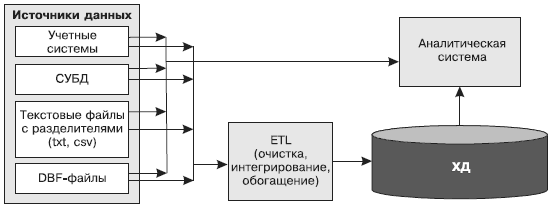
Рис. 30. Загрузка данных из локальных источников
Довольно часто возникают ситуации, когда данные для анализа приходится импортировать непосредственно из источников, минуя хранилища данных и другие промежуточные системы. Это может потребоваться в случае, когда организация отказалась от использования ХД или когда хранилище имеется, но данные из некоторых источников не могут быть в него загружены по техническим причинам, из-за несоответствия моделям и форматам данных, используемым в ХД.
Таким образом, часть данных поступает в аналитическую систему через ХД с соответствующей очисткой и подготовкой, а другая часть — непосредственно из источников (рис. 30).
Рис. 30. Загрузка данных из локальных источников
Извлечение данных напрямую из источников имеет свои преимущества и недостатки, а также порождает ряд проблем, связанных как непосредственно с процессом извлечения, так и с качеством полученных данных.
Главным преимуществом, которое дает использование хранилищ данных в аналитических технологиях, является повышение эффективности и достоверности анализа данных, особенно для поддержки принятия стратегических решений. Это достигается за счет оптимизации скорости доступа к данным, возможности интеграции данных различных форматов и типов, автоматической поддержки целостности и непротиворечивости, обеспечения хронологии и истории данных.
Тем не менее некоторые организации не используют хранилища данных для консолидации анализируемой информации. При необходимости выполнения анализа данные загружаются в аналитическое приложение непосредственно из источников, где они содержатся, а семантический слой обеспечивается средствами самого аналитического приложения.
Причины отказа от использования ХД могут быть следующими.
1. Организация не располагает достаточными ресурсами (финансовыми, техническими, кадровыми) для разработки, приобретения и поддержки ХД.
2. Унаследованная система аналитической обработки эффективно функционирует с использованием обычной реляционной СУБД, и руководство не видит смысла в дорогостоящем и трудоемком процессе внедрения ХД.
3. Объем анализируемых данных невелик, а применяемые технологии анализа данных несложны. В частности, не требуется поддержка хронологии данных, для анализа используются только данные за актуальный период и т.д.
4. Роль анализа в деятельности организации невысока, администрация не осознала его значимость в получении конкурентных преимуществ.
Таким образом, причин для отказа от использования ХД в аналитическом процессе достаточно много и все они могут быть по-своему аргументированы. В некоторых случаях отказ от ХД дает определенные преимущества: аналитический процесс становится проще и дешевле; нет необходимости разрабатывать концепцию его внедрения; не нужны сложный процесс ETL и другие сопутствующие затраты. Кроме того, процессы, связанные с поддержкой ХД, — интегрирование данных из различных источников и ETL, — если они недостаточно продуманы и некачественно реализованы, способны не только свести на нет все преимущества, которые дает ХД, но и ухудшить ситуацию, породив массу ошибок и проблем с получением данных. Возможно также, что лучше быстро реализовать аналитический процесс в упрощенном варианте, чем годами отлаживать взаимодействие OLTP-систем с ХД.
Отказ от использования ХД для консолидации и интегрирования данных не только снижает эффективность анализа, достоверность и значимость его результата, но и порождает ряд дополнительных проблем как технического, так и методического плана. Конечно, они присутствуют и при использовании ХД, но в этом случае они автоматически решаются самим хранилищем и поддерживающими его программными средствами. При осуществлении прямого доступа к источникам данных пользователь (эксперт, аналитик) вынужден сталкиваться с этими проблемами непосредственно. К таким проблемам относятся следующие.
Необходимость самостоятельно определять тип и формат источника данных. Узнать тип и формат файла можно по его расширению. Однако, если приходится иметь дело с экзотическим форматом или типом файла, этот вопрос может потребовать дополнительного исследования. Например, если речь идет о текстовом файле с разделителями, то TXT-формат известен любому, кто работал на компьютере, поскольку его освоение обычно начинается с создания простейших текстовых файлов. В то же время формат CSV в повседневной работе используется достаточно редко и поэтому большинству пользователей неизвестен. Кроме того, при загрузке данных из СУБД пользователь сталкивается с поиском нужной таблицы, что само по себе не очень сложно, но может занять определенное время.
Отсутствие полноценного семантического слоя того уровня, который имеется в ХД. При работе с ХД, которое обеспечивает семантический слой, преобразующий высокоуровневые запросы пользователей в низкоуровневые запросы к источникам данных, пользователь оперирует такими бизнес-терминами предметной области, как наименования товаров и клиентов, цена, количество, сумма, наценка, скидка и т.д. При работе с источниками данных напрямую аналитик вынужден иметь дело непосредственно с именами полей источника, которые в большинстве случаев вводятся на латинице и не всегда понятны, поэтому приходится тратить время на то, чтобы разобраться, в каком поле содержатся нужные данные.
Отсутствие жесткой поддержки структуры и форматов данных. При непосредственной работе с источниками данных часто приходится иметь дело с файлами, в которых структура и формат данных жестко не заданы. Типичный пример — текстовый файл с разделителями, в котором данные упорядочены в столбцы, отделенные друг от друга однотипными символами-разделителями. В таких файлах могут быть любые нарушения структуры и форматов данных. В них могут содержаться неполные поля и записи, использоваться различные символы — разделители столбцов, произвольные разделители целой и дробной частей и групп разрядов в числах. В одном и том же столбце могут оказаться и строковые, и числовые данные, различные форматы даты и т.д. Особенно это характерно для файлов, которые создавались без учета перспективы анализа данных. В подобной ситуации ничего не остается, кроме как попытаться выполнить корректировку данных средствами, имеющимися в аналитическом приложении. Иногда структура данных в файле оказывается настолько искаженной, что его загрузка в аналитическую систему невозможна. Тогда редактировать данные приходится непосредственно в источнике. И в том и в другом случае ручная корректировка данных является очень трудоемкой и затратной по времени. Если затраты на подготовку данных превышают их ценность с точки зрения анализа, то, возможно, от работы с ними следует вообще отказаться.
Отсутствие автоматических средств поддержки целостности, непротиворечивости и уникальности данных. Эта проблема главным образом возникает при работе с локальными файлами. При извлечении данных может произойти разрыв связей между атрибутами и, как следствие, потеря целостности данных.
Отсутствие средств автоматического агрегирования и создания новых данных. При использовании ХД предусмотрены автоматические агрегирование данных и расчет вычисляемых значений (обычно в процессе ETL). Эти новые данные сохраняются и остаются доступными в любой момент, что ускоряет выполнение аналитических запросов. Когда загрузка данных производится напрямую из источников, агрегирование и вычисление новых данных приходится делать непосредственно в ходе выполнения запросов либо вручную, что существенно снижает скорость работы.
Отсутствие средств автоматического контроля ошибок и очистки данных. Это приводит к тому, что в аналитическую систему загружаются «грязные» данные, зачастую непригодные для анализа, поэтому пользователь должен самостоятельно (визуально и с помощью статистических характеристик или специальных средств, если они доступны) оценить качество данных, степень их пригодности для анализа и применить необходимые методы очистки.
Необходимость настройки механизмов доступа к источникам данных. Для осуществления непосредственного доступа к различным источникам данных обычно используются стандартные механизмы доступа — ODBC, ADO и OLE DB. Чтобы указанные компоненты функционировали правильно, они должны быть соответствующим образом настроены, что также зачастую ложится на плечи пользователя или системного администратора.
Помимо недостатков, использование непосредственного доступа к источникам данных имеет ряд преимуществ.
Таким образом, необходимость в организации непосредственного доступа к различным источникам данных из аналитического приложения возникает даже при наличии ХД.
Наиболее часто встречающимися видами источников данных, доступ к которым производится напрямую, являются:
Текстовые файлы с разделителями (TXT, CSV). Файлы в TXT-формате хорошо известны большинству пользователей (даже непрофессиональных) еще со времен MS-DOS. Для создания таких файлов достаточно использовать простейший текстовый редактор, например Блокнот из набора стандартных программ Windows. Однако эти файлы имеют произвольную структуру данных, поэтому они наиболее уязвимы с точки зрения нарушения структуры, использования некорректных форматов и представлений данных. Так что загрузка и очистка TXT-файлов могут вызвать самые серьезные проблемы, несмотря на то что эти файлы очень просты в создании.
Чтобы создать структурированный текстовый файл, который может быть загружен в аналитическую систему, достаточно упорядочить в нем данные в виде вертикальных столбцов и горизонтальных строк, из которых будут сформированы поля и записи соответственно. Для разделения столбцов должны использоваться однотипные символы-разделители, например табуляция, точка с запятой и др. Можно использовать как один символ, так и несколько идущих подряд символов. При создании файла следует придерживаться нескольких правил.
1. В первой строке файла нужно указать заголовки столбцов в произвольной форме, при этом используются кириллица и пробелы. При загрузке в аналитическую систему заголовки столбцов будут преобразованы в метки полей, что позволит аналитику быстрее разобраться с содержимым источника. Поскольку в TXT-файлах имена полей (в том виде, как они представлены в таблицах файлов БД) отсутствуют, при загрузке в аналитическую систему они будут установлены автоматически в соответствии с правилами, принятыми в данной системе. Например, им по умолчанию могут быть присвоены метки COL1, COL2 или FIELD1, FIELD2 и т.д. Если в первой строке текстового файла над каждым столбцом указано его название, то система при загрузке сможет преобразовать эти названия в имена полей, если каким-либо образом указать, что первая строка содержит заголовки. Однако это возможно только при условии, что названия столбцов не противоречат правилам назначения имен полей в данной аналитической системе, то есть не содержат недопустимых символов, не превышают заданную длину и т.д. Это следует учитывать при создании текстовых файлов с разделителями, которые планируется использовать в качестве источников данных для аналитических систем.
2. Необходимо соблюдать регулярность структуры данных, то есть каждые строка и столбец должны содержать одинаковое число элементов. Если некоторые значения были утеряны, то их можно заменить средними значениями по столбцу для числовых атрибутов. Для строковых атрибутов можно указать наиболее вероятное значение или значение по умолчанию, которое впоследствии может быть соответствующим образом обработано (например, NONAME). Оставлять пустые или фиктивные значения нежелательно: пропущенное значение может заблокировать работу аналитических алгоритмов, а фиктивное (например, $999,999) может быть обработано как истинное.
3. Столбцы должны быть типизированы, то есть содержать данные только одного типа (например, только строковые или только числовые). Кроме того, внутри каждого столбца формат представления чисел или дат должен быть одинаковым. Например, использование в одном столбце краткого (12.07.06) и полного (12 июля 2006 г.) форматов даты способно вызвать серьезные проблемы при загрузке данных. Также нежелательно использовать в одном поле числа в экспоненциальном формате (1,2E + 3) и в обычном (12 000), поскольку это может вызвать проблемы при загрузке значений из данного поля.
4. Строковые значения желательно приводить в соответствие унифицированным шаблонам. Например, нежелательно смешивать представление ФИО, указывая инициалы то справа, то слева от фамилии или вообще не указывая, использовать в инициалах то одну, то две буквы и т.д. При указании названий организаций также нужно использовать единое представление. Например, форма собственности должна во всех строках указываться только после названия (это упростит сортировку названий по алфавиту). Несоблюдение этого требования, скорее всего, не вызовет проблем при загрузке, но может привести к неправильной обработке таких данных аналитическим приложением.
5. Символы-разделители и их количество во всех строках и между столбцами должны быть одинаковыми.
6. Необходимо использовать одинаковые разделители целой и дробной частей чисел и групп разрядов. Например, если по умолчанию в качестве разделителя целой и дробной частей используется точка, а в каком-то значении будет обнаружена запятая, это значение будет рассматриваться системой как строковое.
При загрузке в ХД все эти проблемы автоматически корректируются на этапе ETL. А при непосредственной загрузке пользователю приходится отслеживать эти проблемы самому. Если данных в источнике немного, то они могут быть откорректированы вручную. В противном случае приходится использовать средства очистки данных, предусмотренные в аналитической системе (например, восстановление пропущенных значений, трансформация типов и т.д.).
Чтобы настроить процесс импорта текстового файла с разделителями, обычно требуется указать:
Таким образом, чтобы правильно настроить параметры импорта текстового файла, нужно иметь информацию о файле, которая в большинстве случаев может быть получена только опытным путем. Для этого достаточно открыть файл с помощью текстового редактора, просмотреть структуру файла и при необходимости откорректировать ее (например, присвоить столбцам заголовки).
Текстовые файлы в формате CSV менее известны пользователям, поскольку используются реже, чем обычные TXT-файлы. CSV (от англ. ramma separated values — «значения, разделенные запятыми») — это специальный текстовый формат, предназначенный для представления табличных данных. Каждая строка в таком файле соответствует одной строке таблицы. Значения отдельных столбцов разделяются специальным символом — запятой или точкой с запятой. Используемый символ-разделитель зависит от настроек региональных стандартов. В США это запятая, а в России — точка с запятой, поскольку у нас запятая используется для разделения целой и дробной частей чисел (в отличие от США, где для этого служит точка). Файлы такого типа могут быть получены путем конвертации из любого табличного процессора.
Все свойства обычных текстовых файлов с разделителями, описанные выше, и рекомендации по их подготовке и загрузке в полной мере относятся к CSV-файлам. Но у CSV-файлов есть и ряд преимуществ.
Файлы «плоских» таблиц СУБД семейства dBase, FoxBase, FoxPro и т.д. имеют расширение DBF (database file). Как и файлы любых СУБД, DBF-файлы имеют жестко заданную структуру. В них строго определены имена и типы полей, структура полей и записей, используемые форматы представления данных. Следовательно, проблем с загрузкой данных из таких источников намного меньше по сравнению с текстовыми файлами, поскольку все возможные проблемы контролируются в процессе создания файла. СУБД не позволит присвоить полю некорректное имя, ввести в поле данные, не соответствующие его типу или использующие неправильный разделитель групп разрядов в числе, и т.д., поэтому ожидаемое качество данных, загружаемых из DBF-файлов, является более высоким, чем для текстовых.
При загрузке данных из DBF-файлов в аналитическую систему, как правило, достаточно указать их имя. В некоторых случаях требуется дополнительно указать версию СУБД (dBase III или dBase IV), а также кодовую страницу для корректного отображения символов.
Excel — одно из наиболее популярных офисных приложений, применяемых пользователями всех уровней, поэтому возможность загрузки данных из файлов в формате XLS предусмотрена практически в любой аналитической системе. Однако следует учитывать, что в одном столбце таблицы Excel могут содержаться данные различных типов и форматов, допускаться неправильное использование разделителей целой и дробной частей чисел и групп разрядов в них. В этом плане к ним следует относиться так же внимательно, как и к данным из текстовых файлов.
Файлы реляционных СУБД. Источники этого типа самые «желанные» для пользователей аналитических систем, поскольку с ними меньше всего проблем. Структура данных в файлах реляционных СУБД жестко задана, поля строго типизированы, форматы данных соответствуют стандартам. В большинстве СУБД поддерживается автоматический контроль целостности, непротиворечивости и уникальности данных. Для загрузки данных, например, из файла Access достаточно указать имя файла и таблицу, из которой нужно взять данные.
|
|
