Окружающий нас мир насыщен информацией — разнообразные потоки данных окружают нас, захватывая в поле своего действия, лишая правильного восприятия действительности. Не будет преувеличением сказать, что информация становится частью действительности и нашего сознания.
Без адекватных технологий анализа данных человек оказывается беспомощным в жестокой информационной среде и скорее напоминает броуновскую частицу, испытывающую жестокие удары со стороны и не имеющую возможности рационально принять решение.
Статистика позволяет компактно описать данные, понять их структуру, провести классификацию, увидеть закономерности в хаосе случайных явлений. Удивительно, что даже простейшие методы визуального и разведочного анализа данных позволяют существенно прояснить сложную ситуацию, первоначально поражающую нагромождением цифр.
Особенность этой книги заключается в том, что в ней всесторонне, с подробными примерами описано применение разнообразных методов анализа данных.
Вообще, наша идея состояла в том, чтобы вывалить из мешка различные методы, написав своего рода популярную энциклопедию всевозможных методов анализа данных, и позволить пользователю, применяя систему STATISTICA, свободно экспериментировать с этими методами, работая как с собственными данными, так и с предлагаемыми нами. Мы дополнили книгу компакт-диском, на котором записаны демо-версии системы STATISTICA, файлы данных, материалы курсов и многое другое. Запустите диск и одновременно читайте книгу — это позволит всесторонне освоить технологии анализа данных.
Мы описываем как классические методы анализа, так и современные, включая нейронные сети, в частности, чрезвычайно интересный анализ соответствий, позволяющий исследовать сложные многомерные таблицы, возникающие в экономике, маркетинге, медицине и других областях. Даже традиционные методы мы стараемся рассмотреть под новым углом зрения, акцентируя внимание на нестандартных приложениях.
Визуальные методы анализа данных чрезвычайно важны и мы посвящаем им несколько глав. Многие явления, остающиеся за кадром, становятся отчетливыми, если найти подходящее графическое представление.
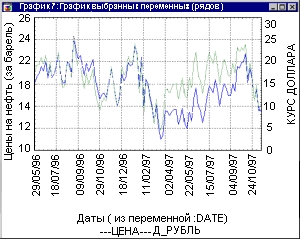
Например, на графике, приведенном ниже, мы видим два временных ряда: цены на нефть в долларах за баррель и курс доллара по отношению к рублю за несколько лет. Рассматривая график, вы видите, какие тенденции имеются в данных. Конечно, это простейший вариант графического представления!
Далее вы можете перейти к построению более сложных моделей, однако первые закономерности, найденные визуально, сохранятся и в углубленных моделях. Именно поэтому мы уделяем визуализации столь большое внимание.
Множество практических примеров рассмотрено в данной книге. Чтобы сделать изложение систематическим, мы начинаем с простейших понятий — которых, к счастью, не так и много — и учимся говорить на языке анализа данных, рассматривая простые и понятные всем примеры, постепенно развивая их до сложных задач.
Мы не следим тщательно за строгим обоснованием методов, а просто говорим: имеются такие-то методы и там-то их применение принесло успех. Если вы желаете, попробуйте применить эти методы для анализа собственных данных и, быть может, получите обнадеживающий результат.
Но что значит обнадеживающий результат? Если из множества возможных вариантов действий вы с большей вероятностью, чем ваш противник, выбираете правильный вариант или добиваетесь более ясного понимания действительности, «снимая» случайность, то, очевидно, вы находитесь в лучшей ситуации, чем ранее, когда полагались на волю случая и отдавали себя во власть неопределенности.
Итак, разнообразие методов и обилие примеров — вот основная идея книги, которая по этой причине может быть названа энциклопедией методов анализа и областей их применения. Строгое обоснование методов — не наша цель, так как многие интуитивно понятные методы и родились из решения практических задач и лишь позднее получили строгое математическое обоснование, что никак не уменьшает их прагматической ценности.
Для широкого круга пользователей полезно знать, где и какие методы применялись на практике и когда привели к успеху, и мы хотим максимально развить интуитивное представление пользователя об анализе данных, не предполагая наличия у него специальной подготовки. Таким образом, мы хотим познакомить читателя с культурой анализа данных.
В качестве источника данных мы используем, например, Интернет и иллюстрируем применение методов анализа на этих данных. Популярность Интернет общеизвестна, но что нового может дать анализ данных в этой области? Вот один из примеров. Вы производите поиск по различным ключевым словам в некоторых поисковых системах и отмечаете количество ссылок, спрашивается, различаются системы поиска или нет? Именно с такого рода примерами мы будем иметь дело.
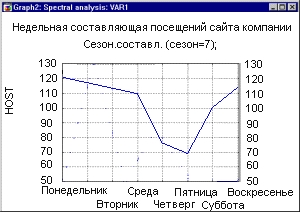
Ниже приведены графики количества посетителей сайта. Спрашивается, как строго доказать, что реклама имела успех? Правило 3-сигма позволяет оценить эффективность рекламной кампании и, следовательно, работу менеджера по рекламе.

График спектральной плотности показывает, что в данных имеется отчетливая периодичность с лагом 7, так как пик спектральной плотности приходится на 7 дней.
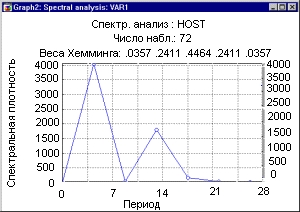
График недельной составляющей позволяет увидеть, как изменяется (в процентах) число посещений сайта в зависимости от дня недели. Исследуя разность нагрузки Интернет в рабочие и выходные дни, можно оценить долю «домашних» подключений к сети.
Подобного рода закономерности возникают в самых различных областях: в торговле, бизнесе, промышленности, — важно уметь находить их и использовать в своих целях.
Прогнозирование: представьте, вы имеете данные ежемесячных продаж. Вам нужно спрогнозировать продажи на текущий месяц. Как вам поступить? Вполне разумный подход состоит в том, чтобы взять в качестве прогноза продажи предыдущего месяца. Далее вы можете развить этот подход, использовать для прогноза продажи нескольких предыдущих месяцев, усреднить их, например, с разными весами. Как крайний случай, вы усредняете все продажи. Так из вполне естественных рассуждений возникает метод скользящего среднего.
Если вы хотите учесть сезонный фактор, например прогнозировать продажи в январе текущего года, используя информацию о продажах в январе предыдущего года, то следует использовать сезонное скользящее среднее. Если вы хотите учесть все продажи, но с разными весами, то используется экспоненциальное сглаживание (exponential smoothing) с очевидными вариациями: сезонное или несезонное, с трендом (отчетливо выраженной тенденцией) или без тренда. Обобщение модели скользящего среднего приводит к моделям АРПСС — авторегрессии и проинтегрированного скользящего среднего или, в английской терминологии, ARIMA (Autoregressive Integrated Moving Average).
Какую из этих моделей выбрать? Ответ: запустите STATISTICA и поэкспериментируйте с различными моделями. Разбейте данные на 2 группы — используйте данные второй группы для проверки качества прогноза (для проверки можно оставить, например, пятую часть ряда). STATISTICA позволяет экспериментировать с методами анализа, а это огромное достижение!
В тех ситуациях, когда классические методы не работают, можно испытать нейронные сети. Мы рассматриваем их как полезный инструмент анализа, имеющий свои достоинства и ограничения (см. главу 17).
Вот типичный пример. Рассмотрим данные о розничных продажах бензина в США (данные доступны на сайте www.economagic.com в разделе Census Bureau: Retail Sales by Kind of Business). В численном виде данные приведены в приложении 1. Прогнозирование тех же данных с помощью нейронных сетей описано в приложении 2.
На графике данные имеют вид:
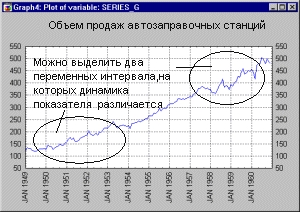
С помощью графика можно выделить два временных интервала, на которых поведение ряда существенно различается.
Технологии прогнозирования, описанные в книге: Боровиков В. П., Ивченко Г. И. «Прогнозирование в системе STAT1STICA в среде Windows», M.: Финансы и статистика, 2000, позволяют построить прогноз продаж бензина с помощью моделей ARIMA — АРПСС (авторегрессии и проинтегрированного скользящего среднего).

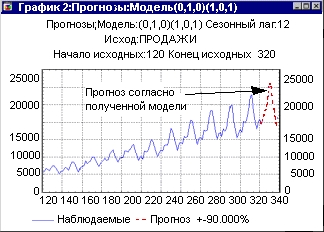
В качестве альтернативы можно использовать экспоненциальное сглаживание. На следующих рисунках показан прогноз, построенный с помощью экспоненциального сглаживания, который сравнивается с прогнозом на основе модели ARIMA — АРПСС. Мы использовали часть данных для построения модели, а на оставшихся данных сравнивали прогнозы.
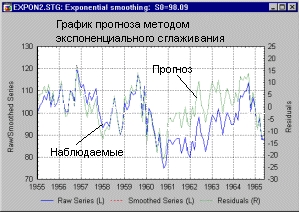
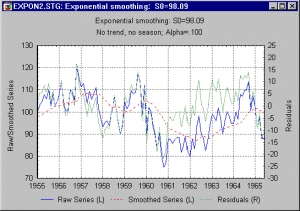
Хотя в книге мы обращаем внимание на тонкие моменты исследования, более важная наша задача — показать читателям, на какие результаты вообще можно рассчитывать, применяя данный метод и как избежать явных ошибок.
Итак, нам хотелось бы донести до читателя клише анализа данных: от визуального анализа данных, описания данных с помощью простейших дескриптивных статистик до сложных продвинутых методов, позволяющих понять структуру данных, классифицировать данные и оценить связи между ними.
Ранее, до появления персональных компьютеров, анализ реальных данных был чрезвычайно сложным, требующим больших интеллектуальных усилий делом, и ни о каких технологиях не могло быть и речи. Это было дело небольшого круга посвященных.
Благодаря таким системам, как STATISTICA, открылся путь к новым технологиям анализа данных, максимально сокращающий рутинные процедуры и делая анализ максимально доступным для широкого круга пользователей.
На следующих рисунках показан типичный диалог в STATISTICA.
Если раньше каждый шаг исследований: представление данных, перевод их в нужный формат, проверка, группировка, сортировка, сжатие, графическая интерпретация, запуск программы обработки, задание параметров анализа, просмотр результатов, был трудной задачей, то теперь достаточно двух-трех щелчков мыши, чтобы огромные объемы данных чрезвычайно быстро преобразовались, обработались и появились на экране в виде графиков, диаграмм, таблиц, статистик критериев.
Наша точка зрения состоит в том. что при современном развитии компьютерных технологий начальные этапы анализа данных, визуальный и описательный анализ, а также пробное применение сложных методов вполне могут проводить специалисты из конкретных областей — те, кому результаты анализа в первую очередь нужны и кто располагает реальными данными, «вжился» в них.
Представьте, вы анализируете некоторый рынок, то есть множество товаров, цен, продавцов, покупателей и т. д. Прежде всего ваша задача состоит в том, чтобы разумно описать рынок, например рынок недвижимости, — ввести данные, провести визуальный анализ, сгруппировать данные и найти некоторые первые устойчивые закономерности в организации рынка. Уже первые шаги такого анализа показывают, что на цены, в основном, влияет тип квартиры и район. Остальные характеристики менее значимы. Так, первый этаж снижает стоимость квартиры примерно на 1/10, последний — в 2-3 раза меньше. Отсутствие балкона или лоджии также снижает стоимость (примерно на ту же величину, что последний этаж). Наличие или отсутствие телефона практически не влияет на цену, но продать телефонизированную квартиру значительно проще. В общем, разница цен между кирпичными и панельными домами невелика, скажем, процентов 5, — имейте в виду, что данный пример во многом искусственный, — но ближе к центру больше ценятся кирпичные дома и т. д.
Проведение такого рода описательного анализа, построение понятных графиков и ответы на разнообразные простые вопросы типа: «А что у нас по пятницам?» и т. д. — это первый естественный шаг всякого исследования. При этом используются самые простые описательные статистики, графики, группировка данных...
Далее, после разбиения жилья на однородные группы, возникают более сложные аналитические вопросы, например, как влияет на стоимость типового жилья появление элитных квартир? Или как повлияют большие продажи муниципального жилья на цены? Как зависит спрос от сезонной составляющей? Как зависят продажи от текущего строительства в городе? Мы рассмотрели рынок недвижимости, но точно такие же методы применяются при исследовании других рынков: финансового, фондовых, товарных, сырьевых...
Здесь нужно перейти от описательного анализа к более сложным статистическим моделям, например, регрессионным.
Любой рынок по существу своему многомерен, то есть описывается многими параметрами, поэтому необходимо применять многомерные методы, например факторный анализ, чтобы понять, какие факторы в основном влияют на цену квартиры, многомерное шкалирование, деревья классификации и т. д. Для анализа динамики цен и прогнозирования изменения цен в зависимости от времени применяются методы анализа временных рядов.
Очень многие сложные задачи успешно решаются довольно простыми статистическими методами. Например, известно, что краткосрочная финансовая политика США строится на основе модели линейной регрессии с учетом сезонной информации о финансах. Однако применение даже простых методов приносит эффект.
В бурно развивающейся отрасли средств телекоммуникации важно решать следующие задачи:
В принципе задача рационального выбора места строительства станции может быть решена с помощью методов множественной (многомерной) регрессии. Она вполне аналогична разбираемой нами задачи о строительстве атомной станции.
Оценка колебаний нагрузки сети в зависимости от дней недели решается с помощью метода сезонной декомпозиции. Для прогнозирования нагрузки в сети можно использовать модели авторегрессии и проинтегрированного скользящего среднего.
Регрессионные модели также используются для процентного выражения прибыли магазина определенного типа в текущем году. В качестве регрессоров используются величина спроса, качество товаров, рост доходов и др. (см. например, статью Thurik A. R. (1985). Retail margins during recession and growth, Econ. Lett., 17, № 3, p. 281-284, где даются расчеты по данным реальных наблюдений и финансово-экономический анализ результатов).
Регрессия эффективно применяется для анализа экономической активности в различных регионах.
Такая модель, например, с успехом применялась для анализа реальных данных в Швеции. Степень вариации или изменчивости параметров модели для различных муниципалитетов интерпретировалась как пространственная изменчивость, а для эффективного оценивания неизвестных параметров принимались некоторые априорные допущения о величине их изменения, см. например, работу Westlund Anders H. (1986) On econometric analysis of regional structural variability, Adv. Modell. And Simul., 5, № 3, p. 25-44.
Интересные результаты регрессии для прогнозирования доходов телевизионных компаний в зависимости от трех факторов: числа продаваемых телевизоров, общего числа рекламных объявлений и правительственных мер, ограничивающих некоторую рекламу (например, рекламу сигарет), можно также получить с помощью регрессионных моделей и т. д.
Мы употребили слово регрессия, которое в анализе данных имеет почти магическое значение и, возможно, отпугивает своей странностью многих.
Но что такое регрессия? В действительности, регрессия — это очень просто, и если отбросить статистический жаргон, включающий такое малопонятное слово, как «регрессия», то вы легко поймете, в чем здесь дело.
Представьте, вы изучаете годовой доход телевизионных компаний. «От чего он может зависеть?» — спрашиваете вы себя и перечисляете следующие факторы, от которых зависит доход: число зрителей, смотрящих ТВ, затраты на рекламу в год и некоторые другие.
Тогда регрессия — это просто уравнение, в котором в левой части стоит интересующая вас переменная, например годовой доход, а в правой число зрителей, умноженное на некоторый коэффициент, плюс затраты на рекламу, умноженные на другой коэффициент, плюс другие параметры. То есть вы имеете уравнение:
ДОХОД = А1 х ЧИСЛО_ЗРИТЕЛЕЙ + А2 х РЕКЛАМА+...
Итак, у вас есть просто зависимость одной переменной от других. Замечательно, что все параметры (коэффициенты уравнения в правой части) рассчитываются по реальным данным, а не назначаются умозрительно.
«А для чего мне нужна эта зависимость, выраженная в явном виде?» — спросите вы. Предположим, вы расширили сеть кабельного телевидения, то есть увеличили число зрителей, тогда вы можете спрогнозировать свой доход. Именно так и поступал R. Sassone в исследовании, выполненном в 1978 году в США (данные были получены частично от McCann-Erickson, Inc., частично от Television Bureau of Advertising).
Аналогично вы можете спросить себя, каким образом изменятся внутренние цены на нефть при изменении цен на международном рынке, и попытаться ответить на этот вопрос с помощью регрессионного анализа. Типичная задача анализа качества: вы имеете группы поставщиков сырья и показатели качества продукции. Как зависит качество продукции от качества сырья?
Слово регрессия мы часто будем заменять словом зависимость и надеемся, нас правильно поймут. Вообще, мы будем стараться максимально уходить от статистического жаргона и выражаться доступным для каждого здравомыслящего человека языком. Потому что на этом языке изначально формулируются задачи анализа данных.
Известны сотни эффективных применений статистических методов и регрессии, в том числе в экономике, маркетинге, финансах, медицине, промышленности и т. д. Результаты выглядят очень простыми, естественными и впечатляющими.
Невозможно проведение актуарных расчетов без анализа конкретных данных — клиента интересует реальный риск, а не виртуальный, так как от оценки риска зависит конкретная процентная ставка и реальный платеж.
Важным полем применения статистических методов являются современные системы электронной торговли. Успешные действия систем онлайновой торговли требуют от фирм предсказания поведения индивидуальных покупателей.
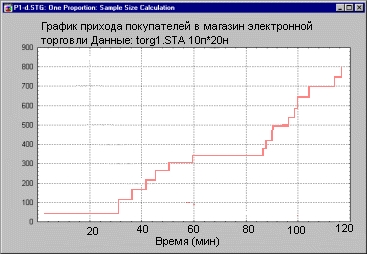
Крупнейшие фирмы, занимаясь электронной коммерцией, несут ежегодно огромные убытки из-за того, что 5-10% покупателей меняют фирму или переходят в пассивное состояние (см. Greg M. Allenby, Robert P. Leone and Lichung Jen (1999). A dynamic model of purchase timing with application to direct marketing, J. American Statistical Association, v. 94, № 446, p. 365-374). Системы регистрации электронной торговли позволяют зафиксировать моменты прихода каждого покупателя в магазин, сумму сделки, количество товаров и другие параметры. Здесь уже все готово для проведения статистического анализа. Важно спланировать его и провести анализ системно.
Одна из возможных задач состоит, например, в том, чтобы оценить периоды между покупками и изменить стратегию воздействия на покупателя — например, провести более активную рекламную кампанию, если покупатель не обращается на фирму в течение чрезмерно долгого времени.
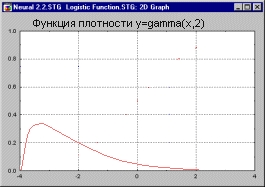
Для описания интервалов времени между приходами посетителей в электронный магазин можно использовать, например, гамма-распределение.
На модельных данных, отражающих реальную ситуацию, нами подробно разбирается пример СУПЕРМАРКЕТ: от первичного, описательного анализа данных о покупках в течение дня до углубленного анализа и получения неочевидных выводов.
Мы начинаем с корреляционной матрицы продаж:
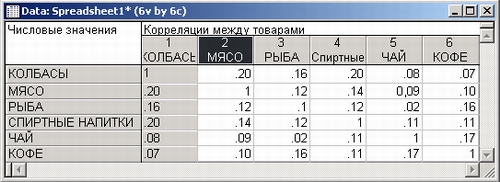
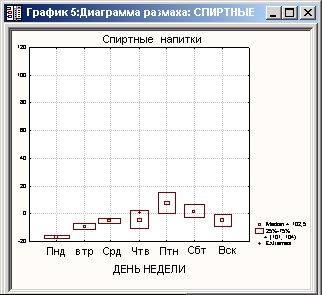
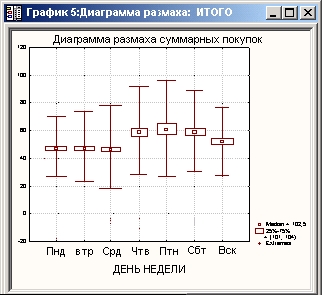
Затем рассматриваются графики, исследуется вариабельность покупок в зависимости от дней недели, применяется многомерный анализ, анализируется потребительская корзина для различных категорий пользователей, различных дней недели и т. д.

Как уже говорилось, много примеров связано с Интернетом. Имея файл с частотами посещений различных страниц сайта, можно изучить структуру посещений различных страниц.
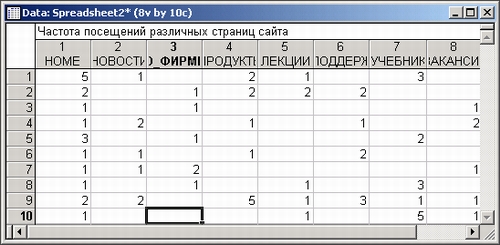
В частности, можно получить выводы типа: из 100 человек, посетивших страницу О_ФИРМЕ, 70 человек посетили страницу ПРОДУКТЫ, 50 человек посетили страницу ПОДДЕРЖКА, 20 человек посетили страницу ВАКАНСИИ. Все это делается в модуле Основные статистики и таблицы системы STATISTICA. Нетрудно также оценить вероятность того, что пользователь с определенной страницы сайта, например, страницы А перейдет на страницу В. Блуждание пользователя по сайту вполне описывается вероятностной моделью. Имея исходные данные, можно оценить параметры этой модели и рассчитать типичный «путь».
В отдельной главе нами всесторонне описываются различные распределения вероятностей и их применение на практике. Зная вероятные распределения, можно описать многие реальные явления, например, спрогнозировать число покупателей в определенные промежутки времени.
Общеизвестно применение статистики в медицине и фармакологии. Оценка эффективности лекарств, классификация больных по степени тяжести заболевания, исследование кардиограмм, самые разнообразные тесты, позволяющие диагностировать пациентов на раннем этапе заболевания и многие другие задачи, хорошо известны. Только математика открывает путь к доказательной медицине.
В знаменитом фрэмингхемском исследовании, выполненном в США (см. Truett, J., Cornfield, J., and Kendall, W. (1967). A Multivariate Analysis of the Risk of Coronary Heart Disease in Framingham, Journal of Chronic Disease 20, p. 511 -524), статистический анализ применялся для оценивания зависимости риска развития ишемической болезни сердца от семи факторов.
В этом исследовании в течение 12 лет были собраны данные о проявлениях ишемической болезни у 1929 мужчин и 2540 женщин в возрасте от 30 до 62 лет. В начале обследования все пациенты были здоровы. Факторами риска служили: возраст, количество холестерина в крови, систолическое давление, вес, количество гемоглобина в крови, количество выкуриваемых в день сигарет (0 — для некурящих, 1 — для выкуривающих меньше одной пачки, 2 — одну пачку, 3 — больше одной пачки), электрокардиограмма (0 — нормальная, 1 — ненормальная или неясная).
Проведенный анализ позволил изучить влияние факторов риска на развитие ишемической болезни сердца и стимулировал целый ряд подобных в самых различных медицинских приложениях.
Рассмотрим классические данные Гринвуда и Юла о влиянии прививки на заболеваемость холерой (данные относятся к началу XX века, см. например, Справочник по прикладной статистике, т. 1, М.: 1989, с. 245).
В приведенной ниже таблице показаны 2 663 пациента, части из которых были сделаны прививки против холеры (привитые пациенты), а части нет (не привитые пациенты).
|
Не заболевшие |
Заболевшие |
Сумма |
|
|
Привитые |
1625 |
5 |
1630 |
|
Не привитые |
1022 |
11 |
1033 |
|
Сумма |
2647 |
16 |
2663 |
Что можно сказать, глядя на эту таблицу? Прежде всего видно, что среди тех, кто сделал прививку, число заболевших меньше, чем среди тех, кто не сделал прививку (второй столбец таблицы, первая и вторая строка).
Кроме того, число не заболевших среди привитых пациентов больше, чем не заболевших среди не привитых (первый столбец таблицы). Это делает правдоподобным заключение об эффективности прививки.
Но как перевести эти рассуждения на рациональный язык? Имеется ли вообще такой язык?
Представьте, нашелся критик результатов (нового метода лечения, нового лекарства), который, заняв крайнюю позицию, резонно замечает, что и в том и другом случае, то есть и среди привитых пациентов, и среди не привитых, были отмечены случаи заболевания, иными словами, полученные результаты носят чисто случайный характер, и утверждение об эффективности прививки весьма сомнительно.
Как рационально ответить на подобную критику?
Лучше всего воспользоваться вероятностными рассуждениями и подходящим статистическим критерием. Для такого рода таблиц, называемых таблицами сопряженности, имеются специально разработанные критерии, например, критерий хи-квадрат или критерий Фишера, названный по имени знаменитого английского статистика Р. А. Фишера.
Эти критерии измеряют силу связи между признаками (переменными) таблицы, в данном примере между признаком прививка и признаком болезнь.
Для представленной выше таблицы величина статистики хи-квадрат равна 6,08, что значимо на уровне 0,0136 (чтобы получить эти цифры, мы сделали два щелчка мыши в системе STATISTICA).
Следовательно, с небольшой вероятностью ошибки (меньше 0,0136) вы можете утверждать, что среди привитых пациентов количество заболевших существенно меньше, чем среди не привитых. Поэтому вероятность того, что суждение критика о неэффективности вакцины справедливо, равна всего 0,0136 (примерно один шанс из 70). Ваша же оценка достоверности результатов существенно выше.
Весьма полезным визуальным методом изучения зависимостей между признаками таблицы являются графики взаимодействий:
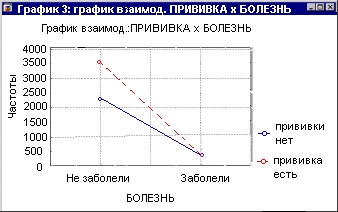
Здесь показаны две прямые, соответствующие категориям больных: привитые — не привитые. Если прямые пересекаются, то говорят, что признаки взаимодействуют, влияют друг на друга. Если прямые параллельны, то говорят, что взаимодействия или зависимости между признаками нет. Это визуальный подход, точные результаты дают статистические критерии.
Первые применения статистики в медицине, по-видимому, относятся к XVIII веку, когда в Англии было замечено, что относительная частота смертности мужчин и женщин одного возраста, живущих примерно в одинаковых условиях, из года в год колеблется, но колеблется в весьма узких пределах. Самым интересным здесь является замечание: «колеблется в узких пределах», — всем известно, что колебания происходят, — неожиданным фактом являются узкие границы колебания, что позволяет с большой точностью предсказать долю умерших в той или иной категории населения и служит основой актуарных расчетов.
Итак, в случайном явлении — смертности или, наоборот, выживаемости людей была открыта устойчивая закономерность: относительная частота или доля для людей одного пола и близкого возраста примерно постоянна. А это удивительное открытие, повлекшее за собой множество событий, в частности современное страхование.
В современной медицине накопились огромные архивы данных, и их исследование с помощью новых технологий чрезвычайно важная задача. STATISTICA позволяет реализовать системный подход к анализу данных.
У каждого врача имеется собственный архив данных, отражающий многолетний опыт его работы, — огромный массив знаний, имеющий большую познавательную ценность.
Ценность этой информации может быть многократно увеличена, если воспользоваться методами анализа данных. И в этот момент на помощь врачу приходит система STATISTICA, позволяющая перевести клинический опыт на язык количественных оценок (подробнее о применении статистики в медицине см.: Ст. Гланц. Медико-биологическая статистика. М.: 1999).
В STATISTICA реализованы множество методов, чрезвычайно полезных врачам для анализа их данных, в частности описательные статистики и таблицы, анализ выживаемости, непараметрическая статистика, дискриминантный анализ и др.

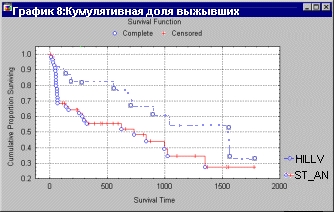
Анализ выживаемости позволяет проанализировать неполные или цензурированные данные, например, о выживаемости больных после операции (см. рис. 24).
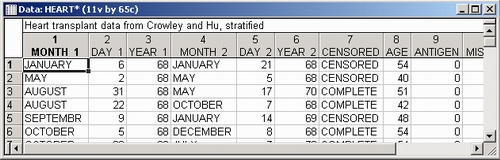
Одной из важных характеристик является функция выживаемости (вероятности того, что пациент проживет t дней после операции. Для оценки функции выживаемости по неполным данным используют так называемую оценку Каплана-Мейера, которая может быть легко получена в STATISTICA (см. рис. 25).

Этот график легко «читается»: вы легко видите, например, что доля пациентов, проживших больше 1 000 дней, равна 0,4.
Можно сравнить функции выживаемости в разных больницах, для разных возрастных групп (см. рис. 26).
Опишем еще одну важную область применения статистических методов — современное высокотехнологичное производство.
Традиционную область применения статистического анализа данных составляет промышленность.
Обычно любая машина или станок, используемые на производстве, позволяет операторам производить настройки, чтобы воздействовать на качество производимого продукта. Изменяя настройки, инженер стремится добиться максимального эффекта, а также выяснить, какие факторы играют наиболее важную роль в улучшении качества продукции. Использование этой информации позволяет достигнуть оптимального качества в условиях данного производства.
Например, на производстве (см. например, книгу: Box, Draper (1990), Empirical model-building and response surfaces, New York: Wiley, 115) проводился эксперимент по нахождению оптимальных условий для изготовления красителя ткани. Качество красителя описывается насыщенностью, яркостью и стойкостью.
Другими словами, в этом эксперименте нам хотелось бы выявить факторы, наиболее заметно (значимо) влияющие на яркость, насыщенность и стойкость производимого красителя. В примере Бокса и Дрейпера рассматривается б различных факторов, влияние которых оценивается с помощью так называемого плана 2(6-0). В данном плане первоначально рассматривались 6 факторов, принимающих два значения, то есть всего имелось 26 = 32 различных вариантов установок. Результаты эксперимента выявили три наиболее важных фактора: Polysulfide (Полисульфид), Time (Время) и Temperature (Температура).
Можно представить ожидаемое воздействие на интересующую нас переменную (например, светостойкость окраски) в виде так называемой кубической диаграммы, которая показывает ожидаемую (предсказываемую) среднюю стойкость краски, нанесенной на ткань, на верхних и нижних уровнях каждого из трех факторов, и определить те значения факторов, которые обеспечивают максимальное качество продукции (см. рис. 28).
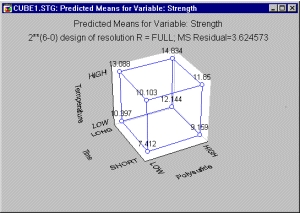
Глядя на эту диаграмму, легко можно понять, что наилучшее расположение факторов для максимизации качества красителя следующее: Polysulfide установлен на верхнем уровне HIGH, Time — на верхнем уровне LONG, Temperature — на верхнем уровне HIGH. Таким образом, оптимум достигается на дальней вершине куба (см. рис. 28).
В описанном эксперименте присутствовало 6 факторов, нередки, однако, случаи, когда очень много (до ста) различных факторов являются потенциально важными на производстве, однако заранее вы не знаете, какие факторы важны, а какие нет.
Специальные планы, например план Плакетта-Бермана или планы с матрицей Адамара, позволяют эффективно «просеять» или, как говорят на статистическом сленге, проскринировать большое число факторов, используя минимальное число наблюдений.
Например, вы можете спланировать и проанализировать эксперимент со 127 факторами, используя всего 128 опытов, а затем оценить главный эффект каждого фактора, определив, какие факторы играют доминирующую роль, а какие нет.
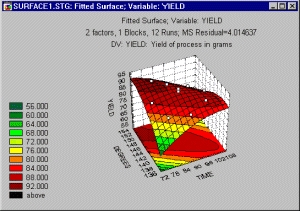
Выход продукта многих химических реакций является функцией времени и температуры. К сожалению, эти переменные влияют на выход не линейно. Другими словами, нельзя сказать: «чем больше продолжительность реакции, тем больше выход» и «чем выше температура, тем больше выход». Цель экспериментатора заключается в определении оптимального выхода или экстремальной точки поверхности выхода, образованной двумя переменными: временем и температурой.
При проведении таких экспериментов используют так называемые центральные композиционные планы, позволяющие инженерам-технологам оценить поверхность регрессии (см. рис. 29 и 30) и найти экстремумы этой поверхности, или точки, отвечающие заданному значению зависимой переменной.
Подобные планы применялись, например, для исследования ракетного топлива, в состав которого входили три компоненты: связывающее вещество, окислитель и горючее, а характеристикой качества являлась эластичность продукта (см. также планы для смесей в модуле Планирование эксперимента в системе STATISTICA).
Требовалось найти такие пропорции (доли) компонент, чтобы эластичность достигала заданного значения (см. Kurotori I. S. (1966). Experiment with mixtures of components having lower bounds, Industrial Quality Control, № 2, p. 592-596).
Это типичные задачи планирования эксперимента, возникающие на производстве, и система STATISTICA предоставляет эффективные методы их решения. Ниже показаны методы планирования эксперимента, доступные в системе.
Не менее важны в промышленности задачи контроля качества.
Для всех производственных процессов возникает необходимость установить пределы характеристик изделия, в рамках которых произведенная продукция удовлетворяет своему предназначению. Вообще говоря, существует два «врага» качества продукции:
1. Уклонения от значений плановых спецификаций изделия;
2. Слишком высокая изменчивость реальных характеристик изделий относительно значений плановых спецификаций, что говорит о несбалансированности процесса.
На более ранних стадиях отладки производственного процесса для оптимизации этих двух показателей качества производства часто используются описанные выше методы планирования эксперимента.
Методы контроля качества предназначены для построения процедур контроля качества продукции в процессе ее производства, то есть текущего контроля качества. Детальное описание принципов построения контрольных карт и подробные примеры можно найти в работах Buffa (1972) Operation management: Problems and models (3rd ed), New York: Wiley, Duncan (1974) Quality control and industrial statistics, Homewood, IL; Richard D. Irwin, Grant and Leavenworth (1980) Statistical quality control (5th ed.) New York: McGraw-Hill, Juran and Gryna (1988) Quality planning and analysis (2nd ed.) New York: McGraw-Hill, Montgomery (1985) Statistical quality control New York: Wiley, Montgomery (1991) Design and analysis of experiment (3rd ed.) New York: Wiley, Shirland (1993) или Vaughn (1974).
В качестве превосходного вводного курса, построенного на основе подхода «как — чтобы», можно указать монографию Hart and Hart (1989) Quantitative methods for quality improvement. Milwaukee, WI: ASQC Quality Press.
Особенно интенсивно методы контроля качества используются в США, Германии, Японии.
Общий подход к текущему контролю качества заключается в следующем.
В процессе производства из произведенной продукции или поступающего сырья проводится отбор выборок изделий заданного объема. После этого на специально разлинованной бумаге строятся диаграммы средних значений и изменчивости выборочных значений плановых спецификаций в этих выборках и рассматривается степень их близости к плановым значениям. Если диаграммы обнаруживают наличие тренда выборочных значений или выборочные значения оказываются вне заданных пределов, то считается, что процесс вышел из-под контроля, и предпринимаются необходимые действия для того, чтобы найти причину разладки.
Такие специальные карты называются контрольными картами Шухарта (названные в честь W. A. Shewhart, который общепризнанно считается первым, применившим их на практике в начале 30-х годов XX века).
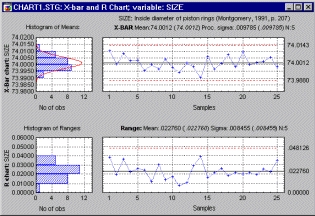
Один из примеров карты Шухарта показан на рис. 33. Смысл этой карты ясен. В последовательно поступающих партиях нефтепродуктов измерялась примесь вредных веществ. Строятся два линейных графика: для средних и размахов (разностей между максимальными и минимальными значениями выборки, что характеризует изменчивость характеристик производственного процесса).
Вначале посмотрим на график средних. Если средние выходят за определенные границы, то мы говорим о неудовлетворительном качестве сырья. На графике средних значений партии неудовлетворительного качества имеют специальную метку.
Далее рассматриваем график размахов. Размах — это разность между максимальным и минимальным значением выборки. Прагматическая ценность этой характеристики в том, что она служит мерой изменчивости. По расположению точек на графике размахов принимают решение о случайности или систематичности отклонения в качестве продукции.
Ниже показаны карты контроля качества, доступные в системе:
На практике могут возникнуть трудности при выборе наилучшей контрольной карты. Чтобы сделать выбор осознанно, нужно учитывать специфику производства, например, если исследуется концентрация определенных веществ в химическом процессе в режиме реального времени, то сложно провести группировку данных и следует применять карты для индивидуальных наблюдений. В отличие от этого, в машиностроении при измерении параметров продукции, например диаметров поршневых колец, легко разбить партию данных на подгруппы и применить соответствующие Х- и R-карты.
Еще одной типичной проблемой, с которой сталкиваются инженеры по контролю качества на производстве, является следующая: определить, сколько именно изделий из партии (например, полученной от поставщика) необходимо исследовать, чтобы с высокой степенью уверенности утверждать, что изделия всей партии обладают приемлемым качеством.
Допустим, что у вашей автомобильной компании есть поставщик поршневых колец для небольших двигателей, и ваша цель — разработать процедуру выборочного контроля поршневых колец в присылаемых партиях, обеспечивающую требуемое качество.
Процедуры выборочного контроля применяются в том случае, когда нужно решить, удовлетворяет ли определенным спецификациям партия изделий, не изучая при этом все изделия.
В силу природы проблемы — принимать или не принимать партию изделий — эти методы иногда называют статистическим приемочным контролем (acceptance sampling).
Очевидное преимущество выборочного контроля над полным или, сплошным, контролем продукции состоит в том, что изучение только выборки (а не всей партии целиком) требует меньше времени и финансовых затрат. В некоторых случаях исследование изделия является разрушающим (например, испытание стали на предельную прочность), и сплошной контроль уничтожил бы всю партию.
Наконец, с точки зрения управления производством, отбраковка всей партии или поставки от данного поставщика (на основании выборочного контроля) вместо браковки лишь определенного процента дефектных изделий (на основании сплошного контроля) часто заставляет поставщиков строже придерживаться стандартов качества.
Если взять повторные выборки определенного объема из совокупности, скажем, поршневых колец и вычислить их средние диаметры, то распределение этих средних значений будет приближаться к нормальному распределению с определенным средним значением и стандартным отклонением (или стандартной ошибкой; для выборочных распределений термин «стандартная ошибка» предпочтительнее, чтобы отличать изменчивость средних значений от изменчивости изделий в генеральной совокупности).
К счастью, нет необходимости брать повторные выборки из совокупности, чтобы оценить среднее значение и изменчивость (стандартную ошибку) выборочного распределения. Располагая хорошей оценкой того, какова изменчивость (стандартное отклонение, или сигма) в данной совокупности, можно вывести выборочное распределение среднего значения. В принципе этой информации достаточно, чтобы оценить объем выборки, необходимый для обнаружения некоторого изменения качества (по сравнению с заданными спецификациями).
Обычно технические условия задают некий диапазон допустимых значений. Например, считается приемлемым, если значения диаметров поршневых колец лежат в пределах 74,0 мм ± 0,02 мм. Таким образом, нижняя граница допуска для данного процесса равна 73,98; верхняя граница допуска 74,02. Разность между верхней границей допуска (ВГД) и нижней границей допуска (НГД) называется размахом допуска.
Простейшим и самым естественным показателем пригодности производственного процесса служит потенциальная пригодность. Она определяется как отношение размаха допуска к размаху процесса; при использовании правила 3 сигма данный показатель можно выразить в виде
Ср = (ВГД - НГД)/(6 х сигма).
Данное отношение выражает долю размаха кривой нормального распределения, попадающую в границы допуска (при условии, что среднее значение распределения является номинальным, то есть процесс центрирован).
В книге Bhote (1988) World class quality, New York: AM A Membership Publications отмечается, что до повсеместного внедрения методов статистического контроля качества (до 1980 г.) обычное качество производственных процессов в США составляло примерно Ср - 0,67. Иными словами, два хвоста кривой нормального распределения, каждый из которых содержал 33/2% общего количества изделий, попадали за границы допуска.
В конце 80-х годов лишь около 30% производств в США находились на этом или еще худшем уровне качества (см. Bhote, 1988, стр. 51). В идеале, конечно, было бы хорошо, если бы этот показатель превышал 1, то есть хотелось бы достигнуть такого уровня пригодности процесса, чтобы никакое (или почти никакое) изделие не выходило за границы допуска. Любопытно, что в начале 80-х годов японская промышленность приняла в качестве стандарта Ср = 1,33! Пригодность процесса, требуемая для изготовления высокотехнологичных изделий, еще выше; компания Minolta установила показатель Ср =2,0 как минимальный стандарт для себя (Bhote, 1988, с. 53) и как общий стандарт для своих поставщиков.
Заметим, что высокая пригодность процесса обычно приводит к более низкой, а не к более высокой себестоимости, если учесть затраты на рекламацию, связанную с низким качеством производимой продукции.
Как правило, более высокое качество обычно приводит к снижению общей себестоимости. Хотя издержки производства при этом увеличиваются, но убытки, вызванные плохим качеством, например из-за рекламаций потребителей, потери доли рынка и т. п., обычно намного превышают затраты на контроль качества.
На практике два или три хорошо спланированных эксперимента, проведенных в течение нескольких недель, часто позволяют достичь высокого показателя Ср.
В качестве одного из интересных примеров применения статистики в промышленности отметим задачу классификации сортов бензина, решаемую с помощью дискриминантного анализа.
Важная роль статистики в управлении экономикой США отмечена в статье: Moynihan D. Р. (1999) Data and dogma in public policy, J. American Statistical Association, v. 94, № 446, p. 359-364: «статистика, — по словам автора, — помогает понять силы, воздействующие на экономику». Без статистики трудно выделить основные факторы, влияющие на экономику, и предпринимать шаги, позволяющие минимизировать неблагоприятные флуктуации рынка.
Разнообразные задачи могут быть решены с помощью статистики на региональном уровне, начиная с задач описательной статистики, например, цен на потребительском рынке продуктов питания, зависимости внутрирегиональных цен от цен в соседних регионах, ввоза товаров из других регионов в пределах экономической территории региона, доходов населения, описание рынка труда, уровня жизни, экологической ситуацией, здравоохранения и т. д.
Также могут быть решены задачи оценки технического состояния транспортных средств города, расчет налоговых льгот для осуществления инвестиций в транспортную систему, классификация объектов незавершенного строительства, классификация должников, классификация источников выбросов загрязняющих веществ и множество других, где до сих пор применяются эмпирические правила.
Методы множественной регрессии позволяют исследовать рынок сельскохозяйственной продукции. В качестве примера укажем статью Honma Masayoshi, Hayami Yujioro (1986) Structure of agricultural protection in industrial countries, J. Int. Econ., 20, №1-2, p. 115-129, в которой исследована система протекции 10 индустриально развитых стран и дан социально-экономический анализ коэффициентов регрессии. Известно, что сельскохозяйственная политика индустриально развитых стран характеризуется сильными протекционистскими (защитными) мерами в отношении собственных производителей, иными словами, создаются такие торговые ограничения и система управления ценами, которые позволяют собственным производителям находиться в заведомо выгодном положении; Система протекции включает, в частности, экспортные налоги и завышенные обменные курсы валют. Следствие такой политики — дискриминационное положение сельскохозяйственных производителей развивающихся стран и неравномерное распределение продовольствия в мире. Подобные методы можно, конечно, применить и к изучению российского рынка.
Как и все математические науки, статистика родилась из практики. Подобно тому как древние египтяне после разливов Нила вынуждены были заново измерять свои участки и для этого разработали начала геометрии, так и современные люди, вовлеченные в стремительно меняющиеся потоки данных (Интернет, газеты, ТВ, слухи, сплетни, мнения экспертов и т. д.), вынуждены анализировать их. Для этого попросту нет ничего иного, кроме статистики и анализа данных.
Классическая математика имеет дело с детерминированными величинами и принципиально не приспособлена для работы со случайными данными. Конечно, мы стремимся интуитивно сузить пределы случайности, максимально уменьшить неопределенность, но сделать это полностью не удается.
По-видимому, случайность является важным элементом мироздания: выброшенные в открытый хаотически меняющийся мир, мы вынуждены либо приспосабливаться к нему и побеждать, либо погибнуть или влачить жалкое существование, не понимая ни сущности вещей, ни событий, происходящих в нем.
Ни у кого не вызывает сомнения, что при строительстве дома следует использовать начальные знания геометрии. Попробуйте точно начертить прямоугольник на участке земли, и вы увидите, что сделать это не так просто.
Как проверить, что начерченный четырехугольник действительно является прямоугольником? Если вы не знаете, что диагонали прямоугольника равны, то столкнетесь с непростой задачей.
Точно так же при исследовании сложных систем, хаотических явлений и потоков информации вы применяете статистику, в которой для измерения случайностей разработаны как простейшие, но очень полезные инструменты, подобные циркулю и транспортиру, так и весьма тонкие и совершенные методы.
Интересен следующий пример, приведенный Ж. Бертраном в его курсе «Исчисление вероятностей»: Некто, прогуливаясь в Неаполе, увидел человека из Базиликаты, который держал пари, что теперь же выбросит 3 шестерки, бросив 3 игральные кости... Удивительный человек из Базиликаты на глазах изумленной публики сделал это, а затем повторил фокус 2, 3,4 и 5 раз подряд... «Черт побери, — воскликнул Некто, — кости же, конечно, налиты свинцом!» — и был прав, потому что наблюдаемое событие, бросить 3 кости пять раз подряд и каждый раз получать 3 шестерки, имеет ничтожно малую вероятность, равную ((1/6) х(1/6 х(1/6))^5 = 4,71 х 10-11. Другими словами, он имел лишь 471 шансов из 10 х 1012 ошибиться в своем заключении. Заметим, что склонность использовать случай в свою пользу была свойственна еще египетским фараонам, в гробнице которых обнаружены игральные кости со смещенными центрами тяжести.
Классическим, и вместе с тем забавным, является пример шевалье де Мере, когда ставший известным в веках благодаря своей любознательности, азартный игрок спросил себя: стоит ли ему ставить на выпадение двух шестерок одновременно при бросании двух костей 24 раза или нет? Его собственные вычисления показали, что стоит, так как вероятность данного события при 24 бросках костей больше 1/2. Как же он удивился, когда с течением времени обнаружил, что постоянно оказывается в проигрыше! Оскорбленный игрок во всем обвинил статистику. И только знаменитый Паскаль нашел, в чем состоит ошибка игрока: оказывается, вероятность данного события 0,49 (меньше 0,5!), следовательно, в длинной серии игр, состоящих в 24 подбрасываниях двух костей, выигрыш происходит лишь в 49%, а не в более 50% игр, как ожидал де Мере.
В STATISTIC А эта задача, то есть вычисление вероятности выпадения двух шестерок, решается несколькими щелчками мыши.
Интересно, что не стоит делать ставку на выпадение двух шестерок при 24-х бросках пары костей, но стоит это делать при 25 бросках, так как вероятность выпадения хотя бы раз пары костей при 25 бросках больше 1/2, следовательно, в длинной серии игр игрок, поставивший на две ш+++++++++++++++++++естерки, будет в выигрыше чаще, чем в проигрыше. Если бы правила игры были изменены и проводилось 25 бросков, то в длинной серии игр де Мере оказался бы в выигрыше.
Конечно, теперь этот пример кажется забавным. Современное взаимодействие статистики с практикой много изощреннее, но суть остается той же: применяя статистические методы, вы должны найти устойчивые закономерности в случайных данных и воспользоваться ими с пользой для себя.
Применение даже простых статистических методов позволяет добиться эффектов там, где непосвященные опускают руки.
Одной из таких задач является пересчет голосов при голосовании. Предположим, что в ходе выборов один из кандидатов уступил другому несколько десятых процентов голосов. Так как разница очень небольшая, то потерпевший неудачу может усомниться в правильности подсчета и поставить вопрос о пересчете. Если пересчет подтвердит результаты голосования, то, по закону, ему нужно будет оплатить расходы, связанные с пересчетом. В противном случае он окажется победителем. Формально, на языке статистики, эта задача сводится к проверке гипотезы о неравенстве математических ожиданий двух биномиальных величин, см. например, работу, Harris Bernard (1988) Election recounting, Amer. Statis., 42, № 1, p. 66-68.
Эти лекции рассчитаны на самый широкий круг читателей, для которых важен анализ данных: статистиков, экономистов, маркетологов, аналитиков, актуариев, бизнесменов, инженеров, лиц, принимающих решения, и многих других.
Иными словами, они полезны тем, кто интуитивно понимает, что из анализа данных можно извлечь реальную пользу. Всех их мы хотим научить искусству анализа данных на компьютере.
Они также чрезвычайно полезна врачам, инженерам, научным работникам, преподавателям и студентам.
Разбираемые нами примеры охватывают самый широкий спектр приложений.
Предлагаемые лекции являются синтезом двух частей: описания разнообразных статистических методов — от элементарных понятий и принципов до возможных конкретных приложений, и описание анализа данных с помощью этих методов на системе STATISTIC А в среде Windows и отражает многолетний опыт автора в этой области.
Система STATISTICA включает в себя все известные методы статистического анализа данных и позволяет сделать процесс анализа высокотехнологичным. Методы, известные ранее по учебникам и научным публикациям, теперь доступны всем.
В лекциях содержится подробное описание основных возможностей системы STATISTICA, описаны основные диалоговые окна и команды системы. Особое внимание уделено новой технологии компьютерной обработки данных, максимально совмещенной со стандартами Windows.
STATISTICA позволяет реализовать системный подход к анализу данных, в частности, средствами STATISTICA можно создать свои модули анализа данных (см. рис. 34). Дополненные методами визуального программирования, эти средства открывают захватывающие перспективы.
Каждая глава наряду с примерами содержит большой справочный материал. Книга написана в двух срезах — для неподготовленного пользователя, впервые знакомящегося с методами анализа, и для тех, кто имеет специальную математическую подготовку и опыт работы на компьютере.
Наше изложение мы начинаем с изложения элементарных понятий. Вообще эти понятия следует разделить на 2 класса: понятия, относящиеся собственно к статистике, и понятия, относящиеся к анализу данных. И здесь есть некоторая тонкость. В статистических исследованиях, например в эконометрике (приложении методов статистики в экономике), мы исходим из априорной экономической модели и пытаемся оценить ее параметры. Это так называемый дедуктивный подход, в котором первична модель, а данные используются для оценки неизвестных параметров и проверки различных гипотез относительно модели. Здесь возникают понятия качества оценок, уровня значимости и т. д.
В анализе данных мы желаем исходить из данных как таковых, имея минимум априорных идей относительно их структуры. Далее мы стремимся понять, как организованы данные, какие переменные или группы переменных связаны (коррелируют) между собой, иными словами, стремимся понять структуру данных, исходя из них самих. Наиболее известная крайняя точка зрения этого подхода выражена в лозунге Бензекри (Benzecri), одного из создателей анализа соответствий: «Модель должна соответствовать данным, а не наоборот!». Насколько правомерен такой подход, судить философам, но он существует и его нельзя отвергать.
Приверженцы анализа данных зачастую критикуют эконометрику, утверждая, что она имеет дело с абстрактными гипотезами, которые никогда не работают на практике.
В действительности, между этими направлениями нет бездонной пропасти — известно, что анализ данных черпает свои идеи из классической статистики и наоборот. Типичный пример — анализ соответствий, чисто индуктивный метод, корни которого тем не менее лежат в математической статистике и свойствах знаменитого критерия хи-квадрат, открытого Карлом Пирсоном.
Пример индуктивного подхода можно найти в интересной статье F.-X. Micheloud, бывшей долгое время доступной на сайте http://www.micheloud.eom/FXM/cor/e/ genera.htm, где разведочный анализ данных (анализ соответствий) применяется к исследованию уровня образования жителей Лозанны (Швейцария). Автор, не используя прямо статистические рассуждения, работает с выборкой 169 836 человек. Спрашивается: «А почему не с выборкой, состоящей из 100 человек?» Очевидно, что для него интерес представляют перманентные, или устойчивые, выводы. Но понять, с какой выборкой нужно иметь дело, можно лишь с помощью теоретико-вероятностных и статистических рассуждений.
В данной книге мы стремились синтезировать классические методы статистики с методами анализа данных и, таким образом, открыть новые возможности для исследователей.
В нашем изложении мы опирались на фундаментальные тексты Кендалла М. Дж. и Стьюарта А., особенно на их замечательную книгу «Статистические выводы и связи» (М.: Наука, 1973).
Для описания функций распределения мы использовали фундаментальное издание: Вероятность и математическая статистика, М.: Большая Российская Энциклопедия, 1999.
В ряде случаев нам оказались полезными справочники:
Айвазян С. А., Енюков И. С., Мешалкин Л. Д. Прикладная статистика: основы моделирования и первичная обработка данных. М.: Финансы и статистика, 1983.
Справочник по прикладной статистике под редакцией Э. Ллойда и У. Ледерма-на, т. 1, 2. М.: Финансы и статистика, 1989.
На этом позвольте закончить наш, возможно, слишком продолжительный экскурс в анализ данных и перейти к систематическому изложению материала.
|
|
