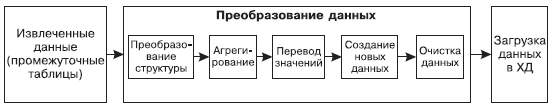
Рис. 26. Процесс преобразования данных в ETL Рассмотрим каждую из этих операций более детально.
Этап ETL-процесса, следующий за извлечением, — преобразование данных. Его цель — подготовка данных к размещению в ХД и приведение их к виду, наиболее удобному для последующего анализа. При этом должны учитываться некоторые выдвигаемые аналитиком требования, в частности, к уровню качества данных. Поэтому в процессе преобразования может быть задействован самый разнообразный инструментарий, начиная от простейших средств ручного редактирования данных до систем, реализующих весьма сложные методы обработки и очистки данных.
В процессе преобразования данных в рамках ETL чаще всего выполняются следующие операции (рис. 26):
Рис. 26. Процесс преобразования данных в ETL Рассмотрим каждую из этих операций более детально.
Во многих случаях данные поступают в хранилище, интегрируясь из множества источников, которые создавались с помощью различных программных средств, методологий, соглашений, стандартов и т.д. Данные из таких источников могут отличаться своей структурной организацией: соглашениями о назначении имен полей и таблиц, порядком их описания, форматами, типами и кодировкой данных, например точностью представления числовых данных, используемыми разделителями целой и дробной частей, разделителями групп разрядов и т.д. Следовательно, во многих случаях извлеченные данные непригодны для непосредственной загрузки в ХД из-за отличия их структуры от структуры соответствующих целевых таблиц ХД.
При этом если таблицы фактов чаще всего соответствуют требованиям ХД, то таблицы измерений нуждаются в дополнительной обработке и, может быть, объединении.
Так, если в источнике, полученном из одного филиала, информация о покупателях хранится в поле Customer_Id, а в источнике, полученном из другого филиала, — в поле Clients_Name, то для создания одного измерения Покупатель придется решать задачу их объединения.
Дополнительная обработка структуры данных также требуется в ситуации, когда одно подразделение фирмы представляет информацию о цене и количестве проданных товаров, а другое — о количестве товаров и общей сумме продаж. В таком случае потребуется привести информацию о продажах, полученную из обоих источников, к общему виду.
Как правило, в качестве источников данных для хранилищ выступают системы оперативной обработки данных (OLTP-системы), учетные системы, файлы различных СУБД, локальные файлы отдельных пользователей и т.д. Общим свойством всех этих источников является то, что они содержат данные с максимальной степенью детализации — сведения о ежедневных продажах или даже о каждом факте продажи в отдельности, об обслуживании каждого клиента и т.д. Распространено мнение, что такое детальное воспроизведение событий в исследуемом бизнес-процессе только пойдет на пользу, поскольку данные никогда не бывают лишними и чем больше их будет собрано, тем точнее окажутся результаты анализа.
Это не совсем так. Элементарные события, из которых состоит бизнес-процесс, например обслуживание одного клиента, выполнение одного заказа и т.д., которые также называют атомарными (то есть неделимыми), по своей сути являются случайными величинами, подверженными влиянию множества различных случайных факторов — от погоды до настроения клиента. Следовательно, информация о каждом отдельном событии в бизнес-процессе практически не имеет ценности. Действительно, на основании информации о продажах за один день нельзя сделать вывод обо всех особенностях торговли. Точно так же нельзя выработать стратегию работы с клиентами на основе исследования поведения одного клиента.
Иными словами, для достоверного описания предметной области использование данных с максимальным уровнем детализации не всегда целесообразно, поэтому наибольший интерес для анализа представляют данные, обобщенные по некоторому интервалу времени, по группе клиентов, товаров и т.д. Такие обобщенные данные называются агрегированными (иногда агрегатами), а сам процесс их вычисления — агрегированием.
В результате агрегирования большое количество записей о каждом событии в бизнес-процессе заменяется относительно небольшим количеством записей, содержащих агрегированные значения. Например, вместо информации о каждой из 365 ежедневных продаж в году в результате агрегирования будут храниться 52 записи с обобщением по неделям, 12 — по месяцам или 1 — за год. Если цель анализа — разработка прогноза продаж, то для краткосрочного оперативного прогноза достаточно использовать данные по неделям, а для долгосрочного стратегического прогноза — по месяцам или даже по годам.
Фактически при агрегировании производится объединение нескольких записей в одну с вычислением агрегированного значения на основе значений каждой записи. При вычислении агрегатов может быть использовано несколько способов. □ Среднее — для данных, расположенных в пределах интервала, в котором они обобщаются, вычисляется среднее значение. Затем все записи из данного интервала заменяются одной, содержащей их среднее значение (рис. 27).
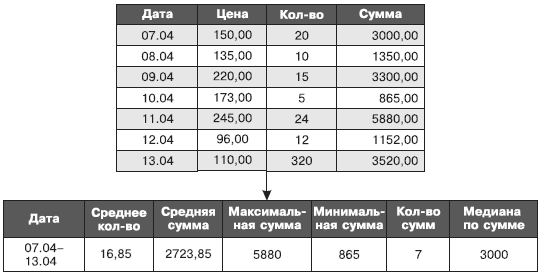
Рис. 27. Пример агрегирования
Закономерен вопрос: нужно ли агрегировать все данные без разбору по всем возможным уровням обобщения или к этому следует подходить внимательно? Для ответа необходимо изучить наиболее вероятные направления использования данных в ХД. Однако если хранилище находится на стадии разработки и внедрения и методика его использования еще не до конца проработана, то сделать это трудно. Тем не менее, если опросить потенциальных пользователей ХД, что именно они хотят получить, возможно, некоторые сведения на этот счет удастся разыскать.
Из всех возможных вариантов агрегирования следует выбрать наиболее значимые с точки зрения планируемых направлений анализа, а от остальных отказаться. Очевидно, можно отказаться от агрегатов, которые имеют малое число подчиненных агрегированных значений (например, агрегирование ежемесячных продаж за квартал), поскольку их легко вычислить в процессе анализа. Или, наоборот, можно отказаться от агрегатов с максимальной степенью детализации (например, агрегирование ежедневных продаж). Второй вариант наиболее предпочтителен, поскольку на первый взгляд сулит существенную экономию, так как число дней в году умножается на число товаров и продавцов. Однако если данные о продажах являются разреженными, то есть не каждый товар продается ежедневно, то экономия может оказаться весьма незначительной.
Выбор нужных агрегатов всегда определяется особенностями бизнеса. При этом следует помнить, что агрегаты, требуемые для анализа, могут быть вычислены и непосредственно при выполнении аналитического запроса к ХД, хотя тем самым время его выполнения несколько увеличится. Подобный подход позволяет, например, отказаться от агрегирования редко используемых данных.
Таким образом, выбор правильной стратегии агрегирования данных в ETL — сложная и противоречивая задача. Увеличение числа агрегатов в ХД приводит к увеличению его размеров и сложности структуры данных. Снижение числа агрегатов в ХД может привести к необходимости их вычисления в процессе выполнения аналитических запросов, что увеличит время ожидания пользователя. Следовательно, необходимо обеспечить разумный компромисс между этими факторами. Существует и более простое правило, определяющее стратегию агрегирования: создавайте только те агрегаты, которые с большой долей вероятности понадобятся при анализе данных.
Часто данные в источниках хранятся с использованием специальных кодировок, которые позволяют сократить избыточность данных и тем самым уменьшить объем памяти, требуемой для их хранения. Так, наименования объектов, их свойств и признаков могут храниться в сокращенном виде. В этом случае перед загрузкой данных в хранилище требуется выполнить перевод таких сокращенных значений в более полные и, соответственно, понятные.
Например, согласно заведенному в организации порядку идентификационный номер операции может быть закодирован в виде 06–04–12–62, где 06–04 — число и месяц, 12 — код товара, 62 — код региона. Такое представление позволяет хранить данные очень компактно. Однако для заполнения соответствующих измерений в многомерной модели запись необходимо декодировать.
Кроме того, часто возникает необходимость конвертировать числовые данные, например преобразовать вещественные в целые, уменьшить избыточную точность представления чисел, использовать экспоненциальный формат и т.д.
В процессе загрузки в ХД может понадобиться вычисление некоторых новых данных на основе существующих, что обычно сопровождается созданием новых полей. Например, OLTP-система содержит информацию только о количестве и цене проданного товара, а в целевой таблице ХД есть поле Сумма. Тогда в процессе преобразования необходимо вычислить сумму как произведение цены на количество проданных единиц товара. Таким образом, будет создано поле, содержащее новую информацию.
Еще одним возможным примером новых данных, создаваемых в процессе обработки, являются экономические, финансовые и другие показатели, которые могут быть вычислены на основе имеющихся данных. Так, на основе данных о продажах можно рассчитать рейтинг популярности товаров и создать новое поле, в котором для каждого товара будет указано соответствующее рейтинговое значение (например, по пятибалльной системе).
Создание новой информации на основе имеющихся данных тесно связано с таким важным процессом, как обогащение данных, которое может производиться (частично или полностью) на этапе преобразования данных в ETL. Агрегирование также может рассматриваться как создание новых данных.
Сбор данных в процессе ETL производится из большого числа источников, многие из которых не содержат автоматических средств поддержки целостности, непротиворечивости и корректного представления данных. В связи с этим при переносе информации в ХД приходится сталкиваться с потоками «грязных» данных, которые могут стать причиной неправильных результатов анализа и даже сделать невозможным применение некоторых аналитических алгоритмов и методов. По этой причине в процессе ETL применяется очистка — процедура корректировки данных, которые в каком-либо смысле не удовлетворяют определенным критериям качества, то есть содержат нарушения структуры данных, противоречия, пропуски, дубликаты, неправильные форматы и т.д.
Некоторые проблемы в данных являются критичными и даже не позволяют выполнить загрузку данных в ХД (как правило, это нарушения структуры и некорректные форматы данных). Другие проблемы менее критичны, не мешают переносу данных в ХД, но не позволяют их корректно анализировать (пропуски, противоречия и дубликаты). Критичные проблемы в данных должны устраняться непосредственно в процессе ETL. Некритичные факторы, снижающие качество данных, могут устраняться как в процессе ETL, так и при подготовке их к анализу в аналитической системе.
Очистка данных — одна из наиболее важных и в то же время наиболее сложных и трудно поддающихся формализации задач ETL-процесса, поскольку набор факторов, снижающих качество данных, весьма разнообразен и может постоянно меняться. Поэтому очистке данных при разработке ETL-процессов уделяют большое внимание.
В принципе, преобразование данных может быть выполнено на любом этапе ETL-процесса. Но иногда требуется выбрать оптимальное место для осуществления преобразования. Некоторые виды преобразований удобнее выполнять «на лету», в процессе извлечения данных из источника, другие — в промежуточной области, третьи — в процессе загрузки данных в ХД. Рассмотрим преимущества и недостатки этих вариантов.
Таким образом, все операции преобразования, которые могут потребоваться при переносе данных в ХД, обычно не сосредотачиваются на одном шаге ETL-процесса, а распределяются по различным этапам в зависимости от того, где выполнение преобразования более эффективно.
|
|
