Рисунок 1
Теория информации, несмотря на очевидные успехи в области технических приложений, является одной из самых неоднозначных дисциплин в концептуальной (семантической) области. Другими словами, мы уже почти понимаем, как «правильно» передать информацию от источника к получателю, осталось понять, что же все-таки считать информацией… В этой ситуации о смысле таких понятий, как данные, информация и знания можно говорить лишь на интуитивном уровне.
В частности, интуитивно понятно, что не всякие данные несут в себе информацию или, по крайней мере, однозначную информацию. Известный статистикам афоризм о «нормальной» средней температуре по больнице – тому подтверждение. Несмотря на то, что средняя температура по больнице – это данные, информацией она может являться, пожалуй, в очень редких случаях.
Вопрос со знаниями – еще сложнее. Относительно знаний понятно одно: они формируются, как обобщения эмпирического опыта (иначе говоря, информации). Более того, следует сказать, что впечатляющие успехи квантовой механики, привели не только к разработке атомной бомбы, но заложили основы «нового рационализма», который с большим опозданием входит в нашу жизнь только сейчас. Основываясь на классических принципах, заложенных в глубокой древности, новый рационализм совершенно иначе трактует многие известные понятия, вводит дополнительные принципы, которые коренным образом изменяют наше отношение к знаниям и, соответственно, к информации.
Таким образом, писать о семантической стороне теории информации в то время, когда еще не существует единой, устоявшейся терминологии, трудно. Еще труднее найти обоснование конкретным технологическим решениям на основе «сырой» теории. Анализ опыта создания и сопровождения хранилищ данных говорит о том, что именно в этой области ИТ-индустрии наиболее резко ощущаются трудности порожденные отсутствием устоявшейся семантической теории информации.
При проектировании, реализации и эксплуатации хранилищ данных, решается задача создания и поддержания предметно-ориентированного, интегрированного и зависимого от времени набора данных. Вопрос выявления и преодоления семантических разрывов, возникающих в потоках данных формирующих подобный набор, является одним из основных при проектировании хранилищ данных.
Технология хранилищ данных является одной из самых современных и предназначена для решения вполне определенного круга задач: сбора и консолидации данных из разрозненных и несогласованных источников в согласованный предметно-ориентированный, интегрированный и зависимый от времени набор данных. Полученный набор данных необходим для поддержки анализа и принятия решений пользователями в условиях большого быстрорастущего объема информации.
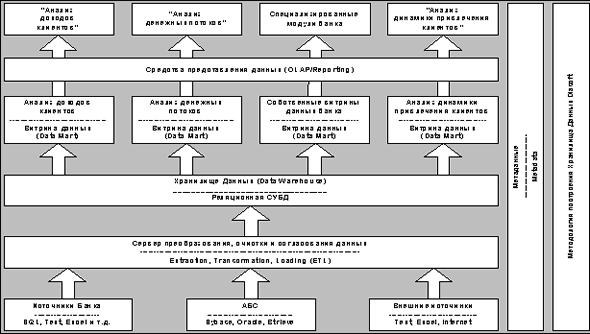
В качестве типовой архитектуры хранилища данных можно представить следующую схему (рис. 1)
Рисунок 1
Нетрудно заметить, что подавляющее большинство процессов, протекающих в хранилище данных, это процессы перегрузки данных из одной базы данных (БД) в другую. Очевидно, что при современном уровне развития информационных технологий простое перемещение данных из одной БД в другую не представляет затруднений. Однако если мы просто переместим данные из всех источников данных в одну БД, то получим всего лишь «свалку», несогласованный набор данных, никому кроме разработчиков непонятных чисел и символов. Для того, чтобы создать нечто доступное для анализа конечным пользователем, необходимо согласовать данные, поступающие из БД источников хранилища данных. Иначе говоря, решить основную задачу построения хранилища данных: создать тот самый согласованный, предметно-ориентированный, интегрированный, зависимый от времени набор данных.
Для того, чтобы сделать это, необходимо разобраться, почему же полученная нами «свалка» непригодна для анализа.
Анализ – это прием научного мышления, в основе которого лежит изучение составных частей и элементов изучаемой системы.
В нашем случае очевидно, что изучаемая система – это весь бизнес или некоторая его логически обособленная часть, представляющая интерес. Выделив в такой системе составные части, изучив их состояние, развитие и связи между ними, можно получить представление о состоянии и развитии системы в целом. Данные, необходимые для такого анализа, должны представлять максимально полный набор измеряемых показателей, отражающих состояние всех составных частей системы в любой момент времени. Именно такие показатели собираются в хранилище данных. Источниками данных, содержащих измеряемые показатели, доступные для хранилища, данных являются OLTP-системы (транзакционные системы).
Выясним, что же такое измеряемые показатели. А это не что иное, как некие понятия, для которых очень точно определены имя, концепт и денотат.
Понятие – это элементарная единица мыслительной деятельности, обладающая известной целостностью и устойчивостью и взятая в отвлечении от словесного выражения этой деятельности.
Поскольку мы мыслим понятиями, то, столкнувшись с каким-либо множеством объектов, мы разбиваем заинтересовавшее нас множество объектов на классы «эквивалентных» в каком-либо отношении элементов (т.е. игнорируя все различия между элементами одного такого класса, не интересующие нас в данный момент). Таким образом, получается новое множество, элементы которого сходны по определенному нами отношению эквивалентности. Элементы этого нового множества можно считать едиными, нерасчленяемыми объектами, полученными в результате «склеивания» всех неразличимых в фиксированных нами отношениях эквивалентности исходных объектов в один. Эти «комки» отождествленных между собой образов исходных объектов и есть то, что мы называем понятие. Как видите, они получены в результате мысленной замены класса близких между собой представлений одним «родовым» понятием.
Понятию, для обеспечения обмена мыслями, присваивается имя (знак):
Имя понятия (знак) – это те самые слова, которые мы употребляем в языковых конструкциях для передачи понятия. Языковый знак – это любая единица языка (морфема, слово, словосочетание, предложение), служащая для обозначения предметов, явлений действительности или понятий.
У понятия есть некий концепт:
Концепт (Смысл, Содержание) – смысл, который это понятие выражает. Перечень признаков (свойств), на основании которых произвели «склеивание».
И оно обладает неким денотатом или обозначает:
Денотат (Значение, Объём понятия) – это та самая совокупность «склеиваемых» в это понятие элементов, о которой сказано выше. Или, иначе говоря, предмет или явление, обозначаемое языком в конкретном речевом произведении.
Нетрудно заметить, что чем обширнее набор признаков, тем уже класс объектов, удовлетворяющих этим признакам, и наоборот, чем уже содержание понятия, тем шире его объём. Очевидно, что работая с данными, Вы желаете получать как можно более точный анализ и максимально полное представление о состоянии своего бизнеса: оперируя понятиями, подобными таким, как «карточка клиента» или «филиал», Вы тем лучше можете проанализировать состояние объекта, чем больше собираете параметров для анализа его состояния. Иными словами, чем больше содержание (набор признаков) понятия, тем более «обширный» концепт Вы рассматриваете. При этом меньшее число объектов обозначается этим понятием, и охватывается меньший объем (денотат). Иначе говоря, чем больше показателей (параметров) объекта регистрируем, тем более точно описан конкретный объект.
Для полноты картины, выясним, что такое набор данных. Пример такого стандартного для информационных систем набора данных приведен на рис. 2.
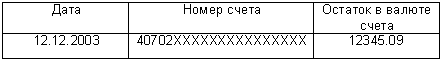
Рисунок 2
Набор данных информационной системы – это совокупность структурированных данных, представленная в виде таблицы. Иными словами, это некоторая знаковая система, совокупность условных знаков и правил их взаимосвязи.
То есть имена понятий и языковые знаки образуют более сложные языковые конструкции – знаковые системы, языки. Замечу кстати, что только что мы ввели в рамках статьи еще одно понятие – «набор данных». А конкретный набор, приведенный на рис. 3, еще одно понятие – «Остаток по счету № 40702ХХХХХХХХХХХХХХХ на дату 12.12.2003». Это понятие связано, очевидно, с понятиями «Остаток», «Номер счета 40702ХХХХХХХХХХХХХХХ» и «Дата 12.12.2003», кроме того, последние так же связаны с другими понятиями и т.д.
Более того, каждый из трех элементов понятия входит в несколько различных систем связей с соответствующими элементами других понятий, то есть образуя связи «многие-ко-многим». В совокупности такие связи образуют понятийную систему, или систему понятий. Если попытаться представить отношения между выделенными нами элементами понятия в виде ER-диаграммы, то получится нечто вроде того, что представлено на рис. 3.
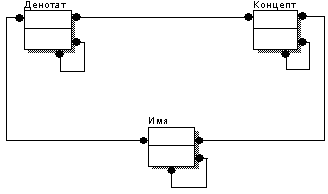
Рисунок 3
С другой стороны, очевидно, что любая знаковая система (язык) не способна полностью описать весь мир. Поэтому создавая информационную систему для определенных задач, ее разработчики опираются всего на одну неполную систему понятий, ту, которая, по их мнению, наилучшим образом подходит для решаемой задачи, создавая, таким образом, некий набор данных информационной системы.
Нетрудно заметить, что и имя понятия, и его концепт определяются достаточно произвольно в рамках различных систем понятий. В разных OLTP-системах, во-первых, одному и тому же денотату понятия могут быть присвоены разные имена, во-вторых, одни и те же имена могут быть присвоены понятиям с различными концептами и следовательно иметь пересекающиеся (а в особо сложных случаях и непересекающиеся) денотаты, в-третьих, понятия (и каждый из их элементов) могут иметь различные системы связей с другими понятиями, то есть имеют различные понятийные системы. Такая ситуация называется семантическим разрывом между системами.
Займемся теперь поиском и классификацией семантических разрывов.
Для этого построим модель. Введем в дополнение к ранее определенному понятию анализа понятие регистрации.
Регистрация – это фиксация на любом носителе результата измерения некоторого показателя.
Соответственно, пространственно-временную точку, в которой производятся измерения и их регистрация, будем называть – точка регистрации, а пространственно-временную точку, в которой производится анализ – точка анализа.
Построим модель процесса передачи данных от точки регистрации в точку анализа.
Для создания такой модели примем некоторые упрощения, а именно, в точке регистрации находится регистратор, который производит замер всего одного показателя (показателем может быть как давление или температура среды, так и остаток по кассе). Вообще говоря, регистратор – роль в самом общем смысле. Регистратором может быть как человек, так и прибор, прибор в свою очередь может быть как реально существующим, так и виртуальным, ниже мы покажем, что особой разницы в рамках нашей модели, нет. Соответственно в точке анализа находится аналитик (точно такая же роль, как и регистратор), который производит анализ. Регистратор и аналитик достаточно удалены друг от друга пространственно или во времени, чтобы не иметь возможности взаимодействовать между собой помимо канала связи, определенного нами. Например, регистратор замеряет температуру в помещении на Манхеттене, а затем пересылает по телеграфу или факсу в Москву, либо регистратор замерил показатель, записал его на листке бумаги и ушел, затем приходит аналитик и изучает записанный показатель.
Далее, поскольку аналитик не знает, какой именно параметр измеряется, то не может ничего с ним сделать. Дополним модель, заставив регистратора к пересылаемой информации добавлять для каждого измеренного показателя его имя.
В нашей модели имеется, как вы уже заметили, еще и канал связи. Вообще-то говоря, канал связи в данной модели при более пристальном взгляде весьма не прост. Но рассмотрение свойств канала выходит за рамки данной статьи. Под каналом связи мы будем понимать любой способ передачи информации, посредством которого регистратор передает результаты проведенного им измерения, аналитику. Под понятие канала связи в нашем случае подпадают как голос, так и локальная компьютерная сеть или Интернет. Единственное ограничение, которое накладываем мы на канал связи – его односторонность. Информация в нашей модели поступает исключительно от регистратора к аналитику и никогда наоборот. Модель на первый взгляд построена (см. рис. 4), назовем ее «Модель Двух Точек» (МДТ).
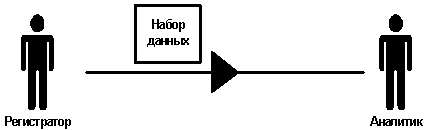
Рисунок 4
Достаточна ли она для того, чтобы найти возникающие в хранилище данных семантические разрывы? Попробуем взглянуть с другой стороны, для этого, неплохо бы подробнее разобраться, что такое анализ.
Согласно БСЭ, выделяют несколько видов анализа как приёма научного мышления:
Первым видом анализа является мысленное (а в эксперименте и реальное) расчленение целого на части. Такой анализ выявляет строение (структуру) целого и предполагает не только фиксацию частей, из которых состоит целое, но и установление отношений между частями. Особое значение имеет случай, когда анализируемый предмет рассматривается как представитель некоторого класса предметов: здесь анализ служит установлению одинаковой (с точки зрения некоторых отношений) структуры предметов класса, это позволяет переносить знание, полученное при изучении одних предметов, на другие.
Вторым – является анализ общих свойств предметов и отношений между предметами, когда свойство или отношение расчленяется на составляющие свойства или отношения; одни из них подвергаются дальнейшему анализу, а от других отвлекаются; на следующем этапе анализу может подвергнуться то, от чего ранее отвлеклись, и т.д. В результате анализа общих свойств и отношений понятия о них сводятся к более общим и простым понятиям.
Третьим видом анализа является также разделение классов (множеств) предметов на подклассы – непересекающиеся подмножества данного множества. Такого рода анализ называют классификацией. Как видно, ни один из видов анализа неприменим к одному единственному измерению показателя. Поскольку, получив информацию из одной единственной точки измерения и ничего не зная более, аналитик не может ничего расчленить, не может выявить общие свойства и связи и не может построить классификацию. Однако ничто не мешает нам собрать из некоторого количества наших моделей модель более высокого уровня, модель системы сбора информации.
Пусть регистраторов будет несколько, все вместе они регистрируют уже не один показатель, а столько, сколько их самих. Например, хотя бы координаты точки регистрации (местоположение и время). Теперь аналитик по нескольким каналам связи получает информацию о том, где, когда, что именно было измерено и каков результат этого измерения. Получилась некоторая система сбора информации для анализа (см. рис. 5). Что теперь может сделать аналитик? Уже очень многое. Например, классифицировать поступающую информацию, по одинаковым координатам, времени или имени показателя. Может попробовать выявить общие свойства и связи между показателями. То есть в различной степени применить все три вида анализа.
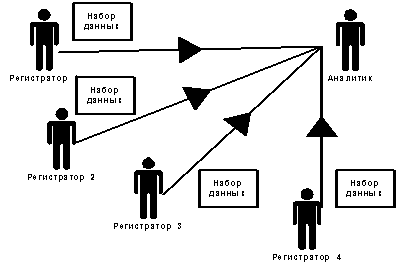
Рисунок 5
Построение модели завершено. Нетрудно заметить, что несмотря на внешнюю простоту, модель описывает массу явлений, как в природе, так и в деятельности человека. Например, работу зрения, где регистраторами выступают рецепторы на сетчатке глаза, а аналитиком — зрительный центр в мозге.
Информационно-аналитические системы (ИАС) предназначены для сбора и анализа всевозможных показателей. Очевидно, что есть некое сходство с нашей моделью.
В любой ИАС есть входящая информация, место, где информация хранится? и некоторые средства для ее анализа. Налицо точки регистрации с регистраторами, канал связи и аналитик. Если подробнее, то в ИАС вводятся данные о каких-то объектах, скажем, операционист в банке вводит данные о сделке с клиентом. При этом он передает в систему несколько показателей с их именами. Это регистратор в точке регистрации. Далее система, получив эти показатели, распределяет их по соответствующим таблицам своей базы данных, то есть производит классификацию. Если быть точным, то подобную классификацию, естественно, разработал человек, аналитик, участвовавший в создании системы, который сумел превратить процесс анализа в алгоритм, которому теперь и следует система, но это не меняет сути происходящего. Итак, наша модель с достаточной степенью соответствия описывает процесс ввода данных для любой информационно-аналитической системы на высшей степени абстракции.
Однако есть и вторая часть работы системы, а именно предоставление информации пользователю для дальнейшего анализа. Мы говорили о том, что вообще-то аналитик ничего не знает о точке регистрации и регистраторе, кроме того, что получает по каналу связи. Так вот, с учетом этого, для аналитика нет никакой разницы, где находится точка регистрации: в реальном мире или мире виртуальном! То есть, если считать, что БД-системы, это некое пространство, в котором существуют свои координаты и протекают во времени свои процессы, то точка регистрации – это поле в таблице БД. Регистратор – это тот запрос, который пользователь применяет к БД, пересылаемые по каналу связи показатели с именами очевидны – результирующий набор данных, формируемый запросом и, наконец, аналитик – сам пользователь.
Если учесть, что многие системы, например хранилища данных, сами выступают в роли пользователя, по отношению к другим системам, то может выстраиваться множество цепочек и звездочек из любого количества звеньев, полностью описывающие продвижение информации от самого первого замера показателя к конечному пользователю. Применение модели правомочно.
Итак, регистратор произвел измерение некоего показателя, следующим его действием является пересылка результата аналитику. Вспомним, что регистратор отправляет в нашей модели аналитику не только собственно результат измерения, но и имя показателя. Как мы выяснили ранее, показатель не что иное, как понятие. То есть регистратор в нашей модели пересылает экземпляр множества денотата, то, что он измеряет, и имя понятия – знак, которым он его обозначает. Раз так, то можно говорить о возможности семантического разрыва и его последствиях для анализа. Посмотрим, какого рода семантические разрывы возникают.
Для этого вновь обратимся к рисункам 2 и 3. На рисунке 3 изображены связи между элементами понятия. Достаточно легко понять, что разрыв может возникать там, где существуют связи многие ко многим между элементами понятия или понятиями в системе понятий. Отметим, что пересылке по каналу связи подвергаются имя понятия и некий объект – значение, входящий в множество денотата этого понятия. Концепт понятия не пересылается вовсе! Разработчиками любой информационной системы подразумевается, что концепт понятия аналитику известен. Семантические разрывы, таким образом, неизбежны. Отмечу, что даже если бы мы попытались переслать концепт, то это не исправило бы ситуацию. Как уже отмечалось, языковой знак, в свою очередь, также является объектом и для него существует понятие, концепт которого тоже надо описать, иначе будет неоднозначность в толковании концепта исходного понятия и т.д.
В отсутствие концепта, неоднозначность связи имени понятия и денотата очевидна. Отсюда возникает следующая ситуация. Регистратор, в силу своего образования, опыта и системы мышления, если это человек, или в силу образования, опыта и системы мышления своего создателя, если это некое устройство, выделяет денотат понятия, то есть то, что он измеряет. Исходя из тех же соображений, регистратор присваивает понятию имя-знак. С другой стороны, аналитик, в силу уже своего опыта и образования, определяет денотат показателя по-своему. Кроме того, определяя денотат показателя для анализа, он опирается на знак (имя), переданный регистратором. Если знак понятия, присвоенный регистратором, интерпретируется аналитиком иначе (имеет другой концепт), чем регистратором, то аналитик определяет денотат понятия иначе, чем регистратор. Это семантический разрыв. Приведем простейший пример с передачей данных из Манхеттена в Москву. Представьте, что регистратор имя понятия передает записанным на английском языке, которого московский аналитик просто не знает.
Семантический разрыв налицо. Этот вариант разрыва простейший, известен с библейских времен вавилонских строителей, поэтому так его и назовем, «вавилонский» или разрыв в интерпретации имен понятий.
Далее, у нас есть цепочки, в каждом из звеньев которых скрывается «вавилонец». Но у нас встречаются и звездочки из таких звеньев! Пусть первый регистратор измеряет диаметр трубы, а второй ну хотя бы длину забора. А теперь внимание! Если один передает: «Размер – 30», а второй «Размер – 30», то, как Вы считаете, какие выводы сделает аналитик? Имена понятий одинаковые, а их концепты и следовательно, наполнение – денотат – разные. Семантический разрыв. Значит, могут быть и разрывы между параллельными потоками данных, поступающими к аналитику. Назовем такие разрывы «кросспотоковыми».
Вернемся к рисунку 2 и вспомним, что всякое понятие встроено в понятийную систему. У каждого из регистраторов своя знаковая система, то есть каждый из них может отправлять набор данных, сформированный в разных системах понятий. Наиболее простым примером будет использование различных единиц измерения и соотношений между их минорными и мажорными вариантами (метры и футы) – два регистратора измеряют длину забора и передают результаты измерения аналитику, первый в метрах, а второй в футах, либо регистратор измеряет длину забора в футах, а аналитик анализирует в метрах. Это «кроссязыковые» семантические разрывы. От вавилонских они отличаются тем, что возникают не на разнице в интерпретации имен понятий, а на разнице в интерпретации связей между понятиями.
Наконец, мы в свое время не стали рассматривать канал. Канал связи передает данные от регистратора к аналитику и может влиять на передаваемую информацию. А именно отфильтровывать часть данных или вызвать задержку в их передаче. Поскольку каждое передаваемое аналитику понятие на самом деле является еще и набором данных (знаковой системой), то задержка в передаче части системы или потеря таковой приведут к семантическому разрыву. Теряются связи. Например, передается понятие «Остаток по счету № 40702ХХХХХХХХХХХХХХХ на дату 12.12.2003». Если ранее или одновременно с этим понятием к аналитику не поступило понятие «Номер счета 40702ХХХХХХХХХХХХХХХ», то имя понятия просто не может быть интерпретировано. Это «асинхронный» разрыв. В итоге складывается классификация семантических разрывов в хранилищах данных (см. рис. 6)

Рисунок 6
Посмотрим теперь на хранилище данных. Что будет, если мы опишем протекающие в нем процессы с помощью нашей модели?
Посмотрим, что модель двух точек даст нам для понимания трудностей, возникающих при проектировании и эксплуатации хранилищ данных. Применим ее для декомпозиции архитектуры хранилища данных и его окружения. Для приведенной на рисунке 1 архитектуры хранилища данных наша модель выстроится в схему, представленную на рис. 7
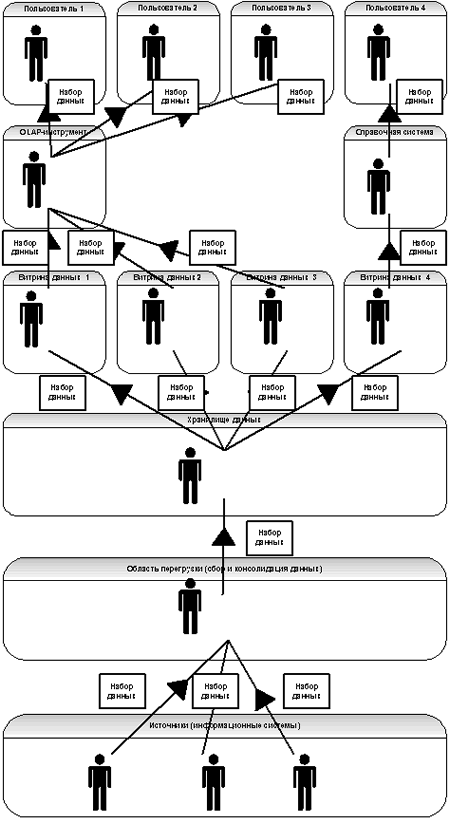
Рисунок 7
В самом низу (на рис. 1) находятся OLTP-системы и прочие источники данных. Чем по отношению к ним является запрос ETL? Регистратором, фиксирующим и пересылающим в хранилище данных некие поименованные показатели. Что же тогда такое хранилище данных? Аналитик, классифицирующий и выявляющий связи между поступающими показателями. Налицо модель двух точек.
Создатели источников проектировали данные системы согласно своим представлениям о потребностях пользователей и по своим собственным представлениям об архитектуре данных систем, таким образом, они создавали для своей системы собственную знаковую систему (язык). Поясню, в каждой из OLTP-систем свои наборы имен таблиц и столбцов, собственные связи между объектами системы, это и есть внутренний язык системы, ее знаковая система. В свою очередь, хранилище данных решает свой собственный круг аналитических задач, поэтому его язык отличается от языка любой из OLTP-систем, используемых в качестве источников. Вот разрыв – «вавилонец». Далее, при поступлении данных в хранилище, они консолидируются, то есть из разных точек регистрации информация приходит в одну точку анализа, значит, есть и второй вид разрыва, «кросспотоковый». В каждой из систем источников используются для хранения данных свои единицы измерений и вообще свои связи между понятиями, отсюда «кроссязыковые» разрывы. Наконец, достаточно передать в хранилище данных сведения о проводке по вновь открытому счету раньше, чем сведения об открытии счета, чтобы получить «асинхронный» разрыв.
Идем дальше, на рисунке видно, что из хранилища данных информация поступает в витрины данных. Обычно, разумеется, витрины данных и хранилище данных проектируются одной командой, поэтому они «говорят на одном языке», однако в общем случае это может быть и не так. В этом случае ситуация полностью повторяется, мы имеем еще одно звено в цепочке наших моделей и еще один набор семантических разрывов.
Над витринами данных (рис. 7) мы видим средства OLAP, вы уже, несомненно, догадались, что и здесь история повторяется, снова наша модель и весь спектр семантических разрывов.
Наконец, последнее звено в архитектуре хранилища данных, отчеты для анализа пользователем. Нетрудно догадаться, что и в этом случае все повторится. Это естественно. Ведь любой человек имеет собственную уникальную систему понятий, выработанную образованием и опытом, поскольку, последние уникальны для каждого пользователя, то и системы понятий уникальны. То есть, вновь наша модель и семантический разрыв.
Семантический разрыв – это синоним непонимания информации, которая заключена в данных. Непонимание, в свою очередь, может быть полным, частичным, разным у разных пользователей или, например, у пользователей и «производителей» данных. Хранилище данных содержит большие объемы разнородных данных и, обычно, большое количество «разнородных» потребителей. Для интенсификации общения специалистов, повышения эффективности анализа и сокращения сроков принятия решений, хранилище обязательно должно обладать средствами исключения семантических разрывов или минимизации времени на их преодоление. Такие системы принято называть подсистемами управления метаданными. Предлагаемая модель семантических разрывов может быть полезна в процессе анализа решений и проектирования подсистем управления метаданными.
Наличие продуманной теории могло бы значительно облегчить ответы на поставленные вопросы, но её, как уже было отмечено, пока нет. В любом случае, плохая теория лучше ее отсутствия.
При создании хранилищ данных очень мало внимания так же уделяется очистке поступающей в него информации. Видимо считается, что чем больше размер хранилища, тем лучше. Это порочная практика и лучший способ превратить хранилище данных в свалку мусора. Данные очищать необходимо. Ведь информация разнородна и собирается из различных источников. Именно наличие множеств точек сбора информации делает процесс очистки особенно актуальным.
По большому счету, ошибки допускаются всегда, и полностью избавиться от них не получится. Возможно, иногда есть резон смириться с ними, чем тратить деньги и время на избавление от них. Но, в общем случае, нужно стремиться любым способом снизить количество ошибок до приемлемого уровня. Применяемые для анализа методы и так грешат неточностями, так зачем же усугублять ситуацию?
К тому же нужно учесть психологический аспект проблемы. Если аналитик не будет уверен в цифрах, которые получает из хранилища данных, то будет стараться ими не пользоваться и воспользуется сведениями, полученными из других источников. Спрашивается, для чего тогда вообще нужно такое хранилище?
Мы не будем уже рассматривать ошибки такого рода, как несоответствие типов, различия в форматах ввода и кодировках. Т.е. случаи, когда информация поступает из различных источников, где для обозначения одного и того же факта приняты различные соглашения. Характерный пример такой ошибки – обозначение пола человека. Где-то он обозначается как М/Ж, где-то как 1/0, где-то как True/False. С такого рода ошибками борются при помощи задания правил перекодировки и приведения типов. Такого рода проблемы худо-бедно сегодня решаются. Нас интересуют проблемы более высокого порядка, те, которые не решаются такими элементарными способами.
Вариантов такого рода ошибок очень много. Есть к тому же ошибки, характерные только для какой-то конкретной предметной области или задачи. Но давайте рассмотрим такие, которые не зависят от задачи:
Для решения каждой из этих проблем есть отработанные методы. Конечно, ошибки можно править и вручную, но при больших объемах данных это становится довольно проблематично. Поэтому рассмотрим варианты решения этих задач в автоматическом режиме при минимальном участии человека.
Для начала нужно решить, что именно считать противоречием. Как ни странно, это задача нетривиальная. Например, пенсионную карточку в России нужно менять в случае изменения фамилии, имени, отчества и пола. Оказывается, в том, что человек родился женщиной, а вышел на пенсию мужчиной, противоречия нет!
После того, как мы определимся с тем, что считать противоречием и найдем их, есть несколько вариантов действий.
Очень серьезная проблема. Это вообще бич для большинства хранилищ данных. Большинство методов прогнозирования исходят из предположения, что данные поступают равномерным постоянным потоком. На практике такое встречается крайне редко. Поэтому одна из самых востребованных областей применения хранилищ данных – прогнозирование – оказывается реализованной некачественно или со значительными ограничениями. Для борьбы с этим явлением можно воспользоваться следующими методами:
Довольно часто происходят события, которые сильно выбиваются из общей картины. И лучше всего такие значения откорректировать. Это связано с тем, что средства прогнозирования ничего не знают о природе процессов. Поэтому любая аномалия будет восприниматься как совершенно нормальное значение. Из-за этого будет сильно искажаться картина будущего. Какой-то случайный провал или успех будет считаться закономерностью.
Есть метод борьбы и с этой напастью – это робастные оценки. Это методы, устойчивые к сильным возмущениям. Мы оцениваем имеющиеся данные ко всему, что выходит за допустимые границы, и применяем одно из следующих действий:
Почти всегда при анализе мы сталкиваемся с шумами. Шум не несет никакой полезной информации, а лишь мешает четко разглядеть картину. Методов борьбы с этим явлением несколько.
Вообще это тема для отдельного разговора, т.к. количество типов такого рода ошибок слишком велико, например, опечатки, сознательное искажение данных, несоответствие форматов, и это еще не считая типовых ошибок, связанных с особенностями работы приложения по вводу данных. Для борьбы с большинством из них есть отработанные методы. Некоторые вещи очевидны, например, перед внесением данных в хранилище можно провести проверку форматов. Некоторые более изощренные. Например, можно исправлять опечатки на основе различного рода тезаурусов. Но, в любом случае, очищать нужно и от такого рода ошибок.
Грязные данные представляют собой очень большую проблему. Фактически они могут свести на нет все усилия по созданию хранилища данных. Причем, речь идет не о разовой операции, а о постоянной работе в этом направлении. Чисто не там где не сорят, а там, где убирают. Идеальным вариантом было бы создание шлюза, через который проходят все данные, попадающие в хранилище.
Описанные выше варианты решения проблем не единственные. Есть еще достаточно много методов обработки, начиная от экспертных систем и заканчивая нейросетями. Многие из этих технологий реализованы в виде freeware компонентов и программ, которые вы можете скачать с нашего сайта. Главное, суметь грамотно ими воспользоваться. Обязательно нужно учитывать то, что методы очистки сильно привязаны к предметной области. От сферы деятельности организации и назначения хранилища данных зависит практически все. То, что для одних является шумом, для других очень ценная информация. Если у нас будет априорная информация о задаче, то качество очистки данных можно увеличить на порядки. К тому же нужно качественно интегрировать этот шлюз с имеющимися источниками данных.
Механизмы фильтрации должны стать таким же неотъемлемым атрибутом хранилищ данных, как OLAP. Иначе в горе собранного мусора будет практически невозможно найти зерно полезного. Может, пока не все разделяют это мнение, но все дело только в размерах хранилищ. По мере его увеличения пользователи обязательно придут к такому же мнению.
При решении практических задач, в частности, задачи прогнозирования, вы обязательно столкнетесь с проблемой подготовки данных. Не надо питать никаких иллюзий, что если не помог один способ прогнозирования, то поможет другой, более изощренный. Дело не в методах. Если в исходных данных не хватает параметров, если информация сильно искажена, то никакой метод не поможет.
Давайте рассуждать на уровне обычной логики. В августе, сентябре, октябре вы продали 10000 единиц какого-либо товара. Что нам говорят эти данные? Это хороший или плохой результат? Однозначно на этот вопрос ответить невозможно. Во-первых, нужно учитывать сезонность, во-вторых, состояние рынка, в-третьих, действия конкурентов — и так можно продолжать еще долго: цена, реклама, изменение законодательства... Если человек не может дать ответ на, казалось бы, достаточно простой вопрос, что стоит ждать от машины. Можно возразить, что эксперты дают прогнозы, основываясь на этих данных, но эти возражения не выдерживают критики. Эксперт всегда имеет много, пусть и не формализованной, дополнительной информации. Это называется опытом работы. В случае применения какого-либо математического метода у нас этих данных нет. Не нужно забывать еще и о различного рода аномальных выбросах и провалах. Эксперт, зная, что происходило в это время, будет или не будет принимать эти сведения в расчет при прогнозировании объемов продаж.
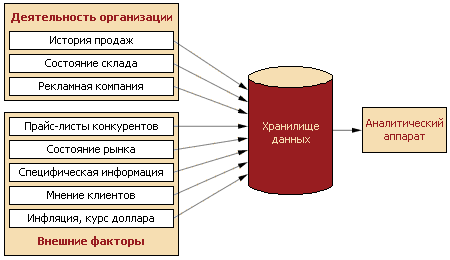
Фундаментальная проблема заключается в том, что информации об истории продаж – то, на основе чего чаще всего предлагается прогнозировать, совершенно недостаточно для сколько-нибудь качественного прогноза. Конечно, можно прогнозировать и имея только эти данные, но это больше напоминает гадание на кофейной гуще. Сведения об объемах продаж, конечно, нужны, но они дают максимум 30% от необходимой информации. Фактически они описывают только то, что произошло внутри организации, и то не в полном объеме. А то, что произошло в это время на рынке, практически игнорируется. В то время как влияние внешних факторов очень велико, в некоторых случаях и решающее.
Для того, чтобы получить качественный прогноз, нужно собрать максимум информации об исследуемом процессе, описывающей его с разных сторон. Например, для прогнозирования объемов продаж необходимо знать:
и многое другое.
Проблема заключается в том, что обычно в системах оперативного учета большей части этой информации просто нет, а та, что есть, искаженная и/или неполная.
Можно систематизировать сведения из систем оперативного учета, регулярно вводить информацию о прайс-листах конкурентов – это открытая информация, наладить учет отказов в обслуживании, заказать маркетинговое исследование, регулярно проводить анкетирование. Есть еще много информации в разного рода статистических сборниках. Конечно, информация, содержащаяся в них, далека от идеала, но это не столь страшно. Значение имеют не абсолютные числа, а тенденции. Тенденции отражаются в этих сборниках достаточно хорошо. Как только будут подготовлены данные, можно говорить о качественном прогнозе.
Подавляющее большинство из необходимой информации можно получить бесплатно или за минимальную плату из совершенно открытых источников. Перед внесением этих сведений в хранилище, возможно, их придется обрабатывать каким-либо образом, но это вполне решаемо. Главное, что необходимую информацию можно получить. Даже если удастся собрать только часть из необходимых данных, уже это позволит значительно улучшить качество прогноза.
Создание хранилища данных — довольно утомительное и дорогое занятие, но вариантов не очень много. Как говорится, "если вы считаете, что образование – это слишком дорого, попробуйте, почем невежество".
|
|
