддержки денормализации триггеры и как обеспечить целостность данных, не прибегая к созданию дополнительного прикладного кода.
Денормализация: что, зачем и когда?
Денормализация — это процесс достижения компромиссов в нормализованных таблицах посредством намеренного введения избыточности в целях увеличения производительности.
В большинстве случаев необходимость денормализации становится очевидной лишь на этапе проектирования модуля. Другими словами, обычно нельзя принять решение о денормализации на основании одной только модели данных. Учтите — то, что для одного человека полезно, для другого — яд, и решение о денормализации в пользу одного модуля (которое повышает его эффективность и простоту) может иметь пагубные последствия для других модулей (причина этого, как правило, заключается в усложнении обновлений или возникновении конфликтов блокировки). Здесь должен господствовать здравый смысл, и повышение эффективности кода, генерирующего годовой отчет, за счет задач, которые выполняются в диалоговом режиме, грамотным назвать нельзя. Выберите в приложении критичные процессы и принимайте решения о денормализации в основном в пользу этих процессов. Критичные процессы обычно определяют по высокой частоте (т.е. они очень часто выполняются), большому объему (они обрабатывают очень много данных), высокой изменчивости (данные часто меняются) или явному приоритету (пользователи говорят, что они важные).
Конечно, если совершенно другая модель данных позволит превратить 200 часов, необходимых для подготовки годового отчета, в 20 минут, то это веская причина для того, чтобы создавать используемые раз в год таблицы. Но даже такое решение разумно лишь в случае, если есть место на диске и процесс создания таблиц занимает гораздо меньше 200 часов. (Некоторые приемы, которые помогут добиться этой цели, приведены в главе 8.)
К сведению
Мы видели, как денормализация использовалась только для упрощения SQL-запросов при обращении к базе данных. Если вы хотите упросить SQL-запросы на уровне приложения или пользователя, то, наверное, лучше использовать представления, а не вводить избыточность. Однако учтите, что представления не упрощают SQL-запрос с точки зрения процессора SQL СУБД Oracle7, который должен раскрывать определение представления в контексте запроса.
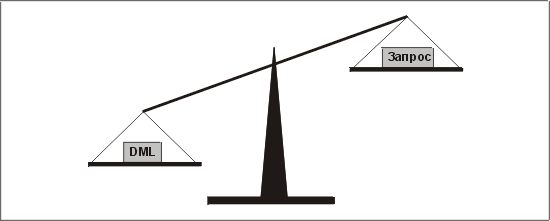
Как правило, денормализация уменьшает время запроса за счет DML-операций (вставки, обновления и удаления) (рис. 4.1). Считайте денормализацию расширением нормализованной модели данных, которое повысит производительность запросов. Определите, что является наиболее важным для приложения, и обязательно отразите все решения (с обоснованием) в журнале проектирования. Помните, что, кроме денормализации, существуют и другие пути повышения производительности. Например, можно внести изменения в схемы индексирования и модульную структуру программы.
Рис. 4.1. Чувствительные весы денормализации
Давайте перейдем к рассмотрению основных типов денормализации. Одни из них мы рекомендуем, а другие — нет (или рекомендуем, но только в исключительных случаях).
Нисходящая денормализация
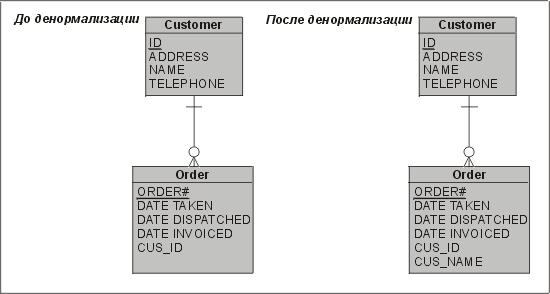
Нисходящая денормализация предполагает перенос атрибута из родительской сущности в дочернюю. На рис. 4.2 видно, что в денормализованной логической модели мы переместили фамилию клиента из сущности Customer ("Клиент") в сущность Order ("Заказ"). Вообще говоря, мы советуем не делать этого! Однако почему же перенос атрибута сделан в данном случае? Единственный выигрыш заключается в том, что мы избежим операции соединения, если захотим вместе с заказом увидеть фамилию клиента.
Рис. 4.2. Пример нисходящей денормализации
Устранение соединений посредством нисходящей денормализации редко оправдывает затраты на ведение денормализованного столбца в таблице ORDER. Такие соединения, как правило, не являются глобальной проблемой, а выполнение нисходящей денормализации может привести к возникновению дорогостоящих каскадных обновлений, дающих небольшую реальную выгоду, а то и не дающих ее вовсе. Например, если клиент меняет фамилию, то нам приходится обновлять все заказы, чтобы отразить это изменения. А нужно ли это делать? Следует ли обновлять старые заказы, которые выполнены и закрыты? Без денормализации эта проблема никогда не возникнет.
Из нашего опыта следует, что нисходящая денормализация оправдана лишь в приложениях хранилищ данных для устранения соединений. Это вызвано тем, что данные в хранилищах — архивные, и поэтому каскадные обновления для них не характерны. Без нисходящей денормализации в таких приложениях во многих запросах может понадобиться соединение таблицы, содержащей миллиард строк, еще с несколькими таблицами значительного размера, что является очень трудоемкой задачей, если не сказать больше. (Хранилища данных подробно рассматриваются в главе 13.)
Восходящая денормализация
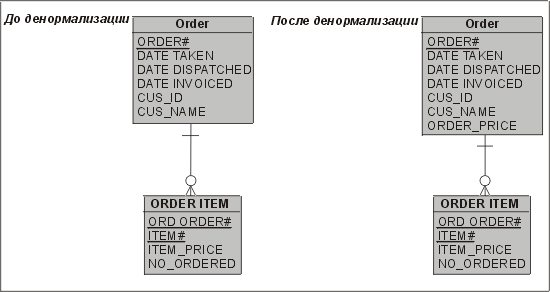
В случае, показанном на рис. 4.3, мы сохраняем информацию из дочерней сущности в родительской — в форме итога.
Рис. 4.3. Пример восходящей денормализации
Рассмотрим простой, но классический пример, показанный в табл. 4.1.
Таблица 4.1. Функции по ведению денормализованных значений
Событие в таблице ORDER ITEM
Действия в соответствующей таблице ORDER
Добавлена новая строка
Удалена строка
Изменена цена
Цена заказа (ORDER_PRICE) увеличена на цену (ITEM_PRICE) новой позиции заказа
Цена заказа (ORDER_PRICE) уменьшена на цену (ITEM_PRICE) старой позиции заказа
Цена заказа (ORDER_PRICE) откорректирована на разницу между старой и новой ценой (ITEM_PRICE) позиции заказа
Если в некоторых критичных функциях системы обработки заказов требуется вычислять общую сумму заказа (суммы ITEM_PRICE в сущностях ORDER_ITEM), то мы можем повысить производительность этих функций, поместив сумму заказа в избыточном столбце таблицы ORDER (в нашем примере он называется ORDER_PRICE, "Цена заказа"). Дополнительные административные задачи, которые возникают при этом, перечислены в табл. 4.1. Однако это создает дополнительную нагрузку на процессы, выполняющие DML-операции в таблице ORDER_ITEM. Это и есть цена, которую мы вынуждены заплатить за повышение производительности запросов. В нашем примере в избыточном столбце хранится сумма значений, но эти приемы применимы к максимальным, минимальным и средним значениям, а также к другим агрегатным показателям.
Методы реализации денормализации
В предыдущем примере мы описали некоторые задачи по управлению денормализованными данных. Однако как же конкретно выполнять эти задачи? В давние времена (Oracle версии 6 и раньше) каждое приложение, генерирующее DML-операции для таблицы ORDER_ITEM, отвечало за обеспечение целостности всех денормализованных столбцов путем выполнения необходимого для этого действия (действий). Это неизбежно приводило к противоречиям в данных. Даже если вы тщательно протестировали приложение, кто-нибудь мог воспользоваться инструментом типа SQL*Plus и "быстренько починить" данные (например, удалить неверную позицию заказа), забыв при этом соответствующим образом откорректировать денормализованные или производные столбцы.
Это привело к необходимости создания специальных скриптов для баз данных Oracle версии б, обеспечивающих проверку целостности денормализованных данных и выдачу сообщений о нарушениях. Эти скрипты должен был периодически прогонять администратор базы данных. Ниже приведен пример такого скрипта для таблиц, построенных от сущностей ORDER и ORDER_ITEM (после денормализации):
SELECT ord.order#
FROM orders ord
WHERE ord.order_price <> (SELECT SUM(oit.item_price)
FROM order_items oit
WHERE oit.ord_order# = ord.order#);
Но эти времена прошли, и авторы подобных скриптов могут отложить клавиатуры, выключить свет и идти домой — Oracle7 позволяет поддерживать денормализацию при помощи триггеров базы данных. Правда, не следует торопиться отпускать последнего автора скриптов — поскольку триггеры можно выключать, нет способа проверки данных, проскользнувших в систему, пока триггеры "спали". По этой причине старые диагностические скрипты могут понадобиться опять! Из приведенного ниже текста триггера видно, насколько просто реализовать в виде триггеров базы данных правила, перечисленные в табл. 4.1.
CREATE OR REPLACE TRIGGER oit_bir BEFOR INSERT ON order_items
FOR EACH ROW
BEGIN
l_new_item_price := :new.item_price;
l_old_item_price := :old.item_price;
l_ord_order := :new.ord_order#;
UPDATE orders ord
SET ord.order_price = ord.order_price - l_old_item_price + l_new_item_price
WHERE ord.order# = l_ord_order;
END;
Поддержка денормализованных столбцов посредством триггеров кажется надежным и элегантным решением. Неужели оно лишено недостатков? К сожалению, существует скрытая проблема, которая в определенных условиях может снизить производительность. Допустим, заказы в среднем имеют по много позиций (скажем, 1000). Мы периодически удаляем заказы и, из-за ограничений ссылочной целостности, сначала должны удалять позиции заказов. Рассмотрим безобидный, на первый взгляд, оператор:
DELETE order_items oit
WHERE oit.ord_id = :x;
Такое удаление повлечет за собой повышение уровня активности в базе данных. Обратившись к определению триггеров, мы видим, что они работают для каждой строки. Это означает, что если удаляемый заказ имеет 1000 позиций, то триггер oit_bdr сработает 1000 раз. Наше разочарование усиливается тем, что мы заранее знаем конечный результат — цена заказа будет равна нулю!
Однако не стоит из-за этого недостатка отказываться от использования триггеров для поддержки денормализации — если эту проблему своевременно выявить, то ее можно обойти. Мы даем триггеру сигнал ничего не делать, устанавливая перед удалением глобальную переменную пакета, которая будет индикатором нашего намерения. Данную переменную можно установить и в триггере DELETE на таблице ORDERS в сочетании с ограничением каскадного удаления. Это вызовет автоматическое удаление связанных с заказом строк в таблице ORDER_ITEMS. Даже в этом случае наш триггер сработает 1000 раз, но он не будет каждый раз выполнять обновление. Фактически он вообще не выполнит никакой обработки, а только проверит вышеупомянутую переменную и завершит работу.
Более подробно использование глобальных переменных пакетов для управления режимами работы триггеров освещено в приложении Б.
Другие способы осуществления нормализации
В этом разделе рассматриваются еще некоторые способы осуществления денормализации — внутритабличная, методом "разделяй и властвуй" и методом объединения таблиц.
Внутритабличная денормализация
Внутритабличная денормализация выполняется в пределах одной таблицы. Чем же может быть вызвана необходимость хранения в строке значения, которое образуется из других данных этой же строки? Единственная веская причина этого - необходимость запроса строки по производному значению. Например, если строка содержит два числовых столбца, Х и Y, то значение Z, равное произведению Х и У (Z = Х * Y), легко вычислить во время выполнения. Однако предположим, что есть запросы, в которых необходимо осуществлять поиск по Z (например, Z, принадлежащему диапазону от 10 до 20). Сохранив избыточные значения Z в столбце, можно построить индекс по Z, и запросы будут использовать этот индекс. Если индекс по Z строить не надо, то решение о его хранении в отдельном столбце зависит от того, что является более приемлемым в данной ситуации — увеличение времени загрузки, вызванное необходимостью постоянно пересчитывать Z, или увеличение времени сканирования, обусловленное удлинением строк за счет его хранения.
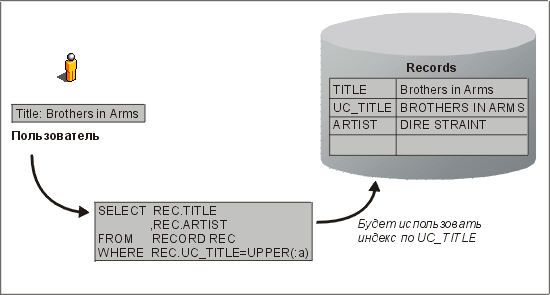
Еще один часто встречающийся пример внутритабличной нормализации проиллюстрирован на рис. 4.4. Здесь одинаковый текст хранится в двух видах: с символами в верхнем и нижнем регистре — для отображения и ввода данных и с символами в верхнем регистре — для обеспечения работы ускоренных запросов без учета регистра.
Рис. 4.4. Оптимизация запроса с помощью производного столбца
Примечание
Oracle заявила о намерении поддерживать в одной из будущих версий своей СУБД индексы для выражений. Это будет особенно полезно для поддержки поиска без учета регистра.
Денормализации этим способом можно избежать, используя прием, который, по нашим данным, дает достойную производительность в таблицах умеренного размера, не влияя ни на размер таблиц, ни на производительность DМL-операций. Он состоит в переработке запроса (см. ниже). Этот прием хорошо срабатывает с данными, которые не сильно "перекошены", но он не столь хорош для атрибутов вроде заголовков рефератов и докладов, многие из которых начинаются с "An" или "The". Этот механизм можно активизировать в Oracle Forms версий 4.0 и 4.5 (опция запроса без учета регистра).
Запрос:
SELECT rec_title
, rec_artist
FROM records r
WHERE r.title - 'Brothers in Arms';
следует преобразовать таким образом:
SELECT rec_title
, rec_artist
FROM records r
WHERE ( r.title LIKE 'Br%'
OR r.title LIKE 'br%'
OR r.title LIKE 'BR%'
OR r.title LIKE 'bR%' )
AND UPPER(r.title) = UPPER('Brothers in Arms');
Денормализация методом "разделяй и властвуй"
Разбиение нормализованной таблицы на две и более таблиц и создание между ними отношения "один к одному" можно, в принципе, классифицировать как форму денормализации. Почему же это делают? Часто по причине технического характера (в данном случае у вас нет выбора). В Oracle есть следующее ограничение: таблица не может иметь больше одного столбца типа LONG или LONG RAW. Допустим, что у вас есть таблица PROGRAMS и нужно сохранить и исходный код (LONG), и объектный код (LONG RAW). Из-за вышеупомянутого ограничения в одной таблице это сделать нельзя, поэтому один из кодов нужно разместить в отдельной таблице. Ожидается, что в Огас1е8 это условие будет смягчено. Однако на данный момент оно может заставить проектировщика разбить таблицу на две.
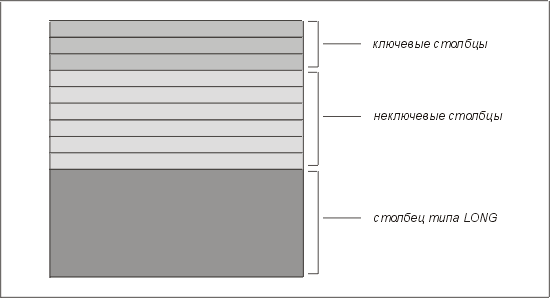
Иногда лучше вынести столбец LONG в отдельную таблицу, даже если вышеупомянутое ограничение не действует. Рассмотрим таблицу, строки которой представлены на рис. 4.5. Предположим, что в большинстве строк столбец LONG содержит данные. Если нет индексов по неключевым столбцам, то при выполнении запросов по любому из этих столбцов Oracle будет осуществлять полное сканирование таблицы. При этом из-за наличия в таблице столбцаLONG понадобятся дополнительные операции ввода-вывода.
Рис. 4.5. Строка таблицы со столбцом типа LONG
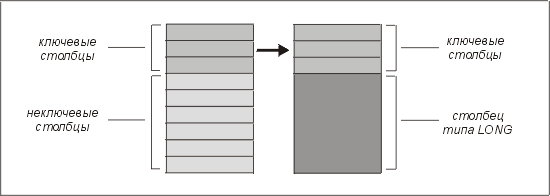
Чтобы устранить эту проблему (если она действительно является проблемой — ведь мы хотели бы полностью избежать полного сканирования таблицы), разделите таблицу так, как показано на рис. 4.6. (Дополнительная информация об использовании столбцов LONG и LONG RAW предлагается в главе 5.)
Рис. 4.6. Выделение столбца LONG
Опять-таки у нас есть основания рассчитывать, что в Oracle8 необходимость в таком искусственном решении исчезнет. В данном случае значение LONG можно будет не хранить как встроенное, а держать его в "дополнительной таблице", зарезервированной для этой цели.
В Oracle7 таблица не может иметь более 254 столбцов, и если предложить таблицу с большим числом столбцов, то также возникнет причина для разделения такой таблицы на две. Однако мы считаем, что в любой хорошо спроектированной схеме базы данных таблицы с числом столбцов около 254 могут понадобиться только в следующих случаях:
• Приложение полностью проектируется на базе унаследованной системы, и каждая таблица строится как точная копия файла унаследованной системы. Конечно, в данном случае наследуется и структура, и все реляционные свойства в ней отсутствуют.
• Выполняется слияние двух таблиц путем формирования в одной из них повторяющейся группы. Этот прием, применение которого оправдано, по нашему мнению, лишь в немногих случаях, рассматривается в следующем разделе.
• Речь идет о хранилище данных, в котором принято решение выполнить массовую нисходящую денормализацию. В этом случае мы рекомендуем создавать таблицы с максимальным для Oracle числом столбцов, так как любое другое решение, вероятно, обусловит необходимость массовых соединений "один к одному".
Хорошей мерой степени нормализации является число столбцов на таблицу. Эмпирическое правило гласит, что очень немногие первичные ключи имеют более двадцати действительно зависимых от них атрибутов.
Денормализация методом слияния таблиц
После того как мы вложили столько сил в нормализацию структур данных и разбивку сущностей, нам предлагается начать слияние таблиц? А как же все те опасности аномалий в данных, о которых мы предупреждали? Фактически, слияние оправдано в очень немногих случаях. Помните, что этот метод, как правило, не следует использовать для того, чтобы избежать соединения — вне хранилищ данных соединения не так уж и плохи.
Один из примеров обоснованного применения слияния — наличие повторяющейся группы, которая гарантированно состоит из фиксированного числа элементов. Хорошими кандидатами на такое объединение являются таблицы со строкой для каждого месяца года или каждого дня недели. В приведенном ниже примере представлена упрощенная система регистрации очков в гольфе. Предполагая, что в раунде не более 18 лунок (причем здесь возможна ошибка), мы можем реализовать таблицу SCORE ("Счет") с одной строкой на раунд, а не с 19 строками на раунд (заголовок плюс 18 записей). Такая реализация показана на рис. 4.7 и 4.8.
рис. 4.7. Простая модель регистрации очков в гольфе
Рис. 4.8. Таблица счета, содержащая повторяющуюся группу с фиксированным числом элементов
В чем преимущество такой реализации? В нашем простом случае ощутимого преимущества может и не быть. Однако следует отметить, что мы можем вычислить сумму по раунду (либо первых, либо последних девяти лунок), обратившись всего к одной строке. Это может быть очень важно, если мы храним в базе данных подробности о большом количестве раундов и часто выполняем итоговые запросы типа "Лучший раунд для Арнольда Палмера", "Лучшие первые девять лунок для Кори Пэйвина в Сент-Эндрюсе" и т.д. В денормализованной структуре запросы такого типа будут работать хорошо.
А вот обеспечить обращение к лункам как к набору будет трудно, да и реализация его будет неэлегантной. Рассмотрим запрос на поиск всех попаданий в лунку с одного удара или, хуже того, запрос на поиск всех препятствий путем соединения с таблицей, в которой имеется по одной строке на трассу, что дает все 18 номиналов для трассы. Это старая-престарая история: подход к денормализации должен определяться требованиями к обработке данных. Одна из замечательных особенностей представленной выше таблицы с повторяющейся группой состоит в том, что вставка в нее осуществляется очень быстро. Для этого нужен всего один оператор INSERT, тогда как в нормализованной версии понадобится девятнадцать таких операторов.
Мы отметили, что правильность предположения о том, что в раунде всегда 18 лунок, сомнительна. В некоторых раундах это число никогда не достигается, тогда как в матчевых встречах оно может быть и больше. Впрочем, возможно, нам не придется регистрировать дополнительные лунки и мы сможем оставить несыгранные лунки пустыми, поэтому наше предположение может оказаться приемлемым. Тем не менее, такая ситуация свидетельствует о том, с какими проблемами можно столкнуться в такой структуре. Единственный случай, где фиксированные группы надежны, — это когда они соответствуют абсолютно постоянным вещам, например, дням недели. В частности, опасно применять этот метод для отражения существующей тенденции с возможными непредвиденными обстоятельствами в будущем. Например, весьма рискованно денормализовать места в самолете и предусмотреть наличие 1000 пассажиров на рейс. Конечно, можно побиться об заклад, что какую бы цифру мы ни использовали, такие гиганты, как "Боинг" и "Эйрбас Индастриз", когда-нибудь построят самолет, рассчитанный на большее число пассажиров!
Альтернатива данному способу денормализации — физическое размещение таблиц в общем кластере. Это позволяет хранить рядом строки логически отдельных таблиц. Кластеры мы опишем в главе 6.
Знаете ли Вы, что Программный сниппет (англ. snippet — фрагмент, отрывок) в практике программирования — небольшой фрагмент исходного кода или текста, пригодный для повторного использования. Сниппеты не являются заменой процедур, функций или других подобных понятий структурного программирования. Они обычно используются для более лёгкой читаемости кода функций, которые без их использования выглядят слишком перегруженными деталями, или для устранения повторения одного и того же общего участка кода. Интегрированные среды разработки (IDE) содержат встроенные средства для ввода конструкций языка. Например, в Microsoft Visual Studio, Borland Developer Studio, для этого необходимо ввести ключевое слово и нажать определённую клавишную комбинацию. В IDE Geany существует специальный файл snippets.conf (путь к файлу: /home/user/.config/geany) позволяющий создавать свои сниппеты. Другие программы, такие как Macromedia Dreamweaver и Zend Studio, позволяют использовать сниппеты в Веб-программировании.