Моделирование данных — это просто средство формального сбора данных, относящихся к бизнес-процессу данной организации. Моделирование является одним из главных на сегодняшний день приемов анализа, основанием, на котором строятся реляционные базы данных.
В главе 1 мы уже описывали, что представляет собой этап анализа в целом. Здесь же рассказывается о том, какие результаты мы можем получить на этом этапе и что они означают. Мы введем понятие семантических моделей данных и диаграмм "сущность-отношение ". Будут определены такие термины, как сущности, атрибуты, ключи, отношения, супертипы, подтипы и нормализация. Особое внимание мы уделим непонятным и сложным структурам данных, которые нельзя непосредственно реализовать в реляционной базе данных без участия проектировщика. Мы также рассмотрим, какой смысл могут привнести в результаты анализа диаграммы жизненных циклов сущностей и диаграммы потока данных.
Вы, возможно, спросите, почему в книге о проектировании мы посвящаем целую главу методам моделирования данных — методам, которые часто считаются частью анализа? Ответ состоит в том, что проектировщикам крайне необходимо полностью уяснить концепции, лежащие в основе модели данных, и конструкции, которые эту модель образуют. Еще важнее тот факт, что мы редко оставляем модель в том виде, который она имела в начале проектирования. Нам необходимо уметь определить, какие конструкции вызовут проблемы, если мы реализуем их как есть, и понять последствия изменения этих конструкций. Это нужно сделать на первых стадиях этапа проектирования, чтобы к концу проектирования мы могли создать физическую модель данных. Для этого достаточно лишь взять концепцию и превратить ее в практичную и работоспособную физическую базу данных.
Типы моделей
Нам необходимо рассмотреть два типа моделей. Этап анализа дает нам информационную модель, а этап проектирования — модель данных. Как мы увидим, в модели данных должны учитываться технические характеристики СУБД Oracle7, тогда как информационная модель не должна ничего предполагать о технологии, которая будет использована для реализации приложения. Задача информационной модели — уточнить реальную ситуацию, которую должно моделировать приложение. Другими словами, хорошую информационную модель можно использовать как входные данные для проектирования, независимо от того, о какой среде идет речь — сетевой, иерархической, объектно-ориентированной или реляционной. Вот перечень элементов, которые вы встретите в модели:
• диаграммы "сущность-отношение" (ДСС);
• диаграммы потока данных (ДПД);
• жизненные циклы сущностей (ЖЦС) или диаграммы изменения состояний (ДИС);
• определения сущностей;
• уникальные идентификаторы сущностей (УИД);
• определения атрибутов;
• отношения между сущностями.
В этом перечне содержатся характеристики данных. Нам также нужно будет сгенерировать иерархию функций и описания большинства функций через сущности и атрибуты, которые они используют, и бизнес-правила, которые они реализуют. (Вопросы функционального моделирования освещены в главе 15.)
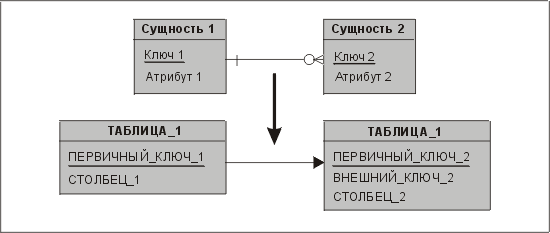
Реализовать этот перечень очень просто, скажете вы. Сущности становятся таблицами, УИДы — первичными ключами, атрибуты становятся столбцами, а отношения — внешними ключами; функции мы преобразуем в определения модулей — и можно идти гулять! Действительно, рис. 3.1 довольно прост и в общих чертах иллюстрирует то, что мы делаем при проектировании, но, к сожалению, он прост не настолько, насколько нам хотелось бы!
Рис. 3.1. Упрощенная схема процесса проектирования данных
Сначала следует проверить, действительно ли при анализе получено большинство элементов нашего перечня. Вероятно, вполне можно обойтись без диаграмм потока данных и жизненных циклов сущностей, но остальные элементы крайне важны.
Затем необходимо выполнить определенный контроль качества результатов, цель которого — обеспечить их полноту и правильность. Некоторые CASE-продукты содержат утилиты, способные выполнить некоторые рутинные задачи. Например, CASE-средствами можно проверить наличие УИД у каждой сущности, а также наличие хотя бы одной функции, создающей ее экземпляры (какая польза от сущности, которая никогда не "наполняется"?), и хотя бы одной функции, которая ссылается на нее (какой смысл создавать что-то, к чему никогда не будет произведен доступ?).
В этой главе мы опишем, какими должны быть основные результаты анализа, и изложим ряд общих принципов их проверки. Однако мы можем только лишь рассказать, как проверить формальную правильность результатов анализа, т.е. достоверны ли они сами по себе. Так, компилятор языка С сообщит вам о том, что та или иная программа является допустимой для С, но сказать, выдаст ли она правильные результаты, он не может. Аналогичным образом мы сможем рассказать вам лишь о том, как определить, является ли модель "сущность-отношение" допустимой, а не о том, как узнать, точно ли она отражает реальную ситуацию, для которой она построена. Вам придется оценить это самостоятельно, и для этого нужно будет читать документацию и задавать вопросы аналитикам и пользователям.
Возвращаясь к вопросу о формальной проверке, мы начнем с рассмотрения базовых объектов анализа: сущностей, их ключей, атрибутов и отношений между сущностями. Затем мы рассмотрим диаграммы "сущность-отношение", которые, как утверждают, являются самым мощным инструментом традиционных методов анализа.
Что такое моделирование данных?
Цель этого раздела — дать самое общее представление о семантических моделях данных. Мы введем такие понятия, как сущности, атрибуты, первичные ключи, отношения, супертипы и подтипы. (Не беспокойтесь, если эти термины вам ничего не говорят, — мы все объясним.) Если вы уже знакомы с этими понятиями, то можете пропустить или только бегло просмотреть данный раздел. (Правда, мы все же рекомендуем прочесть его, так как вы, возможно, не знакомы с обозначениями, которыми мы пользуемся.) Отметим, что этот раздел большей частью является теоретическим и специфику Oracle не отражает.
Сущности, атрибуты и ключи
Сущность — это особый класс реальных вещей или явлений, как то: автомобили, поезда и корабли, о которых что-то известно. Сущностью может быть и нечто нематериальное, например гудвилл, при том условии, что если он существует, то у нас есть о нем какие-нибудь сведения. Экземпляр сущности — это конкретный экземпляр класса сущности (объектно-ориентированный народ называет его реализацией). Например, Titanic ("Титаник") — экземпляр сущности Ship ("Корабль"). В информационном моделировании важно различать классы и экземпляры сущностей.
Свойство сущности, представляющее интерес, называется атрибутом или отношением. Каждая сущность должна иметь свойства, которые ее описывают; в противном случае она не может существовать. Некоторые атрибуты сущности не только описывают, но и уникальным образом идентифицируют ее. Это может быть отдельное свойство-атрибут или сочетание свойств. Их называют первичным ключом, а иногда уникальным идентификатором сущности. Если первичный ключ состоит более чем из одного свойства, его называют составным первичным ключом. Если существует несколько возможностей для выбора первичного ключа, то каждый вариант называют ключом-кандидатом или возможным ключом.
Как и в случае с сущностями, важно различать атрибуты и экземпляры атрибутов. Атрибутом автомобиля является Registration Number ("Регистрационный номер"), а экземпляром этого атрибута — 180 EOD. Сомнительно, чтобы этот атрибут можно было использовать в качестве первичного ключа: регистрационные номера автомобилей часто меняются, и, кроме того, номер может быть уникален только в стране регистрации. Chassis Serial Number ("Заводской номер шасси") — более удачный вариант, но если несколько машин разобрать, смещать их части и собрать автомобили заново, то что будет определять данный автомобиль? Данный пример иллюстрирует тот факт, что задача поиска возможных ключей не всегда так проста, как кажется на первый взгляд.
Отношения
Мы увидели, что в информационной модели сущности могут описываться через первичный ключ и другие неключевые атрибуты. Но у нас нет еще полной картины, потому что сущности рассматриваются отдельно друг от друга. Однако между ними существуют реальные отношения. Например, вы связаны со своим автомобилем как его владелец. Вы и, возможно, ваши супруга и дети, связаны с этим автомобилем как его водители. Если вы взяли ссуду для покупки автомобиля, то ваш банк может быть связан с ним как его финансист. И так далее...
Опять-таки следует различать отношение и конкретные его проявления. Если мы определим отношение между сущностями Cars ("Автомобили") и People ("Люди") и назовем его Is Owner Of ("Является владельцем..."), то одно из проявлений этого отношения будет связывать Batman с Batmobile (если Batmobile можно классифицировать как автомобиль, a Batman — как лицо).
Пытаясь реализовать эту информационную модель как схему базы данных Oracle, мы видим, что несмотря на наличие в Oracle столбцов таблиц, с помощью которых можно непосредственно реализовать атрибуты, единственный механизм, имеющийся здесь для реализации отношений, — это ограничение целостности по внешнему ключу. Поскольку реляционные базы данных не поддерживают "указатели" из одной записи на другую, то приходится хранить в одной записи уникальный идентификатор другой.
Однако таким образом можно реализовать только отношения типа "один к одному" (1:1) и "один ко многим" (1:n). (Что это такое, мы объясним ниже.) Если же нужно реализовать отношение "многие ко многим", необходимо добавить так называемую промежуточную сущность (о ней мы тоже расскажем позже). Главное здесь заключается в том, что если сторона "один" отношения имеет несколько возможных уникальных идентификаторов (первичных ключей-кандидатов), то для поддержки данного отношения можно использовать любой из них. Выбор ключа — это первый пример проектного решения, которое должно быть принято при переходе от информационной модели к модели данных, причем это решение может оказать существенное влияние на производительность.
Отношения могут связывать сущность саму с собой. Такие отношения называют рефлексивными. Типичный пример — отношение для сущности Employees, используемое для определения структуры подчиненности в организации. Рефлексивные отношения часто отражают иерархические отношения внутри структуры данных. Из-за способа изображения в моделях "сущность-отношение" рефлексивные отношения часто называют свиными ушами.
Подтипы и супертипы
Иногда атрибут имеет особое значение для сущности: он разделяет ее на типы, и сущность делится по этим категориям. Полученные в результате сущности называют подтипами, а исходная сущность становится супертипом: Сущность Car ("Автомобиль") можно разбить на категории Two Wheel Drive ("С приводом на два колеса") и Four Wheel Drive ("С приводом на четыре колеса"). Сама сущность Car может быть подтипом более широкой группы, называемой Motor Vehicles ("Автотранспорт"). Важно, чтобы все экземпляры сущности-супертипа относились только к одному из подтипов. Некоторые автомобили можно переключать с двухколесного привода на четырехколесный, поэтому, вероятно, нужно ввести новый подтип — Selectable Drive ("Переключаемый привод"). Чтобы проверить, нужен ли супертип, следует установить, как много одинаковых свойств имеют различные подтипы. Чем меньше они похожи друг на друга (продолжая при этом "пользоваться" одним первичным ключом), тем явственнее необходимость наличия супертипа.
Злоупотребление подтипами и супертипами — довольно типичная ошибка. Проще всего ее выявить путем поиска экземпляра сущности, который можно обоснованно включить более чем в один подтип. Поскольку так делать нельзя, то данный случай использования подтипов может считаться недопустимым.
Диаграммы "сущность-отношение"
Модель данных, представленная в виде перечня сущностей, атрибутов, отношений, супертипов и подтипов, может быть полной и правильной, но сложной для понимания и утомительной для изучения. Поэтому давайте познакомимся с диаграммой "сущность-отношение" (ER-диаграммой). ER-диаграмма обеспечивает графическое представление всех этих объектов, хотя часто атрибуты опускают или показывают только атрибуты первичного ключа. Обычно это делается для того, чтобы не загромождать диаграмму деталями.
Идея ER-диаграммы — это попытка концептуализации требований. Задача проектировщика — превратить концепцию в реальность. Во многих случаях информационная модель слишком сложна и содержит очень много объектов, поэтому создается несколько диаграмм, разбитых на категории по предмету. Например, могут существовать отдельные ER-диаграммы "Производство", "Составление счетов", "Заказы" и т.д. Если вы пользуетесь CASE-продуктом, который в состоянии построить всеохватывающую картину, сделайте это и повесьте полученный рисунок на стенку. Конечно, такая диаграмма, вероятно, будет напоминать карту автодорог Европы или топологию большой интегральной схемы, но она:
1. Служит ценным источником информации для определения последствий от принятия решения, влияющего на всю систему в целом.
2. Является полезным напоминанием о том, что каждый разрабатываемый участок — это не изолированная система, а подсистема сложного комплекса.
Изображение сущностей и атрибутов
Существует несколько способов представления ER-диаграммы, и в каждом из них объекты показываются по-разному. Мы будем пользоваться условными обозначениями, принятыми в Методике разработки информационных систем (IEM). Они несколько отличаются от используемых в CASE-средствах Oracle. По нашему методу, сущность изображается в виде прямоугольника с именем в верхней части (рис. 3.2).
Рис. 3.2. Сущность
В прямоугольнике могут быть перечислены атрибуты сущности, как показано на рис. 3.3. Обратите внимание, что атрибуты, принадлежащие уникальному идентификатору, или первичному ключу, подчеркиваются.
Рис. 3.3. Сущность с атрибутами и уникальным идентификатором
Изображение отношений
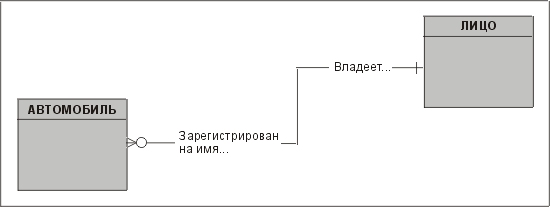
Отношение изображается линией между двумя сущностями, как показано на рис. 3.4. Представленное здесь отношение говорит о том, что каждый автомобиль должен быть зарегистрирован на определенное лицо и что на одно лицо может быть зарегистрирован один и более автомобилей.
Рис. 3.4. Две сущности и отношение между ними
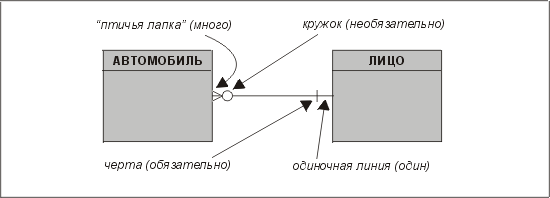
Здесь мы впервые встретились с ключевыми понятиями мощности и опциональности отношений. Символ "птичья лапка" (слева) означает "много", а прямая линия (справа) — "один". Отношение читается вдоль этой линии. Так, автомобиль может быть зарегистрирован только на одно лицо, но при этом на одно лицо может быть зарегистрировано много автомобилей.
Остальные символы на линии, а именно — кружок и вертикальная черта, обозначают опциональность отношения на каждой из сторон. Кружок обозначает необязательность, а черта — обязательность. Так, автомобиль должен иметь владельца, тогда как на имя одного лица может быть зарегистрирован автомобиль.
Чтобы точнее определить отношения, на диаграмме часто дают их названия. Отношение может иметь одно название, но, опять-таки для большей ясности, лучше назвать обе его стороны, как на рис. 3.5.
Рис. 3.5. Две связанные сущности с названиями сторон отношения
Изображение подтипов и супертипов
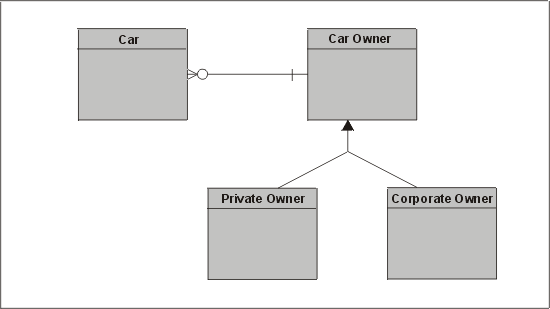
Верно ли, что каждый автомобиль принадлежит какому-нибудь лицу? А как насчет такси и служебных автомобилей? Нам нужно ввести сущность-супертип Car Owner ("Владелец автомобиля") и подтипы Private Owner ("Владелец — физическое лицо") и Corporate Owner ("Владелец — юридическое лицо") (рис. 3.6). Иногда это называют наследованием, так как сущности-подтипы наследуют характеристики супертипа. Атрибуты могут определяться на обоих уровнях, при этом общие атрибуты присваиваются супертипу.
Рис. 3.6. Изображение супертипа (Car Owner) с двумя подтипами
Изображение отношений "многие ко многим"
Некоторые отношения являются отношениями типа "многие ко многим". В таком отношении каждый экземпляр одной сущности связан более чем с одним экземпляром другой сущности. Например, страховка автомобиля может предусматривать управление несколькими водителями, а страховка водителя — управление несколькими автомобилями (это отношение показано на рис. 3.7).
Рис. 3.7. Отношение типа "многие ко многим "
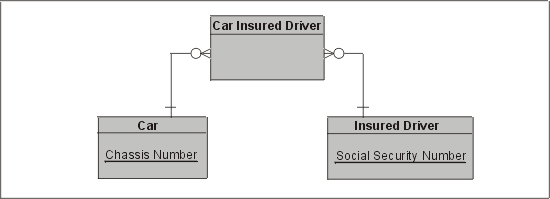
Отношения типа "многие ко многим" нельзя непосредственно реализовать в реляционной модели, поэтому для решения этой проблемы вводят промежуточную сущность, или сущность-пересечение (иногда ее называют связующей сущностью или синтетической сущностью). Первичный ключ этой новой сущности образуется из атрибутов связываемых ею кардинальных сущностей (этим термином обозначаются реальные сущности, которые она соединяет), и она не имеет атрибутов, а только отношения. Такое отношение называют зависимым. Оно изображено на рис. 3.8. Первичными ключами промежуточной сущности Car Insured Driver ("Застрахованный водитель автомобиля") являются Chassis Number ("Номер шасси"; унаследован от сущности Car, "Автомобиль") и Social Security Number ("Номер социальной страховки"; унаследован от сущности Insured Driver, "Застрахованный водитель").
Рис. 3.8. Связующая сущность (Car Insured Driver), позволяющая разрешить отношение "многие ко многим "
Некоторые аналитики считают, что они должны разрешить каждое отношение "многие ко многим" путем ввода связующих сущностей. Однако это необходимо делать на этапе проектирования. Концептуальная информационная модель, создаваемая на этапе анализа, должна представлять бизнес-сущности, и ее не следует загромождать структурами, введенными в целях реализации.
Изображение "свиных ушей"
Завершая описание диаграмм "сущность-отношение", мы рассмотрим так называемые рефлексивные отношения, которые иногда называют рекурсивными отношениями или "свиными ушами " (потому что изображение такого отношения на рисунке похоже на свиное ухо — если проявить немного воображения!). Пример "свиного уха" показан на рис. 3.9. Обратите внимание на то, что такое отношение всегда необязательно; в противном случае оно было бы по определению бесконечной иерархией. Это правило мы рассмотрим ниже, когда начнем изучать недопустимые и нереализуемые структуры данных.
Рис. 3.9. "Свиное ухо"
Контроль качества концептуальной информационной модели
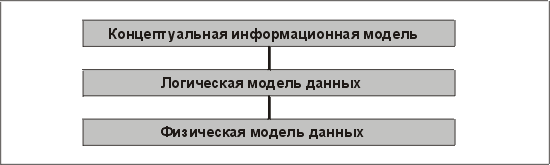
В процессе работы над проектом создаются три модели:
• концептуальная информационная модель;
• логическая модель данных;
• физическая модель данных.
Как мы говорили, одним из важнейших результатов этапа анализа является концептуальная информационная модель. Эта модель должна представлять сущности бизнеса или предприятия и ничего больше. Все, что так или иначе связано с реализацией и физической структурой, должно вводиться во время проектирования, когда создаются логическая и физическая модели данных. Очень важная цель этапа проектирования — проверка качества информационной модели, созданной в процессе анализа.
Концептуальная информационная модель не должна содержать связующих сущностей — отношения "многие ко многим" должны быть смоделированы как есть. Эта модель должна быть полностью нормализована. На ранних стадиях этапа проектирования концептуальная информационная модель преобразуется в логическую модель данных. В нее добавляются объекты, обеспечивающие решение физических и реализационных вопросов (например, сущность очереди на печать), разрешаются отношения типа "многие ко многим" и выполняется выборочная денормализация. На последующих стадиях проектирования из логической модели данных создается физическая модель. При этом разрешаются такие структуры, как дуги и супертипы, и определяются физические свойства и объекты, например индексы.
Во многих проектах работают только с двумя моделями: логической и физической. Вероятная причина этого заключается в том, что некоторые CASE-средства не поддерживают трехуровневую модель. Однако, по нашему мнению, следует создавать три уровня моделей (как показано на рис. 3.10).
Рис. 3.10. Три уровня моделей
Сейчас мы рассмотрим важный вопрос — нормализацию модели, а также дадим некоторые сведения о необычных и нереализуемых структурах в модели данных. А затем, проверяя соответствие модели как минимум третьей нормальной форме и обосновывая наличие неортодоксально выглядящих отношений, мы проведем контроль качества концептуальной информационной модели.
Нормализованная модель данных
Одно из ключевых требований к информационной модели, передаваемой из этапа анализа на этап проектирования, состоит в том, что она должна быть как минимум в третьей нормальной форме (3НФ). Если вы не уверены в том, что знаете, что такое 3НФ, читайте дальше. Перед приемом модели проектировщики должны проверить, соответствует ли она третьей нормальной форме. В последующем они могут избирательно денормализовать данные по причинам, которые почти всегда связаны с производительностью. Однако денормализация в основном является частью процесса проектирования — в концептуальной информационной модели она вообще не должна находить отражение.
Что же такое нормализация? Впервые этот процесс был определен д-ром Е.Ф. Коддом, когда он определил реляционную модель (в 1970 г.). Нормализация является основой для удаления из сущностей нежелательных функциональных зависимостей (ФЗ). ФЗ подразумевается, если мы можем определить значение атрибута, просто зная значение некоторого другого атрибута. Например, если мы знаем название страны, то можем определить название ее столицы. Следовательно, между страной и ее столицей имеется функциональная зависимость.
Существует еще один вариант зависимости, известный как многозначная зависимость (МЗЗ). Она означает, что если мы знаем значение одного атрибута, то можем определить набор значений другого атрибута. Например, зная название страны, можно определить названия всех ее аэропортов; следовательно, между страной и аэропортами существует многозначная зависимость. ФЗ и МЗЗ иногда обозначаются следующим образом:
ФЗ: А • В (А определяет В)
МЗЗ: А • • В (А определяет набор В)
Почему нормализованная информационная модель так важна в реляционном проектировании? Многочисленные испытания доказали, что процесс нормализации дает наилучший результат при моделировании мира с использованием двумерных объектов (таблиц) без установления слишком большого числа ограничений или искажения фактов (данных), для сбора которых мы пользуемся базой данных. С практической точки зрения, нормальные формы помогают проектировать базы данных, в которых нет ненужных избыточных данных и противоречий, которые могут повлечь за собой проблемы производительности или потерю информации при последующем выполнении операций вставки, обновления и удаления. Чтобы подытожить сказанное, отметим, что нормальные формы позволяют избежать искажения данных путем создания ложных данных или разрушения истинных.
Как же проверить, что информационная модель (представленная в виде определений сущностей и атрибутов) нормализована до требуемого уровня (например, до 3НФ)? Нам нужно исследовать отдельно каждую из нормальных форм. Чтобы проиллюстрировать этот процесс, мы, сократив до минимума теоретические выкладки, сначала рассмотрим примеры, противоречащие конкретной модели, а затем — правильное решение.
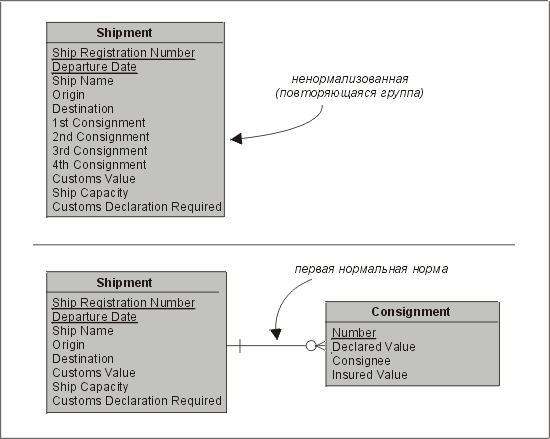
Первая нормальная форма (1НФ). Сущность находится в первой нормальной форме, если значения всех ее атрибутов атомарные. Все повторяющиеся группы должны быть удалены и помещены в новую (связанную) сущность. Пример приведен на рис. 3.11. В первом случае все атрибуты партии (грузополучатель, застрахованная стоимость и объявленная стоимость) повторятся четыре раза — для каждой партии груза. Обратите внимание, что из-за этого приходится вводить правило, согласно которому груз не может состоять более чем из четырех партий, потому что нам некуда отправить пятую и последующие партии. Поэтому если вы пользуетесь этой моделью, скажите своему начальству, чтобы оно ни в коем случае не покупало более крупные корабли!
Рис. 3.11. Первая нормальная форма
Если реализовать эту не соответствующую первой нормальной форме структуру данных, то возникнет множество проблем, например:
• если груз аннулируется и данная строка удаляется, то вместе с ней "тонут" все следы партий, которые должны были быть на борту;
• если в портовый склад прибывает новая партия, а мы еще не включили ее в состав груза, подлежащего отправке, то сведения о партии заносить некуда;
• существует уже упомянутое выше ограничение: превышение установленного числа экземпляров повторяющейся группы не допускается (в нашем случае это четыре партии).
Ясно, что мы столкнемся с серьезными проблемами, если наша модель не будет в первой нормальной форме! Чтобы нормализовать эту структуру в 1НФ, мы просто извлекаем данные о партиях (Consignment) из информации о грузе (Shipment) и помещаем их в отдельную структуру данных. Эта новая структура становится подчиненной структурой структуры Shipment, как показано на рис. 3.11.
Вторая нормальная форма (2НФ). Сущность находится во второй нормальной форме, если она находится в первой нормальной форме, а каждый ее неключевой атрибут функционально полно зависит ключа (или от каждого компонента первичного ключа — для сущностей с составными ключами, состоящими из двух и более атрибутов). Вторая нормальная форма требует, чтобы не было неключевых атрибутов, которые зависят только от части первичного ключа.
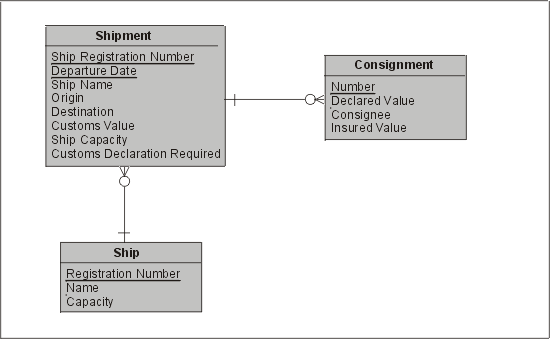
Продолжим рассматривать пример, приведенный на рис. 3.11. Ясно, что грузоподъемность корабля (Capacity) не зависит от даты убытия (Departure Date), а зависит лишь от самого корабля — за исключением крайне невероятного случая, когда каждый корабль после плавания переоборудуется.
На рис. 3.12 мы устраняем это и трансформируем нашу модель в 2НФ. Как и при преобразовании в 1НФ, это действие предполагает изъятие зависимых атрибутов из сущности Shipment и создание связанной подчиненной сущности (в данном случае называемой Ship).
Рис. 3.12. Вторая нормальная форма
Если реализовать модель, не соответствующую 2НФ, то возникнут следующие проблемы.
• Мы не сможем зарегистрировать название (Name) и грузоподъемность (Capacity) корабля (Ship), который еще не доставил ни одного груза, например, если он строится или заказан. Единственный путь решения этой проблемы — определить для него "фиктивный" груз (Shipment) — ужасный ляп!
• Аналогичным образом, если мы удалим запись Shipment после отправки груза, то потеряем все записи о кораблях, для которых нет груза (сейчас или в перспективе).
Если корабль все-таки переоборудуется и получает новую грузоподъемность, как зарегистрировать этот простой факт? Обновить все записи Shipment, включая те, которые были созданы до переоборудования? Но в этом случае окажется, что корабль ранее плавал недогруженным, тогда как на самом деле он был полон. Если же мы решим обновить только те записи Shipment, которые появляются после переоборудования, то тоже возникнут проблемы, так как корабль не эксплуатируется и, вероятно, грузы для него отсутствуют.
Существуют и многие другие "ямы", в которые мы можем попасть, если не обеспечим соответствие 2НФ. Ясно, что 2НФ — именно то, что нужно, но достаточно ли этого?
Третья нормальная форма (ЗНФ). Сущность находится в третьей нормальной форме, если она находится во второй нормальной форме и все ее неключевые атрибуты зависят только от первичного ключа. То есть при этом они не должны зависеть и от других неключевых атрибутов.
В наших примерах, приведенных на рис. 3.11 и 3.12, Customs Declaration Required ("Необходимость таможенной декларации") является, по сути, свойством атрибутов Origin ("Пункт отправления") и Destination ("Пункт назначения"). Если корабль плавает между двумя портами в одной стране или между двумя странами существует режим свободной торговли, то таможенной очистке груз не подлежит. Таким образом, пример на рис. 3.12 явно нарушает 3НФ, так что давайте исправим его.
Решение показано на рис. 3.13. Продолжая руководствоваться принципом "разделяй и властвуй", мы переносим нарушающие форму атрибуты в новую дочернюю сущность (в нашем примере она называется Route, "Маршрут").
Рис. 3.13. Третья нормальная форма
Преобразование в 3НФ. Чтобы преобразовать информационную модель в третью нормальную форму, нужно просто руководствоваться здравым смыслом, призвать на помощь интуицию и помнить старую пословицу: "Все атрибуты сущности должны зависеть от ключа, только от ключа и ни от чего, кроме ключа (и да поможет мне Кодд)" * .
Некоторые опытные люди с подготовкой в области нереляционных систем баз данных (например, иерархических и сетевых) смотрят на процесс нормализации с определенной долей скептицизма. Они считают, что мы создаем при этом большое количество таблиц. (Действительно, переходя от рис. 3.11 к рис. 3.13, мы получили вместо одной сущности четыре.) Эти критики также трактуют низкую производительность периода выполнения как результат соединения таблиц с целью перегруппирования данных в первоначальную форму.
С одной точки зрения (но только с одной), они правы: если у нас есть уникальный ключ, по которому можно выбрать отдельную ненормализованную запись, то размещение всех данных в общем котле даст нам самое короткое время выборки. С другой стороны, Oracle7 не так уж медленно выполняет соединение четырех таблиц, когда это нужно. Однако даже при этом несколько утрачивается суть: ведь большинство запросов, которые придется написать по нормализованным структурам данных, не будут пытаться полностью восстановить исходную плоскую модель, с которой мы начали на рис. 3.11, и вначале у них не будет столь удобного уникального идентификатора. Многие будут соединять четыре нормализованные таблицы с помощью ключей Origin ("Пункт отправления") и Departure Date ("Дата убытия"). А такие нерегламентированные запросы исключительно дороги по сравнению с ненормализованными структурами, не говоря уже о всех остальных недостатках, которые мы уже обсудили.
Третья нормальная форма не является лучшим выходом для всех приложений. В частности, это не самый удачный метод представления данных для проектирования хранилища данных. (Подробнее об этом в главе 13.)
Что за третьей нормальной формой? Большинство тех, кто имеют дело с реляционными системами, конечно же знают о 3НФ. Однако, дойдя до третьей нормальной формы, не обязательно нужно остановиться на достигнутом. За третьей нормальной формой следуют:
• нормальная форма Бойса-Кодда (НФБК);
• четвертная нормальная форма (4НФ);
• пятая нормальная форма (5НФ).
Здесь мы лишь кратко опишем эти формы, а более подробную информацию вы можете почерпнуть из прекрасной книги Криса Дейта. **
Нормальная форма Бойса-Кодда — это фактически несколько улучшенный вариант 3НФ. Аналитикам и программистам нет необходимости использовать четвертую и пятую нормальные формы, а вот проектировщики должны знать, какие проблемы эти формы решают. Эти проблемы — неизбежный результат применения составных первичных ключей, в которых лишь часть ключа сама по себе содержит информацию. Любая структура, находящаяся в ЗНФ и не имеющая составных ключей, должна также находиться в 5НФ.
Нормальная форма Бойса-Кодда (НФБК). НФБК устанавливает дополнительное правило: все транзитивные зависимости должны быть удалены. Таблица R находится в нормальной форме Бойса-Кодда, если для каждой нетривиальной ФЗХ -> AX — суперключ. Что это означает на практике?
Продолжая нашу мореходную тему, предположим, что экипаж судна разделен на группы, отвечающие за разные виды работ. Член экипажа может входить в несколько групп, но в каждую группу входит только один руководитель. Группа, в свою очередь, может иметь несколько руководителей. Кроме того, член экипажа может руководить только одной группой. Это очень сложный сценарий. Таблица, представленная ниже, находится в третьей нормальной форме, но противоречит НФБК.
Таблица 3.1. Распределение экипажа: таблица в ЗНФ, противоречащая НФБК
Член экипажа
Название группы
Фамилия руководителя
Джоуор
Наблюдение
Уэбб
Джоуор
Питание
Кауи
Уэллс
Наблюдение
Реймуол
Купер
Наблюдение
Уэбб
Дерхэм
Питание
Хардисти
Дерхэм
Обслуживание
Каулард
Поуд
Обслуживание
Каулард
Проблема здесь заключается в том, что хотя эта таблица дана в третьей нормальной форме, все равно имеет место аномалия удаления. Если Уэллса убрать из группы наблюдения, то мы потеряем дополнительный элемент несвязанного знания, а именно информацию о том, что Реймуол — руководитель группы наблюдения. Когда в группу наблюдения будет назначен новый член экипажа и мы возьмем список руководителей групп, в подчинение которым можно его назначить, Реймуола в этом списке не будет.
В отличие от предыдущих нормальных форм, где мы могли разбить таблицу без создания избыточности, здесь мы вынуждены хранить некоторую избыточную информацию, иначе эту головоломку не решить. Исходная таблица распределения экипажа остается как есть, но дополняется таблицей руководителей групп (табл. 3.2).
Таблица 3.2. Руководители групп: новая таблица, введенная для обеспечения соответствия НФБК
Название группы
Фамилия руководителя
Наблюдение
Уэбб
Питание
Кауи
Наблюдение
Реймуол
Питание
Хардисти
Обслуживание
Каулард
Теперь, если Уэллса сбросят в море, мы все равно узнаем, что Реймуол руководит группой наблюдения (несмотря на то, что число членов данной группы будет равно нулю). Нового члена группы теперь можно назначить в подчинение Реймуолу.
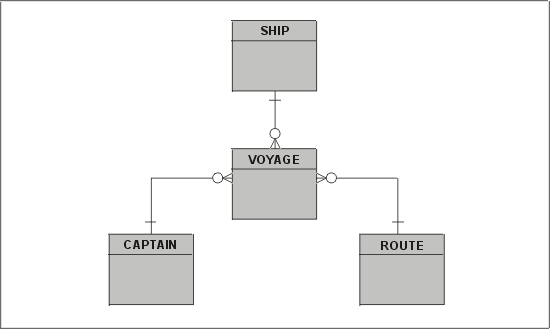
Четвертая нормальная форма (4НФ). Эта форма оперирует многозначными зависимостями (МЗЗ). Она решает проблему, вызванную наличием в таблице более одной МЗЗ. Давайте рассмотрим таблицу, содержащую сведения о кораблях, совершаемых ими рейсах и капитанах, которые управляют кораблями в этих рейсах. В качестве иллюстрации послужит ER-диаграмма, показанная на рис. 3.14.
Рис. 3.14. Пример, иллюстрирующий нарушение 4НФ
Что здесь неправильно? В сущности Voyage ("Рейс") регистрируется слишком много подробностей. Полученная из нее таблица показана ниже (табл. 3.3). Здесь нет ФЗ, поэтому она соответствует НФБК. Тем не менее, аномалия удаления сохранилась. Если Эйрен уволиться и мы уничтожим записи о нем, то потеряем все сведения о том, что корабль "Флейта" плавает между Брюгге и Бостоном. Более того, если удалить новый рейс, то может понадобиться ввести в табл. 3.3 не одну, а несколько строк.
Таблица 3.3. Пример таблицы данных в 4НФ
Ship
Captain
Voyage
"Темная лошадка"
Голл
Саутгемптон-Нью-Йорк
"Темная лошадка"
Эйрен
Саутгемптон- Н ью-Йорк
"Темная лошадка"
Фальконер
Саутгемптон-Нью-Йорк
"Темная лошадка"
Стоун
Саутгемптон-Нью-Йорк
"Темная лошадка"
Ла Спина
Портсмут-Гавр
"Темная лошадка"
Стоун
Портсмут-Гавр
"Флейта"
Эйрен
Брюгге-Бостон
"Флейта"
Данфорт
Нью-Хейвен-Дьепп
"Флейта"
Фальконер
Нью-Хейвен-Дьепп
Если вы еще не догадались, поясним, что эта проблема решается путем разбиения данной таблицы на две: в одной будут столбцы Ship и Voyage, a во второй — Captain и Voyage.
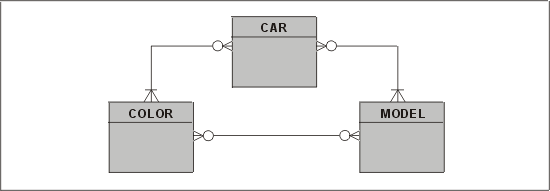
Пятая нормальная форма (5НФ). Пятую нормальную форму иногда называют нормальной формой с проецированием, соединений (НФПС). Она может использоваться при разрешении трех и более сущностей, которые связаны друг с другом отношениями "многие ко многим". В некоторых случаях разрешение этих отношений при помощи связующей сущности может привести к получению дефектной модели, в которой могут появиться несуществующие отношения (известные как аномалия проецирования соединений). Эта проблема может возникнуть, если CASE-инструмент попытается разрешить за вас отношения "многие ко многим", поскольку большинство автоматизированных методов здесь не выявило бы никаких зависимостей. Пример показан на рис. 3.15.
Рис. 3.15. Трехсторонняя структура "многие ко многим "
Каждый автомобиль имеет определенный цвет кузова, и каждый автомобиль имеет определенную модель. Некоторые цвета характерны только для определенных моделей (например, цвет "металлик" встречается только моделей более высокого класса).
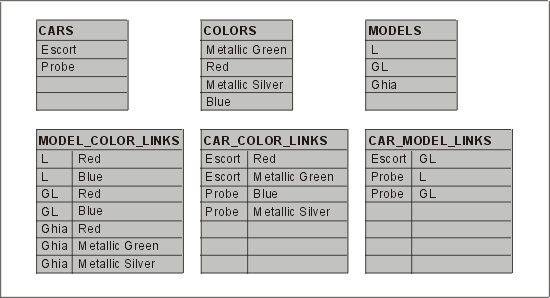
Если мы разобьем эту проблему на составляющие и будем рассматривать ее как три изолированных отношения "многие ко многим", то ее нужно будет решать путем ввода трех связующих сущностей, которые мы назовем CAR COLOR LINK, CAR MODEL LINK и COLOR MODEL LINK. Полученные в результате таблицы базы данных Oracle с примерными данными представлены на рис. 3.16.
Рис. 3.16. Определения таблиц, которые нарушают 5НФ
Предположим, что к нам заходит клиентка и хочет заказать автомобиль. Она предпочитает голубой Ghia, причем модель роли не играет. Поэтому мы выдаем запрос к базе данных, чтобы посмотреть, из каких автомобилей она может выбрать. Ниже приведен SQL-запрос к базе данных Oracle7, используемый для решения этой задачи:
SELECT саr.name
FROM cars car
, car_color_links ccl
, car_model_links cml
WHERE car.name = ccl.name
AND car.name = cml.name
AND ccl.color = 'Blue'
AND cml.model = 'Ghia'
Данный запрос возвращает следующее:
Name
Escort
Probe
Это удивительный результат, так как из таблицы MODEL_COLOR_LINKS мы видим, что моделей Ghia голубого цвета нет. Вывод: возвращена ложная запись. Эта ложная строка — аномалия проецирования соединений и пример нарушения пятой нормальной формы.
К счастью, правильное решение найти очень просто. Нужно ввести одну промежуточную сущность, связывающую остальные три, а именно CAR_COLOR_MODEL_LINK. Правильная форма реализации этой таблицы представлена в табл. 3.4.
Необходимо отметить, что информационные модели, в которых имеются нарушения четвертой и пятой нормальной форм, встречаются относительно редко.
Недопустимые и необычные структуры в информационной модели
Изучая диаграммы "сущность-отношение", вы наверняка заметили, что подавляющее большинство отношений — это отношения "один ко многим", причем большей частью с необязательной стороной "много" и обязательной стороной "один". Отношение такого типа вы видите на рис. 3.17. Его следует читать так: "Каждый отдел может состоять из одного или более служащих, и каждый служащий должен работать только в одном отделе".
Рис. 3.17. Самая распространенная форма отношений
Отношения другого типа стоит рассмотреть более подробно. В частности, ниже описаны отношения, которые либо недопустимы, либо нелогичны. Некоторые из них не являются недопустимыми, однако они необычны и встречаются редко. Одни из них нужно только разъяснить, а другие для реализации в виде таблиц Oracle требуют нетривиальных проектных решений.
"Свиные уши", имеющие сторону с обязательным участием
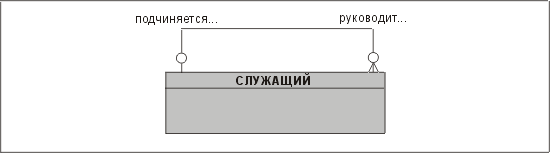
Как мы уже отмечали, "свиное ухо" — это отношение сущности с другим экземпляром такой же сущности. Если какая-либо из сторон отношения обязательна, то в результате получается бесконечная иерархия. Например, отношение, изображенное на рис. 3.18, подразумевает, что у служащего должен быть только один начальник. Если это верно, то кто начальник президента или иного высшего должностного лица компании? В равной степени недопустимо делать другую сторону отношения обязательной — в этом случае каждый должен кем-то руководить, что порождает проблемы в нижней части иерархии, где находится большинство из нас! Таким образом, "свиные уши", имеющие сторону с обязательным участием, всегда некорректны.
Рис. 3.18. "Свиное ухо ", имеющее сторону с обязательным участием
Неисключающие подтипы и невключающие cупертипы
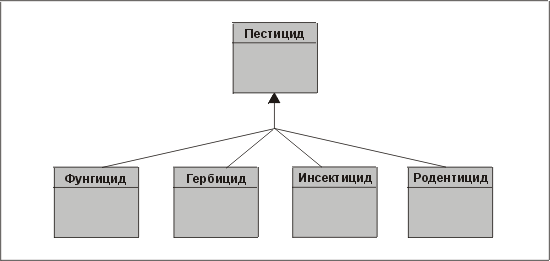
Как мы уже говорили, некоторые сущности при анализе разбиваются на подтипы. В этом случае довольно просто спутать подтипы с членством в классах. Подтипами называются атомарные сущности более сложной сущности (называемой супертипом). Подтипы должны быть разделены между собой и в совокупности образовывать супертип. Другими словами, подтипы должны быть взаимоисключающими, и не может существовать экземпляр подтипа, не принадлежащий супертипу. На рис. 3.19 приведен пример, взятый из агрохимической промышленности, который нарушает эти правила.
Рuc. 3.19. Неправильно созданные подтипы и супертип
Верно, что подавляющее большинство пестицидов можно отнести к следующим классам: фунгициды (для борьбы с заболеваниями растений), гербициды (для борьбы с сорняками), инсектициды (для уничтожения насекомых) или родентициды (для убиения несчастных грызунов). Однако существуют пестициды, имеющие двойное назначение, они, например, служат и фунгицидами, и гербицидами. Далее, некоторые пестициды не являются ни фунгицидами, ни гербицидами, ни инсектицидами, ни родентицидами — это, например, регуляторы роста растений.
Таким образом, приведенная модель некорректна, потому что она не соответствует ни одному из установленных нами правил: подтипы здесь не являются взаимоисключающими, а супертип — не включающий.
Ясно, что для выполнения проверки необходимы определенные знания в данной области. Если вас терзают сомнения, обратитесь к аналитику или пользователю (желательно получить независимые мнения из обоих лагерей). Задайте им соответствующие вопросы, например: "Есть ли сейчас или может на рынке в будущем появиться пестицид для борьбы с двумя и более категориями вредителей?" или "Предлагаются ли на рынке разные продукты в одинаковой упаковке?"
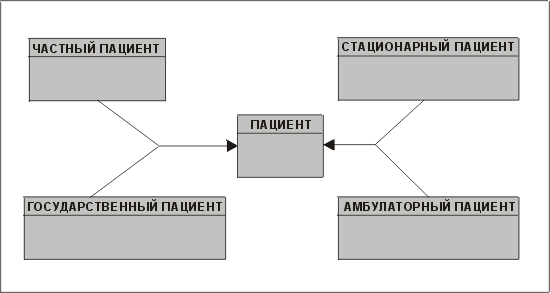
Остерегайтесь относить сущность более чем к одной несвязанной категории. Давайте рассмотрим модель, описывающую пациентов в больнице (рис. 3.20). Мы можем разделить их на стационарных и амбулаторных (медицинский персонал особенно заинтересован в таком делении!). С другой стороны, финансовый отдел делит пациентов поиному: на частных (оплачивающих свое лечение) и государственных (которых лечат бесплатно).
Рис. 3.20. Супертип с подтипами двух категорий
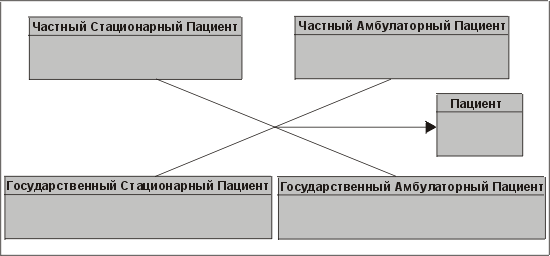
Такое разделение пациентов на две группы вызывает ряд проблем, если попытаться реализовать одну или обе эти категории в виде отдельных таблиц. Попытка скомбинировать несвязанные категории, как на рис. 3.21, лишь усугубит проблемы, опять-таки особенно при попытке реализовать эти сущности в виде отдельных таблиц. Скажем только, что в конце концов вам, скорее всего, придется решить, какая из категорий менее важна, и сделать ее атрибутом. Итак, кто победит — медицинский персонал или финансовый отдел? Давайте начнем сражение!
Рис. 3.21. Комбинирование несвязанных подтипов — город кошмаров
Разрешение подтипа
В предыдущем разделе мы говорили о существовании различных вариантов реализации подтипов. По сути дела, задача сводится к выбору: объединить подтипы в одну таблицу или сделать их отдельными таблицами в базе данных Oracle? Чтобы выбор стал очевидным, выполните следующие операции:
• установите, имеют ли все подтипы одинаковый первичный ключ;
• определите количества общих и индивидуальных атрибутов;
• определите количество отношений с подтипами и количество отношений с супертипом.
Давайте возьмем случай с пациентами из рис. 3.21 и рассмотрим типы "стационарный пациент" и "амбулаторный пациент". Весьма вероятно, что большинство атрибутов пациента будут регистрироваться независимо от того, какой он — стационарный или амбулаторный. Могут иметь место отношения, которые касаются только стационарных пациентов, например, место в палате. Предположим, что нашей задачей является создание одной таблицы. Что же нужно для этого сделать?
Мы добавляем в таблицу Patients ("Пациенты") столбец Patient Type ("Тип пациента") для указания того, какой это пациент — стационарный или амбулаторный. Чтобы в этом столбце стояло только одно из этих двух значений, мы используем ограничение. Для всех обязательных столбцов и внешних ключей, относящихся к одному из данных подтипов, установим следующие ограничения: они не должны быть неопределенными (NOT NULL). Кроме того, мы должны ввести ограничения, обеспечивающие, Чтобы столбцы, относящиеся к определенному подтипу, для других подтипов всегда были неопределенными (NULL). Наконец, можно создать представления, которые покажут, как будут выглядеть наши таблицы, если бы мы избрали вариант с раздельными таблицами. Эти представления можно использовать в приложениях, которые работают только с одним из подтипов.
К сведению
Обратите внимание на ограничение WITH CHECK OPTION. Оно не дает использовать представление для вставки в таблицу строк, которые не удовлетворяют предложению WHERE запроса, использованного при создании представления. Следовательно, данное определение представления позволяет создавать только допустимые подтипы.
Все это создается следующим скриптом:
CREATE TABLE mc_patients
(id NUMBER(9) NOT NULL
,ptype VARCHAR2(10) NOT NULL
CONSTRAINT mc_pat_ccl CHECK (ptype IN ('INPATIENT', 'OUTPATIENT'))
,surname VARCHAR2(30) NOT NULL
,forename VARCHAR2(30) NOT NULL
,date_of_birth DATE
,f_bal_bed NUMBER(9)
,CONSTRAINT mc_pat_pk PRIMARY KEY (id)
,CONSTRAINT mc_pat_bal_fk FOREIGN KEY
REFERENCES mc_bed_allocations
,CONSTRAINT mc_pat_cc2 CHECK (ptype = 'INPATIENT' OR f_bal_bed IS NULL));
CREATE VIEW mc_outpatients_v
AS SELECT pat.id
,pat.surname
,pat.forename
,date of_birth
FROM mc_patients pat
WHERE pat.ptype = 'OUTPATIENT'
WITH CHECK OPTION CONSTRAINT mc_opt_ccl;
CREATE VIEW mc_inpatients_v ...
Отношении "многие ко многим"
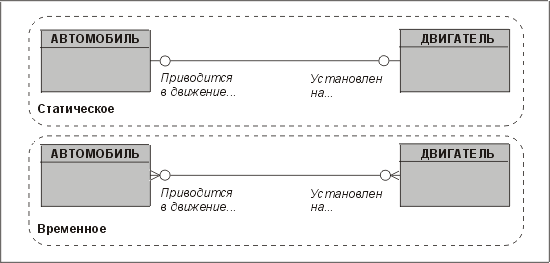
Отношения "многие ко многим" в концептуальной информационной модели должны оставаться в неприкосновенности, и в логической модели мы должны обработать и разрешить каждое из них. Сначала нужно проверить, действительно ли данное отношение является отношением "многие ко многим". Иногда такое отношение используется для представления временного отношения. Этот случай иллюстрируется рис. 3.22. Между автомобилем и его двигателем существует отношение "один к одному". Однако двигатель автомобиля может быть заменен, а старый двигатель отремонтирован и установлен на другой автомобиль. Конечно, ни одну из этих ситуаций нельзя назвать правильной или неправильной — все зависит от того, должна ли система регистрировать архивные данные.
Рис. 3.22. Статическое и временное представление одной и той же конструкции
Поскольку отношение "многие ко многим" нельзя непосредственно реализовать в реляционной базе данных, оно разрешается с помощью новой "сущности", размещаемой посередине. Так, пример на рис. 3.23 разрешается путем создания новой сущности, показанной на рис. 3.24. Эту новую сущность называют по-разному — связующей, ассоциативной или сущностью-пересечением. Если вам не приходит в голову никакое выразительное имя для этой сущности, можете назвать ее Entity1 Entity2 Link ("Связь Сущность1 - Сущность2") или как-нибудь вроде этого. На некоторой стадии вы, возможно, обнаружите, что связующая сущность имеет собственные атрибуты. В нашем примере новая сущность JOB TASK LINK может иметь важный атрибут — Task Order ("Порядок задач"), определяющий порядок выполнения задачи (TASK) в пределах задания (JOB). Если вы найдете новые атрибуты, обратитесь к аналитикам — зачем вам делать их работу? Если то, что вы обнаружили, является важным, то, как правило, это означает, что свою работу они сделали не до конца.
Рис. 3.23. Отношение "многие ко многим" между заданиями и задачами
Рис. 3.24. Разрешение отношения "многие ко многим "с помощью связующей сущности
Первичный ключ связующей сущности почти всегда состоит из комбинации внешних ключей сущностей, которые она связывает (такие сущности часто называют кардинальными). Когда мы приступаем к реализации этой сущности в виде таблицы, порядок, в котором определены компоненты ключа, имеет большое значение. Oracle может использовать индекс лишь в том случае, если известна его лидирующая порция (т.е. первый компонент). Если мы всегда перемещаемся по базе данных от задания к задаче (как это, скорее всего, и происходит в данном случае), то важно, чтобы первичный ключ сущности JOB TASK LINK был определен как (Job Name, Task Name) ("Имя задания", "Имя задачи"). Если по отношению можно проходить в обоих направлениях (от задания к задаче и наоборот), то необходимо определить дополнительный индекс по имени задачи (Task Name) или имени задачи и имени задания (Task Name, Job Name). Дополнительная информация по этому вопросу и об индексах вообще предлагается в главе 6.
Связующая сущность не живет своей жизнью. По сути, если удалить одну из сторон, то смысл существования этой сущности пропадет. Вам нужно определить правила, например такие: если пользователь попытается удалить сущность TASK, то он не сможет этого сделать, если у этой сущности есть одна или несколько сущностей JOB TASK LINK или если это удаление каскадно распространяется на все JOB TASK LINK. Это, скорее всего, не техническое, а бизнес-решение (спросите аналитика или, еще лучше, квалифицированного пользователя).
Такие же факторы действуют при удалении задания. Если у вас есть решение, то вы должны определить, как его реализовать. Фактически, оба варианта в данном случае лучше всего реализуются ограничениями по внешним ключам, предлагаемыми в Oracle. Простое включение ограничения по внешнему ключу будет препятствовать удалению, если существуют дочерние элементы; добавление части предложения CASCADE DELETE приводит к удалению дочерних элементов вместе с их родителем.
Отношения "один к одному "
На рис. 3.25 представлены два варианта отношения типа "один к одному". Первое отношение, между А и В, по сути, является недопустимой конструкцией. Видно, что А и В по определению являются единой сущностью (она образовывается путем слияния двух наборов атрибутов). Если у А и В разные первичные ключи, то мы должны выбрать один из них в качестве первичного ключа объединенной сущности. Второй ключ станет при этом ключом-кандидатом (поддерживаемым ограничением UNIQUE на столбце (столбцах) этой таблице). Достаточных оснований для того, чтобы эти две сущности были отдельными, нет. Конструкции такого типа иногда встречаются при разработке моделей для объединения двух систем, в которых одна сущность называется по-разному. Поскольку здесь мы говорим о логической, а не о физической модели, эти сущности необходимо объединить и присвоить им общее имя.
Рис. 3.25. Два примера отношений "один к одному" (унарных)
Отношение между С и D на рис. 3.25 является допустимым. Примером такого отношения является отношение между персональным компьютером и мышью. ПК может работать как с мышью, так и без нее, тогда как мышь может работать только с компьютером. Здесь нужно принять проектное решение: будем ли мы реализовывать сущности ПК и мышь в виде отдельных таблиц или же объединим их? Некоторые достоинства (+) и недостатки (-) обоих вариантов приведены в табл. 3.5.
Таблица 3.5. Характеристики одно- и двухтабличного решения задачи с отношением "один к одному "
Однотабличное решение
Двухтабличное решение
Обслуживающие программы
(+) Для обслуживания персональных компьютеров и мыши нужно написать только одну обслуживающую программу
(-) Нужно написать две обслуживающие программы
Целостность Данных
(-) Нельзя использовать ограничения NOT NULL, для того чтобы сделать значения относящихся к мыши столбцов обязательными
(-) Нужно написать две обслуживающие программы
Изолированные сущности
(-) Если мы сделаем мышь расширением ПК, то как вести информацию о мыши, не подключенной в данный момент к ПК?
(+) Объекты могут существовать в изоляции
Изменениесвязей
(-) Если взять мышь с одного ПК и подключить к другому, то необходимые обновления будут сложными
(+) Для перемещения мыши нужно просто обновить два внешних ключа
При использовании однотабличного решения атрибуты мыши становятся атрибутами ПК. Все атрибуты мыши, которые были обязательными, становятся необязательными атрибутами новой сущности "ПК-мышь", чтобы учесть случай, когда ПК не имеет мыши. Можно реализовать эти правила через триггеры и дополнительный атрибут, указывающий, работает ли ПК в данный момент с мышью. Впрочем, это несколько громоздкое решение.
Отношение, обязательное на обеих сторонах (рис. 3.26), довольно нетрадиционно, но, конечно, допустимо. Типичный пример — заказ и строка заказа. Строка заказа не может существовать сама по себе, без заказа, в который она помещается. Заказ без строки заказа — вообще не заказ как таковой, мы будем напрасно тратить время, пытаясь доставить пустое место или оформляя документы для него!
Рис. 3.26. Два примера отношений, обязательных на обеих сторонах
Проблема здесь состоит в наличии ситуации "курица и яйцо". Заказ нельзя создать без строки заказа, тогда как для строки заказа должен существовать заказ, в который она будет помещена. Что же создавать в первую очередь? На первый взгляд, кажется, что ответ должен быть следующим: порядок создания не имеет значения, если обе эти сущности создаются в одной транзакции, а при удалении строки выполняется проверка, определяющая, пуст ли теперь заказ; если пуст, то заказ тоже удаляется. Но не всегда все происходит так, как кажется...
Давайте обсудим эту ситуацию с точки зрения проектирования таблиц базы данных Oracle. У нас будет внешний ключ из таблицы ORDER_LINES к таблице ORDERS. Значения соответствующих столбцов можно сделать обязательными с помощью ограничения NOT NULL. Благодаря этому все строки таблицы ORDER_LINES будут снабжены номером заказа. Как ввести правило, согласно которому каждому заказу из таблицы ORDERS должна соответствовать строка в таблице ORDER_LINES? На первый взгляд очевидно, что следует использовать триггеры. Необходимо создать триггер уровня строки на таблице ORDERS, запускающийся перед вставкой строки и проверяющий наличие связанной строки в таблице ORDER_LINE. Если такой строки нет, операция вставки выполняться не будет. Триггер уровня строки на таблице ORDER_LINES, запускающийся после удаления строки, должен проверять наличие в ORDER_LINES других строк, относящихся к тому же заказу. Если таких строк нет, то заказ можно удалить из таблицы ORDERS. Однако, к сожалению, ни один из этих триггеров работать не будет.
К сведению
При вставке строк у нас все равно остается проблема "курицы и яйца". Если первым создается заказ, то этот триггер не найдет в таблице ORDER_LINES ни одной строки, относящейся к этому заказу, так как вставка в эту таблицу еще не проводилась. Если первыми вставляются строки заказа, то наше ограничение по внешнему ключу не сработает, так как родительский элемент еще не вставлен.
Триггер для удаления не сработает, потому что мы пытаемся выбрать элемент в той таблице, из которой была инициирована операция удаления (ORDER_LINES). Поскольку эта таблица рассматривается как "мутирующая" во время работы триггеров уровня строки, то возникнет ошибка. Для проблемы с удалением есть решение. Мы используем триггер уровня строки, чтобы просто запомнить событие (вставку или удаление) в глобальной переменной пакета PL/SQL и возлагаем проверку на триггер AFTER INSERT/DELETE уровня строки. (Этот прием подробно описан в приложении Б.)
Проблему со вставкой решить гораздо труднее. Здесь существует два пути. Можно поместить проверку в приложение (приложения), которые создают заказы и строки, и гарантировать таким образом, что пустые заказы в таблице ORDERS не создаются. Можно попытаться достичь компромисса с пользователем или аналитиком. Если они разрешат создание пустого заказа, то мы напишем подпрограмму, которая каждый вечер в пакетном режиме будет удалять пустые заказы. Если запускать эту подпрограмму до всех других критичных программ обработки и подготовки отчетов, то заказы-призраки никакого вреда не принесут. Впрочем, ни одно из этих решений нельзя назвать идеальным.
Облава на потерянную дугу
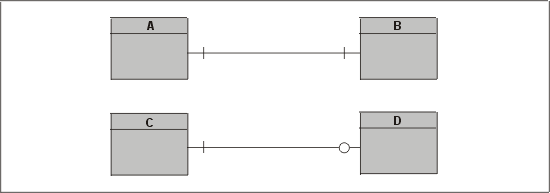
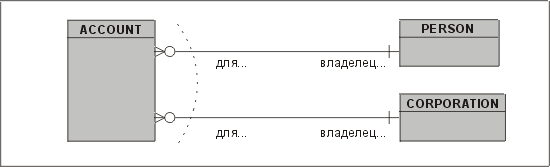
Если сущность имеет набор взаимоисключающих отношений с другими сущностями, то говорят, что эти отношения находятся в дуге. Рассмотрим пример из банковского приложения, проиллюстрированный на рис. 3.27. Эту Диаграмму следует читать так: "Каждый счет должен быть оформлен или на одно и только одно физическое лицо, или на одно и только одно юридическое лицо".
Рис. 3.27. Дуга
Разрешение дуг
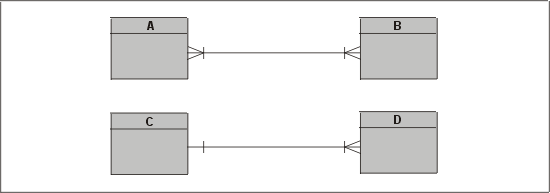
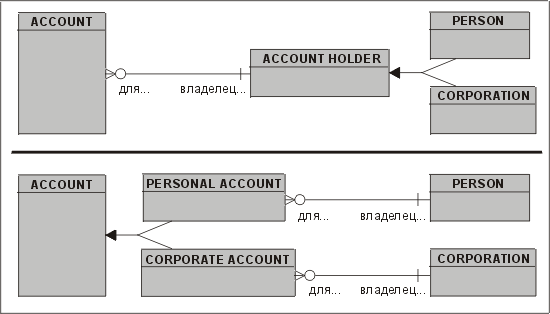
Во многих случаях дуги можно трансформировать в конструкции подтип-супертип. На рис. 3.28 показаны два варианта такой трансформации.
Рис. 3.28. Преобразование дуги в конструкцию подтип-супертип
Факт, что дуги могут быть разрешены путем применения супертипа и подтипов, указывает на существование нескольких вариантов решения. В этом разделе мы рассмотрим некоторые из них.
К сведению
Способ реализации дуги имеет значение лишь в том случае, если вы намереваетесь перемещаться по отношению к ней наружу. В нашем примере это значит, что мы собираемся идти от счета к юридическому или физическому лицу (либо к обоим этим лицам). В противном случае приведенные в этом разделе аргументы никакого смысла не имеют!
1-й метод. Если решение с применением супертипов не подходит, дуги можно разрешить при помощи одного или двух внешних ключей в таблице Accounts. Давайте рассмотрим два варианта этого решения, проанализировав приведенные ниже таблицы.
Таблица 3.6. Реализация дуги при помощи пары внешних ключей и одного (родового)внешнего ключа
решение 1а)
Accounts (Счета)
№
Credit Limit (Предельный размер кредита)
Person (Физическое лицо)
Corporation (Юридическое лицо)
01623907 01694295
100.00
150.00
195
297
Решение 1б)
Accounts (Счета)
№
Credit Limit (Предельный размер кредита)
Holder (Владелец)
Holder Type (Тип владельца)
01623907
01694295
100.00
150.00
195
297
Р
С
Решение 1б) часто называют родовой дугой. Здесь имеется один внешний ключ и столбец (в данном случае Holder Type), который показывает, на какую таблицу ссылается этот внешний ключ. В Oracle7 обычно более предпочтительным является решение 1а), поскольку для реализации этих отношений можно использовать ограничения по внешнему ключу. В решении 16) столбец Holder может содержать ссылку либо на таблицу физических лиц (PERSONS), либо на таблицу юридических лиц (CORPORATIONS), а определить условные ограничения по внешнему ключу невозможно. Поэтому для реализации решения 16) потребовалось бы создать триггеры. Они должны гарантировать, что если при вставке (а возможно, и при обновлении) столбец Holder Type содержит значение Р, то столбец Holder ссылается на нужную строку в таблице PERSONS, а если Holder Type содержит значение С, то столбец Holder ссылается на нужную строку в таблице CORPORATIONS.
Еще одно преимущество решения 1а) над решением 1б) состоит в том, что для соединения таблиц используется более простой и понятный SQL-запрос:
/* 1а */
SELECT acc.credit_limit
,асе.no
FROM accounts асc
,persons per
WHERE per.id = acc.f_per_id
AND ,per.name = 'HEANEY';
/* 1б */
SELECT acc.credit_limit
,acc.no
FROM accounts acc
,persons per
WHERE per.id = acc.f_hld_id
AND acc.holder_type = 'P'
AND per.name = 'HEANEY';
2-й метод. Мы должны разместить физических и юридических лиц в одной таблице, как показано в решении 1а) табл. 3.6. Это возможно лишь в случае, если физические и юридические лица имеют похожие атрибуты. Однако мы можем разместить в "главной" таблице только общие сведения и связать ее необязательными (условными) отношениями "один к одному" с таблицами PERSONS и CORPORATIONS, содержащими характерные для каждой сущности атрибуты. В табл. 3.7 представлен пример того, как общие для физических и юридических лиц атрибуты реализованы в виде таблицы ACCOUNT_HOLDERS (ВЛАДЕЛЬЦЫ_СЧЕТОВ). Отметим, что в этом примере внешний ключ из ACCOUNTS на ACCOUNT_HOLDERS может быть реализован через ограничение по внешнему ключу на ACCOUNTS.
Таблица 3.7. Реализация дуги при помощи подтипа, включающего общие атрибуты сущностей
Accounts (Счета)
№
Credit Limit (Предельный размер кредита)
Holder (Владелец)
01623907
01694295
100.00
150.00
195
297
Account_Holders (Владельцы_Счетов)
ID (Идентификатор)
Type (Тип)
Name (Имя)
Credit Rating (Оценка кредитоспособности)
195
297
P
С
MONKOU
HALL HOLDINGS
GOOD
FAIR
3-й метод. В этом решении (табл. 3.8) имеется внешний ключ из таблицы PERSONAL_ACCOUNTS к таблице PERSONS и внешний ключ из таблицы CORPORATE_ACCOUNTS к таблице CORPORATIONS. В обоих случаях столбец внешнего ключа должен быть столбцом с обязательными значениями — так вводится правило, согласно которому счет должен принадлежать какому-либо лицу: физическому или юридическому.
Таблица 3.8. Отдельные таблицы для счетов физических и юридических лиц
Personal Accounts
№
Credit Limit (Предельный размер кредита)
Holder (Владелец)
01623907
100.00
195
Corporate_Accounts
№
Credit Limit (Предельный размер кредита)
Holder (Владелец)
01694295
150.00
297
Следует отметить, что это решение неэффективно, если необходимо осуществлять совместную обработку всех счетов (физических и юридических лиц).
Какое решение выбрать?
Итак, к какому же выводу относительно дуг мы пришли? Да фактически пока ни к какому. Мы рассмотрели несколько вариантов решения проблемы дуги, но какой из них лучший? На этот вопрос нельзя ответить, пользуясь только моделью данных. Для получения полной картины мы должны рассмотреть определения всех функций, которые будут использовать (и даже сопровождать) эти данные. Наша рекомендация в этом случае — проектируйте в пользу критичных или оперативных функций бизнеса. Если этот подход не позволяет получить явно предпочтительный вариант, то примите решение простым большинством, и зафиксируйте его как таковое. Если каждой функции присвоен вес, то для получения решения можно воспользоваться математической формулой. Это, по крайней мере, позволит избежать субъективности и влияния персональных предпочтений. Например, в распоряжении Ноя был только один ковчег (насколько мы знаем)!
Жизненные циклы сущностей и диаграммы потока данных
Описывая в главе 1, какие результаты анализа передаются на этап проектирования, мы отметили, что диаграммы жизненных циклов сущностей и диаграммы потока данных не являются обязательными. Это, конечно, так, однако эти диаграммы могут оказать большую помощь проектировщику. Как же они связаны с результатами, которые мы уже рассмотрели?
• Диаграммы "сущность-отношения" и определения сущностей описывают данные.
• Иерархии функций и их описания описывают процессы.
• Диаграммы жизненных циклов сущностей и диаграммы потока данных служат для объединения данных и процессов с целью получения более полного описания работы системы.
Жизненные циклы сущностей
Диаграммы жизненных циклов сущностей (ЖЦС) относятся к классу диаграмм, известных как диаграммы изменения состояний (ДИС). Их основная задача — иллюстрировать жизненный цикл сущности по мере перехода ее из исходного состояния в состояние "покоя".
Жизненные циклы сущностей делают анализ более основательным и позволяют лучше понять смысл сущности. Если жизненные циклы входят в перечень результатов вашего проекта, обязательно укажите отдельный цикл для каждой из основных сущностей в системе. Может существовать цикл для каждой кардинальной сущности в модели. Как вы помните, кардинальная сущность — это сущность, которая представляет реальную вещь (в отличие от сущности, которая вводится для разрешения отношения "многие ко многим"). Конечно, не всякая сущность в системе будет подвержена изменению состояния, выходящему за рамки двух неявных состояний "создана" и "удалена" (иногда с дополнительным состоянием "сдана в архив"). Тем не менее, если у сущности есть атрибут с названием статус или что-то вроде того, то для нее должен быть указан жизненный цикл — в форме диаграммы или текста.
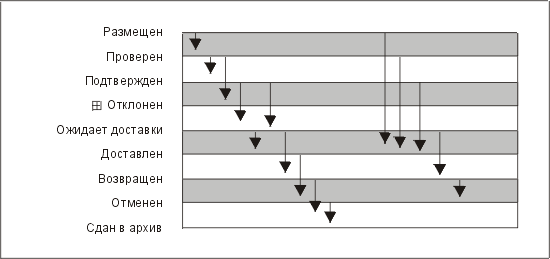
Существует множество способов представления диаграмм такого типа. На рис. 3.29 приведена позаимствованная у Джеймса Марта *** диаграмма-"изгородь", которая отражает жизненный цикл сущности Order ("Заказ") в упрощенной системе ввода заказов (Order Entry System).
Рис. 3.29. Жизненный цикл заказа
Стрелки на диаграмме показывают допустимые изменения состояний. Например, заказ может переходить из состояния "проверен" в состояние "подтвержден" или из состояния "проверен" в состояние "отклонен", но не может переходить из состояния "проверен" непосредственно в состояние "доставлен".
Символ рядом со статусом "отклонен" обозначает состояние, которое может быть разложено на статусы, например, "отклонен из-за низкой кредитоспособности", "отклонен из-за отсутствия на складе" и т.д.
Однако из этой диаграммы не видно, какие состояния являются допустимыми начальными точками в жизненном цикле заказа, а какие — допустимыми конечными состояниями. В рассматриваемом здесь примере состояние в верхней части диаграммы — единственное допустимое исходное состояние заказа ("размещен"), а в нижней части — единственное допустимое конечное состояние ("сдан в архив"). Тем не менее, многие аналитики не учитывают архивацию, потому что это — процесс физический, системного типа. Если состояние "сдан в архив" удалить, то мы получим четыре возможных конечных состояния ("отклонен", "доставлен", "возвращен" и "отменен").
Что же делать с диаграммами жизненных циклов сущностей проектировщикам (кроме того, что восхищаться тем, как красиво они смотрятся)? Большей частью их работа связана с атрибутом, который есть у большинства сущностей и называется STATUS ("Статус") или что-то вроде того. При реализации этого атрибута в виде столбца таблицы требуется ввести три правила:
1. Ограничение для столбца должно быть задано так, чтобы он содержал лишь значения, указанные как допустимые статусы.
2. Исходное значение столбца в новой строке должно быть допустимым исходным значением.
3. При обновлении столбца необходимо обеспечить допустимое изменение состояния.
Первое правило обычно лучше всего реализуется в виде ограничения CHECK на столбце STATUS. Второе правило обычно вводится при помощи запускающегося перед вставкой триггера уровня строки на таблице. Можно также присвоить этому столбцу значение по умолчанию, особенно если для строки существует только одно допустимое исходное состояние. Благодаря этому все приложения, создающие новые элементы этой таблицы, могут не обращать внимания на статус.
Третье правило обычно принимает вид запускающегося перед обновлением триггера уровня строки, который проверяет :old.STATUS и :new.STATUS на предмет допустимости сочетания. Допустимые сочетания могут быть жестко закодированы в триггере (или, что более вероятно, описаны в процедуре, вызываемой этим триггером). Лучший вариант — программно закодировать их в таблице. Если они хранятся в таблице, то можно (по соображениям производительности) рассмотреть возможность кэширования их в PL/SQL-таблице, объявленной как глобальная переменная пакета. Однако похоже, что в текущих промышленных редакциях Oracle7 при таком подходе слишком интенсивно потребляются ресурсы. Как обычно, самый лучший выход — инкапсуляция. Мы пишем триггер для вызова процедуры пакета, а затем проверяем, какой метод является самым быстрым для этих данных, этой платформы и этих версий ПО. Если когда-нибудь потребуется изменить тактику, то достаточно будет изменить только эту процедуру. Ведь код триггера не знает о том, какой механизм используется для выдачи результата.
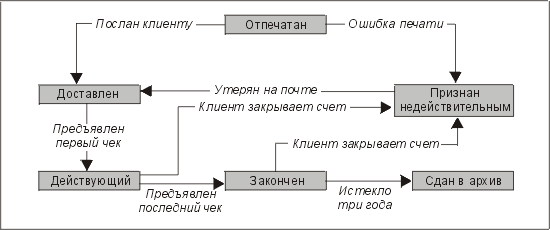
Чтобы проиллюстрировать сказанное, рассмотрим еще один пример, причем с другими условными обозначениями. На рис. 3.30 показан жизненный цикл чека, выданного вашим банком.
Рис. 3.30. Диаграмма жизненного цикла чека
Преимущество диаграммы такого типа состоит в том, что на ней показаны события, которые инициируют изменения статуса сущности. Однако, как и на предыдущей диаграмме, здесь с первого взгляда не понятно, какой из статусов чека является исходным, а какие статусы — допустимыми конечными. В данном случае мы предполагаем, что чек начинает свое существование со статуса "отпечатан" и заканчивает его статусом "признан недействительным" или "сдан в архив". Такой вывод сделан на основании того, что статус "отпечатан" не имеет входящих стрелок, а статусы "сдан в архив" и "признан недействительным" — исходящих. Однако следует отметить, что это еще не гарантирует правильность определения исходных и конечных статусов — они должны быть описаны отдельно.
Диаграммы потока данных
Диаграммы потока данных (ДПД) используются для моделирования процессов перемещения данных в системе путем изображения сетевой структуры этих данных. На ДПД не показываются процессы, которые управляют таким потоком, и не проводится различие между допустимыми и недопустимыми путями. Тем не менее, ДПД имеют множество полезных особенностей. В частности, они:
• позволяют представить систему с точки зрения данных;
• иллюстрируют внешние механизмы подачи данных, которые потребуют наличия интерфейса некоторого вида;
• позволяют представить не только автоматизированные, но и ручные процессы системы;
• выполняют ориентированное на данные секционирование всей системы.
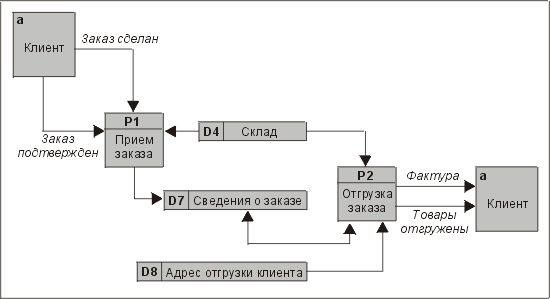
На рис. 3.31 изображена простая диаграмма потока данных, на которой вы можете увидеть многие из типовых конструкций. Прямоугольник с надписью Customer ("Клиент") представляет повторяющуюся внешнюю сущность. Обратите внимание: эта сущность встречается на диаграмме дважды. Такое повторение — типичная особенность ДПД. Лучше показывать поток слева направо, чем пытаться замкнуть его на первую конструкцию. Циклы несколько чужды концепции ДПД, потому что они, скорее, напоминают обработку, а не поток данных.
Рис. 3.31. Простая ДПД, описывающая поток данных в системе обработки заказов
Прямоугольники с закругленными углами Р1 и Р2 — это процессы обработки данных. Возможно, в конечном итоге эти высокоуровневые процессы будут разбиты на более подробные ДПД. Например, процесс Take Order ("Прием заказа", Р1) будет, вероятно, определять метод оплаты и проверять кредитоспособность клиента. Блоки D4, D7 и D8 — это хранилища данных.
О диаграммах потока данных можно говорить очень много, но здесь мы лишь коснулись этой темы, посколькуДПД являются инструментом анализа и предметом нашей книги не являются.
Проектирование, управляемое данными, и метамодели
Большинство приложений рассчитано на управление кодом. Это означает, что, хотя в каждом конкретном случае их действие и может зависеть от значений хранящихся данных (например, от того, имеется ли на банковском счете достаточно денег для выписки чека), правила, действующие в каждом конкретном случае, задаются в коде приложения (или в декларативных ограничениях, применяемых к таблицам). Поэтому любое изменение в этих правилах может быть реализовано только путем внесения изменений в программы, а также затрат времени и средств на повторное тестирование приложения. Если приложение широко распространено, то, возможно, придется решать проблемы с управлением версиями.
Если изъять правила из приложения и поместить их в базу данных, то это сделает приложение более гибким. В большинстве проектов результаты анализа включают ряд справочных таблиц. Некоторые из них часто используются для хранения текстовых толкований закодированных значений (например, соответствий FR — France, DE — Germany). Вероятно, может возникнуть желание хранить в таблицах значения некоторых констант, используемых в программе (например, ставок налога и лимитов ассигнований). Но мы не классифицируем такой подход как проектирование, управляемое данными, и вообще считаем это плохим стилем программирования.
Однако в некоторых проектах очевидно, что пользователям требуется (или может потребоваться, что совсем не одно и то же) обеспечить возможность изменять порядок работы приложения, может быть, даже отдельно для каждой записи. Часто требуется, например, присваивать записи произвольное свойство — автоматизированный эквивалент комментария на визитной карточке (рис. 3.32).
Рис. 3.32. Присваивание записи произвольного свойства
Аналитики должны выявить это требование и ввести атрибут с именем COMMENT или (что более правильно) новую сущность CONTACT_COMMENT, позволяющую хранить любое количество подобных комментариев для данного лица. Проблемы появляются, если мы захотим ввести еще и сущность CONTACT_PROCEDURE, содержащую сведения не только о процедурах, которые пользователь должен выполнять при чтении данной записи, но и о процедуре, которую должно выполнять при чтении записи приложение. Таким образом, мы пытаемся ввести в данные возможность задавать прикладные правила.
В приложении Б мы рассмотрим некоторые приемы, позволяющие справиться с этими задачами, а пока просто отметим, что для поддержки требований такого типа модель сущностей должна принять форму метамодели и что из-за этого степень риска проекта возрастает.
Метамодель — это просто модель другой модели. Любой словарь данных — метамодель, потому что его структуры определены как набор таблиц, служащих для хранения определения набора таблиц. В Oracle, как и в большинстве реляционных СУБД, такая метамодель описывает и саму себя, поэтому таблица Oracle SYS.OBJ$, содержащая информацию обо всех объектах в базе данных Oracle, сама должна включать элемент для таблицы SYS.OBJ$.
Мы говорим, что такая модель имеет два уровня абстрагирования. В словаре есть элемент, определяющий элемент в словаре, который определяет таблицу.
Если вам требуется использовать метамодель, то обратитесь к приложению Б, но сначала убедитесь в том, что вам действительно нужен такой уровень сложности.
Предупреждение
Немногие могут справиться с операциями, охватывающими больше одного уровня абстрагирования, и почти никто не может легко справиться с операциями, охватывающими больше двух уровней абстрагирования.
* Ссылка на д-ра Е. Кодда, отца реляционной базы данных.
** Date, C.J., An Introduction to Database Systems, 6-е издание, Addison-Wesley, 1995.
*** Marth, James and James Odell, Object-Oriented Analysis and Design, Prentice-Hall, 1992.
Знаете ли Вы, что декомпозиция программы - это создание модулей, которые в свою очередь представляют собой небольшие программы, взаимодействующие друг с другом по хорошо определенным и простым правилам.