Если вы программируете на Java, за последние пару лет вам наверняка часто приходилось слышать об XML. Эта лекция поможет вам максимально быстро освоиться с технологией XML и с сопутствующей терминологией, так что вы вскоре сможете оценить все преимущества XML. Когда вы начнете разрабатывать приложения с использованием XML, разделы «Краткий справочник по правилам XML» и «Правила XML» данной лекции могут пригодиться вам в качестве справочного пособия по XML.
Расширяемый язык разметки (Extensible Markup Language, XML), созданный в 1996 году Консорциумом W3C (World Wide Web Consortium), является подклассом стандартного языка разметки (Standard Generalized Markup Language, SGML). XML был задуман как гибкий и в то же время формальный метаязык для использования в Интернете.
Метаязык (metalanguage) — это язык, предназначенный для описания других языков. Например, можно сказать, что словарь английского языка в совокупности с английской грамматикой образуют метаязык, описывающий английский язык.
Что касается языка XML, то назначение его — описывать языки разметки. В языке разметки (markup language) для структурирования данных используются теги. Язык гипертекстовой разметки (Hypertext Markup Language, HTML), наиболее распространенный на сегодняшний день язык разметки, исходно был написан на SGML, но мог бы быть и в какой-то степени был написан и на XML.
Язык HTML был задуман для решения специфических задач — разметки документов научной и академической направленности. Если вы занимались какой-либо деятельностью по разработке web-страниц, то хорошо знаете, что в настоящее время HTML «трещит по всем швам», так как на протяжении многих лет делаются попытки дополнить его так, чтобы он соответствовал всем запросам web-программистов. Многие называют XML заменой HTML, но это не совсем точное высказывание.
В то время как HTML содержит фиксированный набор тегов, в XML теги вообще отсутствуют. Вместо этого XML позволяет программисту самому создать такой язык разметки, который в точности соответствует требованиям конкретного приложения. В нашего курса мы проиллюстрируем процесс создания приложения, относящегося к области электронной коммерции. Язык разметки, который мы будем использовать, содержит теги, выглядящие осмысленно именно в этой области (такие, например, как <price> и <quantity>) [Price — цена, quantity — количество. — Примеч. перев. ].
В приложениях XML обычно используются следующие типы данных и вспомогательные функции:
сам файл XML, имеющий строго определенную структуру;
определение типа документа (Document Type Definition, DTD), где определяется структура файла XML (необязательный элемент);
таблицы стилей, содержащие информацию о том, как данные должны быть отформатированы при выводе (необязательный элемент);
процессор XML и различные служебные функции для манипулирования данными и переформатирования данных.
Для разработчиков web-приложений привычными являются рассуждения о том, что делают с текстом те или иные теги. Мы привыкли к тому, например, что тег <b> выделяет соответствующий текст жирным шрифтом. Тем не менее фактически этот тег не имеет какого-либо собственного значения. Как будет отображен текст, помеченный тегом <b>, полностью зависит от программы, анализирующей данные. В случае HTML такой программой обычно является web-браузер. Поскольку документы HTML создаются обычно в предположении, что их будут читать с помощью web-браузера, многие теги HTML указывают, как следует форматировать данные, но не содержат никакой информации для обычного человека. Назначение XML заключается как раз в том, чтобы отделить данные, содержащиеся в документе, от кода, который задает формат отображения этих данных. Это свойство XML позволяет извлекать данные из документа автоматически, то есть с помощью программных средств.
К примеру, предположим, что вы — торговый посредник и занимаетесь продажей электрических лампочек. На вашем web-сайте приводится самая свежая информация о ценах на товары от различных производителей. Вместо того чтобы вручную проверять web-сайты этих производителей и таким образом узнавать информацию о ценах, вы решаете написать программу, которая автоматически бы считывала цены, добавляла бы 10 % (надбавка для вас) и отображала бы информацию о товарах на вашем web-сайте. Пусть одним из ваших поставщиков является фирма ABC Lightening. В листинге 1.1 приводится часть кода HTML для таблицы, содержащей данные о товарах из web-сайта ABC Lightening [Авторы курса в листингах лекций 1 и 2 приводят вымышленные описания товаров, которые не следует воспринимать всерьез. — Примеч. перев. ].
Листинг 1.1. Код HTML для таблицы, содержащей информацию о товарах [Все представленные в курсе тексты программ можно найти на сайте издательства по адресу www.piter.com. — Примеч. ред. ]
<table> <tr> <th>Название товapa</th> <th>0писание</th> <th>Ценa</th> </tr> <tr> <td><b>Фонарик</b> </td> <td>Свет, который всегда с вами!</td> <td>$9.95</td> </tr> <tr> <td><b>Неоновая лампа</b></td> <td>Ничто не скажет слово "класс" так,
как неоновая лампа!</td> <td>$14.75</td> </tr> </table>
Документ HTML только определяет, как должен быть отформатирован данный текст. Автоматическое извлечение информации из статической страницы HTML даже в лучшем случае окажется весьма непростой задачей. Если вы хотите написать программу, которая бы извлекала данные о цене из приведенного кода HTML, вы можете указать, что цена фонарика присутствует в третьем столбце таблицы в той строке, где в первом столбце стоит слово «фонарик». Но при этом вы рискуете тем, что ваша программа перестанет работать, если изменится дизайн web-сайта ABC Lightening или просто поменяется название данного товара.
Вполне вероятно, что некоторые фирмы-производители динамически создают свои web-сайты на основе информации из баз данных. В таком случае вы можете договориться с web-мастером каждого сайта об обмене информацией прямо из баз данных, но этот процесс требует времени и может происходить по- разному для каждой базы данных, из которой вам требуется получить информацию. Было бы гораздо проще, если сам документ был бы организован так, чтобы из него было легко извлекать содержательную информацию.
В листинге 1.2 приведен пример того, как та же информация может быть представлена с помощью XML [Catalog — каталог, product — товар, name — название, description — описание. — Примеч. перев ].
Листинг 1.2. Документ XML, содержащий информацию о товарах
<?xml version="l.0" standalone="no"?> <!DOCTYPE ABC_Lighting: catalog SYSTEM "catalog.dtd"> <ABC_Ughting: catalog xmlns:ABC_Lighting = "http://www.abclighting.com"> <ABC_Lighting:product> <ABC_Lighting:name>Фонарик</ABC_Lighting:name> <ABC_Lighting:description>Cвeт, который всегда с вами! </ABC_Lighting:description> <ABC_Lighting:price>$9.95</ABC_Lighting:price> </ABC_Lighting:product> <ABC_Lighting:product> <АВС_Lighting:name>Неоновая лампа</ABC_Lighting:name> <ABC_Lighting:description>Ничто не скажет слово "класс" так, как неоновая лампа! </ABC_Lighfmg:description> <ABC_lighting:price>$14.75</ABC_Lighting:price> </ABC_Lighting:product> </ABC_Lighting:catalog>
Первая строка этого документа — объявление XML, которое содержит информацию, предназначенную для анализатора XML. Объявление XML (XML declaration) идентифицирует тип документа и версию XML, которая использовалась при создании документа. Эта строка не является обязательной, но, как правило, именно с нее начинается документ XML. Атрибут standalone = "no" означает, что данный документ снабжен DTD. Следующая строка — это объявление типа документа (document type declaration), которое указывает, какому DTD соответствует этот документ. В данном случае используется определение DTD, называемое catalog.dtd. Обратите внимание на то, что, хотя аббревиатуры совпадают, имеется большая разница между определением типа документа (сокращенно DTD — Document Type Definition) и объявлением типа документа. Объявление типа документа используется, чтобы указать, какому определению типа документа соответствует данный документ XML.
В объявлении типа документа также указывается корневой элемент документа. Корневой элемент (root element) — это элемент, который включает в себя все остальные элементы документа. В данном случае корневым является элемент ABC_Lightening:catalog. Часть имени элемента, расположенная перед двоеточием, идентифицирует пространство имен тега. Пространства имен не являются обязательными, но их можно использовать для того, чтобы гарантировать уникальность тегов. Если фирма ABC_Lightening начнет продавать товары других производителей, то пространства имен помогут избежать возможной путаницы, связанной с тем, что появятся элементы данных, внешние по отношению к этой фирме, с теми же названиями, но иначе структурированные.
Ниже показано, как может выглядеть определение catalog.dtd для гипотетического каталога товаров:
<!ELEMENT ABC_Lightening:catalog (product)> <!ELEMENT ABC_Lightening:product (name, description?, price+)> <!ELEMENT ABC_Lightening:name (#PCDATA)> <!ELEMENT ABC_Lightening:description (#PCDATA)> <!ELEMENT ABC_Lightening:price (#PCDATA)>
Это DTD показывает, какие элементы могут появиться в каталоге, а также определяет порядок их следования и число появлений. С использованием данных XML и DTD автоматическая идентификация и извлечение полезных данных из документа XML становятся довольно простым делом, в чем вы убедитесь, изучив этот курс.
Следующие web-ресурсы содержат информацию о последних разработках в области XML, планах на будущее и инструментальных средствах, полезных при работе с XML:
консорциум W3C (www.w3.org);
O'Reilly&Associates, Inc.'s XML.com (www.xml.com) — один из лучших сайтов в Сети, посвященных коммерческому применению XML;
XML Industry Portal, (www.xml.org);
xmlhack (www.xmlhack.com) — новости для web-разработчиков;
Enhydra (www.enhydra.org) — домашняя страница сервера Enhydra, посвященного приложениям Java/XML;
консорциум Unicode (www.unicode.org).
XML можно применять как на стороне сервера, так и на стороне клиента. Следующие два раздела рассказывают о принципах применения XML в каждой из этих областей. Кроме того, XML можно использовать для хранения данных, о чем говорится в третьем разделе.
На стороне клиента XML позволяет достичь такого уровня соответствия конкретным условиям представления данных, которого очень трудно или невозможно достичь с использованием HTML. Например, для таких устройств, как PDA (Personal Digital Assistant — «карманный» компьютер, предназначенный для выполнения некоторых специальных функций) или мобильный телефон, требуется, чтобы страницы были отформатированы совсем не так, как для стандартных web-браузеров. Обычно, если даже имелась готовая страница, предназначенная для web-браузера, для подобных устройств приходилось полностью ее переделывать, то есть фактически создавать новую версию этой страницы. Однако благодаря структурированным данным документа XML, в котором содержательные данные отделены от форматирующих указаний, все, что вам надо сделать для приведения страницы в соответствие с каждым конкретным отображающем ее прибором, — это применить к имеющимся данным нужную таблицу стилей.
В наши дни XML оказывает очень большое влияние на организацию работы сервера. Один из способов применения XML на стороне сервера — передача сообщений (messaging), то есть обмен данными между приложениями или компьютерами. Чтобы приложения и компьютеры могли обмениваться информацией, для них должен быть определен единый формат сообщений. Представить себе то огромное влияние, которое XML может иметь в этой области, невозможно, не зная, хотя бы в общих чертах, истории передачи сообщений. Выбор стандарта для этого остается проблемой с тех времен, когда люди начали общаться между собой, но здесь я имею в виду только последние 30 лет.
Электронная коммерция, согласно определению европейского семинара, посвященного технической поддержке электронной коммерции (European Workshop on Open System's Technical Guide on Electronic Commerce, EWOS TGEC 066), включает в себя такие разнообразные области, как маркетинг, поддержка логистики, проведение деловых операций и взаимодействие с административными органами (например, обмен данными по налогам и таможенным отчислениям). Механизм EDI (Electronic Data Interchange), предназначенный для обмена данными в электронной форме, начинает свою историю с 1970-х годов, когда он был впервые предложен Комитетом по координации передачи данных (Transportation Data Coordinating Committee, TDCC). В таких отраслях деятельности, как финансовая, где сетевые технологии начали применяться уже более тридцати лет назад, EDI служил в качестве стандартного формата обмена сообщениями. Недостаток систем EDI заключается в том, что их установка и поддержка обходятся дорого и, кроме того, они часто требуют выделенных линий.
В 1980-х годах началось бурное распространение и внедрение в фирмах систем электронной почты для рабочих групп. По мере того как производители пытались утвердить свои варианты таких систем в качестве стандарта, все больше фирм переходило на использование в своем бизнесе электронной почты. Такие пакеты, как Microsoft Mail и Lotus cc:Mail, позволяли небольшим компаниям обмениваться электронными сообщениями в пределах своей внутренней сети, но при попытке увеличить ее охват обычно начинались проблемы, управление сетью становилось все более трудной задачей. Также оказалось сложным объединить с внешним миром локальную сеть (Local Area Network, LAN). Результат, как и всегда в отношении компьютерных технологий, заключался в том, что передача сообщений становилась все более децентрализованной. По мере того как передача электронных сообщений отходила от первоначальной централизованной, строго контролируемой системы, требующей выделенных линий связи, в эту технологию вовлекалось все больше пользователей. Децентрализация привела также к огромным проблемам в отношении совместимости различных форматов, к дублированию разработок в области электронной коммуникации и к невозможности организованного ее развития.
Ко времени появления Интернета все уже очень хорошо понимали необходимость стандартизованного и в то же время гибкого способа организации передачи сообщений как между отдельными людьми, так и между компаниями, занимающимися электронной коммерцией. Широко доступный стандартный формат электронных сообщений имел бы огромное влияние на любой вид обмена информацией, как коммерческой, так и некоммерческой.
В первую очередь нужно было договориться о языке, и здесь XML оказался наиболее подходящим кандидатом. Основная причина, по которой XML прекрасно подходит для создания форматов передачи сообщений, — это его простота. XML подчиняется строго определенному стандарту, он не связан с какой-либо операционной системой или производителем, он совместим с большим количеством инструментальных средств и приложений, которые на протяжении многих лет разрабатывались для SGML. Требование строгого соответствия документов XML стандартам, установленным для правильно оформленных (well-formed) документов, гарантирует, что любой анализатор XML будет в состоянии прочесть и осмыслить любой документ XML. Кроме того, гораздо больше людей знакомы с языками разметки, чем с форматами сообщений, необходимыми для построения систем EDI. Благодаря XML формат сообщений может разработать любой, кто способен составить правильно оформленный документ XML.
Другой областью применения XML в web-документах является определение метасодержимого. Метасодержимое, или сведения о содержимом, позволяет сделать работу поисковых машин гораздо эффективнее. Например, пусть вам нужно найти сообщения о последних событиях в городе Остин (Austin) штата Техас. Тогда вы задаете поисковой машине следующие слова:
Остин Техас новости
Поскольку большинство поисковых машин в настоящее время просто индексируют все содержимое сайта, имеется большая вероятность, что в результате такого поиска вам будет предложено множество не нужных вам документов, найденных по случайному совпадению. Если бы страницы, посвященные новостям из Остина, были написаны в виде структурированных документов XML, их поиск был бы гораздо более целенаправленным — вы могли бы указать, например, следующие параметры:
City = Austin, State = ТХ, StoryType = News.
Использование XML для хранения данных
XML подходит и для создания баз данных. В документе XML используется древовидная структура хранения данных. Хотя по большому счету хранение данных в виде документов XML не слишком эффективно, у такого способа хранения есть свои преимущества. Как и в отношении передачи сообщений, самым большим преимуществом является простота. Древовидная структура — интуитивно понятный и знакомый способ организации данных. Кроме того, почти любой тип древовидной структуры — от реляционных баз данных до объектно-ориентированных баз данных и иерархических структур — может быть представлен с помощью дерева данных XML. Другое существенное преимущество использования XML для хранения данных заключается в том, что XML поддерживает набор символов Unicode. Следовательно, любой символ любого алфавита мира можно включить в документы XML на «законном основании».
Unicode — это официальный путь реализации универсального набора символов (Universal Character Set, UCS), определенного Международной организацией по стандартизации (International Standards Organization, ISO); иначе говоря, это универсальный стандарт кодировки символов для электронного представления текста и его компьютерной обработки. Для преобразования кодировок символов в фактический набор битов используются форматы преобразования UCS, или сокращенно — UTF (UCS Transformation Formats).
Спецификация XML требует, чтобы процессоры XML поддерживали два формата UTF: UTF-8 и UTF-16. В UTF-16 используются два байта для представления каждого символа. В UTF-8 для символов ASCII используется кодировка ASCII, занимающая один байт, а для символов, не входящих в ASCII, — кодировка переменной длины. Формат UTF-8 полезен, если вы хотите поддерживать совместимость с ASCII. Недостатком этого формата является то, что для представления остальных символов (не входящих в ASCII) в нем может потребоваться от 1 до 3 байтов. Если ваш текст в основном состоит из ASCII-символов, UTF-8 позволит вам сэкономить объем памяти. Если же вы используете другие символы, то этот формат, напротив, потребует излишних затрат. По умолчанию в XML применяют формат UTF-8. Кодировка документа определяется в объявлении XML с помощью специального атрибута кодировки (encoding), как показано в следующем примере:
<?xml version="1.0" standalone='no' encochng="UTF-8"?>
В, настоящее время HTML-браузеры, как правило, делают попытки отобразить любой документ, даже содержащий ошибки или использующий очень старую версию HTML. С другой стороны, процессоры XML должны сообщать о неисправимой ошибке в случае, если они встречают ошибку в разметке. Неисправимая ошибка (fatal error) означает, что приложение не может выполняться далее, и выдает сообщение об ошибке. Такая строгая обработка ошибок иногда называется драконовской (draconian error-handling). Хотя этот способ обработки ошибок для тех, кто создает свои документы на HTML или на SGML, может показаться примитивным, в случае с XML он необходим, так как гарантирует, что любые XML-анализаторы будут воспринимать данный документ XML одинаково.
Документ XML, соответствующий правилам синтаксиса XML, называется правильно оформленным (well-formed). Авторы XML включили требование об этом в спецификацию XML, чтобы предотвратить для XML опасность стать жертвой так называемых «войн браузеров». Результатом таких «войн» между Microsoft и Netscape стало то, что теперь при создании HTML-документа авторам приходится постоянно заботиться о совместимости. Если бы такая история приключилась и с языком XML, он стал бы совершенно бесполезным.
Процессор XML (XML processor) — это программный модуль, который обеспечивает доступ приложений к данным, хранящимся в документах XML. Процессоры XML могут быть как проверяющими, так и не проверяющими допустимость (validating) документа. Проверяющий допустимость документа процессор определяет, существует ли для данного XML-документа DTD, и в случае положительного результата — соответствует ли структура документа правилам, указанным в DTD. Не проверяющий допустимость документа процессор должен удостовериться только в том, что документ соответствует правилам XML.
Определение правильно оформленного документа XML
Весь текст XML-документа можно грубо разделить на две категории, символьные данные и разметку. К разметке (markup) относится все, что начинается с символа < и заканчивается символом > или начинается с символа & и заканчивается парой символов &;. Символьные данные (character data) — это все, что не является разметкой. Символьные данные можно подразделить еще на две категории: проверенные символьные данные (Parsed Character DATA, PCDATA) и непроверенные символьные данные (unparsed character data). Как следует из названия, данные PCDATA — это данные, проверенные анализатором XML.
В листинге 1.3 показан пример правильно оформленного документа XML [Beverage — напиток, manufacturer — производитель, nutntion_facts servmg_size= "1 can' — содержание питательных веществ в одной бутылке, calories — калории, amount unit="g" — количество в граммах, fat — жиры, sodium — натрий, carb — углеводы, protein — белки — Примеч перев ]:
Листинг 1.3. Правильно оформленный документ XML
<?xml version="1.0" standalone="yes"?> <beverage> <name>Вода в бутылках</name> <manufacturer> <name>Напитки высшего качества</name> <url href = "http.//www.extragoodbev com"/> </manufacturer> <nutrition_facts serving_size="1 can"> <calories> <amount unit="g">0</amount> </calones> <fat> <amount umt="g">0</amount> </fat> <sodium> <amount unit="g">0</amount> </sodium> <carb> <amount unit="g">0</amount> </carb> <protein> <amount umt="g">0</amount> </protein> </nutntion_facts> </beverage>
В первую очередь в этом листинге следует отметить, что в объявлении XML присутствует атрибут standalone="yes". Это означает, что в данном документе нет определения DTD. Наличие DTD в документах XML не является обязательным. Фактически приложения, в которых задействованы данные XML, часто не включают DTD в целях повышения эффективности в тех случаях, когда структура документа и возможность его многократного использования не являются важными факторами.
Следом за объявлением XML идут элементы. Элемент (element) — это наиболее распространенная форма разметки; он выделяется с помощью угловых скобок (< и >) и описывает тот фрагмент данных, который заключен между скобками > и <. Элемент состоит из открывающего и закрывающего тегов (<beve- rage>...</beverage>, например). Имя элемента называется его общим идентификатором (Generic Identifier, GI) или типом (type). Текст между открывающим и закрывающим тегами называется содержимым (content) элемента. Например, типом следующего элемента является book (книга), а название книги (Java Developer's Guide to XML) — его содержимым:
<book> Java Developer's Guide to XML </book>
Элемент, лишенный содержимого, называется пустым элементом (empty element). Открывающий и закрывающий теги пустого элемента можно объединить в один тег, поместив в его конец косую черту: <br/>. В XML также допускается запись пустого элемента с помощью открывающего и закрывающего тегов, например <br></br>.
Фактически существуют два типа пустых элементов: те, которые заранее определены как пустые и в принципе не могут иметь содержимого, и те, которые оказались пустыми случайно. Чтобы различить эти два типа элементов, рекомендуется использовать пару (открывающий тег, закрывающий тег) для тех элементов, которые не содержат данных, и один тег для тех элементов, которые определены как пустые.
Например, тег HTML <br> не может иметь содержимого, поэтому его нужно записывать как <br/> Если же, к примеру, в вашем документе XML имеется экземпляр элемента, который в данный момент не имеет содержимого, но может получить его в дальнейшем, следует использовать стандартный синтаксис, то есть два тега [Cupboard — шкаф — Примеч перев ]:
<cupboards></cupboards>
У элементов могут быть атрибуты. Атрибут (attribute) — это пара имя-значение, расположенная в открывающем теге элемента. В следующем примере src, width и height являются атрибутами элемента img [Image — изображение, width — ширина, height — высота — Примеч перев ].
<img src = "balloons.gif" width= "100" height = "100" />
Если вы хотите, чтобы ваш код HTML был совместим с XML, то обратите внимание, что тег HTML переноса строки <br> способен причинить немало хлопот. Некоторые браузеры не воспринимают тег <br/>, а пару тегов <br></br> воспринимают как два переноса строки. Для решения этой проблемы поместите пробел между символами br и косой чертой: <br />.
В XML значения атрибутов должны быть заключены в одинарные или двойные кавычки. Список правил, которым должен соответствовать правильно оформленный документ XML, расположен в конце этой лекции.
DTD и допустимость документа XML
DTD, или определение типа документа, — это способ явным образом определить структуру класса документов XML Например, в DTD для перечня животных может быть задано, что для каждого животного нужно указать его имя, вид и характерный звук, который издает это животное DTD для этого перечня может выглядеть так [Animal-list - список животных, animal — животное, name — имя, type — вид, sound — звук. — Примеч перев]:
<!ELEMENT animal-list (ammal)*> <!ELEMENT animal (name,type,sound)> <!ELEMENT name (#PCDATA)> <!ELEMENT type (#PCDATA)> <!ELEMENT sound (#PCDATA)>
Если бы это определение DTD было стандартным зоологическим определением (фактически это не так), любой зоолог мог бы быть уверен, что его данные сможет прочесть любой другой зоолог и что для составления перечня животных все зоологи используют одни и те же правила Документ XML, который соответ- ствует правилам DTD, то есть какому-то конкретному определению, так же как и общим правилам XML, называется правильно оформленным и допустимым. Ниже показан пример правильно оформленного документа XML, который соответствует приведенному выше определению DTD:
<?xml version="l 0" standalone="no"?> <!DOCTYPE animal-list SYSTEM "zoology.dtd"> <animal-list> <animal> <name>Бесси</name> <type>Kopoвa</type> <sound>My-y</sound> </ammal> <animal> <name>Ровер</name> <type>Собака</type> <sound>Гав</sound> </animal> </animal-list>
Слова, набранные в предыдущих примерах только прописными буквами, являются ключевыми словами XML. Это делается не просто из стилистических соображений. Язык XML чувствителен к регистру, поэтому процессор XML выдаст сообщение об ошибке, если в ключевом слове окажется хоть одна строчная буква. Таким образом, в XML слова DOCTYPE и Doctype не более похожи между собой, чем слова DOCTYPE и EGGDROP.
Основным базовым типом объявления в DTD является объявление элемента, <!ELEMENT>. Формат объявления элемента:
<!ELEMENT имя_элемента правило>
Каждый элемент, который используется в документе XML, должен быть определен в DTD. Существует несколько правил, которым нужно следовать при именовании элементов:
имена элементов не должны содержать символа < или >;
имя элемента должно начинаться с буквы или символа подчеркивания. После первой буквы в имени элемента может содержаться любое количество букв, цифр, дефисов, точек или символов подчеркивания;
имена элементов не могут начинаться с последовательности xml (в любой комбинации верхнего или нижнего регистров),
двоеточия запрещены, они применяются только в пространствах имен
В объявлении элемента вы указываете, что может появиться в качестве содержимого этого элемента Если вам нужно объявить элемент, который не должен содержать никаких данных, вы можете использовать тип EMPTY (например, <!ELMENT img EMPTY>).
Хороший пример пустого элемента — элемент HTML img Чтобы этот элемент не нарушал принципа допустимости документа XML, нужно использовать синтаксис, определенный для пустого элемента XML:
<img src="mycar.jpg" />
Если вам нужно, чтобы в элементе были только данные PCDATA, используется следующее объявление:
<!ELEMENT mymemoirs #PCDATA>
Вы можете также указать, какие типы элементов могут появиться в элементе, в каком порядке и в каком количестве, как показано в следующем примере [My memoires — мои воспоминания, title — название, author — автор, philosophizing — философствования, sad_story — грустная история, funny_story — смешная история, lesson — наставление, conclusion — вывод — Примеч nepee ]:
<!ELEMENT mymemoires ( title, author, philosophizing, sad_story, funny_story, lesson, conclusion)>
В данном примере каждый из приведенных типов элементов должен появиться один раз (и только раз) внутри элемента mymemories в том порядке, в котором они перечислены в объявлении.
Элементы, которые появляются в элементе mymemoires, называются его дочерними элементами, а сам элемент mymemoires называется родительским. Каждый элемент может быть дочерним по отношению к любому количеству других элементов в документе. Элементы, разделенные более чем одним уровнем в иерархической системе, называются внуками, правнуками и т. д. (или соответственно дедами, прадедами — в другом направлении). Также можно при описании взаимоотношений между элементами использовать термины «предок» и «потомок».
Вы можете создать более гибкие правила, используя операторы повторяемости. Ниже показаны три оператора:
? — элемент должен встретиться один раз или не встретиться ни разу;
+ — элемент должен встретиться один или более раз;
* — элемент может встретиться любое количество раз или не встретиться вовсе.
Ниже снова приведено объявление элемента mymemoirs, переписанное с использованием операторов повторяемости:
<!ELEMENT mymemoires (title, author, philosophizing+, sad_story*, funny_story*, lesson*, conclusion)>
Вы также можете указать, что некоторые элементы могут появиться как альтернатива другим элементам (то есть что между ними нужно делать выбор) с помощью вертикальной черты (|):
<!ELEMENT mymemoires (title, author, philosophizing+, sad_story*, funny_story*, lesson+| conclusion)>
В этом объявлении элемент mymemoirs может содержать один или более элементов lesson или conclusion, но не оба одновременно. Еще более сложные правила можно создавать с использованием вложенных скобок. В листинге 1.4 показано, как может выглядеть определение mymeroirs.dtd [Paragraph - абзац, letter — письмо. — Примеч. перев. ].
Листинг 1.4. Полная версия определения mymeroirs.dtd
<!ELEMENT mymemoirs (title, author, philosophizing*, sad_story*, funny_story*, (lesson+ | conclusion)*)> <!ELEHENT title (#PCDATA)> <!ELEMENT author (#PCDATA)> <!ELEMENT philosophizing (paragraph)*> <!ELEMENT sad_story (paragraph*, letter*, (lesson | conclusion)*)> <!ELEMENT funny_story (paragraph*, letter*. (lesson | conclusion)*)> <!ELEMENT letter (paragraph)*> <!ELEMENT lesson (paragraph)*> <!ELEMENT conclusion (paragraph)*> <!ELEMENT paragraph (#PCDATA)>
Наименее строгим является правило, которое можно выразить словами: «подходит что угодно». Если вы хотите указать, что в данном элементе могут появиться любые проверенные символьные данные или элементы, вы должны использовать ключевое слово ANY (любой), как показано в следующем примере:
<!ELEMENT mymemoirs ANY>
Такое широкое правило, как элемент типа ANY, не вполне вписывается в строгую структуру XML. Вообще говоря, если вы создаете определение DTD, в котором используется ключевое слово ANY, вы, вероятно, делаете ошибку и вам следует поискать лучший способ определения.
Атрибуты используются для связывания пар имя-значение с элементами. Они определяются с помощью специальных объявлений атрибутов. Формат объявления атрибута в DTD следующий [Target_element — элемент, к которому относится данный атрибут, type — тип, default_value — значение по умолчанию. — Примеч. перев. ]:
<!ATTLIST target_element name type default_value ?>
Атрибуты используются, чтобы сообщить дополнительную информацию об элементах. Иногда бывает трудно решить, является ли некоторый фрагмент данных элементом или атрибутом. Например, два следующих фрагмента XML можно использовать для достижения одной цели:
<dog name = "Snuggles"></dog>
или
<dog> <name>Snuggles</name> </dog>
Хотя выбор остается за вами, имеется несколько общих принципов. Мы расскажем о них в лекции 2, а сейчас вам просто следует запомнить, что этот выбор является непростой задачей для всех программирующих на XML.
Ниже приведены некоторые примеры объявлений атрибутов (несколько позже будет объяснено их значение) [Gender (male|female) — пол (мужской|женский), species — вид, «Cams familiaris» — «собака обыкновенная». — Примеч. перев.]:
<!ATTLIST dog name CDATA #REQUIRED> <!ATTLIST dog gender (male|female) #IMPLIED> <!ATTLIST dog species #FIXED "Canis familiaris">
Существует девять различных типов атрибутов, которые подразделяются на три категории: строковые (string), маркерные (tokenized) и перечислимые (enumerated). Строковые атрибуты определяются с помощью ключевого слова CDATA, которое указывается в качестве типа атрибута, как показано в следующем примере:
<!ATTLIST dog name CDATA>
Значением этой строки может быть любая корректная строка символов.
Существует несколько типов маркерных атрибутов. Наиболее важными являются ID и IDREF. Атрибуты типа ID используются для однозначной идентификации элементов. Атрибут ID должен однозначно идентифицировать тот элемент, в котором он содержится. Например, в следующем объявлении задается обязательный атрибут ID, используемый для идентификации товара:
<iATTLIST product id ID #REQUIRED>
Атрибуты ID и IDREF можно использовать почти так же, как теги якоря А в HTML Значением атрибута IDREF должно быть значение атрибута ID какого-либо другого элемента (то есть они задают перекрестную ссылку). Например, в следующем фрагменте DTD объявляется элемент с атрибутом ID и элемент с атрибутом IDREF, который ссылается на первый элемент [Featured_products — ключевые товары, product_reference — ссылка на товар — Примеч перев]:
<!ELEMENT product (name.description,price)> <!ATTLIST product id ID #REQUIRED> <!ELEMENT featured_products (product_reference)*> <!ELEMENT product_ref (#PCDATA)> <!ATTLIST product_ref link IDREF #IMPLIED>
В файле XML, который использует это DTD, может содержаться фрагмент, подобный следующему:
<product id= "X4343"> <name>rock</name> </product> <featured_products> <product_ref link = "X4343">a rock</product_ref> </featured_products>
В атрибутах перечислимых типов приводится список всех возможных значений этого атрибута. Например, если вы хотите объявить атрибут с именем angle_type для элемента, названного triangle, можно указать возможные значения следующим образом [Triangle — треугольник, angle_type — тип угла, obtuse|acute|nght — тупои|острыи|прямой — Примеч перев]:
<!ATLIST triangle angle_type (obtuse | acute | right)? #REQUIRED>
Существует несколько ключевых слов, которые можно использовать, чтобы указать, должен ли этот атрибут обязательно содержаться в элементе и должен ли он принимать какое-то фиксированное значение. В следующей небольшой таблице приведены эти ключевые слова и указано их значение. Если вы не включите в объявление атрибута ни одно из этих ключевых слов, то по умолчанию будет подразумеваться слово IMPLIED
Ключевое слово |
Определение |
#REQUIRED |
Этот атрибут должен присутствовать в каждом экземпляре элемента |
#IMPLED |
Такой атрибут может не указываться в конкретных экземплярах элемента. Никакого значения для такого атрибута по умолчанию не предусматривается |
#FIXED |
Этот атрибут должен присутствовать в каждом экземпляре элемента и иметь указанное значение |
Объявления сущностей позволяют использовать ссылки на сущность. Ссылка на сущность (entity) — это последовательность символов, которая автоматически подставляется вместо другой последовательности символов. Обычно ссылки на сущность требуются для того, чтобы обозначить символы, которые иначе могут быть приняты за символы разметки. Если вы имели дело с HTML, то, вероятно, сталкивались со ссылками на сущность. Наиболее распространенный тип сущности — это общая сущность (general entity), то есть сущность, которую можно подставить вместо символов в документах XML Формат объявления общей сущности следующий:<
lt;!ENTITY имя_сущности "заменяемые символы">
Ссылки на сущность имеют вид &имя_сущности; В XML имеется пять встроенных сущностей. Их не обязательно объявлять в DTD, хотя в спецификации XML это сделать рекомендуется, чтобы гарантировать возможность взаимодействия с HTML и SGML. Пять встроенных сущностей перечислены в приведенной ниже таблице:
|
Ссылка на сущность |
Числовой заменитель |
Символ |
|
& < > ' " |
& < > ' " |
& < > ' " |
Эти сущности можно объявить следующим образом:
<!ENTITY lt "&,#60,"> <!ENTITY gt ">,"> <!ENTITY amp "&,#38,"> <!ENTITY apos "',"> <!ENTITY quot "",">
Символы < и & в объявлениях It и amp дважды экранируются (escaped), чтобы обеспечить выполнение требований о хорошем оформлении документа XML. Другими словами, символы & и < — это два символа, которые сообщают процессору XML, что следующий текст — это фрагмент разметки. Если эти символы не экранировать дважды в объявлениях сущности, то процессор XML будет интерпретировать их как начало нового фрагмента разметки, не дойдя до конца объявления сущности, и сгенерирует ошибку.
Встроенные ссылки на сущности необходимы для создания документов XML, в которых любой из приведенных символов используется сам по себе, а не как фрагмент разметки Ссылки на общие сущности, которые вы определяете самостоятельно, удобны для присваивания имен последовательностям символов, которые вы часто используете. Например, чтобы объявить ссылку на сущность, представляющую символ торговой марки (™), можно включить следующее объявление:
<!ENTITY tm "™">
Символ торговой марки можно затем вставить в любой документ XML, в котором имеется DTD с этим объявлением. Например:
<product_name> Super Dnnk&tm; </product_name>
Хотя сущности можно использовать в определениях других сущностей, при этом следует постоянно учитывать основной принцип: ссылки не должны быть циклическими.
Ниже приведен пример некорректного определения сущностей:
<!ENTITY myentity "please see &myotherentity, "> <!ENTITY myotherentity "please see &myentity; ">
А это — корректное определение:
<!ENTITY tm "™"> <!ENTITY myentity "I enjoy Super Dnnk&tm; ">
Объявление параметрических сущностей
Также можно объявлять ссылки на сущности, которые в DTD будут заменяться определениями сущности. Такой тип сущностей называется параметрическим. Ссылка на параметрическую сущность (parameter entity) начинается с символа * и не может присутствовать внутри документа XML — только в DTD, где она определяется. Ниже приведен пример использования параметрической сущности:
<!ENTITY % actors " (Joe, Mary, Todd, Bill, Jane)* "> <!ELEMENT dialog %actors;>
Объявление внешних сущностей
Внешние сущности (external entities) — это способ включить внешние файлы в документ XML. Они объявляются следующим образом:
<!ENTITY latest_pnces SYSTEM "http://www.getthepncesofthings.com/today.xml">
После объявления внешней сущности вы можете включить содержимое указанного документа XML в ваш документ, используя ссылку на сущность — в данном случае &latest_prices.
Объявление непроверенных сущностей
Непроверенные сущности (unparsed entities) можно использовать для включения в документ XML данных в формате, отличном от XML. Для определения такой сущности используется ключевое слово NOATA. Например:
<!ENTITY bookcover SYSTEM "http://www.sybex.com/books/xml/javadevguide.gif" NDATA gif>
Непосредственно за ключевым словом NDATA следует ключевое слово нотации (notation data keyword). Это ключевое слово объявляется с помощью объявления нотации. Объявления нотации (notation declarations) предоставляют дополнительную информацию (например, для идентификации) или, как в данном случае, сведения о формате для непроверенных данных. Ключевое слово нотации определяется с помощью объявления <!NOTATION>. Например:
<!NOTATION gif SYSTEM "-//CompuServe//NOTATION Graphics Interchange Format 89a//EN">
Непроверенные символьные данные
Проверенные символьные данные не могут содержать разметку. Следовательно, если вы хотите включить в содержимое элемента символы < или &, вам следует использовать для этого управляющую последовательность. Вы можете заменить эти символы их числовыми заменителями (< и & соответственно) или использовать встроенные в XML ссылки на сущности (&#lt и &#атр соответственно). Имеется еще один вариант, который позволит вам обойтись без управляющей последовательности, — использовать раздел символьных данных (CDATA section), чтобы пометить блок текста как непроверенные символьные данные.
Разделы символьных данных начинаются со строки <![CDATA[ и заканчиваются строкой ]]>. Кроме строки ]]>, содержимое раздела символьных данных не подвергается синтаксическому анализу. Если вы хотите включить пример кода XML в документ XML, вместо того чтобы заменять все символы & и It на < и &атр, можете включить весь блок, содержащий эти символы, в раздел символьных данных. Например:
<example>
Это пример правильно оформленного документа XML:
<!CDATA[ <?xml version="1.0" standalone="yes"?> <beverage> <name>Super-Drink</name> <manufacturer> <name>Extra Good Beverages</name> <url href = "http://www.extrasuperbev.com"/> </raanufacturer> </beverage> ]]> </example>
Комментарии (comments) в XML устроены и функционируют так же, как в
HTML, что видно из следующего примера:
<!-этот текст является комментарием.-->
Комментарии могут располагаться в любом месте документа, но не внутри разметки. Также комментарии не могут употребляться внутри объявлений. Комментарии не являются частью символьных данных и не могут использоваться анализатором XML.
В HTML комментарии часто используются в качестве контейнера текста, который не является частью документа, но доступен для программ. Например, команды CGI и JavaScript в документах HTML часто помещаются внутрь комментариев. Но анализаторы XML могут полностью игнорировать комментарии, поэтому в XML этим приемом не следует увлекаться, для этого имеются снециальные инструкции по обработке.
ВНИМАНИЕ
Мой опыт подсказывает, что попытка сэкономить время на комментариях обычно приводит к тому же эффекту, что перевод часов на летнее время. Так же как за сэкономленный час светлого времени приходиться расплачиватся, несколько дней приспосабливаясь к новому режиму, так и пренебрежение комментариями ради экономии времени впоследствии принесет вам массу проблем.
Инструкции по обработке (Processing Instructions, PI) используются для того, чтобы включить в документ информацию, предназначенную для приложений. Подобно комментариям, инструкции по обработке не считаются частью символьных данных документа. Но в отличие от комментариев, инструкции по обработке не игнорируются анализатором XML, а передаются приложениям.
Инструкции по обработке начинаются с символов <? и заканчиваются символами ?>. Первое слово в PI — это имя того приложения, для которого предназначается данная инструкция. Также можно использовать имя нотации, чтобы связать URI (Uniform Resource Identifier, универсальный идентификатор ресурса) с именем приложения. Следом за идентификационной информацией в PI может содержаться любой тип символьных данных. Ниже приведен пример PI:
<?playsound sounds.mp3?>
Эта инструкция инициирует воспроизведение соответствующим приложением файла формата трЗ.
Хотя определения DTD в настоящее время являются стандартом определений типов документов XML, у них есть несколько серьезных ограничений. Определения DTD были унаследованы от языка SGML, где они были исходно разработаны для определения языков разметки, а не для создания схем баз данных. Самое существенное ограничение определения DTD заключается в том, что оно не обеспечивает достаточного контроля над содержимым элементов. Например, с помощью DTD невозможно указать, что показанный ниже элемент является допустимым [Today's date — сегодняшняя дата — Примеч. перев. ]:
<todaysdate>09/01/2000</todaysdate>
Точно так же нельзя указать, что следующий элемент не является допустимым:
<todaysdate>Яйца, тост, кофе</todaysdate>
Кроме того, вам может потребоваться задать более точные ограничения на количество появлений элемента в документе. С помощью DTD этого сделать не удастся.
В результате этих ограничений, а также из-за того, что XML все больше используется для хранения данных, были предложены некоторые альтернативные варианты. В настоящее время среди них лидирует язык определений схем XML (XML Schema Definition Language, XSD).
На момент написания данного курса XSD находится в стадии разработки. Это означает, что к моменту, когда этот язык получит официальный статус, в нем могут произойти значительные изменения по сравнению с нынешней версией. Со спецификацией XSD можно ознакомиться по адресу www.w3.org/XML/Schema.html.
Назначение схем XML то же, что и DTD: определение классов документов XML. Основная разница между ними заключается в том, что в схемах XML все элементы подразделяются на два типа: простые и сложные.
Элементы, которые содержат другие элементы или атрибуты наряду с символьными данными, относятся к типу сложных (complex), а те элементы, которые содержат только символьные данные, называются простыми (simple) элементами. Атрибуты всегда имеют простой тип. В листинге 1.5 показана схема XML для каталога товаров. В листинге 1.6 приведен документ XML, использующий эту схему [On sale date — дата начала продаж, quantity in stock — количество имеющегося в наличии товара. — Примеч. перев. ].
Листинг 1.5. Схема для каталога (catalog.xsd)
<xsd:schema xmlns:xsd="http://www.w3.org/1999/XMLSchema">
<xsd:element name="Catalog" type="CatalogType"/>
<xsd:complexType name="CatalogType">
<xsd:element name="product" type="ProductType"/>
<xsd:attribute name="onSaleDate" type="xsd:date"/>
<xsd:attribute name="partNum" type="Sku"/>
</xsd:complexType>
<xsd:complexType name="ProductType">
<xsd:element name="productName" type="xsd:string"/>
<xsd:element name="quantity_in_stock">
<xsd:simpleType base="xsd:positivelnteger">
<xsd:maxExclusive value="500"/>
</xsd:simpleType>
</xsd:element>
<xsd:element name="pnce" type="xsd'decimal"/>
<xsd:element name="description" type="xsd:string" minOccurs="0"/>
</xsd:complexType>
<xsd:simpleType name="Sku" base="xsd:string">
<xsd:pat tern value="\[A-Z]{3}-[A-Z]{3}d{3}"/>
</xsd:simpleType>
</xsd:schema>
<catalog>
<product partNum="ABC-PR0336" onSaleDate="12/12/2004">
<productName>BigSoft Xtreminator 3.36</productName>
<quantity_in_stock>20</quantity_in_stock >
<price>195.99</price>
<description>Managing your life has never been so easy.</description>
</product>
<product partNura="ABC-PR0343" onSaleDate="12/12/2004">
<productName>E-Dev ProntoWorks</productName>
<quanti ty_in_stock>35</quantity_in_stock >
<price>299.99</price>
<description>The premier integrated rapid e-development suite for busy e-professionals.</description>
</product>
</catalog>
Элементы сложного типа определяются с помощью элемента compl exType. Как было уже сказано, элементы сложного типа содержат другие элементы и атрибуты. Элементы и атрибуты, содержащиеся внутри сложных элементов, определяются с помощью элементов element и attribute соответственно. Например, в листинге 1.5 элемент product определен как элемент сложного типа. Внутри определения типа ProductType определяются пять элементов: productName, quantity_in_stock, price, comment и partNum.
Элементы простого типа не имеют атрибутов и не содержат других элементов. В XSD имеется ряд встроенных простых типов, в том числе string, binary, boolean, double, float и т. д. На основе встроенных простых типов можно сконструировать дополнительные простые типы. В частности, в предыдущем примере определяется простой тип Sku, сконструированный на основании типа string.
Процесс конструирования новых простых типов из уже существующих называется ограничением (restriction). Обратите внимание, что в определении нового типа Sku используется регулярное выражение, задающее шаблон, которому должно соответствовать содержимое любого элемента или атрибута данного типа.
В схемах XSD имеются гораздо более гибкие операторы повторяемости, чем в DTD. Как говорилось выше, в DTD можно указать, что элемент должен встретиться ноль, один, один или более или любое количество раз. В дополнение к этим операторам схема XML позволяет задавать минимальное и максимальное количество повторов одного элемента в документе, его значение или диапазон значений и т. д.
Создание таблиц стилей с использованием XSL
Расширяемый язык таблиц стилей (Extensible Stylesheet Language, XSL), как следует из его названия, — это язык для конструирования таблиц стилей. Таблицы стилей XSL используются для описания внешнего вида документов XML, предназначенных для чтения людьми.
Например, web-дизайнер может создать таблицу стилей для XML-каталога товаров. В этой таблице стилей может быть указано, какие шрифты, размеры шрифтов и границ нужно использовать в документе, что фактически выполняется, когда сам документ объединяется с таблицей стилей с помощью процессора XSL.
Применение таблицы стилей к документу процессор таблиц стилей осуществляет в два этапа. Первый этап — трансформация дерева (tree transformation). Вы можете, например, написать таблицу стилей, которая расположит товары в вашем каталоге в алфавитном порядке или пронумерует их, прежде чем отобразить. Трансформация дерева позволяет также перемещать данные XML и выполнять вычисления с этими данными.
Второй этап — форматирование (formatting). Форматирование фактически представляет собой процесс задания стиля отображения данных, размеров шрифтов, разрывов страниц и т. п.
Спецификация XSL содержит три различных языка, предназначенных для осуществления этих двух задач:
XML Path Language (XPath) — язык для создания ссылок на различные части документа XML;
XSL Transformations (XSLT) — язык, предназначенный для генерации дерева документа;
Extensible Stylesheet Language (XSL) — XSLT плюс описание набора объектов форматирования и свойств форматирования.
Предположим, что у вас имеется документ XML, описывающий вашу музыкальную библиотеку, например такой, как представленный в листинге 1.7.
Листинг 1.7. Пример каталога музыкальной библиотеки (MyMusic.xml)
<?xml version="l.0"?> <library> <cd> <title>Just Singin' Along</title> <artist>The Happy Guys</artist> <description> A lovely collection of songs that the whole family can sing right along with. </description> <song><title>I'm Really Fine</title></song> <song><title>Can't Stop Grinnin'</title></song> <song><title>Things Are Swell</title></song> <purchase_date>2/23/1954</purchase_date> </cd> <cd> <title> It's Dot Com Enough for Me: Songs From Silicon Somewhere </title> <artist>The Nettizens</artist> <description> A collection of the best folk music from Internet companies. </description> <song><title>My B2B Is B-R-0-K-E</title></song> <song><title>Workin' in a Cubicle</title></song> <song><title>Killer Content Strategy</title></song> <song><title> She Took the Bricks. I Got the Clicks </title></song> <purcnase_date>7/12/2000</purchase_date> </cd> </library>
Допустим, вы хотите создать и напечатать список всего, что имеется в вашей библиотеке. Один из способов сделать это заключается в том, чтобы применить к документу MyMusic.xml таблицу стилей, которая трансформирует его в формат HTML. В листинге 1.8 приводится такая таблица стилей.
Листинг 1.8. Таблица стилей, генерирующая документ HTML (CDstyle.xsl)
<?xml version="l.0"?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/TR/WD-xsl"> <xsl:template match="/"> <TABLE STYLE="border:lpx solid black; width:300px"> <TR STYLE="font-size:10pt; font-family:Verdana; font weight:bold; text-decoration:underline"> <TD>Title</TD> <TD>Artist</TD> </TR> <xsl:for-each select="library/cd"> <TR STYLE="font-family:Verdana; font-size:12pt; padding:0px 6px"> <TD><xsl lvalue-of select=" title"/></TD> <TD><xsl:value-of select="artist"/></TD> </TR> </xsl:for-each> </TABLE> </xsl:template> </xsl:stylesheet>
Связать таблицы стилей с документом XML можно с помощью инструкции по обработке. Например:
<?xml-stylesheet href="CDstyle.xsl" type="text/xsl"?>
Также вы можете использовать каскадные таблицы стилей (Cascading Style Sheets, CSS) для применения определенного формата к данным XML. В этом случае вы должны связать документ с таблицей стилей с помощью инструкции по обработке, подобной следующей:
<?xml-stylesheet href="CDstyle.ess" type="text/css"?>
В листинге 1.8 показан базовый пример трансформации данных XML с помощью стандартной таблицы стилей. XSLT находит данные, которые соответствуют некоторому образцу, и вставляет их в нужное место шаблона. Поиск соответствия с образцом — очень важная часть XSL. Посмотрим на образец, который применялся во второй части нашего примера:
<xsl:for-each selееt="library/cd">
Эта строка задает цикл по всем экземплярам элемента cd внутри элемента library. Если вы хотите создать разделенный запятыми список всех песен на каждом диске (каждому диску соответствует свой экземпляр элемента cd), вы можете задать еще один цикл внутри приведенного выше цикла, как показано в следующем примере:
... <xsl:for-each select="library/cd"> <TR STYLE="font-family:Verdana; font-size:12pt; padding:0px 6px"> <TD><xsllvalue-of select="title"/></TD> <TD><xsl:value-of select="artist"/></TD> <TD> <xsl:for-each select="song"> "<xsl :value-of select="title"/>" <xsl:if test="context()[not(end())]">, </xsl:if> </xsl: for-each> </TD> </TR> </xsl:for-each> ...
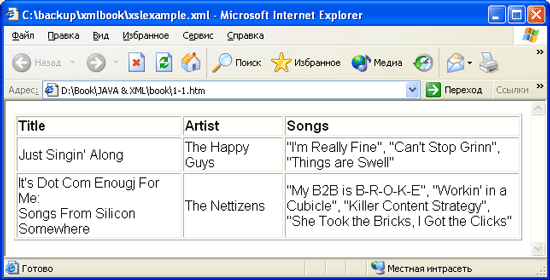
Если получившийся документ XML открыть в браузере, поддерживающем XSL, то он будет выглядеть примерно так, как показано на рис. 1.1.
Рис. 1.1. Результат применения таблицы CDstyle.xsl к файлу MyMusic.xml
Использование XML в приложениях
В данном курсе мы будем использовать базу данных XML, предназначенную для хранения каталога товаров, которыми торгует вымышленный электронный магазин. Хотя мы предполагаем, что доступ к данным XML непосредственно из приложений осуществляется достаточно быстро, все же для повышения эффективности можно импортировать XML-базу данных приложения в реляционную базу данных. В настоящее время все поставщики баз данных предлагают средства (или планируют сделать это), позволяющие передавать данные между реляционной базой данных и документами XML, и ряд других вспомогательных инструментальных средств. Данные можно извлекать из любой базы данных и преобразовывать в данные XML, которые используются в приложении, при этом не приходится модифицировать само приложение. Вероятно, в этом и заключается основное преимущество создания приложений, рассчитанных на данные XML: XML — это стандарт, в который могут быть преобразованы данные любого типа, следовательно, приложение гарантированно сможет работать в будущем с данными любого нового типа.
Теперь, когда вы убедились в том, что XML — это правильный выбор для создания каталогов, рассмотрим два различных подхода к написанию программ на Java, предназначенных для работы с XML.
Язык SGML был ориентирован на документ как на единое целое, поэтому нет ничего удивительного в том, что и в отношении XML сначала использовался подход, связанный с объектной моделью документа (Document Object Model, DOM). Любая обработка документа в соответствии с моделью DOM предполагает, что документ прошел синтаксический анализ и представлен в памяти в виде древовидной структуры, каждая часть которой одинаково доступна. Этот подход символически иллюстрирует рис. 1.2.
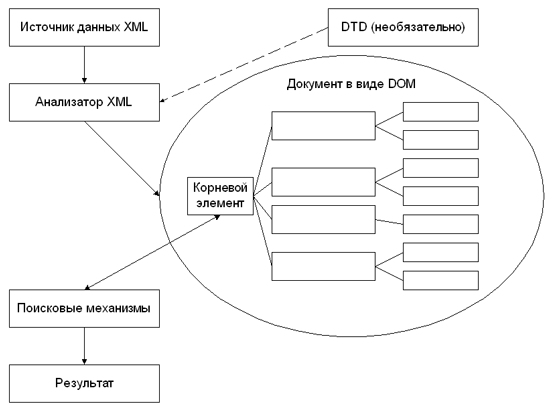
Рис. 1.2. Модель программирования DOM
Когда люди начали программировать в соответствии с моделью DOM, быстро выяснилось, что это не очень удобно — приходилось строить объектную модель всего документа, даже если нужно было отобрать всего лишь несколько элементов. Кроме того, этот способ требует больших ресурсов памяти, что может сделать его использование затруднительным, если не сказать невозможным. В результате возникла необходимость в разработке другого способа, который получил название SAX (Simplified API for XML — упрощенный интерфейс прикладного программирования для XML) И DOM, и SAX представляют собой, таким образом, интерфейсы прикладного программирования, которые были реализованы как на Java, так и на других языках.
Как показано на рис. 1.3, анализатор SAX осуществляет один проход по документу XML, сообщая о результатах анализа путем вызова различных методов из кода вашего приложения. В документации SAX есть термин событие (event): событие происходит, когда анализатор идентифицирует элемент в документе XML, поэтому указанные методы называются обработчиками событий (event handlers). Когда анализатор достигает конца документа, в памяти остается только то, что было сохранено вашим приложением.
Как было сказано ранее и как показано на рис. 1.2 и 1.3, использование DTD не является обязательным в XML.
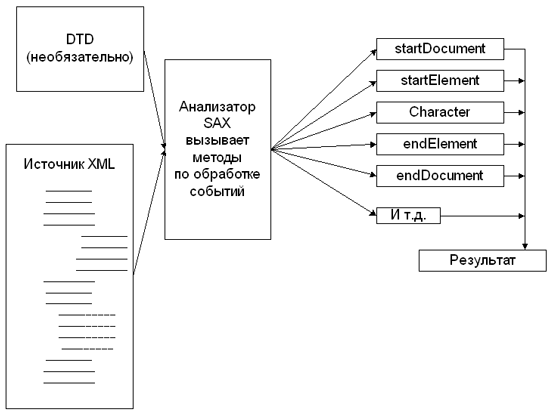
Рис. 1.3. Модель программирования SAX
Для программирования сервлетов и JSP (JavaServer Pages) полезными могут оказаться обе модели, что демонстрируют приведенные ниже примеры. Сначала рассмотрим инструментальные средства Java для «первого уровня» DOM и для версии SAX 1.0. На момент написания курса версия SAX 2.O. и второй уровень DOM находились в разработке, но ко времени, когда курс будет опубликован, вероятно, эти новые версии уже будут доступны.
Программирование на основе DOM
Окончательная версия API для работы с объектной моделью документа находится в пакете org.w3c.dom, одобренном Консорциумом W3C. Этот интерфейс API включает в себя определения интерфейсов и один класс исключений. Основная идея заключается в том, что документ XML преобразуется в документ DOM, состоящий из объектов Java, которые реализуют эти интерфейсы. Любая часть документа становится объектом, а связи между объектами отражают иерархическую структуру документа.
Анализ XML для создания DOM
С точки зрения программиста, нет ничего проще, чем создать документ DOM, поскольку вся работа фактически делается анализатором. Все, что должен сделать программист, — это создать входной поток, выбрать анализатор и отойти в сторону. В листинге 1.9 показан шаблон метода, который считывает данные из файла с помощью утилит из пакета com.sun.xml.parser и возвращает объект com.sun.xml.tree.XmlDocument Класс Xml Document реализует интерфейс Document, как указано в спецификации W3C.
Если вы используете утилиты других пакетов, то конкретные имена могут измениться, но общий принцип останется прежним. В этом конкретном примере используются классы интерфейса прикладных программ Java для анализа XML (Java API for XML Parsing, JAXP), предложенные компанией Sun, которые в настоящее время используются в ядре сервлетов (servlet engine) Tomcat.
За последние годы было создано множество различных анализаторов XML, но только небольшое их число полностью соответствует рекомендациям DOM W3C. Последние тесты на совместимость показали, что наиболее высокий рейтинг в этом отношении имеет анализатор Sun.
Листинг 1.9. Шаблон метода создания объекта XmlDocument
public XmlDocument exampleDOM(String src ) {
File xmlFile = new File( src ) ;
try {
InputSource input = Resolver create!nputSource( xmlFile );
// ... флажок "false" указывает, что проверка не нужна
XmlDocument doc = XmlDocument.createXmlDocument (input, false);
return doc ;
}catch(SAXParseException spe ){
// здесь обрабатываются исключения, возникшие при
// синтаксическом анализе
}catch( SAXException se ){
// здесь обрабатываются другие исключения SAX
}catch( IOException ie ){
// здесь обрабатываются исключения ввода-вывода
}
return null ;
}
Имея в памяти объектную модель документа, вы можете манипулировать ею с помощью методов интерфейса DOM из пакета org.w3c.dom, а также с помощью дополнительных инструментальных средств.
Программирование на основе SAX
Основные этапы обработки документа XML на основе SAX можно сформулировать следующим образом.
Создание одного или нескольких пользовательских классов для обработки событий анализатора SAX.
Создание объекта, который обеспечивает прием входного потока символов.
Создание анализатора на основе одного из пакетов инструментальных средств.
Присоединение классов, обрабатывающих события, к анализатору.
Присоединение входного потока к анализатору, начало анализа.
Обработка всех событий в пользовательских классах, которая позволяет записать нужные данные, отследить ошибки и т. д.
Как видно, обработка документов XML в модели SAX подчиняется совсем другой идеологии, чем в модели DOM. Выбор одного из этих двух подходов для конкретного приложения — самый важный выбор из тех, которые вам предстоит сделать. В табл. 1.1 приведены основные критерии, которые следует учитывать в данном вопросе.
Таблица 1.1. Сравнение программирования на основе DOM и SAX
|
Фактор |
DOM |
SAX |
|
Требования к ресурсам памяти |
Могут оказаться довольно высокими |
Пропорциональны количеству элементов, которые требуется сохранить в памяти |
| Скорость первой обработки | Невысокая, так как анализируются все элементы | Высокая, особенно если нужные элементы легко локализуются |
| Скорость повторной обработки | Сравнительно высокая, так как все элементы уже находятся в памяти | Сравнительно невысокая, так как каждый поиск подразумевает новый проход анализатора по документу |
| Допустимость модификации | Очень высокая | Ограничена необходимостью создания нового документа XML для каждого прохода анализатора |
Краткий справочник по правилам XML
Этот раздел можно считать кратким справочником по самым основным правилам XML. Полную спецификацию XML можно найти по адресу www.w3c.org.
Требования к правильно оформленному документу XML
Каждый элемент должен иметь открывающий и закрывающий теги, за исключением пустых элементов, для которых предусмотрен специальный синтаксис пустого элемента.
Имя открывающего тега должно совпадать с именем закрывающего тега. Заметим, что язык XML чувствителен к регистру. Варианты:
Элементы должны быть правильно вложены друг в друга. Варианты:
Имена элементов не должны содержать символа < или > и должны начинаться с буквы или символа подчеркивания
Имена элементов не могут начинаться с символов xml (в любой комбинации верхнего и нижнего регистров)
В именах элементов не должно содержаться двоеточия, за исключением пространств имен.
Атрибуты не должны появляться более одного раза в открывающем теге или в теге пустого элемента.
Значения атрибутов должны быть заключены в кавычки.
В значениях атрибутов не должны содержаться прямые или непрямые ссылки на внешние сущности.
Текст, подставляемый вместо любой сущности, на которую имеется прямая или косвенная ссылка, являющаяся значением некоторого атрибута, не должен содержать символа < (это не относится к сущности <).
Ниже мы приводим общие сведения об элементах XML, в том числе о синтаксических правилах, регламентирующих применение элементов и их объявление.
Примеры:
<tag/> <tag attribute="value"/> <tag attribute="value"> какой-нибудь текст </tag>
Синтаксис:
<!ELEMENT имя_элемента правило>
|
Тип элемента |
Пример объявления |
|
EMPTY #PCDATA ANY Mixed Children |
<! ELEMENT url EMPTY> <! ELEMENT name #PCDATA> <! ELEMENT contacts ANY> <! ELEMENT list (#PCDATA | item)*> <!ELEMENT co-worker (title, name, address)> |
Ниже мы приводим формат объявления атрибутов. Сюда относятся синтаксис объявления атрибутов, их типы и ключевые слова, определяющие, является ли атрибут обязательным, и т. п.
Синтаксис объявления атрибута:
<!ATTLIST target_element name type default_value ?>
|
Тип |
Атрибут |
Пример объявления |
|
Строковый |
CDATA |
<!ATTLIST image url CDATA> |
| Маркерный |
ID
IDREF IDREFS ENTITY ENTITIES NMTOKEN NMTOKENS |
<!ATTLIST id ID #REQUIRED> |
|
Перечислимый |
<!ATTLIST 11st type (ordered | bullet) "ordered" ?> |
|
Ключевое члово |
Описание |
|
#REQUIRED |
Этот атрибут должен присутствовать в каждом экземпляре элемента |
| #IMPLIED | Такой атрибут может не указываться в конкретных экземплярах элемента. Никакого значения для такого атрибута по умолчанию не предусматривается |
| #FIXED | Этот атрибут должен присутствовать в каждом экземпляре элемента и иметь указанное значение |
Ниже мы приводим краткие сведения об использовании и объявлении сущностей. Сюда относятся примеры применения сущностей и синтаксические правила, регламентирующие их объявление.
Примеры:
Copyright © 2001 Sybex Inc/ while( a %lt; b) // для представления кода Java в HTML
Синтаксис:
<!ENTITY имя "заменяемые символы">
|
Тип сущности |
Пример |
Описание |
|
Общая |
<! ENTITY publisher "Sybex"> |
Может использоваться только в данных XML |
| Параметрическая | <! ENTITY *cdata "#CDATA"> | Может использоваться только в DTD |
| Внешняя | <! ENTITY stockquotes SYSTEM "quotes. xml"> | Используется для включения внешних файлов XML |
| Непроверенная | <! ENTITY picture SYSTEM "picture.jpg" NDATA jpg> | Используется для включения файлов, не являющихся файлами XML |
|
|
