Для успешной работы вашего электронного магазина необходимо, чтобы вы имели некоторое представление о ваших покупателях. Для этого в первую очередь вы должны использовать архивы данных о продажах и о взаимодействии пользователей с вашим web-сайтом. Однако помимо этих записей у вас есть возможность с помощью проводимых на сайте опросов напрямую получать информацию от покупателей. Большинство из них с удовольствием ответят на ваши вопросы, если вы сможете убедить их в соблюдении необходимой конфиденциальности.
Для создания систем сетевых опросов хорошо подходит комбинация XML и сервлетов Java. В этой лекции мы не ограничиваемся простым линейно организованным опросом, а создаем систему, которая может задавать различные вопросы в зависимости от предыдущих ответов пользователя.
В настоящее время многие разделяют беспокойство по поводу сохранения права потребителей на частную жизнь и с подозрением воспринимают любую организацию, которая хранит информацию в компьютерных базах данных. С одной стороны, все фирмы убеждены, что только максимально полная информация о потенциальных покупателях является ключом к победе в жестокой конкурентной борьбе. С другой стороны, люди испытывают тревогу при мысли, что подробности их частной жизни могут стать известными. Вы можете помочь своим клиентам чувствовать себя более уверенно при посещении вашего сайта, если доступно объясните те правила соблюдения конфиденциальности, которым вы следуете.
Желание решить описанную проблему в области электронной коммерции без вмешательства правительства привело к созданию независимой некоммерческой
инициативной организации под названием TRUSTe [Trust (англ.) — доверие. — Примеч. перев.
] (www.truste.org). Основными принципами TRUSTe являются следующие.
Пользователь имеет право на осведомленность и осознанный выбор того, каким
образом будет использоваться его персональная информация.
Ни один из принципов соблюдения конфиденциальности не годится для всех случаев.
Организация TRUSTe осуществляет проверку соблюдения принципов конфиденциальности, так же как, например, организация UL (United Laboratories — объединенные лаборатории) проводит проверки в области электротехнического оборудования- Организации — члены программы получают право на размещение на своих сайтах логотипа TRUSRe, если принципы обеспечения конфиденциальности, которым они следуют, удовлетворяют стандартам TRUSTe. Также эти организации должны заплатить членский взнос и пройти контрольную проверку. Членский взнос составляет сумму 299 долларов для компаний, чей годовой доход не превышает одного миллиона долларов, так что членство в программе TRUSTe вполне доступно.
ПРИМЕЧАНИЕ
Сайты, которые могут собирать информацию у детей в возрасте до 13 лет, должны удовлетворять еще более жестким требованиям в отношении соблюдения конфиденциальности. В настоящее время Конгресс США готовит новое законодательство в данной области.
TRUSTe постоянно проводит наблюдения за теми сайтами, которые являются членами программы, и проверяет соблюдение ими заявленной практики обеспечения конфиденциальности. В процессе наблюдения, в частности, на сайт отправляется вымышленная персональная информация, а затем отслеживается ее использование. Кроме того, TRUSTe активно преследует те сайты, которые несанкционированно размещают логотип TRUSTe.
Как для членов программы, так и для других организаций сайт
www.truste.org представляет собой прекрасное место для знакомства с новостями в области охраны права пользователей на конфиденциальность, особенно в США. TRUSTe также сотрудничает со многими другими организациями, которые пытаются установить стандарты в сфере охраны частной информации пользователей.
Многие считают, что частная информация подвергается такой же опасности при сборе данных, проводимых правительственными организациями, как и при опросах коммерческих организаций. Поэтому неудивительно, что существует несколько общественных организаций, деятельность которых связана с этой проблемой. Одной из таких организаций является EPIC (Electronic Privacy Information Center — Центр конфиденциальности электронной информации), расположенная в Вашингтоне, штат Колумбия (www.epic.org/privacy).
Организация EPIC занимается гражданскими правами и правами на частную жизнь. Часто она дает свидетельские показания на слушаниях дел в судах и,
используя Акт о свободе информации (Freedom of Information Act), расследует и предает гласности нарушения правительственными организациями США прав граждан на частную жизнь.
Организация EPIC связана с Privacy International (www.privacy.org/pi) — международной коалицией групп, работающих в области защиты прав потребителей на конфиденциальность общения. Эта организация, основанная в 1990 году, базируется в Лондоне; она проводит международные конференции по проблемам соблюдения конфиденциальности. Каждый год она публикует список правительственных и коммерческих организаций, получивших титул «Big Brother»
[Большой Брат. — Примеч. перев. ]. Этот титул Privacy International присваивает тем организациям, которые, по ее мнению, ведут наиболее агрессивную и нечестную политику в отношении использования частной информации.
Знание потребностей и интересов своих покупателей существенно для успеха любого предприятия. Но для того, чтобы у посетителей вашего сайта не возникло никаких опасений за их персональную информацию, лучше всего ясно изложить им принципы вашей политики в этом отношении и всегда предоставлять им возможность отказаться от сообщения несущественной информации. Если ваш сайт ориентирован на детей, вам также следует убедиться, что принципы работы с персональной информацией соответствуют принятому законодательству.
Простая, но эффективная форма сбора информации — это проведение опроса по сети. Поскольку язык XML предназначен, в частности, для определения структуры документов, а опрос осуществляется как раз с помощью четко структурированных документов, XML как нельзя лучше подходит для решения нашей задачи. Основанная на XML система опросов, которой посвящены все остальные разделы этой лекции, отличается гибкостью. В этой системе конкретный пользователь не связывается со своими ответами; система просто собирает ответы всех пользователей вместе. В систему несложно внести изменения, которые позволили бы сохранять ответы каждого пользователя в базе данных, но в таком случае вам пришлось бы объяснять пользователю, что именно вы собираетесь делать с его персональной информацией.
В этом разделе мы займемся разработкой обобщенной структуры XML для создания системы сетевых опросов. Мы начнем со списка критериев, которым должна отвечать система.
Управление внешним видом. В идеале, мы хотели бы, чтобы дизайн-страницы с вопросами не нарушал общего стиля нашего web-сайта.
Гибкость методов опроса. Мы должны иметь возможность применять различные методы
опросов: от простых вопросов, на которые пользователь отвечает «да» или «нет»,
до выбора одного из предложенных ответов.
Возможность ветвления. В одном и том же сценарии очередность вопросов должна зависеть от ответов пользователей. Например, если из ответа на некоторый вопрос понятно, что данный пользователь никогда не покупает музыкальные компакт-диски через Интернет, не имеет смысла расспрашивать его о музыкальных предпочтениях и нужно выбрать другую ветвь вопросов.
Расширяемость. Если в систему потребуется добавить новую форму представления
вопросов, необходимые изменения кода должны быть минимальными.
Запись результатов. Результаты опроса каждого участника должны быть записаны
полностью и не должны зависеть от результатов других участников. Это дает
максимальную гибкость при анализе.
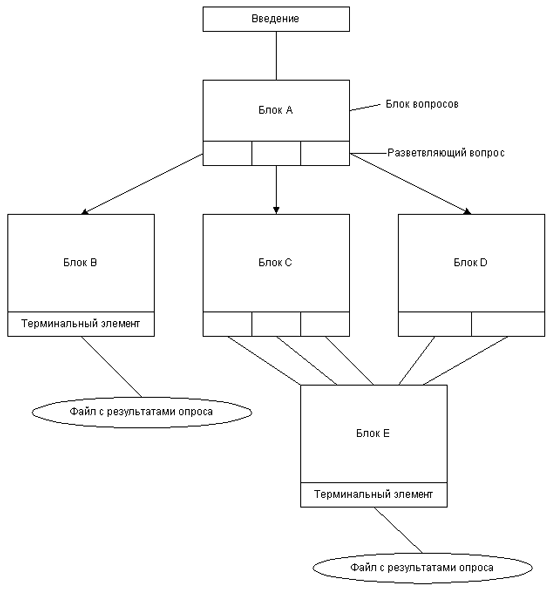
На рис. 7.1 показаны возможные ветви сценария опроса. Существенно следующее: имеются блоки вопросов, в которых ветвление отсутствует и которые заканчиваются многовариантным вопросом — ответ на такой вопрос ведет к переходу по той или иной ветви. Многовариантный вопрос может приводить несколько ветвей к одному блоку (например, блоки С и D приводят к одному блоку Е) или к различным блокам (например, из блока А можно попасть, в зависимости от ответа на многовариантный вопрос, в блок В, С или D). Блоки либо заканчиваются многовариантными вопросами, либо являются завершающими и прекращают опрос. По достижении завершающего блока система записывает все ответы в файл. Система может быть устроена таким образом, чтобы каждому завершающему блоку соответствовал свой уникальный файл.
Переводя эту диаграмму на язык сущностей XML, мы приходим к следующей структуре. В документе Questionnaire на первом уровне имеется элемент Intro (введение) и одна или несколько сущностей Block. Каждая сущность Block содержит одну или более сущностей Ques (вопросы) и может заканчиваться сущностью Terminal. В сущности Block имеется атрибут name, который используется для адресации ветвления, и атрибут type, значение которого равно terminal, если блок заканчивается тегом Terminal. Этот внешний уровень структуры системы опросов схематически описан в листинге 7.1
[Questionnaire — анкета, intro — введение (сокращение от introduction).
— Примеч. перев. ].
Листинг 7.1.
Первый и второй уровень иерархии анкеты
<Questionnai re> <Intro> </Intro>
<Block name="A"> </Block>
<Block name="B" type="terminal"> </Block>
<Block name="C"> </Block>
<Block name="D"> </Block>
<Block name="E" type="terminal"> </Block>
</Questionnai re>
Рис. 7.1. Возможные ветви сценария
Каждый вопрос в блоке создается с помощью тега dues, который включает в себя текстовый фрагмент и два или более варианта выбора, создаваемых тегами Qopt. Атрибуты тегов dues и Qopt позволяют контролировать ветвление и способ представления вопросов. Самый простой способ увидеть, как все это устроено, — рассмотреть несколько вопросов, представленных в примере анкеты в следующем разделе.
В листинге 7.2 показаны введение и первый вопрос анкеты, которую вы могли бы использовать для определения, какие товары добавить в ваш каталог.
ПРИМЕЧАНИЕ
Полная версия анкеты имеется на прилагаемом к курсу каталоге файлов. Тип первого вопроса (атрибут type) определен как QMC (Question Multiple Choice — вопрос, допускающий выбор одного ответа из списка); это вопрос, в качестве ответа на который пользователь должен выбрать один из предложенных вариантов.
Листинг 7.2. Начало документа XML, определяющего анкету (customsurvey.xml)
<?xml version="1.0" standalone="yes" ?>
<Questionnaire title="Example Customer Survey"
author="wbb" date="May 30, 2000"
method="xml" file="e:\scripts\questionnaire\surveyresult.xml"
>
<Intro><![CDATA[
<h1>Welcome Customers</h1><br>
<p>We here at <i>BuyStuff.com</i>
want to meet your every desire to buy <b>STUFF</b>.
To that end we are greatly expanding
our on-line catalog and we want to concentrate on
<b>STUFF</b>
you will want to buy as soon as you see it. Please help by
completing this simple survey.
</p>]]>
</Intro>
<Block name="intro" type="terminal" >
<Ques id="intro:1" type="QMC" >
<Qtext>Which of the following are you most interested in
buying on-line?
</Qtext>
<Qopt val="a" branch="books" >Books</Qopt>
<Qopt val="b" branch="cds" >Cds</Qopt>
<Qopt val="c" branch="gadgets">Electronic goodies</Qopt>
<Qopt val="d" >I am not interested in buying Stuff!</Qopt>
</Ques>
<!-- this terminates the block and the questionnaire -
could substitute different file for recording -->
<Terminal><![CDATA[<h2>Thanks for looking anyway!</h2>
]]>
</Terminal>
</Block>
Элементы Qopt в первом вопросе со значениями атрибута val, равными a, b и с, служат ответвлениями к другим блокам, в то время как вариант ответа d приводит к отображению завершающего сообщения. Можно выбрать только один из предложенных ответов, потому что тип вопроса указан как QMC. В этой лекции мы используем вопросы только двух типов: QMC (Question Multiple Choice — вопрос, допускающий выбор одного ответа из списка) и QMCM (Question Multiple Choice Multiple Answer — вопрос, допускающий выбор нескольких ответов из списка). Результаты ответа пользователя на этот вопрос записываются с помощью атрибута id вопроса и значений атрибутов val элементов Qopt.
В листинге 7.3 показан блок (из листинга 7.2), на который указывает атрибут branch тега Qopt, причем в последнем атрибут val имеет значение а. Вопрос с идентификатором books:! относится к типу QMCM, то есть позволяет выбрать несколько вариантов ответа. Блоки cds и gadgets устроены похожим образом.
Листинг 7.3. Блок вопросов «Книги» (custom.ersurvey.xml)
<Block name="books" type="terminal" >
<Ques id="books:1" type="QMCM" >
<Qtext>Please select all of the book categories you
would like to see in our catalog.
</Qtext>
<Qopt val="0">Best Sellers of all types</Qopt>
<Qopt val="1">Science Fiction</Qopt>
<Qopt val="2">Fantasy Fiction</Qopt>
<Qopt val="3">History and Biography</Qopt>
<Qopt val="4">Computer Technology</Qopt>
<Qopt val="5">Business Related</Qopt>
</Ques>
<Terminal><![CDATA[<h2>Thanks for answering the survey!
</h2>]]>
</Terminal>
</Block>
В этом разделе приводится полный код сервлета Java, который управляет опросом, основанным на приведенном в предыдущем разделе документе XML. Этот сервлет записывает результаты в форме, удобной для дальнейшего анализа. Также мы опишем служебный класс, который позволяет управлять объектами document в процессоре сервлетов, и сервлет для составления таблицы и отчета по результатам опроса.
В листинге 7.4 показаны инструкции импорта, объявления классов и метод init для сервлета QuestionnaireServ. Статическая переменная homedir, значение которой может быть получено из ServletConfig, используется в методе init для считывания файла свойств. С помощью этого файла задается путь к исходному файлу XML для данной анкеты. Также файл свойств может потребоваться для того, чтобы задать значение переменной handler типа Srting. Это значение равно URL- адресу, который используется web-сервером для данного сервлета.
Листинг 7.4. Начало кода сервлета QuestionnaireServ (QuestionnaireServ.java)
public void init(ServletConfig config) throws ServletException
{
super.init(config);
String tmp = config.getInitParameter("homedir");
if( tmp != null ) homedir = tmp ;
System.out.println("Start QuestionnaireServ using " + homedir );
File f = new File( homedir, "questionnaire.properties");
try { qProp = new Properties();
qProp.load( new FileInputStream(f) );
tmp = qProp.getProperty("handler");
if( tmp != null ) handler = tmp ;
System.out.println
("Loaded properties for Questionnaire handler: "
+ handler );
}catch(IOException e){
System.out.println("Error loading " + e );
}
}
Сервлет QuestionnaireServ отслеживает взаимодействие с каждым пользователем, отвечающим на вопросы анкеты, в сеансах. Предполагается, что исходный запрос — это запрос методом GET с HTML-страницы, на которой имеется простая форма для определения значения переменной qname, идентифицирующей требуемую анкету. Приспосабливая этот сервлет для своего приложения, вы на этом этапе можете также записать идентификатор пользователя.
Метод doGet, показанный в листинге 7.5, отыскивает объект document, соответствующий значению переменной qname, используя путь, указанный в файле свойств, и служебную библиотеку DOMlibrary. Если ему удается найти этот объект, далее он получает объект HttpSession и присоединяет к сеансу новый объект Interpreter, в котором хранится документ. Новый объект Recorder также инициализируется и присоединяется к сеансу. Для обработки любой ошибки и создания соответствующего сообщения используется метод errorMsg (см. листинг 7.7).
Объект Interpreter отвечает за создание форм HTML, с помощью которых будет осуществляться опрос, а объект Recorder отвечает за запись ответов пользователя. Эти классы обсуждаются в разделах «Класс Interpreter» и «Класс Recorder».
Результатом вызова метода doGet является страница с текстом, содержащимся в теге Intro документа XML. Для отображения этого текста на странице используется метод dolntro объекта Interpreter; также на странице располагается форма с кнопкой, при щелчке на которой появляется первый вопрос анкеты.
Листинг 7.5. Код метода doGet (QuestionnaireServ.java)
public void doGet
(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
resp.setContentType("text/html");
PrintWriter out = new PrintWriter(resp.getOutputStream());
String qname = req.getParameter("qname") ;
// System.out.println("Start doGet");
if( qname == null || qname.length() == 0 ){
errorMsg( out, "Bad QNAME data", null); return;
}
// MUST have qname = name of xml file
String src = qProp.getProperty( qname );
if( src == null ) {
errorMsg( out, "Bad QNAME lookup", null ); return ;
}
String userid = "unknown" ; // customer or student id or unknown
String tmp = req.getParameter("userid");
if( tmp != null ) userid = tmp;
String usertype = "unknown" ; // "student" "customer" etc etc
tmp = req.getParameter("usertype");
if(tmp != null ) usertype = tmp ;
DOMlibrary lib = DOMlibrary.getLibrary();
System.out.println("DOMlibrary initialized, try for " + src );
Document doc = lib.getDOM( src );
if( doc == null ){
errorMsg( out, "DOM doc failed - unable to continue", null );
return ;
}
HttpSession session = req.getSession( true );
// if not new must be re-entering - could recover here
Interpreter terpret = new Interpreter( doc, handler );
session.putValue( "xmldocument", terpret );
// session.setAttribute("xmldocument",terpret );
// the putValue method was used in the 2.1 API but is now
// a deprecated method,
//
Recorder rb = new Recorder(userid, usertype,
session.getId(), src );
rb.setMethods( doc );
session.putValue("recorder", rb );
//session.setAttribute("recorder", rb );
try { //
terpret.doIntro( out ); // includes head and Form
footer( out );
}catch(Exception e){
errorMsg( out, "doGet ", e );
}
После введения в анкету, как видно из листинга 7.6, все запросы и ответы проходят через метод doPost. После извлечения из объекта HttpSession объектов Interpreter и Recorder данные запроса собираются и с помощью объектов Interpreter и Recorder генерируется ответ.
Листинг 7.6. Метод doPost класса QuestionnaireServ (QuestionnaireServ.java)
public void doPost
(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
resp.setContentType("text/html");
PrintWriter out = new PrintWriter(resp.getOutputStream());
//System.out.println("Start doPost");
HttpSession session = req.getSession(false);
try {
if( session == null ){ errorMsg(out, "No Session ", null );
return ;
}
Interpreter terpret =
(Interpreter)session.getValue("xmldocument"); //deprecated
//in 2.2 API we use this
// (Interpreter)session.getAttribute("xmldocument");
Recorder rb =
(Recorder) session.getValue("recorder");
// (Recorder) session.getValue("recorder");
if( terpret == null ||
rb == null ){
errorMsg( out, "Data not recovered from Session", null );
return;
}
terpret.doPostQ( out, req, rb );
footer( out );
}catch(Exception e ){
errorMsg( out, "doPost ", e );
}
}
В листинге 7.7 показаны некоторые полезные вспомогательные методы класса QuestionnaireServ. Используя метод footer для размещения закрывающих те- гов на каждой странице, можно внизу указывать версию сервлета. Это очень удобно на этапе разработки, а впоследствии из финальной версии сервлета эти теги можно легко удалить.
Отладка сервлетов может оказаться очень непростым делом, особенно если ошибки проявляются лишь время от времени. Отладка особенно затрудняется в том случае, если пользователи не могут четко и однозначно выразить свои проблемы. Для сообщения об ошибках мы предпочитаем использовать метод erroMsg. Если ошибка связана с каким-либо исключением, то на HTML-странице появится сообщение с содержимым стека. Там же указывается и электронный адрес, по которому пользователь может послать сообщение об ошибке и, мы надеемся, копию содержимого стека. Разумеется, вам следует заменить приведенный ниже электронный адрес на свой.
Листинг 7.7. Вспомогательные методы сервлета QuestionnaireServ (QuestionnaireServ.java)
public void footer( PrintWriter out ){
out.println("<hr> Servlet version: " + version + "<br>");
out.println("</body>");
out.println("</html>");
out.close();
}
// assumes response has been set to text/html
private void errorMsg
( PrintWriter out, String msg, Exception ex ){
out.println("<html>");
out.println("<head>
<title>QuestionnaireServ Output</title></head>");
out.println("<body>");
out.println("<h2>Error: " ); out.println( msg );
out.println("</h2><br>");
if( ex != null ){
ex.printStackTrace( out );
}
out.println("<br>");
out.println("<a href=\"mailto:wbrogden@bga.com\">
Please mail me the error message.</a><br>");
footer( out );
}
public String getServletInfo()
{
return "Administers a questionnaire";
}
В классе Interpreter инкапсулирована вся работа по созданию на основе документа XML форм для вопросов. Этот класс устроен так, чтобы быть максимально гибким в отношении способов анкетирования. Хотя в данной версии поддерживаются только два типа вопросов, используемый механизм может быть легко расширен для включения в анкету других типов вопросов.
Статические методы и инструкции импорта для класса Interpreter показаны в листинге 7.9. Константы QMC и QMCM означают два допустимых в нашей версии типа вопросов: QMC — вопрос, допускающий выбор одного ответа из списка, а QMCM — вопрос, допускающий выбор нескольких ответов из списка. Рассмотрим в качестве примера код XML для вопроса о музыкальных предпочтениях, приведенный в листинге 7.8.
Листинг 7.8. Начало блока вопросов в документе XML (customersurvey.xml)
<Block name="cds" type="terminal" >
<Ques type="QMCM" id="palm:1">
<Qtext>Please select all of the categories of
CD that you would like to see in our catalog
</Qtext>
<Qopt val="0">Classical music</Qopt>
<Qopt val="1">Country and Western</Qopt>
<Qopt val="2">The latest Pop Groups</Qopt>
<Qopt val="3">Current Rock</Qopt>
<Qopt val="4">Golden Oldies Rock</Qopt>
<Qopt val="5">Environmental</Qopt>
<Qopt val="6">Novelty and Humor</Qopt>
</Ques>
Открывающий тег Ques использует атрибут type для задания типа вопросов, в данном случае QMCM. Атрибут id является уникальным идентификатором этого вопроса.
Вместо того чтобы сравнивать строку, являющуюся значением атрибута type, с возможными типами вопросов, мы используем хэш-таблицу Hashtable и отыскиваем в ней целочисленное значение типа int, которое можно использовать в инструкции switch для выбора нужного способа представления вопроса. Эта хэш-таблица называется typeHash, а поиск в ней осуществляется с помощью метода 1 ookUpType, показанного в листинге 7.9.
Для добавления нового типа вы просто должны будете определить новую строку String и целочисленную константу типа int в качестве статических переменных класса Interpreter и в хэш-таблице typeHash.
Листинг 7.9.
Константы и инструкции импорта в начале исходного кода класса
Interpreter (Interpreter.java)
public class Interpreter
{
static final String brcrlf = "<br>\r\n";
static final int QMC = 1 ;
static final int QMCM = 2 ;
static Hashtable typeHash = new Hashtable();
static { // static initialization block
typeHash.put("QMC", new Integer( QMC ));
typeHash.put("QMCM", new Integer( QMCM ));
}
static int lookUpType( String type ){
Integer N = (Integer)typeHash.get( type );
if( N == null ) return 0 ;
return N.intValue();
}
В листинге 7.10 приводятся переменные экземпляра и конструктор класса Interpreter. Для каждого сеанса работы пользователя создается экземпляр класса Interpreter, в котором хранится сам документ и отмечается текущая позиция пользователя в процессе его «продвижения» по анкете. Переменные nowBlock и nowNode являются ссылками на объекты, реализующие интерфейс org.w3c.dom.Node.
Листинг 7.10. Переменные экземпляра и конструктор класса Interpreter (Interpreter.java)
// instance variables below this
Document theDom ;
Node nowBlock, nowNode ; // nowNode should be quest type
boolean terminal = false ; // true if the block is terminal
String title ;
String css = "" ; // may change from block to block
String actionStr ;
NodeList blockNodeList ; // Nodes that are <Block type
// the constructor
public Interpreter( Document doc, String handler ){
theDom = doc ; actionStr = handler ;
Element E = theDom.getDocumentElement(); // the root
blockNodeList = E.getElementsByTagName("Block");
// note that in contrast to other get methods, getAttributes
// returns "" if the attribute does not exist
title = E.getAttribute("title");
css = E.getAttribute("css"); // used for <Intro>
}
Для того чтобы обеспечить некоторую гибкость в форматировании вопросов, предусмотрена возможность задавать каскадную таблицу стилей для всего документа и заменять определенный по умолчанию стиль для каждого блока. Метод writeHead, показанный в листинге 7.11, управляет выводом начала HTML-страницы и включает в себя ссылку на таблицу стилей, если она применяется. В этом листинге также показаны методы startForm и endForm. Заметим, что переменная quesid записывается в форму как скрытая переменная, которая впоследствии извлекается в методе doPostQ (листинг 7.16).
Листинг 7.11. Методы для создания различных частей HTML-страницы (Interpreter.java)
// assumes nowNOde is set to the first question
// output form start and question text
public void startForm(PrintWriter out ){
out.print("<form method=\"POST\" action=\"" );
out.print( actionStr ); out.println("\" >");
}
// fills in hidden variable and button
public void endForm( PrintWriter out, String id ){
out.print("<input type=\"hidden\" name=\"quesid\" value=\""
+ id + "\" ><br>" );
out.print("<input type=\"submit\" value=\"" );
out.print("Next" );
out.println("\" name=\"action\" ><br>");
out.println("</form><br>");
}
Метод genQues, приведенный в листинге 7.12, вызывается после того, как переменной nowNode присваивается значение того элемента dues, который требуется отобразить. Обратите внимание на то, как используется указатель типа вопроса (QMC или QMCM) для выбора сообщения-подсказки. После того как напечатаны текст вопроса и подсказка, метод genQues создает форму, содержащую различные варианты ответа.
Листинг 7.12. Метод genQuest (Interpreter-Java)
public void genQuest( PrintWriter out ){
Element E = (Element) nowNode ;
String qid = E.getAttribute("id") ;
String type = E.getAttribute("type");
String lim = E.getAttribute("limit");
// out.print("Question id: " + qid + " type: " + type + brcrlf );
writeHead( out );
NodeList nm = E.getElementsByTagName("Qtext");
out.print( nm.item(0).getFirstChild().getNodeValue() );
out.println(brcrlf );
NodeList opm = E.getElementsByTagName("Qopt");
int optCt = opm.getLength();
int typeN = lookUpType( type );
switch( typeN ){
case QMC :
out.print("Choose one"); break ;
case QMCM :
if( lim.length() == 0 ){
out.print("Choose any number");
}
else { out.print("Choose up to " + lim );
}
break ;
default :
out.print("Unknown type");
}
out.print( brcrlf );
startForm( out ); // creates <form...
for( int i = 0 ; i < optCt ; i++ ){
doOption(out, opm.item(i), typeN );
}
endForm( out, qid );
}
Метод genQuest в предыдущем листинге вызывает метод doOption (листинг 7.13) для каждого элемента <Qopt>. Если вы захотите добавить дополнительные типы ответов, например поле для ввода текста, вам потребуется модифицировать именно этот метод. В этом листинге также показан метод checkBl ockType, который используется для проверки атрибутов элемента Block.
Листинг 7.13. Метод doOption (Interpretr.java)
// opN is from node list of <Qopt> - create output
// <Qopt val="a" branch="" >Option a.</Qopt>
private void doOption(PrintWriter out, Node opN, int typeN ){
Element E = (Element) opN;
String val = E.getAttribute("val") ;
String branch = E.getAttribute("branch");
String content = E.getFirstChild().getNodeValue();
// what else? type of option display?
switch( typeN ){ // known valid
case QMC :
out.print("<input name=\"opt\" value=\"" + val +
"\" type=\"RADIO\" >" );
break ;
case QMCM :
out.print("<input name=\"opt\" value=\"" + val +
"\" type=\"CHECKBOX\" >" );
break ;
} // now for the text
out.println( content );
out.println( brcrlf );
}
// look at the type and css attributes in <Block>
private void checkBlockType( ){
Element E = (Element)nowBlock ;
String tmp = E.getAttribute("type");
terminal = tmp.equals("terminal");
tmp = E.getAttribute("css");
if( tmp.length() > 0 ) css = tmp ;
System.out.println("checkBlockType - css:" + css );
}
В листинге 7.14 представлен метод dolntro, который задает начальный элемент Block, отыскивая первый элемент в списке узлов ЫockNodeList. Когда значение переменной nowBlock задано, вызывается метод setQNodelnBlock для задания значения переменной nowNode равным первому элементу Ques. Если все это успешно выполнено, отображается текст введения и простая форма, которая вызывает первый вопрос.
Листинг 7.14. Метод dolntro, который выводит текст из тега Intro (Interpreter.java)
// <head> has been set, we are in <body>
public void doIntro(PrintWriter out ){
writeHead( out );
nowBlock = blockNodeList.item(0);
if( nowBlock == null ){
out.println("Error 1 setting up first question.<br>");
return ;
}
if( setQnodeInBlock( 0 )== null ){
out.println("Error 2 setting up first question.<br>");
return ;
}
checkBlockType( ); // sets the terminal flag
out.println( getIntro() );
out.print("<form method=\"POST\" action=\"" );
out.print( actionStr ); out.println("\" >");
endForm( out, "intro" );
}
В листинге 7.15 показан метод setBranch, который вызывается из метода doPostQ, когда ответ пользователя на данный вопрос определяет выбор очередной ветви опроса. Этот метод просто просматривает все элементы ВТ ock и ищет имя (значение атрибута name), совпадающее с заданным именем блока. В этом методе также устанавливаются значения переменных nowBlock и nowNode.
Листинг 7.15.
Метод setBranch (Interpreter.java)
// jump to another block has been detected
private void setBranch(String block ){
int ct = blockNodeList.getLength();
for( int i = 1 ; i < ct ; i++ ){ // block 0 was the start
nowBlock = blockNodeList.item(i);
String name = ((Element)nowBlock).getAttribute("name");
if( name.equals( block )){
checkBlockType() ; // to set terminal flag
setQnodeInBlock( 0 ) ; // set nowNode
return ;
}
}
System.err.println("Interpreter.setBranch failed to find "
+ block );
nowBlock = nowNode = null ;
}
Метод doPostQ, начало которого приводится в листинге 7.16, вызывается из метода doPost и управляет созданием новой HTML-страницы. Обратите внимание на то, что в первую очередь этот метод проверяет, не был ли зафиксирован соответствующим объектом Recorder тот факт, что опрос завершен. Это сделано для того, чтобы пользователь не мог с помощью кнопки Back (Назад) браузера возвратиться на предыдущую страницу для ввода данных, когда опрос уже завершен и данные записаны.
Следующая часть кода отводится для обработки специального случая, когда переменная quesid равна intro, то есть вопрос является первым в анкете. Во всех других случаях ответ пользователя записывается путем сравнения значений opt, взятых из формы, с атрибутами тега Qopt с помощью объекта Recorder этого сеанса.
Листинг 7.16. Начало метода doPost (Interpreter.java)
// req contains user response
public void doPostQ( PrintWriter out, HttpServletRequest req,
Recorder recordB ){
if( recordB.terminated ){
writeHead( out );
out.println("<b>This questionnaire has been terminated</b>");
return ;
}
String action = req.getParameter("action");
String quesid = req.getParameter("quesid");
if( !action.equals("Next") ){
out.println("Unexpected state in Interpreter.doPost<br>");
return ;
}
if( quesid.equals("intro") ){
// this calls for generating first question
// doIntro already set nowNode to first <Ques> node
genQuest( out );
return ;
}
// if here, not generating first question, examine request
Element E = (Element) nowNode ;
NodeList oplist = E.getElementsByTagName("Qopt");
int type = lookUpType( E.getAttribute("type"));
String lim = E.getAttribute("limit"); // ?
String[] optS = req.getParameterValues("opt");
recordB.record( quesid, type, optS );
Следующий шаг метода doPostQ, как показано в листинге 7.17, сводится к тому, чтобы определить, инициирует ли последний записанный ответ пользователя переход к новой ветви опроса. Естественно, новая ветвь начинается с первого вопроса в блоке, как указано в методе setBranch. Если переходить на новую ветвь не нужно, определяется место данного вопроса в текущем элементе Block и выполняется переход к следующему вопросу. Также нужно предусмотреть ситуацию, когда элемент, следующий за текущим вопросом, является завершающим; в этом случае мы вызываем метод getTerminal, функции которого описаны в следующем разделе и связаны с формированием последней страницы опроса.
Листинг 7.17. Метод doPost, продолжение (Interpreter.java)
String branch = branchLookUp( oplist, optS );
if( branch != null ){
//System.out.println("Taking Branch:" + branch );
setBranch( branch );
// sets nowBlock and nowNode to new value
if( nowNode == null ) genTerminal( out, recordB );
else genQuest( out );
return ;
}
// branch is null, nowBlock has 1 or more <Ques
NodeList qlist =
((Element)nowBlock).getElementsByTagName("Ques");
int n = 0 ;
int nct = qlist.getLength();
while( qlist.item(n) != nowNode &&
n < nct ) n++ ;
// n = nowNode
Node nxtN = qlist.item(n+1);
if( nxtN != null ){
nowNode = nxtN ;
genQuest( out );
System.out.println("Found nextQ");
return ;
}
if( terminal ) genTerminal( out, recordB );
else out.println("nextQ NULL, not terminal<br>" );
} // end doPostQ
Как показано в листинге 7.18, метод doTerminal выполняет две основные задачи. Во-первых, он формирует завершающую страницу опроса, используя либо текст, содержащийся в элементе Terminal, либо какую-нибудь стандартную фразу. Кроме того, он пробует найти атрибут altfile тега Terminal. Если этот атрибут указан, то его значение (путь доступа к файлу) используется методом Recorder для сохранения результатов опроса в заданном файле; в противном случае метод Recorder по умолчанию выполняет запись в файл, который задается в начале документа XML.
Листинг 7.18. Метод genTerminal (Interpreter.Java)
// have reached the end of a terminal block
// note that a <Terminal>
tag may have an altfile="filepathandname"
// that replaces the default established in the file attribute of
// the <Questionnaire> tag for this particular branch
private void genTerminal( PrintWriter out, Recorder recordB ){
NodeList nl = ((Element)nowBlock).getElementsByTagName
("Terminal");
int ct = nl.getLength();
String altfile = "" ;
writeHead( out );
if( ct == 0 ){
out.println("Thank you for participating.<br>");
}
else { // use text from <Terminal>...</Terminal>
Element E = (Element)nl.item(0); // only one <Terminal> tag
out.println( E.getFirstChild().getNodeValue() );
altfile = E.getAttribute("altfile");
}
try {
recordB.terminal( altfile );
}catch(IOException e ){
out.println("Problem recording results, please notify
webmaster");
}
}
Класс Recorder отвечает за хранение ответов пользователя на каждый вопрос и за их запись в файл для дальнейшего анализа. Каждому пользователю отводится
экземпляр класса Recorder, который связан с данным сеансом и записывает ответы только этого пользователя.
Корневым элементом документа XML является тег Questionnaire, у которого имеется несколько атрибутов, используемых классом Recorder. Как показано в следующем примере тега Questionnaire, эти атрибуты называются title, author, date, method и file:
Атрибуты title, author и date просто записываются в класс Recorder и отображаются позже, но атрибуты method и file управляют действиями класса Recorder. Мы включили атрибут method для того, чтобы можно было записывать результаты опроса в формате, отличном от XML. Например, если вы предпочитаете использовать программу анализа таблиц, можете добавить методы, которые запишут результаты в виде строки текста, разделенного запятыми. Атрибут file задает путь к стандартному файлу, куда будут записываться результаты, если не назначен другой файл в теге Terminal.
В формате XML, который мы здесь используем, ответы каждого пользователя записываются в тег Qresults, для каждого вопроса отводится тег Ques, а для каждого выбранного ответа — тег Qopt. Конечно, такая структура является более объемной, чем запись в одну строку, но зато она очень гибкая. Получившаяся структура не является законченным документом XML, так как в ней отсутствует корневой элемент. Мы покажем, как решается этот вопрос в разделе «Варианты анализа анкеты».
В листинге 7.20 показаны инструкции импорта, переменные экземпляра и единственная статическая переменная класса Recorder. Статическая переменная filelock является объектом типа String, который используется в инструкции synchronized для того, чтобы гарантировать, что в каждый момент времени только один экземпляр объекта Recorder фактически осуществляет запись в файл.
Листинг 7.20.
Начало исходного кода класса Recorder (Recorder.java)
public class Recorder
{ // this String is used to prevent more than one Recorder from
// writing anywhere at the "same time"
static String filelock = "RecorderLock" ;
// these are instance variables
String userid, usertype, sessionid ;
String qresultStr ;
String source ; // the xml file
String method, output ; // how and where we save
Hashtable record ; // one string per response
public boolean terminated = false ;
Конструктор класса Recorder, показанный в листинге 7.21, вызывается из метода doGet сервлета. Он задает несколько переменных, характеризующих конкретного пользователя. Также он создает хэш-таблицу record, которая будет использоваться для записи ответов на вопросы.
В листинге 7.21 также показан метод setMethods, который определяет.метод записи результатов и атрибутов файла с помощью документа XML. Также он создает открывающий тег Qresults и сохраняет его в переменной qresultStr для дальнейшего использования.
Листинг 7.21. Конструктор класса Recorder и метод setMethods (Recorder.java)
public Recorder(String id, String typ, String ses,String src ){
userid = id ; usertype = typ ; sessionid = ses ;
source = src ;
record = new Hashtable();
}
В листинге 7.22 показаны методы terminal, record и toString. Метод terminal отвечает за запись собранных ответов данного пользователя в отведенный для этого файл. Метод toString используется как вспомогательный при отладке.
Метод record вызывается из метода doPost объекта Interpreter после того, как приходит ответ на очередной вопрос. Отметим, что если вам нужно будет создать какой-либо новый тип, требующий специального способа записи, метод record допускает переключение между типами вопросов. Например, если вам потребуется принимать введенный пользователем текст, он будет записан в раздел CDATA, чтобы в случае наличия в этом тексте каких-либо символов, имеющих специальное назначение в XML, не возникло бы затруднений.
При каждом
вызове метода record создается строка, содержащая тег Ques, которая записывается
в хэш-таблице record и ключом для которой служит переменная
quesid. Поскольку хэш-таблица не сохраняет порядок добавления в нее элементов,
очередность расположения тегов Ques в ней непредсказуема. Но это не страшно,
поскольку для определения порядка следования вопросов мы можем использовать
документ XML, содержащий сценарий опроса.
Листинг 7.22. Код класса Recorder, продолжение (Recorder.java)
// called when a <Terminal block is reached
// if altdest is not "" this changes the default output
public void terminal(String altdest ) throws IOException {
if( altdest != null &&
altdest.length() > 4 ) output = altdest ;
if( output == null || output.length() < 5 ){
System.out.println("QARG output is: " + output );
return ;
}
terminated = true ;
// write in append mode
synchronized( filelock ){
FileWriter fw = new FileWriter( output,true );
PrintWriter pw = new PrintWriter( fw );
pw.print( qresultStr );
Enumeration e = record.elements();
while( e.hasMoreElements() ){
pw.print( (String)e.nextElement() ) ;
}
pw.print("</Qresults>\r\n");
pw.close();
} // end synchronized block
}
// recording format in xml
/*<Qresults source=.... date= >
<Ques id="start:1">
<Qopt val="a"></Qopt><Qopt val="b"></Qopt>
</Ques>
</Qresults>
*/
public void record( String quesid, int type, String[] optS ){
if( terminated ) return ; // prevent backing up from terminal Q
// System.out.println("Start record: " + quesid );
StringBuffer sb = new StringBuffer( 100 );
sb.append("<Ques id=\"" ); sb.append( quesid );
sb.append("\" >");
switch( type ){
case Interpreter.QMC :
case Interpreter.QMCM :
if( optS == null || optS.length == 0 ) break ;
for(int i =0 ; i < optS.length ; i++ ){
sb.append("<Qopt val=\""); sb.append( optS[i] );
sb.append("\"></Qopt>");
}
break ;
default :
sb.append("UNKNOWN TYPE");
}
sb.append("\r\n</Ques>\r\n");
String tmp = sb.toString();
// note this will replace answer if user backed up with
browser back record.put( quesid, tmp );
return ;
}
public String toString() // for debugging
{ StringBuffer sb = new StringBuffer( "Recorder user: " );
sb.append( userid ); sb.append(" type: " );
sb.append( usertype ); sb.append(" session: " );
sb.append( sessionid );sb.append(" method: ");
sb.append( method ); sb.append( " output: " );
sb.append( output ); // how and where we save
return sb.toString() ;
}
}
В листинге 23 показаны результаты ответа одного пользователя на простой опрос. Атрибут source указывает, какой файл XML использовался для создания анкеты. В атрибут date записывается дата первого вхождения пользователя в систему и открытия страницы введения в анкету. Мы также включили атрибут sessionid для помощи в отладке, но, вероятно, без него можно обойтись.
Листинг 7.23. Запись результатов опроса одного пользователя на XML
Поскольку формат записи результатов опроса таков, что ответы каждого пользователя сохраняются в виде отдельной записи, имеется много вариантов анализа этих ответов. Для наших целей годится самый простой способ — составление таблицы по каждому вопросу, в которой для каждого варианта ответа указано количество выбравших его пользователей. Задействованные для составления таблиц классы отделены от сервлета, отвечающего за представление опроса в сети, и могут быть использованы для автономного создания HTML-страниц.
Первая проблема, которую предстоит решить, — это преобразование всех написанных сервлетом Questionnaire выходных файлов в формат, пригодный для анализа результатов опроса. Вспомним, что класс Recorder просто записывает теги <Qresults>, которые аккумулируются в выходном файле (или файлах). Нам нужно создать файл, в котором имелся бы корневой элемент. Фактически этот файл явился бы снимком (snapshot) собранных результатов опроса. Для этого программа, анализирующая результаты, должна выполнить следующие шаги.
Получить объект org.w3c.dom.Document, содержащий сценарий опроса.
Отыскать имена выходных файлов.
Создать для каждого новый файл, объединяя корневые элементы с текущим содержимым
выходного файла.
Создание файлов снимков осуществляется классом PrepQxml, как показано в листинге 7.24 и следующих листингах. Конструктор берет объект XML Document и извлекает имена выходных файлов, которые являются значениями атрибута file в тегах Questionnaire и Terminal. Этот класс используется в сервлете, выполняющем анализ результатов (этот сервлет рассматривается далее в этой лекции), но может использоваться также и в других процессах.
public class PrepQxml
{
public int state = 1 ;
Document doc ;
public String primaryfile ;
public String title ;
public String author ;
public String date ;
String[] files ;
Vector allfiles = new Vector() ;
Hashtable prepHash = new Hashtable() ;
PrepQxml( Document d ){
doc = d ;
Element E = doc.getDocumentElement();
primaryfile = E.getAttribute("file");
allfiles.addElement( primaryfile );
title = E.getAttribute("title");
author = E.getAttribute("author");
date = E.getAttribute("date");
NodeList terminals = E.getElementsByTagName("Terminal");
int ct = terminals.getLength();
// this locates any output files created by <Terminal> tags
for( int i = 0 ; i < ct ; i++ ){
E = (Element)terminals.item(i);
String tmp = E.getAttribute("file");
if( tmp.length() > 0 ) allfiles.addElement( tmp );
}
}
public String[] getFiles(){ return files ; }
Для каждого выходного файла из опроса метод createFiles, показанный в листинге 7.25, вызывает метод makeXML, чтобы создать файл, у которого имеется открывающий и закрывающий теги <QResu1tSet>, необходимые для создания корневого элемента. Имя этого файла получается добавлением символов FMT к имени файла с результатами.
Листинг 7.25. Методы createFiles и makeXML (PrepQxml.java)
// for every file in allfiles, create a temporary with xml root
// return array of file path/names
public String[] createFiles() throws IOException {
files = new String[ allfiles.size() ];
int n = 0 ;
Enumeration e = allfiles.elements();
while( e.hasMoreElements() ){
String tmp = (String)e.nextElement();
files[n++] = tmp ;
System.out.println("Create temporary for " + tmp );
prepHash.put( tmp, makeXML( tmp ) );
}
return files ;
}
// fn is the name of the answers file, return the name of
// the formatted file with root for creation of DOM
public String getAnsXml( String fn ){
return (String) prepHash.get( fn );
}
// this creates a complete XML document by adding a root
// element to the Questionnaire output file contents
private String makeXML(String fn )throws IOException {
File inf = new File( fn );
BufferedReader read = new BufferedReader
( new FileReader( inf ));
int p = fn.lastIndexOf('.');
String outFN = fn.substring( 0,p ) + "FMT" + fn.substring(p);
File outf = new File( outFN );
BufferedWriter bw = new BufferedWriter
( new FileWriter( outf ), 4096);
PrintWriter write = new PrintWriter( bw );
write.println( "<?xml version=\"1.0\" standalone=\"yes\" ?>");
write.println( "<!-- formatted Questionnaire results -->");
write.println( "<QresultSet title=\"" + title + "\" >");
String tmp = read.readLine();
int ct = 1 ;
while( tmp != null ){
write.println( tmp );
tmp = read.readLine();
}
read.close();
write.println("</QresultSet>");
write.close();
System.out.println("Created " + outFN );
return outFN ;
}
public String toString()
{ StringBuffer sb = new StringBuffer("PrepQxml title: ");
sb.append( title ); sb.append(" author: ");
sb.append( author ); sb.append(" date: " );
sb.append( date ); sb.append(" primary output: ");
sb.append( primaryfile ); sb.append(" other files: " );
sb.append( "none");
return sb.toString();
}
Класс TallyQues использует интерфейс SAX для обработки документа QResultsSet. В результате этой обработки формируется таблица, в которой указывается, сколько раз встретился тот или иной ответ на данный вопрос. Выбор интерфейса SAX в данном случае очевиден — количество занимаемой памяти не зависит от общего числа ответов.
В листинге 7.26 показаны инструкции импорта, объявления классов, переменных и конструктор для класса TallyQues. Заметим, что мы основываем этот класс на классе Handler-Base пакета org.xml.sax, потому что в нем по умолчанию предусмотрены методы обработки событий. Все, что нам остается сделать, — переписать встроенные обработчики событий так, чтобы они обрабатывали те события, которые представляют для нас интерес.
Для работы класса TallyQues используется хэш-таблица, в которой каждому варианту ответа из полного набора вариантов по всем вопросам отводится свой элемент. Эти элементы являются экземплярами внутреннего класса Counter (см. листинг 7.30). Ключом для каждого элемента является атрибут id тега Ques вместе с атрибутом val тега Qopt.
Также у нас имеется вектор Vector с названием ordered (в котором хранится информация по всем вопросам в том порядке, в котором они следуют в анкете) и хэш-таблица qtext (которая содержит строки Qtext с текстом вопросов, снабженные атрибутами id тегов Quest в качестве ключей). Конструктор использует объект Document, соответствующий нашей анкете, для создания всех этих объектов.
Листинг 7.26.
Начало кода класса TallyQues (TallyQues.java)
/* org.xml.sax.HandlerBase is a convenience class that
extends java.lang.Object and implements the SAX interfaces
implements EntityResolver, DTDHandler,
DocumentHandler, ErrorHandler */
public class TallyQues extends HandlerBase
{
static public String parserClass = "com.sun.xml.parser.Parser" ;
private Hashtable tally = new Hashtable();
// Counters keyed by unique
// ordered has a Vector of Counters per question
private Vector ordered = new Vector();
private Hashtable qtext = new Hashtable(); // <Qtext> by id
public String tableStyle = "align=\"center\" border=\"3\" " ;
public String lastErr = null ;
public int resultCt = 0 ;
String id ; // <Ques> attribute "id" as detected during parse
// constructor creates the vectors and hashtables to store results
// qd is the questionnaire source XML doc
public TallyQues( Document qd ){
Element E = qd.getDocumentElement();
NodeList qnl = E.getElementsByTagName("Ques");
int ct = qnl.getLength();
for( int i = 0; i < ct ; i++ ){
Vector quesv = new Vector(); // for this <Ques>
ordered.addElement( quesv );
E = (Element)qnl.item(i); // Element is a <Ques>
NodeList txn = E.getElementsByTagName("Qtext");
String tx = txn.item(0).getFirstChild().getNodeValue();
// question text
String id = E.getAttribute( "id" );
qtext.put( id, tx );
quesv.addElement( id ); // first element of quesv is the id
NodeList opt = E.getElementsByTagName("Qopt");
int opct =opt.getLength();
for( int n = 0 ; n < opct ; n++ ){
Element opE = (Element) opt.item(n);
String val = opE.getAttribute("val");
String text = opE.getFirstChild().getNodeValue();
Counter cntr = new Counter( id, val, text );
quesv.addElement( cntr );
tally.put( cntr.unique, cntr );
}
}
}
Обработка снимка опроса
Фактическая обработка файла, содержащего снимок результатов опроса, начинается с метода tallyAns. Как показано в листинге 7.27, работа этого метода состоит из следующих этапов.
Файл открывается как объект org.xml .InputSource.
Создается анализатор в соответствии со строкой parserClass (см. листинг 7.26). Мы используем анализатор из пакета Sun, но вы можете заменить его на любой подходящий вам анализатор.
Объект TallyQues присоединяется к анализатору, с тем чтобы он мог получать вызовы методов обработки событий.
Вызывается метод parse и начинается анализ.
Если не происходит никаких ошибок, то по выполнении метода parse таблица готова. Если происходит ошибка, метод tallyAns возвращает null, а если все прошло успешно, то возвращается переменная ordered.
Листинг 7.27. Метод tallyAns (TallyQues.java)
// srcdoc is complete path to a formatted answer set file
public Vector tallyAns(String srcdoc ){
Parser parser ;
InputSource input ;
try {
File f = new File( srcdoc );
input = Resolver.createInputSource( f );
parser = ParserFactory.makeParser( parserClass );
parser.setDocumentHandler( this );
System.out.println("Start parse");
parser.parse( input );
}catch(SAXParseException spe){
StringBuffer sb = new StringBuffer( spe.toString() );
sb.append("\n Line number: " + spe.getLineNumber());
sb.append("\nColumn number: " + spe.getColumnNumber() );
sb.append("\n Public ID: " + spe.getPublicId() );
sb.append("\n System ID: " + spe.getSystemId() + "\n");
lastErr = sb.toString();
ordered = null ;
}catch(Exception e){
lastErr = e.toString();
ordered = null ;
}
return ordered ;
Обработка событий с помощью интерфейса SAX
Теперь рассмотрим метод обработки событий, относящийся к методам интерфейса SAX и представленный в листинге 7.28. Из всех методов интерфейса SAX нам нужен только один — startElement. Для каждого тега Ques мы получаем значение атрибута id, которое используется вместе с тегами Qopt, содержащими варианты ответов на вопрос Ques Для каждого тега Qopt мы создаем строку, которая объединяет значение атрибута id вопроса со значением атрибута val элемента Qopt (варианта ответа) Эта строка используется как ключ для извлечения из хэш-таблицы tally соответствующего объекта класса Counter Таким образом подсчитывается, сколько раз встретился данный вариант ответа на данный вопрос анкеты
Листинг 7.28. Методы обработки событий SAX (TallyQues.java)
// this is the SAX specified "callback" called when the
// parser detects an element
public void startElement( String name, AttributeList attrib)
throws SAXException {
if( name.equals("Ques") ){
id = attrib.getValue("id");
}
else {
if( name.equals("Qopt") ){
String unique = id + ":" + attrib.getValue("val");
Counter cntr = (Counter)tally.get( unique );
if( cntr != null ) cntr.countIt();
}
else {
if( name.equals("Qresults"))resultCt++ ;
}
}
}
Чтобы объединить всю статистическую информацию, полученную классом TallyQues, используется вектор ordered, в котором для каждого вопроса отведен свой элемент, причем эти элементы следуют в том же порядке, в котором расположены вопросы в исходном XML-сценарии анкеты Каждый такой элемент сам по себе также является вектором, в котором содержится идентификатор вопроса id (строка), а затем следуют объекты класса Counter для каждого из вариантов ответа В хэш-таблице qtext указан текст каждого вопроса, ключом к которому является идентификатор данного вопроса
Форматирование полученных результатов
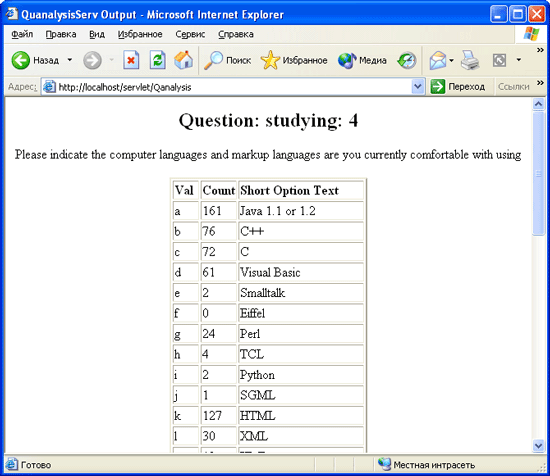
Рассмотрим теперь, каким образом отображается полученная совокупность данных Метод formatAlly, приведенный в листинге 7 29, выводит для каждого вопроса HTML-таблицу, придерживаясь исходного порядка расположения элементов На рис 7 2 показана одна из таблиц, сформированная в результате опроса, который мы недавно проводили на нашем web-сайте в связи с экзаменом на получение сертификата программиста на Java
Листинг 7.29. Метод formatTally создает таблицу HTML (TallyQues.java)
// assumes that tallyAns was just run
public void formatTally(PrintWriter out ){
out.println("<center><h2>" + ordered.size() + " Questions "
+ resultCt + " Responses</h2></center>");
Enumeration e = ordered.elements();
while( e.hasMoreElements() ){
Vector v = (Vector) e.nextElement();
String id = (String)v.firstElement();
out.println("<center><h2>Question: " + id + "</h2>");
out.println("<p>" + qtext.get(id) + "</p>" ) ;
out.println("<table cols=\"3\"" + tableStyle + " >");
out.print("<tr>");
out.print("<th>Val</th><th>Count</th><th>Short
Option Text</th>");
out.println("</tr>");
for( int i = 1 ; i < v.size(); i++ ){
Counter c = (Counter) v.elementAt(i);
out.print("<tr><td>" + c.val + "</td>");
out.print("<td>" + c.count + "</td>" );
out.println("<td>" + c.text + "</td></tr>");
}
out.println("</table></center><br><hr>");
}
}
public String toString()
{ StringBuffer sb = new StringBuffer("TallyQues ");
return sb.toString() ;
}
Рис. 7.2. Отображение в браузере таблицы, сформированной методом fbrmatTally
Остается рассмотреть еще один компонент класса TallyQues — внутренний класс Counter. Как показано в листинге 7.30, в объект Counter входят идентификатор вопроса, значение атрибута val данного варианта ответа и текст варианта ответа. Этот текст мы ограничили по длине, чтобы таблица оставалась компактной, но вы легко можете снять это ограничение.
Листинг 7.30. Внутренний класс Counter (TallyQues.java)
// counter objects represent a single question/option combo
class Counter {
public String val ;
public String unique ; // <Ques id plus ":" plus <Qopt val
public String text ; // the first counterTextLen chars
public int count = 0 ;
Counter( String id, String v, String tx ){
val = v ;
unique = id + ":" + val ;
if( tx.length() > counterTextLen ) {
text = tx.substring(0, counterTextLen);
}
else { text = tx ;
}
}
public void countIt(){ count++ ; }
Классы PrepQxm и TallyQues, рассмотренные в предыдущих разделах, можно по-разному использовать для создания таблиц в формате HTML. В нашем случае мы задействуем сервлет QanalyslsServ, описанный в следующем разделе.
Сервлет QanalysisServ, рассматриваемый в этом разделе, предоставляет доступ по сети к снимку результатов проходящего опроса, поэтому его можно назвать сер- влетом для просмотра результатов отчета. Он использует файл questionnaire.pro- perties для поиска всех текущих опросов и предлагает вам выбрать один из них. Затем он определяет, какие выходные файлы генерируются в этом опросе, и предлагает выбрать один из них для формирования отчета.
В листинге 7.31 показаны инструкции импорта, статические переменные и метод init — начало кода сервлета.
public class QanalysisServ extends HttpServlet
{
static String brcrlf = "<br>\r\n" ;
static String homedir = "e:\\scripts\\questionnaire" ;
static String handler = "http://www.lanw.com/servlet/Qanalysis" ;
static String passwd = "lovexml" ;
static String version = "v1.0 May 28";
Properties qProp ;
// note we share properties file with QuestionnaireServ
public void init(ServletConfig config) throws ServletException
{
super.init(config);
System.out.println("Start QanalysisServ ");
homedir = config.getInitParameter("homedir") ;
File f = new File( homedir, "questionnaire.properties");
try { qProp = new Properties();
qProp.load( new FileInputStream(f) );
String tmp = qProp.getProperty("analysis");
if( tmp != null ) handler = tmp ;
System.out.println("Loaded properties for Qanalysis: "
+ handler );
}catch(IOException e){
System.out.println("QanalysisServ Error loading " + e );
}
}
Входом в сервлет служит метод doGet, показанный в листинге 7.32. Обычно для входа используется форма, в которую требуется ввести пароль пользователя, просто чтобы избежать риска случайного доступа к сервлету постороннего пользователя. Предположим, что все прошло успешно; тогда этот метод генерирует страницу с формой, которая позволяет осуществить выбор среди всех имеющихся в наличии отчетов. Выбранный файл передается методу doPost.
Листинг 7.32. Метод doGet класса QanalysisServ (QanalysisServ.java)
// entry with password
public void doGet(HttpServletRequest req,
HttpServletResponse resp)
throws ServletException, IOException
{ System.out.println("Qanalysis doGet");
resp.setContentType("text/html");
PrintWriter out = new PrintWriter(resp.getOutputStream());
String user = req.getParameter("username");
String tmp = req.getParameter("userpw");
// Obviously this could be a lot more complex
if( !passwd.equals( tmp )){
errorMsg( out, "404 page not found", null );
return ;
}
if( qProp == null ||
qProp.size() == 0 ){
errorMsg( out, "Bad Initialization", null ); return ;
}
HttpSession session = req.getSession( true );
session.putValue( "username", user );
//
Enumeration e = qProp.keys();
Vector v = new Vector();
while( e.hasMoreElements()){
String key = (String)e.nextElement();
// everything not "handler" or "analysis" is a XML file
path name
if( !( key.equals("handler") || key.equals("analysis"))){
v.addElement( key );
}
}
if( v.size() == 0 ){
errorMsg( out, "No Questionnaire files found", null );
return ;
}
out.println("<HTML>");
out.println("<HEAD><TITLE>QanalysisServ Output</TITLE>
</HEAD>");
out.println("<BODY>");
out.println("<h2>Select The Questionnaire XML File</h2>");
out.println("Found " + v.size() + " XML files" + brcrlf );
out.println("<form method=\"POST\"
action=\"http://localhost/servlet/Qanalysis\" >");
out.println("<select name=\"source\" >");
for( int i = 0 ; i < v.size() ; i++){
tmp = (String) v.elementAt( i );
out.println("<option value=\"" + tmp + "\" >" + tmp );
}
out.println("</select>");
out.println("<input type=\"hidden\" name=\"username\"
value=\"" + user + "\"><br>" );
out.println("<input type=\"hidden\" name=\"action\"
value=\"select\" ><br>");
out.println("<input type=\"submit\" value=\"Start\" ><br>" );
out.println("</form>");
footer( out );
}
В первом запросе, выполняемом методом POST, значение переменной action равно
select. Как показано в листинге 7.33, такой запрос инициирует вывод раскрывающегося
списка всех доступных файлов с результатами. При этом используется метод createQList.
Листинг 7.33. Первая часть метода doPost (QanalysisServ.java)
Когда пользователь выберет один из файлов с результатами, переменная action принимает значение analyze. Как показано в листинге 7.34, это инициирует создание нового объекта TallyQues, который используется для формирования таблицы с результатами.
Листинг 7.34. Метод doPost, продолжение (QanalysisServ.java)
Метод createQList, показанный в листинге 7.35, создает форму HTML, которая используется для вывода всех возможных файлов с ответами.
Листинг 7.35. Метод createList (QanalysisServ.java)
// the PrepQxml has located all of the answer files - only one
// can be analyzed at at time
void createQList( PrintWriter out, String source, String[] files ){
out.println("<form method=\"POST\" action=
\"http://localhost/servlet/Qanalysis\" >");
out.println("<input type=\"hidden\" name=
\"action\" value=\"analyze\" ><br>");
out.println("<input type=\"hidden\" name=
\"source\" value=\""
+ source + "\" ><br>");
out.println("<select name=\"ansfile\" >");
for( int i = 0 ; i < files.length ; i++){
String tmp = files[i];
out.println("<option value=\"" + tmp + "\" >" + tmp );
}
out.println("</select>");
out.println("<input type=\"submit\" value=\"Start\" ><br>" );
out.println("</form><br>");
}
Мы почти завершили рассмотрение класса QanalysisServ! В листинге 7.36 показаны некоторые служебные методы, необходимые для форматирования выходных страниц и сообщений об ошибках.
Листинг 7.36. Служебные методы в классе QanalysisServ (QanalysisServ.java)
public void header( PrintWriter out ){
out.println("<HTML>");
out.println("<HEAD><TITLE>QanalysisServ Output</TITLE>
</HEAD>");
out.println("<BODY>");
}
public void footer( PrintWriter out ){
out.println("<hr>" + version + "<br>");
out.println("</BODY>");
out.println("</HTML>");
out.close();
}
// assumes response has been set to text/html
private void errorMsg
( PrintWriter out, String msg, Exception ex ){
out.println("<html>");
out.println("<head><title>QanalysisServ Output</title>
</head>");
out.println("<body>");
out.println("<h2>" ); out.println( msg );
out.println("</h2><br>");
if( ex != null ){
ex.printStackTrace( out );
}
out.println("<br>");
footer( out );
}
}
Существует альтернативный подход к тому, чтобы обеспечить каждому сервлету доступ к соответствующему документу XML. Этот подход заключается в использовании служебных библиотек. В этом случае сервлет просто запрашивает документ из библиотеки независимо от того, находится ли файл XML на диске и где именно или он уже вызван в результате какого-либо другого запроса и находится в памяти.
Ниже перечислены характеристики созданного нами класса DOMlibrary.
Построен по шаблону единичного класса (singleton), который допускает создание только одного экземпляра класса. В такой схеме отсутствует открытый (public) конструктор, вместо него имеется статический метод, контролирующий создание единичного экземпляра класса и доступ к этому экземпляру.
Когда поступает запрос на документ XML, экземпляр DOMlibrary проверяет время создания файла, содержащего документ. Это гарантирует, что в ответ на запрос не будет выдан устаревший документ.
Реализует интерфейс Runnable, поэтому в нем может содержаться объект Thread, который периодически выполняет некоторые вспомогательные функции. Типичной вспомогательной функцией является исключение из памяти объектов Document, которые давно не использовались. Таким образом, постоянно задействованные документы, как правило, окажутся в памяти, в то время как редко используемые документы не будут занимать память, истощая ее ресурсы.
Вместо того чтобы использовать единичный класс, можно было бы реализовать все только через статические методы. Однако благодаря шаблону единичного класса мы выигрываем в отношении гибкости, получая, в частности, возможность реализовать интерфейс Runnabl e и использовать метод run для управления жизненным циклом документа в памяти. Шаблон единичного класса очень часто можно встретить в стандартной библиотеке Java.
В листинге 7.37 показан статический метод getLibrary, который при необходимости создает новый объект DOMlibrary. Все сервлеты, которым требуется доступ к документу XML, вызывают метод getLibrary для получения ссылки на единственный экземпляр библиотеки, а затем с помощью этой ссылки запрашивают нужный документ. Переменная maxAge используется в методе run для того, чтобы определить, когда документ следует убрать из памяти.
Листинг 7.37. Инструкции импорта и статические методы класса DOMlibrary (DOMIibrary.java)
public class DOMlibrary implements java.lang.Runnable
{
private static DOMlibrary theLib ;
private static int maxAge = 6000 ; // age in seconds
public synchronized static DOMlibrary getLibrary(){
if( theLib == null ) theLib = new DOMlibrary();
return theLib ;
}
public static void setMaxAge(int t) { maxAge = t ;}
Как показано в листинге 7.38, единственный конструктор является закрытым (private), чтобы гарантировать, что только лишь статический метод getLibrary может создать новый объект. Резидентные объекты XML document хранятся в хэш- таблице domHash; ключом является путь к соответствующему файлу. Хэш-табли- ца с именем trackerHash, используя тот же ключ, сохраняет объект DomTracker для каждого объекта XML document. Класс DOMTracker — внутренний класс в DOMlibrary; его код приведен в листинге 7.43. Обратите внимание на то, что объекту Thread (потоку, выполняющему метод run), присвоен самый низкий приоритет.
Листинг 7.38. Конструктор и переменные экземпляра класса DOMlibrary (DOMIibrary.java)
Анализ документа XML в DOMlibrary осуществляется в методе loadXML, как показано в листинге 7.39. Чтобы избежать многократных попыток загрузить документ с неверно указанным атрибутом scr (путь к файлу) или документ, загрузка которого вызывает синтаксическую ошибку, этот метод помещает в таблицу domHash строку, содержащую сообщение об ошибке, если таковая встречается. Если анализ документа проходит успешно, в таблицу trackerHash записывается соответствующий объект DomTracker. Это единственный метод, в котором вызываются специфические для анализа документов методы; если бы вы вместо анализатора Sun использовали для анализа что-либо другое, вам потребовалось бы несколько модифицировать этот метод.
Листинг 7.39. Метод loadXML осуществляет анализ документа XML (DOMIibrary.java)
private synchronized void loadXML(File xmlFile, String src ) {
//File xmlFile = new File( src ) ;
try {
long timestamp = xmlFile.lastModified();
InputSource input = Resolver.createInputSource( xmlFile );
// ... the "false" flag says not to validate (faster)
// XmlDocument is in the com.sun.xml.tree package
Document doc =
XmlDocument.createXmlDocument (input, false);
domHash.put( src, doc );
trackerHash.put( src, new DomTracker( timestamp ) );
}catch(SAXParseException spe ){
StringBuffer sb = new StringBuffer( spe.toString() );
sb.append("\n Line number: " + spe.getLineNumber());
sb.append("\nColumn number: " + spe.getColumnNumber() );
sb.append("\n Public ID: " + spe.getPublicId() );
sb.append("\n System ID: " + spe.getSystemId() + "\n");
lastErr = sb.toString();
System.out.print( lastErr );
}catch( SAXException se ){
lastErr = se.toString();
System.out.println("loadXML threw " + lastErr );
domHash.put( src, lastErr );
se.printStackTrace( System.out );
}catch( IOException ie ){
lastErr = ie.toString();
System.out.println("loadXML threw " + lastErr +
" trying to read " + src );
domHash.put( src, lastErr );
}
} // end loadXML
Когда сервлетам требуется получить документ, они вызывают метод getDOM, показанный в листинге 7.40. Если при создании документа возникают какие-либо проблемы, то вместо ссылки на документ этот метод возвращает null. Каждый раз, когда в хэш-таблице обнаруживается требуемый документ, в ассоциированном объекте DomTracker обновляется значение времени последнего использования, которое заменяется текущим временем. Заметим, что в нескольких местах создаются выходные сообщения, которые записываются в объект System.out и служат для отладки. Мы советует закомментировать их после того, как система заработает.
Листинг 7.40. Метод getDOM (DOMIibrary.java)
// either return the doc or null if a problem
public synchronized Document getDOM( String src ){
Object doc = domHash.get( src );
DomTracker dt = (DomTracker) trackerHash.get( src );
boolean newflag = false ;
File f = null ;
if( doc == null ){
System.out.println("DOMlibrary.getDOM new " + src );
f = new File( src );
loadXML( f, src ); // sets trackerHash
doc = domHash.get( src );
dt = (DomTracker) trackerHash.get( src );
newflag = true ;
System.out.println("DOMlibrary load OK");
}
else { // found a document - is it up to date?
f = new File( src );
if( dt.changed( f )){
System.out.println("DOMlibrary reloads " + src );
loadXML( f, src ); // sets trackerHash
newflag = true ;
doc = domHash.get( src );
dt = (DomTracker)trackerHash.get( src );
}
}
// if not a document, must be a string due to error
if( ! (doc instanceof Document )){
System.out.println("DOMlibrary: " + doc );
// could try for re-read here
}
if( doc instanceof Document ) {
if( ! newflag ){
dt = (DomTracker)trackerHash.get( src );
dt.setLastUse( System.currentTimeMillis());
}
return (Document) doc ;
}
return null ;
}
В листинге 7.41 представлена пара служебных методов, которые используются для удаления документа из памяти или для его перезагрузки.
Листинг 7.41. Некоторые служебные методы (DOMIibrary.java)
// use this to force removal of a dom. it
// returns last copy of dom or null if dom not in hash
public synchronized Document removeDOM( String src ){
Document dom = (Document)domHash.get( src );
if( dom != null ){
domHash.remove( src );
trackerHash.remove( src );
// System.out.println("Removed " + src );
}
return dom ;
}
// call this to force a reload after src is modified
public synchronized Document reloadDOM( String src ){
if( domHash.get( src ) != null ){
domHash.remove( src );
trackerHash.remove( src );
}
return getDOM( src );
}
Класс DOMlibrary должен реализовывать интерфейс Runnable, чтобы можно было использовать в фоновом режиме поток, имеющий минимальный приоритет и выполняющий служебные функции. Пример, приведенный в листинге 7.42, очень прост: поток удаляет все документы, которые давно не используются. Также в листинге 7.42 показаны служебные методы toString и getLastErr.
Листинг 7.42. Метод run и другие служебные методы (DOMIibrary.java)
// run is used for upkeep, not reading XML
public void run()
{ while( running ){
try{ Thread.sleep( 60000 );
// example management code
Enumeration keys = trackerHash.keys();
long time = System.currentTimeMillis();
while( keys.hasMoreElements() ){
String key = (String) keys.nextElement();
if(((DomTracker)trackerHash.get(key)).getAge(time) >
maxAge ){
removeDOM( key );
}
}
}catch(InterruptedException e){
}
}// end while
}
public String getLastErr(){ return lastErr ; }
public String toString()
{ StringBuffer sb = new StringBuffer("DOMlibrary contains ");
int ct = domHash.size();
if( ct > 0 ){
sb.append(Integer.toString( ct ) );
sb.append( " DOM objects ");
Enumeration e = domHash.keys();
while( e.hasMoreElements() ){
String key = (String)e.nextElement();
sb.append( key );
sb.append(" " );
}
}
else { sb.append("no DOM objects");
}
sb.append(" Last error: " );
sb.append( lastErr );
return sb.toString();
}
Экземпляр внутреннего класса DOMTracker создается всякий раз, когда загружается документ XML. Этот экземпляр подвергается обработке параллельно с самим объектом document. В нынешней версии нас интересуют только два параметра: время, когда документ XML был создан, и время, когда последний раз поступал запрос на этот документ. Как показано в листинге 7.43, метод getAge возвращает время в секундах, прошедшее с момента последнего использования документа, а метод changed проверяет время создания или последней модификации исходного файла.
Листинг 7.43. Определение класса DOMTracker как члена класса DOMIibrary (DOMIibrary.java)
// utility class to aid in tracking memory resident DOM
class DomTracker {
private long lastMod ;
private long lastUse ;
DomTracker( long timestamp ){
lastMod = timestamp ; // from File.lastModified();
lastUse = System.currentTimeMillis();
}
void setLastUse( long ts ){ lastUse = ts ; }
int getAge( long now ){ // return value in seconds
return (int)(( now - lastUse)/ 1000) ;
}
boolean changed( File f ){
long n = f.lastModified();
return !( n == lastMod );
}
}
}
Используя инструментальные средства, описанные в этой лекции, вы можете создать гибкую систему получения информации о ваших покупателях — как потенциальных, так и уже покупающих товары в вашем магазине. Поскольку эта система использует сценарий, основанный на XML и допускающий возможность изменения без перезапуска сервера, вы можете направлять опрос в то или иное русло в зависимости от мнений, которые высказывает клиент по ходу опроса.
Знаете ли Вы, что cогласно релятивистской мифологии "гравитационное линзирование - это физическое явление, связанное с отклонением лучей света в поле тяжести. Гравитационные линзы обясняют образование кратных изображений одного и того же астрономического объекта (квазаров, галактик), когда на луч зрения от источника к наблюдателю попадает другая галактика или скопление галактик (собственно линза). В некоторых изображениях происходит усиление яркости оригинального источника." (Релятивисты приводят примеры искажения изображений галактик в качестве подтверждения ОТО - воздействия гравитации на свет) При этом они забывают, что поле действия эффекта ОТО - это малые углы вблизи поверхности звезд, где на самом деле этот эффект не наблюдается (затменные двойные). Разница в шкалах явлений реального искажения изображений галактик и мифического отклонения вблизи звезд - 1011 раз. Приведу аналогию. Можно говорить о воздействии поверхностного натяжения на форму капель, но нельзя серьезно говорить о силе поверхностного натяжения, как о причине океанских приливов. Эфирная физика находит ответ на наблюдаемое явление искажения изображений галактик. Это результат нагрева эфира вблизи галактик, изменения его плотности и, следовательно, изменения скорости света на галактических расстояниях вследствие преломления света в эфире различной плотности. Подтверждением термической природы искажения изображений галактик является прямая связь этого искажения с радиоизлучением пространства, то есть эфира в этом месте, смещение спектра CMB (космическое микроволновое излучение) в данном направлении в высокочастотную область. Подробнее читайте в FAQ по эфирной физике.