Каждый день, имея дело с персональными компьютерами, мы стали забывать, для
чего они разрабатывались изначально. Первыми целями были военные и научные
области, всегда сопряжённые со сложными вычислениями. Потому речь пойдёт о
суперкомпьютерных вычислениях. Самые первые устройства для счёта были разработаны для решения задач, которые было сложно или невозможно решить обычными средствами. И с развитием этих устройств росла и потребность в их производительности, что стимулирует их дальнейший рост.
Родоначальниками машин для высокопроизводительных вычислений были системы, использовавшие специальные процессоры, сложные коммуникационные решения, обладавшие большим энергопотреблением и стоимостью. Стоимость обуславливалась уникальностью устанавливаемого оборудования, в первую очередь процессоров.
С переходом на архитектуру MPP (Massive parallel processing) - массовую параллельную обработку, где использовалось большое число серийно выпускаемых процессоров, удалось заметно снизить затраты на создание суперкомпьютеров, поскольку не использовались уже разработанные технологии. Основная стоимость и сложность теперь заключалась в использовании специальных коммуникационных решений для связи этих процессоров. У каждой фирмы были свои разработки и порой создавались под конкретное решение. Несмотря на эффективность, высокая стоимость заставила задуматься об альтернативных решениях.
Такой альтернативой стал проект "Беовульф", созданный в 94-м году. Его суть заключалась в создании вычислительного комплекса (кластера) на основе обычных компьютеров, объединённых недорогой сетью, с распространённой и доступной операционной системой (обычно Linux). Преимущества очевидны - все компоненты легко можно купить и собрать, отсутствие специализированных решений и компонент значительно снизило затраты. Минусом является более низкая скорость обмена данными между узлами, ввиду использования обычной компьютерной сети.
Реализация проекта Беовульф привела к возникновению большого числа последователей, ибо она заложила основу для значительно более низких по стоимости высокопроизводительных вычислений. Примером может стать система Avalon, которая была собрана в 98-м году на базе процессоров Alpha 21164A с частотой 533МГц. Изначально кластер содержал 68 процессоров, затем был расширен до 140. В том же году разработчики выступили на конференции Supercomputing'98, где получили первое место в номинации "Лучшее соотношение цена/производительность" ("1998 Gordon Bell Price/Performance Prize") за доклад "Avalon: An Alpha/Linux Cluster Achieves 10 Gflops for $150k" (Авалон: кластер Alpha/Linux достигает 10 ГФлопс за 150 тыс. дол.). В расширенном варианте его стоимость составляла порядка 313 тысяч долларов, а производительность была на уровне суперкомпьютера 64-мя процессорами SGI Origon 2000, чья стоимость была порядка 1,8 миллионов долларов. Кластер занял 114 место в 12-м издании top500, с производительностью (в тесте LINPACK) 44.7Гфлопс.
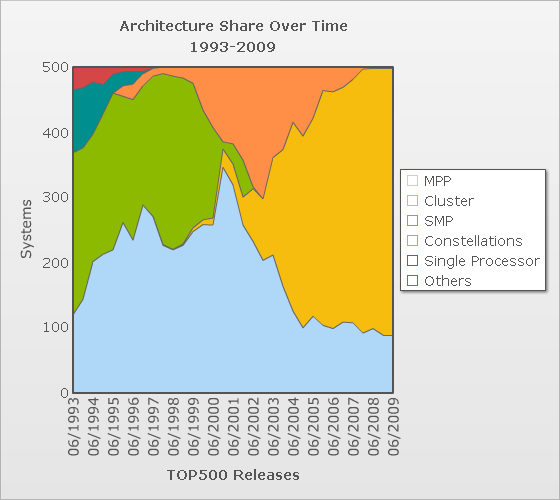
В 2000 году в top500 (15-й выпуск) количество кластерных решений составляло 2.2%. В 2004 в 23 выпуске - 57,8%, в нынешнем, 30-м выпуске - 81,2%. Динамика по годам представлена на графике -
Другой график характеризует распределение суммарной мощности систем по различным архитектурам:

Являются ли кластеры панацеей для высокопроизводительных вычислений или нет? Необходимо учитывать, что их слабое место - скорость коммуникации между узлами. Чтобы дальше анализировать сильные и слабые места необходимо рассмотреть, какими же основными скоростными параметрами характеризуются суперкомпьютеры и вообще вычислительные комплексы.
Вычислительная мощность узла
Популяризация кластерных суперкомпьютеров показала, что существуют более доступные по цене альтернативы, в некоторых приложениях ничуть не уступающие классическим суперкомпьютерам (MPP). Изменилась ли ситуация сейчас, по прошествии большого (по масштабам компьютерного рынка) промежутка времени? Какие сейчас существуют решения, позволяющие производить вычисления с высокой скоростью?
В современных суперкомпьютерах и настольных решениях повсеместно используются скалярные процессоры. Множество же задач может быть представлено в векторном виде. Раньше часто суперкомпьютеры были основаны на следующей концепции - несколько скалярных систем поставляют данные для одного векторного процессора, который их обрабатывает. Так было с Cray. Сейчас есть возможность передавать данные с высокой скоростью, и такой потребности нет. Наоборот, есть недостаток вычислительной мощности. Часто компании создают специализированные процессоры, но они редко получают широкое распространение, в первую очередь по причине слабой вычислительной мощности. Первым процессором, который смог изменить эту ситуацию стал Cell. Совместная разработка Sony, IBM и Toshiba, которая предназначалась в качестве сердца игровой приставки Sony Playstation 3, она привнесла новый принцип создания продуктов. Новая концепция подразумевала соединение с устройствами, оснащёнными таким же процессором для распределения нагрузки. Для этого он снабжён высокоскоростным интерфейсом FlexIO с теоретической скоростью 62,4ГБ/с. Примером была приставка с процессором Cell, телевизор и DVD рекордер. После игры человек захотел записать повтор на диск. Во время этого, процессор приставки и телевизора помогают рекордеру записать диск, после чего возвращаются к расчётам, связанным с игрой, усиливая мощность встроенного в приставку процессора. Сам процессор представляет собой два ядра архитектуры Power (PPE или Power Processor Element), применяемого в процессорах PowerPC и 8 векторных ядер, называемых SPE (Synergistic Processing Element), работающие на частоте 3.2ГГц. Такие особенности, как наличие у каждого из векторных ядер своей памяти вместо кэша, позволяет программисту управлять ими по своему желанию, что невозможно с кэш памятью. 8 векторных ядер предназначены для просчёта графики, являющейся в большинстве своём векторной, с чем легко справляются, благодаря невиданной мощности. Процессорный элемент Power может выполнять 8 инструкций с одинарной точностью (32 бита) и, работая на частоте 3.2ГГц, имеет пиковую скорость в 25,6 Гфлоп, или 2 операции двойной точности, с итоговой скоростью 6,4 Гфлоп каждый. Вторая часть это SPE. Они могут выполнять 4 инструкции с плавающей запятой одинарной точности, достигая пика в 25,6Гфлоп каждый. При выполнении задач с одинарной точностью скорость значительно падает, всё же оставаясь на уровне в 14 Гфлоп. Но с одинарной точностью выходит порядка 204,8. Итого получается, что пиковая производительность одного процессора - 256 Гфлоп при работе с одинарной точностью и 124,8 Гфлоп с двойной. В тесте с двойной точностью Linpack команда разработчиков продемонстрировала скорость порядка 100Гфлоп.

Сразу после появления продукта, Sony объявила, что применением в игровых приставках дело не ограничится, и они будут использованы в разнообразных сферах. Учитывая его мощность, в это легко верится. Компания IBM объявила о выпуске Blade серверов на их основе (высокопроизводительных и компактных систем). Рекомендовалось их встраивать в серверы, дабы разгрузить их, выполняя специфичные расчёты. В пример приводились игровые серверы, где высока доля векторных вычислений и вычислений с плавающей точкой.
Один астрофизик, Гаурав Ханна (Gaurav Khanna) даже использует их, полностью отказавшись от суперкомпьютеров. Он занимается проблемой гравитационных волн и моделированием поглощения звезды сверхмассивной чёрной дырой. Ранее он использовал для расчётов суперкомпьютеры, арендуя их на деньги с грантов, но затем, обратил внимание на альтернативу. Написав программу, оптимизированную под архитектуру Cell, он запустил её на 8 объединённых в сеть приставках Playstation 3. По его утверждениям, замена является практически равноценной и ему теперь не нужно прибегать к использованию суперкомпьютеров, заменив 200 узлов на 8 приставок. Цена аренды одного сеанса суперкомпьютера составляла порядка 5000 долларов, цена же восьми приставок - 3200. Компания Sony всячески поощряет разностороннее использование своих приставок, особенно для научных расчётов. Несколько дистрибутивов Linux уже поддерживают данные процессоры, потому переход достаточно прозрачен. Основная проблема этого варианта - то, что при работе с числами с двойной точностью снижается скорость работы (хотя остаётся на весьма приличном уровне), и что необходимо писать программы иначе, с учётом архитектурных особенностей процессора и с использованием векторных расчётов. Существует ещё недостаток в виде отсутствия у процессора каких-либо механизмов по предсказанию переходов и ветвлений, но её предложено решать с помощью компилятора, заранее разрабатывая программу, с инструкциями подготовки к ветвлению. Это достаточно большая проблема, но как показал Гаурав Канна, проблема решаемая.

GPGPU, General purposed Computation Using Graphics Hardware - вычисления общего назначения с использованием графического аппаратного обеспечения. Развитие индустрии игровой привело к развитию, как процессоров, так и видеокарт. Современные видеокарты уже сопоставимы по производительности с процессорами, а последние поколения уже имеют превосходство. Логично родилась мысль о задействовании этих мощностей и проведении расчётов на графических процессорах. Графический процессор обладает массивом простых векторных конвейеров, которые могут совершать простые операции с векторами, но с огромной скоростью. Так, производительность ускорителя AMD FireStream 9170 (на базе всем известного чипа RV670) составляет порядка 500GFLOPS. Такова же, примерно, производительность G80. Обе компании представили технологии, NVIDIA - GPU Computing (CUDA), ATI - Stream Computing. Суть одна - создание платформы для вычислений на процессорах. Последние процессоры, в частности R600 и G80 обладают уже скалярными ALU процессорами. Моделирование физических явлений - одна из областей, где карты показывают себя во всей красе. Главный недостаток - отсутствие двойной точности вычислений преодолен с выходом нового поколения ускорителей. Остались другие - узкая направленность - отсутствие кэша и алгоритмов предсказывания так же как у Cell перекладывает заботу об этих вещах на головы программистов. С другой стороны, NVIDIA включила в свои драйвера поддержку CUDA, потому дополнительно устанавливать клиенту ничего не понадобится. Большой объём памяти и высокая скорость работы с ней делает карту весьма ценной для ряда задач, подобно моделированию, когда необходимо провести солидные расчёты с большим объёмом данных. Разработчики уже начали создавать приложения, могущие в повседневной работе помочь центральному процессору. К чему это приведёт, и не останется ли это всё красивой сказкой, покажет время.
Распределённые вычисления - весьма перспективное направление. Ранее сводилось к работе конкретной программы по схеме клиент-сервер, когда сервер выдаёт задание, а клиенты-компьютеры его считают. Однако отличие от GRID в отсутствии необходимости пользоваться виртуальными машинами - клиент работает с той ОС, под которой запущен. Это увеличивает скорость работы, хотя часто требует настройки. Сейчас большую популярность набирает движение энтузиастов - людей, которые не хотят, чтобы их компьютер просто выделял тепло. Известно, что компьютер используется, в среднем, на 10%. Остальное - простой. Потому появилась идея учёным, которые занимаются исследованиями, создать клиент и предложить желающим запустить его на своих машинах. Самым популярным проектом такого рода стал SETI@Home - проект поиска неземных цивилизаций путём попытки дешифрации сигналов со спутника. Программа работала в качестве скринсейвера и не тормозила работы. Со всё нарастающим числом безлимитных подключений, данная помощь является по-настоящему бесплатной. Платить за трафик согласятся не все, но когда он дармовый, отношение меняется - считает и почему бы и нет? Так, учёные из Стэндфордского университета сейчас изучают моделирование сворачивания (folding) белков. Это поможет понять, как ведут себя белки в разных условиях и приблизиться к победе над раком. Название проекта - Folding@Home, сокращённо F@H. Главная особенность распределённых вычислений - чаще всего скорость обмена данными клиент-сервер очень низка, потому лучше всего решаются задачи, которые можно пересылать редко и малыми объёмами, скажем, раз в несколько суток. Очень часто различные варианты смешиваются. Так, распределённые вычисления являются самой широкой группой вычислений. После совместной работы выпущен клиент Folding@Home, задействующий мощь видеокарт ATI, чуть позже вышла версия под PS3 и его Cell процессоры. Последнее резко увеличило скорость расчётов и именно активная пропаганда Sony и подключение приставок, позволило преодолеть порог мощности этого виртуального суперкомпьютера в 1 петафлоп, что пока недостижимо для суперкомпьютеров. Мощность первого в списке Top500 суперкомпьютера Blue Gene составляет 478 гигафлоп, то есть меньше половины! Это говорит о невероятном потенциале распределённых вычислений. Проект Folding@Home признан самым успешным по количеству задействованных в нём мощностей. Число процессоров давно перевалила 100тыс, но ведь этот проект не единственный, в отличие от Blue Gene такой мощности.
Клиента можно запускать в виде заставки на рабочий стол, визуализирующей процесс вычислений
|
|
