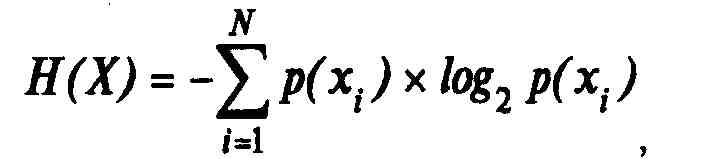
Как известно, применение сжатия данных позволяет более эффективно использовать емкость дисковой памяти. Не менее полезно применение сжатия при передачи информации в любых системах связи. В последнем случае появляется возможность передавать значительно меньшие (как правило, в несколько раз) объемы данных и, следовательно, требуются значительно меньшие ресурсы пропускной способности каналов для передачи той же самой информации. Выигрыш может выражаться в сокращении времени занятия канала и, соответственно, в значительной экономии арендной платы.
Научной предпосылкой возможности сжатия данных выступает известная из теории информации теорема кодирования для канала без помех, опубликованная в конце 40-х годов в статье Клода Шеннона "Математическая теория связи". Теорема утверждает, что в канале связи без помех можно так преобразовать последовательность символов источника (в нашем случае DTE) в последовательность символов кода, что средняя длина символов кода может быть сколь угодно близка к энтропии источника сообщений Н(Х), определяемой как:
где p(xf) — вероятность появления конкретного сообщения .с, из N возможных символов алфавита источника. Число N называют объемом алфавита источника.
Энтропия источника Н(Х) выступает количественной мерой разнообразия выдаваемых источником сообщений и является его основной характеристикой. Чем выше разнообразие алфавита Х сообщений и порядка их появления, тем больше энтропия Н(Х) и тем сложнее эту последовательность сообщений сжать. Энтропия источника максимальна, если априорные вероятности сообщений и вероятности их выдачи являются равными между собой. С другой стороны, Н(Х)=0, если одно из сообщений выдается постоянно, а появление других сообщений невозможно.
Единицей измерения энтропии является бит. 1 бит — это та неопределенность, которую имеет источник с равновероятной выдачей двух возможных сообщений,' обычно символов "О" и "1".
Энтропия Н(Х) определяет среднее число двоичных знаков, необходимых для кодирования исходных символов (сообщений) источника. Так, если исходными символами являются русские буквы (N=32=2 ) и они передаются равновероятно и независимо, то Н(Х)=5 бит. Каждую буквы можно закодировать последовательностью из пяти двоичных символов, поскольку существуют 32 такие последовательности. Однако можно обойтись и меньшим числом символов на букву. Известно, что для русского литературного текста Я(Х)=1,5 бит, для стихов Н(Х)=\ ,0 бит, а для текстов телеграмм Н(.Х)=0,8 бит. Следовательно, возможен способ кодирования в котором в среднем на букву русского текста будет затрачено немногим более 1,5, 1,0 или даже 0,8 двоичных символов.
Если исходные символы передаются не равновероятно и не независимо, то энтропия источника будет ниже своей максимальной величины Я^^(Х)=/о<7^У. В этом случае возможно более экономное кодирование. При этом на каждый исходный символ в среднем будет затрачено и*= Н(Х) символов кода. Для характеристики достижимой степени сжатия используется коэффициент избыточности КИЗБ^^ —Н(Х)/Нмд^(Х). Для характеристики же достигнутой степени сжатия на практике применяют так называемый коэффициент сжатия Кеж- Коэффициент сжатия — это отношение первоначального размера данных к их размеру в сжатом виде, — обычно дается в формате К.сж'-^- Путем несложных рассуждений можно получить соотношение РИЗБ ^1—1 /^еж-Известные методы сжатия направлены на снижение избыточности, вызванной как неравной априорной вероятностью символов, так и зависимостью между порядком поступления символов. В первом случае для кодирования исходных символов используется неравномерный код. Часто появляющиеся символы кодируются более коротким кодом, а менее вероятные (редко встречающиеся) — более длинным кодом.
Устранение избыточности, обусловленной корреляцией между символами, основано на переходе от кодирования отдельных символов к кодированию групп этих символов. За счет этого происходит укрупнение алфавита источника, так как число N тоже растет. Общая избыточность при укрупнении алфавита не изменяется. Однако уменьшение избыточности, обусловленной взаимными связями символов, сопровождается соответствующим возрастанием избыточности, обусловленной неравномерностью появления различных групп символов, то есть символов нового укрупненного алфавита. Происходит как бы конвертация одного вида избыточности в другой.
Таким образом, процесс устранения избыточности источника сообщений сводится к двум операциям — декорреляции (укрупнению алфавита) и кодированию оптимальным неравномерным кодом.
Сжатие бывает с потерями и без потерь. Потери допустимы при сжатии (и восстановлении) некоторых специфических видов данных, таких как видео и аудиоинформация. По мере развития рынка видеопродукции и систем мультимедиа все большую популярность приобретает метод сжатия с потерями MPEG 2 (Motion Pictures Expert Group), обеспечивающий коэффициент сжатия до 20:1. Если восстановленные данные совпадают с данными, которые были до сжатия, то имеем дело со сжатием без потерь. Именно такого рода методы сжатия применяются при передаче информации в СПД.
На сегодняшний день существует множество различных алгоритмов сжатия данных без потерь, подразделяющихся на несколько основных групп.
Этот метод является одним из старейших и наиболее простым. Он применяется в основном для сжатия графических файлов. Самым распространенным графическим форматом, использующим этот тип сжатия, является формат PCX. Один из вариантов метода RLE предусматривает замену последовательности повторяющихся символов на строку, содержащую этот символ, и число, соответствующее количеству его повторений. Применение метода кодирования повторов для сжатия текстовых или исполняемых (*.ехе, *.сот) файлов оказывается неэффективным. Поэтому в современных системах связи алгоритм RLE практически не используется.
В основе вероятностных методов сжатия (алгоритмов Шеннона-Фано (Shannon Fano) и Хаффмена (Huffman)) лежит идея построения "дерева", положение символа на "ветвях" которого определяется частотой его появления. Каждому символу присваивается код, длина которого обратно пропорциональна частоте появления этого символа. Существуют две разновидности вероятностных методов, различающих способом определения вероятности появления каждого символа:
- статические (static) методы, использующие фиксированную таблицу частоты появления символов, рассчитываемую перед началом процесса сжатия;
- динамические (dinamic) или адаптивные (adaptive) методы, в которых частота появления символов все время меняется и по мере считывания нового блока данных происходит перерасчет начальных значений частот.
Статические методы характеризуются хорошим быстродействием и не требуют значительных ресурсов оперативной памяти. Они нашли широкое применение в многочисленных программах-архиваторах, например ARC, PKZIP и др., но для сжатия передаваемых модемами данных используются редко — предпочтение отдается арифметическому кодированию и методу словарей, обеспечивающим большую степень сжатия.
Принципы арифметического кодирования были разработаны в конце 70-х годов В результате арифметического кодирования строка символов заменяется .[ействительным числом больше нуля и меньше единицы. Арифметическое кодирование позволяет обеспечить высокую степень сжатия, особенно в случаях, когда сжимаются данные, где частота появления различных символов сильно варьируется. Однако сама процедура арифметического кодирования требует мощных вычислительных ресурсов, и до недавнего времени этот метод мало применялся при сжатии передаваемых данных из-за медленной работы алгоритма. Лишь появление мощных процессоров, особенно с RISC-архитектурой, позволило создать эффективные устройства арифметического сжатия данных.
Алгоритм, положенный в основу метода словарей, был впервые описан в работах израильских исследователей Якйба Зива и Абрахама Лемпеля, которые впервые опубликовали его в 1977 г. В последующем алгоритм был назван Lempel-Ziv, или сокращенно LZ. На сегодняшний день LZ-алгоритм и его модификации получили наиболее широкое распространение, по сравнению с другими методами сжатия. В его основе лежит идея замены наиболее часто встречающихся последовательностей символов (строк) в передаваемом потоке ссылками на "образцы", хранящиеся в специально создаваемой таблице (словаре). Алгоритм основывается на том, что по потоку данных движется скользящее "окно", состоящее из двух частей. В большей по объему части содержатся уже обработанные данные, а в меньшей помещается информация, прочитанная по мере ее просмотра. Во время считывания каждой новой порции информации происходит проверка, и если оказывается, что такая строка уже помещена в словарь ранее, то она заменяется ссылкой на нее.
Большое число модификаций метода LZ — LZW, LZ77, LZSS и др. — применяются для различных целей, Так, методы LZW и BTLZ (British Telecom Lempel-Ziv) применяются для сжатия данных по протоколу V.42bis, LZ77 — в утилитах Stasker и DoudleSpase, а также во многих других системах программного и аппаратного сжатия.
В качестве примера, поясняющего принципы сжатия, рассмотрим простой метод Шеннона-Фано. В чистом виде в современных СПД он не применяется, однако позволяет проиллюстрировать принципы, заложенные в более сложных и эффективных методах. Согласно методу Шеннона-Фано для каждого символа формируется битовый код, причем символы с различными частотами появления имеют коды разной длины. Чем меньше частота появления символов в файле, тем больше размер его битового кода. Соответственно, чаще появляющийся символ имеет меньший размер кода.
Код строится следующим образом: все символы, встречающиеся в файле выписывают в таблицу в порядке убывания частот их появления. Затем их разделяют на две группы так, чтобы в каждой из них были примерно равные суммы частот символов. Первые биты кодов всех символов одной половины устанавливаются в "О", а второй — в "I". После этого каждую группу делят еще раз пополам и так до тех пор, пока в каждой группе не останется по одному символу. Допустим, файл состоит из некоторой символьной строки aaaaaaaaaabbbbbbbbccccccdddddeeeefff, тогда каждый символ этой строки можно закодировать как показано в табл. 8.1.
Таблица 8.1. Пример построения кода Шеннона-Фано
| Символ | Частота появления | Код |
| а | 10 | 11 |
| b | 8 | 10 |
| с | 6 | 011 |
| d | 5 | 010 |
| е | 4 | 001 |
| f | 3 | 000 |
Итак, если обычно каждый символ кодировался 7—8 битами, то теперь требуется максимум 3 бита.
Однако, показанный способ Шеннона-Фано не всегда приводит к построению однозначного кода. Хотя в верхней подгруппе средняя вероятность символа больше (и, следовательно, коды должны быть короче), возможны ситуации, при которых программа сделает длиннее коды некоторых символов из верхних подгрупп, а не коды символов из -нижних подгрупп. Действительно, разделяя множество символов на подгруппы, можно сделать большей по вероятности как верхнюю, так и нижнюю подгруппы. В качестве примера такой ситуации служат приведенные ниже две таблицы, где одни и те же символы с одинаковыми вероятностями появления в файле имеют различную кодировку.
Более удачен в данном отношении метод Хаффмена. Он позволяет однозначно построить код с наименьшей средней длиной, приходящейся на символ.
Таблица 8.2. Пример кодировки одних и тех же символов различными кодами
| Символ | Частота появления | Код |
| с | 22 | 11 |
| е | 20 | 101 |
| h | 16 | 100 |
| 1 | 16 | 01 |
| а | 10 | 001 |
| k | 10 | 0001 |
| m | 4 | 00001 |
| b | 2 | 00000 |
Таблица 8.3. Пример кодировки одних И тех же символов различными кодами
| Символ | Частота появления | Код |
| с | 22 | 11 |
| е | 20 | 101 |
| h | 16 | 011 |
| • ¦ | 16 | 010 |
| а | 10 | 001 |
| k | 10 | 0001 |
| m | 4 | 00001 |
| Ь | 2 | 00000 |
Суть метода Хаффмена сводится к следующему. Символы, встречающиеся в файле, выписываются в столбец в порядке убывания вероятностей (частоты) их появления. Два последних символа объединяются в один с суммарной вероятностью. Из полученной новой вероятности и вероятностей новых символов, не использованных в объединении, формируется новый столбец в порядке убывания вероятностей, а две последние вновь объединяются. Это продолжается до тех пор, пока не останется одна вероятность, равная сумме вероятностей всех символов, встречающихся в файле.
Таблица 8.4. Кодирование методом Хаффмена
| Символ | Частота появления | Вспомогательные столбцы |
| с | 22 | 22 22 26 32 42 58 100 |
| в | 20 | 20 20 22 26 32 42 |
| h | 16 | 16 16 20 22 26 |
| I | 16 | 16 16 16 20 |
| а | 10 | 10 16 16 |
| k | 10 | 10 16 |
| m | 4 | 6 |
| b | 2 |
Таблица 8.5. Коды символов для кодового дерева на рис. 8.1
| Символ | Код |
| с | 01 |
| е | 00 |
| h | 111 |
| 1 | 110 |
| а | 100 |
| k | 1011 |
| m | 10101 |
| b | 10100 |
Процесс кодирования с использованием метода Хаффмена поясняется табл. 8.4. Для составления кода, соответствующего данному символу, необходимо проследить путь перехода знака по строкам и столбцам таблицы кода.
Более наглядно принцип действия метода Хаффмена можно представить В виде кодового дерева (рис. 8.1) на основе табл. 8.4. Из точки, соответствующей сумме всех вероятностей (в данном случае она равна 100), направляются две ветви. Ветви с большей вероятностью присваивается единица, с меньшей — нуль. Продолжая последовательно разветвлять дерево, доходим до вероятности каждого символа.
100
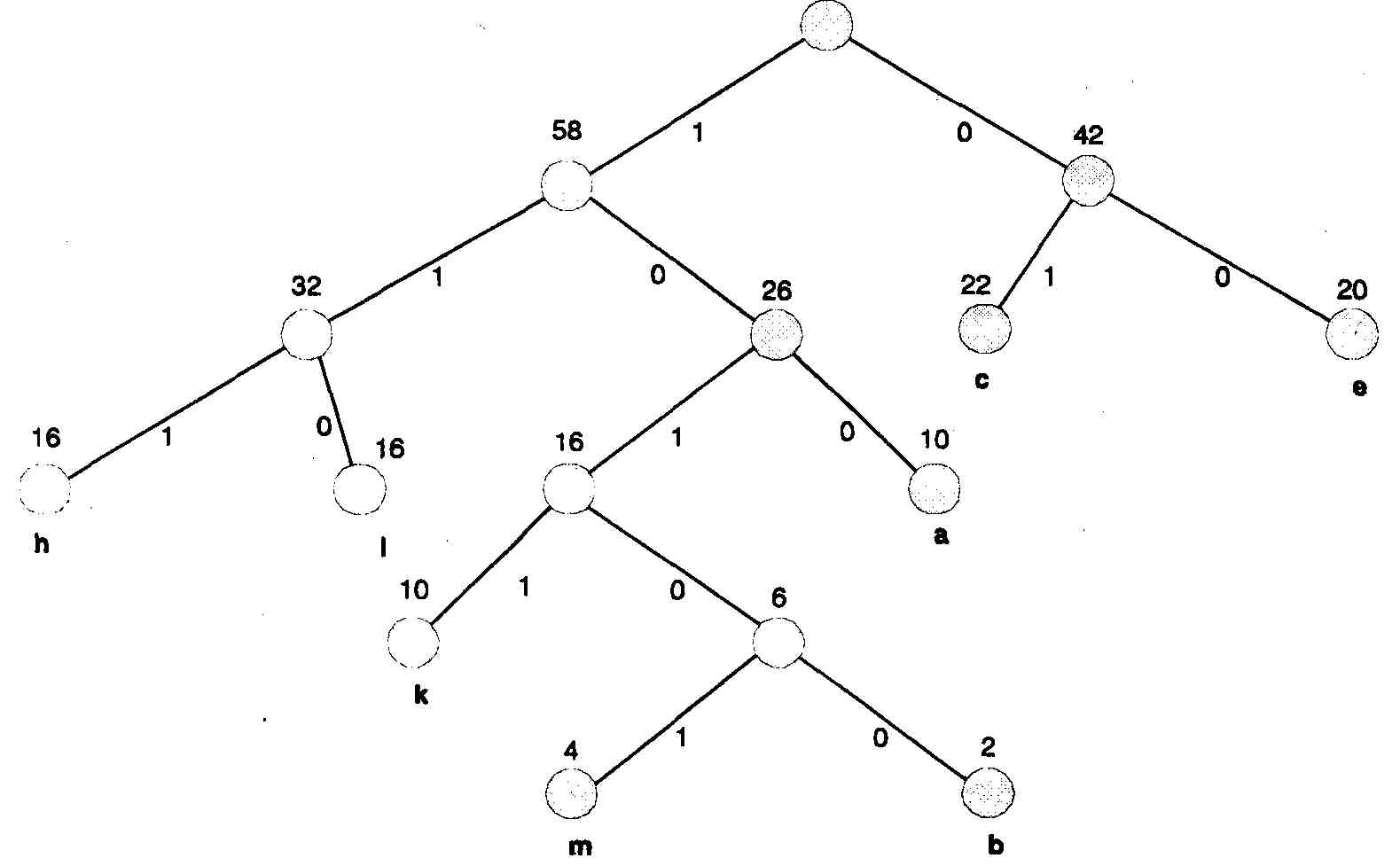
Рис. 8.1. Кодовое дерево для кода Хаффмена
Теперь, двигаясь по кодовому дереву сверху вниз, можем записать для каждого символа соответствующий код (табл. 8.5).
Непосредственным предшественником алгоритма LZW явился алгоритм LZ78, опубликованный в 1978 г. Этот алгоритм воспринимался как математическая абстракция до 1984 г., когда Терри Уэлч (Terry A. Welch) опубликовал свою работу с модифицированным алгоритмом, получившим в дальнейшем название LZW (Lempel-Ziv-Welch).
Алгоритм LZW построен вокруг так называемой таблицы фраз (словаря), которая отображает строки символов сжимаемого сообщения в коды фиксированной длины, равные 12 бит. Таблица обладает свойством предшествования, то есть для каждой фразы словаря, состоящей из некоторой фразы w и символа К, фраза w тоже содержится в словаре.
Алгоритм работы кодера LZW следующий:
Проинициализировать словарь односимвольными фразами, соответствующими символам входного алфавита; Прочитать первый символ сообщения в текущую фразу *г;
Шаг алгоритма:
Прочитать очередной символ сообщения К: Если КОНЕЦ_СООВЩЕНИЯ Выдать ход »; ВЫХОД; Конец Если фраза »К уже есть в словаре, Заменить х на код фравы wK; Повторить Шаг алгоритма; Иначе Выдать ход w; Добавить wK в словарь ; Повторить Шаг алгоритма; Конец Если;
Пример работы кодера LZW при преобразовании трехсимвольного алфавита приведен в табл. 8.6 и 8.7.
Описанный алгоритм кодера не оптимизирует выбор фразы для добавления в словарь или разбор сообщения. Однако в силу его простоты он может быть эффективно использован.
Таблица 8.6. Работа кодера LZW на примере трехсимвольного алфавита (а, б, в)
| Символ | wK | Выход | Добавление в словарь (фраза — позиция) |
| а | 1 | ||
| 6 | 6 | 1 | 16(4) |
| а | 2а | 2 | 2а(5) |
| 6 | 16 | ||
| в | 4в | 4 | 4в(6) |
| б | 36 | 3 | 36(7) |
| а | 2а | ||
| 6 | 56 | 5 | 56(8) |
| а | 2а | ||
| 6 | 56 | ||
| а | 8а | 8 | 8а(9) |
| а | 1а | 1 | 1а(10) |
| а | 1a | ||
| а | 10a | 10 | 10a (11) |
| а | 1a | ||
| а | 10a | '• | |
| а | 11a | 11 | 11a (12) |
| 1 |
Декодер LZW должен использовать тот же словарь, что и кодер, строя его по аналогичным правилам при восстановлении сжатых данных. Каждый считываемый код разбирается с помощью словаря на предшествующую фразу w и символ К. Затем рекурсия продолжается для предшествующей фразы w до тех пор, пока она не окажется кодом одного символа.
Таблица 8.7. Словарь, построенный кодером LZW, для примера из табл. 8.6
| Фразы, добавленные в словарь при инициализации | |
| а | 1 |
| 6 | 2 |
| в | 3 |
| Фразы, добавленные пр | и разборе сообщения |
| 16 | 4 |
| 2а | 5 |
| 4в | 6 |
| 36 | 7 |
| 56 | 8 |
| 8а | 9 |
| la | 10 |
| 10a | 11 |
| 11a | 12 |
При этом завершается декомпрессия этого кода. Обновление словаря происходит для каждого декодируемого кода, кроме первого. После завершения декодирования кода его последний символ, соединенный с предыдущей фразой, добавляется в словарь. Новая фраза получает то же значение кода (позицию в словаре), что присвоил ей кодер. В результате такого процесса, шаг за шагом декодер восстанавливает тот словарь, который построил кодер.
Алгоритм декодирования LZW описывается следующим образом:
КОД 8 Прочитать первый ход сообщения(); ПредмдущийКОД = КОД; Выдать символ К, у которого код(К) == КОД; Последний символ = К;
Следующий ход:
КОД = Прочитать очередной код сообщения( ); ВходнойКОД = КОД ; Если КОНЕЦ_СООБЩЕНИЯ ВЫХОД; Конец Если; Если Неизвестен(КОД) // Обработка исключительной //ситуации Выдать(ПоследнийСимаол) КОД = ПредыдущийКОД ВходнойКОД = код(ПредыдущийКОД, ПоследнийСимвол) Конец Если;
Следующий символ:
Если КОД == ход(wK) В СТЕК (К); КОД = код(к) ; Повторить Следующий символ; Иначе если КОД == код(К) Выдать К; ПоcледнийСимвол в JC; Пока стек не пуст Выдать (ИЗ_СТЕКА( )) ; Конец Пока; Добавить в словарь (ПредыдущийКОД, К); Предыдущий КОД а Входной КОД; Повторить СледующийКОД; Конец Если;
Обычно декодирование LZW намного быстрее процесса кодирования. Автор LZW Терри Уэлч в свое время сумел запатентовать свой алгоритм в США. В настоящее время патент принадлежит компании Unisys. АлгоритмLZW определяется как часть стандарта ITU-T V.42bis, но Unisis установила жесткие условия лицензирования алгоритма для производителей модемов.
Расширяемость MNP при сохранении совместимости с существующими ре-ализациями ярко продемонстрирована в его поддержке Рекомендации ITU-T V.42bis.
В процессе установления соединения передатчик и приемник "оговаривают" использование сжатия данных в процессе. Это выполняется с помощью параметра 9 или 14 блока PDU LR (см. гл. 7). Параметр 9, который специфицирует сжатие данных MNP5 или MNP7, был расширен, чтобы обеспечить "краткую" форму спецификации V.42bis. Параметр 14 является новым параметром, применяемым для детализации особенностей V.42bis, используемого в данном канале.
Если существует возможность поддерживать MNP5 и (или) MNP7 и V.42bis, передатчик может включить как параметр 9 (сжатие MNP), так и параметр 14 (сжатие V.42bis). Ответственность за выбор типа сжатия данных, который будет использоваться, в этом случае несет приемник. Он возвращает PDU LR, который указывает выбранный тип сжатия данных. Если передатчик и приемник поддерживают несколько методов сжатия, то приемник делает свой выбор в соответствии со следующим приоритетом.
Приемник не включает информацию о поддержке V.42bis в свой PDU LR, если он не принял запрос на V.42bis в LR от передатчика. Если передатчик включил такой запрос в свой PDU LR, но не получил подтверждения, он отказывается от использования сжатия по протоколу V.42bis.
Далее рассмотрим особенности реализации сжатия в протоколах MNP.
Таблица 8.8. Приоритеты выбора метода сжатия
| Тип сжатия | Приоритет |
| V.42bis | Высокий |
| MNP7 | Средний |
| MNP5 | Низкий |
Протокол MNP 5 реализует комбинацию адаптивного кодирования с применением кода Хаффмена и группового кодирования. При этом хорошо поддающиеся сжатию данные уменьшают свой исходный объем примерно на 50% и, следовательно, реальная скорость их передачи возрастает вдвое по сравнению с номинальной скоростью передачи данных модемом.
На первом этапе процедуры сжатия используется метод группового кодирования для удаления из потока передаваемых данных слишком длинных последовательностей повторяющихся символов. Этот метод преобразует каждую группу из трех и более (вплоть до 253) одинаковых смежных символов к виду символ и число символов. Поскольку групповое кодирование не связано с большими вычислениями, этот метод особенно хорош для реализации в реальном масштабе времени, в частности, при передаче данных по линиям связи.
Согласно данного метода система группового кодирования проверяет проходящий поток данных. Алгоритм остается пассивным до тех пор, пока в этом потоке не обнаружатся три одинаковых смежных символа. После этого алгоритм начинает счет и удаляет из потока данных до 250 одинаковых следующих друг за другом символов. Счетный байт посылается вслед за тремя исходными символами, и передача продолжается. На рис. 8.2 показан пример группового кодирования потока данных.
Способность метода группового кодирования сжимать длинные последовательности очевидна. Тем не менее, рис. 8.2 иллюстрирует также одну из слабостей данного алгоритма. Кодирование группы из трех символов, наоборот, расширяет поток данных.
На втором этапе сжатия данных протокол MNP5 использует адаптивное кодирование на основе метода Хаффмена, известное также как адаптивное частотное кодирование. Этот способ кодирования основан на предположении,

Рис. 8.2. Групповое кодирование по протоколу MNP5
что некоторые символы будут встречаться в потоке данных чаще, чем другие. Символы, которые встречаются чаще, кодируются с использованием небольшого числа битов. Реже встречающиеся символы передаются с использованием более длинных кодовых последовательностей.
Когда формат передаваемых данных относительно хорошо известен и постоянен, кодовые битовые последовательности, или лексемы, могут быть определены заранее. Однако адаптивный алгоритм может подстраиваться под поток данных путем "обучения" с последующим изменением своих лексем.
В протоколе MNP5 определяются 256 лексем для всех возможных 8-разрядных величин (октетов). Лексема состоит из 3-разрядного префикса (заголовка) и суффикса (тела, или основы), который может включать от 1 до 8 разрядов. Как передатчик, так и приемник инициализируют свои символьно-лексемные таблицы в соответствии с табл. 8.9. Первая и последняя записи
Таблица 8.9. Карта символьно-лексемного кодирования в начале процедуры уплотнения данных
| Значение октета (десятичное) | Заголовок лексемы | Тело лексемы |
| 0 | 000 | о |
| 1 | 000 | 1 |
| 2 | 001 | о |
| 3 | 001 | 1 |
| 4 | 010 | 00 |
| 5 | 010 | 01 |
| 6 | 010 | 10 |
| 7 | 010 | 11 |
| 8 | 011 | 00 |
| 15 | 011 | 111 |
| 16 | 100 | 0000 |
| ..'. | ||
| 31 | 100 | 1111 |
| 32 | 101 | 00000 |
| . | ||
| 63 | 101 | 11111 |
| 64 | 110 | 000000 |
| 127 | 110 | 111111 |
| 128 | 111 | 0000000 |
| 254 | 111 | 1111110 |
| 255 | 111 | 11111110 |
(строки) этой таблицы содержат наиболее и наименее часто встречающиеся октеты, соответственно.
После того как обработан каждый октет, таблица переопределяется, исходя из частоты появления каждого символа. Октетам, которые появляются чаще всего, приписываются наиболее короткие лексемы. На приемном конце лексемы преобразуются в символы. В соответствии с частотой появления тех или иных символов трансформируется таблица приемника. Тем самым осуществляется самосинхронизация, таблиц кодирования и декодирования.
Протокол MNP7 использует более эффективный (по сравнению с MNP5) алгоритм сжатия данных и позволяет достичь коэффициента сжатия порядка 3:1. MNP7 использует улучшенную форму кодирования методом Хаффмена всочетании с марковским алгоритмом прогнозирования для создания кодовых последовательностей минимально возможной длины.
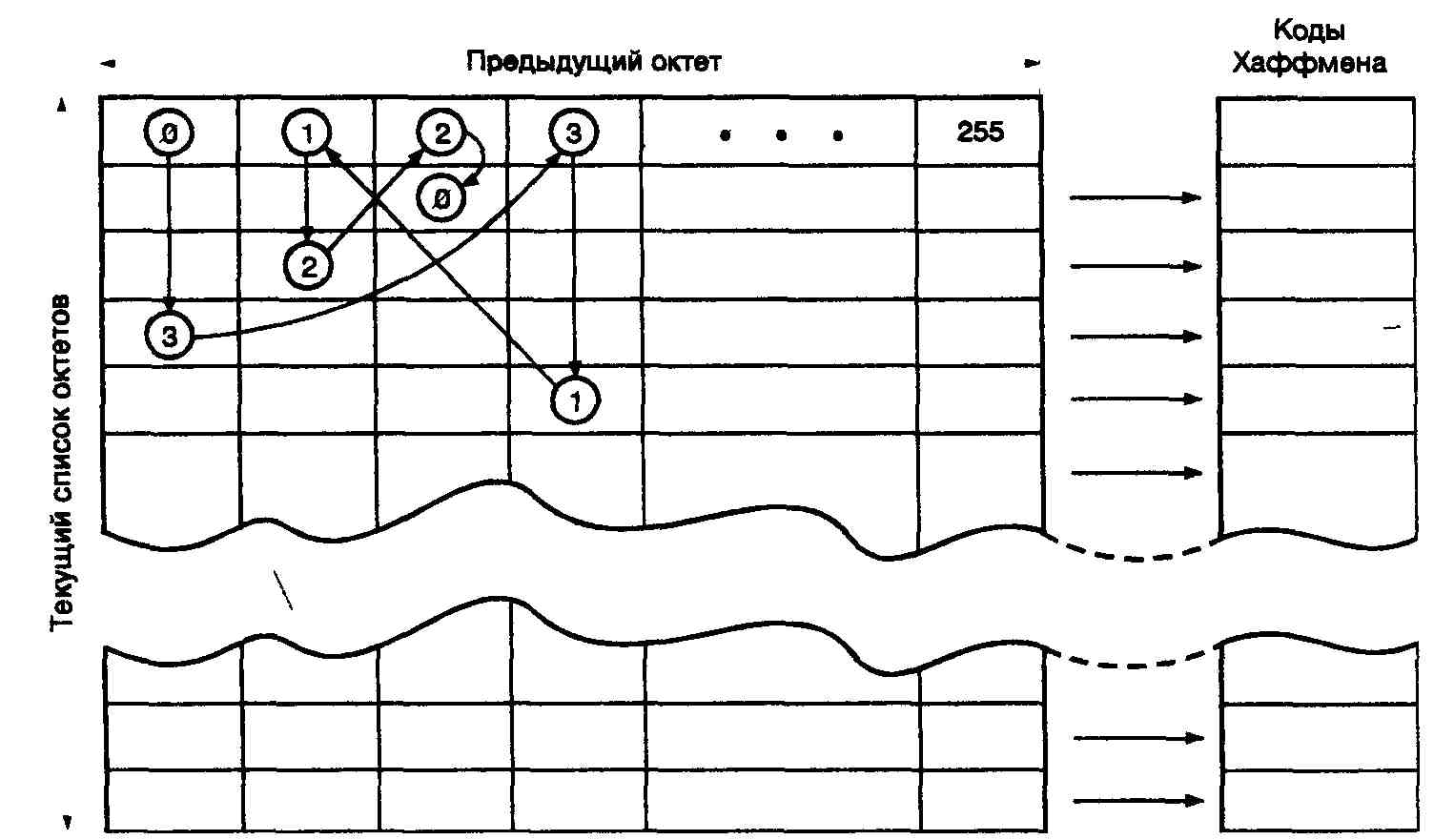
Рис. 8.3. Кодирование при помощи марковского алгоритма прогнозирования и кода Хаффмена
Марковский алгоритм может предсказывать следующий символ в последовательности, исходя из появившегося предыдущего символа. Для каждого ок-Teia формируется таблица из всех 256 возможных следующих за ним октетов, расположенных в соответствии с частотой их появления. Октет кодируется путем выбора столбца, соответствующего предыдущему октету (озаглавливающему столбец), с последующим отысканием в этом столбце значения текущего октета. Строка, в которой находится текущий октет, определяет лексему точно так же, как в описанном выше случае кодирования с использованием кода Хаффмена После того как каждый октет будет закодирован, порядок следования записей (октетов) в выбранном столбце изменяется в соответствии с новыми относительными частотами появления октетов.
На рис. 8.3 показан пример кодирования последовательности октетов 3120 в предположении, что перед этим был передан октет 0. Из рис. 8.3. видно, что в столбце, соответствующем предыдущему октету 0, отыскивается запись (строка) октета 3. После этого передается код Хаффмена для этой записи (октета 3) в таблице. Далее в столбце, соответствующем этому только что переданному октету 3, отыскивается строка с записью следующего октета — в данном случае октета 1, и передается код Хаффмена для этой строки и т.д. В этом примере отсутствует иллюстрация адаптивной части алгоритма, изменяющей порядок расположения октетов в каждом столбце.
В настоящее время методы сжатия данных, включенные в протоколы MNP5 и MNP7, целенаправленно заменяются на метод, основанный на алгоритме словарного типа Лемпеля-Зива-Уэлча (LZW-алгоритме). LZW-алгоритм имеет два главных преимущества:
- обеспечивает достижение коэффициента сжатия 4:1 файлов с оптимальной структурой;
- LZW-метод утвержден ITU-T как составная часть стандарта V.42bis. .
Метод сжатия данных LZW основан на создании древовидного словаря последовательностей символов, в котором каждой последовательности соответствует единственное кодовое слово. Входящий поток данных последовательно, символ за символом, сравнивается с имеющимися в словаре последовательностями. После того, как в словаре будет найдена кодируемая последовательность, идентичная входной, модем передает соответствующее ей кодовое слово. Алгоритм динамически создает и обновляет словарь символьных последовательностей.
Рассмотрим, например, последовательности А, АУ, БАР, БАС, БИС, ШАГ, ШАР и ШУМ. На рис. 8.4 показано, как эти последовательности будут выглядеть в виде деревьев в словаре стандарта V.42bis. Каждый путь от корневого узла к вершине дерева представляет собой последовательность, которая может быть закодирована с помощью одного кодового слова. Имеющиеся последовательности могут расширяться до тех пор, пока не будет достигнута их максимальная длина. Можно добавлять новые последовательности, причем единственным ограничением является объем используемого словаря.
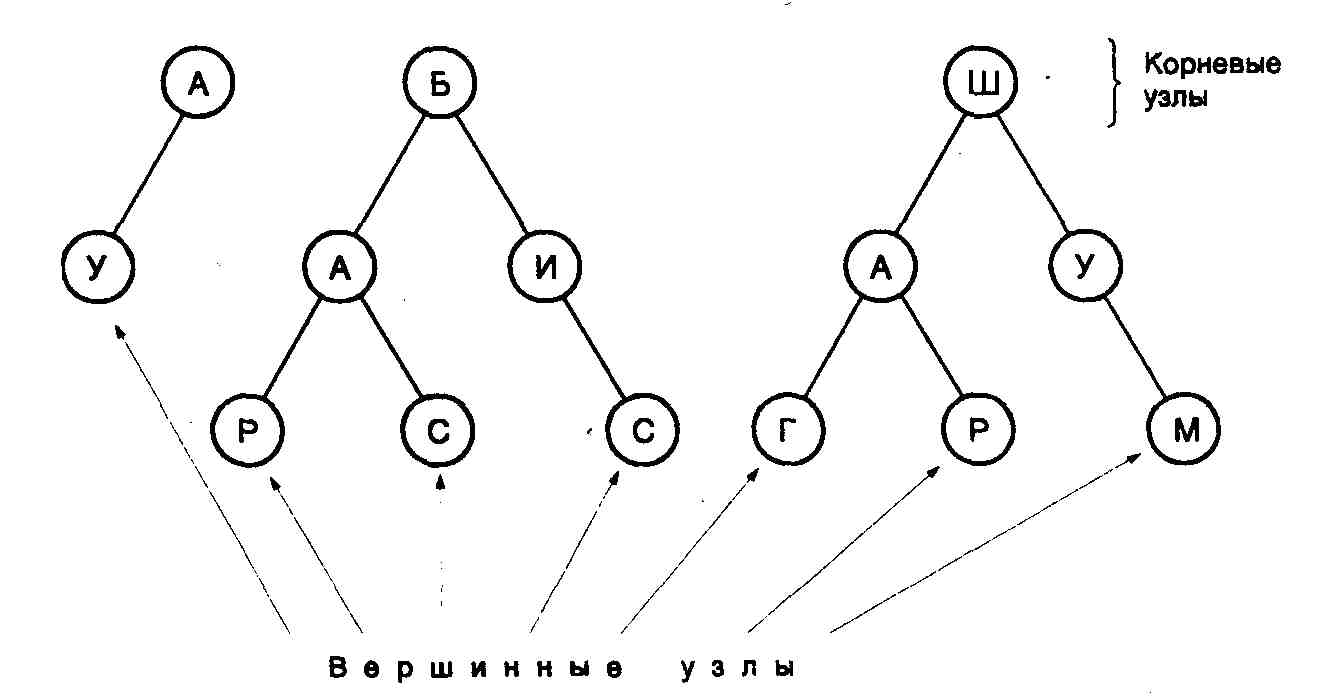
Рис. 8.4. Пример структуры древовидного словаря последовательностей стандарта V.42bis
Алгоритм сжатия, определяемый стандартом V.42bis, весьма гибок. К параметрам, значения которых могут быть согласованы между модемами, относятся: максимальный размер кодового слова, общее число кодовых слов, размер символа, число символов в алфавите и максимальная длина последовательности. Кроме того, алгоритм осуществляет мониторинг входного и выходного потока данных для определения эффективности сжатия. Если сжатия не происходит или оно невозможно (в силу природы передаваемых данных) алгоритм прекращает свою работу. Это свойство обеспечивает лучшие рабочие характеристики при передаче файлов, которые уже были сжаты (заархивированы) или которые не поддаются сжатию.
Дело в том, что в его постановке и выводах произведена подмена, аналогичная подмене в школьной шуточной задачке на сообразительность, в которой спрашивается:
- Cколько яблок на березе, если на одной ветке их 5, на другой ветке - 10 и так далее
При этом внимание учеников намеренно отвлекается от того основополагающего факта, что на березе яблоки не растут, в принципе.
В эксперименте Майкельсона ставится вопрос о движении эфира относительно покоящегося в лабораторной системе интерферометра. Однако, если мы ищем эфир, как базовую материю, из которой состоит всё вещество интерферометра, лаборатории, да и Земли в целом, то, естественно, эфир тоже будет неподвижен, так как земное вещество есть всего навсего определенным образом структурированный эфир, и никак не может двигаться относительно самого себя.
Удивительно, что этот цирковой трюк овладел на 120 лет умами физиков на полном серьезе, хотя его прототипы есть в сказках-небылицах всех народов всех времен, включая барона Мюнхаузена, вытащившего себя за волосы из болота, и призванных показать детям возможные жульничества и тем защитить их во взрослой жизни. Подробнее читайте в FAQ по эфирной физике.
|
|
