Сотри случайные черты, и ты увидишь - мир прекрасен.
Александр Блок
Абстрагирование - принцип игнорирования второстепенных аспектов предмета с целью
выделения главных. Математики считают, что абстрактные системы помогают нам организовать
наш мир и наше мышление.
Абстрагирование в информатике имеет некоторые особенности, отмеченные Питером Деннингом
(Peter Denning) в следующем определении. Абстрагирование в информатике - моделирование
возможных реализаций. Модели подавляют детали, но оставляют существенные особенности.
Отличие от математики еще и в том, что мы рассматриваем абстракции одновременно как
по отношению к решаемой проблеме, так и по отношению к физической машине (второе в
математических абстракциях отсутствует). Мы рассмотрим три типа абстракций в языках
программирования [Appleby 1991].
Абстракцию данных (см. разд. 4.3.2).
Абстракцию управления (см. разд. 4.3.3).
Абстракцию модульности (см. разд. 4.3.4).
Абстрагирование особенно актуально для двух групп языков, которые мы определили
как языки моделирования и программирования.
3.2. Абстракция данных
Исключительное использование сильно типизированного языка является
фактором, в наибольшей степени определяющим возможность проектирования сложной системы
в короткий срок. Н. Вирт
3.2.1. Данные и типы данных
Данные - отдельные элементы, которые могут быть собраны вместе некоторым образом.
Большинство языков программирования имеют хотя бы один встроенный тип данных (как
правило, целые числа).
Исторически можно проследить несколько этапов в становлении типов данных в языках
программирования.
Первый этап. В описании языка заданы все типы данных, которые могут быть использованы.
Например, для языка FORTRAN II это пять простых типов - целые, вещественные, вещественные
двойной точности, комплексные и логические. Единственный структурный тип - массив.
Второй этап. Появление в языках разветвленных средств конструирования типов данных.
Этот этап характеризуют языки Algol-68 и Pascal.
Третий этап. Осознание необходимости абстрактных типов данных. Языки CLU, Modula,
Ada.
Четвертый этап. Появление понятия класса в языках программирования. Языки программирования
- Smalltalk, Object Pascal, C++.
3.2.2. Эволюция определения типа данных
Современное определение типа данных звучит так. Тип данных - это множество значений,
определяемых посредством множества операций.
Далее мы перечислим еще три определения типа данных, появлявшихся последовательно
[Замулин 1990]. В них прослеживается изменение математической позиции с теоретико-множественной
(которая допускает готовые актуально-бесконечные множества) на конструктивную. Конструктивная
позиция рассматривает только потенциально-бесконечные множества, конечные в каждый
момент времени, но дающие возможность добавлять новые элементы.
Тип данных - множество значений. Это самое первое определение типа данных, просуществовавшее
более 15 лет. Оно было актуально для того времени, когда языки программирования предоставляли
лишь ограниченное количество встроенных стандартных типов данных. Неестественность
этого определения для конструктивного по своей сути программирования была отмечена
в 1973 году Джеймсом Моррисом в знаменитой статье "Типы - не множества" [Morris 1973].
Тип данных характеризуется не столько множеством значений, сколько множеством
операций. Таким образом, для определения типа данных требуется образовать множество
операций, конструирующих и анализирующих его значения. Это одно из первых конструктивных
определений.
Тип данных - множество операций, задающих интерпретацию значений универсального
пространства значений. Это конструктивно-операционное определение типа данных.
Об основном вопросе в области типов данных
Основной вопрос в области типов данных можно сформулировать так. Что первично-
данные или типы данных? Мы будем становиться на точку зрения конструктивистов (рассматриваются
только потенциально-бесконечные множества), которая ближе программированию. Первичность
типов данных подчеркивает необходимость двух классов операций - конструкторов данных
определенного типа и анализаторов, определяющих принадлежность данных к определенному
типу.
3.2.3. Абстрактные типы данных
Абстрактным типом данных будем называть модуль, внутренняя часть которого скрыта
от пользователя, и работа с модулем разрешается только при помощи операций.
Развернутое определение абстрактного типа данных включает в себя следующие части:
внешность, содержащую имя типа данных и операций, с указанием типов их аргументов
и типа значения;
абстрактное описание операций и объектов, с которыми они работают, средствами
некоторого языка спецификаций;
конкретное описание операций и объектов средствами обычного языка программирования;
описание того, насколько абстрактное описание представляется конкретным.
Обоснование применимости концепции абстрактных типов данных в практике программирования
было сделано Хоаром (С.A.R. Hoare). Некоторая программа, работающая с данными типа
т и содержащая последовательность операторов, реализующих операции с этим типом, может
быть преобразована в функционально-эквивалентную программу. В результирующей программе
каждая операция с типом т может быть описана в виде функции, а все явно запрограммированные
действия с этим типом могут быть заменены вызовами соответствующих функций.
3.2.4. Разновидности полиморфизма
Все языки могут быть разделены на две группы.
Мономорфные языки, в которых каждое значение и каждая переменная интерпретируются
как принадлежащие одному и только одному типу. Хоар еще в 1975 году отмечал, что размышлять
о типах легче, если придерживаться следующего важного принципа: каждое значение, переменная
и выражение принадлежат одному и только одному типу.
Полиморфные языки, в которых некоторые значения и переменные интерпретируются
как принадлежащие более чем одному типу. ,
Полиморфные типы - типы, чьи операции применимы к значениям более чем одного типа.
Полиморфные функции - функции, чьи операции (параметры) могут иметь значения более
одного типа.
Выделяют два класса и четыре основных подкласса полиморфизма [Cardelli, Wegner
1985].
Универсальный полиморфизм, который будет нормально работать с бесконечным количеством
типов.
Параметрический полиморфизм, в котором полиморфная функция имеет явный или неявный
параметр - тип, определяющий тип аргумента для каждого приложения функции. Примером
могут служить родовые функции.
Полиморфизм включения, в котором объект можно рассматривать как принадлежащий
многим классам. Полиморфизм включения позволяет моделировать подтипы и наследование.
О подклассах универсального полиморфизма
В некотором смысле параметрический полиморфизм аналогичен связыванию на этапе компиляции,
а полиморфизм включения - связыванию на этапе исполнения.
Неуниверсальный полиморфизм, работающий на конечном множестве различных и потенциально
не связанных друг с другом типов.
Перегрузка - это использование для различных функций одного и того же имени,
причем для определения требуемой функции используется контекст.
Приведение - это семантическая операция, необходимая для выполнения преобразования
аргумента к типу, требуемому функцией.
Поясним разницу между перегрузкой и приведением на простом примере. Рассмотрим
оператор сложения, применяемый к различным типам операндов:
3 + 4
3.0 + 4
3 + 4.0
3.0 + 4.0
Неуниверсальный полиморфизм оператора сложения + может быть представлен тремя случаями.
Оператор имеет четыре перегруженных смысла, по одному для каждой комбинации.
Оператор имеет два перегруженных смысла, для целых и вещественных. В том случае,
когда один из операндов целый, а другой - вещественный, целый будет приведен к вещественному.
Оператор определен только для вещественных аргументов. Целочисленные аргументы
всегда приводятся к вещественным.
О перегрузке
Бьерн Страуструп (Bjarne Stroustrup) в статье "Generalizing Overloading for С++ 2000"
(http://www.research.att.com/-bs/papers.html),
датируемой 1 апреля 1998 г., предлагает развивать идеи перегрузки в языке C++. Например,
предлагается перегружать не только пробелы, но и пропущенные пробелы.
3.2.5. Статический и динамический контроль типов
Контроль типов должен выяснять возможность применения данной операции к данным
аргументам.
Существуют два типа контроля.
Статический контроль - контроль периода компиляции. Статический контроль обеспечивает
эффективную реализацию полиморфизма имен операций.
Динамический контроль - контроль периода выполнения. Он обеспечивает универсальность
и надежность, а также дополнительную гибкость.
3.2.6. Статически и динамически типизируемые языки программирования
Языки программирования могут быть статически и динамически типизируемыми. -. ,.|
В статически типизируемых языках программирования семантика каждой1 языковой
конструкции определяется по тексту программы, а не во время выполнения. В описании
переменной всегда указывается тип ее возможных значений.
В динамически типизируемых языках семантика конструкции определяется во время
исполнения.
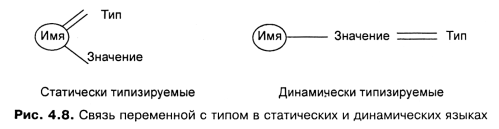
На рис. 4.8 указана связь имени объекта (переменной) с типом и значением для статических
и динамических языков программирования. Одинарная линия на рисунке показывает переменную
связь, а двойная линия - фиксированную, жесткую связь.
Одним из наиболее интересных динамически типизируемых языков программирования является
язык "Автокод Эльбрус" [Сафонов 1989]. При определении переменной целочисленного типа
данных отводится лишь области памяти необходимого формата. Например, описание ф64
а указывает на необходимость отведения для переменной а 64-х битов, в которых далее
может быть размещено целое число. Динамическая типизация может быть эффективно поддержана
аппаратной реализацией (например, архитектура Эльбрус для языка "Автокод Эльбрус").
Статически типизируемые языки программирования чаще всего имеют смешанный контроль
типов данных. Можно выделить три основные группы таких языков.
Слабо типизируемые языки, в которых информация о типе служит только для обеспечения
корректности программы на машинном уровне (например, язык С).
Сильно типизируемые языки, осуществляющие полный контроль типов (например, язык
Ada).
Строго типизируемые языки. В таких языках (например, в языке Pascal) программы,
содержащие конструкции с возможной типовой ошибкой, считаются недопустимыми, даже
если ошибка никогда не может возникнуть.
3.3. Абстракция управления
3.3.1. Структурное программирование
Изучение абстракции управления мы начнем со структурного программирования. Самое
общеизвестное определение структурного программирования - подход к программированию,
в котором для передачи управления в программе используется три конструкции: последовательная,
выбора и итеративная.
Примерно так выглядело историческое становление концепции структурного программирования:
классическая теорема Боэма и Джакопини о структурном программировании утверждает,
что всякую правильную программу (т. е. программу с одним входом и одним выходом, без
зацикливаний и недостижимых веток) можно записать с использованием следующих логических
структур:
последовательности двух или более операторов;
дихотомического выбора;
повторения;
Эдсгер Дейкстра [Дейкстра 1975] предложил отказаться от оператора безусловного
перехода и ограничиться тремя конструкциями - последовательностью, выбором и циклом;
Дональд Кнут продемонстрировал случаи, в которых оператор безусловного перехода
оказывался полезным (например, выход из нескольких вложенных циклов) и подверг критике
утверждение Дейкстры.
Чем еще интересны структурированные программы? В 1965 году академик Глушков обратил
внимание на то, что структурированные программы можно рассматривать как формулы в
некоторой алгебре. Зная правила преобразования выражений в такой алгебре, можно осуществлять
глубокие формальные (и, следовательно, автоматизированные) преобразования программ.
О структурном программировании
Структурное программирование - не самоцель, его основное назначение - получение хорошей
программы. Однако даже в самой хорошей программе операторы перехода требуются, например
при выходе из множества вложенных циклов.
3.3.2. Визуальное структурное программирование
Визуальное структурное программирование также базируется на классической работе
[Дейкстра 1975]. Дейкстра предлагает ограничить топологию блок-схем, запретив проведение
стрелок из любого блока в любой другой блок. Идея визуального структурного программирования
- перейти от одномерного линейного представления программы к двумерному, графическому.
Языки такого программирования - это языки моделирования. На сегодняшний день наиболее
известны три из них.
Язык блок-схем ограниченной топологии. То есть большое многообразие блок-схем
должно быть приведено к трем типам операторов управления.
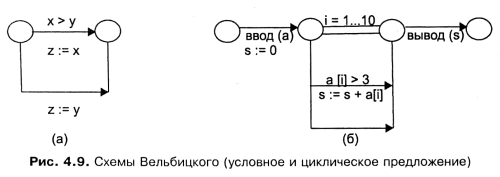
Язык схем Вельбицкого [Вельбицкий 1984]. Эти схемы отличаются от большинства
национальных стандартов построения блок-схем тем, что используется граф, нагруженный
по дугам, а традиционная технология использует граф, нагруженный по вершинам (узлам).
На рис. 4.9 представлены два примера, показывающих представление условного (рис. 4.9,
а) и циклического (рис. 4.9, б) предложения в виде схем Вельбицкого. Такие схемы примерно
на 25% компактнее классических блок-схем.
Язык схем ДРАКОН [Паронджанов 1999]. В этом языке используются два типа элементов
- графические фигуры (графоэлементы) и текстовые надписи (текстоэлементы). Одновременное
использование графики и текста стимулирует одновременно и логическое и образное мышление.
Фактически существует целое семейство языков ДРАКОН:
ДРАКОН-2 - язык визуального программирования систем реального времени, элемент
CASE-технологии;
гибридные визуальные языки программирования, например, ДРАКОН-ПАСКАЛЬ. В таких
языках к визуальному синтаксису языка ДРАКОН по определенным правилам присоединяется
текстовый синтаксис (например, языка Pascal).
Графоэлементы языка ДРАКОН называются иконами, которые могут объединяться в составные
иконы - макроиконы. Шампур-блок - часть ДРАКОН-схемы, имеющая один вход сверху и один
выход снизу, элементы, расположенные на одной вертикали. Терминатор - часть ДРАКОН-схемы,
имеющая либо один выход снизу и не имеющая входа, либо один вход сверху и не имеющая
выхода. Ветки - смысловые блоки, куски алгоритма, представляющие составной оператор
языка ДРАКОН. С помощью веток удобно формализовать смысловое разбиение проблемы, программы
или процесса на части и дать частям удобные смысловые названия. На рис. 4.10 приводится
пример ДРАКОН-схемы с двумя ветками.
Обратим внимание на то, что долгое время в Америке отвергалась идея визуального
программирования, и основной упор там делался на создание универсального языка программирования.
3.3.3. Оператор перехода
Оператор перехода служит для того, чтобы изменить последовательность выполнения
операторов программы.
С точки зрения языка высокого уровня выделяют:
условный оператор (предусматривающий два варианта пути). Обычно в языках программирования
он имеет синтаксис
if (условие) then действие;
оператор выбора (многопутевой). Его типичный синтаксис
switch дискриминант case значение
действие case ...;
Укажем некоторые особенности условного оператора в разных языках программирования:
ряд языков (С и Algol-68) позволяют использовать присваивание в контексте выражений.
Таким образом, в условии может быть присваивание, например
if ( х = у < z) ...;
правило языка С: часть else принадлежит ближайшему оператору if, к которому может
быть присоединена;
ряд языков программирования имеют завершающую "скобку" для условного предложения.
Например, if - fi в языке
Algol-68 и if - end if в языке
Ada;
в языке программирования Ada существуют два различных условных предложения -
одно с частью else, а другое
без нее.
3.3.4. Оператор итерации
Под итерацией будем понимать обращение ко всем элементам агрегата в определенном
порядке, причем каждый элемент посещается единожды. Самый простейший пример итератора
- оператор for. Многие языки поддерживают также операторы while ... do ... И repeat
. . . until.
В некоторых языках программирования итератор традиционно представляется в виде
процедуры. Например, так на языке CLU может быть написано суммирование всех элементов
множества s с помощью итератора elements (s) (листинг 4.1).
Итераторы могут быть положены в основу декларативного программирования. Так можно
на декларативном языке указать множество жителей города Старый Петергоф:
which (х: х живет в Старом Петергофе)
В языках программирования, предназначенных для разработки систем реального времени,
отношение к итераторам особое.
Язык не должен поддерживать циклы while.
Цикл for разрешается использовать только с константными параметрами.
Для периодических событий используется специальная конструкция, например every
(...) do {...}.
3.3.5. Оператор исключения
Говорят, что в программе имеет место исключение, когда выполнение программы прерывается
из-за возникновения некоторого события. Исключения, как правило, должны обрабатываться
программным образом, после чего исполнение программы должно продолжаться дальше. Наиболее
важно, чтобы поступление событий обрабатывалось соответствующим образом в системах
реального времени (например, в программном обеспечении атомных электростанций или
космических кораблей, находящихся в длительном космическом перелете).
Одно из наиболее подробных исследований принципов реализации исключений было выполнено
Страуструпом [Страуструп 2000]. В частности, им обсуждались две стратегии обработки
исключений в языке C++.
Стратегия с возобновлением, в которой обработчик исключения может потребовать
возобновления исполнения программы с того момента, где было возбуждено исключение.
Стратегия с прекращением исполнения. Именно она в конечном итоге была принята,
поскольку реальный практический опыт использования исключений в больших системах свидетельствовал
в ее пользу.
В общем случае следует обращать внимание на реализационные особенности исключений,
приведенные ниже.
Могут ли системные исключения быть перекрыты пользователем?
Каков механизм обработки пользовательских исключений?
Как определяется область действия участка кода, в котором происходит событие
и, следовательно, обрабатывается исключение?
Допускаются ли в языке множественные исключения?
Можно ли передать параметры обработчику исключения?
Существует ли автоматическая (по умолчанию) обработка исключений?
Обратим внимание на то, что многие широко распространенные языки программирования
(например, Pascal) не имеют механизма обработки прерываний.
Понятие обработки событий впервые появилось в языке PL/I. Система прерываний (так
это называлось в PL/I) была предназначена для проверки и обработки различных условий,
которые могут возникнуть в ходе выполнения программы. Основные категории условий в
языке PL/I следующие:
вычислительные условия (например, переполнение или деление на ноль);
условия ввода-вывода (например, конец файла или аппаратная ошибка,, устройства
ввода-вывода);
программные условия (например, выход индекса за границу массива или изменение
значения некоторой переменной).
Программист может явным образом разрешать или запрещать проверку почти всех условий
с помощью явных префиксов, приписываемых к инструкциям, блокам или подпрограммам.
Например, в данном случае в блоке будет выполняться проверка на выход индекса за границы
массива:
(subscriptrange): begin
...
end;
Язык "Автокод Эльбрус" имеет конструкцию, называемую структурное предложение. Это
наиболее развитый на сегодняшний день механизм обработки событий, который образно
можно назвать "goto с человеческим лицом". Основные ситуации в языке "Автокод Эльбрус"
таковы:
статические события, непосредственно связанные со статической структурой текста
программы (например, достижение необходимой точности вычислений);
динамические события, в которых отсутствует фиксированная связь с определенной
точкой в тексте программы (например, ситуация конец файла для совокупности процедур
работы с файлами);
стандартные события, приводящие к прерываниям при выполнении стандартных операций
(например, переполнение или деление на ноль). Они приводят к прерываниям процессора
и обращению к операционной системе (собственно, в этом их отличие от динамических
ситуаций).
Пример структурного предложения языка "Автокод Эльбрус" выглядит так:
до c1, с2
% закрытое предложение
...
при
c1: <обработчик 1>,
с2: <обработчик 2>
всесит
Структурный переход по ситуации c1 в закрытом предложении может быть выполнен,
например, следующим образом: c1!.
3.3.6. Зависимости по управлению и по данным
Важную роль при анализе возможности распараллеливания программы играют зависимости
по управлению и по данным. Для их анализа может быть построен граф программной зависимости.
Его вершинами являются операторы и предикатные выражения, а дуги указывают значения
данных, от которых зависят операции, и управляют условиями, от которых зависит выполнение
операции.
Пример зависимости по управлению:
if ( c1)
{ s1; } /*исполнение этого оператора
зависит от c1 */
s2;
Существуют три разновидности зависимости по данным.
Истинная (потоковая) зависимость по данным. Значение переменной, вычисляемое
в операторе si, используется в операторе s2. Операторы si и s2 нельзя выполнять параллельно.
S1: а:=3;
S2: b:=a;
S3: с:=а+3;
Антизависимость. Переменная в операторе si используется до того, как получает
новое значение в s2. Операторы si и s2 нельзя выполнять параллельно.
S1: а:=b+3;
S2: b:=47;
Выходная зависимость. Переменная в операторе s3 получает новое значение после
того, как уже получила некоторое значение в si.
S1: a:=x+2;
S2: b:=a-3;
S3: а:=с-45;
Множество всех зависимостей задает на операторах и предикатах частичный порядок,
которому нужно следовать, чтобы сохранить семантическую целостность программы.
3.4. Абстракция модульности
3.4.1. Модульное программирование
Модульное программирование - это такой способ программирования, при котором вся
программа разбивается на группу компонентов, называемых модулями, причем каждый из
них имеет свой контролируемый размер, четкое назначение и детально проработанный интерфейс
с внешней средой. Единственная альтернатива модульности - монолитная программа, что,
конечно, неудобно. Таким образом, наиболее интересный вопрос при изучении модульности
- определение критерия разбиения на модули. В основе модульного программирования лежат
три основные концепции.
Принцип утаивания информации Парнаса. Всякий компонент утаивает единственное
проектное решение, т. е. модуль служит для утаивания информации. Подход к разработке
программ заключается в том, что сначала формируется список проектных решений, которые
особенно трудно принять или которые, скорее всего, будут меняться. Затем определяются
отдельные модули, каждый из которых реализует одно из указанных решений.
Аксиома модульности Коуэна. Модуль - независимая программная единица, служащая
для выполнения некоторой определенной функции программы и для связи с остальной частью
программы. Программная единица должна удовлетворять следующим условиям:
блочность организации, т. е. возможность вызвать программную единицу из блоков
любой степени вложенности;
синтаксическая обособленность, т. е. выделение модуля в тексте синтаксическими
элементами;
семантическая независимость, т. е. независимость от места, где программная единица
вызвана;
общность данных, т. е. наличие собственных данных, сохраняющихся при каждом обращении;
полнота определения, т. е. самостоятельность программной единицы.
Сборочное программирование Цейтина. Модули - это программные кирпичи, из которых
строится программа. Существуют три основные предпосылки к модульному программированию:
стремление к выделению независимой единицы программного знания. В идеальном случае
всякая идея (алгоритм) должна быть оформлена в виде модуля;
потребность организационного расчленения крупных разработок;
возможность параллельного исполнения модулей (в контексте параллельного программирования).
3.4.2. Определения модуля и его примеры
Приведем несколько дополнительных определений модуля.
Модуль - это совокупность команд, к которым можно обратиться по имени.
Модуль - это совокупность операторов программы, имеющая граничные элементы и
идентификатор (возможно агрегатный).
Функциональная спецификация модуля должна включать:
синтаксическую спецификацию его входов, которая должна позволять построить на
используемом языке программирования синтаксически правильное обращение к нему;
описание семантики функций, выполняемых модулем по каждому из его входов.
Существуют три основные разновидности модулей, приведенные ниже.
"Маленькие" (функциональные) модули, реализующие, как правило, одну какую-либо
определенную функцию. Основным и простейшим модулем практически во всех языках программирования
является процедура или функция.
"Средние" (информационные) модули, реализующие, как правило, несколько операций
или функций над одной и той же структурой данных (информационным объектом), которая
считается неизвестной вне этого модуля. Примеры "средних" модулей в языках программирования:
задачи в языке программирования Ada;
кластер в языке программирования CLU;
классы в языках программирования C++ и Java.
"Большие" (логические) модули, объединяющие набор "средних" или "маленьких" модулей.
Примеры "больших" модулей в языках программирования:
модуль в языке программирования Modula-2;
пакеты в языках программирования Ada и Java.
3.4.3. Характеристики модульности
Первый набор характеристик предложен Хольтом [Holt 1975]. Это два общих требования.
Хороший модуль снаружи лучше, чем внутри.
Хороший модуль легче использовать, чем построить.
Второй набор предложен Майерсом [Майерс 1980]. Он состоит из следующих конструктивных
характеристик:
размера модуля;
прочности (связности) модуля;
сцепления модуля с другими модулями;
рутинности (идемпотентность, независимость от предыдущих обращений) модуля. Набор
этих характеристик мы сейчас рассмотрим более подробно.
Размер модуля
Вот несколько общих советов по наилучшему размеру модуля.
В модуле должно быть 7 (+/-2) конструкций (например, операторов для функций или
функций для пакета).
О необходимости именно 7 (+/-2) конструкций
Это число берется на основе представлений психологов о среднем оперативном буфере
памяти человека. Символьные образы в человеческом мозгу объединяются в "чанки" - наборы
фактов и связей между ними, запоминаемые и извлекаемые как единое целое. В каждый
момент времени человек может обрабатывать не более 7 чанков.
Модуль (функция) не должен превышать 60 строк. В результате его можно поместить
на одну страницу распечатки или легко просмотреть на экране монитора.
Связность (прочность) модуля
Существует гипотеза о глобальных данных, утверждающая, что глобальные данные вредны
и опасны. Идея глобальных данных дискредитирует себя так же, как и идея оператора
безусловного перехода goto. Локальность данных дает возможность легко читать и понимать
модули, а также легко удалять их из программы.
Связность (прочность) модуля (cohesion) - мера независимости его частей. Чем выше
связность модуля - тем лучше, тем больше связей по отношению к оставшейся части программы
он упрятывает в себе. Можно выделить типы связности, приведенные ниже.
Функциональная связность. Модуль с функциональной связностью реализует одну какую-либо
определенную функцию и не может быть разбит на 2 модуля с теми же типами связностей.
Последовательная связность. Модуль с такой связностью может быть разбит на последовательные
части, выполняющие независимые функции, но совместно реализующие единственную функцию.
Например, один и тог же модуль может быть использован сначала для оценки, а затем
для обработки данных.
Информационная (коммуникативная) связность. Модуль с информационной связностью
- это модуль, который выполняет несколько операций или функций над одной и той же
структурой данных (информационным объектом), которая считается неизвестной вне этого
модуля. Эта информационная связность применяется для реализации абстрактных типов
данных.
О средствах задания информационной связности
Обратим внимание на то, что средства для задания информационно прочных модулей отсутствовали
в ранних языках программирования (например, FORTRAN и даже в оригинальной версии языка
Pascal). И только позже, в языке программирования Ada, появился пакет- средство задания
информационно прочного модуля.
При написании программ следует применять по возможности лишь три вышеперечисленных
типа связности. Перечисленных ниже типов связности следует стараться избегать.
Процедурная связность получается, когда действия сгруппированы вместе благодаря
тому, что они выполняются в течение одной и той же части цикла или процесса.
Временная связность представляет действия, связанные во времени. Например, в
модуле объединяются действия, которые должны быть выполнены в определенный момент
времени.
Логическая связность возникает, когда в модуль объединяются действия только по
признаку их некоторого подобия. Например, в один модуль объединяются функции, предназначенные
для проверки корректности входных данных для всей программы. Как исключение, логическая
связность естественна и допустима только для "больших" модулей.
Случайная связность возникает тогда, когда действия объединяются произвольным,
случайным образом.
Сцепление модулей
Сцепление (coupling) - мера относительной независимости модуля от других модулей.
Независимые модули могут быть модифицированы без переделки других модулей. Чем слабее
сцепление модуля, тем лучше. Рассмотрим различные типы сцепления.
Независимые модули - это идеальный случай. Модули ничего не знают друг о друге.
Организовать взаимодействие таких модулей можно, зная их интерфейс и соответствующим
образом перенаправив выходные данные одного модуля на вход другого. Например, в операционной
системе Unix это можно сделать с помощью каналов (pipes) для ничего не знающих друг
о друге модулей а и b следующим образом - а | b. Достичь такого сцепления сложно,
да и не нужно, поскольку сцепление по данным (параметрическое сцепление) является
достаточно хорошим.
Сцепление по данным (параметрическое) - это сцепление, когда данные передаются
модулю, как значения его параметров, либо как результат его обращения к другому модулю
для вычисления некоторой функции. Этот вид сцепления реализуется в языках программирования
при обращении к функциям (процедурам). Две разновидности этого сцепления определяются
характером данным.
Сцепление по простым элементам данных.
Сцепление по структуре данных. В этом случае оба модуля должны знать о внутренней
структуре данных.
Оставшиеся три типа сцепления не рекомендуется использовать.
Сцепление по управлению ("флажковая зависимость") - это сцепление, в котором
один модуль управляет решениями внутри другого с помощью передачи флагов, переключателей
или специальных кодов. Таким образом, вызывающий модуль должен достаточно подробно
знать структуру вызываемого.
Сцепление по внешним ссылкам возникает, когда у одного модуля есть доступ к данным
в другом модуле.
Сцепление по кодам возникает, если коды инструкций модулей перемежаются друг
с другом. Обычно эта ситуация возникает когда одному из модулей доступна внутренняя
область другого. Сцепление по кодам позволено в языке программирования PL/I.
Рутинность модуля
Рутинность - это независимость модуля от предыдущих обращений к нему (от предыстории).
Будем называть модуль рутинным, если результат его работы зависит только от количества
переданных параметров (а не от количества обращений).
Модуль должен быть рутинным в большинстве случаев, но есть и случаи, когда модуль
должен сохранять историю. В выборе степени рутинности модуля пользуются тремя рекомендациями.
В большинстве случаев делаем модуль рутинным, т. е. независимым от предыдущих
обращений.
Зависящие от предыстории модули следует использовать только в тех случаях, когда
это необходимо для сцепления по данным.
В спецификации зависящего от предыстории модуля должна быть четко сформулирована
эта зависимость, чтобы пользователи имели возможность прогнозировать поведение такого
модуля.
Знаете ли Вы, что Instance, экземпляр объекта в объектно-ориентированном программировании - это конкретный объект из набора объектов данного класса. Все экземпляры одного класса имеют одинаковый набор операций.