Из первой лекции вы узнали, что представляет собой XML и как с помощью XML создаются языки разметки. Теперь вы располагаете инструментальными средствами для создания документов XML и определений типов документов (DTD). Но иметь инструменты — это далеко не то же самое, что уметь их использовать. Как вы знаете, изучение любого языка невозможно без опыта его практического применения.
Для того чтобы вы получили представление о том, как происходят создание документа XML и определение типа документа, какие вопросы при этом должен решить программист, в данной главе мы продемонстрируем вам весь процесс создания XML-каталога товаров для гипотетической компании, занимающейся электронной коммерцией. Рассматривается большая часть аспектов этого процесса, в том числе вопросы сбора данных, разработки DTD и фактического программирования каталога.
Наша гипотетическая компания Xtreme Mega-Large Gifts (XMLGifts) занимается продажей редких музыкальных записей, книг и других предметов. Рынок сбыта очень ограничен, так как магазин расположен в маленьком городе. Однако владельцы компании уверены, что их товары будут пользоваться спросом, если потенциальные покупатели получат информацию об этих товарах. Поэтому компания решила создать свой web-сайт XMLGifts.com.
Как и в любом проекте, первый и, возможно, наиболее существенный его этап — это сбор информации. Поэтому в следующих разделах мы расскажем о требованиях и ограничениях, которые следует учитывать при создании подобного web-сайта.
Бизнес-требования (business requirements), или требования верхнего уровня (high- level requirements), определяют глобальные цели, которые стоят перед компанией, проектирующей свой web-сайт. После того как решение о создании такого сайта принято, следует ясно и четко изложить эти требования в специальном документе, регламентирующем политику компании.
Пользовательские требования (user requirements) — это те задачи, которые должен решать пользовательский интерфейс сайта. Предположим, для сайта XMLGifts.com бизнес-требования и пользовательские требования сводятся к следующему:
посетители сайта должны иметь возможность искать товары по каталогу, добавлять их в корзину покупателя и покупать;
следует предусмотреть возможность расширения и модернизации каталога;
сайт должен быть исходно рассчитан на некоторое умеренное количество посещений, но следует предусмотреть возможность повышения производительности сайта (по мере роста его популярности), причем это не должно требовать его полной переделки;
сайт должен поддерживать партнерские программы, при выполнении которых на других сайтах можно располагать информацию о товарах компании XMLGifts и ссылки на сайт XMLGifts.com;
требуется создать сайт достаточно быстро, чтобы успеть к сезону предпраздничных покупок;
сайт должен обеспечивать возможность обратной связи с клиентами, которая позволит собирать маркетинговую информацию и отзывы покупателей о товарах;
наконец, создание сайта должно уложиться в определенные бюджетные рамки.
Определив эти требования и подробно обсудив их с различными сотрудниками компании, можно сделать новый список с более детальными функциональными требованиями, например:
расширения и дополнения сайта, вероятные в будущем, скорее всего, потребуют изменений в дизайне пользовательского интерфейса и модернизации источника данных. Чтобы сделать эти изменения возможно более безболезненными, бизнес-логика сайта должна как можно меньше зависеть от источника данных и от способа их представления;
клиент не должен быть привязан к какой-либо конкретной серверной платформе или базе данных, хотя на данном этапе в компании используются различные операционные системы и форматы данных. Как и у любой компании, у XMLGifts имеются долгосрочные планы по объединению различных источников данных и приложений вместе в некоторое комплексное приложение, которое должно работать без сбоев;
каталог, созданный для электронного магазина, должен допускать использование в качестве центральной базы данных для всей компании. Например, нужно обеспечить возможность генерации печатной версии каталога из того же источника данных, что и web-сайт;
сайт должен предоставлять другим сайтам несложный метод получения данных из каталога;
для записи данных о клиентах придется создать достаточно дорогостоящую базу данных. Приложение должно отслеживать определенные предпочтения клиентов, а затем на основе этих сведений и базы данных по товарам генерировать отчеты и ориентировать содержимое сайта на конкретного пользователя
Ограничения, которые приходится учитывать при создании web-сайта, возможно, оказывают более значительное влияние на конечный результат, чем приведенные выше требования. Мы имеем в виду ограниченность в финансовых возможностях и во времени. Эти факторы настолько часто оказываются решающими, что заслуживают отдельного обсуждения.
Фундаментальное правило коммерции «быстрее, лучше, дешевле» в данном случае не работает. Многим разработчикам и консультантам понимание этого факта дается нелегко. Если заказчик упорно настаивает на том, чтобы разработка его проекта удовлетворяла всем трем требованиям, — это часто означает, что проект заранее обречен на неудачу или же консультанту придется делать больше за меньшие деньги Чтобы максимально увеличить шансы на успех предприятия, следует предложить заказчику выбор из трех возможностей, о которых мы рассказываем в следующих трех разделах*
Покупка готового пакета — это быстрее и дешевле
Покупка готового пакета приложений для электронной коммерции, который затем настраивается соответственно конкретным требованиям, иногда может сэкономить время на разработку сайта Однако чаще получается, что вы оказываетесь привязанным к конкретным технологиям, и хотя приложение как-то заработает, вряд ли оно будет точно соответствовать нуждам вашего бизнеса и хорошо масштабироваться.
Если вы планируете разместить на своем сайте достаточно стандартный электронный магазин и вам нужно как можно скорее запустить его в работу, то, вероятно, вам подходит такой вариант В этом случае вам следует внимательно отнестись к своему выбору — вы должны убедиться, что выбранный вами пакет действительно будет работать так, как нужно
Такой метод можно назвать быстрее и дешевле, так как он удовлетворяет этим двум требованиям.
ВНИМАНИЕ
Если вы решите воспользоваться этим методом, но не будете достаточно внимательны, вы рискуете оказаться в ситуации, когда вам придется постоянно модифицировать и дополнять исходное приложение, чтобы приспособить его к своим нуждам. Тем самым ваш проект потребует больших затрат времени и денег, чем многие другие решения.
Сборка приложения из стандартных частей — это лучше и дешевле
Другой способ создания сайта заключается в том, чтобы начать с нуля и сконструировать его именно так, как вам нужно. Хотя этот способ требует больше времени, чем покупка и настройка готового приложения, зато функциональность такого сайта будет в точности отвечать требованиям заказчика
Поскольку все необходимое для создания сайта находится в свободном доступе, гораздо большую часть бюджета заказчика можно потратить на достижение именно той функциональности, которая требуется клиенту. Это лучше и дешевле.
Разработка сервера web-приложений — это быстрее и лучше
Чтобы ускорить создание сайта и сохранить все преимущества индивидуальной разработки, можно воспользоваться сервером web-приложений Такой сервер обычно содержит набор готовых объектов, которые служат для решения многих наиболее распространенных задач разработки web-приложения. В вашем приложении могут использоваться эти объекты, а также другие услуги, предоставляемые сервером. К таким услугам обычно относят балансировку нагрузки, кэширование данных, инструментарий для управления магазином, средства планирования и организации выполнения задач.
Все эти услуги и объекты, конечно, обойдутся недешево. И хотя весьма вероятно, что вы заплатите за какие-то функциональные возможности, которыми никогда не воспользуетесь, это быстрее и лучше.
Разработчики часто сталкиваются с такой дилеммой: заказчик не оступается от своих требований сделать сайт быстрее и дешевле, но в то же время ему необходима персональная настройка, которую невозможно обеспечить, взяв за основу готовое приложение. В таком случае искать компромисс между требованиями заказчика и реальными возможностями приходится разработчику
Один из принципов решения такой задачи выглядит следующим образом' не стремитесь сделать более мощное приложение, чем требуется на данный момент. Например, компания XMLGifts предполагает, что в первый год существования загруженность ее сайта посетителями будет невелика. Поэтому, вместо того чтобы заранее пытаться обеспечить функциональность, которая предположительно потребуется впоследствии, можно создать приложение, рассчитанное только на нынешние запросы При необходимости впоследствии это приложение можно будет легко масштабировать.
Одним из результатов этой стратегии может оказаться то, что запросы и ожидания заказчика придется несколько урезать, но зато будут удовлетворены основные требования: разработка сайта уложится в отпущенные сроки и не потребует дополнительных расходов. Если вы навсегда запомните, что невозможно достичь всех трех целей сразу (быстрее, лучше, дешевле), и сумеете находить компромисс в любой ситуации, ваши проекты будут иметь высокие шансы на успех Если вы правильно построите web-приложение, то его расширение и дополнение в будущем не доставят проблем.
Обдумав и взвесив все «за» и «против», компания XMLGifts приняла решение программировать бизнес-логику на Java и использовать XML для представления данных. Впрочем, об этом можно было догадаться, посмотрев на обложку нашего курса.
ПРИМЕЧАНИЕ
В реальной жизни, в отличие от этого курса, Java и XML не всегда являются лучшими решениями. Перед тем как выбрать технологии, которые вы будете использовать в своем приложении, тщательно проанализируйте приоритеты, требования и имеющиеся в вашем распоряжении ресурсы.
Некоторые причины такого выбора приведены ниже:
доступность инструментальных средств;
гибкость инструментальных средств;
совместимость инструментальных средств;
поддержка Unicode.
Приведенные здесь причины более подробно рассматриваются в следующих разделах.
Доступность инструментальных средств
И XML, и Java обязаны своей популярностью и количеством пользователей тому, что они были основаны на открытых и находящихся в свободном доступе стандартах. Можно сказать, что эти технологии естественным образом дополняют друг друга.
Существует большое количество недорогих и даже бесплатных инструментальных средств для разработки Java-приложений, которые работают с данными XML. К ним относятся анализаторы XML, редакторы XML, средства для проверки допустимости документов XML и их преобразования, а также промежуточное программное обеспечение.
До недавнего времени недостающим звеном между Java и XML был стандарт обмена данными между web-приложениями. Но появление протокола SOAP (Simple Object Access Protocol — простой протокол доступа к объектам) восполнило этот недостаток. Пользуясь поддержкой таких гигантов компьютерной индустрии, как Microsoft и IBM, SOAP дает разработчикам прекрасные возможности для создания приложений.
SOAP — это протокол, предназначенный для удаленного вызова процедур, основанный на стандартах XML и HTTP. В декабре 1999 года протокол SOAP был предложен компаниями DevelopMentor Inc., Microsoft и UserLand Software Inc. на рассмотрение Консорциуму W3C как Интернет-проект.
Методы SOAP вызываются с помощью HTTP-запросов POST. В заголовке HTTP SoapMethodName указывается имя метода, который требуется вызвать. В следующем примере в заголовке указаны пространство имен вызываемого метода (sybex- com) и имя метода (getPrice):
POST /xmlstore.jsp HTTP/1.1 Host: www.sybex.com SOAPMethodName: urn:sybex - com:SybexStore#getPrice Content-Type: text/xml Content-Length: nnnn
Содержательная часть сообщения SOAP пишется на XML:
<?xml version='1.0'?> <SOAP:Envelope xmlns:SOAP='urn:schemas-xmlsoap-org:soap.vl'> <SOAP:Body> <nsl:getPrice xmlns:nsl=' urn:sybex-com:SybexStore '> <ISBN>x-xxxx-xxxx-x</ISBN> </nsl:getPrice> </SOAP:Body> </SOAP:Envelope>
Этот запрос просто передает на сервер все данные, необходимые для вызова указанного метода. Обратите внимание, что пространство имен, указанное в первом элементе внутри SOAP:Body, должно совпадать с пространством имен в заголовке SoapMethodName.
Если дальше все идет нормально (запрошенный метод реально существует и удаленный сервер принимает запросы SOAP), то будут предприняты определенные действия, соответствующие запросу. Когда эти действия будут выполнены, полученный HTTP-ответ, содержащий данные XML, будет послан обратно клиенту.
Пока что SOAP не является официальной спецификацией Консорциума W3C, но если вы хотите начать использовать этот протокол прямо сейчас, у вас имеется такая возможность — IBM и DevelopMentor создали библиотеки Java, которые реализуют технологию SOAP. Вы можете воспользоваться сайтом организации Apache (http://xml.apache.org/soap/index.htm), откуда можно загрузить все IBM-версии SOAP, a Perl- и Java-версии компании DevelopMentor можно загрузить по адресу www.develop.com/SOAP.
Гибкость инструментальных средств
Хотя данные для нашего электронного магазина хранятся в виде документов XML, для повышения производительности сайта они могли бы храниться в двоичных реляционных или объектных базах данных, а при поступлении запросов от приложений нужные данные просто преобразовывались бы в XML.
Для выполнения этой задачи существуют различные промежуточные приложения. Наиболее совершенные серверы XML обеспечивают такие возможности, как кэширование, репликация и балансировка нагрузки. Серверы XML обычно представляют собой приложения, написанные на Java и способные воспринять любые данные, для которых у вас имеется драйвер JDBC (Java Database Connectivity — средство доступа Java-приложений к базам данных).
И XML, и Java являются переносимыми стандартами (portable standards). Это означает, что они не зависят от платформы, на которой будет работать приложение. Если приложение написано на Java, то для его работы годится любая виртуальная машина Java. Приложение, которое использует данные XML, может легко взаимодействовать с любым типом источников данных. Если вам потребуется изменить источник данных приложения XML, вносить изменения в само приложение не потребуется.
Совместимость инструментальных средств
Если при разработке сайта вы использовали Java и XML, вам будет легко создавать взаимосвязи с другими web-сайтами и электронными магазинами. При организации любого взаимодействия или передачи данных между web-сайтами приходится решать некоторую проблему, связанную с тем, что вы, с одной стороны, не хотите предоставлять кому бы то ни было доступ к вашей базе данных, а с другой стороны, должны передать другой стороне данные в доступной для понимания форме.
Многие так называемые партнерские программы в настоящее время требуют, чтобы приложение-потребитель (партнерский сайт) получило от поставщика код HTML. Недостатком такого подхода является то, что формат полученной информации предопределен. С другой стороны, с помощью XML потребитель может форматировать данные так, как ему нужно. Дополнительным преимуществом XML при обмене информацией между сайтами является то, что документ XML, в отличие от HTML, может использоваться потребителем не только для отображения информации.
Допустим, что компания XMLGifts решила, помимо всего прочего, распечатать свой каталог на нескольких языках. Встроенная в Java и XML поддержка символов Unicode упрощает эту задачу.
Поскольку web-разработчики все больше и больше стремятся к тому, чтобы пользовательский интерфейс и содержимое web-страниц не были ограничены в языковом отношении, поддержка Unicode становится все более важной характеристикой любой Интернет-технологии. Поддержка Unicode была добавлена и в другие популярные языки web-программирования, такие как Perl и Tel. Однако в отличие от них язык Java был исходно рассчитан на поддержку Unicode, поэтому обработка символов различных алфавитов нисколько не усложняет структуру приложения, как это может произойти на других платформах.
Когда все требования к web-сайту сформулированы и принято решение использовать XML, следующим шагом в создании XML-каталога товаров является изучение имеющихся данных и преобразование их в подходящий формат.
В начале работы над проектом каталог данных сайта XMLGifts.com хранился в виде электронной таблицы. Часть этой таблицы показана в табл. 2.1.
Наш опыт показывает, что такой способ хранения данных характерен для многих физических (в отличие от виртуальных) магазинов, которые только начинают разрабатывать web-сайты. Реальная таблица может иметь гораздо больше столбцов, чем показано в нашем примере, но общий принцип заключается в том, что для каждого товара в таблице отводится отдельная строка, а для каждой возможной характеристики товара имеется отдельный столбец. Подобный тип организации каталога (все данные в одной таблице) обычно является результатом того, что количество видов товаров, с которыми имеет дело данная фирма, растет быстрее, чем техническая квалификация сотрудников. Излишне говорить, что эта ситуация требует кардинального пересмотра. Следующим этапом является выбор оптимального способа организации данных.
Таблица 2.1. Образец каталога XMLGifts.com
|
Шифр |
Название товара |
Описание |
Категория |
Цена |
Количество на складе |
Автор |
|
bk0022 |
Справочник по растениям |
Все, что вы когда-либо хотели узнать о растениях |
Книги |
$12.99 |
4 |
Вильям Смит |
|
cd0024 |
Просто подпевай |
Прекрасная коллекция песен, которые можно петь всей семьей |
Компакт- диски |
$10.00 |
100 |
|
|
WZ0027 |
Ударный интерфейс |
Этот интерфейс позволяет вам общаться со своей любимой вычислительной машиной, ударяя по ее корпусу |
Приборы и устройства |
$109.99 |
7 |
|
Таблицы представляют собой, вероятно, наиболее распространенный способ организации данных. Хранение данных в строках и столбцах обеспечивает гибкость при создании представлений данных и определения взаимосвязей между ними. Тем не менее использование единственной таблицы — это очень неэффективный способ организации данных.
Если бы в нашем примере для создания каталога электронного магазина использовалась реляционная база данных, первым шагом по улучшению организации было бы создание отдельной таблицы для каждого вида товаров. Это помогло бы избежать очевидных потерь, связанных с тем, что в единой таблице приходится отводить целый столбец, в котором, возможно, будет заполнена только одна ячейка (например, если в столбце указывается автор книги, для всех остальных видов товаров, помимо книг, этот столбец будет пустым). Далее, если для какой-то книги указывается не автор, а редактор, то ради одной такой книги придется добавлять целый столбец. Если у какой-либо другой книги два (или более) автора, то снова придется либо создавать очередной столбец, либо создать отдельную таблицу для авторов.
На рис. 2.1 показан один из способов организации взаимоотношений между таблицами.
Рис. 2.1. Схема отношений между таблицами
На рис. 2.2 показан более подробно фрагмент приведенной выше схемы, в которую добавлены некоторые поля из таблицы Авторы.
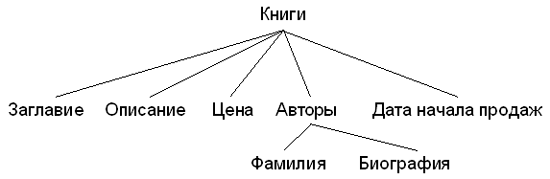
Рис. 2.2. Отношения между таблицами и полями
На рис 2.3 мы добавили некоторые фактические значения и организовали данные в виде древовидной схемы.
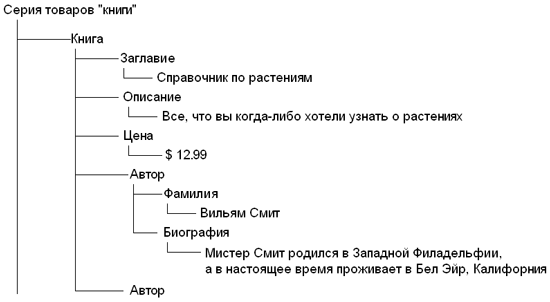
Рис. 2.3. Отношения между таблицами, полями и данными
Что напоминают три приведенные схемы? Эти схемы фактически показывают фрагмент реляционной базы данных в виде иерархической структуры. Иерархические структуры данных (hierarchical data structures), подобные тем, что создаются с помощью XML, очень удобны для организации данных, поскольку в них имеется единая «точка отсчета». Например, в схеме, приведенной на рис. 2.3, такой точкой отсчета для всей структуры является Серия товаров «книги». В документе XML такая точка отсчета, относительно которой строится вся организация данных, называется корневым элементом (root element). Напомним, что в любом документе XML должен присутствовать корневой элемент.
В то время как в реляционных базах данных для организации отношений используются ключевые слова, в языках разметки отношения элементов указываются путем вложения. Например, автор книги может быть указан путем вложения элемента Author внутрь элемента Book.
Отношения и семантику, которые было бы очень сложно показать с помощью реляционной базы данных, можно легко, интуитивно понятным способом показать, используя разметку. Ниже мы приводим фрагмент правильно оформленного документа XML, который содержит ту же информацию, что и приведенная на рис. 2.3:
<Products> <Book> <Тitle>Справочник по растениям</Title> <Descnption> Bce, что вы когда-либо хотели узнать о растениях </Descnption> <Рrice>$12 99</price> <Author> <Name>Вильям Смит</Name> <Biography> Мистер Смит родился в Западной Филадельфии, а в настоящее время проживает в Бел Эйр, Калифорния. </Biography> </Author> </Book> </Products>
Как показано в предыдущем примере, реляционную базу данных часто удается преобразовать в XML. Для этого нужно объявить корневой элемент с тем же именем, что и у базы данных, затем создать элементы с именами, совпадающими с названиями строк в таблице, и отобразить столбцы таблицы в их дочерние элементы.
Преобразование реляционной базы данных в документ XML не обязательно делать вручную. Для этой цели существует множество инструментальных средств, так же как и для решения обратной задачи (преобразование документа XML в таблицу).
Также этот процесс можно автоматизировать с помощью запросов SQL. Основной метод преобразования табличных данных в иерархическую структуру заключается в использовании внешнего соединения SQL. Внешнее соединение (outer join) объединяет две таблицы в одну, причем полностью сохраняются данные лишь одной из них. Структура получившейся в результате таблицы повторяет структуру одной из исходных. Предположим, например, что у нас имеются две таблицы, Books и Authors. Для создания иерархической структуры этих реляционных данных можно использовать что-либо подобное следующей инструкции SQL:
SELECT * FROM Books LEFT JOIN Authors ON [Authors] [Book_ID]=[Books].[ID];
Эта инструкция SQL объединяет таблицы Books и Authors, сохраняя все строки из таблицы Books, даже если в таблице Authors нет соответствующей записи. Поскольку в таком случае главной таблицей является Books, то те строки таблицы Authors, которые не ассоциированы с какой-либо записью из таблицы Books, выбраны не будут. В получившейся таблице данные будут показаны с точки зрения Books (табл. 2.2).
Таблица 2.2. Представление Books
|
Название книги |
Имя автора |
|
По ком звонит колокол Электронный магазин на Java и XML Преступление и наказание |
Эрнест Хемингуэй Вильям Брогден, Крис Минник Федор Достоевский |
Чтобы преобразовать эту таблицу в данные XML, каждый столбец нужно сделать дочерним элементом по отношению к элементу Book, как показано в листинге 2.1 [Book — книга, title — название, author — автор. — Примеч. перев. ].
Листинг 2.1. Документ XML, получившийся в результате преобразования реляционной базы данных (BookView.xml) [Все представленные в курсе тексты программ можно найти на сайте .издательства по адресу www.piter.com, — Примеч. ред. ]
<BookView> <Book> <Title>По ком звонит колокол</Title> <Author> <Name>Эрнест Хемингуэй</Nаmе> </Author> </Book> <Book> <Title>Электронный магазин на Java и XML</Title> <Author> <Name>Вильям Брогден</Name> </Author> <Author> <Name>Крис Mинник</Name> </Author> </Book> <Book> <Title>Преступление и наказание</Title> <Author> <Name>Федор Достоевский</Name> </Author> </Book> </BookView>
Независимо от того как вы преобразуете данные в XML, в процессе написания определения типа документа вы непременно получите представление о потенциальных проблемах, связанных с организацией данных. В DTD должно быть указано, каким образом элементы каталога связаны друг с другом, также DTD должно обеспечивать возможность последующего добавления в каталог новых данных, не нарушая требований допустимости документа XML.
Один из способов создания DTD — начать с правильно оформленного документа XML и выводить DTD из него. Для этого нужно просто последовательно «пройтись» по документу и создать объявления для каждого элемента разметки, который вы встретите. Этот процесс в той или иной степени может быть автоматизирован. Для начала этот метод неплох, но полученное таким образом описание DTD не может быть столь же логичным и столь же полезным, как DTD, созданное с нуля и основанное на подробном исследовании.
Другой способ разработки DTD заключается в том, чтобы писать DTD до того, как написан сам документ XML. Это более формальный метод, который требует тщательного планирования. Если вы начинаете с нуля, не имея каких- -либо данных, которые вам нужно преобразовывать, можно использовать этот метод.
Чаще, однако, при создании DTD используется комбинация этих двух методов. Если, к примеру, нам требуется создать DTD для служебных записок, можно начать с типичной записки и разметить ее как документ XML [Memo — служебная записка, from — от кого, to — кому. — Примеч. перев. ]:
<memo> <from>Крис Минник</from> <to>Сотрудникам</to> <body>Сегодня выходной. Поезжайте на озеро отдыхать</body> </memo>
Для этого простого документа DTD может выглядеть следующим образом:
<!ELEMENT memo (from,to,body)> <!ELEMENT from (#PCDATA)> <!ELEMENT to (#PCDATA)> <!ELEMENT body (#PCDATA)>
После внимательного изучения этого определения DTD его недостатки становятся очевидными, и мы начинаем понимать, что требуется внести ряд исправлений. Первый недостаток заключается в том, что у нас нет способа однозначно идентифицировать записку. Во-вторых, следовало бы более подробно указать, что может содержаться в элементах from и to. В-третьих, возможны ситуации, когда записки посылаются не от одного, а от нескольких лиц или нескольким лицам. Обдумав, какие виды записок реально могут пересылаться между служащими фирмы, мы переделали DTD (листинг 2.2 [Name — название, department — отдел, important part — наиболее существенная часть. — Примеч. перев. ]).
Листинг 2.2. Исправленное определение DTD для записок (memo.dtd)
<!ELEMENT memo (from, to, cc?, body)> <!ATTLIST memo id ID «REQUIRED date CDATA «REQUIRED subject CDATA #IMPLIED> <!ELEMENT from (name.department)*> <!ELEMENT to (name,department)*> <!ELEMENT cc (name,department)*> <!ELEMENT name (#PCDATA)> <!ELEMENT department (#PCDATA)> <!ELEMENT body (#PCDATA,important_part?)> <!ELEMENT important_part (#PCDATA)>
Используя это определение DTD, любой сотрудник фирмы XMLGifts может точно ответить на вопрос, что такое служебная записка В листинге 2 3 показана правильно оформленная и допустимая служебная записка
Листинг 2.3. Правильно оформленная и допустимая служебная записка (memoexamplel.xml)
<?xml version="l.0" standalone="no"?> <!DOCTYPE memo SYSTEM "memo.dtd"> <memo id = "cm0001" date = "8/2/2000" subject = "ваша задача на сегодня"> <from> <name>Крис Минник</name> </from> <to> <department>Bceм coтpyдникaм</department> </to> <body> Поздравляю с окончанием проекта XMLGnfts.com
Предлагаю <important_part>сделать выходной и поехать на озеpo</important_part> </body> </memo>
Этот метод — изучение реального образца данных и последующее исправление DTD с учетом возможных потребностей в будущем — мы и будем использовать при создании каталога товаров для сайта XMLGifts.com
В листинге 2 4 приводится первый черновой вариант документа XML, описывающего несколько товаров из будущего каталога для сайта XMLGifts.com Этот документ написан без DTD Он является правильно оформленным документом XML, но, поскольку никакому определению DTD он не соответствует, его нельзя назвать допустимым и самодокументируемым [Caption — подпись (к рисунку) productlme — серия товаров — Примеч перев ].
Листинг 2.4. Первая черновая попытка описания товаров
<?xml version="1.0"?> <catalog> <product_line name="Books"> <product id="bk0022"> <name>Guide to Plants</name> <description>Everything you've ever wanted to know about plants. </descnption> <price>$12 99</price> <quantity_in_stock>4</quantity_in_stock> <image width="234" height="400" src="images/covers/plants.gif "> <caption> This is the cover from the first edition </caption> </image> <onsale_date>12/23/1999</onsale_date> </product> <product id="bk0035"> <name>Writing Fake Catalogs</name> <description>Chns Hinnick's latest book explains, in agonizing detail, the process of thinking up fake products for a demonstration catalog </description> <pnce>$59.95</pnce> <quantity_in_stock>30</quantity_in_stock> <onsale_date>09/01/2000</onsale_date> </product> </product_line> <product__line name="CDs'> <product id="cd0024"> <name>Just Singin' Along</name> <description>A lovely collection of songs that the whole family can sing right along with </description> <price>$10 00</price> <quantity_in_stock>100</quantity_in_stock> <onsale_date>2/23/2000</onsale_date> </product> <product id="cd0025"> <name>It's Dot Com Enough for Me Songs from Silicon
Somewhere</name> <description>A collection of the best folk music from
Internet companies. </descnption> <clip format="mp3" length="4.32" size="4.0 Mb" src="track2.mp3"> <title>Track 2: My B2B Is B-R-0-K-E</title> </clip> <onsale_date>4/12/2000</onsale_date> </product> </product_line> <product_line name="widgets"> <product id="wi0026"> <name>ElectroThermal Oxidizor</name> <description>This amazing gizmo uses electricity to
produce heat that can be used for oxidization
purposes.</description> <price>$24.95</price> <quantity_in_stoek>10</quantity_in_stock> <image width="200" height="200" src="/images/toaster.gif"> </image> <onsale_date>6/2/2000</onsale_date> </product> <product id="wz0027"> <name>Percusive Interface Unit</name> <description>Communicate with your favorite electric
calculating machine through tapping!</description> <price>$109.99</price> <quantity_in_stock>7</quantity_in_stock> <onsale_date>6/23/200K/onsale_date> </product> </product_line> </catalog>
Создание первого чернового варианта DID
Для создания первого чернового варианта DTD, чтобы определить класс данных, которому принадлежит приведенный выше документ XML, мы использовали редактор XML CLIP!, созданный компанией Techno2000USA, Inc. Этот редактор имеет очень удобное свойство — он позволяет создавать DTD на основе правильно оформленного документа XML. В листинге 2.5 приведено полученное таким образом определение DTD. Для автоматизации процедуры создания первого чернового варианта DTD пригодны многие редакторы XML. Например, редактор XML Spy (доступный по адресу www.xmlspy.com) может сгенерировать DTD (а также некоторые другие типы схем XML) на основе любого правильно оформленного документа XML.
Листинг 2.5. Первый черновой вариант DID
<!ELEMENT catalog (product_line)* > <!ELEMENT product_line (product)* > <!ATTLIST product_line name CDATA #IMPLIED> <!ELEMENT product(name]description|price| quanti ty_in_stock|image|onsale_date|clip)* > <!ATTLIST product id CDATA #IMPLIED> <!ELEMENT name (#PCDATA)* > <!ELEMENT description (#PCDATA)* > <!ELEMENT price (#PCDATA)* > <!ELEMENT quantity_in_stock (#PCDATA)* > <!ELEMENT image (caption)* > <!ATTLIST image width CDATA #IMPLIEO> <!ATTLIST image height CDATA #IMPLIED> <!ATTLIST image src CDATA #IMPLIED> <!ELEMENT caption (#PCDATA)* > <!ELEMENT onsale_date (#PCDATA)* > <!ELEMENT clip (title)* > <!ATTLIST clip format CDATA #IMPLIED> <!ATTLIST clip length CDATA #IMPLIED> <!ATTLIST clip size CDATA #IMPLIED> <!ATTLIST clip src CDATA #IHPLIED> <!ELEMENT title (#PCDATA)* >
Приведенное выше определение DTD правильно описывает документ XML, но все же является весьма расплывчатым. Чтобы определение DTD точнее определяло реальный каталог товаров, его нужно несколько доработать. Следующие несколько разделов будут посвящены последовательному анализу DTD и внесению необходимых исправлений.
Элементы catalog, productline и product
В первой строке содержится объявление корневого элемента catalog:
<!ELEMENT catalog (product_line)*>
Это объявление достаточно очевидное: в нем указывается, что catalog может состоять из любого количества элементов productJ i ne.
Элемент product_line тоже очень просто устроен, но в отличие от элемента catal og у него имеется атрибут name:
<!ELEMENT product_line (product)* > <!ATTLIST product_line name CDATA #IMPLIED>
В объявлении атрибута name элемента productjine указано, что этот атрибут не является обязательным (#IMPLIED). Но информация о принадлежности товара (элемент product) к некоторой серии товаров (элементу productjine) не имеет смысла, если мы не знаем названия этой серии. Поэтому соответствующий атрибут, name, мы сделаем обязательным. Внести это изменение несложно:
<!ATTLIST productjline name CDATA #REQUIRED>
Следующее объявление — наиболее содержательная часть этого определения DTD [Photo — фотография, clip — клип. — Примеч. перев. ]:
<!ELEMENT product(name|description|price|
quantity_in_stock|photo| onsale_date|clip)* >
В таком виде это объявление подразумевает, что элемент product может содержать любое (в том числе нулевое) количество любых перечисленных здесь элементов. Это не соответствует фактической организации каталога на сайте XMLGifts.com. Также здесь не учитываются сведения об авторах книг (для элементов Books) и исполнителях (для элементов CDs). Такие промашки часто случаются, если используется недостаточно большой фрагмент исходных данных, для которых вы составляете DTD. Полностью исправленное объявление элемента product выглядит следующим образом:
<!ELEMENT product name,author* , artist*, description,price,quantity_in_stock,image*, onsale_date?,clip*>
ПРИМЕЧАНИЕ
Обратите внимание, что в исправленной версии объявления элемента product указано, что элементы name, description, quantity_m_stock могут встречаться в одном элементе product только один раз. Заметим также, что они обязательно должны присутствовать в этом элементе. Далее обратите внимание, что элемент photo (фотография) был переименован в image (изображение) для большей общности.
Хотя получившееся определение DTD не идеально и, возможно, не учитывает все особенности каждого товара, все же это неплохое «первое приближение». Поскольку оно было сконструировано для конкретного типа документа, а не как DTD общего назначения, мы можем позволить себе пересматривать DTD по мере изменения каталога. Всегда предпочтительнее (и проще) начинать с более обобщенного определения DTD и добавлять к нему новые элементы по мере надобности. Этот метод называется аддитивным уточнением (additive refinement). Противоположный метод уточнения DTD, который сводится к удалению лишних объявлений элементов, называется субтрактивным уточнением (subtractive refinement).
После определения элемента product в DTD определяется атрибут id этого элемента:
<!ATTLIST product id CDATA #IMPLIED>
Как и с атрибутом name элемента product_line, в каталоге у каждого товара должен быть однозначный идентификатор, поэтому следует сделать этот атрибут обязательным. Кроме того, чтобы гарантировать уникальность значения каждого атрибута id, то есть идентификатора каждого товара, тип атрибута должен быть ID. Исправленное объявление атрибута id выглядит следующим образом:
<!ATTLIST product id ID #REQUIRED>
Кроме определения товара по его уникальному идентификатору также мы хотели бы иметь возможность отыскать этот товар по ключевым словам. Для этого мы добавим в элемент product еще один атрибут, keywords [Keyword — ключевое слово (характеризующее товар) — Примеч перев.]:
<!ATTLIST product keywords CDATA #IMPLIED>
В нашем представлении значение атрибута keywords — это список с разделенными запятыми элементами, который можно использовать для поиска и группировки.
Элементы description, paragraph и general
Следующая часть DTD определяет элементы, дочерние по отношению к product. Дочерний элемент name в настоящий момент может содержать любую разновидность проверенных символьных данных, что вполне соответствует нашим требованиям. Элемент description, определенный таким же образом, содержит информацию, исходно предназначенную для прочтения людьми, но также в нем могут содержаться некоторые данные, которые мы хотели бы сделать доступными для программ, то есть которые можно было бы извлекать автоматически.
Чтобы сделать содержимое элемента description удобным для восприятия и для применения к нему в дальнейшем различных стилей, нужно предусмотреть возможность разделения элемента description на части, которые будут содержать элементы для отображения текста жирным шрифтом, курсивом и т. д. Для этого в первую очередь нужно, чтобы элемент description мог содержать элементы paragraph, и определить paragraph, как это сделано ниже [Paragraph — абзац (имеется в виду просто некая часть текста), bold — полужирный (шрифт), italics — курсив, quote — цитата, link — ссылка — Примеч перев ]:
<!ELEMENT description (paragraph*)> <!ELEMENT paragraph (#PCDATA | bold |
italics|quote|link)*> <!ELEMENT bold #PCDATA> <!ELEMENT italics #PCDATA> <! ELEMENT quote #PCDATA> <!ATTLIST quote attrib CDATA #IMPLIED> <!ELEMENT link (#PCDATA)> <!ATTLIST link href CDATA «REQUIRED alt CDATA #IMPLIED>
Существует большая вероятность того, что такой же список элементов разметки, который используется в элементе paragraph, потребуется в каком-то другом месте DTD (например, в элементе title или footnote, то есть в заголовке или в сноске). Чтобы упростить процесс создания DTD, мы ввели параметрическую сущность, представляющую собой список элементов разметки текста:
<!ENTITY %runmng_text "(#PCDATA | bold |
italics | quote | link)* ">
СОВЕТ
Напомним, что сущность — просто подстановочный текст, который пишется вместо заменяемого им значения, и что общие и параметрические сущности должны быть объявлены прежде, чем будут использованы. Поскольку параметрические сущности могут существовать только в DTD, то обычно их объявления сгруппированы в начале DTD. В нашем случае это тем более удобно, что при необходимости добавления какого-либо элемента разметки в элемент paragraph эту сущность будет легко найти.
Когда объявление параметрической сущности добавлено в начало DTD, объявление элемента paragraph можно переписать следующим образом:
<!ELEMENET paragraph %running_text;>
Если параметрическая сущность применяется правильно, это повышает удобочитаемость определения DTD и способствует его многократному использованию. Но будьте осторожны — так же, как следует избегать излишнего усложнения элементов, вам нужно сопротивляться искушению всюду вводить параметрические сущности. Если их окажется слишком много или они будут неправильно использоваться, пострадает удобочитаемость DTD.
Вторая цель переработки элемента description — обеспечить возможность автоматического извлечения из этих описаний содержательной информации. Для этого мы должны иметь возможность использовать другие элементы внутри элемента description. Предположим, что в нашем каталоге имеется следующий элемент description:
<description> <paragraph>Эта яркая новая группа из Бельгии,
звучание которой можно определить как смесь
Iggy Pop и Spice Girls,стремительно завоевывает популярность во всем мире.</paragraph> </description>
Было бы замечательно, если бы наша схема позволила приложению использовать различные фрагменты этого описания для ссылок на близкие по назначению товары. Проблема же заключается в том, что в описание могут быть включены тысячи различных типов данных. Мы могли бы попытаться создать подробный список возможных фрагментов данных, которые могут встретиться в описании. Но это привело бы к созданию огромного по размерам объявления элемента, в котором было бы невозможно разобраться.
Хорошим способом обойти эту проблему является использование элемента general с атрибутом type. Идентифицирующую информацию можно сделать значением этого атрибута, что дает максимальную гибкость автору документа и тому, кто конструирует разметку элемента description, как видно из приведенного ниже листинга:
<!ELEMENT general #PCDATA> <!ATTLIST general type CDATA #REQUIRED>
Используя элементы general и paragraph, мы можем теперь разметить описание (то есть элемент description) в нашем примере таким образом, чтобы информацию из него могли извлечь и человек, и программа:
<description> <paragraph>Эта яркая новая группа из <general type="country">Бельгии</general>,
звучание которой можно определить как смесь <general type="artist">Iggy Pop</general>и <general type = "artist">Spice Girl</general>
стремительно завоевывает популярность во всем
мире.</paragraph> </description>
Теперь приложение легко справится с задачей преобразования элементов general в пары имя-значение.
В результате объявление элемента description и его дочерних элементов будет выглядеть следующим образом:
<!ELEMENT description (paragraph|general)* > <!ELEMENT paragraph %running_text;> <!ELEMENT bold #PCDATA> <!ELEMENT italics #PCDATA> <!ELEMENT quote #PCDATA> <!ATTLIST quote attrib CDATA #IMPLIED> <!ELEMENT link (#PCDATA)> <!ATTLIST link href CDATA #REQUIRED alt CDATA #IMPLIED> <!ELEMENT general #PCDATA> <!ATTLIST general type CDATA #REQUIRED>
Элементы price, quantity_in_stock и image
Следующий элемент, объявленный в DTD, — элемент price. Было бы замечательно, если бы сведения о ценах действительно имели такой простой формат, как указано в DTD:
<!ELEMENT price(#PCDATA)*>
Но реально ситуация с ценами сложнее и цена товара не выражается какой- то одной фиксированной суммой. В реальном мире для различных товаров могут быть предусмотрены различные скидки, а иногда на какие-то товары или группы товаров объявляется распродажа. Чтобы учесть скидки, в элемент price следует добавить атрибут с именем di scount:
<!ELEMENT price #PCDATA> <!ATTLIST price discount CDATA #IMPLIED>
База данных каталога не занимается определением того, как именно тот или иной клиент получает скидку (как член определенной привилегированной группы клиентов или по распродаже). Эти факторы контролируются приложением и базой данных о клиентах. База данных о клиентах содержит информацию как раз о том, какие клиенты или группы клиентов имеют право на скидки.
Все, что должно содержаться в элементе price, — это сведения о стоимости данного товара. Поскольку в стандартном определении DTD отсутствует возможность указать тип данных элемента, то за соответствие реальным ценам тех данных, которые содержатся в элементе price, отвечает приложение.
Следующий элемент DTD, quantity_in_stock, не требует больших изменений:
<!ELEMENT quantity_in_stock (#PCDATA>*>
Если убрать излишний символ оператора повторяемости (*), то элемент получится как раз таким, как надо:
<!ELEMENT quantity_in_stock (#PCDATA)>
Элемент image на самом деле не будет содержать изображений. В документы XML, которые, в сущности, являются простыми текстовыми файлами, не так-то легко вставить двоичные данные Вместо этого предлагается гораздо более простое (и компактное) решение — в элементе image и его дочерних элементах располагать только адреса, по которым можно отыскать файлы с изображениями товаров, и другую информацию об изображениях, например.
<!ELEMENT image (caption)> width CDATA #IMPLIED> <!ATTLIST image height CDATA #IMPLIED> <!ATTLIST image src CDATA #IMPLIED> <!ELEMENT caption (#PCDATA)*>
Некоторые товары из каталога XMLGifts.com не сопровождаются изображениями В тех случаях, когда изображение товара отсутствует, во многих электронных магазинах появляется определенная картинка, которая извещает посетителей магазина о невозможности предоставить изображение товара Эту замену можно было бы описать в DTD, введя некоторое значение атрибута scr, используемое по умолчанию (то есть когда не указано никакого другого значения) Но, рассмотрев эту возможность, компания XMLGifts решила просто внести соответствующие дополнения в само приложение, а не в DTD Причиной этого является то, что указанная картинка, используемая по умолчанию, на самом деле не содержит никаких сведений о товаре. Она требуется только для того, чтобы при отсутствии изображения товара не пришлось изменять единый для всех товаров дизайн страницы. Поскольку эта картинка связана скорее с представлением данных, чем с описанием товаров, ее не следует включать в DTD.
Хотя наличие изображений не является обязательным требованием для всех товаров, если элемент image все же присутствует, у него обязательно должен быть атрибут scr (источник) и необязательно — caption (подпись).
<!ELEMENT image (caption?)> <!ATTLIST image width CDATA #IMPLIED> <!ATTLIST image height CDATA #IMPLIED> <!ATTLIST image src CDATA #REQUIRED> <!ELEMENT caption (#PCDATA)>
Существует еще одна деталь, которую необходимо уточнить при описании элемента image. Это способ указания формата изображения Чтобы гарантировать, что форматы изображения товаров окажутся приемлемыми для большинства web-браузеров, мы ограничим количество возможных форматов тремя — GIF, PNG и JPG Ограничения на формат можно записать с помощью следующего нового атрибута
<!ATTLIST image format (gif|png|jpg) #REQUIRED>
Теперь у элемента image имеется один дочерний элемент (caption) и четыре атрибута, из которых два (scr и format) являются обязательными.
Заголовок изображения может содержать только символьные данные Здесь появляется прекрасная возможность — снова использовать элемент paragraph, который мы создали для элемента description
<!ELEMENT caption (paragraph*)>
Хотя элемент image и его дочерние элементы фактически не содержат изображений, они предоставляют всю информацию, которая необходима для использования изображений товаров.
<!ELEMENT image (caption?)> <!ATTLIST image format (gif|png|jpg) #REQUIRED width CDATA #IMPLIED height CDATA #IMPLIED src CDATA #REQUIRED> <!ELEMENT caption (paragraph*) >
Элементы onsale_date, time, clip и title
Следующий объявленный в DTD элемент — onsa!e_date. Исходным назначением этого элемента было обеспечение возможности внесения товаров в каталог заранее, еще до фактического начала их продажи В будущем возможно и другое применение этого элемента. Например, мы можем предоставить пользователю возможность просматривать новые товары или учитывать значение этого элемента (дату начала продаж) при составлении отчетов для внутреннего использования
Как отмечалось в главе 1, не существует способа указать в DTD, что значением некоего элемента должна быть дата Тем не менее можно создать несколько дочерних элементов onsale_date, чтобы более точно указать, данные какого типа ожидаются, а также чтобы формат этих данных был достаточно гибким и мог включать, например, день недели, число месяца или даже часы, минуты и секунды [Day of week — день недели, month — месяц, day of month — день месяца year — год, hour — час, minute — минута, seconds — секунды — Примеч перев]
<!ELEMENT onsale_date (day_of_week?.month?,day_of_month?,year?,
(hour,minute, seconds?)?)> <!ELEMENT day_of_week (#PCDATA)> <!ELEMENT month (#PCDATA)> <!ELEMENT day_of_month (#PCDATA)> <!ELEMENT year (#PCDATA)> <!ELEMENT hour (#PCDATA)> <!ELEMENT minute (#PCDATA)> <!ELEMENT seconds (#PCDATA)>
Здесь уже структура элемента становится несколько сложнее. Фактически в приведенном объявлении говорится, что каждый из дочерних элементов onsale_date может присутствовать один раз или отсутствовать Элемент time не является обязательным, но, если он присутствует, то и часы, и минуты (элементы hour и minute) должны быть указаны. Здесь мы можем несколько усовершенствовать DTD, введя параметрическую сущность date_time [Date — дата, time — время — Примеч перев ], которую можно будет повторно использовать в других элементах для указания даты и времени:
<!ENTITY % date_time"(day_of_week?,month?,
day_of_month?,year?,(hour.minute, seconds?)?)"> <!ELEMENT onsale_date %date_time;>
Чтобы включить в наше приложение отрывки из музыкальных записей, дающие покупателю представление о том или ином компакт-диске, в документе XML и в соответствующем определении DTD используется элемент clip (то есть музыкальный клип). Этот элемент функционирует так же, как элемент image, — он содержит ссылку на файлы мультимедиа, которые хранятся отдельно в базе данных XlL [Size — размер, format — формат — Примеч перев ]:
<!ELEMENT clip (title)* > <!ATTLIST clip format CDATA #IMPLIED> <!ATTLIST clip length CDATA #IMPLIED> <!ATTLIST clip size CDATA #IMPLIED> <!ATTLIST clip src CDATA #IMPLIED> <!ELEMENT title (#PCDATA)* >
Возможно, вы обратили внимание на то, что название (title) определено как дочерний элемент, в то время как format, length, size и src определены как атрибуты. Хотя и title можно было бы определить как атрибут, но основная причина, по которой мы не сделали этого, заключается в том, что атрибуты format, length, size и src в первую очередь предназначены для приложения, в то время как title — для людей. Также учитывались соображения логической согласованности: в элементе image подпись (caption) также была определена как дочерний элемент.
Как и в предыдущих объявлениях элементов этого определения DTD, можно внести несколько изменений в элемент clip и его атрибуты и дочерние элементы, чтобы добиться более точного соответствия с реальным документом XML. В первую очередь следует изменить правило для самого элемента clip. Хотя вполне возможно, что для одного товара может быть несколько клипов (элементов clip), но трудно представить ситуацию, в которой для одного клипа потребуется несколько названий (то есть несколько элементов title для одного элемента clip). Мы можем переписать объявление для clip заново, чтобы учесть это соображение:
<!ELEMENT clip (title)>
Также может возникнуть ситуация, когда для какого-то клипа потребуются пояснения. Для этого в элемент clip можно включить элемент description, содержащий описание данного клипа:
<!ELEMENT clip (title, description?)>
Как и в случае с атрибутом format элемента image, значение атрибута format элемента clip должно быть ограничено несколькими возможными форматами мультимедиа:
<!ATTLIST clip format (mp3|mpeg|mov|rm) #REQUIRED>
Атрибут scr элемента clip также должен быть объявлен как обязательный атрибут. Что касается атрибутов scr и length, их можно оставить почти в том же виде, в котором они определены на данный момент. Мы думаем, что нам поначалу не придется слишком много работать с этими атрибутами; мы просто укажем их значения рядом со ссылкой на файл мультимедиа. На самом деле мы все равно можем сделать лишь немногое в отношении задания единиц или ограничений для этих полей. За проверку правильности этих атрибутов отвечает само приложение.
Наконец, нам нужен элемент, описывающий требования по доставке товаров покупателю. Хотя исходно каталог был рассчитан на товары, которые доставляются покупателю посылкой, но на случай расширения каталога нужно предусмотреть и другие возможности, например пересылку определенных видов товаров по электронной почте или пересылку каких-то особых товаров, для которых имеются специфические требования [Shipping info — информация о доставке — Примеч перев. ].
<!ELEMENT shipping_info > <!ATTLIST shipping_info type CDATA #REQUIRED> <!ATTLIST shnpping_infо value CDATA #IMPLIED>
Вместо того чтобы указывать какую-то одну характеристику отправляемого товара (например, вес), мы выбрали более общий термин — величина (атрибут value). Этот атрибут можно легко приспособить к любому типу товаров и способу их доставки; например, если мы будем продавать электронные версии книг, загружаемые через Интернет, то данный атрибут будет идентифицировать размер книги в мегабайтах.
После того как мы внесли все указанные выше исправления в первую черновую версию, мы можем скомпоновать окончательную версию определения catalog.dtd и создать пример каталога catalog.xml. Он довольно сильно отличается от первой версии и (как мы надеемся) гораздо лучше соответствует нашим требованиям. Листинг 2.6 содержит последнюю версию нашего определения DTD.
Листинг 2.6. Исправленный файл catalog .dtd
<!ENTITY % running_text "(#PCDATA | bold |
italics | quote | link | general)*"> <!ENTITY % date_time "(day_of_week?, month?,
day_of_month?, year?,(hour, minute, seconds?)?)"> <!ELEMENT catalog (product_line*) > <!ELEMENT product_line (product*)> <!ATTLIST product_line name CDATA #IMPLIED> <!ELEMENT product (name,author*,artist*,description, price,quantity_in_stock,image*, onsale_date?,clip*,shipping_info*)> <!ATTLIST product id ID #REQUIRED> <!ATTLIST product keywords CDATA #IMPLIED> <!ELEMENT name (#PCDATA)> <!ELEMENT author (name)> <!ELEMENT artist (name)> <!ELEMENT description (paragraph|general)* > <!ELEMENT paragraph %running_text;> <!ELEMENT bold (#PCDATA)> <!ELEMENT italics (#PCDATA)> <!ELEMENT quote (#PCDATA)> <!ATTLIST quote attrib CDATA #IMPLIED> <!ELEMENT link (#PCDATA)> <!ATTLIST link href CDATA #REQUIRED alt CDATA #IMPLIED> <!ELEMENT general (#PCDATA)> <!ATTLIST general type CDATA #REQUIRED> <!ELEMENT price (#PCDATA)> <!ATTLIST price discount CDATA #IMPLIED> <!ELEMENT quantity_in_stock (#PCDATA)> <!ELEMENT image (caption?)> <!ATTLIST image format (gif|png|jpg) #REQUIRED width CDATA #IMPLIED height CDATA #IMPLIED src CDATA #REQUIRED> <!ELEMENT caption (paragraph)* > <!ELEMENT onsale_date %date_time;> <!ELEMENT day_of_week (#PCDATA)> <!ELEMENT month (#PCDATA)> <!ELEMENT day_of_month (#PCDATA)> <!ELEMENT year (#PCDATA)> <!ELEMENT hour (#PCDATA)> <!ELEMENT minute (#PCDATA)> <!ELEMENT seconds (#PCDATA)> <!ELEMENT clip (title,description?)> <!ATTLIST clip format (mp3|mpeg|mov|rm) #REQUIRED length CDATA #IMPLIED size CDATA #IMPLIED src CDATA #REQUIRED> <!ELEMENT title (#PCDATA)>
В листинге 2.7 содержится правильно оформленный и допустимый документ XML, в котором используется DTD из файла catalog.dtd. Это только фрагмент исходного текста для полного каталога, который вы найдете на прилагаемом к данному курсу каталоге файлов.
Листинг 2.7. Пример каталога из файла catalog.xml
<?xml version="1.0" standalone="no"?> <!DOCTYPE catalog SYSTEM "catalog.dtd"> <!-- modified 10/12/2000 --> <catalog> <product_line name="Books"> <product id="bk0022" keywords="gardening, plants"> <name>Guide To Plants</name> <description> <paragraph> <italics>Everything</italics> you've ever wanted
to know about plants. </paragraph> </description> <price>$12.99</price> <quantity_in_stock>4</quantity_in_stock> <image format="gif" width="234" height="400"
src="images/covers/plantsv1.gif"> <caption> <paragraph>This is the cover from the first
edition.</paragraph> </caption> </image> <onsale_date> <month>4</month> <day_of_month>4</day_of_month> <year>1999</year> </onsale_date> <shipping_info type="UPS" value="1.0" /> </product> <product id="bk0023" keywords="gardening,
plants"> <name>Guide To Plants, Volume 2</name> <description> <paragraph>Everything else you've ever wanted
to know about plants.</paragraph> </description> <price>$12.99</price> <quantity_in_stock>4</quantity_in_stock> <image format="gif" width="234" height="400"
src="images/covers/plantsv2.gif"> <caption> <paragraph>This is the cover from the first
edition.</paragraph> </caption> </image> <onsale_date> <month>4</month> <day_of_month>8</day_of_month> <year>2000</year> </onsale_date> <shipping_info type="UPS" value="1.0" /> </product> <product id="bk0024"
keywords="how-to, technology"> <name>The Genius's Guide to the 3rd Millenium</name> <author> <name>Christoph Minwich</name> </author> <description> <paragraph>Learn to convert your replicator
into a transporter..and other neat tricks.</paragraph> </description> <price>$59.95</price> <quantity_in_stock>0</quantity_in_stock> <image format="gif" width="234" height="400"
src="images/covers/millenium.gif"> </image> <onsale_date> <month>1</month> <day_of_month>1</day_of_month> <year>2001</year> </onsale_date> <shipping_info type="UPS" value="2.0" /> </product> <product id="bk0025" keywords="how-to, art"> <name>Dryer Lint Art</name> <description> <paragraph>A new book about the new folk art
that's catching on like wildfire.</paragraph> </description> <price>$5.95</price> <quantity_in_stock>34</quantity_in_stock> <image format="gif" width="200" height="200"
src="images/covers/dryerart.gif"> </image> <onsale_date> <month>11</month> <day_of_month>3</day_of_month> <year>1971</year> </onsale_date> <shipping_info type="UPS" value="1.5" /> </product> </product_line> <!-- end Book Product Line --> <!-- being CDs Product Line --> </product_line> <product_line name="CDs"> <product id="cd0023" keywords="music,easy
listening,pets,dogs"> <name>Music for Dogs</name> <description> <paragraph>Keep your pets calm while you're
away from the house! Each of the 15 tracks
on this CD has been scientifically shown to
relax pets of all kinds.</paragraph> </description> <price>$14.99</price> <quantity_in_stock>50</quantity_in_stock> <image format="gif" width="200" height="200"
src="http://www.musicfordogs.com/images/cover.gif"> </image> <onsale_date> <month>3</month> <day_of_month>2</day_of_month> <year>1990</year> </onsale_date> <clip format="mp3" length="2:12" size="1.6 Mb" src="http://www.musicfordogs.com/sounds/track1.mp3"> <title>Track 1: Fetching the Stick</title> <description> <paragraph>An exciting and playful melody.</paragraph> </description> </clip> <shipping_info type="UPS" value="0.5" /> </product> <product id="cd0024" keywords="music,easy listening"> <name>Just Singin' Along</name> <description> <paragraph>A lovely collection of songs that the whole family can sing right along with.</paragraph> </description> <price>$10.00</price> <quantity_in_stock>100</quantity_in_stock> <onsale_date> <month>2</month> <day_of_month>23</day_of_month> <year>2000</year> </onsale_date> <shipping_info type="UPS" value="0.5" /> </product> <product id="cd0025" keywords="music,folk"> <name>It's Dot Com Enough For Me: Songs From Silicon Somewhere</name> <description> <paragraph>A collection of the best folk music from Internet companies.</paragraph> </description> <price>$12.99</price> <quantity_in_stock>4</quantity_in_stock> <onsale_date> <month>4</month> <day_of_month>12</day_of_month> <year>2000</year> </onsale_date> <clip format="mp3" length="4.32" size="4.0 Mb" src="track2.mp3"> <title>Track 2: My B2B is B-R-O-K-E</title> </clip> <shipping_info type="UPS" value="0.5" /> </product> </product_line> <!-- end CDs product line --> <!-- begin Widgets product line --> <product_line name="widgets"> <product id="wg0026" keywords="appliance,electronics"> <name>ElectroThermal Oxidizer</name> <description> <paragraph>This amazing gizmo uses electricity to produce heat that can be used for oxidization purposes.</paragraph> </description> <price>$24.95</price> <quantity_in_stock>10</quantity_in_stock> <image format="jpg" width="208" height="178" src="/images/toaster.jpg"> </image> <onsale_date> <month>6</month> <day_of_month>2</day_of_month> <year>2000</year> </onsale_date> <shipping_info type="UPS" value="12.0" /> </product> <product id="wg0027" keywords="computing,
electronics, input device"> <name>Percusive Interface Unit</name> <description> <paragraph>Communicate with your favorite
electric calculating machine--through
tapping!</paragraph> </description> <price>$109.99</price> <quantity_in_stock>7</quantity_in_stock> <onsale_date> <month>6</month> <day_of_month>23</day_of_month> <year>2001</year> </onsale_date> <shipping_info type="UPS" value="12.0" /> </product> <product id="wg0028" keywords="outdoors"> <name>Umbrella</name> <description> <paragraph>Imagine going out into the rain and NOT getting wet! The amazing umbrella makes it possible.</paragraph> </description> <price>$10.99</price> <quantity_in_stock>7</quantity_in_stock> <onsale_date> <month>7</month> <day_of_month>2</day_of_month> <year>2000</year> </onsale_date> <shipping_info type="UPS" value="10.0" /> </product> <!-- end widgets product line --> <!-- end catalog --> </catalog>
Если вы взяли на себя труд внимательно проследить весь процесс создания DTD для каталога товаров, описанный нами в этой главе, возможно, вы отчаялись и решили никогда больше не связываться с XML и DTD. Но мы не советуем вам сдаваться, так как на самом деле существует несколько удобных обобщений, которые используются при создании DTD. В этом разделе мы обсудим наиболее полезные из них.
В первой главе мы говорили о двух различных языках для определения классов документов XML: язык определения типов документов, который включен в спецификацию XML 1.0, и схемы XML. В настоящее время обсуждается возможность принятия в качестве стандарта определения типа документа других методов, в том числе XML-Data и DCD (Document Content Description — описание содержимого документа).
ПРИМЕЧАНИЕ
Хотя в нашем курсе при определении типа документа мы используем спецификацию XML 1.0, многие концепции, упоминаемые в этом разделе, не характерны для определения типа документа, построенного с помощью этой конкретной разновидности языка.
Определенная разновидность языка разметки электронного текста существовала уже несколько десятилетий назад, и за прошедшие годы у людей сформировался определенный опыт в области разметки документов. Создатели XML учли те проблемы, с которыми сталкивались авторы, использовавшие SGML, и намеренно освободили XML от некоторых из них. Достичь этого помогло более простое, чем SGML, устройство языка XML. В то же время создатели XML смогли обеспечить совместимость этого языка с SGML.
За последние несколько лет, тем не менее, авторы, пишущие на XML, столкнулись со многими затруднениями как свойственными языку SGML, так и специфическими для XML. Ниже мы приводим несколько советов, которые помогут вам избежать некоторых проблем, возникающих при разработке DTD.
Репрезентативный образец данных
При создании DTD общего назначения главная задача заключается в том, чтобы проанализировать достаточно большую подборку данных. При этом вы, с одной стороны, не должны упустить из виду никаких существенных деталей, но, с другой стороны, не следует и вдаваться в избыточные подробности, раздувая DTD до огромных размеров.
Следует помнить, что нельзя объять необъятное. Если стремиться к этому, вы увязнете в бесконечных спорах и обсуждениях. История показывает, что, когда люди пытаются договориться о стандартах в какой бы то ни было области, будь то языки разметки, программирование или строительство, — всегда существует вероятность углубиться в длительные дискуссии, оставляя нерешенным главный вопрос. Поэтому следует принять волевое решение и остановиться на пусть несовершенном и, возможно, слишком общем определении DTD, которое впоследствии можно будет при необходимости доработать и дополнить, вместо того чтобы продолжать бесконечные споры.
Избегайте субтрактивного уточнения
Авторам, пишущим на HTML, хорошо известно, что субтрактивное уточнение гораздо сложнее, чем аддитивное. Создатели браузеров за годы существования HTML сделали множество дополнений (или расширений) этого языка. В свое время многие из этих дополнений играли важную роль, отвечая определенным потребностям, но теперь они только тормозят развитие языка и должны быть удалены как из спецификации HTML, так и из употребления.
Самым известным примером таких дополнений HTML является элемент font (шрифт). Когда этот элемент был введен, не существовало никакого жизнеспособного альтернативного способа указать, как именно должен форматироваться текст. В настоящее время имеются каскадные таблицы стилей (Cascading Style Sheets, CSS) и, более того, расширяемый язык таблиц стилей (Extensible Stylesheet Language, XSL), которые предназначены как раз для работы с форматом представления документов. Но до сих пор многие (если не большинство) web-дизайнеры используют элемент font для форматирования текста. Причина в том, что web-дизайнеры хорошо знакомы с этим элементом и знают в точности его действие на текст документа. Каскадные таблицы стилей являются гораздо более гибким, но и более сложным инструментом; кроме того, реализация CSS в каждом из браузеров сопровождается различными сбоями и неполадками, пока что недостаточно хорошо изученными.
Последние несколько лет Консорциум W3C пытается исключить элемент font из HTML. Но так как этот элемент присутствует в очень многих web-страницах и очень многие web-дизайнеры весьма активно его используют, видимо, пройдет еще немало времени, прежде чем элемент font прекратит свое существование. Было бы замечательно, если бы всегда удавалось избегать субтрактивного уточнения, но реально это не всегда получается. Тем не менее можно постараться минимизировать количество элементов, которые впоследствии, возможно, придется удалять из документа.
Первый шаг, который следует предпринять, если вы хотите минимизировать потребность в субтрактивном уточнении, — это осознание причин, по которым такое уточнение вообще становится необходимым. Основной причиной удаления объявлений из DTD является то, что эти объявления задают типы данных или правила, не соответствующие или вступающие в противоречие с теми реалиями данной сферы деятельности, которые призваны отображать. Например, представьте себе, что у вас имеется DTD для разметки документов, описывающих счета за предоставленные услуги. Допустим, в вашей фирме оплата производится по фиксированной шкале, за каждый вид работ назначена определенная сумма. Но определение DTD могло сохраниться с тех времен, когда присутствовала и другая форма оплаты — почасовая. Соответствующие объявления могли бы выглядеть следующим образом [Invoice — счет, service — вид работ, duration — затраченное время, rate — оплата за час работы, fee — стоимость работ, totaldue — общая сумма к оплате. — Примеч. перев. ]:
<!ELEMENT invoice (service*,total_due)> <!ELEMENT service (description,(duration,rate)?,fee?)> <!ELEMENT description (#PCDATA)> <!ELEMENT duration (hours.minutes)> <!ELEMENT rate (#PCDATA)> <!ELEMENT fee (#PCDATA)> <!ELEMENT total_due(#PCDATA)>
Поскольку в вашей фирме больше не используется почасовая оплата, эти объявления становятся ненужными и только вносят путаницу. Например, если ваша фирма за какую-то работу берет с клиента 300 долларов и эта работа выполняется за 3 часа, то существуют по меньшей мере два способа записать эту информацию:
<!-первый способ записи--> <invoice> <service> <description>Установка бензинового нacoca</description> <duration> <hours>3</hours> <minutes>0</minutes> </duration> <rate>$100</rate> <fee>$300</fee> </service> </invoice> <!-второй способ записи--> <invoice> <service> <description>Установка бензинового нacoca</description> <fee>$300</fee> </service> </invoice>
Согласно существующему определению DTD, оба эти способа корректны, но только второй отражает реальную ситуацию. Чтобы исключить возможность некорректного использования этого определения, следует удалить элементы rate и duration, как это сделано во втором способе записи.
Не делайте определение DTD настолько сложным, чтобы его нельзя было легко и просто прочитать. Чем легче для чтения и понимания будет ваше DTD, тем оно окажется полезнее. Если вы разрабатываете DTD для очень специализированной области применения, оно неизбежно будет сложнее, чем DTD для обычного каталога товаров. В листинге 2.8 представлены два определения DTD, причем второе выполняет те же функции, хотя гораздо проще первого [Phone call — телефонный звонок, valid phone digits — допустимые телефонные символы, from — от, to — кому, content — содержимое, phone number — телефонный номер, digit — цифра (символ), dash — тире, caller — вызывающий абонент, answerer — отвечающий абонент — Примеч. перев. ].
Листинг 2.8. Два возможных DTD для описания телефонного звонка.
<!—DTD для элемента phone_call--> <!ENTITY % valid jihone_ch gits '"
(1|2|A|B|C|3|D|E|F|4|G|H|I|5|J|K|L|6|M|N|
0|7|P|R|S|8|T|U|V|9|W|X|Y|0)"> <'ELEMENT phone_call (from*.to*,content)> <!ELEMENT from (phone_number)> <!ELEMENT phone_number ((dig!t?,digit'.digit?,dash?)?, digit, digit, digit, dash, digit, digit,digit,digit)> <!ELEMENT digit EMPTY> <!ATTLIST digit number
%valid_phone_dlgits; #REQUIRED> <!ELEMENT dash EMPTY> <!ATTLIST dash value CDATA #FIXED "-"> OELEMENT to (phone_number)> <iELEMENT content
(caller|answerer)*> <'ELEMENT caller (#PCDATA)>
<!ELEMENT answerer (#PCDATA)> <!—упрощенное определение DTD для элемента phone_call--> <!ELEMENT phone_call (from*,to*,content)> <!ELEMENT from EMPTY> <!ATTLIST from
phone_number CDATA #REQUIRED> <!ELEMENT to EMPTY> <!ATTL1ST to phone_number CDATA #REQUIRED> <!ELEMENT content (caller|answerer)*> <!ELEMENT caller (#PCDATA)> <!ELEMENT answerer (#PCDATA)>
В большинстве случаев достаточно использовать второе, упрощенное определение DTD, так как первое является слишком сложным. Сколько потребуется времени, чтобы разобраться в нем и понять, что это всего лишь определение обычного телефонного номера? В данном случае возможная область применения DTD, несомненно, преувеличена. Нужно ли нам на самом деле выделять каждую цифру телефонного номера? Может быть, данный пример несколько утрирован, но он иллюстрирует основную идею' не злоупотребляйте подробностями при создании DTD или документов XML. Здесь существует некий предел, переход за который может оказаться губительным.
Вероятно, при разработке DTD наиболее часто задается и наиболее горячо обсуждается вопрос о том, в каких случаях следует использовать элементы, а в каких — атрибуты. Например, если у вас имеется книга и ее название, как вы определите, какой из следующих способов представления данных правилен:
первый способ:
<Book> <Titlе>Справочник по растениям</Тitle> </Book>
второй способ:
<Book Title="Справочник по растениям"> </Book>
Суть заключается в том, что по большому счету это дело личного выбора. Как и в большинстве ситуаций, в этом вопросе имеются прямо противоположные точки зрения. Некоторые утверждают, что использование атрибутов упрощает программный доступ к данным в документах XML. Побочным эффектом предпочтения атрибутов является то, что получившийся документ становится сложнее для человеческого восприятия Другие считают, что данные следует организовывать исключительно в виде элементов. Большинство же придерживается золотой середины, применяя как атрибуты, так и элементы для записи данных.
Существует, однако, несколько правил, которые были выработаны уважаемыми авторами, долгое время пишущими на XML и SGML. Этими правилами можно руководствоваться в вопросе о том, как следует оформить конкретный фрагмент данных — в виде элемента или в виде атрибута. Чтобы пользоваться этими правилами, нужен некоторый опыт. Также следует помнить, что из любых правил существуют исключения.
Атрибуты следует использовать для записи информации о содержимом (метаданные), в то время как элементы следует использовать для записи фактической информации. Например, цвет обложки книги может быть отнесен к метаданным и записан как атрибут. Абзац из этой книги следует рассматривать как фактическое содержимое.
Для записи данных перечислимого типа (например, номера товара в списке или его уникального идентификатора) следует использовать атрибуты.
При записи данных, предназначенных для программного прочтения, используйте атрибуты. Для записи данных, которые будут читать люди, используйте элементы.
Если важен порядок следования значений, используйте элементы. (Причина заключается в том, что невозможно задать порядок следования атрибутов, но порядок следования элементов можно смоделировать нужным образом.)
Рассуждайте в терминах реальных процессов
При разработке DTD лучше рассуждать в терминах реальных бизнесс-процес- сов, а не в терминах конкретного приложения. Если вы не делаете никаких предположений о том, как и кем будет обрабатываться документ, вы составите гораздо более гибкое определение DTD. Например, хотя с большой вероятностью можно предположить, что DTD для нашего электронного магазина будет гораздо чаще обрабатываться приложением, чем изучаться людьми, это обстоятельство при разработке DTD не учитывается. Если бы мы составляли определение DTD, которое заведомо использовалось бы только программами, мы, к примеру, могли бы сэкономить значительный объем памяти за счет более коротких (но менее понятных!) имен элементов и за счет более широкого использования параметрических сущностей. Но такой подход искажает саму суть языка XML, предназначенного как раз для того, чтобы чтение документа было легким как для машин, так и для людей. Жертвуя пространством на диске и скоростью работы приложения, вы получаете гораздо более значимый выигрыш — гибкий и удобный в использовании документ XML с корректной разметкой данных.
Шаблоны XML — это готовые решения распространенных проблем, возникающих в определенных ситуациях. В последнее время шаблоны все больше привлекают внимание как способ совершенствования процесса разработки приложений и обмена полезной информацией как внутри отдельных компаний, так и в сфере разработки программного обеспечения в целом.
Несмотря на большое количество появившихся в последнее время книг и статей о шаблонах, лежащая в их основе идея не представляет собой ничего нового. Это та же идея, на которой основаны книги по нетрадиционной медицине, диетическому питанию и оздоровительным процедурам, — сходные задачи имеют сходные решения. В шаблоне просто формулируется контекст задачи, сама задача и способ ее решения. Шаблоны обычно составляются некоторым стандартным образом, что облегчает их чтение и понимание.
Если при конструировании DTD вы будете использовать исключительно готовые шаблоны, вы, вероятнее всего, не сделаете грубой ошибки, но одновременно вряд ли добьетесь оптимального решения. Тем не менее очень часто оказывается, что кто-то другой уже сталкивался с такой же задачей, которую пытаетесь решить вы, и, заглянув в архив шаблонов, вы найдете искомое решение и вам не придется изобретать велосипед.
Для описания шаблонов имеется определенный стандарт, состоящий из нескольких разделов (краткое описание шаблона, контекст, пример и т. д.). Ниже описывается шаблон универсального элемента (generic element) для web-документов. Этот шаблон и многие другие можно найти на сайте www.xmlpatterns.com.
Для обеспечения максимальной гибкости был сконструирован универсальный элемент. Область применения этого элемента не фиксируется жестко, поэтому авторы могут использовать его по своему усмотрению.
Основная задача, стоявшая перед создателями шаблона, — обеспечить гибкость конструкции, так как не известно в точности, каким образом авторы документов будут использовать универсальный элемент.
Этот элемент можно использовать в документах общего назначения, в которых важным требованием является гибкость.
Более гибкие типы документов могут оказаться более удобными. Универсальный элемент облегчает обработку документа.
Шаблон универсального элемента создает новый элемент, не имеющий специфического назначения.
Ниже приводится пример кода шаблона:
<Paragraph> Повесть Алберта Камю <General
type="book">Посторонний</General>
служит примером выражения идей
экзистенциализма в литературе </Paragraph>
Недостаток гибкости может послужить причиной использования авторами документа неподходящего элемента для разметки. Это может привести к тому, что документы будут трудны для восприятия и при их обработке возникнут ошибки.
При обработке конструкций, отвечающих требованиям гибкости, могут возникнуть некоторые проблемы. Добавление атрибута role к универсальному элементу дает обрабатывающим программам некоторые ключи к тому, как следует обрабатывать этот элемент.
Вместе с универсальным элементом часто используется шаблон Role Attribute (атрибут role).
Элементы div и span в XHTML являются распространенными примерами применения данного шаблона.
В настоящее время во многих приложениях, которые используют XML, DTD отсутствует. Это в основном относится к тем приложениям, которые связаны с передачей сообщений, а не с хранением данных. Даже если вы не создаете формального определения DTD, вам все равно приходится думать о том, как лучше разметить данные в вашем приложении. Выбор способа разметки может оказаться достаточно сложным и длительным процессом.
Многие из тех, кто использует XML для создания приложений, надеются, что в будущем им не придется так много беспокоиться по поводу разработки DTD. Когда будет принято соглашение о языке схем, лучше других приспособленном для описания данных, будет гораздо проще стандартизировать и многократно использовать определения типов документов.
Хотя пользовательское определение DTD, подобное тому, которое мы разработали в этой главе для сайта XMLGifts.com, может быть очень мощным инструментом, достоинства XML проявятся в полную силу лишь тогда, когда большее количество организаций договорятся о стандартных схемах.
В приведенном ниже списке перечислены некоторые схемы XML для электронной коммерции, рекламируемые в настоящее время различными производителями и организациями.
Commerce One, поставщик программного обеспечения для электронной коммерции, предлагает «общую бизнес-библиотеку» — Common Business Library (CBL) — открытые спецификации XML для обмена документами между разными промышленными секторами. Такими документами могут быть заказы на приобретение, описания продуктов или схемы поставок.
Организация UN/CEFACT (The United Nations Centre for the Facilitation of Procedures and Practices for Administration, Commerce and Transport — Центр по упрощению процедур и практики в управлении, торговле и на транспорте) при ООН реализует проект EbXML (XML for electronic bismess — XML для электронного бизнеса), направленный на создание «единого глобального электронного рынка», который поддерживается Организацией OASIS (Organization for the Advancement of Structured Information Standards). Согласно определению, приведенному на web-сайте www.ebxml.org, EbXML — это открытый глобальный основанный на XML стандарт для электронной коммерции.
Согласно IBM, язык BRML (Business Rules Markup Language — язык разметки для деловых операций) — это «промежуточный язык для службы Agent Communication, основанный на программах Courteous/Ordinary Logic». BRML используется совместно с CommonRules IBM — библиотекой Java, которая обеспечивает функциональность для деловых операций.
Язык traML (Trading Partner Agreement Markup Language — язык разметки для соглашений между торговыми партнерами) предложен компанией IBM как язык для организации электронных контактов между торговыми партнерами.
В настоящее время разработана спецификация ОТР (Online Trading Protocol — открытый торговый протокол), которая представляет собой структуру для осуществления деловых транзакций на основе XML, независимую от систем оплаты. Протокол ОТР был разработан несколькими банками и компаниями, занимающимися проведением коммерческих расчетов через Интернет, в том числе SET, Mondex, CyberCash, DigiCash и GeldKarte.
Гибкость и возможность многократного использования данных являются ключевыми принципами при развитии удобных в управлении приложений XML. Тщательная разработка DTD или, если возможно, соглашение о едином стандарте DTD в данной области должны стать первым шагом при разработке любого серьезного приложения XML. В следующих главах нашего курса при обсуждении вопросов манипулирования данными XML с помощью языка Java всегда будет использоваться определение DTD (хотя время от времени его придется модифицировать) для обеспечения структурированности и целостности данных.
1. Электромагнитная волна (в религиозной терминологии релятивизма - "свет") имеет строго постоянную скорость 300 тыс.км/с, абсурдно не отсчитываемую ни от чего. Реально ЭМ-волны имеют разную скорость в веществе (например, ~200 тыс км/с в стекле и ~3 млн. км/с в поверхностных слоях металлов, разную скорость в эфире (см. статью "Температура эфира и красные смещения"), разную скорость для разных частот (см. статью "О скорости ЭМ-волн")
2. В релятивизме "свет" есть мифическое явление само по себе, а не физическая волна, являющаяся волнением определенной физической среды. Релятивистский "свет" - это волнение ничего в ничем. У него нет среды-носителя колебаний.
3. В релятивизме возможны манипуляции со временем (замедление), поэтому там нарушаются основополагающие для любой науки принцип причинности и принцип строгой логичности. В релятивизме при скорости света время останавливается (поэтому в нем абсурдно говорить о частоте фотона). В релятивизме возможны такие насилия над разумом, как утверждение о взаимном превышении возраста близнецов, движущихся с субсветовой скоростью, и прочие издевательства над логикой, присущие любой религии.
4. В гравитационном релятивизме (ОТО) вопреки наблюдаемым фактам утверждается об угловом отклонении ЭМ-волн в пустом пространстве под действием гравитации. Однако астрономам известно, что свет от затменных двойных звезд не подвержен такому отклонению, а те "подтверждающие теорию Эйнштейна факты", которые якобы наблюдались А. Эддингтоном в 1919 году в отношении Солнца, являются фальсификацией. Подробнее читайте в FAQ по эфирной физике.
|
|
