Здесь рассматривается I/O на базе ОС Linux версии 2.6 и старше.
Файл
-
фундаментальная абстракция в Linux. Linux придерживается
философии <все есть файл>, а значит большая часть взаимодействия реализуется
через чтение и запись файлов. Операции с файлом осуществляются с помощью
уникального дескриптора - файлового дескриптора или fd. Большая часть
системного программирования в Linux состоит в работе с файловыми дескрипторами.
Существуют обычные и специальные файлы
Обычный файл, regular file
-
это именованная запись на каком-либо носителе информации, то к чему мы
привыкли (самый обыкновенный <файл> в привычном понимании).
Специальный файл, special file
-
это некоторый объект, который для различных действий над ним
представляется как файл.
Linux поддерживает 4 разновидности специальных файлов:
Файлы блочных устройств
Файлы устройств посимвольного ввода-вывода
Именованные конвейеры (named pipe или FIFO)
Сокеты
Сокет (англ. socket - углубление, гнездо, разъём)
-
название программного интерфейса для обеспечения обмена данными между процессами. Процессы при таком
обмене могут исполняться как на одной ЭВМ, так и на различных ЭВМ, связанных
между собой сетью. Сокет - абстрактный объект, представляющий конечную точку
соединения. Следует различать клиентские и серверные сокеты.
Клиентский сокет
-
это оконечный, терминальный интерфейс, предназначенный для
установления связи с сервером. Точнее, с серверным сокетом, даже если этот
сокет выполнен на другом языке программирования. Нахождение нужного сервера
осуществляется в сети по его имени, либо IP-адресу. После установления
соединения программа может взаимодействовать с сервером, а именно - посылать и
принимать данные.
Серверный сокет
-
это своеобразный программный коммутатор, в котором могут использоваться
принципы мультиплексирования, так как он предполагает обмен данными с многими
клиентами. В принципе, от клиентской реализации он отличается тем, что способен
работать с несколькими клиентами одновременно. На базе серверного сокета можно
создавать программы - серверы, которые предоставляют возможность внедрять
собственные протоколы верхнего уровня, т. е. реализовывать различные схемы
обмена данными.
Клиентское приложение (например, браузер) использует только клиентские
сокеты, а серверное (например, веб-сервер, которому браузер посылает запросы)
- как клиентские, так и серверные сокеты.
Интерфейс сокетов впервые появился в BSD Unix. Программный интерфейс сокетов
описан в стандарте POSIX.1 и в той или иной мере поддерживается всеми
современными операционными системами.
Сокеты и является предметом рассмотрения, потому как сокеты обеспечивают
коммуникацию между двумя различными процессами, которые могут находится на
разных компьютерах (клиент-сервер). Фактически сетевое программирование и
программирование для интернета строится именно на сокетах.
В первом приближении достаточно рассматривать только регулярные файлы и
сокеты.
Модели ввода/вывода
Всего в Unix подобных системах доступно 5 + 1 различных моделей ввода/вывода. <Плюс одна> я объясню немного позже, а пока рассмотрим каждую модель более детально.
Блокирующий I/O (blocking I/O)
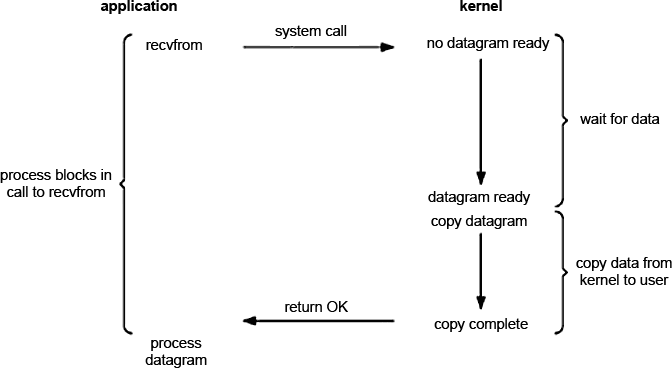
По умолчанию весь ввод вывод выполняется в блокирующем стиле. Рассмотрим схематичное изображение процессов происходящих при блокирующем вводе/выводе.
В данном случае процесс делает системный вызов recvfrom. В результате процесс заблокируется (уйдет в сон) до тех пор пока не придут данные и системный вызов не запишет их в буфер приложения.
После этого системный вызов заканчивается (return OK) и мы можем обрабатывать наши данные.
Очевидно, что данный подход имеет очень большой недостаток - пока мы ждем данные (а они могут идти очень долго из-за качества коннекта и т.п.) процесс спит и не отвечает на запросы.
Неблокирующий I/O (nonblocking I/O)
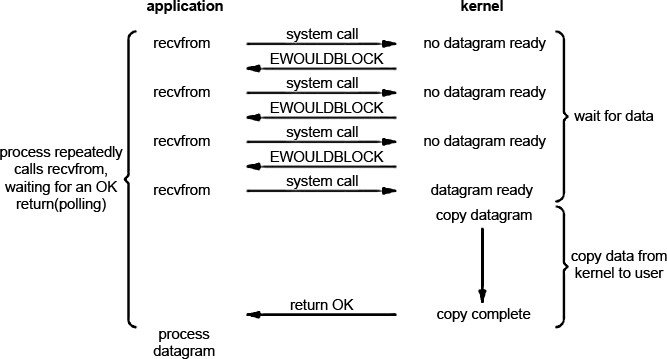
Мы можем установить неблокирующий режим при работе с сокетами, фактически сказав ядру следующее: <Если ввод/вывод, который мы хотим осуществить, невозможен без погружения процесса в блокировку (сон), то верни мне ошибку что не можешь этого сделать без блокировки.> Рассмотрим схематичное изображение процессов происходящих при неблокирующем вводе/выводе.
Первые три раза, которые мы посылаем системный вызов на чтение не возвращают результат, т.к. ядро видит, что данных нет и просто возвращает нам ошибку EWOULDBLOCK.
Последний системный вызов выполнится успешно, т.к. данные готовы для чтения. В результате ядро запишет данные в буфер процесса и они станут доступными для обработки.
На этой основе можно создать цикл, который постоянно вызывает recvfrom (обращается за данными) для сокетов, открытых в неблокирующем режиме. Этот режим называется опросом (поллинг/polling) т.к. приложение все время опрашивает ядро системы на предмет наличия данных. Я принципиально не вижу ограничений чтоб опрашивать несколько сокетов последовательно и соответственно читать из первого, в котором есть данные. Такой подход приводит к большим накладным расходам (overhead) процессорного времени.
Мультиплексирование I/O (multiplexing I/O)
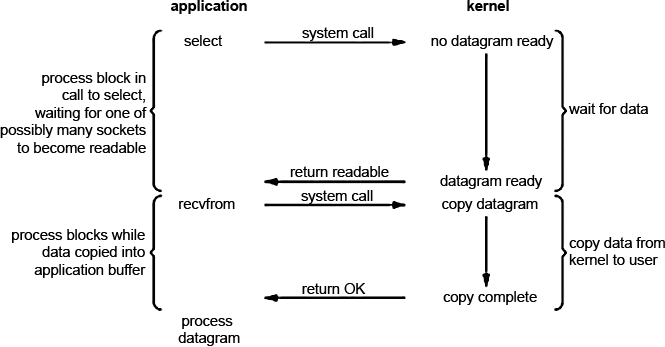
Вообще слово multiplexing переводится как <уплотнение>. Мне кажется его удачно можно описать девизом тайм-менеджмента - <учись успевать больше>. При мультиплексировании ввода/вывода мы обращаемся к одному из доступных в ОС системному вызову (мультиплексору например select, poll, pselect, dev/poll, epoll (рекомендуемый для Linux), kqueue (BSD)) и на нем блокируемся вместо того, чтобы блокироваться на фактическом I/O вызове. Схематично процесс мультиплексирования представлен на изображении
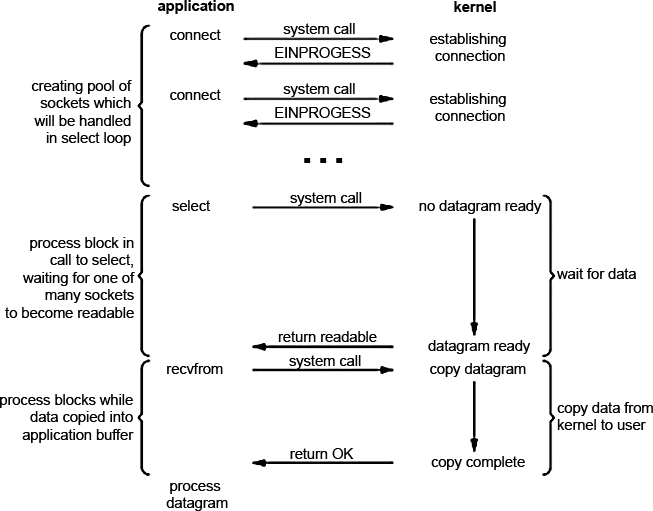
Приложение блокируется при вызове select'a ожидая когда сокет станет доступным для чтения. Затем ядро возвращает нам статус readable и можно получать данные помощью recvfrom. На первый взгляд - сплошное разочарование. Та же блокировка, ожидание, да и еще 2 системных вызова (select и recvfrom) - высокие накладные расходы. Но в отличии от блокирующего метода, select (и любой другой мультиплексор) позволяет ожидать данные не от одного, а от нескольких файловых дескрипторов. Надо сказать, что это наиболее разумный метод для обслуживания множества клиентов, особенно если ресурсы достаточно ограничены. Почему это так? Потому что мультиплексор снижает время простоя (сна). Попробую объяснить следующим изображением
Создается пул дескрипторов, соответствующих сокетам. Даже если при соединении нам пришел ответ EINPROGRESS это значит, что соединение устанавливается, что нам никак не мешает, т.к. мультиплексор в ходе проверки все равно возьмет тот, который первый освободился.
А теперь внимание! Самое главное!
Ответьте на вопрос: У какого события вероятность больше? У события А, что данные будут готовы у какого-то конкретного сокета или у события Б, что данные будут готовы хотя бы у одного сокета?. Ответ: Б
В случае с мультиплексированием у нас в цикле проверяются ВСЕ сокеты и берется первый который готов. Пока мы с ним работаем, другие также могут подоспеть, тоесть мы снижаем время на простой (первый раз мы может ждем долго, но остальные разы - гораздо меньше).
Если же решать проблему обычным способом (с блокировкой) то нам придется гадать, из какого коннекта прочитать первым вторым и т.п. т.е. мы 100% ошибемся и будем ждать, а хотя могли бы не тратить это время.
I/O в тредах/дочерних процессах (One file descr per thread or process)
Говоря в начале что существует 5 + 1 способ, имелся ввиду как раз такой подход, когда используется несколько потоков или процессов, в каждом из которых производится блокирующий I/O. Он похож на мультиплексирование ввода/вывода, но при этом имеет ряд недостатков. Всем известный - потоки в линуксе достаточно дорогие (с т.з. системных команд), так что использование потоков вызывает увеличение накладных расходов. К тому же если рассматривать python в качестве языка программирования, в нем существует GIL и соответственно в каждый момент времени внутри 1 процесса может выполняться только один поток. Другой вариант - создавать дочерние процессы для обработки ввода/вывода в блокирующем стиле. Но тогда надо продумывать взаимодействие между процессами (IPC - interprocess communication), что имеет некоторые сложности. К тому же если суммарное количество ядер не превышает единицы, то такой подход имеет сомнительный выигрыш. Кстати, насколько я знаю Apache работает как раз примерно по такой схеме (MPM prefork или threads) обслуживая клиента либо в треде либо в отдельном процессе.
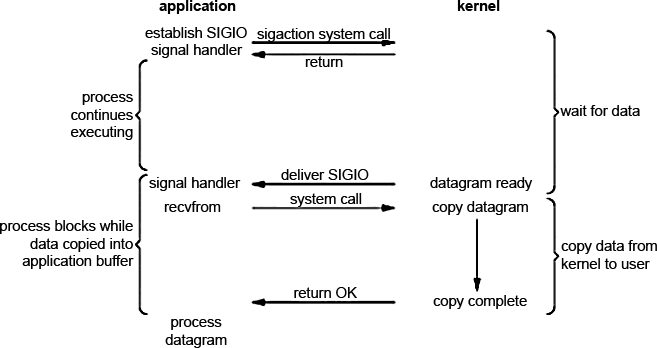
Существует возможность использовать сигналы, заставляя ядро посылать нам сигнал вида SIGIO, когда появляется возможность считать данные без блокировки (дескриптор готов к считыванию). Схематично такой подход представлен на изображении
Вначале необходимо установить параметры сокета для работы с сигналами и назначить обработчик сигналов (signal handler) с помощью системного вызова sigaction. Результат возвращается мгновенно и приложение, следовательно, не блокируется. Фактически, всю работу на себя берет ядро, т.к. оно отслеживает когда данные будут готовы и посылает нам сигнал SIGIO, который вызывает установленный на него обработчик (функция обратного вызова, callback). Соответственно сам вызов recvfrom можно сделать либо в обработчике сигнала, либо в основном потоке программы. Насколько я могу судить, здесь есть одна проблема - сигнал для каждого процесса такого типа может быть только один. Т.е. за раз мы можем работать только с одним fd (хотя я не уверен)
Асинхронный ввод/вывод (asyncronous I/O)
Асинхронный ввод/вывод осуществляется с помощью специальных системных вызовов. В основе лежит простая идея - ядру дается команда начать операцию и уведомить нас (с помощью сигналов, или еще как-то) когда операция ввода/вывода будет полностью завершена (включая копирование данных в буфер процесса). Это основное отличие данной реализации от реализации на сигналах. Схематично процессы асинхронного ввода вывода представлены на изображении.
Делаем системный вызов aio_read и указываем все необходимые параметры. Всю остальную работу делает за нас ядро. Конечно, должен существовать механизм который бы уведомил процесс о том что I/O завершен. И тут потенциально возникает множество проблем. Но об этом в другой раз.
Вообще с данным термином связано очень много проблем, примеры ссылок уже приводились. Часто происходит смешение понятий между асинхронным, неблокирующим и мультиплексированным вводом выводом, видимо потому что само понятие <асинхронный> может трактоваться по-разному. В моем понимании асинхронный - значит независимый во времени. Тоесть единожды запущенный он живет своей жизнью пока не выполнится, а затем мы просто получаем результат
Ввод-вывод на практике
На практике происходит комбинирование разных моделей исходя из задачи. Поступают следующим образом:
Используют по потоку/процессу на каждую операцию с блокировкой - не выгодно
Много клиентов в разных тредах/процессах. Каждый тред/процесс использует мультиплексор
Много клиентов в разных тредах/процессах. Используется асинхронный ввод/вывод (aio)
Я надеюсь что теперь хоть немного станет ясно об отличиях в тех вещах, в которых легко запутаться.
Ну и да, мультиплексинг рулит (пока не допилят aio, я думаю).
Изучая справочную литературу я пришел к выводу что в отличии от сокетов, регулярные файлы невозможно перевести в неблокирующий режим. Для них вроде бы доступен aio что рассмотрено тут: Asynchronous I/O on linux or welcome to hell
Знаете ли Вы, что защищённый режим компьютера, разработан фирмой DEC и заключается в том, что программист и разрабатываемые им программы используют логическое адресное пространство, размер которого может быть намного больше, чем объем ОЗУ. Логический адрес преобразуется в физический адрес автоматически с помощью схемы управления памятью (MMU). При этом содержимое сегментного регистра не связано напрямую с физическим адресом, а является номером сегмента в соответствующей таблице. Благодаря защищённому режиму, в памяти может храниться только та часть программы, которая необходима в данный момент, а остальная часть может храниться во внешней памяти (например, на жёстком диске). В случае обращения к той части программы, которой нет в памяти в данный момент, операционная система может приостановить программу, загрузить требуемую секцию кода из внешней памяти и возобновить выполнение программы. Следовательно, становятся допустимыми программы, размер которых больше объёма имеющейся памяти, и пользователю кажется, что он работает с большей памятью, чем на самом деле.