Индекс
-
структура данных, которая помогает СУБД быстрее обнаружить
отдельные записи в файле и сократить время выполнения запросов пользователей.
Индекс в базе данных аналогичен предметному указателю в книге. Это —
вспомогательная структура, связанная с файлом и предназначенная для поиска
информации по тому же принципу, что и в книге с предметным указателем. Индекс
позволяет избежать проведения последовательного или пошагового просмотра файла в
поисках нужных данных. При использовании индексов в базе данных искомым объектом
может быть одна или несколько записей файла. Как и предметный указатель книги,
индекс базы данных упорядочен, и каждый элемент индекса содержит название
искомого объекта, а также один или несколько указателей (идентификаторов
записей) на место его расположения.
Хотя индексы, строго говоря, не являются обязательным компонентом СУБД, они
могут существенным образом повысить ее производительность. Как и в случае с
предметным указателем книги, читатель может найти определение интересующего его
понятия, просмотрев всю книгу, но это потребует слишком много времени. А
предметный указатель, ключевые слова в котором расположены в алфавитном порядке,
позволяют сразу же перейти на нужную страницу.
Структура индекса связана с определенным ключом поиска и содержит записи,
состоящие из ключевого значения и адреса логической записи в файле, содержащей
это ключевое значение. Файл, содержащий логические записи, называется файлом
данных, а файл, содержащий индексные записи, — индексным файлом. Значения в
индексном файле упорядочены по полю индексирования, которое обычно строится на
базе одного атрибута.
Типы индексов
Для ускорения доступа к данным применяется несколько типов индексов.
Основные из них перечислены ниже.
Первичный индекс
-
это такой специальный массив-указатель порядка записей, когда файл данных последовательно упорядочивается по полю ключа упорядочения, а
на основе поля ключа упорядочения создается поле индексации, которое
гарантированно имеет уникальное значение в каждой записи.
Индекс кластеризации
-
это такой специальный массив-указатель порядка записей, когда
файл данных последовательно упорядочивается по неключевому полю, и на
основе этого неключевого поля формируется поле индексации, поэтому в файле
может быть несколько записей, соответствующих значению этого поля индексации.
Неключевое поле называется атрибутом кластеризации.
Вторичный индекс
-
это индекс, который определен на поле файла данных, отличном от поля, по
которому выполняется упорядочение.
Файл может иметь не больше одного первичного индекса или одного индекса
кластеризации, но дополнительно к ним может иметь несколько вторичных индексов.
Индекс может быть разреженным (sparse) или плотным (dense). Разреженный индекс
содержит индексные записи только для некоторых значений ключа поиска в данном
файле, а плотный индекс имеет индексные записи для всех значений ключа поиска в
данном файле. Ключ поиска для индекса может состоять из нескольких полей.
Индексно-последовательные файлы
Отсортированный файл данных с первичным индексом называется индексированным
последовательным файлом, или индексно-последовательным файлом. Эта структура
является компромиссом между файлами с полностью последовательной и полностью
произвольной организацией. В таком файле записи могут обрабатываться как
последовательно, так и выборочно, с произвольным доступом, осуществляемым на
основу поиска по заданному значению ключа с использованием индекса.
Индексированный последовательный файл имеет более универсальную структуру,
которая обычно включает следующие компоненты:
первичная область хранения;
отдельный индекс или несколько индексов;
область переполнения.
Обычно большая часть первичного индекса может храниться в оперативной памяти,
что позволяет обрабатывать его намного быстрее. Для ускорения поиска могут
применяться специальные методы доступа, например метод бинарного поиска.
Основным недостатком использования первичного индекса (как и при работе с любым
другим отсортированным файлом) является необходимость соблюдения
последовательности сортировки при вставке и удалении записей. Эти проблемы
усложняются тем, что требуется поддерживать порядок сортировки как в файле
данных, так и в индексном файле. В подобном случае может использоваться метод,
заключающийся в применении области переполнения и цепочки связанных указателей,
аналогично методу, используемому для разрешения конфликтов в хэшированных
файлах.
Вторичные индексы
Вторичный индекс также является упорядоченным файлом, аналогичным первичному
индексу. Однако связанный с первичным индексом файл данных всегда отсортирован
по ключу этого индекса, тогда как файл данных, связанный со вторичным индексом,
не обязательно должен быть отсортирован по ключу индексации. Кроме того, ключ
вторичного индекса может содержать повторяющиеся значения, что не допускается
для значений ключа первичного индекса. Для работы с такими повторяющимися
значениями ключа вторичного индекса обычно используются перечисленные ниже
методы.
Создание плотного вторичного индекса, который соответствует всем записям
файла данных, но при этом в нем допускается наличие дубликатов.
Создание вторичного индекса со значениями для всех уникальных значений
ключа. При этом указатели блоков являются многозначными, поскольку каждое его
значение соответствует одному из дубликатов ключа в файле данных.
Создание вторичного индекса со значениями для всех уникальных значений
ключа. Но при этом указатели блоков указывают не на файл данных, а на сегмент,
который содержит указатели на соответствующие записи файла данных.
Вторичные индексы повышают производительность обработки запросов, в которых
для поиска используются атрибуты, отличные от атрибута первичного ключа. Однако
такое повышение производительности запросов требует дополнительной обработки,
связанной с сопровождением индексов при обновлении информации в базе данных. Эта
задача решается на этапе физического проектирования базы данных.
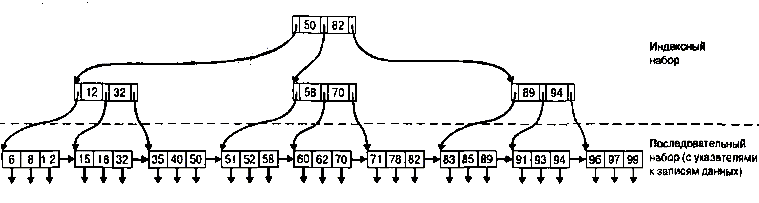
Многоуровневые индексы
При возрастании размера индексного файла и расширении его содержимого на
большое количество страниц время поиска нужного индекса также значительно
возрастает. Обратившись к многоуровневому индексу, можно попробовать решить эту
проблему путем сокращения диапазона поиска. Данная операция выполняется над
индексом аналогично тому, как это делается в случае файлов другого типа, т.е.
посредством расщепления индекса на несколько субиндексов меньшего размера и
создания индекса для этих субиндексов. На каждой странице файла данных могут
храниться две записи. Кроме того, в качестве иллюстрации здесь показано, что на
каждой странице индекса также хранятся две индексные записи, но на практике на
каждой такой странице может храниться намного больше индексных записей. Каждая
индексная запись содержит значение ключа доступа и адрес страницы. Хранимое
значение ключа доступа является наибольшим на адресуемой странице.
Дерево
-
это структура данных, используемая во многих СУБД для хранения данных
или индексов. Дерево состоит из иерархии узлов (node), в которой
каждый узел, за исключением корня (root), имеет родительский (parent) узел, а
также один, несколько или ни одного дочернего (child) узла. Корень не имеет
родительского узла. Узел, который не имеет дочерних узлов, называется листом
(leaf).
Глубина дерева
-
это максимальное количество уровней между корнем и
листом. Глубина дерева может быть различной для разных путей доступа к листам.
Сбалансированное дерево, В-дерево, В-Тгее
-
это дерево, у которого глубина дерева одинакова для всех листов.
Степень (degree), порядок (order) дерева
-
это максимально допустимое количество дочерних узлов для каждого
родительского узла. Большие степени обычно используются для создания более
широких и менее глубоких деревьев.
Поскольку время доступа в древовидной
структуре зависит от глубины, а не от ширины, обычно принято использовать более
"разветвленные" и менее глубокие деревья.
Бинарное дерево, binary tree
-
это дерево порядка 2, в котором каждый узел имеет не больше двух дочерних
узлов.
Усовершенствованные сбалансированные древовидные индексы определяются по
следующим правилам.
Если корень не является лист-узлом, то он должен иметь, по крайней мере,
два дочерних узла.
В дереве порядка n каждый узел (за исключением корня и листов) должен
иметь от n/2 до n указателей и дочерних узлов. Если число n/2 не является
целым, то оно округляется до ближайшего большего целого.
В дереве порядка n количество значений ключа в листе должно находиться в
пределах от (n-1)/2 до (n-1). Если число (n-1)/2 не является целым, то оно
округляется до ближайшего большего целого.
Количество значений ключа в нелистовом узле на единицу меньше количества
указателей.
Дерево всегда должно быть сбалансированным, т.е. все пути от корня к
каждому листу должны иметь одинаковую глубину.
Листы дерева связаны в порядке возрастания значений ключа.
Знаете ли Вы, что релятивизм (СТО и ОТО) не является истинной наукой? - Истинная наука обязательно опирается на причинность и законы природы, данные нам в физических явлениях (фактах). В отличие от этого СТО и ОТО построены на аксиоматических постулатах, то есть принципиально недоказуемых догматах, в которые обязаны верить последователи этих учений. То есть релятивизм есть форма религии, культа, раздуваемого политической машиной мифического авторитета Эйнштейна и верных его последователей, возводимых в ранг святых от релятивистской физики. Подробнее читайте в FAQ по эфирной физике.