
Строго говоря, проблема поиска документа, отвечающего тем или иным критериям, возникает в любом хранилище
данных, содержащем более одного документа. Очевидно, что решение этой проблемы
так или иначе замыкается на те способы, которые применяются при создании систем
хранения. Можно указать два основных способа:
использование иерархической
модели;
использование гипертекстовой модели.
Использование иерархической
модели подразумевает многоуровневую рубрикацию информационных ресурсов. Для
выбора пути к нужному документу используются описания, составленные службой
поддержки данной системы.
Гипертекстовая модель позволяет связывать документы
ссылками, которые располагаются непосредственно в тексте.
Эти две модели
имеют очевидные недостатки. Так как и многоуровневая рубрикация, и простановка
ссылок выполняется высококвалифицированными специалистами, объем обработанных
таким образом документов не может быть очень большим. По этой же причине
страдает актуальность описания массива документов. Помимо этого связанные
документы ограничены какой-либо одной предметной областью, о которой, к тому же,
у пользователя системы может быть иное представление, чем у составителя
рубрикатора. И наконец, для нахождения необходимого документа пользователю таких
систем потребуется просмотреть множество документов, полезной информацией в
которых будут только ссылки на другие ресурсы.
Эти проблемы становятся
особенно острыми при больших объемах информации, высокой скорости их обновления
и высокой разнородности потребностей пользователей. Помочь в решении этих
проблем призваны информационно-поисковые системы (ИПС). Такие системы, однажды
созданные, могут работать автономно. Принцип их взаимодействия с пользователем
заключается в выдаче списка указателей на документы, удовлетворяющие запросу.
Этот список может быть отсортирован по релевантности (степени соответствия
документа запросу). Таким образом, ИПС может обеспечить очень быстрый поиск
необходимого документа - при том, что от пользователя требуется лишь ввести
запрос.
Первые информационно-поисковые системы были созданы достаточно давно.
Большинство открытий в этой области приходится на 70-е и 80-е годы. Сейчас, с
развитием Интернета, количество пользователей этих систем исчисляется
миллионами, а в скором будущем будет исчисляться миллиардами. Так же
стремительно растет количество документов, хранящихся в Интернете, что ставит
все более сложные задачи перед разработчиками ИПС.
12.1.2. Основные принципы информационного
поиска
Основные принципы информационного поиска были
сформулированы еще в первой половине этого века. Между 1939 и 1945 годами У. Е.
Баттеном была разработана система для отыскания патентов. Каждый патент
классифицировался в соответствии с понятиями, к которым он имел отношение. Для
каждого понятия, использовавшегося в системе, была создана 800-позиционная
перфокарта. При регистрации в системе нового патента находились карты,
соответствующие тем понятиям, которые в нем рассматриваются, и в позиции
пробивались номера патента. Чтобы найти патент, в котором рассматривается
одновременно несколько понятий, необходимо было совместить карты,
соответствующие этим понятиям. Номер нужного патента определялся из позиции
просвета.
Основные принципы информационного поиска с тех пор не изменились.
На примере уже этой ИПС видно, как происходит процесс поиска. Во-первых, должен
быть создан массив указателей на информационные ресурсы. Указатель (index)
содержит в себе некое свойство документа и ссылки на документы, этим свойством
обладающие. Указатели могут быть различных видов. Широко распространен,
например, авторский указатель. Такой указатель позволяет получить ссылки на
работы интересующего нас автора. Также указатели могут быть составлены и по
другим атрибутам документа. В системе Баттена использовался предметный
указатель, то есть документы классифицировались по понятиям (предметам), которые
в них затрагиваются.
Процесс создания указателей на документы называется
индексированием, а термины, использующиеся для индексирования, называются
терминами индексирования. В случае с авторским указателем роль терминов
индексирования будут выполнять фамилии авторов хранящихся в фонде работ.
Совокупность используемых терминов индексирования называется словарем.
Массив
указателей, полученный после индексации информационных ресурсов, называется
индексом (Index database).
После создания индекса к нему обращаются
посредством запросов. Так как процесс поиска заключается в сопоставлении запроса
пользователя с имеющимися данными, полученный запрос также должен быть переведен
на язык индексирования. В индексе выполняется поиск соответствующих запросу
документов, пользователю выдается список ссылок на подходящие ресурсы.
Для
повышения скорости индексирования и поиска словарь и индекс должны быть
упорядочены по системе, наиболее отвечающей задачам поиска в данной предметной
области.
12.1.3. Предметное индексирование и механизм
поиска
Когда говорят об информационно-поисковой системе,
подразумевают, что она использует предметный указатель. Предметный указатель
позволяет отыскивать документы, касающиеся некоего "предмета". Для составления
предметного указателя анализируется содержание документа и определяется
"предмет" или "предметы", о которых в документе идет речь. Затем названия этих
предметов переводятся на информационно-поисковый язык (ИПЯ). Таким образом, мы
получаем поисковый образ документа (ПОД). Проиндексировав (создав поисковые
образы) все информационные ресурсы, мы получаем то, что принято называть
индексом (index database) - основной массив данных ИПС.
Так как процесс
поиска заключается в сопоставлении запроса пользователя с имеющимися данными,
полученный запрос также должен быть переведен на ИПЯ. После сопоставления
переведенного на ИПЯ запроса и поисковых образов документов пользователь
получает список ссылок на документы, которые соответствуют, по мнению системы,
его запросу.
Типовая схема ИПС, использующей предметное индексирование,
представлена на рис. 12.1.
Как видно, поиск происходит не по тексту
документов, а по их поисковым образам, составленным на ИПЯ. Поэтому ИПЯ -
основная часть информационно-поисковой системы, от которой в первую очередь
зависит качество системы. В состав информационно-поискового языка входят:
1.
Словарь индексационyых терминов - множество терминов индексирования.
2.
Кодовый словарь - множество кодовых терминов.
3. Словарь входов - множество
входных терминов.
4. Вспомогательные средства языка индексирования -
средства, используемые совместно с индексационными терминами для расширения или
сужения определенных понятий.
5. Правила использования языка
индексирования.
Для повышения эффективности поиска словарь, используемый
системой, должен быть контролируемым, то есть он должен быть организован таким
образом, чтобы полнота и точность поиска была оптимальной. Очевидно, что
организация словаря зависит от многих факторов - предметной области, в которой
будет использоваться ИПС, характера интересов пользователей, степени их
подготовки и т. д.
Рис. 12.1. Типовая схема ИПС
Для улучшения результатов
поиска необходимо определить степень специфичности терминов, используемых при
индексации. Принято использовать два принципа - использование наиболее
специфического термина, соответствующего объему и содержанию отражаемого
понятия, и избыточное индексирование.
Под избыточным индексированием
понимается дополнение поискового образа терминами, связанными с основным. При
этом могут использоваться термины, связанные как с основным отношением обобщения
или спецификации, так и ассоциативной связью. Дополнение поискового образа
терминами с ассоциативной связью может увеличить полноту поиска, но неизбежно
понижает его точность. Недостатком избыточного индексирования является также
увеличение объема поисковых образов. Для решения этой проблемы во многих ИПС
используется избыточное индексирование не документов, а
запросов.
Использование предметного индексирования не исключает использования
при создании поискового образа атрибутов документа. Это могут быть такие
атрибуты, как данные об авторе, дата публикации, язык публикации и т. д.
12.1.4. Стратегии
поиска
Точность и полнота поиска зависят не только от
характеристик самой ИПС, но и от того, как создается запрос. Идеальный запрос
может быть составлен пользователем, в полном объеме знакомым с той предметной
областью, которая его интересует, а также с используемой ИПС. Но такому
пользователю ИПС, очевидно, не нужна.
Остальные же пользователи вынуждены
довольствоваться или низкой точностью поиска, или низкой полнотой. Для повышения
качества поиска можно использовать различные методы. Наиболее употребляемый из
них - использование логических операторов AND, OR, NOT.
Использование
логических операторов - довольно простой способ повысить релевантность
выдаваемых документов, но он имеет и свои недостатки. Главный из них - плохая
масштабируемость. Применение оператора AND может сильно сузить выдачу, а
оператора OR - сильно расширить.
Степень точности и полноты поиска зависит от
того, насколько общие термины использовались при формулировке запроса. Может
быть неверным использование как наиболее общих терминов (возрастает уровень
информационного шума), так и слишком специфичных терминов (снижается полнота
поиска). Использование слишком специфичных терминов может быть чревато еще и
тем, что в словаре ИПС этого термина может не оказаться.
В общем виде
процедура поиска является процедурой итеративной, то есть за этапом выдачи
результатов поиска следует коррекция запроса, поиск по этому запросу и т. д.
Схематично такая процедура показана на рис. 12.2.
Коррекция запроса
происходит исходя из количества полученных документов и их релевантности, и
может выполняться как пользователем, так и самой информационно-поисковой
системой.

Рис. 12.2. Процедура поиска
В зависимости от соотношения полноты и точности найденных документов
пользователь может сузить или расширить область поиска, перейдя к более общим
или, наоборот, более специфичным терминам, а также использовав родственные
понятия. В случае поиска по нескольким терминам такая коррекция области поиска
может происходить по одному из нескольких терминов, что позволяет изменять эту
область достаточно плавно.
Может оказаться полезным знание пользователя о
наличии определенно релевантных документов. Не найдя их в списке найденных
документов, область поиска надо расширить.
Коррекция запроса системой
информационного поиска происходит на основании анализа документов, помеченных
пользователем как наиболее точно отвечающих его потребности. В таком случае при
следующем поиске система ищет те документы, в которых, помимо заданных в
первоначальном запросе, содержатся термины, встречающиеся в документах,
отмеченных пользователем.
Улучшить результаты поиска можно различными
способами, если функции для этого предоставляются интерфейсом
информационно-поисковой системы.
12.1.5. Интерфейс
системы
Важным фактором, во многом определяющим эффективность
поиска, может быть вид представления информации в программе, то есть ее
интерфейс. По форме диалога, способу задания условия отбора и механизму поиска
рассматриваемые программные средства можно разделить на два класса:
системы
рубрикационного типа;
структурно-логические системы.
Первые реализуются
интерфейсом в виде иерархических последовательно раскрывающихся списков, через
которые обеспечивается доступ к тематически связанным группам документов.
Раскрывая очередную рубрику и перемещаясь, таким образом, по тематической
иерархии, пользователь уточняет предметную область и увеличивает (усредненно)
степень точности соответствия выдаваемых документов и информационной
потребности. При таком решении предопределенность соотнесения документов с
отдельными рубриками компенсируется логичностью естественно-научной
классификационной схемы, заменяющей пользователю
путеводитель.
Структурно-логические методы формирования запроса обычно
используются для работы с базами данных структурированной информации, когда
каждый документ состоит из многих информационных полей, возможно, разного типа.
Критерий отбора в этом случае строится как логическая комбинация простых,
сводящихся к проверке условия присутствия или отсутствия в документе, слов (имен
собственных или имен понятий, определяющих предмет поиска).
При составлении
запроса к системе используют либо "меню-ориентированный" подход, либо командную
строку. Первый позволяет ввести список терминов, обычно разделяемых пробелом, и
выбрать тип логической связи между ними. Логическая связь распространяется на
все термины. Многие ИПС позволяют сохранять запросы пользователя - в большинстве
систем это просто фраза на ИПЯ, которую можно расширить за счет добавления новых
терминов и логических операторов. Но это только один способ использования
сохраненных запросов, называемый расширением или уточнением запроса. Для
выполнения этой операции традиционная ИПС хранит не запрос как таковой, а
результат поиска - список идентификаторов документов, который объединяется или
пересекается со списком, полученным при поиске документов по новым терминам.
12.1.6. ИПС глобальных
сетей
ИПС глобальной сети имеет отличия, обусловленные как
характером сети, так и особенностями работы пользователей такой системы.
Рассмотрим основные особенности использования ИПС в глобальной сети на примере
сети Интернет.
Схематично ИПС для Интернета выглядит так, как показано на
рис. 12.3:
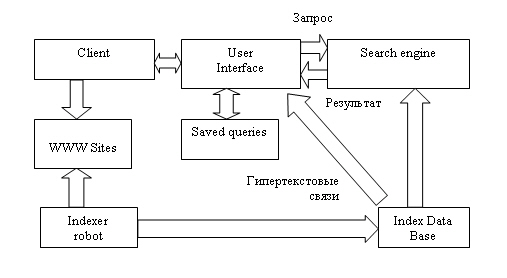
Рис. 12.3. ИПС для Интернета
Client (клиент) на этой
схеме - это программа просмотра конкретного информационного ресурса. Такая
программа обеспечивает просмотр документов WWW, Gopher, Wais, FTP-архивов,
почтовых списков рассылки и групп новостей Usenet. В свою очередь, все эти
информационные ресурсы являются объектом поиска информационно-поисковой
системы.
User interface (пользовательский интерфейс) - способ общения
пользователя с поисковым аппаратом: системой формирования запросов и просмотра
результатов поиска.
Search engine (поисковая машина) - служит для трансляции
запроса на информационнопоисковом языке, в формальный запрос системы, поиска
ссылок на информационные ресурсы Сети и выдачи результатов этого поиска
пользователю.
Index database (индекс базы данных) - индекс, который является
основным массивом данных ИПС и служит для поиска адреса информационного ресурса.
Queries (запросы пользователя) - сохраняются в его (пользователя) личной базе
данных. На отладку каждого запроса уходит достаточно много времени, и поэтому
чрезвычайно важно запоминать запросы, на которые система дает хорошие
ответы.
Index robot (робот индексирования) - служит для просмотра данных в
Интернете и поддержания базы данных индекса в актуальном состоянии. Эта
программа является основным источником информации о состоянии информационных
ресурсов сети.
WWW sites - это весь Интернет, или, точнее, информационные
ресурсы, просмотр которых обеспечивается программами просмотра.
Как мы видим,
источником информации о состоянии информационных ресурсов сети является
робот-индексировщик. Это программа, которая по определенному алгоритму "заходит"
на различные страницы, "читает" их и индексирует.
Индекс поисковых систем
Интернета обновляется с периодичностью около недели. Отсюда видно, что в индекс
поисковой системы не могут попасть материалы, например, периодических изданий,
так как выходят они заведомо чаще, чем обновляется индекс.
Еще одна проблема
заключается в том, что не все документы хранятся в виде файлов HTML, с которыми
роботу работать легче всего. Если информация хранится в другом формате, может
сложиться ситуация, когда адрес страницы, выдаваемой пользователю, содержит
параметры, которые робот не знает, и, следовательно, он не может эти данные
проиндексировать
Объем информации, опубликованной в Интернете, приводит также
к ограничению количества терминов, которыми индексируется документ. Современные
ИПС в Интернете используют порядка 100 терминов для индексации документа. Выбор
терминов, используемых для индексации, зависит от реализации данной системы.
Чаще всего первым критерием является отношение частоты употребления термина в
документе к частоте употребления этого термина во всех ранее проиндексированных
документах. То есть наибольший вес присваивается тем терминам, которые наиболее
часто встречаются в данном документе и наиболее редко - во всех остальных
проиндексированных документах. Термины, которые используются в очень большом
количестве документов, при индексировании не используются совсем.
Для
определения терминов индексирования, используемых для создания поискового
образа, робот может также использовать разметку индексируемой страницы. И в
индексе присваивать наибольший вес термину, используемому, например, в
заголовке. Автор информационного ресурса также может повлиять на индексацию
собственной страницы, указав роботу, какие термины надо использовать для
индексирования. Но многие поисковые системы отказались от использования описаний
ресурсов, представленных авторами. Это было сделано по причине
недобросовестности некоторых авторов, которые использовали для описания своих
страниц термины, наиболее часто встречающиеся в запросах.
Так как на запрос
могут быть выданы ссылки на сотни ресурсов, необходимо предоставить пользователю
отсортированный список. Наиболее часто используется сортировка по релевантности.
Она происходит по тем же принципам, что и отбор терминов, применяющихся при
индексировании.
Как уже отмечалась ранее, произвести точный поиск тем
сложнее, чем шире круг потребностей пользователей системы. В глобальной сети эта
проблема принимает глобальный же характер.
Очень сильно усложняется поиск по
причине непрофессионализма как пользователя, формулирующего запрос, так и автора
информационного ресурса. И если непрофессионализм пользователя мешает лишь ему
самому (если не считать непроизводительной загрузки поискового сервера), то
непрофессионализм автора ресурса стоит гораздо больше. Многие отмечают все время
растущий уровень шума в результатах, выдаваемых на запрос.
Для уменьшения
уровня этого шума может использоваться платная регистрация ресурса, которая
подразумевает, что автор ответственно относится к его содержимому. Существует,
например, система платной регистрации RealNames. База данных этой службы
используется некоторыми поисковыми системами. Ресурсы, зарегистрированные в базе
RealNames, будут помещаться в начало списка найденных документов.
|
|
