
Ваш электронный магазин предлагает великолепные товары по конкурентоспособным ценам — что еще можно сделать, чтобы посетители возвращались на ваш сайт снова и снова? В идеале, ваша домашняя страница должна быть настолько интересной, чтобы люди «приходили» на нее просто для того, чтобы посмотреть, что происходит.
Вы, вероятно, замечали, что в последние годы многие сайты включают в свои домашние страницы заголовки новостей, пытаясь заинтересовать пользователей и привлечь их к посещению сайта. На этих сайтах новости не создаются — они заимствуются у различных web-служб, предназначенных для синдицирования (syndicating) и распространения информации; в этой лекции мы покажем, как вы можете воспользоваться этими службами.
Мы также рассмотрим различные типы источников новостей, доступных в Интернете. Кроме того, вы найдете здесь пример кода для загрузки форматированных с помощью XML заголовков новостей с одного из самых крупных их источников. Когда файлы XML загружены, следующим этапом является создание класса Java, с помощью которого организуются эффективный поиск и выборка новостей. Наконец, мы приводим примеры того, как генерируется код HTML для форматирования заголовков.
Вероятно, вы знакомы с идеей синдицирования в мире средств массовой информации. Корреспонденты, авторы передовиц и карикатуристы печатаются не только в своей родной газете, но и в газетах, которые заключили с ними контракт на право опубликования их работ. Синдицирование открывает перед газетой огромные возможности по публикации сообщений без вложения больших средств.
В мире печатных средств массовой информации фактическое содержание сообщения распространяется среди различных изданий; читатель, открывая газету, ожидает увидеть напечатанным полный текст сообщения, будь то хроника происшествий или комикс. Создатель сообщения получает небольшой гонорар, организацией оплаты занимается соответствующее агентство, приобретающее информацию и продающее ее различным газетам для одновременной публикации.
Однако в Интернете, где пользователь может легко переходить с одной страницы на другую, синдицированию подлежит лишь сам факт того, что где-то существует определенный ресурс. Создатель этого ресурса может синдицировать его заголовок, снабженный ссылкой на полный текст сообщения. Тогда заинтересованные в этой информации люди будут попадать на его сайт по ссылке на данное сообщение и попутно читать объявления или узнавать о товарах, которые можно заказать на этом сайте.
Компания Netscape первой предложила идею создания страниц новостей, поступающих из различных источников, на сайте Netscape Netcenter (www.netscape.com) и разработала специальный формат Rich Site Summary (RSS) для упрощения этого процесса. Идея состоит в том, что новости, размещенные на сотрудничающих с Netscape Netcenter web-сайтах, записываются в специальном едином для всех сайтов формате и автоматически становятся доступными на сайте Netscape Netcenter. Такой подход сделал сайт Netscape одним из наиболее популярных порталов в Интернете.
Основанный на XML формат RSS (иногда называемый также RDF Site Summary — Resource Description Framework Site Summary, стандарт на описание ресурсов) до сих пор является одним из основных форматов для распространения новостей в Интернете. Тот сайт, где фактически создается сообщение, формирует файл ресурса (feed) в формате RSS, определяя канал новостей (news channel). Этот файл должен быть выложен на открытый web-сайт, где он автоматически становится доступным для других сайтов, с которыми заключены соответствующие соглашения. Инструкции по созданию собственного канала новостей вы можете получить по адресу: http://my.netscape.com/publish/help/quickstart. Большой web-сайт, который каждый час обновляет заголовки новостей, поступающих по различным каналам, может оказаться очень привлекательным для многих посетителей. В качестве примера вы можете попробовать заглянуть на сайт http://my.userland.com (но будьте осторожны: вы можете провести там гораздо больше времени, чем планировали!).
Примером технически ориентированного сайта, подключенного к каналам RSS, является система Meerkat (www.oriellynet.com/meerkat).
Международный совет по медиа-телекоммуникациям (The International Press Telecommunications Council, IPTC), представленный по адресу www.iptc.org, предпринимает попытки создать на основе XML стандарт кодирования, который упростил бы процесс составления, передачи и получения информационных сообщений. Во время написания этого курса была выпущена версия 1.0 этого стандарта, названного NewsML.
Возможности этого стандарта по сравнению со стандартом RSS весьма широки. Например, он включает в себя различные мультимедийные элементы и предусматривает явные связи между сообщениями.
Поскольку в совет IPTC входит большое количество организаций, многие из которых зарабатывают на информационных сообщениях, при создании стандарта сталкивается множество различных интересов. Если NewsML утвердится в качестве стандарта, описанные в этой лекции методики по-прежнему будут применимы.
Для задач, которые решаются в этой лекции, мы используем формат импорта и экспорта сообщений, предложенный организацией Moreover.com (www.moreover.com). Мы выбрали Moreover.com для рассказа о технологиях обмена новостями по причине простоты используемого формата и большого количества тематических категорий на сайте. Разумеется, в пользу этого формата говорит и то, что он распространяется свободно.
Хотя организация Moreover.com была создана только в декабре 1999, к июлю 2000 она получала заголовки с 1500 сайтов. Программное обеспечение, занимающееся сбором заголовков новостей, автоматически разделяет их на более чем 250 категорий.
Формат, используемый Moreover.com, проще RSS и выдает только сами заголовки. Для индивидуальной настройки импорта информационных сообщений нужно зарегистрироваться в системе, сообщив свой электронный адрес и пароль, а затем выбрать нужные тематические категории и указать количество заголовков сообщений, которые вы хотели бы увидеть. На рис. 9.1 показана небольшая часть страницы, на которой происходит выбор тематических категорий.
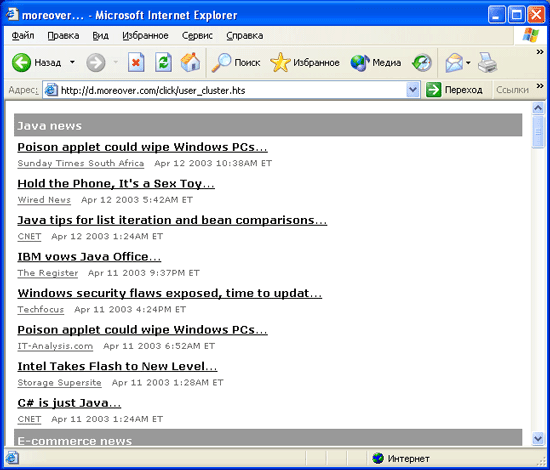
Рис. 9.1. Выбор категорий заголовков на сайте Moreover.com
Первым этапом процесса настройки вашего web-сайта на использование материалов информационных web-синдикатов является получение исходного файла XML от поставщика. В нашем примере мы обращаемся на сайт www.moreover.com, указывая параметр поиска, который генерирует данные по нашим заранее выбранным категориям сообщений. Ниже приведен полный URL-адрес:
www.moreover.com/cgi-local/page?wbrogden@bga.com+xml
После получения доступа к этому ресурсу на сервере Moreover.com специальное приложение возвращает текстовый поток в формате XML, содержащий заголовки по выбранным темам. В листинге 9.1 показаны заголовок и первый элемент в том виде, в котором они были исходно получены при загрузке файла XML. Обратите внимание на то, что строка DOCTYPE ссылается на определение DTD, расположенное на сайте Moreover.com. Чтобы обеспечить возможность анализа файла XML во время тестирования без доступа к web-сайту Moreover.com, класс XMLgrabber модифицирует строку DOCTYPE так, чтобы она ссылалась на определение DTD как на локальный файл.
Листинг 9.1. Заголовок и первый элемент загруженного файла XML (xmldump.xml)1
<?xml version="1.0" encoding="iso-8859-1"?> <!DOCTYPE moreovernews SYSTEM "moreovernews.dtd"> <moreovernews> <article id="_8510757"> <url>http://c.moreover.com/click/here.pl?x8510756</url> <headline_text>Cyclone Commerce Poised to Fulfill Promise of E-Signature Legislation</headline_text> <source>Java Industry Connection</source> <media_type>text</media_type> <cluster>Java news</cluster> <tagline> </tagline> <document_url> http://industry.java.sun.com/javanews/more/hotnews/ </document_url> <harvest_time>Jul 25 2000 8:34AM</harvest_time> <access_registration> </access_registration> <access_status> </access_status> </article>
Обратите внимание, что элемент, который в Moreover.com называется cl uster, идентифицирует основную тематическую категорию, к которой относится данное сообщение. В приведенном ниже примере сервлета мы используем только элементы url, headline_text, source и cluster. Определение DTD moreovernews, как видно из листинга 9.2, устроено относительно просто.
Листинг 9.2. Файл moreovernews.dtd (moreovernews.dtd)
<!ELEMENT moreovernews (article*)> <!ELEMENT article (url,headline_text,source,media_type, cluster,tagline,document_url,harvest_time, access_registration,access_status)> <!ATTLIST article id ID #IMPLIED> <!ELEMENT url (#PCDATA)> <!ELEMENT headline_text (#PCDATA)> <!ELEMENT source (#PCDATA)> <!ELEMENT media_type (#PCDATA)> <!ELEMENT cluster (#PCDATA)> <!ELEMENT tagline (#PCDATA)> <!ELEMENT document_url (#PCDATA)> <!ELEMENT harvest_time (#PCDATA)> <!ELEMENT access_registration (#PCDATA)> <!ELEMENT access_status (#PCDATA)>
Сервлет, который используется в рассматриваемом в этой лекции приложении, включает в себя класс NetNewsSuper. Этот класс запускает поток Thread, который создает объект XMLgrabber для загрузки файла с наиболее свежими заголовками новостей, а также текущий файл DTD. В листинге 9.3 показано начало этого класса, в том числе его конструктор. Заметим, что конструктор снабжен URL- адресом искомого ресурса, а также содержит путь и имя файла, который будет использоваться для локальной копии.
Листинг 9.3. Начало класса XMLgrabber (XMLgrabber.java)
package com.XmlEcomBook.Chap09;
import java.net.* ; import java.io.* ; import java.util.*;
public class XMLgrabber
{
String source ; // complete URL to run std query
// example
"http://www.moreover.com/cgi-local/
page?wbrogden@bga.com+xml";
String saveDir ; // for both temp and final xml file
String tfnxml ; // temp file name - see createTempXmlWriter
String tfndtd ; // temp file name for dtd
String saveName ; // for xml
String dtdURL ; // complete DTD url from <!DOCTYPE line
String dtdFname ; // for dtd
PrintWriter pw ; URL theURL ; Thread queryT ;
// all files from a given source will go to dest directory
XMLgrabber( String src, String dest, String fname ){
source = src ;
saveDir = dest ;
saveName = fname ;
// System.out.println("XMLgrabber initialized for " + src );
}
Поскольку мы не можем всегда рассчитывать на быстрое соединение с сайтом Moreover.com и так как в некоторых случаях попытка получить новые данные может провалиться, получение данных XML осуществляется отдельным от функций сервлета потоком (объектом Thread). Более того, файл со старыми данными не заменяется сразу же новым файлом; вместо этого полученные данные записываются во временный файл. Только когда мы удостоверимся, что полученный файл XML содержит все необходимые данные, мы удаляем старый файл и присваиваем имя временному файлу. Как показано в листинге 9.4, метод doQueryNow создает структуру для получения наиболее свежей информации. Помимо получения файла XML, содержащего заголовки сообщений, мы также пытаемся получить самое последнее определение DTD.
Листинг 9.4. Метод doQueryNow (XMLgrabber.java)
// run by external Thread to get file resident
// return true if suceeds
public boolean doQueryNow() throws IOException {
theURL = new URL( source );
createTempXmlWriter();
grabXml();
if( !renameTemp( tfnxml, saveName )) return false ;
tfnxml = null ;
// now for the dtd
if( dtdURL == null ) return true ;
// System.out.println("Start DTD retrieval");
theURL = new URL( dtdURL );
createTempDtdWriter();
grabDtd();
boolean ret = renameTemp( tfndtd,dtdFname );
tfndtd = null ;
return ret ;
}
Существует несколько возможных ситуаций, в которых этот метод дает сбой: либо в случае, когда при попытке получить доступ к исходному файлу возникает исключение lOException, либо в случае неполадок с локальной файловой системой. Чтобы не загромождать локальный диск временными файлами, которые были созданы, но не прошли надлежащей обработки, для работы с файлами tfnxml и tfndtd разработана специальная методика.
Файл tfnxml создается при вызове метода createTempXmlWriter. Заметим, что если не возникнет исключительных ситуаций и переименование файла tfnxml в saveName пройдет успешно, переменная tfnxml устанавливается равной null. В противном случае метод finalize (листинг 9.9) попытается удалить временный файл. Файл tfndtd, предназначенный для загрузки DTD, проходит такую же обработку.
В листинге 9.5 показаны методы объекта XMLgrabber, которые применяются для создания и управления временными файлами.
Листинг 9.5. Методы для управления временными файлами (XMLgrabber.java)
// saveDir used for all
private boolean renameTemp(String tmp, String saveN ) {
File src = new File( saveDir, tmp );
File dest = new File( saveDir, saveN);
dest.delete();
return src.renameTo( dest );
}
private void createTempXmlWriter() throws IOException {
tfnxml = "$" + Integer.toString((int) System.currentTimeMillis())
+ ".xml";
File tfile = new File( saveDir, tfnxml );
while( tfile.exists() ){ // hunt for unique name
tfnxml = tfnxml + "X" ;
tfile = new File( saveDir, tfnxml );
}
// ok, unique file name in tfnxml, File tfile set up
FileWriter fw = new FileWriter( tfile.getAbsolutePath() );
pw = new PrintWriter( fw );
}
private void createTempDtdWriter() throws IOException {
tfndtd = "$" + Integer.toString((int) System.currentTimeMillis())
+ ".dtd";
File tfile = new File( saveDir, tfndtd );
while( tfile.exists() ){ // hunt for unique name
tfndtd = tfndtd + "X" ;
tfile = new File( saveDir, tfndtd );
}
// ok, unique file name in tfndtd, File tfile set up
FileWriter fw = new FileWriter( tfile.getAbsolutePath() );
pw = new PrintWriter( fw );
}
Как показано в листинге 9.6, метод grabXml считывает строки текста из входного потока, создав соединение по нужному URL-адресу. Строка заголовка XML, содержащая ссылку на файл DTD, переформатируется методом reformDoctype, который заменяет URL на имя локального файла. Это делается для того, чтобы гарантировать, что синтаксический анализ файла XML будет проходить независимо от соединения с Интернетом.
Листинг 9.6. Метод grabXML считывает строки файла XML из заданного с помощью URL источника (XMLgrabber.java)
// at this point pw is open to a temp file
private void grabXml() throws IOException {
URLConnection urlC = theURL.openConnection();
urlC.setUseCaches( false );
urlC.setAllowUserInteraction(false);
urlC.connect();
InputStream is = urlC.getInputStream();
InputStreamReader isr = new InputStreamReader(is);
BufferedReader br = new BufferedReader( isr );
String tmp = br.readLine() ;
while( tmp != null ){
tmp = tmp.trim();
if( tmp.startsWith("<!DOCTYPE") ) {
// change to use local copy
tmp = reformDoctype( tmp );
}
pw.println( tmp );
tmp = br.readLine();
}
pw.close(); // does a flush()
}
В предположении, что метод ref ormDoctype корректно задает переменную dtdURL, метод grabDtd, показанный в листинге 9.7, загружает DTD в локальный временный файл. В этом листинге также показан служебный метод createURL, который устанавливает значение переменной экземпляра theURL.
Листинг 9.7. Метод grabDtd получает текущее определение moreovernews.dtd (XMLgrabber.java)
// at this point pw is open to a temp file for dtd
private void grabDtd() throws IOException {
System.out.println("grabDtd:" + dtdURL );
URLConnection urlC = theURL.openConnection();
urlC.setUseCaches( false );
urlC.setAllowUserInteraction(false);
urlC.connect();
InputStream is = urlC.getInputStream();
InputStreamReader isr = new InputStreamReader(is);
BufferedReader br = new BufferedReader( isr );
String tmp = br.readLine() ;
while( tmp != null ){
pw.println( tmp.trim() );
tmp = br.readLine();
}
pw.close(); // does a flush()
//System.out.println("grabDtd OK");
}
private boolean createURL(String str){
try {
theURL = new URL( str );
return true ;
}catch(MalformedURLException e){
return false ;
}
}
Как показано в листинге 9.8, метод reformDoctype извлекает ссылку на файл DTD из строки DOCTYPE, а затем устанавливает значения переменных dtdURL и dtdFname.
Листинг 9.8. Метод reformDocType модифицирует ссылку на DTD (XMLgrabber.java)
// string has doctype declaration, revise to
//point to local version
private String reformDoctype( String dts ){
int p1 = dts.indexOf( "http:"); // points at h
if( p1 < 0 ) return dts ;
//
int p2 = dts.indexOf( '"', p1 );
int p3 = dts.lastIndexOf('/', p2);
if( p3 < 0 ) return dts ;
dtdURL = dts.substring( p1 , p2 );
dtdFname = dts.substring( p3 + 1, p2 );
// System.out.println("DTD url:" + dtdURL + "<");
// System.out.println("DTD fname:" + dtdFname + "<");
String tmp = dts.substring(0,p1); // includes "
return tmp + dts.substring( p3 + 1 );
}
Так как процесс загрузки в некоторых точках может быть прерван, существует опасность накопления пустых или частично записанных временных файлов. Метод finalize, как показано в листинге 9.9, пытается удалить эти файлы, если они существуют. Если все идет нормально, переменные tfnxml и tfndtd должны содержать null и тогда попытки удалить временные файлы не происходит.
Листинг 9.9. Метод finalize может удалять временные файлы (XMLgrabber.java)
// last chance to clean up temp files if something failed
public void finalize(){
if( tfnxml != null ){
new File( saveDir, tfnxml ).delete();
}
if( tfndtd != null ){
new File( saveDir, tfndtd ).delete();
}
}
}
Теперь, когда файл XML и соответствующий файл DTD находятся на локальном жестком диске, нам нужен класс для синтаксического анализа файла XML и создания DOM. Написанный нами для ^того класс называется NewsModel; он создает коллекции элементов в соответствии с типом содержимого, или, если использовать терминологию Moreover.com, кластеры (clusters). В классе NewsModel предусмотрены также методы для извлечения и форматирования отдельных элементов.
В листинге 9.10 показано начало класса NewsModel, включая переменные экземпляра и конструктор. Обратите внимание на то, что здесь присутствуют две коллекции, Hashtable и Nodelist, которые будут «заселены» элементами article, когда завершится создание DOM. Конструктору просто передаются параметры, содержащие путь и имя файла XML. В зависимости от того, какой анализатор XML вы используете, вам может потребоваться несколько изменить инструкции импорта и метод loadXML, показанный в листинге 9.11, но остальные методы должны работать с любым анализатором, потому что они используют интерфейсы org.w3c.dom.
Листинг 9.10. Начало класса NewsModel (NewsModel.java) package com.XmlEcomBook.Chap09;
package com.XmlEcomBook.Chap09;
import java.io.* ; import java.util.* ; import com.sun.xml.tree.* ; import com.sun.xml.parser.Resolver ; import org.xml.sax.* ; import org.w3c.dom.* ;
public class NewsModel
{
long timestamp ;
public String dateStr ;
Document doc ;
String path, fname ;
public boolean usable ;
public String lastErr ="no error";
// see locateCategories for creation of following
Hashtable clusterHash ;
NodeList articleNodeList ;
public NewsModel( String pth, String fn ){
path = pth ; fname = fn ;
}
Процесс синтаксического анализа контролируется методом loadXML, как показано в листинге 9.11. Заметьте, что (для сохранения максимально полной информации по отладке) исключения SAXParseException перехватываются по отдельности и подробная информация о причинах возникновения исключения сохраняется в переменной lastErr. Хотя документы XML, содержащиеся на сайте Moveover.com, обычно правильно оформлены, у нас был один случай неправильно оформленного документа — в нем содержался недопустимый символ. В этом случае подробная информация о причинах исключительной ситуации при синтаксическом анализе оказалась очень ценной.
Листинг 9.11. Метод loadXML осуществляет синтаксический анализ (NewsModel.java)
// return true if sucessful - if false, see lastErr
public synchronized boolean loadXML( ) {
File xmlFile = new File( path, fname );
System.out.println("NewsModel.loadXML start " +
xmlFile.getAbsolutePath() );
try {
timestamp = xmlFile.lastModified();
dateStr = new Date( timestamp ).toString();
InputSource input = Resolver.createInputSource( xmlFile );
// ... the "false" flag says not to validate (faster)
// XmlDocument is in the com.sun.xml.tree package
doc = XmlDocument.createXmlDocument (input, false);
System.out.println("Created document");
usable = true ;
return true ;
}catch(SAXParseException spe ){
StringBuffer sb = new StringBuffer( spe.toString() );
sb.append("\n Line number: " + spe.getLineNumber());
sb.append("\nColumn number: " + spe.getColumnNumber() );
sb.append("\n Public ID: " + spe.getPublicId() );
sb.append("\n System ID: " + spe.getSystemId() + "\n");
lastErr = sb.toString();
System.out.print( lastErr );
return false ;
}catch( SAXException se ){
lastErr = se.toString();
System.out.println("loadXML threw " + lastErr );
se.printStackTrace( System.out );
return false ;
}catch( IOException ie ){
lastErr = ie.toString();
System.out.println("loadXML threw " + lastErr +
" trying to read " + xmlFile.getAbsolutePath() );
return false ;
}
} // end loadXML
Если анализ XML завершился успешно и была создана объектная модель документа, вызывается метод locateCategories. Как показано в листинге 9.12, этот метод получает NodeList — список всех элементов article, и записывает его в переменную articleNodeList. Затем он вызывает метод processArticle для каждого элемента. Метод processArticle строит вектор элементов для каждого значения элемента cluster. Это как раз тот вектор, который выдает заголовки сообщений, если в запросе пользователя указана конкретная тематика.
Листинг 9.12. Метод locateCategories классифицирует заголовки (newsModel.java)
public void locateCategories(){
Element dE = doc.getDocumentElement(); // the root element
clusterHash = new Hashtable();
articleNodeList = dE.getElementsByTagName("article");
int act = articleNodeList.getLength();
//System.out.println("Article count: " + act );
for( int i = 0 ; i < act ; i++ ){
Element aE = (Element) articleNodeList.item( i ) ;
processArticle( aE );
}
}
private void processArticle( Element artE ){
NodeList clusterNL =
artE.getElementsByTagName("cluster");
if( clusterNL.getLength() == 0 ) return ;
Element clE = (Element)clusterNL.item(0);
String clusterStr = clE.getFirstChild().getNodeValue().trim() ;
// System.out.println("cluster ct " + clusterNL.getLength() +
// " value: " + clusterStr );
Object obj = clusterHash.get( clusterStr );
Vector v = null ;
if( obj == null ){
v = new Vector();
clusterHash.put( clusterStr, v );
}
else {v = (Vector)obj ;
}
v.addElement( artE );
}
Теперь мы подошли к рассмотрению методов сервлета, которые отвечают на запросы пользователя о поиске определенных заголовков сообщений. Для нашего примера мы ограничились двумя методами выбора заголовков: вы можете либо просмотреть всю коллекцию в поисках заголовков, которые содержат определенную последовательность символов, либо извлечь все заголовки, входящие в конкретную категорию.
При вызове метода articlesByKeyword, показанного в листинге 9.13, ему передается строка, содержащая одну или более последовательностей символов, разделенных запятыми. Первый шаг заключается в преобразовании этой строки keystring в массив типа String. Этот шаг выполняется методом prepKeys, который, кроме того, переводит все символы в верхний регистр. Далее метод searchArticle осуществляет поиск по всем элементам article и все совпадения возвращаются в виде массива ссылок на соответствующие элементы.
Листинг 9.13. Метод articlesByKeyWord вызывается сервлетом (NewsModel.java)
// articles by keyword appearance in headline
// keys may be word or phrase, one or more, sep by comma
// just use original order
public Element[] articlesByKeyWord( String keystring ){
String[] keys = prepKeys( keystring );
// upper case and separated
Vector v = new Vector();
int i ;
int ct = articleNodeList.getLength();
for( i = 0 ; i < ct ; i++ ){
Element aE = (Element) articleNodeList.item( i ) ;
if( searchArticle( aE, keys )){
v.addElement(aE);
}
}
Element[] ret = new Element[ v.size() ];
for( i = 0 ; i < ret.length ; i++ ){
ret[i] = (Element) v.elementAt(i);
}
return ret ;
}
// convert to upper case and separate at commas
private String[] prepKeys( String s ){
StringTokenizer st =
new StringTokenizer( s.toUpperCase(), ",");
String[] ret = new String[ st.countTokens() ];
int i = 0 ;
while( st.hasMoreTokens() ){
ret[i++] = st.nextToken().trim();
}
return ret ;
}
Метод searchArticle, как показано в листинге 9.14, сложнее, чем вы, возможно, ожидали. Это объясняется некоторыми особенностями анализатора XML. Рассмотрим содержимое элемента <headline_text>, куда включена сущность (например, &атр;):
<headline_text>Q&A: Will Sony I
Rule the Digital World</ I headline_text>
Эта строка будет разделена анализатором на три объекта Node: два текстовых узла, разделенных узлом EntityReference. Так как нам нужен полный текст заголовка, для получения соответствующей строки вызывается метод getFullText, выдающий текст заголовка целиком.
Метод getFullText, который также показан в листинге 9.14, объединяет текст всех частей заголовка. Текст, представляющий узел EntityReference, должен быть построен как объединение с символами ; и & имени узла.
Листинг 9.14. Методы, которые поддерживают поиск заголовков по ключевым словам (NewsModel.java)
// return true if one of the keys appears
//in the headline_text element
private boolean searchArticle( Element aE, String[] keys ){
NodeList htNL =
aE.getElementsByTagName("headline_text");
if( htNL.getLength() == 0 ) return false ;
// there is only one headline_text
Element htE = (Element)htNL.item(0);
String str = getFullText( htE ).toUpperCase() ;
for( int i = 0 ; i < keys.length ; i++ ){
if( str.indexOf( keys[i] ) >= 0 ) return true ;
}
return false ;
}
// this is needed to cope with headline text that has entities
private String getFullText( Node nd ){
NodeList nl = nd.getChildNodes();
int ct = nl.getLength();
if( ct == 0 ) return "";
if( ct == 1 ) return nd.getFirstChild().getNodeValue();
StringBuffer sb = new StringBuffer();
for( int i = 0 ; i < ct ; i++ ){
Node n = nl.item(i);
if( n instanceof EntityReference ){
// reconstruct & notation
sb.append( '&' ); sb.append( n.getNodeName());
sb.append( ';' );
}
else {
sb.append( n.getNodeValue() );
}
}
return sb.toString();
}
Метод locateCategories (см. листинг 9.12) создал коллекцию clusterHash, в которой элементы (заголовки сообщений) хранятся в соответствии со своими тегами <cluster>. Мы не совсем понимаем, почему в Moreover.com этот элемент называется cluster (кластер) — нам кажется, что более подходящим названием для этого тега было бы topic (тема); поэтому метод, приведенный в листинге 9.15, называется articlesByTopic (статьи по темам). В этом листинге также показан метод getAllTopics, который просто превращает весь список узлов articleNodeList в массив типа Element.
Листинг 9.15. Этот метод возвращает все элементы с заданным значением элемента cluster (NewsModel.java)
// return array of Element for this topic
// or null if none available
public Element[] articlesByTopic( String topic ){
Vector v = (Vector) clusterHash.get( topic );
if( v == null ) return null ;
Element[] ret = new Element[ v.size() ];
for( int i = 0 ; i < ret.length ; i++ ){
ret[i] = (Element) v.elementAt( i );
}
return ret ;
}
public Element[] getAllTopics(){
int ct = articleNodeList.getLength();
Element[] ret = new Element[ ct ];
for( int i = 0 ; i < ct ; i++ ){
ret[i] = (Element)articleNodeList.item( i );
}
return ret ;
}
Чтобы пользователь мог выбирать темы сообщений, нам нужно иметь список всех тем, имеющихся в текущей модели DOM. Для создания списка тематических категорий применяется класс NetNewsBean, который мы и будем рассматривать ближе к концу этой лекции. В этом классе используется массив типа String, который создается в методе getTopics, приведенном в листинге 9.16. Обратите внимание на то, что для сортировки объектов Srting в данном массиве необходим метод shell Sort, потому что порядок следования ключей в хэш-таблице непредсказуем.
Листинг 9.16. Метод getTopics (NewsModel.java)
// return exact names of all topics available
public String[] getTopics(){
Enumeration keys = clusterHash.keys();
String[] ret = new String[ clusterHash.size() ];
int i = 0;
while( keys.hasMoreElements() ){
ret[i++] = (String)keys.nextElement();
}
shellSort( ret );
return ret ;
}
Метод formatElement, показанный в листинге 9.17, предлагает простой способ вставить текст из объекта art (который соответствует некоторому заголовку) в строку, обычно содержащую информацию относительно разметки HTML. Ниже приводится пример такой форматирующей строки, в которой содержатся теги, показывающие, куда нужно вставить элементы url, headline_text и source:
<tr><td><a href="<%url>"x%headline_text> </a> " from <%source></ tdx/tr>
Работа этого метода заключается в отыскании символов <%, выделении имени элемента и вызове метода getContent для извлечения текста элемента из соответствующего объекта Element. Заметим, что метод getContent вызывает метод getFullText для получения полного текста выбранного элемента.
Листинг 9.17. Метод formatElement (NewsModel.java)
// Element known to be an article, formatting string
public String formatElement( Element art, String fmt ){
StringBuffer sb = new StringBuffer( 3 * fmt.length() );
int p0 = 0 ;
int p1 = fmt.indexOf("<%");
int p2 = fmt.indexOf('>', p1);
while( p1 > p0 && p2 > p1 ){
sb.append( fmt.substring( p0, p1 ));
sb.append( getContent( art, fmt.substring(p1 + 2, p2) ));
p0 = p2 + 1 ;
p1 = fmt.indexOf("<%", p0);
if( p1 > p0 ){
p2 = fmt.indexOf('>', p1);
}
}
sb.append( fmt.substring( p0 ));
return sb.toString();
}
// element known to be an article
private String getContent( Element art, String key ){
NodeList nl = art.getElementsByTagName( key );
if( nl.getLength() == 0 ) return "";
Element kE = (Element)nl.item(0);
return getFullText( kE ) ;
}
Последняя часть кода класса NewsModel, приведенная в листинге 9.18, содержит метод she! 1 Sort и некоторые другие служебные методы.
Листинг 9.18. Метод для сортировки и другие служебные методы (NewsModel.java)
public void shellSort (String[] srted ) {
// h is the separation between items we compare.
int h = 1;
while ( h < srted.length ) {
h = 3 * h + 1;
}
// now h is optimum
while ( h > 0 ) {
h = (h - 1)/3;
for ( int i = h; i < srted.length; ++i ) {
String item = srted[i];
int j=0;
for ( j = i - h;
j >= 0 && compare( srted[j], item ) < 0;
j -= h ) {
srted[j+h] = srted[j];
} // end inner for
srted[j+h] = item;
} // end outer for
} // end while
} // end sort
// return -1 if a < b , 0 if equal, +1 if a > b
int compare(String a, String b ){
String aa = a.toUpperCase() ;
String bb = b.toUpperCase() ;
return bb.compareTo( aa ) ;
}
public String toString() {
StringBuffer sb = new StringBuffer( "NewsModel " );
if( !usable ){
sb.append("is not usable due to ");
sb.append( lastErr );
return sb.toString();
}
sb.append("count of articles ");
sb.append( Integer.toString( articleNodeList.getLength()) );
sb.append("Unique clusters " + clusterHash.size() );
sb.append("\n");
Enumeration keys = clusterHash.keys();
while( keys.hasMoreElements() ){
String key = (String)keys.nextElement();
Vector v = (Vector)clusterHash.get( key );
sb.append(" Topic: " ); sb.append( key ) ;
sb.append(" has " ) ; sb.append(Integer.toString( v.size()));
sb.append("\n");
}
return sb.toString();
}
}
Теперь мы переходим к рассмотрению класса, который управляет процессом получения заголовков через определенные промежутки времени и обеспечивает доступ к ним сервлетов. Класс NetNewsSuper устроен согласно обычной схеме единичного класса (singleton). В нем имеются статические переменные и методы, которые гарантируют, что для каждого источника XML (URL-адрес вместе с именами папки и файла) создается только один экземпляр NetNewsSuper. Как показано в листинге 9.19, этот URL-адрес используется в качестве ключа для получения экземпляра NetNewsSuper из хэш-таблицы nnsHash или для его создания, если он еще не существует.
Листинг 9.19. Начало класса NetNewsSuper (NetNewsSuper.java) package com.XmlEcomBook.Chap09;
package com.XmlEcomBook.Chap09;
import java.util.*; import java.io.* ;
public class NetNewsSuper extends java.lang.Thread
{
static Hashtable nnsHash = new Hashtable() ;
static long classLoaded = System.currentTimeMillis();
static long longTime = 1000 * 60 * 60 * 2 ;// two hours
static int maxErrCt = 10 ;
// source is URL + query, dest is abs
//file path, destFname = name
// hash stored by complete source string as key
static synchronized NetNewsSuper
getNetNewsSuper(String source,
String destPth, String destFname ){
NetNewsSuper nns = (NetNewsSuper)nnsHash.get( source );
if( nns == null ){
nns = new NetNewsSuper( source, destPth, destFname ) ;
nnsHash.put( source, nns );
}
return nns ;
}
static synchronized
void removeNetNewsSuper( String sourceURL ){
Object obj = nnsHash.remove( sourceURL );
if( obj == null ){
System.out.println("removeNetNewsSuper of " +
sourceURL + " failed." );
}
else { // allow Thread to die
((NetNewsSuper)obj).running = false ;
}
}
Причина, по который мы сделали класс NetNewsSuper расширением класса Thread, вместо того чтобы реализовать интерфейс Runnable, связана с удобством отладки и управления набором сервлетов. Самое простое — это написать сервлет, который перечисляет все работающие потоки (объекты Thread) в виртуальной машине процессора сервлетов. Вы можете отобразить и имя экземпляра, и результат вызова метода toString.
Как видно из кода конструктора класса, приведенного в листинге 9.20, имя потока устроено таким образом, что включает в себя имя извлекаемого файла. Когда вызывается .конструктор, ему передаются URL-адрес источника, имя папки и имя файла, которые используются для записи данных XML. Поскольку предполагается, что получение нового набора заголовков будет происходить в фоновом режиме, то данный поток получает минимальный приоритет.
Листинг 9.20. Переменные экземпляра и конструктор класса NetNewsSuper (NetNewsSuper.java)
// instance variables and methods follow String sourceURL ; String destPath, destFname ; public String errStr ; public boolean usable ; int errCt = 0 ; boolean running ;
NewsModel newsM ;
private NetNewsSuper
(String source, String dest, String fname ){
sourceURL = source ; destPath = dest ; destFname = fname ;
setName("NetNewsSuper " + fname );
setPriority( Thread.MIN_PRIORITY );
start();
System.out.println("NetNewsSuper Thread started");
}
Как показано в листинге 9.21, первое, что делает метод run, — вызывает метод checkSrc, который проверяет, существует ли уже требуемый файл XML. Если это не так, создается объект класса XMLgrabber и выполняется его метод doQueryNow для получения исходного файла XML. Если файл XML присутствует, то выполняется метод createModel, который создает новый объект NewsModel.
Листинг 9.21. Метод run класса NetNewsSuper (NetNewsSuper.java)
// low priority - check for need to update xml
public void run(){
running = true ;
try { // runs when first started
if( !checkSrc() ){
XMLgrabber grab = new XMLgrabber
( sourceURL, destPath, destFname );
System.out.println("NetNewsSuper runs doQueryNow");
if( !grab.doQueryNow() ){
errCt++ ;
System.out.println
("NetNewsSuper.run - bad return from grab");
}
}
createModel();
}catch(Exception e1){
errCt++ ;
}
while( running ){
try {
sleep( longTime );
XMLgrabber grab = new XMLgrabber
( sourceURL, destPath, destFname );
//System.out.println("NetNewsSuper.run runs doQueryNow");
if( running && grab.doQueryNow() ){
if( errCt > 0 ) errCt-- ;
createModel();
}
else {
errCt++ ;
System.out.println
("NetNewsSuper.run - bad return from grab");
}
}catch(InterruptedException ie){
errCt++ ;
System.err.println("NetNewsSuper.run " + ie );
}catch(Exception ee ){
errCt++ ;
System.err.println("NetNewsSuper.run " + ee );
}
if( errCt > maxErrCt ){
System.out.println
("NetNewsSuper.run too many errors: " + errCt +" run exiting.");
running = false ;
}
}
System.out.println("Leaving NetNewsSuper.run method");
}
// return true if XML source file is found
private boolean checkSrc(){
File f = new File( destPath, destFname );
return (f.exists() && f.canRead());
}
В листинге 9.22 показан метод, который создает новый экземпляр класса NewsModel и затем вызывает методы экземпляра loadXML и locateCategories. В случае ошибки переменная usabl е устанавливается равной fal se.
Листинг 9.22. Этот метод создает новый объект NewsModel (NetNewsSuper.java)
// xml source known to exist, go for it
private synchronized void createModel(){
newsM = new NewsModel( destPath, destFname );
if( !newsM.loadXML()){ // error in getting data
errStr = newsM.lastErr ;
usable = false ;
}
else {
newsM.locateCategories();
usable = true ;
}
}
Как мы увидим при обсуждении в следующем разделе классов NetNewsBean и NetNewsServ и как показано в листинге 9.23, сервлет запрашивает текущую модель NewsModel с помощью метода getNewsModel. Если она отсутствует, что может случиться из-за сбоя в сети, который прерывает нормальную работу метода run, метод getNewsModel делает попытку получить NewsModel заново.
Листинг 9.23. Метод getNewsModel возвращает NewsModel (NetNewsSuper.java)
// Note that there are two steps to getting a news
//model resident:
// 1. grabbing the current XML to local file if not there already
// 2. creating the NewsModel from the local XML
public synchronized NewsModel getNewsModel() throws
Exception {
if( newsM != null ) return newsM ;
// must be newly created NetNewsSuper
if( !checkSrc() ){
XMLgrabber grab = new XMLgrabber( sourceURL, destPath,
destFname );
//System.out.println("getNewsModel runs doQueryNow");
if( !grab.doQueryNow() ){
// System.out.println(" bad return from grab");
return null ;
}
}
// source exists, create model
createModel();
return newsM ; // may or may not be usable
}
Метод toString, как показано в листинге 9.24, предоставляет краткую сводку о текущем состоянии объекта NetNewSuper.
Листинг 9.24. Метод toString (NetNewsSuper.java)
public String toString()
{
StringBuffer sb = new StringBuffer( "NetNewsSuper for ");
sb.append( sourceURL );
if( newsM == null ){
sb.append(" No NewsModel resident ");
}
else {
sb.append(" NewsModel resident, status: " + usable );
}
sb.append(" class loaded: " );
sb.append( new Date( classLoaded ).toString() );
return sb.toString() ;
}
}
Классы для отображения заголовков
Для отображения заголовков мы используем два класса — сервлет с именем NetNewsServ и класс для форматирования NetNewsBean. Существует множество способов задействовать на web-сайте все то, чему мы к этому моменту уже научились. Например, вы можете записывать в базу данных предпочтения каждого посетителя в отношении тематики сообщений и автоматически формировать начальную страницу для данного посетителя с учетом его интересов. Но в нашем случае мы используем более простой подход.
Этот сервлет выполняет две существенные функции: метод doGet создает форму, которая позволяет пользователю выбирать интересующие его темы сообщений и/или задавать ключевые слова, а метод doPost осуществляет сам процесс отображения подходящих заголовков. В листинге 9.25 показано начало кода серв- лета. Чтобы не усложнять наш пример, мы жестко запрограммировали значение переменной queryStr, которая содержит URL для поиска соответствующего ресурса, путь и имя файла XML, а также значение переменной alias с URL-адре- сом сервлета. В реально работающей системе эти переменные будут считываться из файла свойств в методе init.
Листинг 9.25. Начало исходного кода NetNewsServ (NetNewsServ.java)
package com.XmlEcomBook.Chap09;
import java.io.*; import javax.servlet.*; import javax.servlet.http.*;
public class NetNewsServ extends HttpServlet
{
static String version = "1.02 July 26, 2000";
static String queryStr =
"http://www.moreover.com/cgi-local/page" +
"?wbrogden@bga.com+xml";
static String destDir = "e:\\scripts\\netnews" ;
static String queryFile = "xmldump.xml" ;
static String alias = "http://www.lanw.com/servlet/netnews" ;
String keywords = "Amazon,Dell,Microsoft"; String fmt = "<tr><td><a href=\"<%url>\" > <%headline_text></a>" + " from <%source></td></tr>" ;
public void init(ServletConfig config) throws ServletException
{
super.init(config);
}
Метод doGet генерирует простую форму, которая позволяет выбрать одну или несколько тематических категорий и/или ввести ключевые слова. Как показано в листинге 9.26, он получает объект NetNewsBean для определенного источника новостей. Метод getTopicsAsSelect объекта NetNewsBean создает код для отображения списка возможных категорий. Получившаяся в результате страница HTML показана на рис. 9.2.
Листинг 9.26. Метод doGet создает простую форму (NetNewsServ.java)
public void doGet(HttpServletRequest req,
HttpServletResponse resp)
throws ServletException, IOException
{
resp.setContentType("text/html");
PrintWriter out = new PrintWriter(resp.getOutputStream());
out.println("<HTML>");
out.println("<HEAD><TITLE>NetNewsServ Output</TITLE>
</HEAD>");
out.println("<BODY>");
try {
NetNewsBean nnb = new NetNewsBean( queryStr, destDir,
queryFile );
out.println("<h1>The News</h1>");
out.println("<p>Select the general categories you would like
to see. "+ "You can also enter a list of key words or phrases
separated by " + "commas and the system will locate any
headlines containing them.</p>"
);
out.println("<center><form method=\"POST\" action=\"" +
alias + "\" >" );
out.println("Key Words: <input type=\"TEXT\" size=\"60\"" +
" maxlength=\"120\" name=\"keywords\" ><br>");
out.println("Select one or more topics (use <ctrl>click.)
<br>");
out.println( nnb.getTopicsAsSelect() );
out.println("<br>
<input type=\"SUBMIT\" value=\"Continue\" >");
out.println("</form></center><br>");
footer( out );
}catch(Exception e){
errorMsg( out, "NetNewsServ.doGet ", e );
}
}
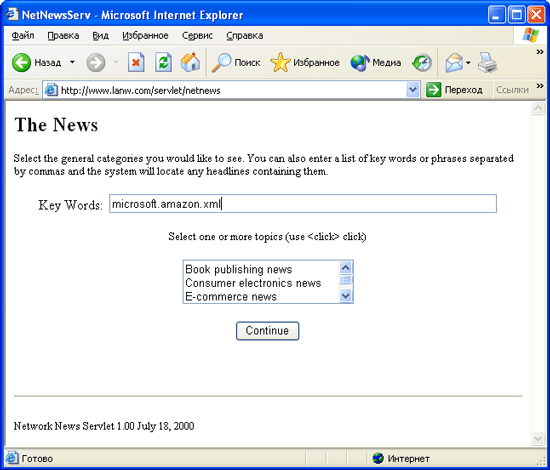
Рис. 9.2. Форма для выбора темы заголовков
Когда пользователь щелкает на кнопке Continue (Продолжить), методу doPost, приведенному в листинге 9.27, отправляется запрос. Если пользователь не ввел никаких ключевых слов и не выбрал никаких категорий в списке, вызывается метод doGet для обновления содержимого формы. В противном случае генерируется страница, содержащая таблицу HTML, строки которой создаются при помощи метода doNetNews. Разумеется, это сильно упрощенный вариант функционирования реального коммерческого сайта.
Листинг 9.27. Метод doPost (NetNewsServ.java)
// assumes response has been set to text/html
private void errorMsg
( PrintWriter out, String msg, Exception ex ){
header( out );
out.println("<h2>Error: " ); out.println( msg );
out.println("</h2><br>");
if( ex != null ){
ex.printStackTrace( out );
}
out.println("<br>");
out.println("<a href=\"mailto:wbrogden@bga.com\">
Please mail me the error message.</a><br>");
footer( out );
}
private void header(PrintWriter out ){
out.println("<html>");
out.println("<head><title>Network News Servlet</title>
</head>");
out.println("<body>");
}
private void footer(PrintWriter out ){
out.println("<hr><br>Network News Servlet " +
version + " <br>" );
out.println("</body>");
out.println("</html>");
out.close();
}
}
Как показано в листинге 9.28, метод doNetNews получает объект NetNewsBean и выводит полученные заголовки в виде строк таблицы.
Листинг 9.28. Этот метод форматирует полученные заголовки (NetNewsServ.java)
// assumes a table has been started
// topics[] are tags from list, ie 0, 1 etc.
private void doNetNews
( PrintWriter out,String keywords, String[] topics ){
int i =0 ;
try {
NetNewsBean nnb = new NetNewsBean
( queryStr, destDir, queryFile );
out.println("Update " + nnb.getDocDate());
String[] tstr = nnb.getTopicsAsArray();
if( keywords.length() > 0 ) {
out.println("<tr><td>
Selected by keywords: " + keywords + "</td></tr>");
out.println( nnb.getContentByKeyWord( keywords, fmt )) ;
}
out.println("<hr>") ;
if( topics == null ){ // none selected
for( i = 0 ; i < tstr.length ; i++ ){
out.println("<tr><td>topic: " + tstr[i] + "</td></tr>" );
out.println( nnb.getContentByTopic( tstr[i], fmt ) );
}
}
else {
for( i = 0 ; i < topics.length ; i++ ){
int tn = Integer.parseInt( topics[i] );
out.println("<tr><td>topic: " + tstr[tn] + "</td></tr>" );
out.println(nnb.getContentByTopic(tstr[ tn ], fmt));
}
}
}catch(Exception e){
out.println( "<tr><td>" );
e.printStackTrace(out );
out.println("</td></tr>");
}
}
Все остальные методы в классе NetNewsServ являются служебными; некоторые из них показаны в листинге 9.29.
Листинг 9.29. Некоторые служебные методы (NetNewsServ.java)
// assumes response has been set to text/html
private void errorMsg
( PrintWriter out, String msg, Exception ex ){
header( out );
out.println("<h2>Error: " ); out.println( msg );
out.println("</h2><br>");
if( ex != null ){
ex.printStackTrace( out );
}
out.println("<br>");
out.println("<a href=\"mailto:wbrogden@bga.com\">
Please mail me the error message.</a><br>");
footer( out );
}
private void header(PrintWriter out ){
out.println("<html>");
out.println("<head><title>Network News Servlet</title>
</head>");
out.println("<body>");
}
private void footer(PrintWriter out ){
out.println("<hr>
<br>Network News Servlet " + version + " <br>" );
out.println("</body>");
out.println("</html>");
out.close();
}
}
Этот класс выполняет роль интерфейса между сервлетом и хранящимся в памяти объектом NewsModel, который соответствует конкретному источнику сообщений. Как показано в листинге 9.30, конструктор использует класс NetNewsSuper для получения текущего объекта NewsModel для заданного источника.
Листинг 9.30. Начало класса NetNewsBean (NetNewsBean.java) package com.XmlEcomBook.Chap09;
package com.XmlEcomBook.Chap09;
import java.util.* ; import org.w3c.dom.* ;
public class NetNewsBean
{
static String noDataStr ="No Data is available";
static String dataSourceErr = "Error when loading data " ;
NewsModel newsM ; // has public boolean usable and errStr
// create with source url string, dest file path, dest fname
NetNewsBean( String source, String pth, String fn )
throws Exception {
NetNewsSuper nns =
NetNewsSuper.getNetNewsSuper( source,pth,fn );
newsM = nns.getNewsModel() ; // throws exception
}
public String getDocDate(){
if( newsM == null ) return noDataStr ;
if( newsM.usable ) return newsM.dateStr ;
return dataSourceErr ;
}
В листинге 9.31 показаны методы, которые обеспечивают доступ к списку тематических категорий в конкретном объекте NewsModel. Метод getTopicsAsArray просто возвращает массив типа String, в то время как getTopicsAsSelect возвращает список в формате HTML.
Листинг 9.31. Методы, которые возвращают тематические категории в виде массива и в виде списка в формате HTML (NetNewsBean.java)
public String[] getTopicsAsArray(){
if( newsM == null || !newsM.usable ) return null;
return newsM.getTopics();
}
// return available topics as a Select control with values
// matching the index of the topics array
public String getTopicsAsSelect(){
if( newsM == null ) return noDataStr ;
StringBuffer sb = new StringBuffer(1000);
if( newsM.usable ){
String[] topics = newsM.getTopics();
sb.append("
<select name=\"topics\" MULTIPLE size=\"3\">\r\n");
for( int i = 0 ; i < topics.length ; i++ ){
sb.append("<option value=\"");
sb.append( Integer.toString( i ));
sb.append("\" > ");
sb.append( topics[i] );
}
sb.append("</select>\r\n");
}
else {
sb.append( dataSourceErr );
sb.append( newsM.lastErr );
}
return sb.toString();
}
Метод getContentByKeyWord, показанный в листинге 9.32, контролирует выбор и формат заголовков, содержащих одно или несколько ключевых слов, введенных пользователем.
Листинг 9.32. Метод, контролирующий поиск заголовков по ключевым словам (NetNewsBean.java)
public String getContentByKeyWord( String kwds, String fmt ){
if( newsM == null ) return noDataStr ;
StringBuffer sb = new StringBuffer(1000);
if( newsM.usable ){
Element[] art = newsM.articlesByKeyWord( kwds );
for( int i = 0 ; i < art.length ; i++ ){
sb.append( newsM.formatElement( art[i], fmt ));
sb.append("\n");
}
}
else {
sb.append( dataSourceErr );
sb.append( newsM.lastErr );
}
return sb.toString();
}
Альтернативным вариантом является представление всех заголовков новостей, которое осуществляется методом getAllTopics. Как показано в листинге 9.33, для каждого заголовка этот метод создает строку, содержащую форматированный текст заголовка.
Листинг 9.33. Метод getAHTopics форматирует все имеющиеся заголовки (NetNewsBean.java)
public String getAllTopics( String fmt ){
if( newsM == null ) return noDataStr ;
StringBuffer sb = new StringBuffer(1000);
if( newsM.usable ){
Element[] art = newsM.getAllTopics();
for( int i = 0 ; i < art.length ; i++ ){
sb.append( newsM.formatElement( art[i], fmt ));
sb.append("\n");
}
}
else {
sb.append( dataSourceErr );
sb.append( newsM.lastErr );
}
return sb.toString();
}
На рис 9 3 показана страница с заголовками свежих новостей, выбранных в соответствии с указанными ключевыми словами и форматированных методом getContentByTopic, который приведен в листинге 934
Листинг 9.34. Метод getContentByTopic (NetNewsBean.java)
public String getContentByTopic( String content, String fmt ){
if( newsM == null ) return noDataStr ;
StringBuffer sb = new StringBuffer(1000);
if( newsM.usable ){
Element[] art = newsM.articlesByTopic( content );
if( art == null ) return dataSourceErr ;
for( int i = 0 ; i < art.length ; i++ ){
sb.append( newsM.formatElement( art[i], fmt ));
sb.append("\n");
}
}
else {
sb.append("getContentByTopic " + dataSourceErr );
sb.append("getContentByTopic " + newsM.lastErr );
}
return sb.toString();
}
public String toString()
{
StringBuffer sb = new StringBuffer("NetNewsBean ");
return sb.toString() ;
}
}
Хотя основанный на использовании DOM подход является вполне приемлемым для систем с небольшой нагрузкой на сервер, он не слишком эффективен, так как для доступа к каждой странице нужно выполнять одни и те же вычисления Хуже всего, когда в тексте заголовков встречаются ссылки на сущности
Разумной альтернативой хранению DOM в памяти является представление отдельного заголовка через класс Java и создание коллекции таких классов путем перехвата событий анализатором SAX Если у этого класса также имеется возможность применять требуемый формат HTML к заголовкам сообщений, то конструктор может заранее форматировать весь элемент и хранить только строку, представляющую данный элемент, плюс строку, содержащую текст заголовка для поиска
Создание пользовательской библиотеки тегов JSP для заголовков не требует написания длинных программ, но такая библиотека упростила бы работу web- дизайнера по наделению любой страницы средствами представления заголовков новостей, причем без необходимости модифицировать код Java.
Релятивисты и позитивисты утверждают, что "мысленный эксперимент" весьма полезный интрумент для проверки теорий (также возникающих в нашем уме) на непротиворечивость. В этом они обманывают людей, так как любая проверка может осуществляться только независимым от объекта проверки источником. Сам заявитель гипотезы не может быть проверкой своего же заявления, так как причина самого этого заявления есть отсутствие видимых для заявителя противоречий в заявлении.
Это мы видим на примере СТО и ОТО, превратившихся в своеобразный вид религии, управляющей наукой и общественным мнением. Никакое количество фактов, противоречащих им, не может преодолеть формулу Эйнштейна: "Если факт не соответствует теории - измените факт" (В другом варианте " - Факт не соответствует теории? - Тем хуже для факта").
Максимально, на что может претендовать "мысленный эксперимент" - это только на внутреннюю непротиворечивость гипотезы в рамках собственной, часто отнюдь не истинной логики заявителя. Соответсвие практике это не проверяет. Настоящая проверка может состояться только в действительном физическом эксперименте.
Эксперимент на то и эксперимент, что он есть не изощрение мысли, а проверка мысли. Непротиворечивая внутри себя мысль не может сама себя проверить. Это доказано Куртом Гёделем.
Понятие "мысленный эксперимент" придумано специально спекулянтами - релятивистами для шулерской подмены реальной проверки мысли на практике (эксперимента) своим "честным словом". Подробнее читайте в FAQ по эфирной физике.
|
|
