7.1. Основные понятия теории баз данных
7.1.1. Понятие базы данных
7.1.2. Модели организации данных
7.1.3. Реляционная модель данных
7.1.4. Язык SQL
7.1.5. Программные системы управления базами данных
7.1.6. Применение СУБД в экономике
7.2. СУБД MS Access и ее основные возможности
7.2.1. Общая характеристика СУБД MS Access
7.2.2. Основные этапы разработки базы данных в среде MS Access
7.2.3. Экономические приложения СУБД MS Access
7.2.4. Создание таблиц и схем данных
7.2.5. Создание схемы данных
7.2.6. Разработка запросов к базе данных
7.2.7. Конструирование экранных форм для работы с данными
7.2.8. Конструирование отчетов
7.2.9. Средства макропрограммирования в MS Access
7.2.10. Разработка программных приложений для MS Access
7.3. Организация взаимодействия между системами управления данными
7.3.1. Проблема форматнонезависимого доступа к данным и технология
ODBC
7.3.2. Доступ из MS Access к источникам данных в формате других
программных приложений
7.3.3. Технологические решения по организации доступа к данным
7.4. Организация многопользовательского доступа к данным
7.4.1. Проблема многопользовательского доступа и параллельной
обработки данных в автоматизированных информационных системах
7.4.2. Основные направления развития технологии клиент-сервер
7.4.3. Организация защиты данных в СУБД MS Access
Ключевые понятия
Контрольные вопросы
Литература
В самом широком смысле любая программа имеет дело с некоторой внешней по отношению
к ее коду информацией, задающей какие-либо параметры или режим ее работы. Такую
информацию также называют данными программы. Очевидно, что в зависимости от
типа решаемых задач проблемы организации работы с данными будут качественно
различными. В подавляющем большинстве случаев при решении хозяйственных, экономических
и финансовых задач приходится иметь дело с обширными специфически структурированными
и взаимозависимыми массивами данных. Такие сложные наборы данных традиционно
принято называть базами данных.
7.1. Основные понятия теории баз данных
7.1.1. Понятие базы данных
Базу данных (БД) можно определить как унифицированную совокупность данных, совместно
используемую различными задачами в рамках некоторой единой автоматизированной
информационной системы (ИС).
Теория управления базами данных как самостоятельная дисциплина начала развиваться
приблизительно с начала 50-х годов двадцатого столетия. За это время в ней сложилась
определенная система фундаментальных понятий. Приведем некоторые из них.
Предметной областью принято называть часть реального мира, подлежащую изучению
с целью организации управления в этой сфере и последующей автоматизации процесса
управления. В рамках данной книги для нас в первую очередь представляют интерес
предметные области, так или иначе связанные со сферой экономики и финансов.
Объектом называется элемент информационной системы, сведения о котором хранятся
в базе данных. Иногда объект также называют сущностью (от англ, entity). Классом
объектов называют их совокупность, обладающую одинаковым набором свойств.
Атрибут - это информационное отображение свойств объекта. Каждый объект характеризуется
некоторым набором атрибутов.
Ключевым элементом данных называются такой атрибут (или группа атрибутов), который
позволяет определить Значения других элементов-данных. Запись данных (англ,
эквивалент record) - это совокупность значений связанных элементов данных.
Первичный ключ - это атрибут (или группа атрибутов), который уникальным образом
идентифицируют каждый экземпляр объекта (запись). Вторичным ключом называется
атрибут (или группа атрибутов), значение которого может повторяться для нескольких
записей (экземпляров объекта). Прежде всего вторичные ключи используются в операциях
поиска записей.
Процедуры хранения данных в базе должны подчиняться некоторым общим принципам,
среди которых в первую очередь следует выделить:
o целостность и непротиворечивость данных, под которыми понимается как физическая
сохранность данных, так и предотвращение неверного использования данных, поддержка
допустимых сочетаний их значений, защита от структурных искажений и несанкционированного
доступа;
o минимальная избыточность данных обозначает, что любой элемент данных должен
храниться в базе в единственном виде, что позволяет избежать необходимости дублирования
операций, производимых с ним.
Программное обеспечение, осуществляющее операции над базами данных, получило
название СУБД - система управления базами данных. Очевидно, что его работа должна
быть организована таким образом, чтобы выполнялись перечисленные принципы.
7.1.2. Модели организации данных
Набор принципов, определяющих организацию логической структуры хранения данных
в базе, получил название модели данных. Модели баз данных определяются тремя
компонентами:
- допустимой организацией данных;
- ограничениями целостности;
- множеством допустимых операций.
В теории систем управления базами данных выделяют модели четырех основных типов:
иерархическую, сетевую, реляционную и объектно-реляционную.
Терминологической основой для иерархической и сетевой моделей являются понятия:
атрибут, агрегат и запись. Под атрибутом (элементом данных) понимается наименьшая
поименованная структурная единица данных. Поименованное множество атрибутов
может образовывать агрегат данных. В некоторых случаях отдельно взятый агрегат
может состоять из множества экземпляров однотипных данных, или, как еще говорят,
являться множественным элементом. Наконец, записью называют составной агрегат,
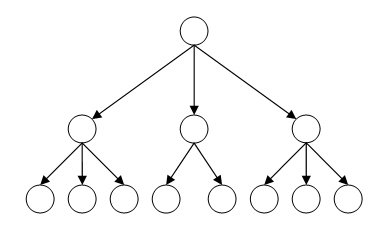
который не входит в состав других агрегатов. В иерархической модели все записи,
агрегаты и атрибуты базы данных образуют иерархически организованный набор,
то есть такую структуру, в которой все элементы связаны отношениями подчиненности,
и при этом любой элемент может подчиняться только одному какому-нибудь другому
элементу. Такую форму зависимости удобно изображать с помощью древовидного графа
(схемы, состоящей из точек и стрелок, которая связна и не имеет циклов). Пример
иерархической структуры базы данных приведен на рис. 7.1.
Рис. 7.1. Схема иерархической модели данных
Типичным представителем семейства баз данных, основанных на иерархической модели,
является Information Management System (IMS) фирмы IBM, первая версия которой
появилась в 1968 г.
Концепция сетевой модели данных связана с именем Ч. Бахмана. Сетевой подход
к организации данных является расширением иерархического. В иерархических структурах
запись-потомок должна иметь в точности одного предка; в сетевой структуре данных
потомок может иметь любое число предков (рис. 7.2).
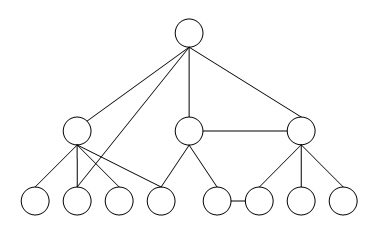
Рис. 7.2. Схема сетевой модели данных
Сетевая БД состоит из набора записей и набора связей между этими записями,
точнее, из набора экземпляров записей заданных типов (из допустимого набора
типов) и набора экземпляров из заданного набора типов связи. Примером системы
управления данными с сетевой организацией является Integrated Database Management
System (IDMS) компании Cullinet Software Inc., разработанная в середине 70-х
годов. Она предназначена для использования на "больших" вычислительных
машинах. Архитектура системы основана на предложениях Data Base Task Group (DBTG),
Conference on Data Systems Languages (CODASYL), организации, ответственной за
определение стандартов языка программирования Кобол.
Среди достоинств систем управления данными, основанных на иерархической или
сетевой моделях, могут быть названы их компактность и, как правило, высокое
быстродействие, а среди недостатков - неуниверсальность, высокая степень зависимости
от конкретных данных.
7.1.3. Реляционная модель данных
Концепции реляционной модели впервые были сформулированы в работах американского
ученого Э. Ф. Кодда. Откуда происходит ее второе название - модель Кодда.
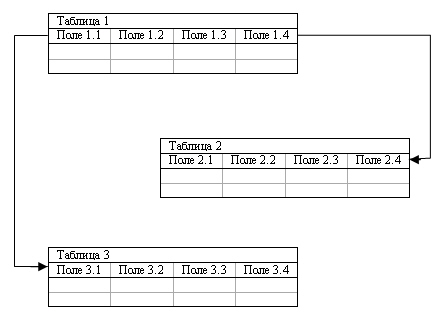
Рис. 7.3. Схема реляционной модели данных
В реляционной модели объекты и взаимосвязи между ними представляются с помощью
таблиц (рис. 7.3). Для ее формального определения используется фундаментальное
понятие отношения. Собственно говоря, термин "реляционная" происходит
от английского relation - отношение. Если заданы произвольные конечные множества
D1, D2 ,…, Dn, то декартовым произведением этих множеств D1 ? D2 ? … ? Dn называют
множество всевозможные наборов вида (d1, d2 ..., dn), где
d1 D1, d2 D2,..., dn Dn. Отношением R определенным на множествах D1, D2 ,…,
Dn,, называется подмножество декартова произведения Dl x D2x ... х Dn. При этом
множества D1 ? D2 ? … ? Dn называются доменами отношения, а элементы декартова
произведения - кортежами отношения. Число я определяет степень отношения, а
количество кортежей - его мощность. Наряду с понятиями домена и кортежа при
работе с реляционными таблицами используются альтернативные им понятия поля
и записи.
В реляционной базе данных каждая таблица должна иметь первичный ключ (ключевой
элемент) - поле или комбинацию полей, которые единственным образом идентифицируют
каждую строку в таблице.
Важным преимуществом реляционной модели является то, что в ее рамках действия
над данными могут быть сведены к операциям реляционной алгебры, которые выполняются
над отношениями. Это такие операции, как объединение, пересечение, вычитание,
декартово произведение, выборка, проекция, соединение, деление.
Важнейшей проблемой, решаемой при проектировании баз данных, является создание
такой их структуры, которая бы обеспечивала минимальное дублирование информации
и упрощала Процедуры обработки и обновления данных. Код-дом был предложен некоторый
набор формальных требований универсального характера к организации данных, которые
позволяют эффективно решать перечисленные задачи. Эти требования к состоянию
таблиц данных получили название нормальных форм. Первоначально были сформулированы
три нормальные формы. В дальнейшем появилась нормальная форма Бойса-Кодда и
нормальные формы более высоких порядков. Однако они не получили широкого распространения
на практике.
- Говорят, что отношение находится в первой нормальной форме, если все его атрибуты
являются простыми.
- Говорят, что отношение находится во второй нормальной форме, если оно удовлетворяет
требованиям первой нормальной формы и каждый не ключевой атрибут функционально
полно зависит от ключа (однозначно определяется им).
- Говорят, что отношение находится в третьей нормальной форме, если оно удовлетворяет
требованиям второй нормальной формы и при этом любой не ключевой атрибут зависит
от ключа нетранзитивно. Заметим, что транзитивной называется такая зависимость,
при которой какой-либо не ключевой атрибут зависит от другого не ключевого атрибута,
а тот, в свою очередь, уже зависит от ключа.
Принципиальным моментом является то, что для приведения таблиц к состоянию,
удовлетворяющему требованиям нормальных форм, или, как еще говорят, для нормализации
данных над ними, должны быть осуществлены перечисленные выше операции реляционной
алгебры.
Основным достоинством реляционной модели является ее простота. Именно благодаря
ей она положена в основу подавляющего большинства реально работающих СУБД.
7.1.4. Язык SQL
В разработанной Коддом реляционной модели были определены как требования к организации
таблиц, содержащих данные, так и язык, позволяющий работать с ними. Впоследствии
этот язык получил название SQL (Structured Query Language - структурированный
язык запросов). SQL был впервые реализован фирмой I в начале 70-х годов двадцатого
века под названием Structures English Query Language (SEQUEL). Он был ориентирован
на управление прототипом реляционной базы данных IBM-System R. В дальнейшем
SQL стал стандартом de facto языка работы с реляционными базами данных. Этот
его статус был впервые зафиксирован в 1986 году Американским национальным институтом
стандартов (ANSI). Другими достаточно известными стандартами SQL стали стандарты
ANSI SQL-92 ISO SQL-92, X/Open. В составе SQL могут быть выделены следующие
группы инструкций:
- язык описания данных - DDL (Data Definition Language);
- язык манипулирования данными - DML (Data Manipulation Language);
- язык управления транзакциями.
Инструкции DDL предназначены для создания, изменения и удаления объектов базы
данных. Их описание приведено в табл. 7.1.
Таблица 7.1. Инструкции языка определения данных (DDL)
| Инструкция | Назначение |
| CREATE | Создание новых объектов (таблиц, полей, индексов и т. д.) |
| DROP | Удаление объектов |
| ALTER | Изменение объектов |
Например, нам необходимо создать таблицу, содержащую данные по каталогу фирм, каждая фирма в котором характеризуется кодом, наименованием, MCCTOJV расположения штаб-квартиры, размером уставного фонда. Данной операции со ответствует SQL-выражение
CREATE TABLE Фирмы
( КодФирмы TEXT (5),
НазвФирмы TEXT (30),
АдресФирмы TEXT (40),
УстФонд DOUBLE );
Отметим, что допустимые имена полей создаваемой таблицы и типы содержащихся в них данных могут варьироваться для различных версий и диалектов SQL Если нам понадобится изменить структуру таблицы Фирмы - допустим, добавит! к ней еще одну колонку с фамилией директора, то сделать это можно с помощью SQL-инструкции:
ALTER TABLE Фирмы ADD COLUMN Директор TEXT.(30);
а выражение, дающее Команду на уничтожение таблицы, будет выглядеть так:
DROP TABLE Фирмы;
Инструкции DML (табл. 7.2) позволяют выбирать данные из таблиц, а также добавлять, удалять и изменять их.
Таблица 7.2. Инструкции языка манипулирования данными (DML)
| Инструкция | Назначение |
| SELECT | Выполнение запроса к базе данных с целью отбора записей, удовлетворяющих заданным критериям |
| INSERT | Добавление записей в таблицы базы данных |
| UPDATE | Изменение значений отдельных записей и полей |
| DELETE | Удаление записей из базы данных |
SELECT - команда на выборку записей из базы данных - является наиболее часто используемой SQL-инструкцией. Сфера данных, которыми она манипулирует, определяется с помощью специальных предложений. Перечень основных предложений языка SQL приведен в табл. 7.3.
Таблица 7.3. Основные предложения языка SQL
| Инструкция | Назначение |
| FROM | Указывает имя таблицы, из которой должны быть отобраны данные |
| WHERE | Специфицирует условия, которым должны удовлетворять выбираемые данные |
| GROUP BY | Определяет, что выбираемые записи должны быть сгруппированы |
| HAVING | Задает условие, которому должна удовлетворять каждая группа отобранных записей |
| ORDER BY | Специфицирует порядок сортировки записей |
Примером простейшего применения инструкции SELECT может служить команда на
выборку всех данных из таблицы Фирмы:
SELECT * FROM Фирмы;
Однако, вообще говоря, данная инструкция представляет собой весьма мощный инструмент манипуляции с содержимым баз данных. Так, выражение
SELECT Int([УстФонд]/500)*500 AS Диапазон,
Count(КодФирмы) AS ЧислоФирм
FROM Фирмы
GROUP BY Int([УстФонд]/500)*500;
задает команду на вывод данных о распределении значений уставных фондов фирм по интервалам длиной 500 денежных единиц (д. е.), то есть сколько фирм имеют уставный фонд менее 500 д. е., от 500 до 1000 д. е. и т. д. Третьей составной частью SQL является язык управления транзакциями. Транзакция - это логически завершенная единица работы, содержащая одну или более элементарных операций обработки данных. Все действия, составляющие транзакцию, должны либо выполниться полностью, либо полностью не выполниться. Инструкции языка управления транзакциями приведены в табл. 7.4.
Таблица 7.4. Инструкции языка управления транзакциями
| Инструкция | Назначение |
| COMMIT | Фиксация в базе данных всех изменений, сделанных текущей транзакцией |
| SAVEPOINT | Установка точки сохранения (начала транзакции) |
| ROLLBACK | Откат изменений, сделанных с момента начала транзакции |
В большинстве СУБД элементарные команды, составляющие тело транзакции, выполняются над некоторой буферной копией данных, и только если их удается успешно довести до конца, происходит окончательное обновление основной базы. Транзакция начинается от точки сохранения, задаваемой инструкцией SAVEPOINT, и может быть завершена по команде COMMIT или прервана по команде ROLLBACK (откат). Также в современных системах управления данными предусмотрены средства автоматического отката транзакций при возникновении системных сбоев. Таким образом, механизм управления транзакциями является важнейшим инструментом поддержания целостности данных.
7.1.5. Программные системы управления базами
данных
Кратко остановимся на конкретных программных продуктах, относящихся к классу
СУБД. На самом общем уровне все СУБД можно разделить:
- на профессиональные, или промышленные;
- персональные (настольные).
Профессиональные (промышленные) СУБД представляют собой программную основу для
разработки автоматизированных систем управления крупными экономическими объектами.
На их базе создаются комплексы управления и обработки информации крупных предприятий,
банков или даже целых отраслей. Первостепенными условиями, которым должны удовлетворять
профессиональные СУБД, являются:
- возможность организации совместной параллельной работы большого количества
пользователей;
- масштабируемость, то есть возможность роста системы пропорционально расширению
управляемого объекта;
- переносимость на различные аппаратные и программные платформы;
- устойчивость по отношению к сбоям различного рода, в том числе наличие многоуровневой
системы резервирования хранимой информации;
- обеспечение безопасности хранимых данных и развитой структурированной системы
доступа к ним.
Промышленные СУБД к настоящему моменту имеют уже достаточно богатую историю
развития. В частности, можно отметить, что в конце 70-х - начале 80-х годов
в автоматизированных системах, построенных на базе больших вычислительных машин,
активно использовалась СУБД Adabas. В настоящее время характерными представителями
профессиональных СУБД являются такие программные продукты, как Oracle, DB2,
Sybase, Informix, Ingres, Progress.
Основоположниками СУБД Oracle стала группа американских разработчиков (Ларри
Эллисбн, Роберт Майнер и Эдвард Оутс), которые более двадцати лет тому назад
создали фирму Relational Software Inc. и поставили перед собой задачу создать
систему, на практике реализующую идеи, изложенные в работах Э. Ф. Кодда И К.
Дж. Дейта. Результатом их деятельности стала реализация переносимой реляционной
системы управления базами данных с базовым языком обработки SQL. В 1979 г. заказчикам
была представлена версия Oracle для мини-компьютеров PDP-11 фирмы Digital Equipment
Corporation сразу для нескольких операционных систем: RSX- 11, IAS, RSTS и UNIX.
Чуть позже Oracle был перенесен на компьютеры VAX под управлением VAX VMS. Значительная
часть кода была написана на ассемблере, и поэтому процесс переноса системы на
новую платформу требовал значительных усилий. Основным отличием Oracle очередной,
третьей версии было то, что она была полностью написана на языке С. Такое решение
обеспечивало переносимость системы на многие новые платформы, в частности, на
различные клоны UNIX. Второй важной особенностью новой (1983 г.) версии была
поддержка концепции транзакции. Примерно в это же время фирма получила новое
имя - Oracle Corporation - и заняла лидирующее место на рынке производителей
СУБД. Четвертая версия Oracle характеризовалась расширением перечня поддерживаемых
платформ и операционных систем. Oracle был перенесен как на большие ЭВМ фирмы
IBM (мэйнфреймы), так и на персональные компьютеры, работающие под управлением
MS DOS. Именно в четвертой версии был сделан важный шаг в развитии технологии
поддержки целостности баз данных. Для многопользовательских систем было предложено
оригинальное решение Oracle поддержки "непротиворечивости чтения".
В пятой версии была впервые реализована СУБД с архитектурой "клиент- сервер".
Последующие версии СУБД Oracle были ориентированы на построение крупномасштабных
систем обработки транзакций, изменение методов реализации систем ввода/вывода,
буферизации, подсистем управления параллельным доступом, резервирования и восстановления.
Также была реализована поддержка симметричных мультипроцессорных архитектур.
Проект и экспериментальный вариант СУБД Ingres были разработаны в университете
Беркли под руководством одного из наиболее известных в мире ученых и специалистов
в области баз данных Майкла Стоунбрейкера. С самого начала СУБД Ingres разрабатывалась
как мобильная система, функционирующая в среде ОС UNIX. Первая версия Ingres
была рассчитана на 16-разрядные компьютеры и работала главным образом на машинах
серии PDP. Это была первая СУБД, распространяемая бесплатно для использования
в университетах. Впоследствии группа Стоунбрейкера перенесла Ingres в среду
ОС UNIX BSD, которая также была разработана в университете Беркли. Семейство
СУБД Ingres из университета Беркли принято называть университетской Ingres.
В начале 80-х была образована компания RTI (Relational Technology Inc.), которая
разработала и стала продвигать коммерческую версию СУБД Ingres. В настоящее
время коммерческая Ingres поддерживается, развивается и продается компанией
Computer Associates. Сейчас это одна из наиболее развитых коммерческих реляционных
СУБД. В то же время, по поводу университетской Ingres имеется много высококачественных
публикаций. Более того, университетскую Ingres можно опробовать на практике
и даже посмотреть ее исходные тексты.
Перечисленные выше (для СУБД Oracle) тенденции носят универсальный характер
и определяют пути развития других программных продуктов, что вполне объясняется
жесткой конкурентной ситуацией, сложившейся на данном рынке.
Персональные системы управления данными - это программное обеспечение, ориентированное
на решение задач локального пользователя или компактной группы пользователей
и предназначенное для использования на микроЭВМ (персональном компьютере). Это
объясняет и их второе название - настольные. Определяющими характеристиками
настольных систем являются:
- относительная простота эксплуатации, позволяющая создавать на их основе работоспособные
приложения как "продвинутым" пользователям, так и тем, чья квалификация
невысока;
- относительно ограниченные требования к аппаратным ресурсам.
Исторически первой среди персональных СУБД, получивших массовое распространение,
стала Dbase фирмы Ashton-Tate (впоследствии права на нее перешли к фирме Borland,
а с 1999 г. данная программа поддерживается фирмой dBASE Inc.). В дальнейшем
серия реляционных персональных СУБД пополнилась такими продуктами, как FoxBase/FoxPRO
(Fox Software, в дальнейшем - Microsoft), Clipper (Nantucket, затем - Computer
Associates), R:base (Microrim), Paradox (Borland, на настоящий момент правами
владеет фирма Corel), Access (Microsoft), Approach (Lotus).
Завоевавшие широкую популярность в России системы Dbase, FoxPRO и Clipper работали
с таблицами данных, размещавшихся в файлах, имевших расширение *.dbf (термин
dbf-формат стал общепринятым). Впоследствии семейство этих баз данных получило
интегрированное наименование Xbase.
Несмотря на неизбежные различия, обусловливавшиеся замыслами разработчиков,
все перечисленные системы в ходе своей эволюции приобрели ряд общих конструктивных
черт, среди которых, прежде всего, могут быть названы:
- наличие визуального интерфейса, автоматизирующего процесс создания средств
манипуляции данными, - экранных форм, шаблонов отчетов, запросов и т. п.;
- наличие инструментов создания объектов базы данных в режиме диалога: Experts
в Paradox, Wizards в Access, Assistants в Approach;
- наличие развитого инструментария создания программных расширений в рамках
единой среды СУБД: язык разработки приложений PAL в Paradox, VBA (Visual Basic
for Applications) в Access, Lotus Script в Approach;
- встроенная поддержка универсальных языков управления данными, например SQL
или QBE (Query By Example).
Среди СУБД, которые, условно говоря, занимают промежуточное положение между
настольными и промышленными системами, могут быть названы SQLWindows/ SQLBase
фирмы Centura (до 1996 г. Gupta), InterBase (Borland), наконец, Microsoft SQL
Server.
В завершении раздела необходимо отметить, что в последние годы наметилась устойчивая
тенденция к стиранию четких граней между настольными и профессиональными системами.
Последнее, в первую очередь, объясняется тем, что разработчики в стремлении
максимально расширить потенциальный рынок для своих продуктов постоянно расширяют
набор их функциональных характеристик.
7.1.6. Применение СУБД в экономике
Очевидно, что экономические задачи, для решения которых необходимо применять
программное обеспечение СУБД, весьма обширны и разнообразны. На его основе строятся
автоматизированные системы управления предприятий различных уровней (от малых
до крупных). Оно лежит в основе практически всех прикладных бухгалтерских программ
(например, "1C: Бухгалтерия", "Парус" и др.). Одновременно
СУБД применяются для автоматизации систем управления, мониторинга и прогнозирования
развития отраслей и экономики страны в целом.
В качестве примера мы более подробно остановимся на вопросах использования СУБД
при создании прикладного программного обеспечения, решающего задачи управления
работой банков и финансовых компаний, или автоматизированных банковских систем
(АБС).
В настоящее время среди ведущих российских разработчиков программных продуктов
в классе АБС могут быть названы фирмы "ПрограмБанк", "Диасофт",
"Инверсия", "Асофт". В частности, фирмой "ПрограмБанк"
разработаны такие известные банковские системы, как "Центавр", "Афина",
"Гефест".
В середине 1998 г. компании "ПрограмБанк" и "Диасофт" объединили
усилия в области разработки систем автоматизации, рассчитанных на крупные и
крупнейшие банки. Учрежденная ими дочерняя компания "Диасофт+ПрограмБанк"
сосредоточилась исключительно на развитии и продвижении информационной системы
управления банковской деятельностью (ИСУБД) "Новая Афина", в основу
которой легли ИБС "Афина" компании "ПрограмБанк" и разработка
"Диасофта" - DiasoftBANK 5NT. Данная банковская система разработана
на основе программной платформы Oracle.
ИСУБД "Новая Афина" обеспечивает комплексную автоматизацию всех направлений
деятельности банка, финансовые методы управления им, поддержку текущего законодательства
и правил ведения бухгалтерского учета, ведение планов счетов произвольной структуры,
поддержку различных форм платежного документооборота и маршрутизацию прохождения
платежей с использованием различных вариантов верификации документов. Также
в рамках ИСУБД решаются задачи управления многофилиальной структурой банка в
едином информационном пространстве в режиме реального времени, автоматизации
мультивалютного расчетно-кассового обслуживания, управления ЛОРО- и НОСТРО-счетами,
обработки сообщений S.W.I.F.T., ведения договоров, контрактов и их приложений,
формирования бухгалтерской и аналитической отчетности, связи с внешними информационными
системами, администрирования и аудита, получения отчетов произвольной формы.
Согласно информации, опубликованной на сайте фирмы "ПрограмБанк",
ИСУБД "Новая Афина" применяют такие ведущие банки, как Сбербанк РФ,
Внешторгбанк РФ, МДМ-банк, а также ряд представительств зарубежных банков.
7.2. СУБД MS Access и ее основные возможности
7.2.1. Общая характеристика СУБД MS Access
Microsoft Access в настоящее время является одной из самых популярных среди
настольных (персональных) программных систем управления базами данных Среди
причин такой популярности следует отметить:
- высокую степень универсальности и продуманности интерфейса, который рассчитан
на работу с пользователями самой различной квалификации. В частности, реализована
система управления объектами базы данных, позволяющая гибко и оперативно переходить
из режима конструирования в режим их непосредственной эксплуатации;
- глубоко развитые возможности интеграции с другими программными продуктами,
входящими в состав Microsoft Office, а также с любыми программными продуктами,
поддерживающими технологию OLE;
- богатый набор визуальных средств разработки.
Нельзя не отметить, что существенной причиной такого широкого распространения
MS Access является и мощная рекламная поддержка, осуществляемая фирмой Microsoft.
В процессе разработки данного продукта на рынок представлялись его различные
версии. Наиболее известными (в некотором смысле этапными) стали Access 2.0,
Access 7.0 (он впервые был включен в состав программного комплекса MS Office
95). Позже появились версии Access 97 (в составе MS Office 97 и Access 2000
(в составе MS Office 2000).
Очевидно, что отправной точкой в процессе работы с любой СУБД является создание
файла (или группы файлов) базы данных. На рис. 7.4 показано окно, которое появляется
после создания новой базы.
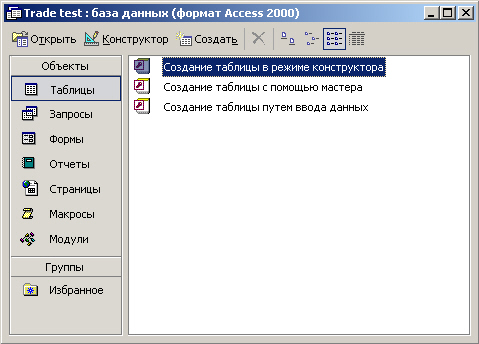
Рис. 7.4. Главное окно базы данных в Access
Основные разделы главного окна соответствуют типам объектов, которые может
содержать база данных Access. Это Таблицы, Запросы, Отчеты, Макросы и Модули.
Заголовок окна содержит имя файла базы данных. В данном случае он называется
TradeTest.
Интерфейс работы с объектами базы данных унифицирован. По каждому из них предусмотрены
стандартные режимы работы:
- Создать - предназначен для создания структуры объектов;
- Конструктор - предназначен для изменения структуры объектов;
- Открыть (Просмотр, Запуск) - предназначен для работы с объектами базы данных.
Важным средством, облегчающим работу с Access для начинающих пользователей,
являются мастера - специальные программные надстройки, предназначенные для создания
объектов базы данных в режиме последовательного диалога. Для опытных и продвинутых
пользователей существуют возможности более гибкого управления ресурсами и возможностями
объектов СУБД в режиме конструктора.
Специфической особенностью СУБД Access является то, что вся информация, относящаяся
к одной базе данных, хранится в едином файле. Такой файл имеет расширение *.mdb.
Данное решение, как правило, удобно для непрофессиональных пользователей, поскольку
обеспечивает простоту при переносе данных с одного рабочего места на другое.
Внутренняя организация данных в рамках mdl формата менялась от версии к версии,
но фирма Microsoft поддерживала их ее вместимость снизу вверх, то есть базы
данных из файлов в формате ранних вер сии Access могут быть конвертированы в
формат, используемый в версиях боле поздних.
7.2.2. Основные этапы разработки базы данных
в среде MS Access
Как нетрудно догадаться, процесс разработки конкретного программного приложения
в среде Access в первую очередь определяется спецификой автоматизируемой предметной
области. Однако для большинства из них можно выделить ряд типичных этапов. Это:
- разработка и описание структур таблиц данных;
- разработка схемы данных и задание системы взаимосвязей между таблицам
- разработка системы запросов к таблицам базы данных и (при необходимости их
интеграция в схему данных;
- разработка экранных форм ввода/вывода данных;
- разработка системы отчетов по данным;
- разработка программных расширений для базы данных, решающих специфические
задачи по обработке содержащейся в ней информации, с помощью иструментария макросов
и модулей;
- разработка системы защиты данных, прав и ограничений по доступу.
Очевидно, что между перечисленными этапами существует большое количеств обратных
связей, подразумевающих возврат к более ранним шагам, исходя из вновь открывшихся
обстоятельств, которые невозможно было заранее учесть ил предвидеть.
Еще раз подчеркнем, что описанная последовательность этапов разработки баз данных
в MS Access не является безусловным эталоном. Однако очень часто отклонения
от нее свидетельствуют не столько об оригинальности хода мысли разработчика,
сколько о погрешностях, допущенных им при планировании процесс разработки, или
вообще об отсутствии у него какого-либо плана.
7.2.3. Экономические приложения СУБД MS
Access
Продуманность пользовательского интерфейса Access делает его особенно привлекательным
в качестве средства решения задач организации и обработки данных для специалистов
в области экономики и финансов, одновременно не имеющих квалификации или опыта
в профессиональном программировании. Оговоримся что здесь речь идет о приложениях,
создаваемых таким специалистом для собственного пользования. В то же время,
как только возникает необходимость в разработке средств для других пользователей,
без программирования, как правил обойтись не удается. Можно перечислить более
чем обширный список возможных приложений Access для решения финансово-экономических
задач. Мы остановимся на достаточно условном примере, с помощью которого, однако,
можно наглядно проиллюстрировать большинство наиболее важных функциональных
возможностей этого программного продукта.
Предположим, что перед нами стоит задача автоматизации процесса управления торгами
набором финансовых активов (ценных бумаг) на некотором ограниченном секторе
рынка. Для ее решения (еще раз подчеркнем, при условии относительной ограниченности
объемов информации) хорошо подходит СУБД MS Access.
Представим рассматриваемую ситуацию на содержательном уровне. Пусть на рынке
(в некоторой торговой системе) циркулирует определенный набор ценных бумаг (акций),
каждая из которых характеризуется наименованием, номинальной ценой, суммарным
объемом пакета (то есть сколько всего единиц данной бумаги был эмитировано),
датой эмиссии. Одновременно на рынке действуют его субъекты (агенты), которые
могут продавать и покупать бумаги. Очевидно, что каждый агент характеризуется
по меньшей мере наименованием и величиной средств, которыми он обладает. Таким
образом, достаточно естественно выкристаллизовываются четыре массива информации:
данные по бумагам, данные по агентам (рынка), данные по принадлежности бумаг
агентам (по портфелям) и, наконец, данные по заявкам агентов на покупку или
продажу тех или иных бумаг.
Теперь допытаемся описать структуры потоков информации, которые фигурируют в
автоматизируемой предметной области, на более логически строгом уровне.
Массив (таблица) данных по существующим активам (присвоим ей имя Бумаги) будет
содержать колонки (поля):
- Код бумаги;
- Наименование бумаги;
- Номинальная цена;
- Суммарный объем пакета;
- Дата эмиссии;
- Тип бумаги (например, акция или облигация).
Соответственно, таблица Агенты будет состоять из колонок:
- Код агента;
- Наименование агента;
- Объем денежных средств, которыми обладает агент;
- Комментарий по агенту.
Заметим, что поля Код бумаги и Код агента являются ключами, обеспечивающими
уникальную идентификацию записей в соответствующих таблицах.
Для хранения информации о содержание портфелей ценных бумаг, которыми владеют
агенты, создадим таблицу Портфели со структурой:
- Код бумаги;
- Код агента;
- Количество бумаг данного наименования в портфеле, которым обладает данный
агент.
В таблице Портфели мы сталкиваемся с составным ключом, который образует комбинация
полей Код бумаги и Код агента. Наконец, информацию намерениях тех или иных агентов
продать те или иные бумаги поместим в таблицу Заявки:
- Код заявки;
- Код бумаги;
- Код агента;
- Объем заявки (в единицах измерения, соответствующих бумагам данного наименования);
- Цена заявки.
Отметим, что экономическое содержание, вкладываемое в величину, содержащуюся
в поле Объем заявки, может иметь различные интерпретации. Например, можно считать,
что если это значение положительно, то это заявка на покупку, а если отрицательно,
то - на продажу. Очевидно, что возможны и альтернативные решения по организации
данной таблицы. Например, можно было бы создать два отдельных поля: Объем заявки
на покупку и Объем заявки на продажу. Дополнительно хочется обратить внимание
на те резоны, в соответствии с которыми в качестве ключа использовано отдельное
поле Код заявки. Это позволяет одновременно хранить в таблице разные предложения
по одной и той же бумаге, поступающие от одного и того же агента.
Простота описанной системы таблиц не должна вводить читателя в заблуждение.
Она определяется исключительно условностью рассматриваемого примера, в котором
мы из соображений наглядности изложения абстрагировались от многих черт реального
процесса торгов ценными бумагами.
7.2.4. Создание таблиц и схем данных
Как уже отмечалось ранее, процесс разработки базы данных в СУБД MS Access начинается
с задания описания структур таблиц. Рассмотрим этот процесс более подробно для
таблиц примера, описанного в 7.2.3.
Итак, для начала нам необходимо создать описание таблицы Бумаги. Нажав кнопку
Создать и выбрав в появившемся вслед диалоговом окне режим Конструктор, мы попадаем
в окно, предназначенное для ввода описания структуры создаваемой таблицы. Оно
изображено на рис. 7.5.
При создании баз данных, предназначенных для решения финансовых и экономических
задач, процесс описания атрибутов полей в создаваемой таблице приобретает особое
значение. Как видно из рис. 7.5, процесс описания атрибутов поля начинается
с присвоения ему имени (идентификатора). Желательно, чтобы это имя было, с одной
стороны, информативным, а с другой - кратким, что обеспечивает несомненные удобства
при дальнейших манипуляциях с ним. Далее необходимо определить тип поля, что,
очевидно, должно делаться, исходя из содержания тех данных, которые будут в
нем храниться.

Рис. 7.5. Создание описания структуры таблицы Бумаги
Обратим внимание на тип Счетчик, присвоенный полю КодБум (код бумаги). Он означает,
что СУБД будет самостоятельно помещать в это поле некоторое числовое значение
для каждой вновь создаваемой записи таблицы, обеспечивая таким образом его уникальность.
Выбор типа данных в Access одновременно определяет набор дополнительных атрибутов
соответствующего поля. В частности, поле ДатаЭм (дата эмиссии) имеет тип Дата
и, как это показано на рис. 7.5, может иметь дополнительные атрибуты:
- формат поля, определяющий условия вывода данных из этого поля (по умолчанию);
" Маска ввода, определяющая условия ввода данных в поле;
- подпись - содержит расширенный заголовок;
- значение по умолчанию - позволяет указать значение, автоматически присваиваемое
полю при создании новой записи. В нашем случае по умолчанию будет задаваться
текущая дата, возвращаемая встроенной функцией Date();
- условие на значение - определяет требования к данным, вводимым в поле. Например,
для выполнения требования, чтобы дата эмиссии предшествовала текущей, следует
задать выражение <=Date();
- сообщение об ошибке - определяет текст сообщения, которое будет выводиться
в случае нарушения заданного выше условия;
- обязательное поле - указывает, требует или нет поле обязательного ввода значения;
- индексированное поле - определяет индекс, создаваемый по данному полю. Индекс
ускоряет выполнение запросов, в которых используются индексированные поля, и
операции сортировки и группировки.
Основываясь на опыте проектирования различных баз, необходимо заметить, что
не следует пренебрегать возможностями управления данными, которые открывают
дополнительные атрибуты полей. Их грамотное и продуманное использование позволяет
организовать централизованный и эффективный контроль за корректностью и целостностью
данных.
На завершающем этапе процесса проектирования структуры таблицы происходит задание
ключей и индексов. В первом случае достаточно выделить строки, которые должны
составить ключевое выражение, и щелкнуть мышью по пиктограмме Ключ на панели
инструментов (рис. 7.6). В таблице Бумаги роль уникального ключевого идентификатора
выполняет поле КодБум.
![]()
Рис. 7.6. Панель инструментов конструктора таблиц
Также при создании таблицы имеет смысл заранее продумать возможные упорядочения, которые могут понадобиться при работе с содержащимися в ней данными. Задание индексов с соответствующими ключевыми выражениями может в дальнейшем существенно ускорить процесс работы (особенно с большими массивами данных). В частности, при работе с данными из таблицы Бумаги весьма вероятно, что нам придется выводить их в алфавитном порядке по названиям, а также отсортированными в порядке убывания дат. Процесс задания соответствующих индексов показан на рис. 7.7.
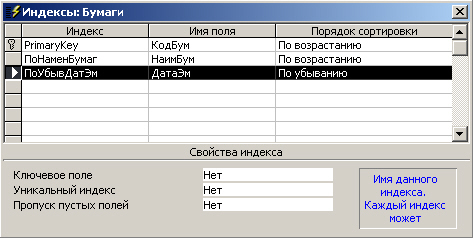
Рис. 7.7. Создание индексов для таблицы
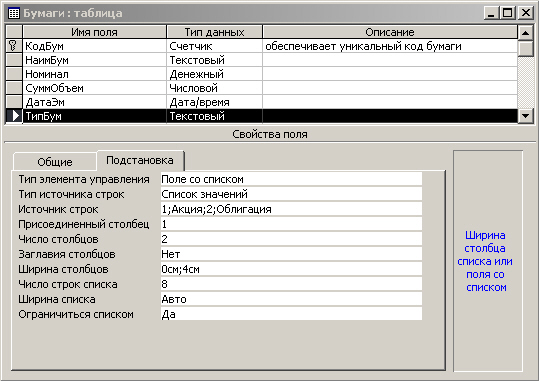
Рис. 7.8. Задание списка подстановки для поля
Эффективным методом решения задач контроля корректности входных данных является
ограничение множества допустимых значений поля некоторым списком. Рассмотрим
это более подробно на примере поля ТипБум (тип бумаги), которая, допустим, в
рассматриваемой торговой системе может быть либо акцией, либо облигацией. Нетрудно
заметить, что будет разумным присвоить типу Акция код 1, а типу Облигация -
код 2. Это позволит существенно сэкономить место за счет уменьшения объема хранимой
информации (особенно при большом количестве записей). Однако с точки зрения
восприятия вводимой информации пользователем гораздо удобнее иметь дело с осмысленным
текстом, чем запоминать, какие коды ему соответствуют.
Средством решения этой проблемы в Access является задание подстановочного списка
значений для поля. Для этого следует выбрать вкладку Подстановка в окне Свойства
поля, далее для свойства Тип элемента управления задать значение Список. На
рис. 7.8 показано, как описать другие свойства элемента управления Список, чтобы
организовать заполнение поля ТипБум требуемыми значениями.
После создания описания структуры таблицы можно перейти в режим непосредственного
ввода в нее данных. Как уже говорилось, важным преимуществом интерфейса СУБД
Access является продуманная гибкая система перехода от режима Конструктора к
режиму ввода данных в таблицу (Режим таблицы). Такой переход можно осуществить,
щелкнув мышью по пиктограмме Вид, расположенной на панели инструментов, либо
выбрав функцию меню Вид > Режим таблицы.
На рис. 7.9 показано окно режима непосредственного ввода данных в таблицу Бумаги,
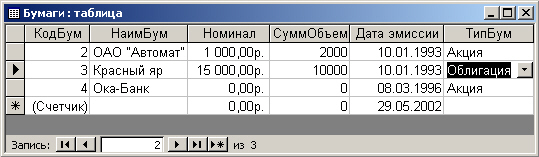
Рис. 7.9. Ввод данных в таблицу Бумаги
Хочется еще раз обратить внимание читателя на то, что выбор типа бумаги осуществляется из заранее предопределенного списка.
7.2.5. Создание схемы данных
Очевидно, что те действия, которые были подробно описаны для таблицы Бумаги,
следует проделать и для остальных информационных массивов: Агенты, Портфели,
Заявки. В результате мы получим систему таблиц базы данных TfadeTest. Подчеркнем,
именно систему, так как находящиеся в них данные тесно и содержательно связаны
между собой. Действительно, данные, находящиеся в поле Код агента таблицы Портфели,
должны быть согласованы по типу и размеру с данными, находящимися в одноименном
поле таблицы Бумаги. Более того, логика рассматриваемой задачи требует, чтобы,
работая с информацией, относящейся к портфелю, мы могли одновременно обратиться
к данным, характеризующим текущего агента, и т. д.
Механизм описания логических связей между таблицами в Access реализован в виде
объекта, называемого Схемой данных. Перейти к ее созданию можно из панели инструментов
База данных, доступной из главного окна. Альтернативный вариант вызова данного
режима доступен через меню Сервис > Схема данных. Вид, который будет иметь
схема данных для построенных на предыдущих шагах таблиц, представлен на рис.
7.10.

Рис. 7.10. Создание схемы данных
Интерфейс задания связей между полями в схеме основан на "перетаскивании"
(перемещении при нажатой левой кнопки мыши) выбранного поля и "наложении"
его на то поле, с которым должна быть установлена связь. Для связывания сразу
нескольких полей их следует перемещать при нажатой клавише Ctrl. Выделяют несколько
типов связей между таблицами в схеме. " Один к одному" (1:1) - одному
значению поля в одной таблице соответствует только одно значение поля в другой.
"Один ко многим" (1:?) - одному значению поля в одной таблице соответствует
несколько (одно или более) значений в другой.
Важнейшей задачей, которую позволяет решать схема, является обеспечение логической
целостности данных в базе. Так, в базе данных TradeTest нарушение целостности
может возникнуть в случае удаления из таблицы Бумаги записей по тем бумагам,
о которых существуют записи в таблицах Портфели или Заявки, в результате чего
в их составе окажутся ссылки на "потерянные" коды. Очевидно, что это
можно предотвратить, если каскадно удалить как записи из таблицы Бумаги, так
и записи из связанных с ней таблиц. Такой эффект в Access может быть достигнут
за счет задания определенных свойств для связи. Чтобы это сделать, необходимо
щелкнуть кнопкой мыши, находясь на линии схемы, обозначающей связь. После этого
появляется диалоговое окно, предназначенное для изменения свойств связи. Как
видно из рис. 7.11, в рамках режима обеспечения целостности данных можно по
выбранной связи задать как каскадное обновление значений для связанных полей,
так и каскадное удаление связанных записей.
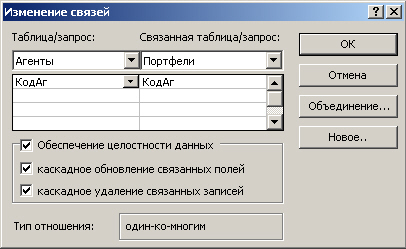
Рис. 7.11. Задание свойств связи
7.2.6. Разработка запросов к базе данных
Появление даже очень небольшой таблицы мгновенно приводит к возникновению целого
комплекса проблем, связанных с необходимостью обработки содержащихся в ней данных.
К простейшим задачам обработки могут быть отнесены:
o поиск записи по условию (см. функцию меню Правка > Найти);
o сортировка записей в требуемом порядке (см. функцию меню Записи > Сортировка);
o получение выборки записей таблицы, удовлетворяющей заданному условию, или,
как еще говорят, задание фильтра для таблицы (Записи > Фильтр).
Рис. 7.12. Контекстное меню работы с данными в таблице
Перечисленные функции также доступны из контекстного меню, активизирующегося
по нажатии правой клавиши мыши (рис. 7.12). Данный интерфейс представляется
особенно удобным при практической работе с таблицами Access. Однако этих возможностей
явно недостаточно для задач обработки данных, которые возникают в реальных экономических
приложениях. Для их решения в СУБД Access служит развитой инструментарий запросов
к базе данных. Понятие запроса в Access употребляется в расширительном плане.
Его следует трактовать как некоторую команду на выбор, просмотр, изменение,
создание или удаление данных. Также нельзя не отметить значение запросов для
решения задач анализа данных.
Наиболее распространенным и, если так можно выразиться, естественным типом запросов
является запрос на выборку. Данный тип, собственно говоря, и устанавливается
по умолчанию для вновь создаваемого запроса.
При работе с системой данных очень часто возникает задача соединения данных
из различных связанных таблиц в одну. Так, в рамках нашего примера естественной
представляется проблема построения таблицы, содержащей информацию по содержанию
портфелей и имеющей следующую структуру:
- Наименование бумаги;
- Наименование агента;
- Тип бумаги;
- Номинальная стоимость пакета, вычисляемая как произведение номинальной цены
на количество бумаг данного вида, которым обладает текущий агент.
Для ее решения следует перейти к разделу Запросы главного окна базы данных,
нажать на кнопку Создать и выбрать режим Конструктор. Процесс создания запроса
начинается с выбора таблиц (в том числе и Других запросов), на основе которых
строится запрос. В дальнейшем состав этого набора может быть изменен. Наш запрос
будет построен на основе данных таблиц Портфели, Агенты и Бумаги. Заметим, что
при добавлении таблиц к запросу по умолчанию добавляются и связи между ними,
заданные в схеме. В процессе формирования запроса можно выделить ряд принципиальных
этапов:
o описание структуры запроса (то есть указание того, какая информация должна
выводиться в колонках таблицы запроса);
o задание порядка, в котором данные должны выводиться при выполнении запроса;
o задание условий вывода записей в запросе.
На рис. 7.13 показано окно конструктора запроса.
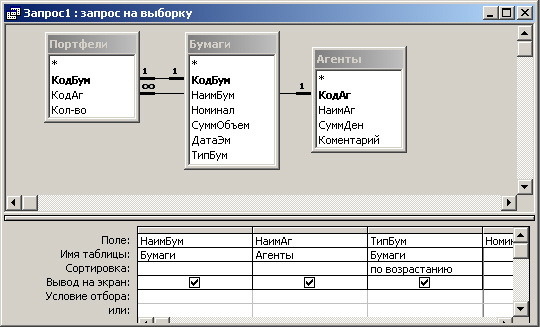
Рис. 7.13. Окно конструктора запроса
Отметим, что колонки таблицы запроса на рис. 7.13 содержа? как поля таблиц,
так и выражения, построенные на основе полей. В частности, последняя колонка
(ей присвоено имя НоминСтоим) содержит выражение [Номинал]*[СуммОбъем], при
этом записи будут выводиться отсортированными по типу бумаг.
По аналогии с принципами организации интерфейса работы с таблицами данных, при
конструировании запросов также существует возможность оперативного перехода
из режима Конструктор в Режим таблицы. При первом входе в Режим таблицы появляется
приглашение сохранить вновь созданный запрос. В данном случае ему дано имя СтруктураПортфелей.
На рис. 7.14 показано окно, в котором выводятся записи, соответствующие этому
запросу.
Следует обратить внимание на исключительно важную роль механизма запросов в
решении проблемы обеспечения минимальной избыточности сохраняемой в базе информации.
Действительно, с их помощью мы можем получать произвольное количество виртуальных
таблиц, представляющих в самых различных видах и разрезах единственную реально
хранимую совокупность данных.
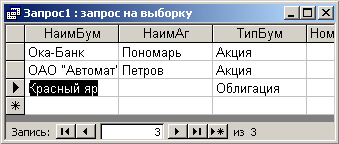
Рис. 7.14. Вывод данных по запросу СтруктураПортфелей
Рассмотрим еще один случай применения запросов для решения задач обработки данных. Достаточно типичной (в том числе для приложений финансово-экономического характера) является проблема группировки данных по тому или иному признаку. Например, в рамках построенной нами базы данных может быть поставлена задача определения суммарного (или среднего) спроса и предложения по ценным бумагам, циркулирующим на рынке. Решить ее можно, построив запрос, содержащий групповые операции. Для активизации возможности их задания в окне Конструктора запросов необходимо включить функцию меню Вид > Групповые операции.
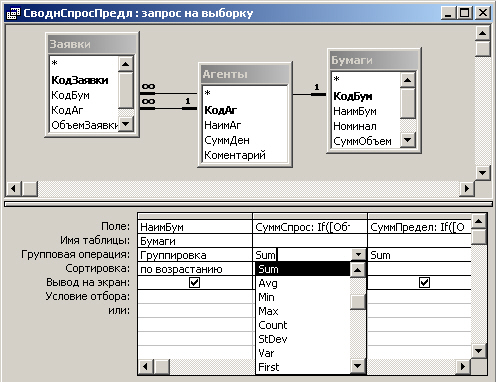
Рис. 7.15. Создание запроса с групповыми операциями
На рис. 7.15 показано окно конструктора в процессе создания запроса, выводящего информацию по суммарному спросу и предложению на ценные бумаги. Операция свертки нескольких записей из таблицы Заявки в одну результирующую запись, осуществляемая для каждого наименования бумаги, определяется командой Группировка, расположенной в строке Групповая операция. Для двух последующих колонок запроса (СуммСпрос и СуммПредл) определены операции суммирования по группе (Sum), расположенные в той же строке, а в строке Поле находятся производные выражения, суммы которых мы хотим получить в запросе. В соответствии с ранее принятыми соглашениями объем суммарного спроса определяется совокупностью всех записей по данной бумаге, имеющих положительное значение в поле ОбъемЗаявки, а объем суммарного предложения - записями, содержащими в данном поле отрицательную величину. Таким образом, для вычисления СуммСпрос необходимо просуммировать If[0бъем3аявки]>=0; [Цена3аявки]*[0бъем3аявки];0), а для вычисления СуммПредл - If[ОбъемЗаявки]<=0;-1* [Цена3аявки]*[0бъем3аявки];0).
ПРИМЕЧАНИЕ
Встроенная функция lf(bArg; Arg1; Arg2) возвращает значение аргумента Arg1,
если значение аргумента bArg, который может содержать только логическую величину,
является истинным (bArg = ИСТИНА), и значение Агд2, если bArg = ЛОЖЬ.
Также следует обратить внимание читателя на такие важные возможности конструктора
запросов, как:
- задание параметров, запрашиваемых при открытии запроса;
- встроенные статистические функции, доступные при задании групповых операций.
Они делают запросы мощным инструментом анализа хранимой информации.
В завершение обзора средств построения запросов в СУБД Access следует указать
также и на то, что в нее помимо мощного и эффективного визуального конструктора
встроен также и режим непосредственного ввода SQL-выражений, определяющего запрос.
Данный режим существует параллельно и доступен из меню Вид > Режим SQL (а
также из пиктограммы Вид на панели инструментов). Перейдя в него, в частности,
можно просмотреть SQL-выражение, соответствующее ранее построенному запросу
СводнСпросПредл. Оно выглядит так:
SELECT Бумаги.НаимБум,
Sum(IIf([ОбъемЗаявки]>=0,[Цена3аявки]*[0бъем3аявки],0))
AS СуммСпрос,
Sum (IIf ([ОбъемЗаявки]<=0,-[ЦенаЗаявки]*[0бъемЗаявки],0))
AS СуммПредл
FROM Бумаги INNER JOIN
(Агенты INNER JOIN Заявки ON Агенты.КодАг = Заявки.КодАг)
ON Бумаги.КодБум = Заявки.КодБум
GROUP BY Бумаги.НаимБум
ORDER BY Бумаги.НаимБум;
Пользователь, владеющий синтаксисом языка SQL, может модифицировать данное
выражение в ручном режиме. Очевидно, что такая техника работы требует существенно
большей квалификации, но одновременно она дает в руки разработчика мощный и
универсальный аппарат управления данными.
Говоря о связи между режимом визуального конструктора запросов и режимом построения
SQL-выражений, необходимо отметить, что существует естественная и логичная связь
между типами запросов и реализующими их SQL-операторами. В частности, запросу
на выборку соответствует оператор SELECT, запросу на создание - CREATE, запросу
на обновление.- UPDATE, запросу на удаление - DELETE и т. д.
7.2.7. Конструирование экранных форм для
работы сданными
В 7.2.4 был рассмотрен режим непосредственного ввода данных в таблицу. Очевидно,
что он имеет весьма ограниченное применение. Это обусловливается как тем, что
длина записи может оказаться достаточно большой и вводить информацию в нее в
табличной форме будет технически неудобно, так и соображениями более принципиального
характера:
o во-первых, структура таблицы должна строиться на основе логики задач хранения
информации, которая, вообще говоря, может существенно отличаться от логики ее
накопления и ввода;
o во-вторых, важным показателем качества автоматизированной системы является
организация ее системы ввода/вывода в виде, максимально приближенном к традиционным
формам представления информации на немашинных носителях. Такие формы, как правило,
делают программное обеспечение привлекательным для конечного пользователя, уменьшают
период его адаптации ко вновь внедряемой системе и позволяют быстро сосредоточиться
на решении основных профессиональных задач;
o в-третьих, в сложной и развитой автоматизированной информационной системе
должно обеспечиваться разделение доступа к различным группам полей и записей
для различима категорий пользователей в зависимости от выполняемых ими функций.
Также в определенных ситуациях требуется представить одну и ту же информацию
либо в различных видах и разрезах, либо в различных сочетаниях с другой информацией.
Для решения как этих, так и многих других проблем организации интерфейса ввода/
вывода данных в Access служит механизм электронных форм. Выберем вкладку Формы
главного окна базы данных и нажмем кнопку Создать. Появляющееся диалоговое окно
позволяет выбрать как таблицу или запрос, для работы с данными которых составляется
форма, так и режим ее создания. В зависимости от квалификации пользователя и,
естественно, сложности разрабатываемой формы можно либо воспользоваться встроенными
программными надстройками-мастерами, либо сразу начать ее создание с нуля в
режиме Конструктора. Весьма плодотворным также оказывается комбинированный подход:
сначала используется соответствующий мастер, а затем полученная форма дополнительно
дорабатывается в "ручном режиме". Проиллюстрируем сказанное на примере.
Создадим форму для работы с таблицей Бумаги, воспользовавшись надстройкой Автоформа:
в столбец. В результате получим окно следующего вида.
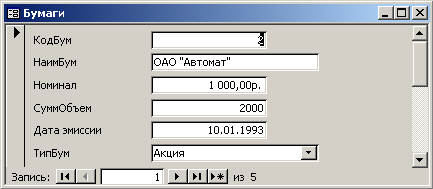
По умолчанию форме было предложено присвоить такое же имя, как и у таблицы,
на основе которой она была создана, то есть Бумаги. Как видно из рис. 7.17,
при создании подписей полей программная надстройка использовала их соответствущие
атрибуты, заданные при конструировании таблицы. Последнее не всегда бывает удобным
с точки зрения интерфейса пользователя. Для устранения этих и подобных недостатков
нам придется вернуться в режим изменения макета формы (кнопка Конструктор либо
пиктограмма Вид на панели инструментов).
На рис. 7.18 показана та же форма в режиме Конструктор. Технология процесса
проектирования форм в среде Access сводится к добавлению управляющих элементов
и изменению их свойств. В связи с этим при переходе в режим Конструктор >;>Ш
Экране по умолчанию появляются два дополнительных окна:
Окно Панель элементов, которое предназначено для выбора очередного добавляемого
к проектируемой форме управляющего элемента. В конструктор форм Access встроены
такие элементы управления, как надпись, поле, кнопка, флажок, переключатель,
список, набор вкладок и др. Помимо этого к форме можно подключать специальные
(дополнительные) элементы управления OLE, что значительно расширяет возможности
развития интерфейса управления данными.
Окно Свойств текущего элемента управления, предназначенное для изменения его
атрибутов и настроек, например, цвета, шрифта, размера и т. п.
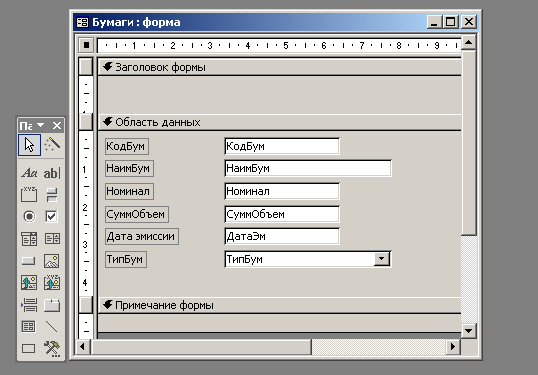
Рис. 7.18. Форма Бумаги в режиме конструктора
В режиме Конструктор явно видна структура формы. Она состоит из трех частей:
Заголовок формы, Область данных и Примечание формы. Как нетрудно догадаться,
такая структура в первую очередь ориентирована на возможности представления
таблично организованных данных. Заметим, что как сама форма, так и ее разделы
также рассматриваются как элементы управления, обладающие некоторыми настраиваемыми
наборами свойств.
В качестве иллюстрации возможностей конструктора по изменению интерфейса ввода/вывода
проведем следующие манипуляции над формой Бумаги:
L Удалим фоновый рисунок: очистим свойство Рисунок, когда текущим выбранном
элементом является вся форма.
2. Изменим цвет фона: выберем элемент ОбластьДанных и изменим у нее атрибут
Цвет фона (рис. 7.19).
3. Изменим внешний вид полей: выделим группу полей (поля выбираются с помощью
мыши при нажатой клавише Shift) и в окне свойств изменим значение атрибута Оформление
на Утопленное.
4. Отредактируем подписи полей и несколько изменим их расположение друг относительно
друга: для этого достаточно воспользоваться возможностями визуального редактирования
элементов.
5. Добавим разделительную линию после поля НаимБум (наименование бумаги): для
этого следует воспользоваться элементом Линия.
6. Добавим кнопку завершения работы с формой: в большинстве ситуаций эту и подобные
операции проще и удобнее делать в режиме мастера (нажата соответствующая кнопка
на панели Элементы управления). В этом случае от пользователя требуется лишь
ввести минимальное количество параметров для добавляемого программного компонента.
Добавленную кнопку поместим в область Примечания формы.
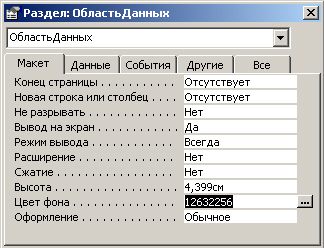
Рис. 7.19. Окно свойств элемента управления
В результате отредактированная форма Бумаги примет вид, показанный на рис 7.20.

Рис. 7.20. Форма Бумаги после редактирования
Пример организации ввода/вывода данных в таблицу Бумаги с помощью одноименной
формы носит в некотором смысле вырожденный характер: в нем структура полей в
форме однозначно соответствует их структуре в таблице. Однако, как правило,
при создании реальных приложений приходится решать задачу управления Данными,
находящимися в системе взаимосвязанных таблиц, из единой формы. В качестве примера
рассмотрим задачу построения формы, в которой для каждой данной бумаги одновременно
выводится информация по заявкам на ее покупку и продажу. Ее внешний вид приведен
на рис. 7.11. Верхняя (заголовочная) часть формы соответствует текущей строке
таблицы Бумаги и меняется при переходе от записи к записи, который может производиться
с помощью стрелок, расположенных в нижней части окна. Одновременно должны меняться
строки таблиц Заявки на продажу и Заявки на покупку, в которые выводится только
информация, относящаяся к текущей бумаге.
Рассмотрим более подробно те средства Access, с помощью которых может быть получен
такой результат. Это так называемая сложная/или составная форма (Заявки по бумагам).
Процесс ее создания состоит из двух принципиальных этапов:
- создание основной (главной) формы. Для этого осуществляются действия, аналогичные
тем, которые выполнялись при создании формы Бумаги;
- создание подчиненных форм. Для этого в созданную главную форму добавляется
элемент управления Подчиненная форма. При создании подчиненной формы в Access
существует две принципиальные возможности:
- создать новую форму на базе некоторой таблицы или запроса;
- воспользоваться уже существующей формой, сделав ее подчиненной.
В данном случае созданы две новые подчиненные формы. Причем созданы они на базе
специальных запросов. Такое решение позволяет выделить по отдельности из общей
таблицы Заявки записи с заявками на продажу и на покупку. В частности, запрос
ЗаявПрод, возвращающий выборку из заявок на продажу ценных бумаг, имеет структуру,
показанную на рис. 7.22. В качестве преимуществ такого подхода к организации
источника данных для подчиненной формы следует отметить следующие моменты:
o во вспомогательном запросе достаточно просто обработать условие, идентифицирующее
тип заявки (если объем заявки меньше нуля, то это заявка на продажу). Более
того, для конечного пользователя в качестве объема заявки вместо отрицательных
величин выводятся выглядящие более естественно положительные значения -1*[0бъем3аявки];
o данные выводятся отсортированными по возрастанию предлагаемых цен, что несомненно
упрощает процесс работы с ними в экранной форме.
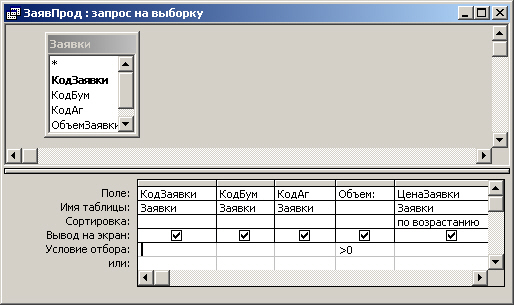
Рис. 7.22. Структура запроса ЗаявПрод (заявки на продажу)
Запрос, возвращающий записи с заявками на покупку, создается аналогично с учетом
модификации условия отбор.
Наиболее существенным моментом в процессе внедрения подчиненной формы в главную
является правильное задание условия связи между ними. Во многих случаях с этим
корректно справляются программные надстройки мастеров. При этом они используют
информацию из схемы данных и описаний структуры таблиц. В to же, время, не следует
забывать и о возможностях изменения условий связи между ведущей и подчиненной
формами в ручном режиме. Для этого необходимо изменить атрибуты в элементе управления
Подчиненная форма, находясь в режиме Конструктор
7.2.8. Конструирование отчетов
Неотъемлемой функцией любых программных систем, так или иначе связанных с обработкой
данных, является представление обетов по хранимой информации. Под отчетом традиционно
понимается специальным образом структурированное представление хранимых данных,
выводимое (как правило) на бумажный носитель. Перечислим принципиальные отличия
отчетов от экранных форм, обусловившие выделение их в отдельный программный
объект СУБД Access:
- во-первых, отчеты являются исключительно средством вывода информации;
- во-вторых, организация данных в отчетах предполагает возможность их сложного,
многоуровневого структурирования;
- в-третьих, структура информации, выводимой в отчете, должна быть согласована
со структурой носителя. Например, разбиение отчета на страницы предполагает
организацию вывода регулярных элементов в начале и конце каждого листа (колонтитулов),
дублирование шапок таблиц и т.д. Также на внешний вид отчета значительное влияние
оказывают параметры конкретного печатающего устройства, которое будет использовано
для его вывода.
В то же время, к числу важных достоинств Access относится то, что идеология
работы как с экранными формами, так и с отчетами максимально универсализирована.
В частности, интерфейс режима конструирования макета отчета аналогичен режиму
конструктора для экранных форм.
Рассмотрим способы решения задач разработки отчетов, которые могут возникать
в рамках описываем9Й нами программной системы управления торгами ценными бумагами.
Простейшие отчеты, которые, скорее всего, будут необходимы пользователям системы,
- это распечатанные списки бумаг и агентов. Для их создания можно воспользоваться
надстройками Автоотчет в столбец или Автотчет ленточный. На рис. 7.24 показан
макет отчета по агентам, созданный в режиме Автоотчет ленточный.

Рис. 7.24. Отчет по агентам в режиме конструктора
Из рис. 7.24 видно, что в процессе конструирования в макет отчета могут быть
добавлены те же самые управляющие элементы, что и при конструировании макета
экранной формы. В то же время следует отметить, что структура отчета как объекта
базы данных имеет свою специфику. Во-первых, она определяется уровнями группировки
данных, выводимых в отчет, а во-вторых, содержит секции, соответствующие регулярным
элементам, помещаемым в начале и конце каждого листа - верхнему и нижнему колонтитулам.
Для задания уровней группировки данных используется функция меню Вид > Сортировка
и группировка или же одноименная пиктограмма на панели инструментов Конструктор
отчетов.
При работе с отчетами активно используются (это видно из рис. 7.24) встроенные
переменные [Page] и [Pages], возвращающие номер текущей страницы отчета и общее,
количество страниц в нем, а также функция NowQ, определяющая текущую дату и
время по системному календарю.
Остановимся теперь на более сложном примере. Поставим задачу построить отчет,
выводящий сведения о спросе и предложении по ценным бумагам с учетом их типа,
то есть записи должны быть структурированы по следующим уровням:
все бумаги;
тип бумаги;
агент;
предложения агента по данной бумаге.
Также по каждому из уровней желательно предусмотреть вывод промежуточных итогов
(или же соответствующих средних значений).
Информация для данного отчета (назовем его РаспределЗаявок) должна браться из
различных таблиц, поэтому в качестве источника данных для него целесообразно
использовать специально построенный запрос. Для наглядности приведем SQL-выражение,
соответствующее данному запросу:
SELECT
IIf([ТипБум]= "1", "Акции", "Облигации") AS Тип,
Заявки.КодБум,
Бумаги.НаимБум,
Бумаги.Номинал,
Агенты.НаимАг,
IIf ([0бъем3аявки]<0,-1*[0бъем3аявки],0) AS
ОбъемПродажи,
IIf ([ОбъемЗаявки]<0,[ЦенаЗаявки],0) AS ЦенаПродажи,
IIf ([0бъем3аявки]>0,[0бъем3аявки],0) AS ОбъемПокупки,
IIf ([ОбъемЗаявки]>0, [ЦенаЗаявки],0) AS ЦенаПокупки,
FROM Бумаги
INNER JOIN (Агенты INNER JOIN Заявки ON Агенты.КодАг = Заявки.КодАг) ON
КодБум = Заявки.КодБум
ORDER BY IIf ([ТипБум]="1", "Акции", "Облигации"),
Бумаги.НаимБум;
На основе построенного запроса можно перейти к разработке отчета. На начальном
этапе представляется рациональным воспользоваться услугами мастера отчетов.
Он в режиме диалога с пользователем позволяет создать походящую "заготовку",
избавляя нас от многих рутинных операций, например таких, как добавление полей
и подписей к ним.
Далее полученный макет вручную "доводится" до желаемого вида в режиме
Конструктор

Рис. 7.26. Задание уровней группировки и сортировки
Важным этапом при создании многоуровневого отчета является задание уровней
группировки выводимых данных. Это делается в окне, показанном на рис. 7.26,
которое вызывается из меню Вид > Сортировка и группировка. Для каждого из
заданных уровней группировки данных могут быть определены раздел типа Заголовок,
выводимый в начале каждой группы, и раздел типа Примечание, формируемый, когда
группа заканчивается.
Задачи получения средих и итоговых значений по группам данных решаются с помощью
встроенных функций Sum() и Avg(). Например/для получения среднего значения цены
продажи бумаги в соответствующем элементе управления свойство Данные содержится
строка =Avg([ОбъемПродажи]), а для определения итогового спроса используется
формула =Sum([ОбъемПродажи]* [ЦенаПродажи]).
Распределение заявок
7.2.9. Средства макропрограммирования в
MS Access
Access, как и любая другая развитая программная система, обладает средствами
разработки программных приложений, ориентированных на конечных пользователей.
Эти средства базируются на инструментах двух типов: макросах и модулях. Само
понятие макроса подразумевает наличие набора некоторых стандартных команд системы,
или макрокоманд (допустим, таких, как открытие формы, выполнение запроса, вывод
отчета), из которых и конструируется сам макрос.
Макрос может быть как собственно макросом, состоящим из последовательности макрокоманд,
так и группой макросов. Группой макросов называют их набор, сохраняемый под
общим именем. В некоторых случаях для решения, должна ли в запущенном макросе
выполняться определенная макрокоманда, может применяться условное выражение.
Особый интерес вызывает механизм вызова макросов в Access. Для этого существует
две принципиальных возможности:
вызов макроса по команде пользователя (либо непосредственно из раздела Макросы
главного окна базы данных, либо с помощью меню или панели инструментов, с которыми
он также может быть ассоциирован);
вызов макроса по некоторому системному событию (открытие или закрытие формы,
изменение управляющего элемента и т. п.).
Весьма полезной представляется возможность организовать автоматическое выполнение
ряда действий при открытии базы данных. Для этого они должны быть описаны в
специальном макросе с именем Autoexec.
Возможности применения макросов при работе в среде СУБД Access можно наглядно
продемонстрировать на следующем примере. Предположим, что в ранее созданную
форму Бумаги мы хотим добавить процедуру дополнительного контроля вводимых значений
дат эмиссии ценных бумаг, которая должна будет выдавать предупреждающее сообщение,
если вводится слишком "ранняя" дата. Допустим, что к таковым относятся
даты, предшествующие 1 января 1991 года.
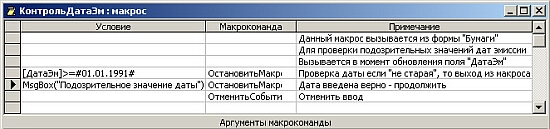
Рис. 7.28. Создание макроса
Технически решение представляется удобным реализовать в виде макроса, вызываемого
по событию "до обновления", ассоциированному с полем ДатаЭм в форме
Бумаги.
На рис. 7.28 показан процесс разработки данного макроса (ему дано имя КонтрольДатаЭм).
Из него видно, что макрос содержит три макрокоманды:
- Первая, ОстановитьМакрос - прерывает работу, если введена дата более поздняя,
чем 1 января 1991 года.
- Вторая, ОстановитьМакрос - выполняется, если пользователь считает, что несмотря
на сделанное предупреждение введенная дата является верной. Для вывода предупреждения
используется встроенная функция MsgBox.
- Третья - отменяет событие ввода данных, если они после предупреждения признаются
ошибочными.
Хорошим стилем разработки макросов является снабжение их комментариями, располагаемыми
в соответствующей колонке.
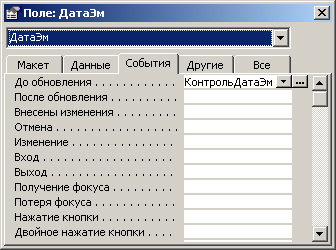
Рис. 7.29. "Привязка" макроса к событию
На рис. 7.29 показана привязка разработанного макроса к событию "до обновления" поля ДатаЭм формы Бумаги.
7.2.10. Разработка программных приложений
для MS Access
Модули, в отличие от макросов, являются более тонким и мощным средством создания
программных расширений в среде Access, максимально приближающимся по своим функциональным
возможностям к таким профессиональным инструментам, как Delphi, Visual Basic
или Power Builder. Одновременно применение модулей требует от пользователя навыков
и квалификации программиста, а также знания основных принципов объектно-ориентированного
программирования.
Для программирования в Access используется процедурный язык Visual Basic для
приложений (VBA- Visual Basic for Applications) с добавлением объектных расширений
и элементов SQL. Сам процесс создания программных расширений в среде Access
предполагает активное использование технологии объектно-ориентшрованного программирования
(ООП). В основе ООП лежит идея "упакованной функциональности", в соответствии
с которой программа строится из фундаментальных сущностей, называемых объектами.
Каждый из объектов характеризуется набором свойств (англ, -property) и операций,
которые он может выполнять (англ,- method). Реализация взаимодействий между
объектами ложится на исполняющую cpеду того средства разработки, на котором
пишется программа, и поэтому работа программиста в рамках технологии ООП сводится
к созданию объектов, описанию их свойств и реакций на те иди иные внешние события.
Фундаментальным понятием ООП является класс. Класс - это шаблон, на основе которого
может быть создан конкретный программный объект. Созданный объект в таком случае
становится экземпляром класса. К основополагающим принципам ООП относятся:
" инкапсуляция - объединение свойств и действий, присущих объекту, в едином
пакете и сокрытие подробностей их реализации от окружающего мира. Это означает,
что пользовательский доступ к объекту допускается только через его свойства
и методы;
" наследование - предусматривает создание новых классов на базе существующих,
что дает возможность классу-потомку иметь (наследовать) все свойства класса-родителя;
" полиморфизм - (от греч. "многоликость") означает, что порожденные
объекты обладают информацией о том, какие методы они должны использовать в зависимости
от того, где они находятся в цепочке наследования;
" модульность - объекты заключают в себе полное определение их характеристик,
никакие определения методов и свойств объекта не должны располагаться вне его,
что делает возможным свободное копирование и внедрение одного объекта в другие.
Многие программные объекты в Access совпадают с физическими объектами базы данных,
такими как таблицы, формы, отчеты. Для названия составных объектов, которые
включают в себя совокупность более простых объектов, используется термин семейство.
Например, объект отчет входит в семейство отчеты. Помимо "видимых"
объектов существует и большое количество "скрытых" объектов, управлять
которыми можно только из программных приложений.
В Access существуют два типа модулей: стандартные и модули класса.
Стандартные модули содержат процедуры и функции, которые могут быть вызваны
из любого окна базы данных. Как правило, такие модули содержат программный код
универсального характера, предназначенный для применения в различных местах
текущего приложения или даже в различных приложениях.
Модули класса используются, для создания новых классов объектов. При создании
конкретного объекта, являющегося экземпляром такого класса, любые процедуры,
определенные в модуле, становятся свойствами и методами этого объекта.
Модули форм и модули отчетов являются модулями класса, связанными с определенной
формой или отчетом. Заметим, что в ранних версиях Access они являлись единственно
возможным инструментом объектно-ориентированного программирования. Эти модули
содержат процедуры обработки событий, запускаемых в ответ на их возникновение
в форме или отчете. Процедуры обработки событий используются для управления
поведением формы или отчета и их откликом на события, например такие, как нажатие
кнопки.
Важнейшей областью применения объектно-ориентированного программирования в Access
является программирование доступа к данным. Для решения данной задачи фирмой
Microsoft был разработан специальный интерфейс - ОАО (Data Access Objects).
DAO - это набор объектных классов, которые моделируют структуру реляционной
базы данных. Они обеспечивают свойства и методы, которые позволяют выполнять
такие операции, как создание базы данных, определение таблиц и индексов, задание
связей между таблицами, формирование запросов и отчетов и т. п. Существенным
достоинством объектной модели ОАО является ее универсальный характер: она доступна
для большинства средств разработки программного обеспечения, поддерживаемых
Microsoft, в частности, для Visual Basic. Классы объектов доступа к данным организованы
по иерархической схеме. На ее вершине находится объект DbEngine, представляющий
собой ядро базы данных. Далее следуют объекты, отвечающие за управление сеансами
доступа пользователя к данным, - Workspace (от англ, "рабочая область").
Каждая рабочая область включает один или несколько объектов класса база данных
- Database, а они, в свою очередь, содержат семейства объектов таблиц (TableDef),
запросов (QueryDef), наборов записей (RecordSet) и т. д.
В заключение раздела, посвященного модулям, отметим, что мы сознательно не затрагиваем
собственно вопросы теории и практики создания программ на VBA в среде Access,
так как они являются весьма обширными. В случае необходимости читатели могут
ознакомиться с ними в специальных профессиональных изданиях и руководствах.
7.3. Организация взаимодействия между системами
управления данными
7.3.1. Проблема форматно независимого доступа к данным и технология
ODBC
Процесс разработки и развития любой СУБД неизбежно приводит к необходимости
решать проблему взаимодействия с данными, созданными и управляемый в рамках
других программных систем, или, как еще говорят, к проблеме доступа к внешним
источникам данных. Это, в свою очередь, определяет принципиальное требование,
которому должны удовлетворять прикладные СУБД: ^программные процедуры обработки
информации, создаваемые в рамках СУБД, должны быть максимально независимыми
от формата хранимых данных.
Выполнение этого принципа позволяет:
- во-первых, с наименьшими затратами осуществлять переход от одной СУБД к другой,
потребность в чем, допустим, возникает при масштабировании ранее созданного
программного обеспечения для предприятий и фирм качественно иного размера;
- во-вторых, успешно решать задачи интеграции двух и более независимых программных
систем.
Важнейшим инструментом форматно независимого доступа к данным из программ стала
технология ODBC (Open Data Base Connectivity), созданная фирмой Microsoft. Ее
принципиальная схема изображена на рис. 7.30.
Как следует из рис. 7.30, в рамках ODBC:
- программное приложение непосредственно взаимодействует с диспетчером драйверов,
посылая ему ODBC-вызовы;
- диспетчер драйверов отвечает за динамическую загрузку нужного ODBC-драйвера,
через который обращается к СУБД (серверу баз данных);
Рис. 7.30. Принципиальная схема технологии ODBC
- ODBC-драйвер выполняет все вызовы ODBC-функций, "переводит" их
на язык источника данных;
- СУБД хранит и выводит данные в ответ на запросы со стороны ODBC-драйвера (или
же возвращает код ошибки).
В настоящее время в состав подавляющего большинства систем управления данными
входят соответствующие ODBC-драйверы.
Таким образом, при работе с базой данной через ODBC-драйвер она выступает как
некоторый виртуальный источник данных, которым можно управлять с помощью SQL-подобных
команд.
Рис. 7.31. Окно Администратора источников данных ODBC
Задание ODBC-источника данных (DSN - data source name) является действием,
которое осуществляется средствами операционной системы, управляющей компьютером.
В частности, в операционных средах Windows для этого в Панели
управления предусмотрен пункт Источники Данных ODBC (32 разр), из которого вызывается
Администратор источников данных ODBC.
С его помощью могут быть заданы:
- пользовательский DSN - источник данных, доступный только текущему пользователю
на текущем компьютере;
- файловый DSN - источник данных, которые могут применять совместно различные
пользователи, у которых установлены одинаковые ODBC-драйверы;
- системный DSN - источник данных, доступный всем пользователям и службам текущего
компьютера.
Окно Администратор источников данных ODBC показано на рис. 7.31.
7.3.2. Доступ из MS Access к источникам
данных в формате других программных приложений
В MS Access предусмотрены две принципиальные возможности работы с внешними данными.
Это импорт данных и связь с внешними таблицами данных. Оба режима доступны из
меню главного окна базы данных: Файл > Внешние данные.
В случае импорта происходит создание дубликата внешних данных во вновь создаваемой
таблице. Среди преимуществ такого решения могут быть названы:
- доступность всего арсенала средств СУБД Access при манипуляциях импортированными
данными;
- высокое быстродействие при обращении к ним;
- независимость от исходного источника данных.
Однако, приобретая указанные преимущества, мы одновременно получаем и потенциальные
проблемы, связанные с поддержанием актуальности и соответствия друг другу двух
параллельных копий одной и той же информации. Очень часто подобные проблемы
оказываются неразрешимыми.
Eejrtf актуальность данных является для нас критичным фактором, то необходимо
использовать другой способ работы с внешними данными - связь. В этом случае
в базе данных добавляется лишь ссылка на внешние источники данных и работа с
ними происходит с помощью специальных драйверов. В поставку MS Access традиционно
входят драйверы для работы с данными, созданными в форматах Paradox" Excel,
dBase, FoxPRO, а также в текстовом (*.txt) и гипертекстовом (*.htm) форматах.
Базы данных Paradox, Excel, dBase, FoxPRO и некоторых других форматов также
называют базами данных с индексно-последовательной организацией (англ. - ISAM
- Indexed Sequential Access Method). Специфические IS AM-драйверы, учитывающие
конкретные особенности перечисленных форматов организации данных, как правило,
обеспечивают высокую эффективность и быстродействие при работе с ними. Одновременно
в Access существует возможность работы с обширным множеством универсальных источников
данных, для которых установлены ODBC-драйверы. Для этого при указании типа файла,
с которым устанавливается связь, необходимо выбрать Базы данных ODBCQ (рис.
7.32).
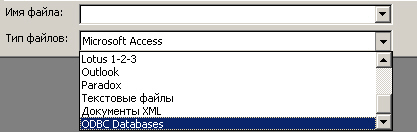
Рис. 7.32. Выбор типа внешнего источника данных
"Платой" за применение технологии связывания с внешними данными являются ограничения возможностей по управлению структурой добавляемых таблиц, а также зависимость от состояния самого внешнего источника, к которому мы подключаемся.
7.3.3. Технологические решения по организации
доступа к данным
Рассмотрим чуть подробнее архитектуру доступа к данным в Access. Схематично
она представлена на рис. 7.33. В представленной схеме блок пользовательского
интерфейса олицетворяет видимую часть СУБД, то есть то, с чем пользователь взаимодействует
непосредственно (формы, отчеты и другие объекты). Под хранилищем данных понимаются
файл (файлы), содержащие таблицы данных (например, в Access это mdb-файлы).
Хранилище - это некоторый пассивный элемент, в нем данные просто содержатся.
Осуществлять манипуляции с ними - это задача процессора базы данных (или, как
еще говорят, ядра базы данных). Он транслирует команды приложения в физические
операции, непосредственно меняющие файл (файлы) хранилища данных. Основным достоинством
описанной схемы является независимость приложения от типа базы данных, к которой
она обращается: будут ли это данные во внутреннем формате Access или данные
какой-то другой структуры - в приложении используются одни и те же объекты и
методы доступа к ним.

Рис. 7.33. Архитектура доступа к данным в Access
В СУБД MS Access используется процессор, получивший название Jet (Join* Engine
Technology). Он реализован в виде набора файлов динамически компонуемых библиотек
(DLL), которые связываются с прикладной программой Access в период ее выполнения.
В состав процессора Jet входят процессор запросов SQL и процессор обработки
результатов, возвращаемых этими запросами.
Рассмотренная ранее модель объектного интерфейса доступа к данным ОАО представляет
собой программную надстройку над процессором Jet. Jet также реализует описанные
в 7.3.1 возможности по доступу к внешним данным в формате ISAM и источникам
данных ODBC.
Для работы СУБД MS Access 97 был использован процессор Jet версии 3.5 для 32-разрядных
приложений. Среди принципиальных преимуществ новой версии могут быть названы:
- ODBCDirect - альтернативный режим DAO, который предоставляет возможности прямого
обращения к источникам данных ODBC в обход ядра Jet. Это позволяет в некоторых
случаях оптимизировать процесс работы с данными за счет использования специфических
характеристик удаленных ODBC-источников;
- для баз данных, управляемых процессором Jet, определены новые объекты, свойства
и методы, позволяющие использовать новые возможности частичной репликаций.
Также следует отметить, что в Jet реализована технология Rushmore - специальная
методика управления запросами, которая позволяет очень эффективно отбирать Наборы
записей при использовании в их критериях определенных типов выражений.
7.4. Организация многопользовательского
доступа к данным
7.4.1. Проблема многопользовательского доступа
и параллельной обработки данных
в автоматизированных информационных системах
Естественным следствием развития СУБД является проблема организации совместной
работы нескольких пользователей с одной и той же совокупностью данных, или,
кратко, проблемы многопользовательского доступа к данным.
Остановимся более подробно на основных аспектах этой проблемы. Прежде всего
ситуация разделения одной и той же совокупности данных между несколькими пользователями
может приводить к возникновению конфликтов (попытка единовременного изменения
одной и той же записи, совпадение операций чтения и удаления информации и т.
д.). Отдельное место при работе с СУБД занимают
вопросы предотвращения коллизий, которые могут возникнуть в случае несогласованных
изменений структуры таблиц, форм дли отчетов одним пользователем, когда с ними
работают другие.
С точки зрения организации совместного доступа к данным со стороны нескольких
пользователей режимы работы с ними делятся на режим монопольного (эксклюзивного)
доступа и режим общего (разделенного) доступа.
Режим монопольного доступа к базе данных предусматривает, что только один из
пользователей (программных процессов) может работать с ней, а возможность ее
открытия другими пользователями (процессами) блокируется. Открытие базы данных
в монопольном режиме, как правило, используется для выполнения операций по изменению
структуры таблиц и связей между ними, экспорта большого количества информации,
выполнения служебных операций с данными (сохранение, восстановление, сжатие)
и т. п.
Соответственно, в режиме разделенного доступа сразу несколько пользователей
могут работать с базой данных. Для предотвращения возможных конфликтов при попытках
со стороны различных пользователей изменить одни и те же записи в СУБД используется
механизм блокировок. Блокировка того или иного объекта в случае работы с ним
какого-либо пользователя означает предотвращение любых других попыток изменить
этот объект, но при этом сохраняется возможность его чтения. Таким образом,
механизм блокировок предоставляет более гибкие возможности для манипуляций с
данными по сравнению с режимом монопольного доступа.
Для различных СУБД конкретные технические решения по реализации аппарата блокировок
существенно различаются. В MS Access, в частности, при изменении записи одним
пользователем по умолчанию происходит ее автоматическая блокировка вплоть до
момента завершения операции. При создании форм, отчетов или запросов в Access
предусмотрены возможности задания параметров режима блокировки. На рис. 7.34
показан процесс изменения свойства Блокировка записей для формы.
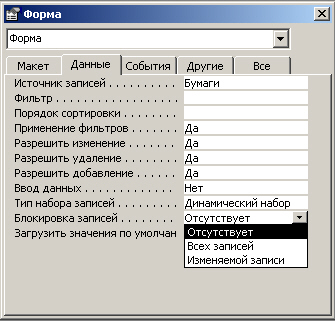
Рис. 7.34. Задание режима блокировки для данных, доступных из формы
Как видно из рисунка, свойство Блокировка записей может принимать значения:
- Отсутствует - допускается одновременное изменение записей со стороны нескольких
пользователей. При этом если два пользователя пытаются сохранись произведенные
изменения в одной и той же записи, то второму пользователю выводится предупреждающее
сообщение, на основе которого он может либо отказаться от дальнейших действий,
либо заместить изменения, сделанные первым пользователем, сохранив собственный
вариант. Очевидно, что в таком режиме сохраняется максимальная свобода действий
пользователей, "платой" за которую являются возможные конфликты ввиду
несогласованности их действий.
- Всех записей - происходит блокировка всех записей в источнике данных при его
открытии одним из пользователей, в результате чего он может беспрепятственно
изменять его. Другие пользователи имеют доступ только на чтение (просмотр).
- Изменяемой записи - один из пользователей получает доступ на изменение нужной
ему записи, а другие пользователи могут только читать содержащиеся в ней данные.
Данный режим накладывает минимальные ограничения на совместную работу. Следует
добавить, что технически в Access блокируются не записи как таковые, а так называемые
страницы - блоки файла базы данных размером 2048 байт, содержащие нужные записи.
Отмена блокировки в Access происходит тогда, когда пользователь, ранее блокировавший
запись, либо сохранит произведенные изменения, либо откажется от них. Для того
чтобы изменения, производимые одним пользователем, становились видны другим,
через определенные интервалы времени предусмотрено автоматическое обновление
содержания таблиц, форм и отчетов. Значение периода обновления задается из меню
Сервис > Параметры, вкладка Другие, поле Период обновления.
Другим ^существенным вопросом, который должен быть решен для обеспечения нормального
функционирования многопользовательских СУБД, является организация системы администрирования
данных. Среди задач администрирования могут быть названы:
- создание системы пользователей и разделение прав доступа различных пользователей
к объектам СУБД;
- организация и поддержание системы резервного хранения информации и ее восстановления
в случае программных и аппаратных сбоев;
- мониторинг программных и аппаратных ресурсов, задействованных для обеспечения
работы СУБД, и принятие на его основе решений по оптимизации их использования.
Некоторые вопросы, связанные с организацией системы пользователей СУБД, будут
рассмотрены в 7.4.3.
Первые многопользовательские СУБД имели централизованную архитектуру и базировались
на больших компьютерах или мини-ЭВМ. Рабочие места пользователей располагались
на терминалах, подключенных к центральному компьютеру, ria котором выполнялись
все процессы по манипуляции с данными. Однако с распространением персональных
компьютеров особую актуальность приобрели СУБД, реализующие технологии распределенной
обработки данных, то есть такие технологии, которые позволяют вести одновременную
работу с нескольких относительно ограниченных по аппаратным возможностям машин,
объединенных в ceть. В этом случае одна часть функций СУБД выполняется на компьютере-клиенте,
а другая - на компьютере-сервере, причем их взаимодействие осуществляется через
некоторый согласованный протокол.
Исторически первая технология распределенной работы с данными получила название
файл-сервер (FS-модель). В ее рамках предполагается, что один из компьютеров
в сети является файловым сервером и предоставляет свои ресурсы по обработке
файлов другим компьютерам, на нем также располагается хранилище данных. На других
компьютерах имеется прикладное программное обеспечение, реализующее функции
пользовательского интерфейса доступа к данным, и копия процессора базы данных
(СУБД). Всякий раз, когда прикладная программа обращается к базе, процессор
данных обращается к файловому серверу. В ответ файловый сервер направляет по
сети требуемый блок данных, получив который, СУБД осуществляет действия, декларированные
в прикладной программе. Протокол обмена между серверным и клиентскими компьютерами
представляет собой набор низкоуровневых вызовов, обеспечивающих интерфейсному
приложению доступ к файловой системе сервера.
Технологические недостатки FS-модели вытекают из внутренне присущих ей ограничений.
Среди них в первую очередь следует назвать:
- высокий сетевой трафик, обусловливаемый необходимостью передавать большое
количество файловых блоков от сервера к приложениям;
- ограниченный набор допустимых действий по обработке данных на файловом сервере,
который не способен "понимать" внутреннюю логическую структуру базы
данных и воспринимает эту базу так же, как и любой другой файл;
- отсутствие надежных средств обеспечения безопасности работы с данными - допускается
защита только на уровне функций сетевой операционной системы.
Перечисленные проблемы определяют то, что СУБД, основанные на технологии файл-сервер,
могут применяться только в очень ограниченных масштабах. Например, при создании
коллективных информационных систем, рассчитанных на небольшое количество пользователей
и ограниченные информационные потоки. Одновременно следует отметить, что FS-модель
положена в основу архитектур подавляющего большинства настольных СУБД, таких
как FoxPRO, Clipper, Clarion, Paradox, Access, завоевавших широкую популярность
среди отечественных разработчиков.
7.4.2. Основные направления развития технологии
клиент-сервер
Работа по преодолению недостатков, органически присущих системам файл-ceрвер,
привела к появлению более прогрессивной технологии, получившей название - сервер.
Ее принципиальные отличия показаны на рис. 7.35.
a
b
Рис. 7.35. Принципиальная схема технологий файл-сервер(a) и клиент- сервер(b)
В системе клиент-сервер процессор базы данных размещается на центральном сервере
умеете с хранилищем данных. Он может обслуживать одновременно несколько клиентских
приложений, управляя хранилищем и возвращая запрошенную информацию после обработки
запросившему ее локальному приложению. К настоящему моменту можно назвать ряд
этапов, которые технология клиент-сервер прошла в своем развитии: RD А-модёль,
DBS-модель и AS-модель. В RDA-модели клиентское приложение направляет запросы
(как правило, на языке SQL) к информационным ресурсам сервера, на котором функционирует
ядро СУБД. Ядро обрабатывает полученные запросы и возвращает клиенту результат,
оформленный как блок данных. При такой схеме программы на компьютерах-клиетах
являются инициаторами манипуляций с данными, а ядру СУБД отводится я роль. Основное
достоинство RDA-модели состоит в унификации интерфейса взаимодействия с сервером
с помощью стандартного языка запросов.
Унификация позволяет реализовывать дополнительные меры по защите хранимой информации
на уровне задания системы прав по отношению к тем иди иным командам. В рассматриваемой
модели также происходит существенная разгрузка трафика сети за счет того, что
между станциями сети теперь передаются не части файла базы данных, а команды
и ответы на них.
Основу DBS-модели составляет механизм хранимых процедур. Хранимые процедуры-
это средство программирования сервера баз данных. Они хранятся в словаре базы
данных, могут разделяться между различными клиентами и выполняются на том же
компьютере, где запущен программный процесс сервера баз данных. Как правило,
языки, на которых создаются хранимые процедуры, представляют собой процедурные
расширения языка SQL На настоящий момент не существует единого стандарта для
таких языковых средств; поэтому они являются специфичными для каждой конкретной
СУБД. Среди достоинств DBS-модели могут быть названы возможность централизованного
администрирования прикладных функций, дальнейшее снижение трафика (вместо SQL-запросов
по сети передаются вызовы хранимых процедур), экономия ресурсов компьютера за
счет использования однократно разработанного плана выполнения процедуры. К традиционным
проблемам, связанным с DBS-моделью, относят трудности, сопутствующие процессам
создания, отладки и тестирования хранимых процедур. О популярности и перспективности
данной модели свидетельствует прежде всего то, что она реализована в таких широко
используемых реляционных СУБД, как Oracle, Sybase, Informix, Ingres.
В AS-модели процесс, выполняющийся на компьютере-клиенте, называется клиентом
приложения (Application Client - А С) и отвечает за интерфейс с пользователем.
В случае необходимости выполнить те или иные прикладные операции он обращается
к серверу приложения (Application Server - AS). Все операции над информационными
ресурсами выполняются специальными программными компонентами, по отношению к
которым AS играет роль клиента. В качестве примера прикладных компонентов могут
быть названы ресурсы различных типов - базы данных, очереди, почтовые службы
и др.
Само по себе ядро базы данных Jet, как уже упоминалось ранее, не является процессором,
поддерживающим технологию клиент-сервер. Однако с помощью Access можно создавать
соответствующие приложения, связываясь с клиент-серверными источниками данных
через ODBC.
7.4.3. Организация защиты данных в СУБД
MS Access
Непременной функцией любой развитой СУБД является обеспечение защиты
данных от несанкционированного доступа. Очевидно, что полноценный с точки зрения
надежности и устойчивости режим защиты может быть обеспечен только в рамках
промышленных систем управления при условии комплексной реализации мер программного,
аппаратного и административного характера. Перед настоящим параграфом поставлена
более скромная задача - на примере MS Access описать на принципиальном уровне
те подходы, которые применяются в СУБД Для обеспечения программной защиты данных.
MS Access обеспечивает два традиционных способа защиты базы данных:
- установка пароля, требуемого при открытии базы данных;
- защита на уровне определения прав пользователей, которая позволяет ограничить
возможность получения или изменения той или иной информации в базе данных для
конкретного пользователя.
Кроме того, можно удалить изменяемую программу Visual Basic из базы данных,
чтобы предотвратить изменения структуры форм, отчетов и модулей, сохранив базу
данных как файл MDE.
Установка пароля на открытие базы данных представляет собой простейший способ
защиты. После того как пароль установлен (функция меню Сервис > Защита >
Задать пароль базы данных), при каждом открытии базы данных будет появляться
диалоговое окно, в котором требуется ввести пароль. Открыть базу данных и получить
доступ к ее ресурсам могут получить только те пользователи, которые введут правильный
пароль. Этот способ достаточно надежен (MS Access шифрует пароль, так что к
нему нет прямого доступа при чтении файла базы данных). Однако проверка проводится
только при открытии базы данных, после чего все ее объекты становятся полностью
доступными. В результате, установка пароля обычно оказывается достаточной мерой
защиты для баз данных, которые совместно используются небольшой группой пользователей
или установлены на автономном компьютере.
Гораздо более надежным и гибким способом организации защиты является защита
на уровне пользователей. Он подобен способам, используемым в большинстве сетевых
систем. Процесс задания защиты на уровне пользователей состоит из двух принципиальных
этапов:
- создание системы пользователей, объединенных в группы (Сервис > Защита
> Пользователи и группы);
- задание прав доступа различных пользователей и групп по отношению к объектам
базы данных (Сервис > Защита > Разрешения).

Рис. 7.36. Задание системы пользователей
Информация о системе пользователей сохраняется в специальном файле, называемом файлом рабочих групп. По умолчанию это файл System.mdw. Однако с помощью специальной программы, входящей в поставку Access, различные базы данных можно ассоциировать с различными файлами рабочих групп. При запуске Access от пользователей требуется идентифицировать себя и ввести пароль. Отдельные пользователи могут объединяться в группы, причем один и тот же пользователь может являться членом различных групп. Такая организация системы пользователей позволяет весьма гибко манипулировать набором их прав доступа, исходя из функциональной специфики предметной области. В файле рабочих групп Access по умолчанию создаются две группы: администраторы (группа Admins) и группа Users, в которую включаются все пользователи. Допускается также определение других групп. Процесс создания системы пользователей и определения их принадлежности к группам показан на рис. 7.36.
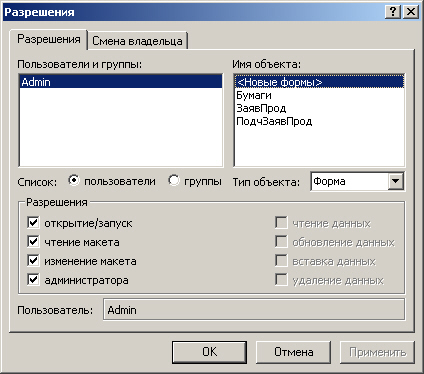
Рис. 7.37. Задание прав пользователей
Как группам, так и пользователям предоставляются разрешения на доступ, определяющие
допустимые для них действия по отношению к каждому объекту базы данных. Набор
возможных прав, очевидно, определяется спецификой объекта. Так, к примеру, список
градаций разрешений на работу с экранной формой показан на рис. 7.37.
По умолчанию члены группы Admins имеют все разрешения на доступ ко всем объектам
базы данных. Поскольку группа Users объединяет всех пользователей то ей имеет
смысл присваивать некоторый минимальный набор прав. Далее имеется возможность
установить более разветвленную структуру управления, создавая собственные учетные
записи групп, предоставляя этим группам соответствующие разрешения и добавляя
в них пользователей. Процесс задания прав доступа пользователей по работе с
формами базы данных TradeTest показан на рис. 7.37. Заканчивая разговор о системах
защиты, еще раз подчеркнем, что ее эффективная реализация возможна только на
основе подробного изучения функциональной структуры автоматизируемого объекта
и тщательного проектирования системы управления данными.
Ключевые понятия
- база данных;
- предметная область;
- ключ;
- запись, поле;
- модель данных;
- индекс (индексная таблица);
- модель данных;
- SQL;
- транзакция;
- DAO;
- ODBC;
- процессор баз данных Jet;
- клиент-сервер.
Контрольные вопросы
1. Что такое база данных и что такое СУБД? В чем различие этих понятий?
2. Дайте определения следующих понятий: объект, атрибут, запись, ключ.
3. Что такое модель данных? Какие модели вы знаете?
4. Основные свойства реляционной модели данных.
5. Что такое нормальные формы?
6. Назовите основные группы инструкций языка SQL.
7. Для чего служит инструкция SELECT?
8. Какие классы СУБД вы можете назвать? В чем их принципиальные различия?
9. Опишите основные этапы создания базы данных в среде MS Access.
10. Для чего служит схема данных MS Access?
11. Какие способы создания форм и отчетов в Access вы можете привести?
12. В чем основное различие функций макросов и модулей в Access?
13. Опишите основные принципы организации программирования доступа к данным
в Access.14;
14. Какие основные методы доступа к внешним данным из СУБД Access вы можете
назвать?
15. Для чего служит технология ODBC?
16. Опишите принципиальную схему организации доступа к данным в Access.
17. Какие принципиальные решения заложены в основу технологии клиент-сервер?
18. Перечислите основные этапы развития технологии клиент-сервер.
19. Какие основные методы защиты данных в Access вы можете назвать?
Литература
1. Бекаревич Ю. Б., Пушкина Н. В., Смирнова Е. Ю. Управление базами данных.
СПб.: Изд. СПбГУ, 1999.
2. Горев А., Ахаян Р., Макашарипов С. Эффективная работа с СУБД. СПб.: Питер,
1997.
3. Корнелюк В. К., Веккер 3. Е., Зиновьев Н. Б. Access 97. М.: СОЛОН, 1998.
4. Ramakrishnan R. Database management systems. McGraw-Hill, 1997.
Понятие же "физического вакуума" в релятивистской квантовой теории поля подразумевает, что во-первых, он не имеет физической природы, в нем лишь виртуальные частицы у которых нет физической системы отсчета, это "фантомы", во-вторых, "физический вакуум" - это наинизшее состояние поля, "нуль-точка", что противоречит реальным фактам, так как, на самом деле, вся энергия материи содержится в эфире и нет иной энергии и иного носителя полей и вещества кроме самого эфира.
В отличие от лукавого понятия "физический вакуум", как бы совместимого с релятивизмом, понятие "эфир" подразумевает наличие базового уровня всей физической материи, имеющего как собственную систему отсчета (обнаруживаемую экспериментально, например, через фоновое космичекое излучение, - тепловое излучение самого эфира), так и являющимся носителем 100% энергии вселенной, а не "нуль-точкой" или "остаточными", "нулевыми колебаниями пространства". Подробнее читайте в FAQ по эфирной физике.
|
|
