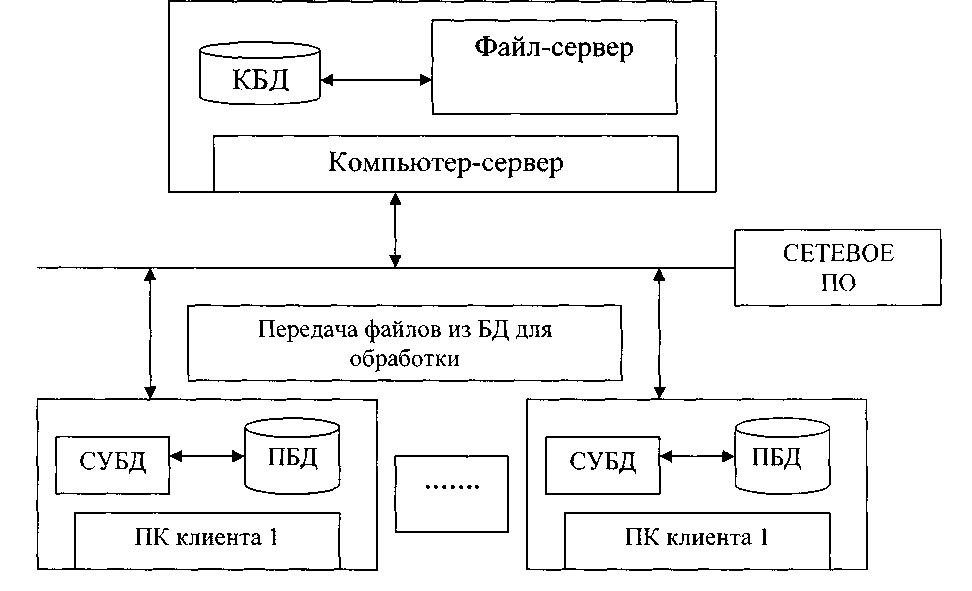
Самой простой архитектурой для реализации является архитектура "файл-сервер" (рисунок 1), но она же обладает и самым большим количеством недостатков, ограничивающих спектр решаемых ею задач. Простейшим случаем является случай, когда данные располагаются физически на том же компьютере, что и само приложение.
Рисунок 1 Структура информационной системы с файл-сервером
К существенным неудобствам, возникающим при работе с системой, построенной по такой архитектуре, можно отнести следующее:
- трудности при обеспечении непротиворечивости и целостности данных;
- существенная загрузка локальной сети передаваемыми данными;
- в целом, невысокая скорость обработки и представления информации;
- высокие требования к ресурсам компьютеров. При этом возникают следующие ограничения.
- невозможность организации равноправного одновременного доступа; пользователей к одному и тому же участку базы данных;
- количество одновременно работающих с системой пользователей не превышает пяти человек для ЛВС, построенной в соответствии со спецификацией 10BaseT (скорость обмена данными до 10Мб/с);
При всем этом система обладает одним очень важным преимуществом - низкой стоимостью.
Архитектура "файл-сервер" предусматривает концентрацию обработки на рабочих станциях. Основным преимуществом этого варианта является простота и относительная дешевизна. Подобное решение приемлемо, пока число пользователей, одновременно работающих с базой данных, не превышает 5-10 человек. При увеличении количества пользователей система может "захлебнуться" из-за перегруженности ЛВС большими потоками необработанной информации.
Сервер, как правило, — самый мощный и самый надежный компьютер. Он обязательно подключается через источник бесперебойного питания, в нем предусматриваются системы двойного или даже тройного дублирования. В особо ответственных случаях можно подключить вместе несколько серверов так, что при выходе из строя одного из них в работу автоматически включится "дублер". Таким образом, при концентрации обработки данных на сервере надежность системы в целом ограничивается только материальными средствами, которые заказчики готовы вложить в техническое оснащение.
Решение по автоматизации учета и управления в корпоративных структурах предполагает распределенную обработку данных, организацию параллельных вычислений, глубокое разграничение уровней доступа, возможность выбора различных операционных систем и серверных платформ. Если бизнес не велик, подобное решение оптимально.
В ходе эксплуатации были выявлены общие недостатки файл-серверного подхода при обеспечении многопользовательского доступа к базе данных.
Вся тяжесть вычислительной нагрузки при доступе к базе данных ложится на приложение клиента, что является следствием принципа обработки информации в системах "файл-сервер": при выдаче запроса на выборку информации из таблицы вся таблица базы данных копируется на клиентское место, и выборка осуществляется на клиентском месте. Локальные СУБД используют так называемый "навигационный подход", ориентированный на работу с отдельными записями.
Не оптимально расходуются ресурсы клиентского компьютера и сети; например, если в результате запроса мы должны получить 2 записи из таблицы объемом 10000 записей, все 10000 записей будут скопированы с файл-сервера на клиентский компьютер; в результате возрастает сетевой трафик и увеличиваются требования к аппаратным мощностям пользовательского компьютера.
В базе данных на файл-сервере гораздо проще вносить изменения в отдельные таблицы, минуя приложения. Эта возможность облегчается тем обстоятельством, что у локальных СУБД база данных — понятие более логическое, чем физическое, поскольку под базой данных понимается набор отдельных таблиц, сосуществующих в едином каталоге на диске. Все это позволяет говорить о низком уровне безопасности - как с точки зрения хищения и нанесения вреда, так и с точки зрения внесения ошибочных изменений.
Недостаточно развитый аппарат транзакций для локальных СУБД служит потенциальным источником ошибок как с точки зрения одновременного внесения изменений в одну и ту же запись, так и с точки зрения отката результатов серий объединенных по смыслу в единое целое операций над базой, когда некоторые из них завершились неуспешно, а некоторые - нет; это может нарушать ссылочную и смысловую целостность базы данных.
Недостатки настольных СУБД обычно проявляются не сразу, а лишь в процессе длительной эксплуатации, когда объем хранимых данных и число пользователей становятся достаточно велики - это приводит к снижению производительности приложений, использующих такие СУБД.
Поскольку настольные СУБД не содержат специальных приложений и сервисов, управляющих данными, а используются для этой цели файловые сервисы операционной системы, вся реальная обработка данных в таких СУБД осуществляется в клиентском приложении, и любые библиотеки доступа к данным в этом случае также находятся в адресном пространстве клиентского приложения. Поэтому при выполнении запросов данные, на основании которых выполняется такой запрос, должны быть доставлены в то же самое адресное пространство клиентского приложения. Это и приводит к перегрузке сети при увеличении числа пользователей и объема данных, а также грозит иными неприятными последствиями, например разрушением индексов и таблиц. Недаром до сих пор популярны утилиты для "ремонта" испорченных файлов настольных СУБД.
Недостатки архитектуры "файл-сервер" решаются при переводе приложений в архитектуру "клиент-сервер", которая знаменует собой следующий этап в развитии СУБД. Характерной особенностью архитектуры "клиент-сервер" является перенос вычислительной нагрузки на сервер базы данных (SQL-сервер) и максимальная разгрузка приложения клиента от вычислительной работы, а также существенное укрепление безопасности данных - как от злонамеренных, так и просто ошибочных изменений.
БД в этом случае помещается на сетевом сервере, как и в архитектуре "файл-сервер", однако прямого доступа к базе данных (БД) из приложений не происходит. Функция прямого обращения к БД осуществляет специальная управляющая программа - сервер БД (SQL-сервер), поставляемый разработчиком СУБД.
|
|
