В этой главе мы приводим обзор интерфейсов API (Application Programming Interface — интерфейс прикладных программ) для сервлетов Java, для JSP-страниц и для манипулирования элементами XML. Перечисленные инструментальные средства весьма существенны для создания динамических web-страниц на основе данных XML. Затем, используя эти интерфейсы API, мы рассмотрим различные подходы к представлению в сети каталога, созданного нами в главе 2.
При создании коммерческого сайта в Интернете программисты, пишущие на языке Java, имеют очень широкий выбор различных вариантов. Все эти варианты, однако, ограничены возможностями web-протоколов. Наиболее существенным ограничением является следующий аспект взаимодействия web-браузера клиента и web-сервера: каждый запрос пользователя инициирует один ответ сервера. Такое взаимодействие называется неустойчивым (stateless), так как в протоколе отсутствует требование, чтобы на сервере сохранялась какая-либо информация о транзакции после того, как ответ сервера отослан клиенту.
Взаимодействие по протоколу HTTP
Консорциум W3C (www.w3.org) поддерживает протокол HTTP 1.1 (это модификация предыдущей версии, HTTP 1, у которой было много недостатков) в качестве текущего стандарта для web-серверов. Этот стандарт определяет требования к формату запросов браузера и ответов web-сервера.
Сообщение-запрос браузера, отсылаемое на сервер, начинается с заголовка, состоящего из одной или нескольких строк ASCII-символов, каждая из которых заканчивается символом crl f (carriage-return-line-feed — возврат каретки и перевод строки). Первая строка нужна для указания метода,, идентификатора URI (Uniform Resource Identifier — универсальный идентификатор ресурса) и индикатора используемой версии HTTP. Стандартными методами для протокола HTTP 1.1 являются OPTIONS, GET, HEAD, POST, PUT, DELETE, TRACE и CONNECT, но для коммерческих сайтов обычно используются методы GET и POST. После заголовка могут следовать дополнительные данные.
В запросе на обычную HTML-страницу используется метод GET. Простые поисковые запросы также пересылаются методом GET, в то время как для отправки заполненных форм, например в приложении «корзина покупателя», обычно применяется метод POST. Практически разница между этими методами заключается в том, что в запросе по методу GET параметры присоединяются к строке заголовка, содержащей идентификатор URI, а в методе POST данные передаются в теле сообщения.
Заголовок также содержит строки, дающие дополнительную информацию о типах данных, которые может принять данный браузер, о предпочтительном типе соединения и о типе и версии самого браузера. В листинге 3.1 показан пример запроса, который посылается методом POST после щелчка на кнопке Send (Отправить) на обычной HTML-странице, содержащей формы для заполнения их пользователем и скрытую переменную с именем action и значением showkeywords. Заметим, что строки Accept: и User-Agent: разбиты на две части, так как иначе они бы не поместились на странице.
Листинг 3.1. Сообщение, пересылаемое браузером на сервер методом POST [Все представленные в курсе тексты программ можно найти на сайте издательства по адресу www.piter.com. — Примеч. ред.]
POST /servlet/cattest HTTP/1.1
Accept: application/msword, application/vnd .ms-excel, image/gif, image/x-xbitmap, image/]peg, image/pjpeg, */*
Referer: http://localhost/XmlEcommBook/CTestSnoop.html
Accept-Language: en-us
Content-Type: application/x-www-form-urlencoded
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)
Host: localhost:9000
Content-Length: 19
Connection: Keep-Alive
action=showkeywords
Ответное сообщение web-сервера на запрос браузера также обязательно содержит заголовок. Заголовок начинается со строки состояния, в которой указан используемый протокол, численный код состояния и текстовая версия кода состояния. В следующих строках приводится дополнительная информация в формате ключевое слово: значение, затем следует одна пустая строка.
В заголовке ответа обычно указываются тип и размер содержимого тела сообщения. Заголовок ответа также может содержать строки, которые устанавливают в браузере значения элементов cookie. Ниже приведен заголовок, полученный в ответ на запрос, показанный в листинге 3.1. После этого заголовка идет пустая строка, а затем — тело сообщения, содержащее код HTML:
НТТР/1.0 200 ОК
Server: Microsoft-PWS/2.0
Date. Mon, 25 Sep 2000 14:15:55 GMT
Content-Type, text/html
Тело ответного сообщения сервера может быть каким угодно, от стандартной HTML-страницы до двоичных данных закодированного изображения (а также совокупностью фрагментов данных, представленных в любых других специализированных форматах). Заметим, что в предыдущем заголовке тип содержимого был указан как text/html.
СОВЕТ
Для более детального изучения HTML мы советуем обратиться на сайт www.piter.com, где вы найдете множество изданий по этой тематике.
Технология сервлетов Java используется на самом базовом уровне web-сервера и важна для всех Java-функций сервера. Технология сервлетов подходит для выполнения вообще всех функций web-сервера, а серверы, построенные на других технологиях, могут быть сконфигурированы так, чтобы перенаправлять определенные типы запросов специальным расширениям, предназначенным для обработки сервлетов (процессорам сервлетов).
ПРИМЕЧАНИЕ
Полноценное описание API для сервлетов Java требует отдельной курса. В этом разделе мы приводим только краткий обзор по данной тематике.
На момент написания курса текущей версией API для сервлетов Java является версия 2.2, а версия 2.3 находится в стадии тестирования. Ко времени издания этого курса версия API 2.2, вероятно, будет уже широко поддерживаться специализированными web-серверами, а на существующих web-серверах будут установлены соответствующие расширения.
Если web-сервер снабжен расширением для обработки сервлетов, то соответствующие настройки конфигурации этого сервера позволяют определить, какие запросы должны обрабатываться сервлетами. На сайте компании Sun Microsystems по адресу http://java.sun.com/products/servlet/industry.html представлен список доступных расширений для сервлетов и специализированных web- серверов.
Ниже перечислены web-серверы, соответствующие критерию 100% Pure Java.
Tomcat. Открытый проект Apache Software Foundation (http://jakarta.apache.org).
Enhydra. Недорогой коммерческий сервер приложений, написанный на Java (www.lutris.com) и поддерживающий технологии сервлетов JavaServer Pages и Enterprise JavaBeans.
Orion. Коммерческий сервер приложений (www.ononserver.com), поддерживающий все последние технологии Java, включая Е2ЕЕ и Enterprise JavaBeans.
Resin. Этот сервер (www.caucho.com/index.xtp), соответствующий критерию 100% Pure Java, задуман как сервер приложений масштаба предприятия и специализируется на использовании XML и XSL.
Согласно терминологии Sun, web-сервер, обрабатывающий сервлеты Java, выполняет роль контейнера сервлетов (servlet container), так же как браузер играет роль контейнера апплетов. Контейнер сервлетов должен загружать и инициализировать требуемые классы и выполнять основные части транзакции HTTP. Контейнер сервлетов создает объект HttpServletRequest, который содержит удобное представление запроса пользователя, и объект HttpServl etResponse, который обеспечивает методы, необходимые для того, чтобы сервлет мог отослать ответ.
Контейнер сервлетов также создает поток (класс Thread), предназначенный для выполнения кода сервлета в ответ на запрос пользователя. Каждый запрос получает собственный поток, который независимо выполняет методы сервлета, причем обычно создается только один экземпляр сервлета. Это означает, что программистам следует быть очень внимательными при использовании переменных экземпляров.
Поскольку обычно экземпляр сервлета остается загруженным в память web- сервера в течение длительного времени, ответ на запрос, обращенный к сервлету, формируется очень быстро. Этот способ работает гораздо быстрее, чем технологии, в которых приходится порождать новый процесс и загружать приложение каждый раз, когда возникает запрос.
Классы и интерфейсы для сервлетов Java
Пакеты javax.servlet и javax.servlet.http содержат классы и интерфейсы, используемые при создании сервлетов. Пакет javax.servlet в основном содержит обобщенные классы и интерфейсы, в то время как классы пакета javax.servlet.http специализированы для работы с протоколом HTTP. В табл. 3.1 перечислены интерфейсы пакета javax.servlet.
Таблица 3.1. Интерфейсы пакета javax.setvlet
|
Интерфейс |
Описание |
|
Servlet |
Этот интерфейс определяет методы, которые должны быть реализованы в каждом сервлете. Интерфейс Servlet реализуется классом GenericServlet |
|
Servl etRequest |
Доступ ко всей информации о запросе клиента осуществляется через объект, реализующий этот интерфейс. За создание объекта ServletRequest отвечает процессор сервлетов |
|
Serl etResponse |
Объекты, реализующие этот интерфейс, создаются процессором сервлетов и передаются методу service сервлета для формирования ответа клиенту |
|
RequestDispatcher |
Этот интерфейс позволяет переадресовать запрос от текущего сервлета к другому сервлету или JSP-странице для дальнейшей обработки запроса |
|
SerletConfng |
Объекты, использующие этот интерфейс, применяются для хранения информации, которая помогает конфигурировать сервлет во время его инициализации |
|
Servl etContext |
Объекты, использующие этот интерфейс, позволяют сервлету получать информацию о процессоре сервлетов и об окружении сервлета |
|
SingleThreadModel |
В этом интерфейсе не содержится методов. Он используется для того, чтобы предотвратить одновременный доступ нескольких потоков к одному экземпляру сервлета. Процессор сервлетов выполняет это требование либо путем ограничения доступа и организации очереди запросов, либо путем создания отдельного экземпляра сервлета для каждого потока |
Классы пакета javax.servlet (табл. 3.2) обеспечивают только основной минимум необходимой функциональности. Вообще говоря, обычно программисты работают с классами, расширяющими классы этого пакета и предназначенными для более специализированных применений.
Таблица 3.2. Классы пакета javax.servlet
|
Класс |
Описание |
|
GenericServlet |
Этот класс обеспечивает минимально необходимую функциональность |
|
ServletInputStream |
Класс для чтения потока двоичных данных из запроса |
|
ServletOutputStream |
Класс для записи потока двоичных данных, входящих в ответ |
В пакете javax.servlet определены только два исключения. ServletException — это исключение общего назначения, используемое в классах сервлетов, в то время как исключение UnavaliableException возникает в случаях, когда сервлет должен сообщить, что он временно или постоянно недоступен. Эти классы не наследуют класса RuntimeException, поэтому, если некий метод объявляет, что он вызвал исключение ServletException, вызывающий метод должен перехватить это исключение.
Пакет javax.servlet.http добавляет интерфейсы, перечисленные в табл. 3.3, и классы, перечисленные в табл. 3.4. Это те интерфейсы и классы, с которыми вам как программисту придется работать при создании web-приложения с сервлетами.
Таблица 3.3. Интерфейсы пакета javax.servlet.http
|
Интерфейс |
Описание |
|
HttpServletRequest |
Это расширение интерфейса ServletRequest добавляет методы, специфические для запросов HTTP, например getCookies, который возвращает содержимое заголовка Cookie |
|
HttpServletResponse |
Это расширение интерфейса ServletResponse добавляет методы, специфические для протокола HTTP, например setHeader, который задает заголовки HTTP-ответов |
|
HttpSession |
Объекты, реализующие этот интерфейс, составляют существенную часть приложения «корзина покупателя», так как они позволяют программисту хранить информацию о пользователе в промежутках между посещениями страницы или между транзакциями |
|
HttpSessionBinding Listener |
Объекты, реализующие этот интерфейс, могут получить автоматические уведомление, когда они присоединяются к интерфейсу HttpSession или отсоединяются от него |
Таблица 3.4. Классы пакета javax.servlet.http
|
Класс |
Описание |
|
HttpServlet |
Это абстрактный класс, расширениями которого являются все используемые web-сервлеты |
|
Cookie |
Эти объекты используются, чтобы манипулировать информацией, которая содержится в файлах cookie и которая посылается сервером на браузер и возвращается при последующих запросах. Эта информация записывается в объект Cookie с помощью методов интерфейса HttpServletRequest |
|
HttpUtils |
Статические методы этого класса оказываются полезными в различных ситуациях |
|
HttpSessionBinDingEvent |
Класс событий, адресуемых объектам, которые реализуют интерфейс HttpSessionBindmgListener |
В обычных коммерческих приложениях запросы пользователей обрабатываются в следующей последовательности.
Данные, передаваемые в запросе, используются для создания объекта HttpServletRequest, который содержит информацию из заголовка запроса и всю остальную дополнительную информацию. Также создается объект HttpServletResponse в ходе подготовки к созданию ответа на запрос.
Вызывается метод service сервлета со ссылками на указанные два объекта. На основании типа запроса принимается решение, какой из методов обработки запроса следует вызвать в данном случае. Специализированные сер- влеты обычно не отменяют метод service, но могут заменить методы doGet и/или doPost.
Метод doGet или doPost исследует запрос и определяет, какие действия должно осуществить приложение. Во всех приложениях, за исключением самых простых, сервлеты обычно используют другие объекты для выполнения запросов к базам данных или для вычислений.
Обычное приложение с сервлетами включает в себя класс, который расширяет класс HttpServlet и реализует методы, необходимые для обработки различных типов запросов, адресованных приложению. В простом примере, показанном в листинге 3.2, сервлет должен отвечать только на запросы методом GET, поэтому в нем реализован только метод doGET. Обратите внимание, что ответ записывается в объект PrintWriter с именем out, который получен из объекта HttpServletResponse.
Листинг 3.2. Простой сервлет, обрабатывающий запрос GET (DateDemo.java)
import java.io.*;
import java.util.* ;
import javax.servlet.*;
import javax.servlet.http.*;
public class DateDemo extends HttpServlet
{
public void doGet(HttpServletRequest req,
HttpServletResponse resp)
throws ServletException, IOException
{
resp.setContentType("text/html");
PrintWriter out = resp.getWriter();
String username = req.getParameter("uname");
if( username == null ) username = "unknown person" ;
out.println("<HTML>");
out.println("<HEAD><TITLE>Date Demo</TITLE></HEAD>");
out.println("<BODY>");
out.println("Hello " + username + "<br>");
out.println("Date and time now: " + new Date().toString() + "<br>");
out.println("</BODY>");
out.println("</HTML>");
out.close();
}
}
В этом примере метод doGet пытается отыскать параметр с именем uname в объекте HttpServl etRequest, чтобы использовать его в ответе. Заметим также, что в сервлете задействован метод setContentType, для того чтобы установить тип содержимого ответа как text/htral.
Когда контейнер сервлета загружает код и создает экземпляр класса сервлета, API гарантирует, что первым будет вызван метод init и что он будет выполнен прежде, чем начнется обработка любых запросов пользователя. API сервлета обеспечивает передачу параметров инициализации вновь созданному экземпляру, используя объект класса ServletCongigClass.
До появления версии 2.2 API сервлетов каждый производитель использовал свой способ конфигурирования настроек инициализации. Теперь, когда компания Sun выбрала основанную на XML спецификацию, можно рассчитывать, что появится единая стандартная конфигурация.
Листинг 3.3 содержит документ XML, используемый для задания параметров инициализации сервлетов, которые мы будем обсуждать в главе 7.
Листинг 3.3. Задание параметров инициализации сервлетов (web.xml)
<web-app> <servlet><servlet-name>cattest</servlet-name> <servlet-class>com.XmlEcomBook.catalog.CatalogTestServ </servlet-class> </servlet> <servlet><servlet-name>catalog</servlet-name> <servlet-class>com.XmlEcomBook.catalog.CatalogServ </servlet-class> <init-param> <param-name>workdir</param-name> <param-value>e:\\scripts\\XMLgifts</param-value> </init-param> </servlet> <servlet><servlet-name>Questionnaire</servlet-name> <servlet-class>com.XmlEcomBook.Chap07.QuestionnaireServ </servlet-class> <init-param> <param-name>homedir</param-name> <param-value>e:\\scripts\\questionnaire</param-value> </init-param> </servlet> <servlet><servlet-name>Qanalysis</servlet-name> <servlet-class>com.XmlEcomBook.Chap07.QanalysisServ </servlet-class> <init-param> <param-name>homedir</param-name> <param-value>e:\\scripts\\questionnaire</param-value> </init-param> </servlet>
</web-app>
В методе init сервлета QuestionnaireServ параметр с именем homedir используется для того, чтобы задать значение Srting с именем homedir:
homedir = config.getlnitParameter("homedir");
Здесь config —это объект ServletConfig, переданный методу init или полученный из метода getServletConfigO. Помимо этого, метод init обычно устанавливает связь с базами данных и открывает файлы регистрации.
Генерирование ответа сервлетом
Все ресурсы, необходимые для контроля за созданием ответа, содержатся в интерфейсах ServletResponse и HttpServletResponse. Например, приведенные ниже обращения к методу setHeader можно использовать для того, чтобы запретить браузеру кэшировать посылаемую ему страницу:
response. setHeader("Expires",
"Mon, ,26 Jul 1990 05:00:00 GMT");
response.setHeader("Cache-Control" ,
"no-cache, must-revalidate");
response.setHeader("Pragma", "no-cache"); // для HTTP 1.0
Объект ServletResponse предоставляет программе-сервлету выходной поток, в который будет записано содержимое посылаемой страницы. Этот поток может быть типа PrintWriter, и тогда возможно преобразование содержимого в формат Unicode, или типа ServletOutputStream, то есть поток простых двоичных данных, когда преобразование не происходит.
Огромный успех языка Java обусловлен его простой архитектурой, основанной на компонентах JavaBeans. Хотя сначала планировалось использовать их как компоненты графического интерфейса, вскоре оказалось, что они весьма полезны и в неграфических приложениях. JavaBeans — это просто класс Java, который удовлетворяет следующим критериям:
он должен быть открытым и реализовывать Seri al i zabl e;
класс должен иметь конструктор без параметра;
доступ к любым переменным, используемым другими классами, в классе JavaBeans осуществляется через методы setXxx и getXxx.
Создавая классы и называя методы в соответствии с этими простыми условиями, можно частично автоматизировать конструирование различных приложений, используя готовые компоненты, особенно в технологии JavaServer Pages. Вы, вероятно, слышали название Enterprise JavaBeans в контексте разговоров о серверах web-приложений. Технология Enterprise JavaBeans значительно отличается от JavaBeans и является гораздо более сложной.
Многочисленные попытки разработать системы, позволяющие включать в статический контекст HTML-страницы динамические данные с помощью специальных тегов, встроенных в код HTML, основаны на следующей идее: при передаче страницы специальный процессор распознает эти теги и использует их для того, чтобы динамически вставить данные по мере передачи страницы. Часто тип файла, содержащего такую страницу, обозначается специальным образом, чтобы указать web-серверу на необходимость специальной обработки данного файла.
В качестве очень удачных примеров реализации такой системы можно назвать сервер Cold-Fusion (www.allaire.com) и страницу ASP (Active Server Pages) компании Microsoft (http://msdn.microsoft.com/workshop/server/default.asp).
Компания Sun для динамического генерирования web-страниц использует технологию JavaServer Pages QSP). Версия JSP 1.1 (на момент написания курса) входит в J2EE и играет важную роль при написании серверов web-приложений на языке Java.
Технология JSP основана на технологии сервлетов. По сути, процессор JSP преобразует статические элементы web-страниц и динамические элементы, определенные тегами JSP, в исходный код Java для класса сервлетов. Когда на web- сервер поступает запрос, адресованный JSP-странице, для создания ответа выполняется этот класс сервлетов. До тех пор пока статические элементы страницы не изменятся, создание ответа на запрос происходит очень быстро, потому что класс остается в памяти.
Одна из ведущих компаний-производителей программного обеспечения недавно провела тест на производительность для приложений ASP и аналогичных приложений JSP. Результаты теста показали, что реализация приложения на основе Orion JSP гораздо более быстродействующая, чем ASP-реализация. Постоянно обновляемые результаты тестов публикуются по адресу www.orionservr.com/ benchmarks/benchmark.html.
В приведенном ниже коде JSP-страницы теги JSP начинаются с символов <*= и заканчиваются символами %>. После компиляции в Java-класс запрос, обращенный к этой JSP-странице, выдаст обычный статический текст HTML-страницы, куда будет вставлена динамически сгенерированная строка, созданная с помощью метода toStnng, примененного к новому объекту Date:
<HTML>
<HEAD><TITLE>JRun Date Demo</TITLE></HEAD>
<BODY>
<H2>Date And Time <%= new java util Date().toString() %></H2>
<hr>
</BODY>
</HTML>
Из-за больших различий между интерфейсами API для ранних версий JSP и для текущей версии 1.1 на данный момент существуют два стиля написания тегов JSP. Старый стиль пока применяется наряду с новым.
Таблица 3.5. Теги JSP, использующие символы <% (старый стиль)
|
Тег |
Назначение |
Пример |
|
<%-- --%> |
Комментарии |
<%--это комментарий--%> |
|
<%= %> |
Выражения (вычисляемые как объекты класса String) |
<%= new Date() %> |
|
<%! %> |
Объявления |
<%! Date myD = new Date(): %> |
|
<% %> |
Фрагменты кода |
<%for( int i = 0 : i < 10 ; i++ { %> |
|
<%@ %> |
Директивы |
<%@ page imprt="java.util.*" %> |
Как показано в табл. 3.6, новый стиль тегов JSP согласован с правилами форматирования, принятыми в XML. Вообще говоря, политика компании Sun в этом отношении сводится к тому, чтобы страницы JavaServer Pages соответствовали правилам языка XML.
Таблица 3.6. Теги JSP, согласованные с правилами XML (новый стиль)
|
Тег JSP |
Описание |
|
<jsp: include /> |
Включает в страницу текст из указанного файла |
|
<jsp: forward /> |
Переадресует запрос сервлету, другой JSP-страницеили статической web-странице |
|
<jsp:param /> |
Используется внутри тегов forward, include и plugin для добавления или модифицирования параметров в объекте request |
|
<jsp:getProperty /> |
Выдает значение свойства bean-компонента по его имени |
|
<jsp:setProperty /> |
Задает значения свойств bean-компонентов |
|
<jsp:useBean /> |
Создает или отыскивает bean-компонент с указанным именем и областью видимости |
|
<jsp:plugm /> |
Предоставляет полную информацию для загрузки подключаемых модулей Java (Java Plug-In) в web-браузер клиента |
Пользовательские библиотеки тегов
Удобным свойством интерфейса API для JavaServer Pages является возможность определять пользовательские библиотеки тегов. Это очень мощное средство, позволяющее задействовать специализированные инструментальные средства так же легко, как стандартные теги.
Пользовательские теги задействуют интерфейсы и классы пакета javax.se- rlet. jsp.tagext. Пользовательские библиотеки тегов намного упрощают работу по созданию JSP-страниц.
Ниже описана последовательность событий, происходящих при обработке запроса, обращенного к JSP.
Запрос, обращенный к JSP, направляется web-сервером к процессору JSP (JSP engine).
Если исходная страница изменилась или еще не была скомпилирована, то компилятор обрабатывает исходный код и создает эквивалентный исходный код Java для сервлета, реализующего интерфейс HttpJspPage.
Затем код компилируется и выполняется новый сервлет. Сервлет может оставаться в памяти, что позволяет очень быстро отвечать на следующий запрос.
Объекты request и response — это в точности те же самые объекты, которые используются в обычных сервлетах; разница заключается только в том, что метод service создается процессором JSP.
Встроенные переменные в JSP-страницах
В табл. 3.7 перечислены встроенные переменные, которые доступны в JSP-страницах по умолчанию.
Таблица 3.7. Встроенные переменные в JSP-страницах
|
Имя переменной |
Тип |
Описание |
|
request |
Объект класса, являющегося подклассом javax.servlet.ServletRequest |
Представляет запрос пользователя |
|
response |
Объект класса, являющегося подклассом javax.servlet.ServletResponse |
Создает ответ на запрос |
|
pageContext |
Объект класса javax.servlet.jsp.PageContext |
Содержит атрибуты страницы |
|
session |
Объект класса javax.servlet.http.HttpSession |
Содержит произвольные переменные, связанные с данным сеансом |
|
application |
Объект класса javax.servlet.ServletContext |
Содержит атрибуты для всего приложения и влияет на интерпретацию некоторых других тегов |
|
out |
Объект класса javax.servlet.jsp.JspWriter |
Выходной поток для данного ответа |
|
config |
Объект класса javax.servlet.ServletConfig |
Содержит пары имя-значение для параметров инициализации сервлета и объект ServletContext |
|
page |
Ссылка на объект, синоним this |
Возвращает ссылку на сервлет |
|
exception |
Объект класса javax.lang.Throwable или одного из его подклассов |
Содержит только те страницы, которые обозначены в директиве страницы как ошибочные |
Каталог товаров, созданный нами в виде документа XML, организован последовательно. Однако мы хотели бы, чтобы пользователи имели возможность более гибкого доступа к элементам каталога, то есть чтобы им не приходилось просматривать страницу за страницей в поисках нужного товара. В этом разделе мы рассмотрим технологии Java, позволяющие организовать такой гибкий доступ к элементам каталога.
API для объектной модели документа
В этом курсе мы в основном будем использовать набор инструментальных средств JAXP (Java API for XML Parsing — интерфейс прикладных программ Java для анализа XML) компании Sun. Основной интерфейс API для манипулирования фрагментами документов XML согласован с формальной спецификацией DOM (Document Object Model — объектная модель документа) Консорциума W3C. Этот интерфейс API дает наиболее полный доступ ко всем элементам документа XML, с чем связана его сложность по сравнению с другими интерфейсами API. Существуют более простые интерфейсы API, поддерживающие DOM, но версия Консорциума W3C является наиболее распространенной.
Текущую версию набора инструментальных средств JAXP вы можете загрузить с web-сайта компании Sun или использовать версию, представленную на сайте Tomcat по адресу jakarta.apache.org. Этот набор состоит из пакетов Java, которые представляют WSC-версию интерфейса API, и пакетов, реализующих различные анализаторы и служебные программы. На момент написания курса этот набор не входил в стандартную библиотеку расширений Java, и его придется загрузить с сайта разработчиков по адресу http://developer.java.sun.com/developer/ products/xml.
Создание объектной модели документа для каталога товаров
Как мы говорили в главе 1, исходное создание объектной модели документов на Java очень просто, поскольку вся работа выполняется анализатором, входящим в набор инструментальных средств. В листинге 3.4 показан фрагмент кода, который на основе документа XML строит объект org.w3c.dom.Document. Основная часть кода состоит из инструкций, перехватывающих различные синтаксические ошибки.
Листинг 3.4. Пример синтаксического анализа документа (TheCatalog.java)
]
import javax.xml.parsers.* ;
import org.xml.sax.* ;
import org.w3c.dom.* ;
public class TheCatalog
{
org.w3c.dom.Document catDoc ;
public TheCatalog( File f, TextArea msg, TextField status ){
try {
timestamp = f.lastModified();
DocumentBuilderFactory dbf =
DocumentBuilderFactory.newInstance ();
// statements to configure the DocumentBuilder would go here
DocumentBuilder db = dbf.newDocumentBuilder ();
catDoc = db.parse( f );
}catch(ParserConfigurationException pce){
lastErr = pce.toString();
System.out.println("constructor threw " + lastErr );
}catch(SAXParseException spe ){
StringBuffer sb = new StringBuffer( spe.toString() );
sb.append("\n Line number: " + spe.getLineNumber());
sb.append("\nColumn number: " + spe.getColumnNumber() );
sb.append("\n Public ID: " + spe.getPublicId() );
sb.append("\n System ID: " + spe.getSystemId() + "\n");
lastErr = sb.toString();
System.out.print( lastErr );
}catch( SAXException se ){
lastErr = se.toString();
System.out.println("constructor threw " + lastErr );
se.printStackTrace( System.out );
}catch( IOException ie ){
lastErr = ie.toString();
System.out.println("constructor threw " + lastErr +
" trying to read " + f.getAbsolutePath() );
}
}
Структура данных DOM выстраивается в памяти в такую же иерархическую систему, какая была в документе XML. Объекты Java представляют различные части документа XML и связаны ссылками на соседние элементы, как показано на рис. 1.2 в главе 1. Программные интерфейсы объектов Java, представляющие различные части документа, определены в пакете org.w3c.dom. Каждая часть документа XML, включая корневой элемент, представлена в виде объекта, реализующего интерфейс, который является расширением фундаментального интерфейса Node.
Исходный набор методов для всего пакета org.w3c.dom обеспечивается интерфейсом Node. В этом пакете имеется 13 интерфейсов, производных от интерфейса Node, которые представляют различные части документа. Хотя все они являются расширением Node, определенные методы этого интерфейса в некоторых производных интерфейсах не имеют смысла. В табл. 3.8 перечислены методы интерфейса Node. Обратите внимание на то, что интерпретация возвращаемых значений nodeName и nodeValue зависит от типа узла [Node — узел. — Примеч. перев. ].
Таблица 3.8. Методы интерфейса Node
|
Метод |
Возвращаемое значение |
Описание |
|
getNodeName |
NodeName |
Возвращаемое значение — строка, представляющая имя Node; интерпретация зависит от типа узла |
|
getNodeVal ue |
NodeVal ue |
Возвращаемое значение — строка, представляющая значение узла; интерпретация зависит от типа узла |
|
setNodeValue |
Пустое множество |
|
|
getNodeType |
Целочисленное значение типа short |
Возвращаемое число идентифицирует тип узла согласно определению в интерфейсе Node |
|
getParentNode |
Ссылка на узел |
Возвращается ссылка на узел, являющийся родительским по отношению к данному в иерархии DOM. Не для всех типов узлов существуют родительские узлы |
|
getChildNodes |
Ссылка на семейство узлов NodeList |
Объекты NodeList обеспечивают доступ к упорядоченному списку ссылок на узлы |
|
getFirstChild |
Ссылка на узел |
Первый дочерний узел для данного узла или null, если дочерние узлы отсутствуют |
|
getLastChild |
Ссылка на узел |
Последний дочерний узел для данного или null, если дочерние узлы отсутствуют |
|
getPrevlous Sibling |
Ссылка на узел |
Узел, непосредственно предшествующий данному, или null, если таковой отсутствует |
|
getNextSibling |
Ссылка на узел |
Узел, непосредственно следующий за данным, или null, если таковой отсутствует |
|
getAttributes |
Ссылка на семейство NamedNodeMap |
Методы NamedNodeMap обеспечивают доступ к атрибутам по имени. Возвращает null, если атрибуты отсутствуют |
|
getOwnerDocument |
Ссылка на документ |
Объект Document, которому принадлежит данный узел, или null, если этот узел сам является объектом Document |
Тип узла, с которым мы будем в основном иметь дело, называется Element; эти объекты используют интерфейс org.w3c.dom.Element. Интерфейс Element добавляет несколько методов для работы с атрибутами и именованными узлами, содержащимися в узле Element.
ПРИМЕЧАНИЕ
Для упрощения терминологии мы будем называть объекты, реализующие интерфейсы Node, Element и др., объектами Node, Element (узел, элемент) и др. соответственно. Фактический тип объектов, реализующих интерфейсы, не играет роли, так как мы будем использовать только методы интерфейсов.
Поскольку за недостатком места мы не можем предоставить формальное изложение API org.w3c.dom в том виде, в котором оно приводится на сайте консорциума W3C, исследуем по крайней мере, каким образом фрагмент каталога, соответствующий какому-то товару, представляется объектами Java. В листинге 3.5 показан код XML для одного товара; объект Element для этого кода будет содержать иерархию объектов Node, представляющих XML.
Листинг 3.5. Код XML для одного товара (catalog.xml)
<product id="bk0022" keywords="gardening, plants">
<name>Guide to Plants</name>
<description>
<paragraph>
<italics>Everything</italics> you've ever wanted to know about plants.
</paragraph>
</description>
<price>$12.99</price>
<quanti ty_i n_stock>4</quanti ty_in_stock>
<image format="gif" width="234" height="468"
src=»images/covers/plants.gif»>
<caption>
<paragraph>This is the cover from the first edition.</paragraph>
</caption>
</image>
<onsale_date>
<month>4</month>
<day_of_month>4</day_of_month>
<year>1999</year>
</onsale_date>
</product>
Например, если вы выполните метод getFirstChild элемента product, то получите ссылку на узел, представляющий элемент name. Элемент name содержит дочерний узел типа Text, а значением этого узла является строка Guide to Plants (справочник по растениям).
Доступ к XML-атрибутам элемента product осуществляется с помощью метода getAttribute, который по имени атрибута возвращает строку — значение атрибута, как в следующем примере:
String id = product.getAttribute("id")
String keywords = product.getAttribute("keywords");
Доступ к узлам первого по отношению к элементу product уровня иерархии осуществляется с помощью метода getChil dNodes. Этот метод возвращает объект, реализующий интерфейс NodeLi st. Объект NodeLi st отличается от других тем, что он содержит динамическое представление документа XML. Это значит, что если в иерархию узлов элемента product будет встроен какой-либо новый узел, это изменение автоматически отразится в объекте NodeLi st (списке узлов XML).
В этом интерфейсе имеются только два метода:
Node item ( int n ) — возвращает ссылку на n-й узел в списке или null, если данная позиция списка пуста.
Объект Java, который инкапсулирует весь документ XML, реализует расширение Document интерфейса Node. Большая часть методов этого интерфейса связана с созданием или модифицированием DOM в памяти. Тот метод, который мы будем использовать (getDocumentElement), просто возвращает ссылку на корневой элемент данного документа:
Element rootE = catDoc.getDocumentElement();
Например, чтобы получить список узлов (объект NodeLi st) всех элементов product в документе catDoc, следует использовать следующие методы:
Element rootE = catDoc.getDocumentElement();
NodeList nl = rootE.getElementsByTagName("product");
Пользуясь приведенным выше кратким обзором интерфейсов Java, дающих доступ к объектной модели документа, мы можем исследовать вопрос о создании
различных структур данных, которые ускорят процесс поиска товаров по каталогу, оставляя в то же время информацию о товарах в формате DOM. Ниже перечислены некоторые структуры данных и функциональные возможности, которые нам нужны:
перечень категорий product_line (серий товаров) каталога;
перечень всех товаров каждой серии;
быстрый поиск информации о конкретном товаре (содержимого элемента product) по указанному идентификатору товара (id);
список всех используемых ключевых слов, который можно предоставить пользователю для поиска нужных ему товаров;
быстрый поиск товаров по выбранным ключевым словам.
Метод scanCatalog, как показано в листинге 3.6, создает структуры данных, удовлетворяющие этим требованиям. Эти структуры данных — массивы типа String с именами productLineNames и keywords и объекты Hashtable с именами productLi neHT, productHT и prodByKeyHT. Мы используем классы коллекций, совместимые как с пакетом JDK Java 1.1, так и с JDK Java 1.2, поскольку (на момент написания курса) некоторые процессоры сервлетов до сих пор используют библиотеки Java 1.1.
Метод scanCatal og вызывается сразу же после того, как конструктор этого класса (листинг 3.4) завершил разбор файла XML. Заметим, что в методе scanCatalog первый метод, примененный к корневому элементу (гЕ), — это метод normalize(). Причина этого заключается в том, что у анализатора Sun имеется свойство воспринимать символы возврата каретки и дополнительные пробелы в тексте (которые авторы, пишущие на XML, часто используют для того, чтобы документ было легче просматривать) так, что этот текст разбивается указанными символами на несколько узлов типа Text. Метод normalize объединяет содержимое всех примыкающих друг к другу узлов Text в один узел Text.
Листинг 3.6. Метод scanCatalog инициализирует различные объекты Hashtable (theCatalog.java)
public void scanCatalog(){
Element rE = catDoc.getDocumentElement();
// the root
rE.normalize();
productLineNL = rE.getElementsByTagName("product_line");
productLineHT = new Hashtable();
productHT = new Hashtable();
prodByKeyHT = new Hashtable();
// note that in contrast to other get methods, getAttributes
// returns "" if the attribute does not exist
int i,j, ct = productLineNL.getLength();
productLineNames = new String[ ct ];
for( i = 0 ; i < ct ; i++ ){
Element plE = (Element)productLineNL.item(i);
productLineNames[i] = plE.getAttribute("name");
NodeList prodNL = plE.getElementsByTagName("product");
productLineHT.put( productLineNames[i], prodNL ); // node list
int pct = prodNL.getLength();
System.out.println( productLineNames[i] + " ct " + pct );
for( j = 0 ; j < pct ; j++ ){
Element prodE = (Element)prodNL.item(j) ;
String id = prodE.getAttribute("id");
if( id == null ){
System.out.println("No id - productLine " +
productLineNames[i] + " product " + j );
}
else { productHT.put( id, prodE );
// product by id
String keys = prodE.getAttribute("keywords");
if( keys != null ){
addProdByKey( keys, prodE );
}
}
}
}
// end loop over product lines
ct = prodByKeyHT.size();
keywords = new String[ ct ];
i = 0 ;
Enumeration en = prodByKeyHT.keys();
while( en.hasMoreElements()){
keywords[i++] = (String)en.nextElement();
}
shellSortStr( keywords );
}
Метод addProdByKey создает объект prodByKeyHT, как показано в листинге 3.7. Этот метод должен разрешить некое затруднение, связанное с тем, что строка keywds может содержать не одно, а несколько ключевых слов (или фраз), разделенных запятыми. Для решения этой задачи используется класс StringTokenizer, но обратите внимание, что после разбора строки с помощью метода StringTokenizer нужно использовать метод trim, который убирает лишние пробелы перед строкой ключевых слов и после нее. Объект Vector, в котором хранятся ссылки на элементы, сохраняет исходный порядок расположения товаров, то есть такой же, какой был в файле XML.
Листинг 3.7. Метод addProdByKey (TheCatalog.java)
// разбивает строку keywds на отдельные ключевые слова,
// затем создает вектор v или добавляет элемент рЕ к уже
// существующему вектору в prodByKeyHT
private void addProdByKey( String keywds, Element pE ){
StringTokenizer st = new StringTokenizer( keywds, ",");
while( st.hasMoreTokens() ){
String key = st.nextToken().trim();
Vector v = (Vector)prodByKeyHT.get( key );
if( v == null ){
v = new Vector();
prodByKeyHT.put( key, v );
}
v.addElement( pE );
}
}
Информация для представления каталога в сети
Вообще говоря, перед тем как каталог отображается в окне браузера пользователя, содержащаяся в нем информация проходит несколько этапов обработки. Основной элемент DOM, который фигурирует на этих этапах, — Element, представляющий отдельный товар. Этапы создания виртуального магазина на основе каталога XML следующие.
Берется объектная модель документа (каталога), представленная в виде списка узлов (NodeLi st), каждый из которых соответствует некоторому товару.
К списку узлов применяются правила отбора. Возможные правила отбора включают идентификатор товара (id), ключевое слово или название серии товаров (productjtine).
При необходимости массив элементов сортируется.
Для каждого элемента (товара) генерируется и добавляется к создаваемой странице код HTML, задающий формат представления данных об этом товаре.
Организация поиска по ключевым словам
Поскольку мы уже проделали некоторую работу по кодированию ключевых слов для каждого товара в каталоге, мы, конечно, хотели бы, чтобы пользователю было удобно работать с этими ключевыми словами. Напомним, что, как сказано в предыдущем разделе, методы scanCatalog и addProdByKey создают массив ключевых слов (объектов типа String), а также поддерживают объект Hashtable, содержащий объект Vector, в котором хранятся ссылки на элементы Element, снабженные ключевыми словами.
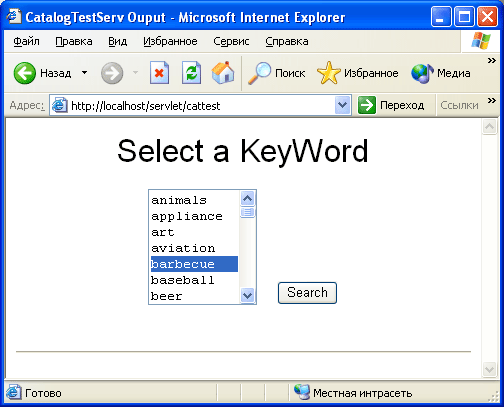
Можно было бы, конечно, организовать поиск таким образом: пользователь набирает какое-либо слово, характеризующее искомый товар, в специальной форме на HTML-странице, а потом осуществляется проверка, содержится ли оно в списке ключевых слов. Но мы организуем поиск иначе, с помощью раскрывающегося списка. Для этого используется тег HTML SELECT и список всех ключевых слов и фраз. Получившаяся страница представлена на рис. 3.1.
Код HTML этой страницы (с небольшим количеством ключевых слов) представлен в листинге 3.8. Заметим, что помимо перечня ключевых слов мы включили в код скрытую переменную с именем action и значением keywordsearch.
Листинг 3.8. Код HTML для создания раскрывающегося списка ключевых слов
<center><h2>Select a KeyWord</h2>
<form raethod="POST" action="http://localhost/servlet/cattest" >
<input type="HIDDEN" name="action" value="keywdsearch" >
<select name="keyword" size="8">
<option value="animals" > animals
<option value="appliance" > appliance
<option value="area codes" > area codes
<option value="art" > art
<option value="aviation" > aviation
<option value="barbecue" > barbecue
<option value="basebaU" > baseball <option value="beer" > beer
<option value="writing" > writing
</select>
<input type="SUBMIT" value="Search" >
</form>
</center><hr>
Рис. З.1. Форма для выбора ключевого слова
Чтобы инкапсулировать функции форматирования каталога в один класс, который можно было бы использовать как с сервлетами, так и с JSP-страницами, мы написали класс CatalogBean. Включив как можно больше форматирующих функций в CatalogBean, мы значительно упростим код сервлета. В сервлет достаточно включить следующий код для генерации раскрывающегося списка ключевых слов:
public void doKeywordSelect( PrintWriter out ){
CatalogBean cb = new CatalogBeanO;
cb.setHidden( "action","keywdsearch");
out.println("<center><h2>Select a KeyWord</h2>");
out.print( cb.doKeywordSelect( alias ) );
out.println("</center><hr>") ; }
Вызывая метод setHidden, мы тем самым сообщаем классу CatalogBean, что при форматировании всех списков нужно добавить тег скрытой переменной. В данном случае получится следующий результат:
<input type= "HIDDEN" name= "action" value = "keywdsearch">
За счет того что метод doKeywordSelect возвращает String, в то время как этому методу передаются данные типа PrintWriter, мы избегаем необходимости связывать метод doKeywordSel ect с каким-либо конкретным типом выходного потока. Как показано в листинге 3.9, мы используем класс StringBuffer для создания всего текста раскрывающегося списка товаров. Заметим, что при обращении к методу getKeywords выдает массив Stri ng, созданный методом scanCatal og (листинг 3.6).
Листинг 3.9. Метод, форматирующий строковый массив в раскрывающийся список (Catalog Bean.java)
public String doKeywordSelect(String alias ){
StringBuffer sb = new StringBuffer( "<form method=\"POST\"
action=\"" );
sb.append( alias ); sb.append("\" >\r\n");
String[] kwd = getKeywords();
int i ;
int ct = hiddenNames.size();
if( ct > 0 ){
for( i = 0; i < ct ; i++ ){
sb.append("<input type=\"HIDDEN\" name=\"");
sb.append( hiddenNames.elementAt(i) );
sb.append("\" value=\"");
sb.append( hiddenVals.elementAt(i) );
sb.append( "\" >\r\n");
}
}
sb.append("<select name=\"keyword\" size=\"8\">" );
for( i = 0 ; i < kwd.length ; i ++ ){
sb.append("<option value=\"" );
sb.append( kwd[i] );
sb.append( "\" > " );
sb.append( kwd[i] ); sb.append("\r\n");
}
sb.append("</select>\r\n");
sb.append("<input type=\"SUBMIT\" value=\"Search\" >\r\n" );
sb.append("</form>\r\n" );
return sb.toString();
}
Форматирование описаний товаров
Пытаясь решить, как должны выглядеть описания товаров, мы пришли к выводу, что критериями выбора способа представления должны являться:
гибкость стилей — существенным требованием является отделение внешних аспектов стиля (таких, как цвет текста и размер шрифта) от кода, создающего изображение;
гибкость содержимого — нужен метод, позволяющий web-дизайнеру страницы выбирать содержимое любой части документа XML (каталога товаров), не меняя при этом классы Java.
Самым очевидным инструментом для достижения гибкости в применении различных стилей к документу являются каскадные таблицы стилей. С помощью CSS задаются параметры стиля различных компонентов web-страницы. В настоящее время CSS является наиболее широко поддерживаемым стандартом и входит в официальную часть спецификации HTML 4.
Помещая информацию о стиле в отдельный файл — так называемую таблицу стилей (style sheet), мы значительно уменьшаем объем текста, который приходится генерировать сервлету. Если для всех страниц на вашем сайте используется одна и та же таблица стилей, то web-браузер пользователя может кэшировать ее и таким образом уменьшить время ожидания ответа от сервера для всего сайта.
В листинге 3.10 приводится простая таблица стилей, задающая стиль тегов HTML <body>, <hl>, <h2> и <р> — четыре именованных стиля, которые мы будем использовать в следующем примере.
СОВЕТ
Превосходное пособие по применению таблиц стилей вы найдете на сайте www.htlmhepl.com/reference/ess.
Листинг 3.10. Пример таблицы стилей (catalog.css)
body{font-family:Arial font-size:10.0pt}
h1{font-size:30pt; font-family:Arial; color:red ;}
h2{font-size:20pt; font-family:Arial; color:navy; }
p {font-size:10pt; font-family:Arial, Helvetica;
background-color:#fef6df ;}
.ch1{font-size:30pt; font-family:Arial; color:red ;}
.ch2{font-size:20pt; font-family:Arial; color:navy ;}
.ch3{font-size:15pt; font-family:Arial; color:purple ;}
.ch4{font-size:10pt; font-family:Arial; color:black ;}
Таблицу стилей можно присоединить к HTML-странице с помощью тега link, помещенного внутрь тега <head>, как показано в следующем примере:
<head><title>Catalog Test Servlet Output</title>
<link rel="stylesheet" href="http://localhost/XmlEcommBook/catalog.css"
type="text/css" media="screen" >
</head>
Присоединив к странице такую таблицу стилей, можно очень легко задавать стиль любого элемента. Для этого нужно просто добавить к тегу атрибут, например style = "ch2". Указанный таким образом стиль замещает стиль, задаваемый браузером по умолчанию для этого элемента.
Чтобы понять, насколько использование таблиц стилей эффективнее, можно сравнить два фрагмента кода HTML, выполняющих одну и ту же функцию.
Пример использования таблицы стилей:
<а class="ch3" href= "http://localhost/servlet/cattest?action=showproduct">
Guide to Plants </a>
<span class="ch4">price ea = $12.99 </span>
Пример непосредственного задания стилей:
<font face="Anal" SIZE="15pt" color="purple" >
<a class="ch3" href= "http://localhost/servlet/cattest?action=showproduct">
Guide to Plants
</a>
</font>
<font face="Anal" SIZE="10pt" color="black" > price ea = $12.99 </font>
Чтобы добиться гибкости внутреннего содержимого страницы, мы собираемся использовать форматирующий класс с именем ProductFormatter Этот класс выдает данные элемента XML product в формате, задаваемом с помощью списка имен полей, которому сопоставлен список стилей, применяемых к тексту каждого поля.
В качестве простого примера рассмотрим следующую ситуацию: для каждого товара требуется отобразить на странице его название в формате ch3 и цену в формате ch4. Для этого мы определяем два массива типа String:
Stnng[] elem = { "prname", "price" };
String[] shortSt = { "ch3", "ch4"
Также мы хотим, чтобы имя каждого товара было представлено в виде ссылки, щелчок на которой вызывает отображение полной информации о данном товаре. Для этого строковой переменной alink присваивается соответствующее значение, наподобие следующего:
"http://localhost/servlet/cattest?action=showproduct"
Также нам надо определить целочисленную переменную типа int с именем linkN, содержащую индекс (номер) поля, которое должно стать ссылкой. В нашем случае linkN0, так как такой ссылкой должно быть имя элемента (название товара). Когда эти параметры установлены, метод doOutput, приведенный в листинге 3.11, может форматировать данные для конкретного товара (элемента product), содержащиеся в документе XML catalog.xml. В результате выполнения метода doOutput получается строка, которую уже можно вставлять в HTML-страницу.
Листинг 3.11. Метод doOutput (productFormatter.java)
public String doOutput( Element el ){
StringBuffer sb = new StringBuffer( );
String pid = null ;
if( aLink != null ){
pid = "&id=" + el.getAttribute("id") ;
System.out.println("pid is " + pid );
}
else { System.out.println("aLink null");
}
for( int i = 0 ; i < elem.length ; i++ ){
if( i == linkN && pid != null ){
sb.append( "<a class=\"" );
sb.append( style[i] );
sb.append("\" href=\"");
sb.append( aLink );
sb.append( pid );
sb.append("\">");
addText( sb, elem[i], el );
sb.append( " </a>");
}
else {
sb.append( "<span class=\"");
sb.append( style[i] ); sb.append("\">");
addText( sb, elem[i], el );
sb.append( " </span>");
}
}
return sb.toString();
}
Например, для элемента product, данные о котором приведены в листинге 3.12, в результате выполнения метода doOutput получится следующая строка:
<а class="ch3" href= "http //localhost/servlet/cattest?action=showproduct">
Guide to Plants </a> <span class="ch4">price ea = $12 99 </span>
Листинг 3.12. Описание отдельного товара (элемента product) из каталога catalog.xml
<product id="bk0022" keywords='gardening, plants">
<name>Guide to Plants</name>
<description>
<paragraph>
<italics>Everything</italics> you've ever wanted to know about plants.
</paragraph>
</description>
<price>$12 99</price>
<quantity_in_stock>4</quantity_in_stock>
<image format="gif" width="234" height="400" src="images/covers/plantsvl gif">
<caption>
<paragraph>This is the cover from the first edition </paragraph>
</caption>
</image>
<onsale_date>
<month>4</month>
<day_of_month>4</day_of_month>
<year>1999</year>
</onsale_date>
<shipping_infо type="UPS" value="l.0" />
</product>
До сих пор мы занимались форматированием данных для одного товара Теперь посмотрим, как создать на странице список товаров со ссылками на их полные описания В классе CatalogBean имеется массив ссылок на элементы с именем selected Метод setlmtialSelected (листинг 3 13) устанавливает, что будет содержаться в этом массиве — либо полный список всех товаров, либо список товаров какой-либо одной серии
Листинг 3.13. Метод setlmtialSelected из CatalogBean (CatalogBean.java)
public boolean setInitialSelect(String s){
boolean ret = false ;
if( s.equals("all") ){
selected = cat.getAllProduct(); ret = true ;
}
else {
selected = cat.getProductsByPL( s );
if( selected != null ) ret = true ;
else {
System.out.println("not working yet");
}
}
return ret ;
}
public String doOutput( int n ){
return pf.doOutput( selected[n] );
}
В классе Catal ogBean имеется также метод doOutput, который просто вызывает метод doOutput класса ProductFormatter Элемент (товар), к которому применяется последний метод, указывается как n-й элемент массива selected:
public String doOutput( int n ){
return pf doOutput( selected[n] );
}
Теперь мы можем объединить все написанные нами компоненты для создания форматированной HTML-страницы, отображающей весь каталог. В листинге 3 14 приведен метод сервлета doPost, который устанавливает заголовок страницы, затем создает теги <head> и <title>, за которыми следует строка, содержащая тег <link> для связывания HTML-страницы с таблицей стилей. Затем следует тег <boby> и вызывается метод completeCatalog Далее пишутся закрывающие теги и закрывается выходной поток PnntWnter
Листинг 3.14. Метод doPost сервлета, отображающий весь каталог (CatalogTestServ.java)
public void doPost(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
resp.setContentType("text/html");
PrintWriter out = new PrintWriter(resp.getOutputStream());
String action = req.getParameter("action");
out.println("<html>");
out.println("<head><title>CatalogTestServ Output</title>");
out.println( cssLink );
out.println("</head>\r\n<body>");
try {
if( "showcatalog".equals( action )){
completeCatalog( out );
}
else if( "selectkeyword".equals( action )){
doKeywordSelect( out );
}
}catch( Exception e ){
e.printStackTrace( out );
}
out.println("</body>");
out.println("</html>");
out.close();
}
Как показано в листинге 3.15, метод completeCatalog использует теги HTML для создания таблицы с тремя столбцами. Каждый столбец заполняется информацией о товарах одной из серий, причем данные по каждому из товаров форматируются методом doOutput, приведенным в листинге 3.11.
Листинг 3.15. Метод completeCatalog для создания полного каталога товаров (CatalogTestServ.java)
public void completeCatalog( PrintWriter out ){
CatalogBean cb = new CatalogBean();
out.println("<h2>Complete Catalog</h2>");
out.println("<table width=\"90%\" border=\"3\" align=\"center\" >");
out.println("<thead><tr><th>Books</th><th>CDs</th>
<th>Gadgets</th>" + "</tr></thead>");
out.println("<tbody><tr valign=\"top\"><td>");
String link = alias + "?action=showproduct" ;
cb.setInitialSelect("Books");
int ct = cb.getSelectedCount();
out.println("We have " + ct + " titles." + brcrlf );
cb.setOutput("short", link);
for( int i = 0 ; i < ct ; i++ ){
out.println( cb.doOutput(i) );
out.println( brcrlf );out.println( brcrlf );
}
out.println("</td><td>");
cb.setInitialSelect("CDs");
ct = cb.getSelectedCount();
out.println("We have " + ct + " CD titles." + brcrlf );
cb.setOutput("short", link);
for( int i = 0 ; i < ct ; i++ ){
out.println( cb.doOutput(i) );
out.println( brcrlf );out.println( brcrlf );
}
out.println("</td><td>");
cb.setInitialSelect("widgets");
ct = cb.getSelectedCount();
out.println("We have " + ct + " kinds." + brcrlf );
cb.setOutput("short", link );
for( int i = 0 ; i < ct ; i++ ){
out.println( cb.doOutput(i) );
out.println( brcrlf );out.println( brcrlf );
}
out.println("</td></tr></table>");
}
В листинге З 16 приводится текст первой части получившейся HTML-страницы Обратите внимание, что многие строки разбиты на несколько частей, чтобы поместиться на страницу Несмотря на использование таблицы стилей, экономящей память, вся страница полностью занимает 17 213 байт
Листинг 3.16. Первая часть генерируемой сервлетом HTML-страницы
<html>
<head><title>CatalogTestServ Output</title>
<link rel="stylesheet" href= "http //localhost/XmlEcommBook/catalog.css" type="text/css" media="screen" >
</head>
<body>
<h2>Complete Catalog</h2>
<table width="90%" border="3" align='center" >
<thead><tr><th>Books</th><th>CDs</th>
<th>Gadgets</th></tr></thead>
<tbodyxtr valign="top"><td>
We have 28 titles <br />
<a class="ch3" href= "http //Iocalhost/servlet/cattest?action=showproduct">
Guide to Plants </a> <span class= "ch4">price ea = $12.99 </span>
<br />
<br />
<a class="ch3" href= "http //localhost/servlet/cattest?action=showproduct">
Guide to Plants, Volume 2 </a> <span class= "ch4">price ea = $12.99 </span>
<br />
<br />
<a class="ch3" href= "http //Iocalhost/servlet/cattest?action=showproduct" >
The Genius's Guide to the 3rd Millenium </a>
<span class= "ch4'>price ea = $59.95 </span>
<br />
Конечный результат наших усилий — отображенная в браузере HTML-страница с каталогом товаров (рис 32)
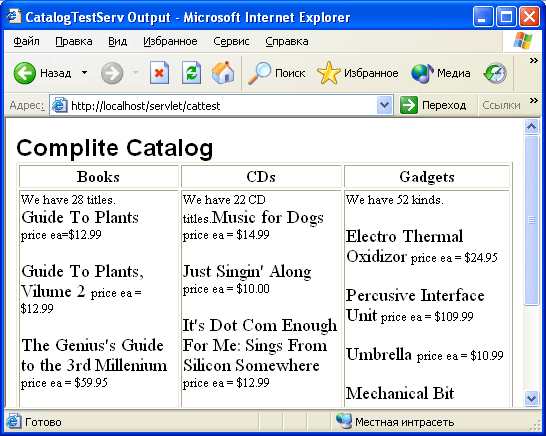
Рис. 3.2. Отображение каталога товаров
В следующей главе мы расскажем, как можно расширить функциональность классов CatalogBean и ProductFormatter для создания представлений, необходимых при работе с корзиной покупателя.
|
|
