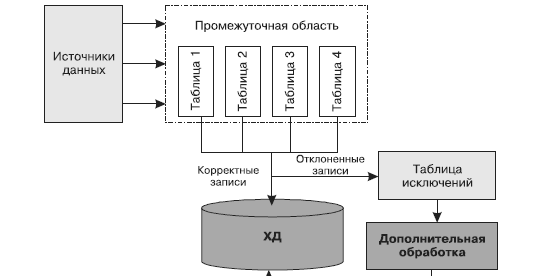
Рис. 28. Последовательность действий при наличии отклоненных записей в процедуре загрузки в ХД
После того как данные извлечены из различных источников и выполнены преобразование, агрегация и очистка данных, осуществляется последний этап ETL — загрузка данных в хранилище. Процесс загрузки заключается в переносе данных из промежуточных таблиц в структуры хранилища данных. От продуманности и оптимальности процесса загрузки данных во многом зависит время, требуемое для полного цикла обновления данных в ХД, а также полнота и корректность данных в хранилище.
Первыми в процессе загрузки данных в ХД обычно загружаются таблицы измерений, которые содержат суррогатные ключи и другую описательную информацию, необходимую для таблиц фактов.
При загрузке таблиц измерений требуется и добавлять новые записи, и изменять существующие. Например, измерение Клиент может содержать десятки тысяч клиентов, при этом информация меняется только для незначительного их числа (не более 10%). Нужно добавить данные о новых клиентах и одновременно модифицировать информацию о существующих.
При добавлении новых данных в таблицу измерений требуется определить, не существует ли в ней соответствующая запись. Если нет, то она добавляется в таблицу. В противном случае могут использоваться различные способы обработки изменений в зависимости от того, нужно ли поддерживать старую информацию в хранилище с целью ее последующего анализа. Например, если изменился только адрес клиента, то в большинстве случаев нет необходимости хранить старый адрес, поэтому запись может быть просто обновлена.
У быстро растущих компаний часто возникают новые регионы продаж. Например, если сначала регионом продаж была только Рязанская область, то впоследствии он может расшириться на весь Центральный федеральный округ (ЦФО) и далее на всю Российскую Федерацию. Если в ХД требуется хранить как старую географическую иерархию, так и обновленную, можно создать дополнительную таблицу измерений, записи которой будут содержать и старые географические данные, и новые. В качестве альтернативы можно добавить дополнительные поля в существующие таблицы, чтобы сохранить старую информацию и добавить новую.
При загрузке таблицы фактов новая информация обычно добавляется в конец таблицы, чтобы не изменять существующие данные.
Одной из основных проблем данного этапа ETL является то, что далеко не всегда данные загружаются полностью: в загрузке некоторых записей может быть отказано. Отклонение записей происходит по следующим причинам.
При появлении данных, попытка загрузки которых потерпела неудачу, необходимо предусмотреть следующие действия (рис. 28):
Рис. 28. Последовательность действий при наличии отклоненных записей в процедуре загрузки в ХД
Если и повторная попытка загрузки данных не увенчалась успехом, то в хранилище окажутся неполные данные, анализ которых может привести к неправильным выводам. Для решения этой проблемы можно:
При очередной загрузке в ХД переносится не вся информация из OLTP-системы, а только та, которая была изменена в течение промежутка времени, прошедшего с предыдущей загрузки. При этом можно выделить два вида изменений — добавление и обновление (дополнение).
Для обеспечения этих функций загружаемые данные распределяются по двум параллельным потокам (data flow) — потоку добавления и потоку обновления (рис. 29).
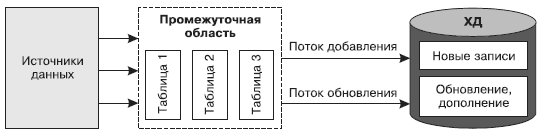
Рис. 29. Поток добавления и поток обновления
Для распределения загружаемых данных на потоки используются средства мониторинга изменений в данных. Они фиксируют состояние данных в некоторые моменты времени и определяют, какие данные были изменены или дополнены. Применяются следующие методы:
Распределение загружаемых данных на поток добавления и поток обновления позволяет выполнять перенос данных в хранилище с помощью обычных запросов, не используя какие-либо фильтры для разделения данных на новые и обновляющие.
Обновление данных должно производиться строго в соответствии с требованиями к обеспечению истории данных, то есть не должно приводить к потере уже существующих данных, за исключением особых случаев.
Следует отметить, что при разработке методики загрузки данных в ХД нет общего подхода к тому, как модифицировать таблицы измерений. Например, если изменилось описание некоторого продукта, придется создать новое поле в таблице, чтобы сохранить старое описание и добавить новое. Если требуется сохранить все старые описания продукта, то придется создавать новую запись для каждого изменения и назначать соответствующие ключи.
После завершения загрузки выполняются дополнительные операции над данными, только что загруженными в ХД, перед тем как сделать их доступными для пользователя. Такие операции называются постзагрузочными. К ним относятся переиндексация, верификация данных и т.д.
С точки зрения аналитика, наиболее важной задачей является верификация данных. Прежде чем использовать новые данные для анализа, полезно убедиться в их надежности и достоверности. Для этих целей можно предусмотреть комплекс верификационных тестов. Например:
Кроме того, может оказаться полезным сравнивать данные не только в различных разрезах после их загрузки в ХД, но и с источниками данных. Так, если значения какого-либо показателя в источнике и хранилище равны, то все нормально, в противном случае данные, возможно, некорректны.
Если тестирование показало, что несоответствия, позволяющие заподозрить потерю или недостоверность данных, отсутствуют, то можно считать загрузку данных в ХД успешной и приступать к анализу новой информации.
Когда тот или иной физик использует понятие "физический вакуум", он либо не понимает абсурдности этого термина, либо лукавит, являясь скрытым или явным приверженцем релятивистской идеологии.
Понять абсурдность этого понятия легче всего обратившись к истокам его возникновения. Рождено оно было Полем Дираком в 1930-х, когда стало ясно, что отрицание эфира в чистом виде, как это делал великий математик, но посредственный физик Анри Пуанкаре, уже нельзя. Слишком много фактов противоречит этому.
Для защиты релятивизма Поль Дирак ввел афизическое и алогичное понятие отрицательной энергии, а затем и существование "моря" двух компенсирующих друг друга энергий в вакууме - положительной и отрицательной, а также "моря" компенсирующих друг друга частиц - виртуальных (то есть кажущихся) электронов и позитронов в вакууме.
Однако такая постановка является внутренне противоречивой (виртуальные частицы ненаблюдаемы и их по произволу можно считать в одном случае отсутствующими, а в другом - присутствующими) и противоречащей релятивизму (то есть отрицанию эфира, так как при наличии таких частиц в вакууме релятивизм уже просто невозможен). Подробнее читайте в FAQ по эфирной физике.
|
|
