Задача поиска ассоциативных правил предполагает отыскание частых наборов в
большом числе наборов данных. В контексте анализы рыночной корзины это поиск
наборов товаров, которые наиболее часто покупаются вместе. В задаче не
учитывался такой атрибут транзакции как время. Тем не менее, взаимосвязь событий
во времени также представляет большой интерес. Основываясь на том, какие
события чаще всего следуют за другими, можно заранее предсказывать их появление,
что позволит принимать более правильные решения.
Отличие поиска
ассоциативных правил от секвенциального анализа (анализа последовательностей) в
том, что в первом случае ищется набор объектов в рамках одной транзакции, т.е.
такие товары, которые чаще всего покупаются ВМЕСТЕ. В одно время, за одну
транзакцию. Во втором же случае ищутся не часто встречающиеся наборы, а часто
встречающиеся последовательности. Т.е. в какой последовательности покупаются
товары или через какой промежуток времени после покупки товара "А", человек
наиболее склонен купить товар "Б". Т.е. данные по одному и тому же клиенту, но
взятые из разных транзакций.
Получаемые закономерности в действиях покупателей можно использовать для
формирования более выгодного предложения, стимулирования продаж определённых
товаров, управления запасами и т.п. Секвенциальный анализ актуален и для
телекоммуникационных компаний. Основная проблема, для решения которой он
используется, - это анализ данных об авариях на различных узлах
телекоммуникационной сети. Информация о последовательности совершения аварий
может помочь в обнаружении неполадок и предупреждении новых
аварий.
Введём некоторые обозначения и определения.
D - множество всех транзакций T, где каждая транзакция характеризуется
уникальным идентификатором покупателя, временем транзакции и идентификатором
объекта (id товара);
I - множество всех объектов (товаров) общим числом m;
si - набор, состоящий
из элементов множества I;
S - последовательность, состоящая из различных наборов si;
Дальнейшие рассуждения строятся на том, что в любой случайно выбранный момент
времени у покупателя не может быть более одной транзакции. Шаблон
последовательности - это последовательность наборов, которая часто
встречается в транзакциях (в определённом порядке). Последовательность<
a1,a2,...,an >
является входящей в последовательность <
b1,b2,...,bn >
, если существуют такие i1 <
i2 < ... < in, при
которых . Например,
последовательность <(3)(6,7,9)(7,9)> входит в
<(2)(3)(6,7,8,9)(7)(7,9)>, поскольку . Хотя
последовательность <(2)(3)> не входит в <(2,3)>, так как исходная
последовательность говорит о том, что "3" был куплен после "2", а вторая, что
товары "2" и "3" были куплены вместе. В приведённом примере цифрами
обозначены идентификаторы товаров. В ходе анализа последовательностей нас
будут интересовать такие последовательности, которые не входят в более длинные
последовательности. Подержка последовательности - это отношение числа
покупателей, в чьих транзакциях присутствует указанная последовательность к
общему числу покупателей. Также как и в задаче поиска ассоциативных правил
применяется минимальная и максимальная поддержка. Минимальная поддержка
позволяет исключить из рассмотрения последовательности, которые не являются
частыми. Максимальная поддержка исключает очевидные закономерности в появлении
последовательностей. Оба параметра задаются пользователем до начала работы
алгоритма.
Алгоритм AprioriALL
Существует большое число разновидностей алгоритма Apriori, который изначально
не учитывал временную составляющую в наборах данных. Первым алгоритмом
на основе Apriori, позволившим находить закономерности в последовательностях
событий, стал предложенный в 1995 году ( Argwal и Srikant ) алгоритм
AprioriALL. Данный алгоритм, также как другие усовершенствования Apriori
основывается на утверждении, что последовательность, входящая в часто
встречающуюся последовательность, также является часто встречающейся. Формат
данных, с которыми работает алгоритм уже был описан выше. Это таблица транзакций
с тремя атрибутами (id клиента, время транзакции, id товаров в
наборе). Работа алгоритма состоит из нескольких фаз. Фаза
сортировки заключается в перегруппировке записей в таблице транзакций.
Сперва записи сортируются по уникальному ключу покупателя, а затем по времени
внутри каждой группы. Пример отсортированной таблицы приведён ниже.
Идентификатор покупателя
Время транзакции
Идентификаторы купленных товаров
1
Окт 23 08
30
1
Окт 28 08
90
2
Окт 18 08
10, 20
2
Окт 21 08
30
2
Окт 27 08
40, 60, 70
3
Окт 15 08
30, 50, 70
4
Окт 8 08
30
4
Окт 16 08
40, 70
4
Окт 25 08
90
5
Окт 20 08
90
Фаза отбора кандидатов - в исходном наборе данных производится
поиск одно-элементных последовательностей в соответствии со значением
минимальной поддержки. Предположим, что значение минимальной поддержки 40%.
Обратим внимание, что поддержка рассчитывается не из числа транзакций, в
которые входит одно-элементная последовательность (в данном случае это есть
набор), но из числа покупателей у которых во всех их транзакциях встречается
данная последовательность. В результате получим следующие одно-элементные
последовательности.
Последовательности
Идентификатор последовательности
(30)
1
(40)
2
(70)
3
(40, 70)
4
(90)
5
Фаза трансформации. В ходе работы алгоритма нам многократно
придётся вычислять, присутствует ли последовательность в транзакциях покупателя.
Последовательность может быть достаточно велика, поэтому, для ускорения процесса
вычислений, преобразуем последовательности, содержащиеся в транзакциях
пользователей в иную форму. Заменим каждую транзакцию набором одно-элементных
последовательностей, которые в ней содержатся. Если в транзакции отсутствуют
последовательности, отобранные на предыдущем шаге, то данная транзакция не
учитывается и в результирующую таблицу не попадает. Например, для покупателя
с идентификатором 2, транзакция (10, 20) не будет преобразована, поскольку не
содержит одно-элементных последовательностей с нужным значением минимальной
поддержки (данный набор встречается только у одного покупателя). А транзакция
(40, 60, 70) будет заменена набором одно-элементных последовательностей {(40),
(70), (40, 70)} Процесс преобразованная будет иметь следующий вид.
Идентификатор покупателя
Последовательности в покупках
Отобранные последовательности
Преобразованные последовательности
1
<(30)(90)>
<{(30)}{(90)}>
<{1}{5}>
2
<(10, 20)(30)(40, 60, 70)>
<{(30)}{(40)(70)(40, 70)}>
<{1}{2, 3, 4}>
3
<(30, 50, 70)>
<{(30)(70)}>
<{1, 3}>
4
<(30)(40, 70)(90)>
<{(30)}{(40)(70)(40, 70)}{(90)}>
<{1}{2, 3, 4}{5}>
5
<(90)>
<{(90)}>
<{5}>
Фаза генерации последовательностей - из полученных на предыдущих
шагах последовательностей строятся более длинные шаблоны
последовательностей. Фаза максимизации - среди имеющихся
последовательностей находим такие, которые не входят в более длинные
последовательности. Проиллюстрируем две последние фазы на примере. Пусть
после фазы трансформации имеется таблица с последовательностями покупок для пяти
покупателей.
<{1,5}{2}{3}{4}>
<{1}{3}{4}{3,5}>
<{1}{2}{3}{4}>
<{1}{3}{5}>
<{4}{5}>
Значение минимальной поддержки выберем 40% (последовательность должна
наблюдаться как минимум у двоих покупателей из пяти). После фазы отбора
кандидатов мы получили таблицу с одно-элементными последовательностями.
1-Последовательность L1
Поддержка
<1>
4
<2>
2
<3>
4
<4>
4
<5>
4
В фазе генерации последовательностей из исходных одно-элементных
последовательностей сгенерируем двух-элементные и посчитаем для них поддержку.
Оставим только те, поддержка которых больше минимальной. После этого сгенерируем
трёх, четырёх и т.д. элементные последовательности, пока это будет
возможно.
2-Последовательность L2
Поддержка
<1 2>
2
<1 3>
4
<1 4>
3
<1 5>
3
<2 3>
2
<2 4>
2
<3 4>
3
<3 5>
2
<4 5>
2
3-Последовательность L3
Поддержка
<1 2 3>
2
<1 2 4>
2
<1 3 4>
3
<1 3 5>
2
<2 3 4>
2
4-Кандидаты
4-Последовательность L4
Поддержка
<1 2 3 4>
<1 2 3 4>
2
<1 2 4 3>
<1 3 4 5>
<1 3 5 4>
Последовательность <1 2 4 3>, например, не проходит отбор,
поскольку последовательность <2 4 3>, входящая в неё, не присутствует в
L3. Так как сформировать
пяти-элементные последовательности невозможно, работа алгоритма на этом
завершается. Результатом его работы будут три последовательности,
удовлетворяющие значению минимальной поддержки и не входящие в более длинные
последовательности: <1 2 3 4>, <1 3 5> и <4 5>. Алгоритм в
пcевдо-коде. L1 =
{одно-элементные последовательности, удовлетворяющие минимальному значению
поддержки} //Результат фазы отбора кандидатов (L-itemset) for (k=2;
; k++)
begin
Ck = Генерация
кандидатов из Lk − 1
foreach последовательность покупок с клиента в базе данных
do
Увеличить на единицу поддержку всех кандидатов из Ck, которые содержатся в
c
Lk = Кандидаты из
Ck с минимальной
поддержкой.
end
Результат: последовательности максимальной длинны (не входящие в другие
последовательности) в ; Процедура
генерации кандидатов выполняется следующим образом: insert intoCk selectp.itemset1,...,p.itemsetk
−
1,q.itemsetk
− 1 fromLk −
1p,Lk − 1q where; После чего
удалить все последовательности , такие что (k-1)
последовательность из c не входит в Lk − 1.
Алгоритм GSP
Ограничения AprioriAll Рассмотренный алгоритм AprioriAll позволяет
находить взаимосвязи в последовательностях данных. Это стало возможно после
введения на множестве наборов данных отношения порядка (в примере с анализом
покупок стало учитываться время транзакции). Тем не менее, AprioriAll не
позволяет определить характер взаимосвязи, её силу. При поиске зависимостей
в данных нас могут интересовать только такие, где одни события наступают вскоре
после других. Если же этот промежуток времени достаточно велик, то такая
зависимость может не представлять значения. Проиллюстрируем сказанное на
примере. Книжный клуб скорее всего не заинтересует тот факт, что человек,
купивший "Основание" Азимова, спустя три года купил "Основатели и Империя". Их
могут интересовать покупки, интервал между которыми составляет, например, три
месяца. Каждая совершённая покупка - это элемент последовательности.
Последовательность состоит из одного и более элементов. Во многих случаях не
имеет значения, если бы наборы товаров, содержащиеся в элементе
последовательности, входили не одну покупку (транзакцию), а составляли бы
несколько покупок. При условии, что время транзакций (покупок) укладывалось бы в
определённый интервал времени (окно). Например, если книжный клуб установит
значение окна равным одной неделе, то клиент, заказавший "Основание" в
понедельник, "Мир-Кольцо" в субботу, и затем "Основатели и Империя" и "Инженеры
Мира-Кольцо" (последние две книги в одном заказе) в течении недели, по-прежнему
будет поддерживать правило 'Если "Основание" и "Мир-Кольцо", то "Основатели и
Империя" и "Инженеры Мира-Кольцо"'. Ещё одним ограничением алгоритма
AprioriAll является отсутствие группировки данных. Алгоритм не учитывает их
структуру. В приведённом выше примере можно было бы находить правила,
соответствующие не отдельным книгам, а также авторам или литературным
жанрам.
Описание входных данных и другие определения Множество
объектов данных обозначим как I =
i1,i2,...,im.
Пусть T - ориентированный граф на множестве I, задающий
таксономию. ТАКСОНОМИЯ [taxonomy] — теория и результат классификации и
систематизации сложных систем, обычно иерархической структуры. Выделенные для
исследования элементы и группы объектов, подсистемы называются
таксонами. Если существует ребро из вершины p к вершине c,
то мы говорим, что p является родителем для c, а с является
потомком p. Таким образом, p является обобщением для
c.
Для применения алгоритма нам потребуется множество
последовательностей D. Каждая последовательность представляет собой список
транзакций. Транзакции в последовательности упорядочены по времени согласно
значению соответствующего поля в таблице транзакций. Поля таблицы транзакций:
идентификатор последовательности, идентификатор транзакции, время транзакции,
объекты, присутствующие в транзакции. Как и в случае с AprioriAll, мы
предполагаем, что никакая последовательность не содержит транзакций с одинаковым
полем "время транзакции". Также нас не интересует сколько раз каждый объект
встречается в отдельно взятой транзакции. Важно лишь присутствие или
отсутствие. Поддержка последовательности - это число
последовательностей, содержащих указанную последовательность, отнесённое к
общему числу последовательностей. В случае с алгоритмом GSP требуется учитывать
дополнительные условия, чтобы определить, содержит ли последовательность
указанную последовательность (подпоследовательность). По аналогии с
алгоритмом AprioriAll, последовательность содержит подпоследовательность
(назовём её s), если она содержит все элементы подпоследовательности
s. Добавим к этому определению понятие таксономии. Так транзакция T
содержит объект если x присутствует в
Т, или x является потомком какого-либо элемента из T. Транзакция Т содержит
последовательность (одно-элементную) если в транзакции Т
присутствуют все объекты из y. Последовательность d = < d1...dm
> содержит последовательность s = <
s1...sm > , если существуют
такие целые числа i1 <
i2 < ... < in что s1 входит в , s2 входит в , sn входит в . Теперь добавим к
определению понятие скользящего окна. Допускается, что элемент
последовательности может состоять не из одной, а из нескольких транзакций, если
разница во времени между ними меньше чем размер окна. Формально это можно
выразить следующим образом. Последовательность d =
< d1...dm > содержит
последовательность s = <
s1...sm > , если существуют
такие целые числа , что:
si содержится в ,
Разница во времени транзакций и
размера окна, .
Также мы упоминали, что бывает необходимо задавать временные рамки для
наборов транзакций, которые представляют собой упорядоченные элементы
последовательности. В примере с книгами, это означает, что нас будут
интересовать правила на основе таких транзакций, где время между покупками
больше некого минимального значения и меньше выбранного максимального значения
(например от одного месяца до трёх). Сформулируем условия для транзакций,
удовлетворяющих приведённым критериям. Для заданных параметров размера окна,
минимального и максимального значения временного интервала между транзакциями
последовательность d = <
d1...dm > содержит
последовательность s = <
s1...sm > , если существуют
такие целые числа , что:
si содержится в ,
Разница во времени транзакций и
размера окна, .
Время транзакции минус время
транзакции min-gap, ,
Время транзакции минус время
транзакции max-gap, .
При отсутствии группировки данных (таксономии), min-gap = 0, max-gap = ,
размер окна = 0. Где каждый элемент последовательности представляет собой набор
объектов из одной транзакции. Подобный случай описывался при рассмотрении
алгоритма AprioriAll. Пример. Рассмотрим набор исходных данных и
попытаемся найти правила, добавляя в условие задачи понятие окна, минимального и
максимального интервала времени между элементами последовательности,
таксономи.
Идентификатор последовательности
Время транзакции
Наборы
C1
1
Ringworld
C1
2
Foundation
C1
15
Ringworld Engineers, Second Foundation
C2
1
Foundation, Ringworld
C2
20
Foundation and Empire
C2
50
Ringworld Engineers
Значение минимальной поддержки установим, к примеру, равным двум. В самом
простом случае (без учёта размера окна, таксономий и проч.) на основе данных
можно выделить лишь одну двух-элементную последовательность:
<(Ringworld)(Ringworld Engineers)>. Теперь добавим скользящее окно,
размер которого установим в семь дней. Получим ещё одну часто встречающуюся
последовательность <(Foundation, Ringworld)(Ringworld
Engineers)>. Теперь добавим к условию задачи max-gap=30 дней. Две
найденные последовательности в этом случае не поддерживаются покупателем
С2. Если же просто добавить таксономию, но не задавать значение скользящего
окна и max-gap, то получим правило <(Foundation)(Asimov)>. Описание
работы алгоритма В общем виде работа алгоритма заключается в нескольких
прходах по исходному набору данных. На первом проходе алгоритм подсчитывает
поддержку для каждого элемента (число последовательностей, в которые входит
элемент). В выполнения данного шага алгоритм выделяет из исходного набора
элементов часто встречающиеся элементы, удовлетворяющие значению минимальной
поддержки. Каждый подобный элемент на первом шаге представляет собой
одно-элементную последовательность. В начале каждого последующего прохода
имеется некоторое число часто встречающихся последовательностей, выявленных на
предыдущем шаге алгоритма. Из них будут формироваться более длинные
последовательности, называемые кандидатами. Каждый кандидат - это
последовательность, которая на один элемент длиннее чем те из которых кандидат
был сформирован. Таким образом, число элементов всех кандидатов одинаково. После
этого рассчитывается поддержка для каждого кандидата. В конце шага станет
известно, какие из последовательностей кандидатов на самом деле являются
частыми. Найденные частые последовательности послужат исходными данными для
следующего шага алгоритма. Работа алгоритма завершается тогда, когда не найдено
ни одной новой частой последовательности в конце очередного шага, или когда
невозможно сформировать новых кандидатов. Таким образом, в работе алгоритма
можно выделить две основные операции:
генерация кандидатов;
подсчёт поддержки кандидатов.
Рассмотрим эти операции более подробно.
Генерация кандидатов
Последовательность, состоящую из k элементов будем называть
k-последовательностью. Пусть Lk - содержит все частые
k-последовательности, а Ck
набор кандидатов из k-последовательностей. В начале каждого шага мы
располагаем Lk − 1 - набором
частых (k-1)-последовательностей. Необходимо на их основе построить набор всех
частых k-последовательностей. Введём определение смежной
подпоследовательности. При наличии последовательности s = <
s1s2...sn >
и подпоследовательности c, c будет являться смежной
последовательностью s, если соблюдается одно из условий:
c получается из s при удалении элемента из s первого
(s1) или последнего (sn).
c получается из s при удалении одного объекта из элемента
si, если в его составе не
менее двух объектов.
c - смежная подпоследовательность c`, если c` смежная
подпоследовательность s.
Например, дана последовательность s=<(1,2)(3,4)(5)(6)>.
Последовательности <(2)(3,4)(5)>, <(1,2)(3)(5)(6)> и <(3)(5)>
являются смежными подпоследовательностями s. А последовательности
<(1,2)(3,4)(6)> и <(1)(5)(6)> таковыми не являются. Генерация
кандидатов происходит в две фазы.
Фаза объединения. Мы создаём последовательности кандидаты путём
объединения двух последовательностей Lk
− 1.
Последовательность s1
объединяется с s2 если
подпоследовательность, образующаяся путём удаления объекта из первого элемента
s1 будет та же, что и в случае
удаления объекта из последнего элемента s2. Объединение последовательностей
происходит путём добавления к s1
последнего элемента из s2. При
объединении L1 c L1 нам нужно также добавить элемент к
s2 как дополнительный объект к
последнему элементу, так и в качестве отдельного элемента, так как <(x y)>
и <(x)(y)> дадут одну и ту же последовательность <(y)> при удалении
первого объекта. Таким образом исходные последовательности s1 и s2 являются смежными
подпоследовательностями для новой последовательности-кандидата.
Фаза очистки. Удаляем последовательности-кандидаты которые содержат
смежные (k-1)-подпоследовательности, чья поддержка меньше минимально
допустимой. Если параметр max-gap не задан, то также удаляются кандидаты,
содержащие последовательности (в т.ч. не смежные), поддержка которых меньше
минимально допустимой.
В таблице показаны L3 и C4 после завершения обеих фаз. В фазе
объединения последовательность <(1,2)(3)> объединяется с <(2)(3,4)>
и образует <(1,2)(3,4)>, а с последовательностью <(2)(3)(5)> -
<(1,2)(3)(5)>. Оставшиеся последовательности не объединяются друг с
другом. Например, последовательность <(1,2)(4)> не может быть объединена
ни с одной другой из L3 так как не
существует последовательности вида <(2)(4 x)> или <(2)(4)(x)>. В
фазе очистки последовательность <(1,2)(3)(5)> удаляется, поскольку её
смежная подпоследовательность <(1)(3)(5)> не входит в L3, а значит не является часто
встречающейся.
Подсчёт поддержки кандидатов
Делая проход по исходным данным (сканируя наборы последовательностей), мы
обрабатываем последовательности по одной. Для тех кандидатов, которые содержатся
в обрабатываемой последовательности, увеличиваем значение поддержки на единицу.
Другими словами, имея набор кандидатов C и набор исходных данных
(последовательностей) d, мы ищем все последовательности из C,
которые содержатся в d. Рассмотрим на примерах как происходит поиск
кандидатов в исходных последовательностях данных. Пусть исходный набор данных
имеет вид:
Время транзакции
Объекты
10
1, 2
25
4, 6
45
3
50
1, 2
65
3
90
2, 4
95
6
Пусть max-gap = 30, min-gap = 5, размер окна равен нулю. Для
последовательности-кандидата <(1,2)(3)(4)> мы сперва найдём вхождение
элемента (1,2) в транзакции с временной отметкой 10, затем найдём элемент (3) в
транзакции с отметкой 45. Разница во времени между двумя этими элементами
составляет 35 дней, что больше чем значение max-gap. Данные значения нас не
устраивают. Продолжаем поиск элемента (1,2) с временной отметки 15, потому что
временная отметка для последнего найденного элемента (3) равна 45, а значение
max-gap = 30. Если (1,2) встретился бы раньше временной отметки 15, то разница
во времени между (3) и (1,2) всё равно была бы больше max-gap. Находим (1,2) в
транзакции с временной отметкой 50. Так как это первый элемент
последовательности-кандидата, то проводить сравнение max-gap не с чем. Двигаемся
дальше. Так как (3) не встречается в ближайшие 5 дней (50 + min-gap), продолжаем
поиск элемента (3) после значения 55. Находим этот элемент в момент времени 65.
65 - 50 < 30 (max-gap). Производим поиск элемента (4). Находим его в момент
времени 90. 90 - 65 < 30, так что этот вариант нас устраивает. Мы установили,
что последовательность-кандидат присутствует в исходной последовательности
данных, значит поддержка последовательности-кандидата увеличивается на
единицу. Теперь приведём пример поиска одно-элементной
последовательности-кандидата в исходном наборе данных. В этот раз установим
значение размера окна равным семи дням. Допустим, нам необходимо найти вхождение
элемента (2,6) после временной отметки 20. Находим "2" в момент времени 50 и "6"
в момент времени 25. Так как разница во времени между ними больше размера окна
данное вхождение не считается, продолжаем поиск с момента времени 50 - 7 = 43.
Помним, что объект "2" был найден в момент времени 50. Находим объект "6" в
момент времени 95. Разница во времени всё ещё больше чем размер окна. Продолжаем
поиск с позиции 95 - 7 = 88. Находим "2" в момент времени 90, при том, что
объект "6" был найден в момент времени 95. Разница между ними меньше размера
окна. На этом поиск окончен.Кандидат (2,6) присутствует в последовательности
данных.
Иерархия данных. Таксономия
Таксономия отражает структуру в данных. В примере с книгами можно задать
ориентированный граф, вершиной которого будет являться "Science Fiction", двумя
узлами, связанными с вершиной будет "Asimov" и "Niven". Каждый из этих узлов
будет связан с узлами "Foundation", "Foundation and Empire", "Second Foundation"
и "Ringworld", "Ringworld Engineers" соответственно. Для учёта этих данных
последовательность вида <(Foundation, Ringworld)(Second Foundation)> будет
расширена до <(Foundation, Ringworld, Asimov, Niven, Science Fiction)(Second
Foundation, Asimov, Science Fiction)>. После чего можно использовать алгоритм
GSP для анализа полученной последовательности данных.
Знаете ли Вы, что только в 1990-х доплеровские измерения радиотелескопами показали скорость Маринова для CMB (космического микроволнового излучения), которую он открыл в 1974. Естественно, о Маринове никто не хотел вспоминать. Подробнее читайте в FAQ по эфирной физике.
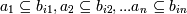 .
.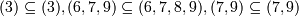 . Хотя
последовательность <(2)(3)> не входит в <(2,3)>, так как исходная
последовательность говорит о том, что "3" был куплен после "2", а вторая, что
товары "2" и "3" были куплены вместе.
. Хотя
последовательность <(2)(3)> не входит в <(2,3)>, так как исходная
последовательность говорит о том, что "3" был куплен после "2", а вторая, что
товары "2" и "3" были куплены вместе.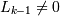 ; k++)
; k++)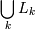 ;
;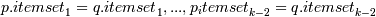 ;
;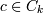 , такие что (k-1)
последовательность из c не входит в
, такие что (k-1)
последовательность из c не входит в 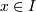 если x присутствует в
Т, или x является потомком какого-либо элемента из T. Транзакция Т содержит
последовательность (одно-элементную)
если x присутствует в
Т, или x является потомком какого-либо элемента из T. Транзакция Т содержит
последовательность (одно-элементную) 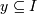 если в транзакции Т
присутствуют все объекты из y.
если в транзакции Т
присутствуют все объекты из y. 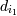 ,
, 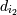 ,
, 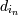 .
.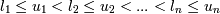 , что:
, что: 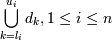 ,
,
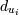 и
и 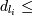 размера окна,
размера окна, 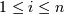 .
. 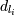 минус время
транзакции
минус время
транзакции 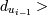 min-gap,
min-gap, 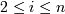 ,
,
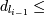 max-gap,
max-gap, 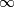 ,
размер окна = 0. Где каждый элемент последовательности представляет собой набор
объектов из одной транзакции. Подобный случай описывался при рассмотрении
алгоритма AprioriAll.
,
размер окна = 0. Где каждый элемент последовательности представляет собой набор
объектов из одной транзакции. Подобный случай описывался при рассмотрении
алгоритма AprioriAll.