Файловая
структура и система управления файлами являются прерогативой операционной среды,
поэтому принципы обмена данными подчиняются законам операционной системы. По
отношению к базам данных эти принципы могут быть далеки от оптимальности. СУБД
подчиняется несколько иным принципам и стратегиям управления внешней памятью,
чем те, которые поддерживают операционные среды для большинства пользовательских
процессов или задач.
Это и послужило
причиной того, что СУБД взяли на себя непосредственное управление внешней памятью.
При этом пространство внешней памяти предоставляется СУБД полностью для управления,
а операционная среда не получает непосредственного доступа к этому пространству.
Физическая
организация современных баз данных является наиболее закрытой, она определяется
как коммерческая тайна для большинства поставщиков коммерческих СУБД. И здесь
не существует никаких стандартов, поэтому в общем случае
каждый поставщик создает свою уникальную структуру и пытается обосновать ее
наилучшие качества по сравнению со своими конкурентами. Физическая организация
является в настоящий момент наиболее динамичной частью СУБД. Стремительно расширяются
возможность устройств внешней памяти, дешевеет оперативная память, увеличивается
ее объем и поэтому изменяются сами принципы организации физических структур
данных. И можно предположить, что и в дальнейшем эта часть современных СУБД
будет постоянно меняться. Поэтому при рассмотрении моделей данных, используемых
для физического хранения и обработки, мы коснемся только наиболее общих принципов
и тенденций.
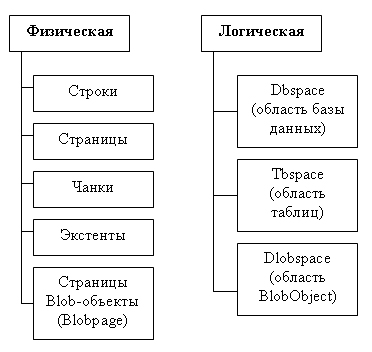
При распределении
дискового пространства рассматриваются две схемы структуризации: физическая,
которая определяет хранимые данные, и логическая, которая определяет некоторые
логические структуры, связанные с концептуальной моделью данных (рис. 9.12).
Рис.
9.12. Классификация объектов при статичной организации физической
модели данных
Определим
некоторые понятия, используемые в указанной классификации.
Чанк (chank)
— представляет собой часть диска, физическое пространство на диске, которое
ассоциировано одному процессу (on line процессу обработки данных).
Чанком может
быть назначено неструктурированное устройство, часть этого устройства, блочно-ориентированное
устройство или просто файл UNIX.
Чанк характеризуется
маршрутным именем, смещением (от физического начала устройства до начальной
точки на устройстве, которая используется как чанк), размером, заданным в Кбайтах
или Мбайтах.
При использовании
блочных устройств и файлов величина смещения считается равной нулю.
Логические
единицы образуются совокупностью экстентов, то есть таблица моделируется совокупностью
экстентов.
Экстент
— это непрерывная область дисковой памяти.
Для моделирования
каждой таблицы используется 2 типа экстентов: первый и последующие.
Первый экстент
задается при создании нового объекта типа таблица, его размер задается при создании.
EXTENTSIZE — размер первого экстента, NEXT SIZE — размер каждого следующего
экстента.
Минимальный
размер экстента в каждой системе свой, но в большинстве случаев он равен 4 страницам,
максимальный — 2 Гбайтам.
Новый экстент
создается после заполнения предыдущего и связывается с ним специальной ссылкой,
которая располагается на последней странице экстента. В ряде систем экстенты
называются сегментами, но фактически эти понятия эквиваленты.
При динамическом
заполнении БД данными применяется специальный механизм адаптивного определения
размера экстентов.
Внутри экстента
идет учет свободных станиц.
Между экстентами,
которые располагаются друг за другом без промежутков, производится своеобразная
операция конкатенации, которая просто увеличивает размер первого экстента.
Механизм
удвоения размера экстента: если число выделяемых экстентов для процесса
растет в пропорции, кратной 16, то размер экстента удваивается каждые 16 экстентов.
Например,
если размер текущего экстента 16 Кбайт, то после заполнения 16 экстентов данного
размера размер следующего будет увеличен до 32 Кбайт.
Совокупность
экстентов моделирует логическую единицу — таблицу-отношение (tblspace).
Экстенты
состоят из четырех типов страниц: страницы данных, страницы индексов, битовые
страницы и страницы blob-объектов. Blob — это сокращение Binary Larg Object,
и соответствует оно неструктурированным данным. В ранних СУБД такие данные относились
к типу Memo. В современных СУБД к этому типу относятся неструктурированные большие
текстовые данные, картинки, просто наборы машинных кодов. Для СУБД важно знать,
что этот объект надо хранить целиком, что размеры этих объектов от записи к
записи могут резко отличаться и этот размер в общем случае неограничен.
Основной
единицей осуществления операций обмена (ввода-вывода) является страница данных.
Все данные хранятся постранично. При табличном хранении данные на одной странице
являются однородными, то есть станица может хранить только данные или только
индексы.
Все страницы
данных имеют одинаковую структуру, представленную на рис. 9.13.
Слот —
это 4-байтовое слово, 2 байта соответствуют смещению строки на странице
и 2 байта — длина строки. Слоты характеризуют размещение строк данных на странице.
На одной странице хранится не более 255 строк. В базе данных каждая строка имеет
уникальный идентификатор в рамках всей базы данных, часто называемый RowID —
номер строки, он имеет размер 4 байта и состоит из номера страницы и номера
строки на странице. Под номер страницы отводится
3 байта,
поэтому при такой идентификации возможна адресация к 16 777 215 страницам.
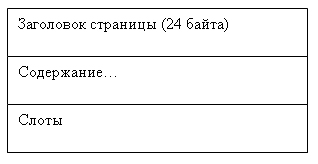
Рис.
9.13. Обобщенная структура страницы данных
При упорядочении
строк на страницах не происходит физического перемещения строк, все манипуляции
происходят со слотами.
При переполнении
страниц создается специальный вид страниц, называемых страницами остатка. Строки,
не уместившиеся на основной странице, связываются (линкуются) со своим продолжением
на страницах остатка с помощью ссылок-указателей «вперед» (то есть
на продолжение), которые содержат номер страницы и номер слота на странице.
Страницы
индексов организованы в виде В-деревьев. Страницы blob предназначены для хранения
слабоструктурнровашюй информации, содержащей тексты большого объема, графическую
информацию, двоичные коды. Эти данные рассматриваются как потоки байтов произвольного
размера, в страницах данных делаются ссылки на эти страницы.
Битовые страницы
служат для трассировки других типов страниц. В зависимости от трассируемых страниц
битовые страницы строятся по 2-битовой или 4-битовой схеме. 4-битовые страницы
служат для хранения сведений о столбцах типа Varchar, Byte, Text, для остальных
типов данных используются 2-битовые страницы.
Битовая структура
трассирует 32 страницы. Каждая битовая структура представлена двумя 4-байтными
словами. Каждая i-я позиция описывает одну i-ю страницу. Сочетание разрядов
в i-х позициях двух слов обозначает состояние данной страницы: ее тип и занятость.
При обработке
данных СУБД организует специальные структуры в оперативной памяти, называемые
разделяемой памятью, и специальные структуры во внешней памяти, называемые журналами
транзакций. Разделяемая память служит для кэширования данных при работе с внешней
памятью с целью сокращения времени доступа, кроме того, разделяемая память служит
для эффективной поддержки режимов одновременной параллельной работы пользователей
с базой данных.
Журнал транзакций
служит для управления корректным выполнением транзакций.
Однако тема параллельной обработки данных выходит за рамки данного раздела, и поэтому архитектура разделяемой памяти будет освещена в разделах, посвященных распределенной обработке данных.
|
|
