Распределенная обработка данных — методика выполнения прикладных программ группой систем.
Сущность DDP заключается в том, что пользователь получает возможность работать с сетевыми службами и прикладными процессами, расположенными в нескольких взаимосвязанных абонентских системах. При этом возможны несколько видов работ, которые он может выполнять:
Для распределенной обработки осуществляется сегментация прикладных программ — разделение сложной прикладной программы на части, которые могут быть распределены по системам локальной сети.
Сегментация осуществляется с помощью специального инструментального программного обеспечения, которое автоматизирует рассматриваемый процесс. С помощью технологии, предоставляемой объектно-ориентированной архитектурой в результате выполнения указанного процесса прикладная программа делится на самостоятельные части, загружаемые в различные системы. Благодаря этому, создается возможность перемещения программ из одной системы в другую и распределенной обработки данных.
В результате сегментации каждая выделенная часть программы включает управление данными, алгоритм и блок презентации. Благодаря этому, она может быть оптимальным образом выполнена на основе платформ, используемых в сети.
Передача данных для распределенной обработки происходит при помощи удаленного вызова процедур либо электронной почты. Первая технология характеризуется высоким быстродействием, а вторая - низкой стоимостью.
Удаленный вызов процедур работает аналогично местному вызову процедур и обеспечивает организацию обработки данных. Этой цели служит механизм навигации в сети, поиска информации, запуска процесса в нескольких системах, передачи полученных результатов пользователям, пославшим запросы. Выполняемый процесс характеризуется прозрачностью, благодаря которой объекты сети, расположенные между пользователями и программами не видны обоим партнерам.
Выполнение удаленного вызова процедур является дорогостоящей операцией, ибо на все время ее выполнения системы, участвующие в работе, должны по каналам передавать данные друг другу. Альтернативной удаленного вызова является применение интеллектуальных агентов или выполнение распределенной обработки данных с использованием электронной почты. Этот метод не требует больших затрат, но работает значительно медленнее.
Известны также программные средства Системы Управления Распределенной Базой Данных (СУРБД), содержимое которой располагается в нескольких абонентских системах информационной сети.
Задачей СУРБД является обеспечение функционирования распределенной базы данных. СУРБД должна действовать так, чтобы у пользователей возникла иллюзия того, что они работают с Базой Данных (БД), расположенной в одной абонентской системе. Использование СУРБД, по сравнению с группой невзаимосвязанных баз данных, позволяет сокращать затраты на передачу данных в информационной сети. СУРБД так распределяет файлы по сети, что в каждой системе хранятся те данные, которые чаще всего используются именно в этом месте.
В СУРБД осуществляется тиражирование данных. Его сущность заключается в том, что изменение, вносимое в одну часть базы данных, в течение определенного времени отражается и в других частях базы.
При планировании обработки данных могут рассматриваться три модели обработки:
При любой обработке имеются три основных уровня манипулирования данными:
При обработке в одноранговой сети все три уровня, как правило, выполняются на одном - персональном - рабочем месте. В современных технологиях применения вычислительной техники персональная обработка информации, когда все данные и средства их обработки сосредоточены в пределах одного рабочего места, и обмен данными между рабочими местами не происходит или выполняется эпизодически (например, средствами электронной почты), постепенно уходит в прошлое. Современные информационные, управленческие, офисные системы в большей или меньшей степени ориентируются на многопользовательскую обработку, при которой данные доступны (возможно, одновременно доступны) многим пользователям с разных рабочих мест. Соображения эффективности и надежности требуют централизации процессов хранения и обработки данных.
И централизованная обработка, и модель клиент/сервер в равной мере используют преимущества централизации. Различие между этими двумя моделями состоит в том, что при централизованной обработке представление информации конечному пользователю также выполняется средствами центральной вычислительной системы - на ее терминалах (неинтеллектуальных), подключенных к вычислительной системе через порты/каналы ввода-вывода. В модели же клиент/сервер терминалы, представляющие информацию, являются интеллектуальными - самостоятельными вычислительными системами (обычно персональными компьютерами) и связаны с сервером через сетевые средства.
Вычислительный ресурс (это может быть отдельная ЭВМ в сети или отдельный процесс в многозадачной вычислительной системе), обеспечивающий хранение, администрирование, предоставление доступа к данным, называется сервером. Вычислительные ресурсы (отдельные ЭВМ или процессы), обеспечивающие использование данных и представление их конечному пользователю, называются клиентами. Вся модель, обеспечивающая такое распределение функций, называется моделью клиент/сервер.
При перемещении большей части функций манипулирования данными на высокопроизводительный и высоконадежный сервер могут быть обеспечены следующие преимущества:
Хотя централизованная обработка обеспечивает большую эффективность в сопровождении системы и в скорости обмена, предпочтительной все же представляется модель клиент/сервер, к числу достоинств которой следует отнести прежде всего гибкость - возможность строить клиентские рабочие места на разных платформах и в разных операционных средах и, таким образом, гибко приспосабливать возможности интеллектуального терминала АИРС к стоящим перед данным рабочим местом задачам.
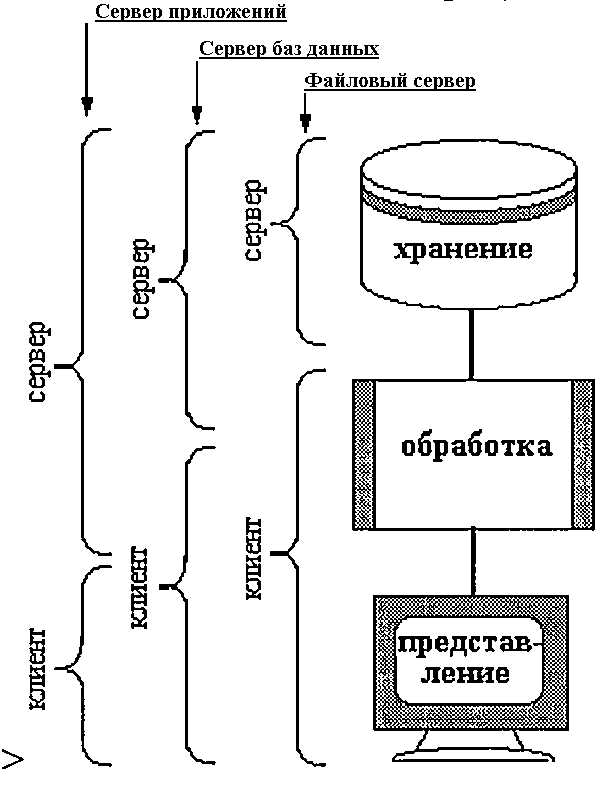
Распределение функций манипулирования данными между клиентом и сервером может быть различным, как показано на рисунке 1.
Вариант файлового сервера предполагает, что сервер выполняет только хранение данных. При необходимости вся единица хранения данных (файл) пересылается клиенту, и всю дальнейшую работу с данными (в том числе и выборку) выполняет клиент. Этот вариант требует значительных ресурсов как вычислительных (так как на каждом рабочем месте должна размещаться копия обрабатываемых данных и все средства их обработки), так и коммуникационных (так как по сети передаются файлы целиком). Кроме того, этот вариант либо ограничивает одновременный доступ клиентов блокировкой файлов, либо приводит к неидентичности копий информации у разных клиентов. В предельном случае вариант файлового сервера сводится к персональной обработке данных, пусть и в среде локальной сети.
Рис. 1.
Вариант сервера базы данных предполагает, что на сервер возлагается выполнение одной из самых трудоемких функций логики приложения - выборки из базы данных только тех записей, которые необходимы для решения конкретной задачи. В этом случае экономятся ресурсы вычислительной системы и обеспечивается действительно многопользовательский доступ. Вместе с тем, в зависимости от сложности оставшейся части логики приложения, объем клиентской части ресурсов может все еще оставаться достаточно большим.
Вариант сервера базы данных особенно эффективен в системах со специализированными рабочими местами, так как позволяет подобрать аппаратные и операционные среды рабочих мест в наиболее точном соответствии с решаемыми задачами.
Вариант сервера приложений предполагает, что вся или почти вся логика
приложений выполняется на сервере, а в клиентскую часть передаются лишь
результаты обработки. Клиентская часть, таким образом, ответственна только за представление результатов конечному пользователю. Такой вариант предъявляет повышенные требования к ресурсам сервера, но объемы ресурсов клиентов могут быть минимальны. Такой вариант позволяет также легко организовать гетерогенную систему, в которой разные клиенты будут работать в разных
операционных средах, так как объем программного обеспечения, который нужно переписать, чтобы адаптировать клиента к новой среде, относительно невелик – это только часть, зависимая от средств визуализации на данном рабочем месте. В предельном случае модель сервера приложений, однако, сводится к централизованной обработке.
Технологии распределенных вычислений.
Программное обеспечение (ПО) организации распределенных вычислений называют программным обеспечением промежуточного слоя (Middleware). Новое направление организации распределенных вычислений в сетях Internet-Intranet основано на создании и использовании программных средств, которые могут работать в различных аппаратно-программных средах. Совокупность таких средств называют многоплатформенной распределенной средой - МРС (сrossware).
Находят применение технологии распределенных вычислений RPC (Remote Procedure Call), ORB (Object Request Broker), MOM (Message-oriented Middleware), DCE (Distributed Computing Environment), мониторы транзакций, ODBC.
RPC - процедурная блокирующая синхронная технология, предложенная фирмой Sun Microsystems. Вызов удаленных программ подобен вызову функций в языке С. При пересылках на основе транспортных протоколов TCP или UDP данные представляются в едином формате обмена XDR. Синхронность и блокирование означают, что клиент, обратившись к серверу, для продолжения работы ждет ответа от сервера.
Для систем распределенных вычислений разработаны специальные языки программирования, для RPC это язык IDL (Interface Definition Language), который дает пользователю возможность оперировать различными объектами безотносительно к их расположению в сети. На этом языке можно записывать обращения к серверам приложений. Другой пример языка для систем распределенных вычислений - NewEra в среде Informix.
RPC входит во многие системы сетевого программного обеспечения.
ОRB - технология объектно-ориентированного подхода, включает 13 пунктов (служб). Основные службы:
При применении ORB (в отличие от RPC) в узле-клиенте хранить сведения о расположении серверных объектов не нужно, достаточно знать расположение в сети программы-посредника ORB. Поэтому доступ пользователя к различным объектам (программам, данным, принтерам и т.п.) существенно упрощен. Посредник должен определять, в каком месте сети находится запрашиваемый ресурс, направлять запрос пользователя в соответствующий узел, а после выполнения запроса возвращать результаты пользователю.
MOM - также объектная технология. Связь с серверами асинхронная. Это одна из наиболее простых технологий, включает команды "послать" и "получить", осуществляющие обмен сообщениями. Отличается от E-mail реальным масштабом времени. Однако могут быть варианты МОМ с очередями, тогда режим on-line необязателен и при передаче не требуется подтверждений, т.е. опора на протокол IP без установления соединения.
Распределенная среда обработки данных
(Distributed Computing Environment (DCE*)) — технология распределенной обработки данных, предложенная фондом открытого программного обеспечения.
Она не противопоставляется другим технологиям (RPC, ORB), а является средой для их использования.
Среда DCE*, разработанная в 1990 г., представляет собой набор сетевых служб, предназначенный для выполнения прикладных процессов, рассредоточенных по группе абонентских систем гетерогенной (неоднородной) сети. Основные ее компоненты показаны в табл.1.
Табл. Основные компоненты DCE*.
|
№ п/п |
Служба |
Выполняемые функции |
|
1. |
База Данных (БД) имен пользователей и средств, предназначенных для доступа пользователей к сетевым службам. |
|
|
2. |
Технология, обеспечивающая взаимодействие двух прикладных программ, расположенных в различных абонентских системах. |
|
|
3. |
Программное Обеспечение (ПО) разрешения на доступ к ресурсам системы или сети. |
|
|
4. |
Многопоточность |
Программы, обеспечивающие одновременное выполнение нескольких задач. |
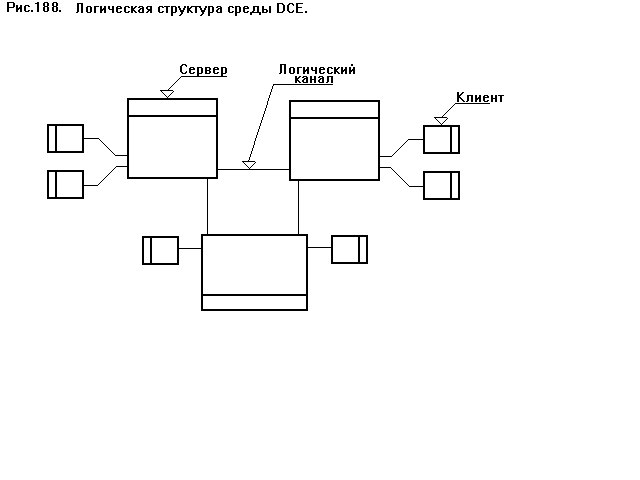
Системы, имеющие программы распределенной среды, соответственно, являются серверами и клиентами. Серверы связаны друг с другом логическими каналами, по которым передают друг другу файлы (рис.188)
Каждый сервер имеет свою группу клиентов.
Среда имеет трехступенчатую архитектуру: прикладная программа ѕ база данных ѕ клиент.
Функции, выполняемые средой, включают прикладные службы:
Программное Обеспечение (ПО) среды погружается в Сетевую Операционную Систему (СОС). Серверы имеют свои, различные, Операционные Системы (ОС). В роли сервера может, также, выступать главный компьютер со своей операционной системой.
Функционирование распределенной среды требует выполнения ряда административных задач. К ним, в первую очередь, относятся средства:
С точки зрения логического управления среда обработки данных делится на ячейки DCE*. В каждую из них может включаться от нескольких единиц до тысяч абонентских систем. Размеры ячеек территориально не ограничены. Входящие в одну и ту же ячейку системы могут быть расположены даже на разных континентах. В ячейках выполняются службы:
Распределение прикладных процессов по ячейкам защищает от сбоев, позволяет приспособить процессы к конкретным нуждам групп пользователей. Последние могут иметь доступ только к определенным ячейкам.
|
|
