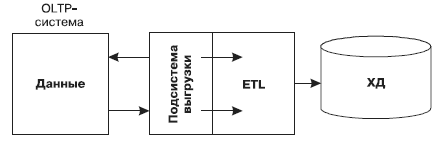
Рис. 23. Первый способ извлечения данных в ETL
Начальным этапом процесса ETL является процедура извлечения записей из источника данных и подготовка содержащейся в них информации к процессу преобразования.
При разработке процедуры извлечения данных в первую очередь необходимо определить регламент загрузки ХД и соответственно частоту выгрузки данных из OLTP-систем или отдельных источников. Например, выгрузка может производиться по истечении заданного временного интервала (день, неделя, месяц или квартал). В некоторых случаях предусматривается возможность внерегламентного извлечения данных после завершения определенного бизнес-события (приобретение нового бизнеса, открытие филиала, поступление большой партии товаров). В зависимости от объема извлекаемых данных, сложности доступа к ним и скорости работы оборудования, выгрузка данных занимает определенное время, которое так и называют — «окно выгрузки». Очевидно, что в течение «окна выгрузки» резко увеличивается нагрузка на компьютерную сеть организации и ее работа может оказаться частично или полностью парализованной. Особенно это актуально для OLTP-систем, где в такие периоды может резко возрасти время ожидания отклика. Поэтому «окно выгрузки» стараются выбрать так, чтобы оно в минимальной степени влияло на рабочий процесс, например в обеденный перерыв, сразу по завершении рабочего дня или ночью.
Если выгрузку данных производить более часто, то, с одной стороны, количество «окон загрузки» увеличивается, но поскольку за меньший период в OLTP-системе накапливается меньше изменений, то «окна загрузки» становятся короче и нагрузка на систему — ниже.
Процедуру извлечения можно реализовать двумя основными способами.
1. Извлечение данных с помощью специализированных программных средств (рис. 23).
Рис. 23. Первый способ извлечения данных в ETL
Преимущества данного способа заключаются в том, что использование специализированных программ позволяет, во-первых, избежать необходимости оснащать OLTP-системы средствами выгрузки, во-вторых, учитывать особенности всего ETL-процесса уже в процессе выгрузки. В случае, когда данные извлекаются из локальных источников (отдельных документов, таблиц и т.д.), альтернативы использованию специальных средств нет, поскольку такие виды источников данных не содержат средств выгрузки данных.
2. Извлечение данных средствами той системы, в которой они хранятся (рис. 24).
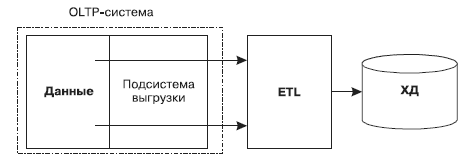
Рис. 24. Второй способ извлечения данных в ETL
Поскольку средства «самовыгрузки» разрабатываются с учетом особенностей структуры данных OLTP-системы, это позволяет адаптировать процедуру извлечения к структуре извлекаемых данных, что в ряде случаев делает процесс более эффективным.
После извлечения данные помещаются в так называемую промежуточную область, где для каждого источника данных создается своя таблица или отдельный файл (или и то и другое). В некоторых случаях, когда требуется выгрузить данные из нескольких источников одного типа, для них создается общая таблица; одно из ее полей указывает на источник, из которого были взяты данные. Пример подобной схемы организации выгрузки приведен на рис. 25.
Чтобы начать процесс извлечения данных, в общем случае необходимо использовать некоторую служебную информацию:
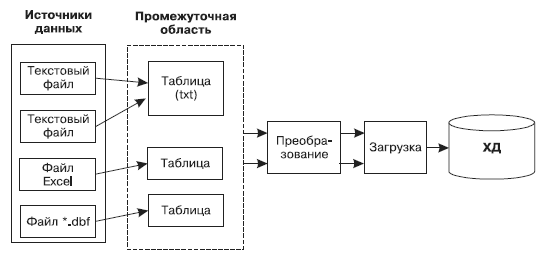
Рис. 25. Схема организации ETL
Перед тем как приступить к процессу извлечения данных, необходимо определить, в каких именно источниках хранятся данные, которые должны попасть в хранилище. Все источники можно разделить на две группы — расположенные в корпоративных информационных системах и на локальных компьютерах отдельных пользователей. С точки зрения соблюдения регламента и периодичности загрузки данных в ХД предпочтительны источники из первой группы, поскольку они также функционируют в соответствии с определенным порядком, который проще согласовать с периодичностью загрузки данных в хранилище. Что касается источников на локальных ПК, то обычно никаких сколь-нибудь строгих правил работы с ними не устанавливается: пользователи включают и выключают компьютеры, когда хотят; постоянно возникают те или иные проблемы с сетью и т.д. Тем не менее именно на локальных компьютерах часто собирается очень ценная для анализа информация. Поэтому при выборе источников данных для загрузки в ХД необходимо учитывать следующие факторы:
Как правило, приходится искать компромисс между этими факторами. Например, данные могут представлять несомненную ценность для анализа, но сложность их извлечения или некорректность структуры может свести на нет все преимущества от их использования. В другом случае данные легкодоступны и не требуют дополнительной обработки при загрузке в ХД, но при этом практически не представляют интереса с точки зрения анализа.
После того как источники, из которых будут извлекаться данные, выбраны, необходимо определить, все ли имеющиеся в источниках данные нужны в ХД.
Если извлекать нужно не все записи подряд, а только определенные, аналитик может описать набор условий, которые позволят отобрать только записи, представляющие интерес. Например, можно поставить условие, что записи, которые содержат информацию о продажах на сумму меньше заданной, извлекать и помещать в ХД не нужно, поскольку их ценность с точки зрения результатов анализа ничтожна.
Пример
Легко представить, что посетитель супермаркета зашел туда случайно: не для покупки товара, а чтобы переждать дождь, встретиться с кем-то, помочь донести сумки и т.д. При этом он приобретает коробку спичек, авторучку или другую мелочь, которую мог купить и на обычном уличном лотке. Однако даже для спичечного коробка пробивается чек и создается соответствующая запись в регистрирующей системе. И запись о покупке спичечного коробка за 50 коп. требует места на диске или в памяти не меньше, чем о продаже бутылки коньяка за 1000 руб. В результате после агрегирования данных о продажах за день по отделу выясняется, что зарегистрировано 100 продаж, которые дали в сумме 300 руб., и 10 продаж на общую сумму 15 000 руб. Возникает вопрос: нужно ли тратить время на обработку и хранение огромного количества записей, вклад которых в результат анализа будет ничтожен. Более того, включение в анализ информации о мелких покупках, сделанных случайными клиентами, может только помешать, например, построению модели поведения постоянных клиентов. Поэтому аналитик может задать условие, что извлекаться должны лишь те записи, в которых значение поля «Сумма» не менее 20 руб.
Другой важный момент — определение глубины выгрузки данных по времени. Очевидно, что все записи понадобятся только при первичном заполнении хранилища. В процессе его пополнения из источников должны извлекаться лишь те записи, которые добавлялись или изменялись после прошлого извлечения. Иногда хранилища полностью очищают и перезагружают. Но это возможно только в случае, если ХД не очень большое и процесс регенерации занимает не слишком много времени, а также если регенерация происходит редко и за промежуток времени между ними большая часть данных изменяется или утрачивает актуальность.
Вопрос определения глубины выгрузки актуален только при начальной загрузке хранилища, когда требуется определить, информация за какой период времени является актуальной. В простейшем случае, когда никаких соображений на этот счет нет, можно загрузить все имеющиеся записи. Однако этот подход не всегда оптимален, поскольку в хранилище может оказаться много информации, не представляющей ценности для анализа в связи с потерей актуальности. Таким образом, выбор глубины выгрузки исторических данных должен обеспечить компромисс между объемом выгружаемых данных и их ценностью с точки зрения анализа.
Процедура определения глубины выгрузки облегчается, если в источнике данных присутствует поле, в котором указывается время создания и изменения каждой записи. В этом случае отбирать извлекаемые записи по времени можно с помощью несложного фильтра.
При повторных загрузках ХД важно не только определить глубину выгрузки, но и организовать поиск измененных данных вообще. Для этой цели разработаны различные методики, например использование меток времени. Для каждой измененной записи создается метка, указывающая на время изменения, и при очередной выгрузке извлекаются только те записи, метки времени которых созданы позднее прошлого извлечения.
Если источником данных является реляционная СУБД, то часто используются так называемые триггеры (triggers) — специальные процедуры, запускаемые автоматически при выполнении операций вставки, обновления или удаления. Триггеры позволяют сохранять измененные записи в специальной таблице (таблице изменений), из которой они могут быть извлечены при следующей выгрузке. Однако использование триггеров существенно увеличивает нагрузку на систему, поэтому, если система уже работает с большой нагрузкой, к применению триггеров надо подходить осторожно.
Процесс извлечения данных в рамках ETL существенно зависит от типов и структуры источников данных. Можно выделить три разновидности источников данных, с которыми чаще всего сталкиваются организаторы аналитических проектов.
Базы данных (SQL Server, Oracle, Firebird, Access и т.д.). В большинстве случаев извлечение данных из баз данных не вызывает проблем, поскольку структура данных в них жестко задана, соответствует определенным стандартам и общепринятым требованиям. Кроме того, во многих СУБД предусмотрен автоматический контроль за целостностью и непротиворечивостью данных.
Структурированные файлы различных форматов. Такие файлы очень широко распространены, поскольку средства их создания (в большинстве случаев это типовые офисные приложения) общедоступны и не требуют высокой квалификации персонала и высокой производительности систем. К таким источникам относятся текстовые файлы с разделителями, файлы электронных таблиц (например, Excel, CSV-файлы, HTML-документы и т.д.). Здесь проблем больше, поскольку пользователь может допускать ошибки, пропуски, вводить противоречивые данные, терять фрагменты данных и т.д. Пользователи офисных приложений часто понятия не имеют о том, что такое тип данных, и уж тем более не связывают вводимые ими данные с задачами будущего анализа. Очевидно, что в этой ситуации при извлечении данных можно столкнуться с чем угодно. Единственным плюсом является то, что для доступа к типовым структурированным данным можно применять такие стандартные средства, как ODBC и ADO.
Неструктурированные источники. Как правило, эта ситуация требует особого внимания. Если избежать использования неструктурированных источников не получается, нужно применить специальные средства их преобразования в структурированный вид. Когда источник невелик, возможно, это удастся сделать вручную. Но в большинстве случаев приходится разрабатывать специальный инструментарий, учитывающий особенности организации данных в источнике и то, какую структуру из них следует создать. Существуют также готовые программные системы для решения этой задачи. Конечная цель структурирования — так упорядочить данные в файле, чтобы их в том или ином виде можно было загрузить в реляционную таблицу.
Таким образом, извлечение данных из OLTP-систем, СУБД и отдельных структурированных источников в рамках ETL-процесса может оказаться задачей достаточно сложной в техническом плане и важной для эффективного анализа данных. Поэтому разработкой и организацией процесса извлечения данных должны заниматься как технические специалисты, так и аналитики.
Вещество и поле не есть что-то отдельное от эфира, также как и человеческое тело не есть что-то отдельное от атомов и молекул его составляющих. Оно и есть эти атомы и молекулы, собранные в определенном порядке. Также и вещество не есть что-то отдельное от элементарных частиц, а оно состоит из них как базовой материи. Также и элементарные частицы состоят из частиц эфира как базовой материи нижнего уровня. Таким образом, всё, что есть во вселенной - это есть эфир. Эфира 100%. Из него состоят элементарные частицы, а из них всё остальное. Подробнее читайте в FAQ по эфирной физике.
|
|
