
Доклад был представлен Алексеем Воропаевым, руководителем группы ранжирования Поиска Mail.ru, на Четвертом Форуме Технологий Mail.Ru Group, который прошел 17 октября 2012 года в московском выставочном центре ИнфоПространство и был посвящен теме веб-технологий.
Так исторически сложилось, что большинство систем, которые разрабатываются крупными интернет-компаниями, в той или иной степени используют машинное обучение. И в связи с этим возникает одна интересная проблема: большинству людей об этом известно, но известно ровно столько, сколько содержит в себе высказывание Джона Хеннесси (John Hennessy), президента Стэнфордского университета – «Машинное обучение – это новая популярная тема». О том, что это какая-то новая популярная тема – известно практически всем, а больше никто о ней ничего не знает.
Прежде, чем говорить о том, что такое машинное обучение (без каких-то деталей, без страшных математических формул), прежде, чем говорить об алгоритмах, нужно понять, зачем это нужно. Зачем нам нужно машинное обучение?
По большому счету, задачей любого разработчика, независимо от того, чем он занимается, является передача некоторых знаний, который находятся у него в голове, компьютеру. То есть, эти знания нужно как-то абстрагировать и формализовывать.
Когда эти знания находятся в голове разработчика, тогда никаких проблем – он садится и пишет код. Но бывает, что эти знания находятся в голове другого человека. И этот человек может объяснить разработчику, что у него в голове, а может и не рассказать всего, что знает. Ярким примером является создание поисковой формулы ранжирования.
Все знают, что существуют асессоры, люди, которые могут оценить, насколько хорош или релевантен документ, но они не могут объяснить, как они это делают. Поэтому в поиске так важна роль машинного обучения. Что же это такое?
Есть очень много всяких разных определений машинного обучения. Большинство из них звучат, как масло масляное, вроде: «машинное обучение – это машины, которые способны обучаться». Однако лучшим определением машинного обучения является это: «Построение абстракций по множеству наблюдений». Это и есть как раз та бизнес-логика, которая лежит в голове у человека. Какие абстракции? Это все очень зависит о того, что конкретно разрабатывается. И в общем случае абстракций примерно столько же, сколько и в изобразительном искусстве:
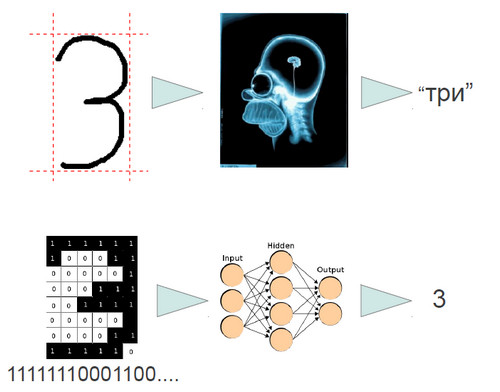
Первая абстракция, с которой можно начать – это абстракция черного ящика. Ярким примером такой абстракции является голова Гомера Симпсона. То есть, эта голова может посмотреть на картинку и сказать, что на ней изображена цифра три. Но при этом никто, даже самый крутой ученый в мире не сможет до конца объяснить, как Гомер это делает. Поэтому голова Гомера становится черным ящиком, ибо известно только, что приходит на вход и что приходит на выход.
Допустим, нужно создать некоторую модель компьютера, которая распознает эти буквы и взламывает капчи. Что нужно для этого сделать? Нужно оцифровать входные данные. В случае с изображениями это сделать достаточно легко - просто разным цветам нужно назначить разные числа и записать этот объект в виде длинного вектора. Получится некоторое векторное представление этого объекта:
Какие у этого векторного представления должны быть свойства? Во-первых, каждый элемент вектора должен помогать решать поставленную задачу. Во-вторых, векторное описание, с которым ведется работа, должно быть семантически идентичным. Это значит, что один и тот же элемент вектора должен обозначать одно и то же для всех объектов. Во-третьих, это означает, что этот вектор должен быть, как минимум одной длины, поэтому картинку надо смаштабировать до какого-то конкретного размера.
После этого можно взять Гомера, дать ему много картинок, и он будет говорить, что и на какой картинке изображено. Это и будет то самое обучающее множество, на основании которого и строится некая цифровая модель, в которой, передавая подобные оцифрованные картинки, будет получен результат – цифра три. Классическая задача распознавания изображения, распознавания букв.
Как это работает? Какие есть алгоритмы? Первый алгоритм, с которого нужно начать – наиболее известный на сегодняшний день и самый старый. Родился этот алгоритм из изучения биологии и называется он нейронные сети. Это на самом деле целый класс алгоритмов.
Нейронная сеть есть внутри каждого из нас. Это наш мозг. И эта нейронная сеть делает нас людьми. Базовым элементом нейронной сети является нейрон. У нейрона есть входы. На вход подается некоторый сигнал, какая-то цифра. И этот сигнал либо усиливается, либо ослабевает при помощи синапса:
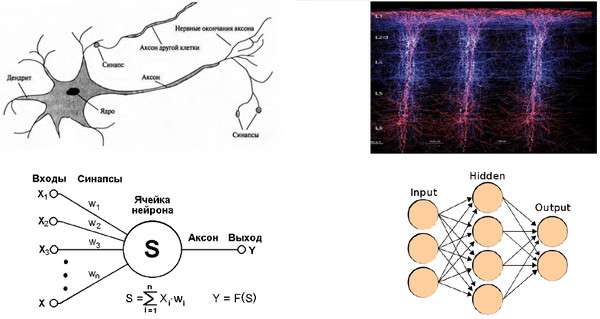
К этому сводится вся суть обучения. Настраивая синапсы, можно обучить сеть тем или иным знаниям. Память – это то место, где вся эта штука программируется. Дальше все взвешенные сигналы суммируются и подаются на выход этого нейрона. Простейшая операция. Понятное дело, что один нейрон - в поле не воин, и много при помощи него не сделаешь. Поэтому нейроны и группируются в сеть.
Сеть, в свою очередь, состоит из слоев. В каждом слое нейроны друг с другом не взаимодействуют, они полностью независимы. Но зато каждый нейрон каждого слоя принимает сигнал от всех абсолютно нейронов предыдущего слоя и передает этот сигнал всем из следующего слоя. Вот такое незатейливое взаимодействие позволяет решать достаточно сложные задачи, причем ключевым элементом здесь является количество связей. А количество слоев – это некоторый вспомогательный механизм, в реальных предложениях их обычно не больше трех.
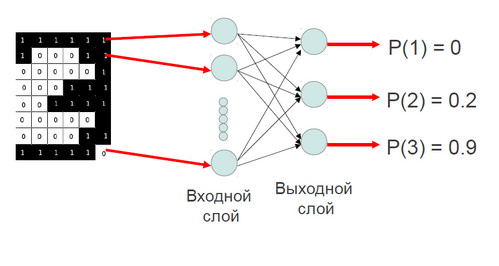
Как это работает? Вернемся к старой задаче – распознать изображение, смоделировать Симпсона. Есть оцифрованная картинка, и есть первый слой нейронной сети. Задача первого слоя – перераспределение информации на следующий слой, без какой-либо обработки. Соответственно, каждый входной нейрон соответствует какому-то пикселю на изображении. Очевидно, что количество нейронов в нашем случае равно количеству элементов в векторе.
Что делает каждый нейрон? Он перераспределяет эту информацию на нейроны выходного слоя. Количество нейронов выходного слоя равно количеству нейронов, которые желательно, чтобы сеть научилась распознавать. Пусть в нашем случае сеть будет распознавать картинки от 1 до 3. Так делают все нейроны входного слоя, и получается такая связь: все нейроны со всеми. После того, как информация приходит в нейрон выходного слоя, она там суммируется, и на выходе этого нейрона мы получаем некоторую вероятность того, что картинка принадлежит к данному классу картинок. Первый нейрон отвечает за распознавание цифры «один», второй нейрон за распознавание цифры «два» и так далее.
В чем суть обучения? У каждого выходного слоя нейронов есть набор синапсов, причем каждый синапс соответствует пикселю на входном изображении. В принципе, можно визуализировать эти синапсы и тогда получится следующая картина:
Для тех пикселей, которые характерны для данного изображения, для цифры три – там будут положительные значения. Те синапсы, которые не соответствуют пикселям изображения, например, пиксели слева, обычно у цирф «три» они выключены – там будут отрицательные изображения. И появление какого-то сигнала будет говорить о том, что это не цифра три. Ну, и соответственно, какие-то пиксели, которые не характерны для всех объектов будут иметь нулевые значения. Обучение производится очень просто – берется входное значение, и к тем нейронам, которые угадали, какая там была цифра, прибавляется это изображение, а те нейроны, которые не угадали изображение, вычитаются. Получается такой итеративный процесс, который повторяется несколько раз и, в конце концов, сеть начинает это неплохо распознавать.
Следующий алгоритм, о котором хочется рассказать, называется деревья принятия решений. Он приобретает все большую популярность в настоящее время. Объяснить его проще всего на примере очень важной для поискового ранжирования задачи - разбиения текста на предложения.
Допустим, есть некоторый текст. В этом тексте есть некоторый потенциальный делитель - точка. Это очень важно, потому что это помогает строить хорошие сниппеты. Но реальный интернет очень далек от литературного русского языка. Есть очень много кейсов, когда точка не является точкой. Поэтому нужно проанализировать контекст, который находится около этой точки. То есть, при помощи лингвистов пишется какой-то анализатор, который начинает проверять простые правила. Например, он смотрит, есть ли там пробел справа. Это говорит о том, что это, скорее всего конец предложения. Также проверяется, есть ли большая буква справа.
Этих двух правил точно недостаточно, так как есть, например, инициалы людей, и там такая же ситуация, когда точка, пробел и большая буква потом. И вот таких правил на текущий момент около 40. Проблема в том, как эти правила скомбинировать между собой, и как произвести финальную оценку. Здесь также применяется машинное обучение, а в частности - деревья принятия решений.
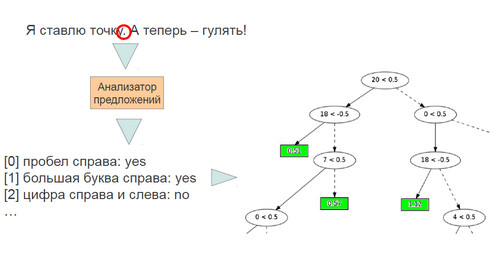
Дерево принятия решений – это обычное бинарное дерево. В этом дереве находится условие, которое проверяет, сработал или не сработал признак. Признаки кодируются при помощи нуля и единицы. Если признак 20 не сработал – нужно идти налево, если сработал –направо. После того, как выбрано лево или право, там может быть проверка какого-то нового условия. И получаются такие достаточно длинные цепочки условий, либо лист дерева, а в листе дерева уже записывается, что это вероятность того, что это конец предложения.
Но тут возникает проблема – у дерева ограниченное количество листов. И в результате, если используется только одно дерево, получается такая грубая ступенчатая функция, дающая совершенно недостаточное качество. Как можно это преодолеть?
Первый способ – увеличивать глубину дерева. В этом случае цепочки дерева становятся все длиннее и длиннее. А есть математическая теорема, которая говорит, что в любом конечном наборе данных, коим является наше обучающее множество, всегда можно найти какую-нибудь закономерность. И дерево его успешно находит, и этот процесс называется переобучение. В итоге, по мере того, как дерево растет - и качество возрастает, но потом оно начинает деградировать и останавливается на каком-то недостаточном для решения задачи уровне.
Второй способ, при помощи которого можно увеличивать качество – называется бустинг. Идея бустинга заключается в том, что строится первое дерево, и для всех элементов обучающего множества вычисляется ошибка. После этого строится следующее дерево, только его задача уже не предсказывать концы предложений, а указывать на ошибку предыдущего дерева. И вот так, по цепочке, строится несколько десятков, а иногда и сотен деревьев. И получается достаточно гладкое решение.
Следующий алгоритм, также заслуживающий рассмотрения, называется наивный Байес. Томас Байес (Thomas Bayes) – это был такой священник в 18 веке, поставивший целью своей жизни доказать существование Бога при помощи математики. Существование Бога он не доказал, зато придумал вот такую теорему Байеса:
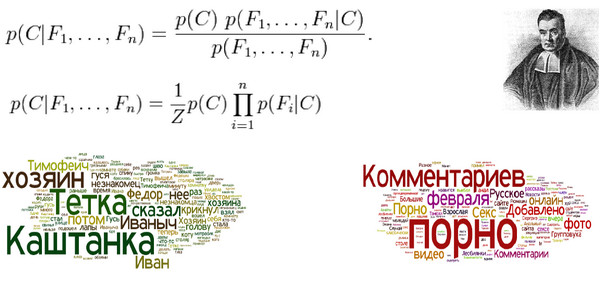
Предположим, что есть некоторый объект. У этого объекта есть некоторые признаки, обозначенные буквой F. Нужно выяснить, какова вероятность принадлежности этого объекта к некоторому классу, который обозначен буквой C.
О чем говорит эта теорема? Вероятность того, что этот объект принадлежит классу С, при заданном наборе свойств F, - фактически равна вероятности встретить такой набор свойств F в некотором классе С.
На первый взгляд все кажется очень просто. Берется обучающее множество, считается частота какого-то набора признаков в этом обучающем множестве и получается классификация. Но если этих признаков много, то вероятность того, что встретится хоть какая-то повторяемость набора, или сам конкретный набор, в это обучающем множестве – стремится к нулю. И тут делается предположение - из-за этого алгоритм и получил свое название – что все эти свойства независимы.
Так, для классификации текста предполагается, что каждое слово встречается независимо от других слов. Это наивное предположение, потому что на самом деле это не так. Но зато, это позволяет сделать один хитрый математический трюк. А именно - эта вероятность попросту равна произведению вероятности встретить каждое слово в этом конкретном наборе. Т.е. просто для каждого слова высчитывается, сколько раз оно встречалось в том или ином наборе, а затем это высчитывается и для нового документа, который приходит на анализ.
Алгоритм работает, но недостаточно хорошо. Для его улучшения используется технология Deep learning. Берется вероятность, которая не очень хорошо работает, к ней добавляются какие-то признаки и отгружаются в дерево. Результат получается замечательный. Детектор порнографии в поиске Mail.ru вполне сравним с детектором порнографии других ведущих поисковиков.
Допустим, есть какой-то сервис и у этого сервиса есть пользователи, и нужно узнать, кто эти пользователи. Для этого берутся логи и с них считываются какие-то характеристики, например, на какие странички пользователь заходил, сколько переходов сделал, как часто и куда возвращался. Получатся некоторые характеристики.
Допустим, таким способом были определены две характеристики, которые описывают пользователя. Согласно этим характеристикам, пользователи разделились на две группы: одна группа – это нормальные люди, а другая группа – наглые спамеры, которые портят всем жизнь. Основываясь на данных о второй группе пользователей, можно сделать антиспам. Это к тому, что могут дать две характеристики, а в реальности их бывает на порядок больше.
Эта задача решается при помощи алгоритмов кластеризации, который можно рассмотреть на примере алгоритма К-means.
Первое что нужно сделать – это предположить, что в данных будет три вида пользователей. Для каждого вида пользователей определяется какой-то среднестатистический пользователь, путем сравнения с которым все остальные пользователи разделяются на соответствующие группы. Так начинается процесс улучшения – кластеризация.
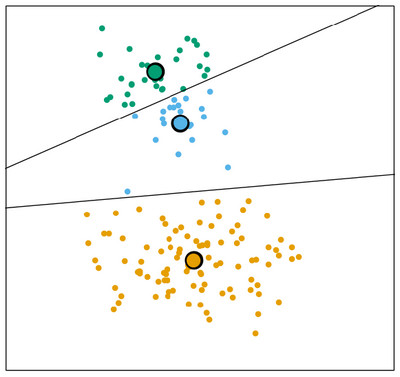
Но есть одна проблема. Мы предположили, что есть три вида пользователей, а их по факту два. И вот эти два кластера, два спамера – они описывают одну и ту же группу. И это не есть хорошо, потому что на практике все эти кластера – это какие-то наборы цифр. И тут начинается следующая веселая задача – кластеризуй результаты кластеризации. Это большая проблема и для борьбы с ней в поиске используется алгоритм, который называется самоорганизующиеся карты Кохонена.
Этот алгоритм также работает с модельными пользователями, но только уже берет их не случайно. А прежде чем начать кластеризацию, пользователи уже организованы в некоторую сетку, и для каждого кластера назначено, кто будет его соседом. А дальше берется некоторый кластер и сдвигается к центру объектов. Отличие в том, что туда также подтягиваются и назначенные соседи, то есть, двигаются уже не один, а несколько центроидов:
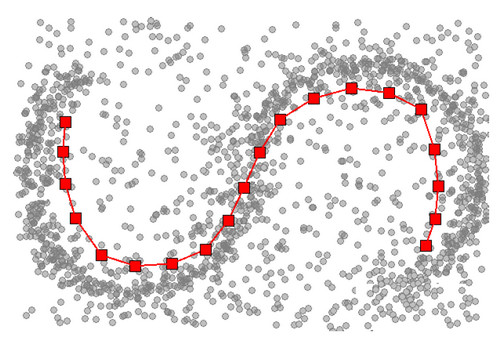
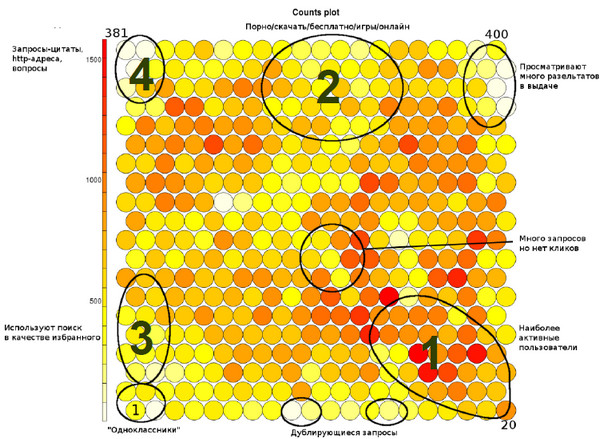
Этот алгоритм используется, например, в исследовании пользователей поиска. Так, были собраны определенные характеристики на какое-то количество пользователей (на рисунке каждый кругляшок – это кластер, они объединены в двухмерную сетку, а цвет кругляшка показывает количество людей, которое туда попало).
В нижнем правом углу скопились обычные, нормальные пользователи gomail.ru (1). Другая группа была условно названа «любители порнографии», потому что в их запросах есть какие-то порнографические слова (2). Третий вид пользователей условно зовутся «Одноклассники» - те люди, которые пользуются поиском Mail.ru, как закладкой (3). Они просто заходят в поиск, выбирают Одноклассники и проваливаются туда или на какие-то другие свои любимые сайты. Это тоже не совсем нормальные пользователи, они используют поиск по одному какому-то своему целевому назначению и, наверное, для них этот поиск нужно делать как-то особенно. Ну, и четвертый класс – это самые натуральные SEO-роботы, задача которых просматривать, где и какие сайты на каких позициях находятся (4). Вот такая своеобразная карта:
Ранжирование Поиска Mail.ru строится при помощи машинного обучения. Для этого есть специальные люди, которым даются пары «запрос-документ», они их размечают и говорят, какие из них хорошие, какие плохие. На текущий момент, подобных пар скопилось уже больше миллиона, то есть, есть очень и очень большой массив данных, которые просто нереально просмотреть.
Достаточно сложно спроецировать 1600мерное пространство на двухмерную плоскость. Но это возможно. На слайде изображена сетка, состоящая из клеточек, кластеров. Цвета этих кластеров говорят об оценке тех документов, которые туда попали.
Розовый цвет говорит о том, что это документы, которые хорошо соответствуют запросу.
Синий цвет говорит о плохих документах, которые совершенно не соответствуют запросу.
Среди хороших документов есть еще и желтые документы, что означает не очень хорошие.
Для поиска желтый цвет - это аномалия. Для пользователей поиска этот квадратик – это совершенно нерелевантная выдача по запросу. При ближайшем рассмотрении стало ясно, что это совершенно нормальные документы, просто попавшие в соседние кластера, и поэтому находящиеся рядом и в пространстве. На самом деле здесь имеет место быть ошибка асессоров. Асессоры - это тоже люди, которые делают ошибки. Асессить – очень монотонная работа, люди на ней устают и делают ошибки. Документы были отправлены на переоценку, и с релевантностью все стало значительно лучше, цвет квадратика изменился:
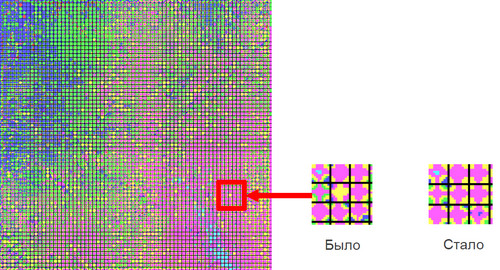
Таким образом можно достаточно дешево находить большое количество ошибок, исправлять их и делать поиск лучше.
Последний алгоритм, о котором обязательно нужно рассказать в связи с машинным обучением, называется «Apriory» и предназначен он для поиска ассоциативных правил.
Что такое ассоциативные правила? Наверняка всем известно, что такое рекомендательная система, например, в некотором магазине. В магазин приходят люди, делают покупки и соответственно, каждая строчка – это чек. Первый пользователь купил товары - a, b, c, второй - b, d и так далее. Нужно понять, какие товары покупаются вместе, чтобы можно было ставить их рядом друг с другом и рекомендовать.
Можно было бы скомбинировать все возможные комбинации, сгруппировать их, а потом выбрать самую высокочастотную и получить свой профит. Но в реальном магазине это нереально сделать, потому что слишком много процессорного времени понадобится. Можно делать гораздо проще. Все покупаемые товары вносятся в таблицу, где становится понятно, какие из них покупаются редко – они отбрасываются. Оставшиеся тоже сравниваются и отбираются те, что покупаются наиболее часто в паре с другим товаром. Получаются уже пары товаров. Для этих пар опять вычисляется, сколько раз они встречаются… Такая процедура повторяется столько раз, сколько нужно, пока не будут получены товары a, b, c.
Вот именно таким незамысловатым образом, однажды в недалекой Америке, в незамысловатом магазине, люди поняли, что вместе с подгузниками в пятницу вечером очень хорошо идет дорогое пиво. Поставили рядом с подгузниками пивной ларек, и продажи пошли в гору. Простейшее объяснение - отцы возвращаются после трудовой недели, берут памперсы для ребенка и пиво для себя.
Все, что было рассказано про алгоритмы покрывает 90% кейсов, которые бывают на эту тему. Наверняка у многих возникает вопрос – все очень сложно, не хочется ничего программировать, наверное, что-то готовое уже есть? Конечно, есть. Есть такая замечательная программа, которая называется WEKA.
WEKA написана на Java, запускается везде, и представляет собой графическую IDE для создания машинного обучения. Можно взять свои данные, которые могут быть в любом формате, нажать кнопку «Загрузить», нажать «Вот такой алгоритм хочу», ползунком отрегулировать нужные параметры, и все – модель готова. Не нужна никакая математика, не нужно никакое программирование. Можно ее модернизировать. Единственный недостаток – она работает на одном компьютере, и очень много данных в нее не запихаешь. Для решения этой проблемы есть замечательная программка Mahout. Она позволяет строить машинное обучение на кластере.
Вопрос из зала: Сейчас у крупных поисковиков появился поиск изображения по содержанию. То есть, есть какое-то изображение, и он ищет такое же. У вас будет такое или нет? Google сейчас сделал обучение без учителя. И как будут запрещать поиск по фотографиям, если они будут содержать порнографию?
Алексей Воропаев: На первый вопрос могу сказать, что обязательно будет в светлом будущем, но когда - сказать не могу. Как с этим связано машинное обучение? Обучение без учителя – это и есть кластеризация, про которую я говорил. И весь вопрос сводится к тому, какие факторы вы найдете. А фильтрация порнографии – это вечная тема. Есть способ, как ее решают в картинках, но это долго рассказывать.
Вопрос из зала: Какова роль оптимизации? Вы какие-то новые методы используете? Потому что они могут повысить качество вашей поисковой системы.
Алексей Воропаев: Используем ли мы какие-то крутые алгоритмы? Несомненно, используем. Многое мы использовали в WEKA. Например, формулу ранжирования в WEKA не построишь. Там на кластере из многих десятков машин, алгоритмы, которые строят наши деревья, работают часами. И мы используем свои какие-то алгоритмы для решения своих специфических задач. Если говорить кратко, то это не самое главное в машинном обучении. Самое главное – это факторы и обучающее множество, то, как оно построено.
Вопрос из зала: В Google, когда я пишу какой-то запрос, он потом мне еще в течение месяца выводит рекламу по этому запросу. Как вы этот вопрос решали? Как находили баланс между вынесением рекламы и адаптацией погрешности?
Алексей Воропаев: Google рассчитывает некоторые факторы, основанные на вашем поведении. Эти факторы для модели, которая решает показывать или не показывать вам рекламу, имеют какую-то силу, и до тех пор, пока этот ваш фактор не наберет конкретную силу, они продолжают показывать. Соответсвенно, этот порог срабатывания зависит от того, как они строят эту модель.
Вопрос из зала: Сколько у вас признаков ранжирования документов? Сколько деревьев и какой размер дерева?
Алексей Воропаев: У нас больше 1600 признаков на текущий момент: хороших, плохих, работающих, сломанных. Обучающее множество – это более миллиона документов. Количество деревьев измеряется несколькими тысячами.
Вопрос из зала:Не пробовали ли вы использовать WEKA для локального обучения? Как вы реализовали свой градиентный бустинг?
Алексей Воропаев: Большинство машинных результатов, большинство моделей, которые мы строили при помощи WEKA, при помощи чего-то другого, оно работает на кластере. И отвечая на второй вопрос, я не буду рассказывать о том, как устроен наш бустинг, потому что это немножко секрет.
Дело в том, что в его постановке и выводах произведена подмена, аналогичная подмене в школьной шуточной задачке на сообразительность, в которой спрашивается:
- Cколько яблок на березе, если на одной ветке их 5, на другой ветке - 10 и так далее
При этом внимание учеников намеренно отвлекается от того основополагающего факта, что на березе яблоки не растут, в принципе.
В эксперименте Майкельсона ставится вопрос о движении эфира относительно покоящегося в лабораторной системе интерферометра. Однако, если мы ищем эфир, как базовую материю, из которой состоит всё вещество интерферометра, лаборатории, да и Земли в целом, то, естественно, эфир тоже будет неподвижен, так как земное вещество есть всего навсего определенным образом структурированный эфир, и никак не может двигаться относительно самого себя.
Удивительно, что этот цирковой трюк овладел на 120 лет умами физиков на полном серьезе, хотя его прототипы есть в сказках-небылицах всех народов всех времен, включая барона Мюнхаузена, вытащившего себя за волосы из болота, и призванных показать детям возможные жульничества и тем защитить их во взрослой жизни. Подробнее читайте в FAQ по эфирной физике.
|
|
