Из этой главы вы узнаете, почему тщательно продуманная структура базы данных жизненно важна для успешной работы приложения, использующего Oracle в качестве технологии базы данных. Главной особенностью, которая отличает Oracle от многих других реляционных систем управления базами данных, является способность поддерживать широкую номенклатуру архитектур и операционных сред. Приложение может работать как на автономном ПК, так и на мэйнфрейме, обслуживающем свыше тысячи пользователей. И эффективность его работы на обоих концах этого диапазона, зависит от структуры базы данных. Продукты Oracle отличаются богатым набором функциональных возможностей. Это означает, что один и тот же результат можно получить несколькими способами. Задача проектировщиков — выбрать наиболее подходящий для заданных исходных требований метод.
В этой главе представлены базовые архитектуры, которые поддерживает Oracle, в том числе архитектура клиент/сервер, распределенная база данных, хранилища данных и параллельная обработка. (Более подробно мы остановимся на этом в части III книги.) Кроме того, вы ознакомитесь с методами проектирования, позволяющими достичь оптимальной производительности системы. В конце главы приведен перечень существенно важных для проектировщиков особенностей СУБД Oracle7 и дан краткий обзор тех возможностей СУБД Oracle8, которые оказывают влияние на процесс проектирования.
Проектирование в расчете на конкретную архитектуру
Иногда архитектура создаваемой системы должна рассматриваться как заданная. Например, тот факт, что на столах у пользователей конкретного узла уже стоят ПК, которые применяются для выполнения других задач, может вынудить нас использовать архитектуру клиент/сервер. Во многих случаях выбирать тот или иной вариант нас заставляют ограничения, сформулированные при анализе. Например, пропускная способность может быть критическим фактором для рассматриваемой системы, и после тестирования мы можем прийти к выводу о том, что единственный путь достижения необходимой пропускной способности — использовать Parallel Query Option. Как бы многие из нас ни хотели применить ту или иную технологию просто потому, что она привлекательна, приходится быть реалистами и полностью осознавать последствия выбора технологического пути.
Давайте рассмотрим конкретные архитектуры, на которые можно ориентироваться при проектировании.
Клиент/сервер
В том смысле, в котором термин клиент/сервер вошел в употребление, системы клиент/сервер характеризуются тем, что экранная форма, или клиент, и база данных, или сервер, как правило, находятся на разных компьютерах. Клиент и сервер могут быть соединены локальной вычислительной сетью (ЛВС) с высокой скоростью передачи данных и высокой пропускной способностью или глобальной вычислительной сетью (ГВС), которая работает гораздо медленнее и имеет более низкую пропускную способность.
Ключом к качественному проектированию системы клиент/сервер является такое распределение функций по обработке данных между компьютером-клиентом и компьютером-сервером, при котором число операций обмена между ними (число пар сообщений) минимально. Вторая задача — минимизация размеров сообщений. Если следовать этим критериям, то клиент и сервер, как правило, будут работать с максимальной эффективностью. Клиент представляет данные в удобной для пользователя форме, а сервер своевременно отвечает на запросы данных и обеспечивает целостность данных.
Выполняя проектирование процедур, мы должны определить, где они должны располагаться: на клиенте, сервере или и на клиенте, и на сервере. В отдельных случаях наилучший результат достигается при разбиении процедуры между клиентом и сервером, а некоторые процедуры можно реализовать в двух экземплярах — на клиенте и на сервере. В общем случае на клиенте следует размещать только процедуры управления пользовательским интерфейсом, а всю логику приложений и обработки данных нужно выполнять на сервере. Неверные решения при размещении процедур обработки могут серьезно повлиять на производительность и удобство эксплуатации системы.
Переходя к трехуровневым архитектурам, мы рассчитываем найти логику представления данных на клиенте, прикладную логику — на среднем уровне, а логику обработки данных — на сервере данных. Архитектура NCA (Network Computing Architecture), предложенная корпорацией Oracle, делает трехуровневые, а по сути дела n-уровневые, приложения более доступными для проектировщиков. (Подробнее об NCA вы узнаете в разделе "Версия 7.3".)
Давайте вернемся к примеру с прокатом автомобилей. Наши пользователи будут работать с приложением клиент/сервер на ПК. Для них важна возможность быстрой обработки процедуры возврата автомобилей, так как часто клиент спешит, например опаздывает на самолет. Мы решили спроектировать процедуру расчета с клиентом так, чтобы при вводе номера документа на право проката вся информация, необходимая для завершения транзакции, загружалась с сервера на ПК и хранилась локально. Она не обязательно должна появляться на экране вся сразу (и загромождать экран), а будет храниться в памяти ПК или на его локальном диске. После завершения транзакции на сервер отправляются только новые и измененные данные. Говоря языком Oracle, на сервере будет пакет хранимых процедур, обрабатывающий запросы клиента; клиенту никогда не понадобится непосредственно обращаться к таблицам Oracle на сервере.
Более подробно проектирование для архитектур клиент/сервер рассматривается в главе 11.
Распределенные базы данных
Распределенные базы данных характеризуются тем, что хранение данных и управление ими обеспечиваются несколькими серверами. Ключ к успеху при проектировании распределенной базы данных — установление оптимального способа разбивки данных между этими серверами. Важными основаниями для разбивки данных являются улучшение производительности вследствие размещения данных ближе к их основному пользователю и повышение устойчивости путем устранения всеобщей зависимости от центрального сервера. Вариантов здесь множество.
Некоторые данные настолько трудно разделить без ущерба для смысла, что единственное решение — оставить их на одном сервере. Другие данные поддаются вполне естественному разделению, при этом каждое подмножество может располагаться на отдельном сервере — например, данные, зависящие от географического расположения (от страны или региона), можно держать на сервере, обслуживающем этот регион. К разделенным таким образом данным можно обращаться с удаленного узла посредством распределенного запроса. Их даже можно обновлять в удаленном режиме, пользуясь распределенной транзакцией, в которой можно одновременно обновлять данные на нескольких узлах. Альтернативная реализация секционированных данных — наличие неизменяемых копий секции на некоторых или всех других серверах. Эти копии, называемые снимками, периодически обновляются, однако 100%-ная их актуальность не гарантируется.
Если данные не "живут" на каком-то конкретном сервере, то может оказаться приемлемым решение, основанное на схеме с множеством мастерузлов. Эта технология позволяет нескольким узлам владеть одной таблицей и обновлять ее так же, как любую локальную таблицу. Изменения в этой таблице будут распространяться во все остальные копии — либо синхронно (в пределах транзакции), либо асинхронно (позже).
Oracle с SQL*Net поддерживает все эти возможности с помощью таких средств, как каналы связи базы данных, двухфазная фиксация, снимки, неизменяемые снимки и репликация.
В нашем примере мы решили поставить серверы в каждом из крупных пунктов (это основные аэропорты). Локальные базы данных будут содержать сведения об автомобилях, которые находятся в данный момент на стоянке в данном пункте и еще не взяты напрокат. Как только клиент берет автомобиль, сведения об этом автомобиле и договор о прокате посылаются на центральный сервер (поскольку мы не знаем, куда будет возвращен автомобиль). Вся необходимая для составления счетов информация поступает с центрального сервера, но для повышения производительности мы решили хранить неизменяемые данные на локальной машине. Информация о местных налогах хранится на локальных серверах. Мы будем проектировать распределенную схему на основании неизменяемых снимков (для данных о ценах и справочных сведений) и асинхронной репликации (для базы данных автомобилей). Такая структура позволит локальным офисам сдавать автомобили напрокат и принимать их от клиентов даже в том случае, если центральный сервер выйдет из строя.
Подробно о проектировании распределенных баз данных рассказывается в главе 12.
Хранилища данных
Некоторые приложения предполагают использование потенциально сложных управленческих отчетов. Однако при проведении Moscow-анализа системы проката автомобилей (см. главу 1) мы указали, что задача создания управленческих отчетов не включена в данный проект. Это сделано потому, что идею разработки управленческих отчетов в рамках проекта и планирования их работы с действующей базой данных в большинстве случаев нельзя назвать удачной. Причины этого следующие:
• Нельзя предусмотреть все варианты отчетов, которые потребуются пользователям. Это не могут сделать даже те, кто принимает решения. Принятие решений — эвристическая и итеративная область; видя результаты одного отчета, мы испытываем искушение получить следующий.
• Действующая база данных оптимизируется для работы с поддержкой транзакций. Сложные отчеты, охватывающие много таблиц, работают крайне медленно и могут существенно снизить производительность действующей системы.
Хранилище данных строится по следующему принципу. Необходимые данные извлекаются из действующих систем и преобразуются в формат, приемлемый для сложных нерегламентированных запросов. Эти данные хранятся в отдельной базе данных, которая может быть очень большой и содержать архивную информацию, уже изъятую из "живых" систем. Мы добавляем к этой базе данных необходимые пользователям средства для нерегламетированных обращений, позволяющие им "углубиться" в данные, и даем пользователям полную свободу в работе с этими средствами. Проектирование базы данных и средств ввода данных для хранилища данных отличаются от проектирования традиционной системы оперативной обработки транзакций (OLTP — Online Transaction Processing). Для такого проектирования необходимо много новых навыков — например, знание многомерного анализа.
Руководство фирмы по прокату автомобилей в нашем примере хочет разобраться в региональных и сезонных колебаниях и тенденциях на рынке проката автомобилей. Иногда в каком-то пункте не хватает машин определенной категории. В очень напряженные дни в некоторых пунктах вообще не хватает машин. Поэтому для успешной работы фирмы важно предвидеть эти изменения спроса, формировать соответствующие резервы и перегонять при необходимости автомобили из одного пункта в другой.
Подробно проектирование хранилищ данных рассматривается в главе 13.
Параллельная обработка
Параллельная обработка заключается в использовании максимального количества наличных аппаратных ресурсов путем инициирования достаточного для полной загрузки машины объема работы. Самые очевидные ресурсы — это центральные процессоры (ЦП) и запоминающие устройства, как правило, диски. Например, ПО Oracle Server специально предназначено для использования всех преимуществ многопроцессорных машин. Parallel Query Option позволяет разбить определенные запросы на компоненты, а затем послать каждый компонент для выполнения на отдельный ЦП. Параллельную обработку можно успешно применять и при работе с дисками: например, стрипинг позволяет распределять нагрузку между дисками. Необходимо оценить потенциальные узкие места в системе и решить, например, что является более серьезной проблемой — нагрузка на сервер или ограничения, накладываемые сетью.
Существует ряд принципов и правил, которым можно следовать, даже если не используются средства параллельной обработки Oracle. Давайте рассмотрим одно из таких правил в контексте нашей системы проката автомобилей.
Базовая платформа системы — Unix-сервер с четырьмя ЦП и 128 Мбайт оперативной памяти. Когда работает программа ежемесячного начисления оплаты, никаких других операций сервер не выполняет, поэтому три процессора большей частью простаивают. Мы решаем увеличить пропускную способность системы, разбив выполнение этой программы на четыре фрагмента одинакового размера и передавая их для выполнения параллельно. Конечно, обязательно следует позаботиться о том, чтобы между этими процессами не возникало конфликтов, иначе наша умная структура начнет работать против нас.
Чтобы добиться должного уровня отказоустойчивости дисковых устройств, на которых располагается база данных, мы используем технологию RAID 1. Кроме прочих преимуществ, это обеспечит некоторую параллельность операций обмена с дисками.
Подробно проектирование для систем параллельной обработки рассматривается в главе 14.
Обеспечение высокой производительности
Обеспечение максимальной производительности системы — одна из основных целей проектирования баз данных. Плохо спроектированные базы данных Oracle, как правило, работают также плохо, и проблемы производительности в них нельзя решить простым наращиванием мощности аппаратных средств. Цена устранения недостатков проектирования — перепроектирование, которое означает, что массу проделанной работы нужно выбросить в корзину и начать ее заново. Сегодня пользователи уже не относятся снисходительно к системам с большим временем ответа. Повышенные требования пользователей объясняются тем, что они ориентируются на производительность своего настольного ПО (например, текстового процессора). Пользователи считают, что по мере улучшения характеристик аппаратных средств производительность программных средств должна улучшиться прямо пропорционально.
Корпорация Oracle поняла, что сегодня нужен очень высокий уровень производительности и, следуя этой тенденции в технологии аппаратных средств, разработала ПО Oracle Parallel Server, которое позволяет использовать преимущества кластерных систем и систем с массовым параллелизмом. Одни преимущества этой архитектуры доступны "по умолчанию", а для использования других требуется тщательное проектирование.
Если недостатки проектирования не устранены, система будет плохо принята пользовательским сообществом и получит плохую репутацию. Ведь многие пользователи являются закоренелыми скептиками. Это объясняется тем, что они имели дело с плохими системами, которые отличались низкой производительностью или недопустимыми ограничениями.
Почти каждый аспект проектирования так или иначе связан с производительностью, но есть несколько главных аспектов, которые мы и рассмотрим в следующих разделах.
Ключи и индексы
Ключи и индексы для таблиц следует выбирать очень внимательно. Это нельзя делать в отрыве от прикладного кода, который будет обращаться к ним. Необходимо изучить соответствующие модули и попросить пользователей определить, какие пути поиска или доступа обычно используются для запроса данных. Следует добиться баланса между операциями запроса и операциями вставки/обновления данных — чем больше индексов создано для таблицы, тем больше вспомогательных задач придется выполнять Oracle при создании, удалении и обновлении строк. Возможно, стоит удалить индексы перед запуском пакетного процесса, в котором выполняется много операций вставки, обновления ключей и удаления.
В определенных случаях на производительность очень влияет расположение данных. Можно рассмотреть возможность кластеризации данных по ключевому значению, чтобы данные с одинаковым ключевым значением были расположены близко. Для статичных таблиц, доступ к которым обычно производится по полностью заданному уникальному ключу, вероятно, неплохо будет использовать хеш-кластер.
Что касается нашего приложения-примера, то, думается, кластеризация здесь не подходит. Однако мы создадим некоторые дополнительные индексы для наших таблиц, чтобы улучшить реакцию на запросы. Например, мы создаем индекс для столбца REGISTRATION_NUMBER таблицы RENTAL_CARS (первичный ключ этой таблицы — CAR_ID), чтобы автомобили можно было легко найти с помощью уникального ключа, который государство требует указывать на заднем бампере каждого автомобиля (а в большинстве стран мира — и на переднем). (Шире эта тема освещается в главе 6.)
Денормализация
Денормализация — это избирательное хранение избыточной информации в базе данных. Информация избыточна, если ее можно вывести из других элементов базы данных. Сейчас наиболее распространенной формой денормализации является хранение в родительской записи итоговых значений и сумм, которые можно вычислить с помощью дочерних записей. Как и при выборе ключей, принимая решение о том, когда выполнять денормализацию, необходимо стремиться к достижению компромисса между увеличением скорости выполнения запроса и замедлением обработки данных.
В некоторых случаях вместо денормализации можно применить другие методы. Если есть отчет, который без широкомасштабной денормализации, скорее всего, будет работать крайне медленно, можно написать подпрограмму, копирующую необходимые данные в несколько временных таблиц, что значительно повысит скорость генерации отчета.
В нашем приложении-примере мы создаем в таблице CUSTOMERS столбец OUTSTANDING_INVOICE_AMOUNT, содержащий сумму по столбцу INVOICE_AMOUNT таблицы INVOICES для клиента, значение STATUS которого в данный момент не равно PAID. Это позволяет быстро проверять задолженность клиентов, не читая счетов-фактур. Мы определяем триггеры на таблице INVOICES, которые ведут это значение. Например, если значение в столбце STATUS для данного клиента изменяется на PAID, значение INVOICE_AMOUNT вычитается из OUTSTANDING_INVOICE_AMOUNT в таблице CUSTOMERS.
Более подробно денормализация освещается в главе 4.
Выбор оптимизатора
Oracle7 позволяет выбрать один из двух оптимизаторов, построенных на разных подходах к оптимизации SQL-запросов. В традиционном методе оптимизации на основе правил, для определения более предпочтительного пути доступа к данным используется ряд четко сформулированных правил. Метод оптимизации на основе стоимости претендует на большую интеллектуальность и предполагает принятие информированных решений на основании сведений об относительном размере и распределении данных.
Конечно, хотелось бы иметь возможность переключаться между этими режимами оптимизации, не заботясь о том, как спроектирована и написана система. Однако в действительности проектирование необходимо выполнять с учетом метода оптимизации. Почти наверняка возникнет ситуация, когда вы будете знать оптимальный путь к данным лучше оптимизатора и вам нужно будет повлиять на оптимизатора с тем, чтобы он выбрал именно этот путь.
Поскольку система проката автомобилей — совершенно новый проект и старый программный код в нем не используется, мы принимаем решение в пользу оптимизатора по стоимости. Нам приятно осознавать, что если распределение наших данных радикально изменится, то выбранный нами оптимизатор сможет адаптироваться автоматически.
Принятие решения о выборе оптимизатора тесно связано со стратегией индексирования. Эта тема рассматривается в главе 6.
Методы программирования
Большинство рассмотренных нами приемов повышения производительности ориентировано на базу данных. Кроме того, нужно обратить внимание на методы, которые используются для разработки кода. Мы уже упоминали о некоторых из них, рассматривая архитектуру клиент/сервер. Например, мы реализуем общие алгоритмы и код, интенсивно использующий базу данных, в виде хранимых пакетов и процедур. Мы также решили кэшировать неизменяющиеся данные на локальных машинах для ускорения расчета стоимости заказа.
Существуют и другие способы уменьшения количества вызовов между приложением и сервером Oracle. Например, большинство инструментальных средств Oracle позволяет использовать массивный интерфейс, который обрабатывает набор (массив) строк базы данных за одну операцию выборки (для запросов) или за одну вставку, обновление или удаление (для DML-операций).
Другие факторы, которые нужно учитывать при проектировании
В этом разделе рассматриваются некоторые особенности реляционных баз данных, которые необходимо учитывать при принятии решений в процессе проектирования.
Очень большие базы данных
Большинство современных баз данных должны быть способны справляться с гигабайтами, если не с терабайтами, данных. Объем этих данных, вероятно, будет расти из года в год с феноменальной скоростью, и это не должно отрицательно сказываться на производительности. База данных и данные в ней должны оставаться управляемыми и контролируемыми. Администраторы баз данных, как бы опытны они не были, не смогут залатать прорехи, вызванные низким качеством проектирования, при котором не был учтен рост объема данных.
К счастью, ПО Oracle Server способно справиться с большими объемами данных, причем, как правило, без отрицательного влияния на производительность. Главная задача проектировщика — установить размеры различных объектов схемы базы данных, а также выполнить эффективное планирование, учитывающее возможный рост объема данных.
Временные ряды (временные данные)
Поскольку в реляционных системах данные представлены в виде таблиц, то эти данные по своей природе двумерны. Если вы захотите ввести дополнительное измерение (чтобы сделать данные многомерными), то придется сделать кое-какие изменения. Иначе вы можете получить систему, выдающую непредсказуемые результаты, или систему, которая выдает предсказуемые результаты, но затрачивает на это уйму времени. Во многих проектах разработчики ухитряются создать программы, которым нужна вечность, чтобы выдать неправильный ответ; это — наихудшее сочетание вышеупомянутых случаев.
Наиболее часто в таблицы в качестве дополнительного измерения вводят время. Это бывает в случаях, когда нужно сохранить старые значения, чтобы составить полную историю данных. Она может понадобиться либо для аудита, либо для выполнения транзакций так, как будто вы находитесь в прошлом (например, применение цен предыдущего месяца для оформления счетов-фактур текущего месяца). Как правило, в этом случае во всех строках таблицы добавляются столбцы (например, DATE_TO и DATE_FROM). Пусть вас не обманывает кажущаяся легкость этой операции — здесь есть много проблем, они рассматриваются нами в главе 7.
В нашем примере с прокатом автомобилей мы добавляем столбцы (DATE_TO, DATE_FROM) к таблице BILLING_RATES. Это позволяет в случае необходимости пересчитывать счета-фактуры, используя старые данные.
Стыковка с другими системами
К сожалению, лишь немногие проекты начинаются "с нуля". Когда приложение сдается в эксплуатацию, всегда присутствует набор исходных данных, которые нужно взять из унаследованных систем. Это могут быть справочные данные, данные транзакций или и те, и другие. Аналогично, очень немногие компьютерные системы работают в блаженной изоляции от окружающего их мира: как правило, им необходим обмен данными с другими приложениями, которые работают в других системах.
Существует много способов обмена данными. До сих пор широко распространен (благодаря своей простоте) интерфейс на основе двумерных файлов. Система-поставщик выдает данные в предопределенном формате в файл. Этот файл пересылается в систему-приемник, где соответствующая утилита читает его и обновляет базу данных. Однако в современной сетевой технологии интерфейс позволяет читать данные непосредственно из одной системы, а затем записывать их в другую систему. Каждый интерфейс необходимо оценить и определить наиболее подходящий механизм передачи данных. Безусловно, одним из важнейших факторов является то, насколько важна для принимающей системы актуальность данных. Например, если загрузить данные вечером, то к концу следующего дня они будут на сутки устаревшими. В некоторых случаях это не допустимо. (Эта тема освещена в главе 8.)
Давайте вернемся к системе проката автомобилей. Мы планируем провести несколько операций загрузки данных из старой системы. В каждой их них будет передаваться двумерный файл с записями фиксированной длины, поскольку этот формат более удобен для программистов, работающих со старой системой. Новая система должна иметь интерфейс, работающий на вывод данных, с ПО бухгалтерского учета. При этом используются промежуточные таблицы — наша система будет осуществлять запись в эти таблицы, а ПО — чтение из таблиц. Мы также планируем создать интерфейс, работающий на ввод данных. Для посетителей, которые хотят поскорее сдать автомобиль, предусмотрен вариант быстрого возврата. Они просто указывают некоторые данные на своем контракте на право проката и при возврате автомобиля опускают контракт в ящик. С помощью устройств считывания штрихового кода и оптических устройств распознавания символов мы перенесем эти данные в файл, который будет загружаться в базу данных вечером.
Проектирование для
Oracle7
Как уже отмечалось, проектирование заключается в максимально эффективном использовании имеющегося материала и технологии. Проектируя базы данных для Oracle, вы убедитесь, что один из важнейших моментов при принятии проектных решений — это выбор версии СУБД Oracle, которая будет использоваться для генерации. Чем новее версия, тем больше у нее возможностей.
Мы предполагаем, что вы уже обладаете достаточным опытом работы с Oracle. В этом разделе мы не пытаемся привести полное описание СУБД Oracle7, а лишь хотим подчеркнуть некоторые особенности, существенно влияющие на проектирование, и объяснить, почему они так важны.
Примечание
Если вы хорошо знакомы с Огас1е7, можете пропустить этот раздел. Однако задумайтесь, хорошо ли вы понимаете, что такое:
• триггеры и хранимые процедуры;
• разделяемый пул;
• буферный пул;
• ограничения целостности;
• табличные пространства только для чтения;
• симметричная репликация;
• ручное секционирование.
Учтите, что у многих потребителей работает несколько экземпляров СУБД на нескольких серверах, и они вряд ли в состоянии обеспечить согласованность этих экземпляров. Другими словами, даже на одном и том же сервере у них могут работать разные экземпляры под разными версиями Oracle. Существует целый ряд причин возникновения подобной ситуации. Самая простая (и, вероятно, самая распространенная) состоит в том, что это позволяет протестировать новую версию перед запуском ее в эксплуатацию.
Более сложные ситуации возникают, если на узле эксплуатируются аппаратные платформы разных типов. Это связано с тем, что корпорация Oracle не выпускает одновременно версии для всех поддерживаемых платформ. Более того, некоторые версии для определенных платформ вообще отсутствуют.
Одно из величайших достижений Oracle состоит в том, что код, успешно работающий с одной версией СУБД Oracle, будет (в большинстве случаев) работать и со следующей версией. Корпорация обращает серьезное внимание на то, чтобы версии обладали такой совместимостью. Исключения из этого правила наблюдались в основном при переходе с версии 5 на версию 6. Для большинства читателей этот факт сейчас имеет чисто историческую ценность, хотя ходят слухи, что в мире до сих пор есть узлы, на которых эксплуатируются промышленные системы на базе Огас1е5. Мы знаем одну многонациональную компанию, у которой в июне 1996 г. в Европе было несколько узлов с Огас1е5. Она оправдывала это, в частности, тем, что данное приложение обеспечивает требуемую производительность и поэтому никаких причин "тревожить" его нет.
Отметим, однако, что если в версию Oracle внесут изменение, например, в реализацию языка SQL добавят новые зарезервированные слова, то вам придется либо работать в режиме совместимости (в котором нельзя будет воспользоваться как минимум несколькими новыми возможностями), либо обеспечить, чтобы это зарезервированное слово не применялась в приложении как имя объекта или столбца.
В следующих разделах мы не затрагиваем вопросы лицензирования ПО. Однако следует учитывать, что многие из описанных возможностей доступны лишь за дополнительную плату. Поскольку политика взимания платы за эти возможности со стороны Oracle может измениться, мы рекомендуем проверить статус ваших лицензионных соглашений с этой корпорацией и лишь затем считать, что то или иное средство будет доступно вам на всех соответствующих платформах.
Версия 7.0
В этом разделе представлены ключевые особенности СУБД Oracle версии 7.0, которые оказывают существенное влияние на проектирование.
Триггеры, процедуры и функции
В первых выпусках Огас1е7 была реализована возможность хранения и выполнения кода внутри базы данных либо в форме триггеров, которые могли применяться к таблицам, либо в форме процедур и функций, вызываемых из клиентского приложения через анонимные блоки PL/SQL.
PL/SQL — переносимый язык третьего поколения, запатентованный корпорацией Oracle, — в версии 7.0 подвергся существенной модернизации, но область его применения все равно остается несколько ограниченной. Хотя у этого языка есть ряд особенностей, которые делают его привлекательным и эффективным для реализации правил обработки данных и бизнес-правил в схеме базы данных, на наш взгляд, ему не хватает мощности и гибкости для того, чтобы стать реальным инструментом для написания завершенного приложения. *
С точки зрения архитектуры важно уяснить, что процессор PL/SQL, по сути, не зависит от процессора SQL и может быть использован в других средах, например, в Oracle Forms и Oracle Reports.
Ключевой задачей проектирования для Огас1е7 является эффективное распределение функций между прикладным кодом и кодом, хранящимся в базе данных.
Оптимизатор по стоимости
В версии 7.0 был также введен предложенный Oracle оптимизатор по стоимости (о котором мы упоминали выше, в разделе "Выбор оптимизатора"), а также новый SQL-оператор ANALYZE, обеспечивающий сбор статистической информации. Хотя новый оптимизатор и позволил получить определенную выгоду, производительность оптимизации по стоимости не оправдала ожиданий многих пользователей Oracle и они продолжали пользоваться оптимизатором по правилам в существующих (а иногда и в новых) приложениях. Оптимизатор по стоимости в Oracle версии 7.0 не учитывает распределение ключевых значений и не имеет стоимостной модели оценки выполнения условий в запросах.
Одна из главных особенностей оптимизатора по стоимости состоит в том, что он позволяет автору кода инструктировать оптимизатор на предмет того, как выполнять запрос, используя подсказку, а не туманные побочные Эффекты, как в предыдущих версиях Oracle. При традиционном способе задания полного сканирования таблицы даже при наличии подходящего индекса применялась такая конструкция:
SELECT e.employee_name
FROM employees e
WHERE NVL(e.division, NULL) = SALES';
При использовании оптимизатора по стоимости тот же эффект достигается более рациональным способом:
SELECT /*+ FULL E */ e.employee_name
FROM employees e
WHERE e.division = 'SALES';
Вторая форма дает существенное повышение производительности, поскольку здесь к каждой строке таблицы не применяется функция NVL. Функции SQL работают достаточно эффективно, но этот язык является интерпретируемым и затрат на выполнение функций лучше избегать.
Примечание
В большинстве книг и курсов по Oracle рекомендуют применять конкатенацию или сложение для подавления использования индекса. Например:
WHERE e.division || '' = 'SALES'
или
WHERE e.deptno + 0 = 30
Следует отметить, что во всех протестированных нами версиях Oracle функция NVL работает заметно быстрее конкатенации и сложения.
Возможность управлять оптимизацией запросов очень удобна для проектировщика. Это позволяет достичь большей гибкости в проектировании БД, поскольку устраняет необходимость избегать неэффективно работающих программных конструкций. Однако, чтобы воспользоваться оптимизатором, учитывающим фактическое распределение значений данных, вам придется перейти на версию 7.3.
В Oracle версии 7.0 существенные изменения были внесены и в порядок оптимизации соединений таблиц, расположенных на разных машинах, что позволило устранить ряд проблем, сдерживающих рост производительности.
Ограничения целостности
Помимо возможности определять триггеры на таблицах, в версии 7.0, в дополнение к ограничению NOT NULL, были реализованы другие ограничения целостности. Это первоначально планировалось сделать в Огас1е6. Однако эта версия поддерживала только синтаксис, а его реализация отсутствовала. Одна из особенностей, которая не переставала поражать технических специалистов с момента появления Oracle7, — это явное нежелание проектировщиков и администраторов БД применять ограничения целостности, средство, которое признано как эффектным, так и эффективным.
Использование ограничений целостности существенно влияет на проектирование. В частности, ограничения внешнего ключа влияют на проектирование справочных или ссылочных таблиц. Ограничения, конечно, обеспечивают необходимый уровень целостности данных, однако действуют они не на уровне транзакций, а на уровне команд. Это значит, что при этом отлавливаются так называемые "промежуточные" нарушения.
Распределенная база данных
В версии 7.0 к имеющимся в SQL*Net средствам поддержки операций с распределенными базами данных были добавлены DML-операции (INSERT, UPDATE, DELETE, LOCK, SELECT FOR UPDATE). Для этого была реализована полностью прозрачная форма двухфазной фиксации (2ФФ). Несмотря на свою эффектность, эта возможность широко не использовалась, чему был целый ряд причин (мы обсудим их в главе 12). Проектирование сетевой топологии и распределение данных между узлами открывает совершенно новую дисциплину в проектировании БД Oracle.
Был введен новый тип объекта базы данных, снимок, и создан механизм, позволяющий переносить изменения, внесенные в таблицу на одном узле, на другие узлы (снимки) с заданным интервалом. Этот механизм обладал рядом проектных и реализационных дефектов, которые устранены в последующих версиях.
Производительность сервера
В версии 7.0 были приняты меры по устранению некоторых проблем производительности, которые проявлялись в версии 6, и внесены существенные изменения в механизм управления кэшами процессора SQL.
В Oracle всегда применяется не статический, а динамический SQL, т.е. планы выполнения отдельных предложений SQL определяются во время выполнения, а не на более ранних стадиях подготовки программ. Так, каждый раз, когда процессу нужно было выполнить SQL-предложение, он должен был представлять его СУБД, которая перед выполнением разбирала и оптимизировала это предложение.
В версии 7.0 была введена область, которая называется разделяемый пул. Среди прочих достоинств, разделяемый пул позволял одному пользователю задействовать план выполнения, построенный другим пользователем. Существует ряд приемов для клиентских приложений, которые позволяют максимально повысить эффективность этого средства.
Ранние версии Oracle, как правило, страдали от чрезмерного трафика сетевых сообщений при работе в конфигурациях клиент/сервер, и в версии 7.0 было формально введено понятие составных (compound) вызовов. (Они в разных формах присутствовали в ряде ранних версий.) Значение этой поддержки рассматривается в главе 11.
Другие существенные особенности
Из множества других особенностей, появившихся в Oracle7, мы выделим две, которые оказывают определенное влияние на проектирование.
Первая — это расширенная поддержка больших двоичных объектов (BLOB), что позволяет хранить в столбце до двух гигабайт данных. BLOB обеспечивает хранение элементов данных, например, графики и документов текстовых процессоров, без искусственного разбиения их на отдельные строки. Тем не менее, хотя в версии 7.0 и поддерживалась порционная выборка, весь BLOB нужно было вставлять сразу, вследствие чего для него фактически существовал лимит размера — где-то один мегабайт. Подпрограммы управления пространством базы данных не были настроены на обработку BLOB, что влекло за собой дополнительные трудности.
Второе усовершенствование — из области безопасности, где введение ролей и профилей упростило задачи, связанные с проектированием подсистемы защиты в приложениях. Организация защиты, чувствительной к данным (например, пользователю можно видеть зарплату сотрудников только отделов 21, 22 и 25), остается обязанностью приложений.
Версия 7.1
Основываясь на опыте эксплуатации версии 7.0, корпорация Oracle ввела в версии 7.1 ряд новых возможностей, ориентированных как на администраторов, так и на разработчиков. Эти средства оказались весьма важными для эффективного проектирования.
Динамический SQL в PL/SQL
Одним из направлений использования хранимых процедур PL/SQL в версии 7.0 была инкапсуляция прикладных функций — то есть клиентское приложение не должно было выдавать весь необходимый SQL-код, а могло для достижения результата вызвать одну-единственную процедуру. Обнаружилось, что при обновлениях данных это работает хорошо, а при запросах — плохо, потому что вызывающему приложению всегда приходилось задавать критерии выбора. В результате процедура PL/SQL включала большое число SQL-запросов — на все случаи жизни. Чтобы решить эту проблему, в версии 7.1 был предложен механизм, позволяющий хранимым процедурам (и функциям) PL/SQL реализовать настоящий динамический SQL. Процедура может формировать свой SQL-запрос в VARCHAR2, а затем выполнять его.
Это позволяет проектировщику создать промежуточный слой между приложением и базой данных, благодаря чему устраняется зависимость от структуры базы данных в приложении. Это также позволяет освободить приложение от специфичного для Oracle кода и облегчить перенос в другие системы управления базами данных, хотя, вероятно, сама Oracle эту выгоду не искала.
Поддержка множества триггеров
По мере того как для сложной проверки и при пересылке данных между приложениями все больше и больше использовались триггеры табличного уровня, пользователи стали обнаруживать, что инсталляционные скрипты отказывают при создании триггера на конкретном объекте, потому что уже существует триггер с такими же временными параметрами. Поэтому в версии 7.1 в таблицах может быть несколько триггеров по одному событию с одинаковыми временными параметрами. Благодаря такой возможности каждый инсталляционный скрипт может помещать независимые триггеры на одну таблицу.
Влияние на проектирование здесь состоит в том, что мы можем реализовать каждое бизнес-правило или правило проверки данных при помощи отдельного триггера, вместо того чтобы объединять несколько несвязанных между собой бизнес-правил в одной спецификации триггера.
Функции PL/SQL внутри SQL
Как упоминалось выше, процессор PL/SQL практически не зависит от процессора SQL. В версии 7.1 можно вызывать функции PL/SQL из SQL.
Например:
CREATE OR REPLACE FUNCTION cube (x IN NUMBER)
RETURN NUMBER IS
BEGIN
RETURN x ** 3;
END;
Это позволяет создавать на SQL-запросы наподобие следующего:
SELECT e.emp_name
, е.basic
, t.gross
FROM employees e
, emp_year_totals t
WHERE e.emp# = t.emp#
AND t.year = 1997
AND t.gross >= CUBE(e.basic)
ORDER BY t.gross/e.basic DESC;
Однако при этом возникает ряд проблем, поскольку в PL/SQL есть переменные, сохраняющие свое состояние в пределах сессии, и, кроме того, он может выдавать DML-команды. Oracle обеспечила механизмы для объявления уровня чистоты функции PL/SQL, т.е. степени возможных побочных эффектов, например таких, как внесение изменений в БД.
Если вы собираетесь использовать функции PL/SQL внутри SQL на этапе генерации, то в процессе проектирования их необходимо протестировать. Мы рекомендуем применять функции PL/SQL в SQL-предложениях лишь в случае, если эти функции предназначены специально для вызова из SQL.
Табличные пространства только для чтения
Oracle поддерживает в файлах данных заголовочные блоки, в которых, помимо прочего, указано, какой самый старый журнал должен быть доступен для правильного запуска данного файла. В версиях до 7.1 это означало, что со всех файлов данных нужно было регулярно снимать резервные копии, даже если администратор знал, что они не изменились, потому что в противном случае во время восстановления Oracle настаивала на обработке всех архивных журналов, начиная с даты самого старого файла.
Чтобы сократить время резервного копирования (и восстановления) баз данных с большими объемами статических данных, в версии 7.1 была реализована возможность установки для табличного пространства статуса "только для чтения". После резервного копирования такого табличного пространства его больше не нужно копировать, потому что программа восстановления знает, что данные в этом пространстве не могли измениться с момента предыдущего резервного копирования, и не будет применять архивные журналы к файлам этого табличного пространства. Это идеальный вариант для больших таблиц архивных данных, и благодаря этой возможности на некоторых узлах объем регулярно копируемых данных сократился более чем на 90%. Здесь есть и недостаток: для того чтобы организовать раздел данных, которые могут быть объявлены как неизменяемые, может потребоваться секционирование данных. Проектируя физическое размещение базы данных, вы можете разделить изменяющиеся и неизменяющиеся данные и поместить неизменяющиеся данные в табличное пространство только для чтения. Учтите это размещение при планировании стратегии резервного копирования с администратором БД.
Parallel Query Option
Oracle всегда обладала достаточно масштабируемой архитектурой — в силу того, что у каждого пользователя, помимо фоновых процессов, выполняющих административные задачи и запись в БД, был выделенный серверный процесс. В симметричной многопроцессорной среде (СМП-системе) это позволяет распределить обработку, выполняемую для разных пользователей, на все центральные процессоры. Однако такая архитектура мало влияет на одиночный процесс, выполняющий большой и сложный SQL-запрос. Средство Parallel Query Option (PQO) в версии 7.1 позволяет разбивать запрос, требующий полного сканирования таблицы, и распределять его на несколько центральных процессоров. Для любого запроса, требующего полного сканирования таблицы, Parallel Query Option должно попытаться довести до 100% либо степень использования ЦП, либо (что бывает чаще) эффективность операций обмена с диском.
Проектируя пакетные процессы и сложные отчеты, необходимо выявить модули, которые могут пользоваться этим средством, и определить оптимальное число процессов, которое оно должно использовать на эксплуатационной платформе (платформах). Кроме того, обязательно следует обсудить с администратором БД вопрос о том, как распределить таблицу на несколько дисков. PQO также может оказать существенное влияние на время построения индекса.
Дополнительная информация о параллельной обработке предлагается в главе 14.
Версия 7.1.6
В версии 7.1.6 появился ряд новых возможностей, влияющих на проектирование.
Симметричная репликация
В версии 7.1.6 впервые на промышленном уровне была реализована предложенная Oracle поддержка симметричной репликации. Это позволяет хранить несколько копий одних и тех же данных на разных узлах и независимо обновлять их асинхронно или с отсроченным распространением изменений, а также выявлять и разрешать возникающие при этом конфликты.
Чтобы задавать действия по репликации в распределенной среде, в Oracle реализован набор упакованных процедур, который называется RepCat (replication catalogue — каталог репликации). Эти процедуры обеспечивают сопровождение всех объектов словаря данных, необходимых для поддержки репликации.
Механизм распространения изменений данных построен на асинхронных RPC (удаленных вызовах процедур). Они, в свою очередь, используют двухфазную фиксацию для обеспечения целостности при передаче действий из одного экземпляра базы данных в другой. Асинхронные RPC также доступны пользовательским приложениям на PL/SQL, выполняющимся на сервере базы данных.
В главе 12 более подробно освещаются факторы, которые необходимо учесть, рассматривая возможность использования асинхронных обновлений. Надеемся, что читателю ясно, почему асинхронная операция не может быть запросом — она не может возвратить результат в вызывающую программу, которая давно перешла к выполнению другой операции.
Разделяемый пул
Ранние версии Огас1е7 страдали рядом недостатков, связанных с управлением разделяемым пулом. Полный анализ этих проблем выходит за рамки книги по проектированию, поэтому мы лишь отметим основные трудности — способ кэширования триггеров и тенденция пула к сильной фрагментации.
Как упоминалось выше, одна из главных целей использования триггеров — выполнение вспомогательного действия при внесении изменений в таблицу базы данных. Как и можно было ожидать, реализованная в Oracle поддержка симметричной репликации интенсивно задействует триггеры, и в этой версии был принят ряд мер, призванных уменьшить проблемы, связанные с разделяемым пулом.
Версия 7.2
В этом разделе описываются особенности версии 7.2, на которые нужно обратить особое внимание при проектировании.
Ручное секционирование
В версии 7.2 реализована ограниченная поддержка секционирования данных в форме ручного секционирования. Попросту говоря, при определенных ограничивающих условиях оптимизатор запросов версии 7.2 может заносить условия соединения в представление с UNION ALL.
Предположим, что у нас есть две таблицы, ORDERS и OLD_ORDERS, с идентичными столбцами и индексами и мы объявляем представление ALL_ORDERS следующим образом:
SELECT *
FROM orders
UNION ALL
SELECT *
FROM old_orders;
Запрос
SELECT c.cust_name , o.order_date , e.order_value
FROM customers с
, all_orders о
WHERE c.zip = 12345 AND c.cust# = o.cust#;
теперь будет выполнен так:
SELECT c.cust_name , o.order_date , о.order_value
FROM customers с
, orders о
WHERE c.zip = 12345 AND c.cust# = o.cust#;
UNION ALL
SELECT c.cust_name , o.order_date , о.order_value
FROM customers с
, old_orders о
WHERE c.zip = 12345 AND c.cust# = o.cust#;
В более ранних версиях Oracle перед соединением был бы создан экземпляр представления. Создание экземпляра представления предполагает построение временной таблицы, описываемой представлением, и применение к ней всех условий соединения и предикатов. При высоко избирательных запросах к большим таблицам последствия для производительности были просто катастрофические.
Эта особенность имеет особое значение при проектировании многомерных таблиц, например, временных или пространственных данных, где этот метод широко используется. Она может быть полезной и при проектировании стратегий архивации там, где может понадобиться периодическая совместная обработка архивных и текущих данных.
Планировщик заданий PL/SQL
Версия 7.2 также включает планировщик заданий PL/SQL, позволяющий пользователю или разработчику настраивать PL/SQL-задачи на выполнение в указанный день и время и на повторение их с заданным интервалом. Это призвано в некоторой степени смягчить проблему отсутствия в Огас1е7 собственной подсистемы пакетного планирования.
Неблокирующие вызовы
Еще одна особенность, которую долго ждали проектировщики, использующие Oracle, — это возможность указать Oracle сделать что-нибудь, не дожидаясь ответа. Она была реализована в версии 7.2 в форме неблокирующих вызовов из Oracle Call Interface (OCI), который, как правило, используется в программах на С или C++.
Много лет назад, после того как Oracle выпустила прекомпиляторы версии 1, позволяющие использовать SQL-вызовы непосредственно в программах на языках третьего поколения (например, на С и Коболе), корпорация объявила о своем намерении прекратить поддержку OCI. По ряду технических причин этот шаг встретил сильное сопротивление со стороны поставщиков, продающих программные средства для работы с Oracle. Наиболее важно то, что OCI позволяет свободно передавать курсор при помощи ссылки из одной подпрограммы в другую, делая возможным написание универсального кода, обрабатывающего любое количество курсоров. Поскольку Oracle произвела ряд внутренних изменений, чтобы привести OCI в соответствие с современными требованиями в версии 7.0, наличие неблокирующих вызовов в версии 7.2 означает, что появилась еще одна важная группа функциональных возможностей, которые можно получить только через этот интерфейс вызова.
Неблокирующие вызовы особенно привлекательны в ситуациях, когда приложение одновременно связано с несколькими экземплярами и требуется инициировать действия параллельно с каждым из этих экземпляров. Эта возможность также позволяет проектировщику пользовательского интерфейса попытаться развлечь пользователя, отображая на экране какую-нибудь анимацию во время ожидания ответа от сервера.
Использование OCI влечет за собой дополнительные затраты на разработку, так как он разрабатывается, как правило, дольше, чем эквивалентный код, написанный с помощью прекомпиляторов Oracle. Придется взвесить выгоду и затраты и, возможно, проанализировать техническую осуществимость использования комбинации двух вышеупомянутых технологий. В старых версиях Oracle использование OCI могло привести к созданию программ, которые работали во много раз медленнее, чем эквивалентная программа на Рго*С или Pro*COBOL. В Oracle7 этот недостаток устранен, но пользователи, вероятнее всего, так и не увидят никакого повышения производительности при работе с OCI.
Версия 7.3
Выпуск версии 7.3 ознаменовал собой появление большого числа важных новых возможностей. По сути дела, как уже отмечали представители Oracle на конференциях и брифингах, единственная причина, по которой версию 7.3 не назвали Oracle8, состоит в том, что название Огас1е8 было давно зарезервировано для объектно-ориентированного расширения Oracle.
Разделяемый пул
В версии 7.3 Oracle по-новому реализовала механизм управления триггерами в словаре данных, а также внесла усовершенствования в управление кэшем для хранимых процедур. Это должно устранить ряд связанных с производительностью проблем, возникающих при использовании хранимых процедур вообще и триггеров в частности.
Гистограммы значений
Оптимизатор по стоимости в версии 7.3 имеет доступ к распределению значений столбцов для каждого индексированного столбца и даже для неиндексированных столбцов. Эта возможность, конечно, хороша, но по этому поводу хочется высказать несколько замечаний.
Во-первых, гистограммы значений строятся по значениям столбцов, а не по значениям ключей. Конечно, для одностолбцовых индексов это не имеет значения, но для составных индексов разница очень велика. В результате существуют ситуации, когда у оптимизатора по стоимости нет хороших данных, на основании которых можно принять решение о том, использовать составной индекс или нет. Так, в частности, бывает, когда столбцы, входящие в лидирующую часть индекса, не очень избирательны и диапазон значений в них невелик, однако сочетания этих значений обладают очень большой степенью избирательности.
Во-вторых, у оптимизатора запросов версии 7.3, как и прежде, нет модели, которая учитывает загрузку центрального процессора, связанную с выполнением предложений, содержащих условия. Для ранних версий оптимизатора по стоимости была характерна сильная тенденция к использованию полного сканирования таблицы для условий, которые выполнялись бы быстрее посредством диапазанного сканирования индекса. В результате тестов, проведенных для версии 7.3.2, обнаружилось, что в некоторых случаях оптимизатор выбирал полное сканирование таблицы там, где диапазонное сканирование индекса выполнялось бы быстрее, а в других случаях он выбирал диапазонное сканирование индекса вместо полного сканирования таблицы.
В-третьих, Oracle не распространила сферу использования распределений значений на оптимизацию запросов, содержащих связанные переменные. Например, запрос следующего вида
SELECT COUNT(*) FROM trades WHERE currency = 'NOK'
оптимизировать довольно просто, если имеются индекс по валюте (CURRENCY) и гистограмма, показывающая, что значение NOK встречается менее чем в 1,25% случаев. Если же эта гистограмма говорит о том, что значение USD встречается более чем в 85% случаев, то единственно правильного варианта оптимизации для запроса
SELECT COUNT(*) FROM trades WHERE currency = :curr;
не существует, и для выбора хорошей стратегии доступа мы должны знать значение связанной переменной. Это серьезная проблема, поскольку с годами программисты, работающие над высокопроизводительными приложениями, вбили себе в голову, что связанные переменные (:curr в приведенном примере) — лучший подход к использованию разделяемого пула и экономии времени на синтаксический анализ. Возникает эта проблема потому, что Oracle придерживается своего традиционного подхода: оптимизация каждого дерева синтаксического анализа производится до его первого выполнения, а затем этот же план запросов используется для последующих выполнений.
Снятие ограничений на число экстентов
В версии 7.3 каждый объект (таблица, индекс, кластер, сегмент отката, временный сегмент) может иметь неограниченное число экстентов в базе данных. Эта особенность очень полезна для администраторов БД. Для проектировщика она уменьшает потенциальный ущерб от ошибок в планировании пространства.
Bilinap-индсксы
До версии 7.0 Oracle поддерживала только индексы со структурой В-дерева. В версии 7.0 были введены хеш-кластеры, но они оказались не особенно привлекательны для проектировщиков и разработчиков. Хеш-кластеры, как оказывается, используются относительно редко, и, по некоторым данным, те, кто их использует, ожидаемого повышения производительности не добились.
В версии 7.3.3 Oracle поддерживает bitmap-индексы на сервере (они в течение нескольких лет используются в продукте SQL*TextRetrieval). Bitmap-индексы могут быть очень эффективными для не очень избирательных ключей, например, для внешних ключей к таблицам с кодовыми значениями, особенно когда в условии WHERE указано несколько таких ключей и используется логическая операция AND.
Новые способы выполнения соединений
Традиционными для Oracle стратегиями эквисоединений являются вложенные циклы (nested loops) и сортировка-слияние (sort merge). Эти методы очень эффективны, но дают плохую производительность при определенных условиях, обычно существующих в приложениях хранилищ данных и OLAP-приложениях.
В версии 7.3 Oracle предложила соединения по схеме "звезда" и хеш-соединения. Оптимизатор запросов может развертывать их раздельно или вместе.
Соединение по схеме "звезда" ориентировано на запросы, где центральная таблица фактов соединяется с несколькими справочными таблицами, каждая из которых может соединяться с таблицей фактов, но никогда не соединяется с другими справочными таблицами. Соединение по схеме "звезда" нацелено на использование именно такого отсутствия взаимосвязей — сначала формируется декартово произведение всех нужных строк из справочных таблиц, а затем выполняется его соединение с таблицей фактов. Соединения по схеме "звезда" особенно уместны в приложениях для хранилищ данных.
Операцию соединения, в зависимости от объемов данных, может оказаться эффективнее провести как хеш-соединение, при котором Oracle пытается использовать методы хеширования в качестве альтернативы традиционной технике, основанной на полной сортировке каждого из отношений с последующим слиянием данных.
В некоторых приложениях соединения по схеме "звезда" реализовывали вручную путем построения декартова произведения в промежуточной таблице. Они обеспечивают значительный выигрыш в производительности по сравнению с неуклюжим подходом, который используется оптимизатором Oracle.
Архитектура сетевых вычислений
По мере усовершенствования сетевых продуктов Oracle их коммуникационные возможности расширялись, и сейчас эти продукты обеспечивают не только выполнение SQL-предложений на сервере, но и передачу удаленных вызовов процедур.
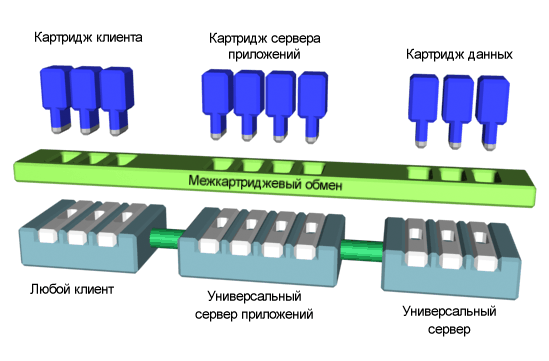
В рамках новой архитектуры — Network Computing Architecture (Архитектура Сетевых Вычислений, рис. 2.1) Oracle опубликовала ряд стандартных интерфейсов, позволяющих картриджам, или именованным сервисам, делать запросы и отвечать на запросы, поступающие из других картриджей. Эти картриджи, которые могут включать относительно традиционные клиенты и серверы, формально не организованы в иерархию, но каждый из них взаимодействует с общим связующим уровнем. Здесь просматривается четкая аналогия с World Wide Web и, действительно, в качестве одного из языков для создания картриджей поддерживается Java. Следует также ожидать, что Oracle будет продвигать свой сетевой компьютер (Network Computer, NC) как основной пользовательский интерфейс для выполнения картриджей, написанных на Java.
Вероятно, еще более интересна для проектировщиков (которые ищут, как удовлетворить сложные требования к серверу в среде Oracle) возможность использовать PL/SQL-вызовы для выполнения запросов к другому картриджу. Этот механизм к моменту написания книги был совершенно нов, и у нас не было возможности построить что-нибудь с его помощью. Но кажется, что он предоставляет гибкий метод вызова любого картриджа из Oracle. Традиционно эти возможности проектирования были ограничены вызовом других экземпляров Oracle средствами SQL или PL/SQL и обращениями к другим СУБД через прозрачные шлюзовые сервисы Oracle.
Многие фирмы стали партнерами Oracle по разработке картриджей различных типов, и мы с большим интересом следим за развитием событий в этой области. Мы уверены, что при подготовке второго издания этой книги у нас будет что сказать о мерах, которые обеспечивают эффективное использование картриджей данных, а также о затратах и выгодах, связанных с новыми возможностями Огас1е8.
Об Оrасlе8
Многие специалисты по Oracle ожидали, что Oracle анонсирует Oracle8 на объединенной конференции Oracle Open World и International Oracle User Group в Сан-Франциско в ноябре 1996 г., однако представители корпорации сделали на этой конференции очень мало официальных заявлений о содержании Огас1е8 и времени ее выхода в свет. Oracle подтвердила, что у ряда клиентов и партнеров имеются бета-версии. Однако мы знаем, что промышленная версия программы может заметно отличаться от бета-версий (которые также могут существовать в различных вариациях). Редко, но бывает, что уже включенные в систему средства исчезают затем вследствие отрицательного опыта их эксплуатации. Чаще же функции системы подвергаются существенным изменениям после пользовательских опытов в ходе бета-тестирования. По этой причине мы не рекомендуем принимать проектные решения на основании бета-кода.
Эти замечания могут оказаться особенно важными в отношении Огас1е8, которая содержит новые функции, нацеленные главным образом на поддержку гораздо больших баз данных по сравнению с нынешними. Кроме того, все давно ждут, что в новой версии будет реализована некоторая поддержка объектной ориентации (00) в SQL.
Секционирование
Самая важная из анонсированных особенностей Огас1е8 — возможность объявлять таблицу, секционированную по ключу. Таблица, секционированная по ключу, — это структура, в которой логическая таблица определена в виде набора столбцов и ограничений, а затем определены несколько физических секций для хранения строк, причем каждая секция соответствует определенному диапазону значений ключа секционирования. В нашей книге мы часто описываем приемы, которые можно применять в Oracle7 для того, чтобы воспользоваться преимуществами секционированных таблиц, но, естественно, лучше, когда они непосредственно поддерживаются сервером. Главная цель — сделать единицей восстановления секцию, а не таблицу, а также дать возможность оптимизатору использовать секционные индексы.
Предупреждаем: здесь возникает серьезный вопрос об уникальных ключах, которые нужно вводить на уровне таблицы, а не на уровне секции. Если ключ секционирования (поле, определяющее, в какой секции хранится строка) входит как в первичный ключ, так и во все другие уникальные ключи, то проблема не стоит остро. В противном случае для обеспечения уникальности необходим индекс табличного уровня.
Проектировщикам — уже не в первый раз — нужно быть готовыми к поиску компромисса. В данном случае им придется выбирать между недостатками индекса табличного уровня (время создания, использование пространства, одна точка отказа для всех секций) и риском нарушения целостности данных из-за его отсутствия.
Совместимость с
Oracle7
Единственная серьезная потенциальная проблема совместимости, о которой мы в настоящее время знаем, — это то, что формат идентификатора строки изменился настолько, что сейчас, по сути, есть две его формы. Краткая форма — это все, что нужно для ссылки на строку именованной таблицы, а длинная форма позволяет однозначно идентифицировать любую строку в базе данных.
Несмотря на то, что эти изменения почти наверняка сделают бесполезными большое количество скриптов, написанных администраторами БД, лишь немногие приложения основываются на внутренней структуре идентификатора строки. Краткая форма (которой вполне хватает для SELECT ROWID...FOR UPDATE) умещается в 18 байтах, которые должны были выделяться для старой формы. Хотелось бы отметить, что все приложения, использующие внутренний формат идентификатора строки, не заслуживают переноса в Огас1е8.
Но...
Повторим то, что мы сказали в начале этого небольшого раздела, посвященного Огас1е8: хотя эти и многие другие возможности, на первый взгляд, выглядят очень привлекательно, перед тем как принимать решение об использовании их в проекте, нужно предпринять целый ряд мер. Как минимум, применять их в приложении промышленного уровня можно лишь после того, как Oracle введет их в промышленную версию. Кроме того, для адекватного прогнозирования результатов их использования компьютерная индустрия должна накопить опыт работы с этими средствами в реальных условиях.
Что сказать о материале по Oracle7, который содержится в этой книге? Устареет ли он с выходом Огас1е8? Нам кажется, что ненужным станет лишь незначительная его часть. Надеемся, впрочем, что новые возможности помогут найти новые решения для ваших проблем проектирования.
* Тем не менее, Стивен Фойерштейн делал с этим языком потрясающие вещи. См. Oracle PL/SQL Programming (O'Reilly & Associates, 1995) и Advanced Oracle PL/SQL Programming with Packages (1996).
Знаете ли Вы, что диаграмма компонентов, Component diagram - это метод объектно-ориентированного проектирования, описывающий особенности физического представления системы. Диаграмма компонентов позволяет определить архитектуру разрабатываемой системы, устанавливая зависимости между компонентами.