Рис. 5. Принцип организации многомерного куба
Основное назначение многомерных хранилищ данных (МХД) — поддержка систем, ориентированных на аналитическую обработку данных, поскольку такие хранилища лучше справляются с выполнением сложных нерегламентированных запросов.
Многомерная модель данных, лежащая в основе построения многомерных хранилищ данных, опирается на концепцию многомерных кубов, или гиперкубов. Они представляют собой упорядоченные многомерные массивы, которые также часто называют OLAP-кубами (аббревиатура OLAP расшифровывается как On-Line Analytical Processing — оперативная аналитическая обработка). Технология OLAP представляет собой методику оперативного извлечения нужной информации из больших массивов данных и формирования соответствующих отчетов.
Сущность многомерного представления данных состоит в следующем. Большинство реальных бизнес-процессов описывается множеством показателей, свойств, атрибутов и т.д. Например, для описания процесса продаж могут понадобиться сведения о наименованиях товаров или их групп, о поставщике и покупателе, о городе, где производились продажи, а также о ценах, количествах проданных товаров и общих суммах. Кроме того, для отслеживания процесса во времени должен быть введен в рассмотрение такой атрибут, как дата. Если собрать всю эту информацию в таблицу, то она окажется сложной для визуального анализа и осмысления. Более того, она может оказаться избыточной: если, например, один и тот же товар продавался в один и тот же день в различных городах, то придется несколько раз повторить одно и то же соответствие «город — товар» с указанием различных суммы и количества. Все это способно окончательно запутать и сбить с толку любого, кто попытается извлечь из такой таблицы полезную информацию с целью анализа текущего состояния продаж и поиска путей оптимизации процесса торговли. Указанные проблемы возникают по одной простой причине: в плоской таблице хранятся многомерные данные.
Проясним суть вопроса с помощью геометрической аналогии. Представьте себе трехмерную фигуру (например, тетраэдр или параллелепипед) и спроецируйте его на плоскость, а затем по полученной плоской проекции попытайтесь оценить форму и размеры исходной объемной фигуры. Сделать это будет трудно: во-первых, потеряна информация об одном измерении, а во-вторых, фигура теперь представлена в совершенно несвойственном ей плоском виде.
Примерно то же самое можно сказать об информации, представленной несколькими рядами данных. Каждый такой ряд (поле таблицы) можно рассматривать как своего рода информационное измерение, и тогда «плоская» таблица может быть интерпретирована как результат преобразования многомерной информационной структуры в совершенно несвойственную ей плоскую форму. Чтобы компенсировать потерю информации от исключения одного или нескольких измерений, приходится усложнять структуру таблицы, а это в большинстве случаев приводит к тому, что разобраться в ней становится очень сложно.
Можно пойти другим путем — выполнить декомпозицию информации в несколько более простых таблиц, связать их некоторым набором отношений и перейти к реляционной модели, которую используют классические базы данных. Однако доказано, что реляционная модель не является оптимальной с точки зрения задач анализа, поскольку предполагает высокую степень нормализации, в результате чего снижается скорость выполнения запросов. Поэтому разработка многомерной модели представления данных, которая реализуется с помощью многомерных кубов, стала естественным шагом.
Замечание
Не следует пытаться провести геометрическую интерпретацию понятия «многомерный куб», поскольку это просто служебный термин, описывающий метод представления данных.
В основе многомерного представления данных лежит их разделение на две группы — измерения и факты.
Измерения — это категориальные атрибуты, наименования и свойства объектов, участвующих в некотором бизнес-процессе. Значениями измерений являются наименования товаров, названия фирм-поставщиков и покупателей, ФИО людей, названия городов и т.д. Измерения могут быть и числовыми, если какой-либо категории (например, наименованию товара) соответствует числовой код, но в любом случае это данные дискретные, то есть принимающие значения из ограниченного набора. Измерения качественно описывают исследуемый бизнес-процесс.
Факты — это данные, количественно описывающие бизнес-процесс, непрерывные по своему характеру, то есть они могут принимать бесконечное множество значений. Примеры фактов — цена товара или изделия, их количество, сумма продаж или закупок, зарплата сотрудников, сумма кредита, страховое вознаграждение и т.д.
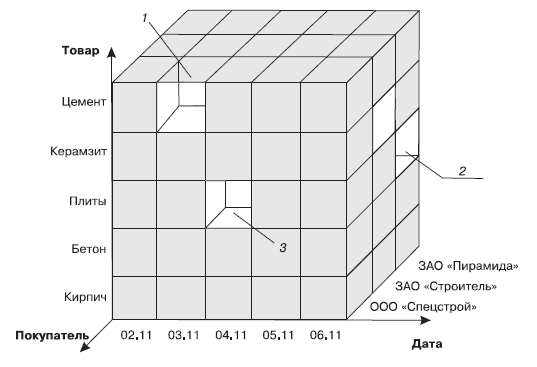
Многомерный куб можно рассматривать как систему координат, осями которой являются измерения, например Дата, Товар, Покупатель. По осям будут откладываться значения измерений — даты, наименования товаров, названия фирм-покупателей, ФИО физических лиц и т.д.
В такой системе каждому набору значений измерений (например, «дата — товар — покупатель») будет соответствовать ячейка, в которой можно разместить числовые показатели (то есть факты), связанные с данным набором. Таким образом, между объектами бизнес-процесса и их числовыми характеристиками будет установлена однозначная связь.
Принцип организации многомерного куба поясняется на рис. 5. В ячейке 1 будут располагаться факты, относящиеся к продаже цемента ООО «Спецстрой» 3 ноября, в ячейке 2 — к продаже плит ЗАО «Пирамида» 6 ноября, а в ячейке 3 — к продаже плит ООО «Спецстрой» 4 ноября.
Рис. 5. Принцип организации многомерного куба
Многомерный взгляд на измерения Дата, Товар и Покупатель представлен на рис. 6. Фактами в данном случае могут быть Цена, Количество, Сумма. Тогда выделенный сегмент будет содержать информацию о том, сколько плит, на какую сумму и по какой цене приобрела фирма ЗАО «Строитель» 3 ноября.
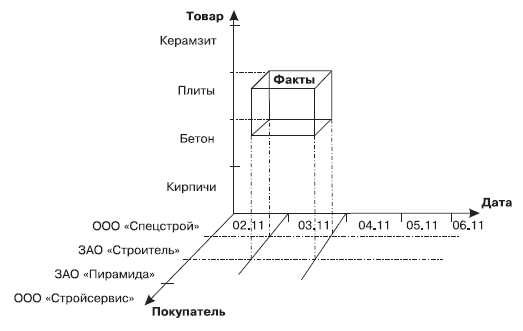
Рис. 6. Измерения и факты в многомерном кубе
Таким образом, информация в многомерном хранилище данных является логически целостной. Это уже не просто наборы строковых и числовых значений, которые в случае реляционной модели нужно получать из различных таблиц, а целостные структуры типа «кому, что и в каком количестве было продано на данный момент времени». Преимущества многомерного подхода очевидны.
В принципе, OLAP-куб может быть реализован и с помощью обычной реляционной модели. В этом случае имеет место эмуляция многомерного представления совокупностью плоских таблиц. Такие системы получили название ROLAP — Relational OLAP.
Использование многомерной модели данных сопряжено с определенными трудностями. Так, для ее реализации требуется больший объем памяти. Это связано с тем, что при реализации физической многомерности используется большое количество технической информации, поэтому объем данных, который может поддерживаться МХД, обычно не превышает нескольких десятков гигабайт. Кроме того, многомерная структура труднее поддается модификации; при необходимости встроить еще одно измерение требуется выполнить физическую перестройку всего многомерного куба. На основании этого можно сделать вывод, что применение систем хранения, в основе которых лежит многомерное представление данных, целесообразно только в тех случаях, когда объем используемых данных сравнительно невелик, а сама многомерная модель имеет стабильный набор измерений.
В процессе поиска и извлечения из гиперкуба нужной информации над его измерениями производится ряд действий, наиболее типичными из которых являются:
Сечение заключается в выделении подмножества ячеек гиперкуба при фиксировании значения одного или нескольких измерений. В результате сечения получается срез или несколько срезов, каждый из которых содержит информацию, связанную со значением измерения, по которому он был построен. Например, если выполнить сечение по значению ЗАО «Строитель» измерения Покупатель, то полученный в результате срез будет содержать информацию об истории продаж всех товаров данного предприятия, которую можно будет свести в плоскую таблицу. При необходимости ограничить информацию только одним товаром (например, керамзитом) потребуется выполнить еще одно сечение, но теперь уже по значению Керамзит измерения Товар. Результатом построения двух срезов будет информация о продажах одной фирме по одному товару. Манипулируя таким образом сечениями гиперкуба, пользователь всегда может получить информацию в нужном разрезе. Затем на основе построенных срезов может быть сформирована кросс-таблица и с ее помощью очень быстро получен необходимый отчет. Данная методика лежит в основе технологии OLAP-анализа.
На рис. 7 схематично представлены сечения гиперкуба. Слева сечение выполнено при некотором фиксированном значении измерения Дата. Полученный срез (светло-серая область) содержит информацию обо всех товарах и всех покупателях на определенную дату. На правом фрагменте рисунка получено два среза, пересечение которых будет содержать информацию обо всех покупателях, но на определенный товар и на определенную дату.
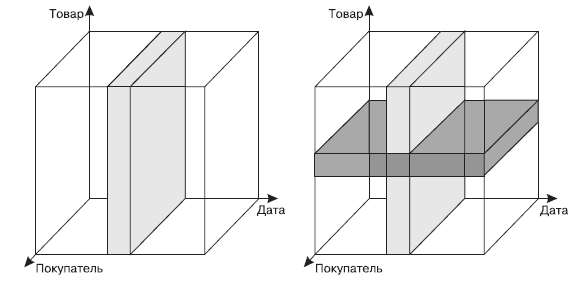
Рис. 7. Сечения гиперкуба
Транспонирование (вращение) обычно применяется к плоским таблицам, полученным, например, в результате среза, и позволяет изменить порядок представления измерений таким образом, что измерения, отображавшиеся в столбцах, будут отображаться в строках, и наоборот. В ряде случаев транспонирование позволяет сделать таблицу более наглядной.
Операции свертки (группировки) и детализации (декомпозиции) возможны только тогда, когда имеет место иерархическая подчиненность значений измерений. При свертке одно или несколько подчиненных значений измерений заменяются теми значениями, которым они подчинены. При этом уровень обобщения данных уменьшается. Так, если отдельные товары образуют группы, например Стройматериалы, то в результате свертки вместо отдельных наименований товаров будет указано наименование группы, а соответствующие им факты будут агрегированы. Проиллюстрируем результаты свертки: в табл. 2 представлена исходная таблица, а в табл. 3 — результат ее свертки по измерению Товар.
Таблица 2. Исходная таблица
|
Группа |
Товар |
Сумма |
|
Стройматериалы |
Кирпич |
22 000 |
|
Цемент |
12 000 | |
|
Керамзит |
4500 | |
|
Доска |
7400 | |
|
Инструмент |
Отвертка |
1200 |
|
Электропила |
7600 | |
|
Дрель |
2450 | |
|
Шпатель |
780 |
Таблица 3. Результат свертки исходной таблицы по измерению «Товар»
|
Группа |
Сумма |
|
Стройматериалы |
45 900 |
|
Инструмент |
12 030 |
Детализация — это процедура, обратная свертке; уровень обобщения данных уменьшается. При этом значения измерений более высокого иерархического уровня заменяются одним или несколькими значениями более низкого уровня, то есть вместо наименований групп товаров отображаются наименования отдельных товаров.
|
|
